Nota del autor: Análisis profundo de las capacidades de codificación, el rendimiento de agentes y los métodos de acceso a la API de las versiones MiniMax-M2.5 y M2.5-Lightning. Con un 80.2% en SWE-Bench, se sitúa muy cerca del 80.8% de Opus 4.6, pero a solo 1/60 del precio.
MiniMax lanzó el 12 de febrero de 2026 las versiones MiniMax-M2.5 y M2.5-Lightning. Se trata del primer modelo de código abierto que supera a Claude Sonnet en capacidades de programación, alcanzando un 80.2% en SWE-Bench Verified, solo 0.6 puntos porcentuales por debajo de Claude Opus 4.6. Ambos modelos ya están disponibles en la plataforma APIYI. Además, mediante las promociones de recarga, es posible obtener un precio un 20% inferior al de la web oficial.
Valor principal: Gracias a los datos de pruebas reales y los ejemplos de código de este artículo, conocerás las diferencias clave entre las dos versiones de MiniMax-M2.5, podrás elegir la que mejor se adapte a tus necesidades y aprenderás a integrar su API rápidamente.

Resumen de capacidades clave de MiniMax-M2.5
| Indicadores clave | MiniMax-M2.5 Estándar | MiniMax-M2.5-Lightning | Valor diferencial |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.2% (Misma capacidad) | Cercano al 80.8% de Opus 4.6 |
| Velocidad de salida | ~50 TPS | ~100 TPS | Lightning es el doble de rápido |
| Precio de salida | $0.15/$1.20 por millón de Tokens | $0.30/$2.40 por millón de Tokens | La versión estándar cuesta solo 1/63 que Opus |
| Llamadas a herramientas BFCL | 76.8% | 76.8% (Misma capacidad) | Muy por encima del 63.3% de Opus |
| Ventana de contexto | 205K tokens | 205K tokens | Soporta el análisis de grandes bases de código |
Detalles de la capacidad de codificación de MiniMax-M2.5
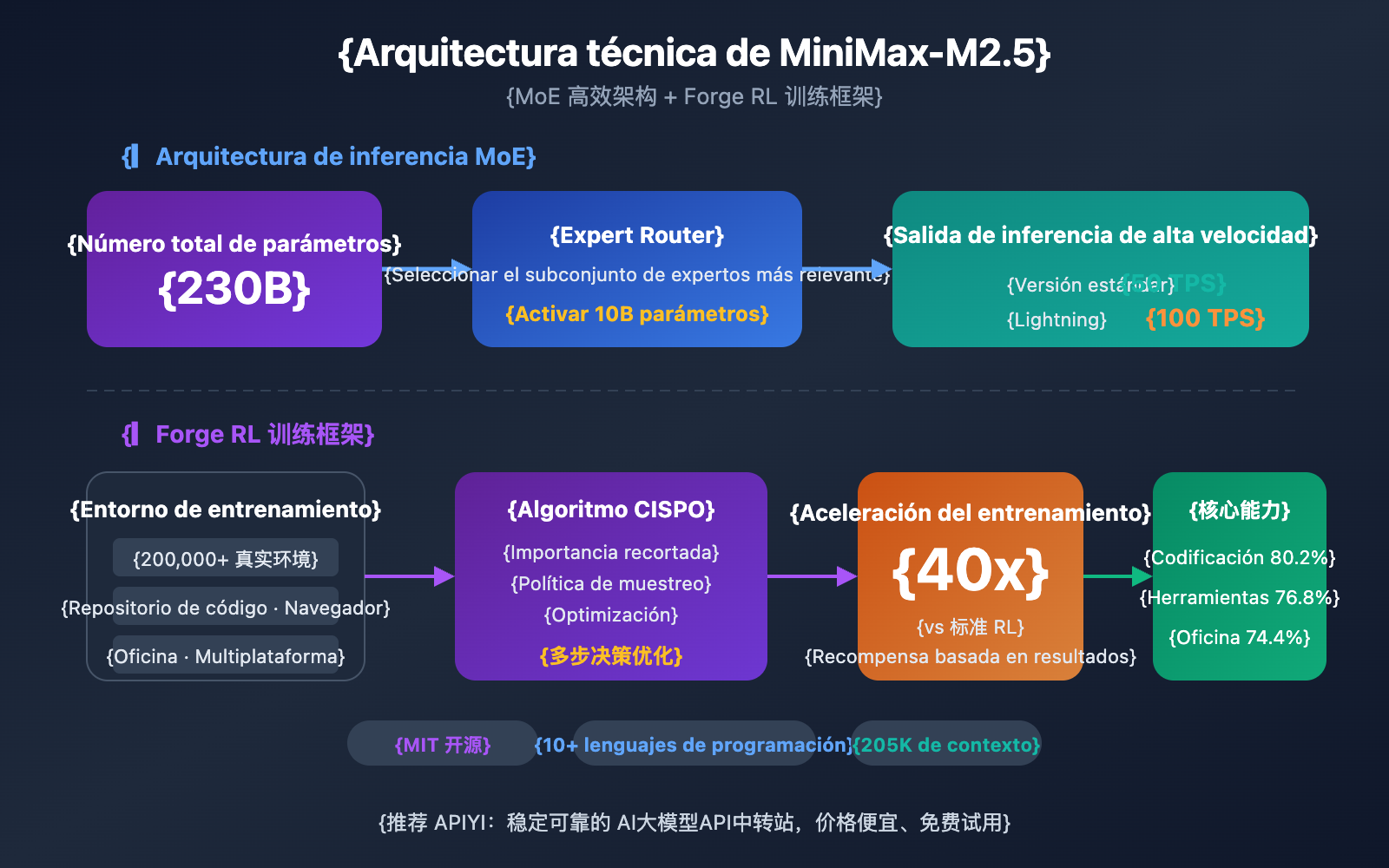
MiniMax-M2.5 utiliza una arquitectura MoE (Mixture of Experts) con un total de 230B de parámetros, aunque solo activa 10B para la inferencia. Este diseño permite que el modelo mantenga capacidades de programación de vanguardia reduciendo drásticamente los costes de computación.
En tareas de programación, el M2.5 muestra una "tendencia a la redacción de especificaciones" única: antes de ponerse manos a la obra con el código, realiza un desglose de la arquitectura y una planificación del diseño del proyecto. Este patrón de comportamiento lo hace destacar especialmente en proyectos complejos de múltiples archivos, logrando una puntuación del 51.3% en Multi-SWE-Bench, superando incluso el 50.3% de Claude Opus 4.6.
El modelo es compatible con el desarrollo full-stack en más de 10 lenguajes, incluyendo Python, Go, C/C++, TypeScript, Rust, Java, JavaScript, Kotlin, PHP, entre otros. Además, soporta proyectos multiplataforma para Web, Android, iOS y Windows.
Capacidades de agentes y llamadas a herramientas de MiniMax-M2.5
El M2.5 obtuvo una puntuación del 76.8% en el benchmark BFCL Multi-Turn, superando con creces el 63.3% de Claude Opus 4.6 y el 61.0% de Gemini 3 Pro. Esto significa que, en escenarios de agentes que requieren diálogos de varios turnos y colaboración entre múltiples herramientas, el M2.5 es actualmente la opción más sólida.
En comparación con la generación anterior (M2.1), el M2.5 reduce en aproximadamente un 20% las rondas de llamadas a herramientas necesarias para completar tareas de agentes, y su velocidad de evaluación en SWE-Bench Verified ha mejorado un 37%. Esta mayor eficiencia en el desglose de tareas reduce directamente el consumo de Tokens y los costes por llamada.
Comparativa entre MiniMax-M2.5 Estándar y versión Lightning
Elegir qué versión de MiniMax-M2.5 utilizar depende de tu escenario de uso específico. Las capacidades de ambos modelos son idénticas; la diferencia principal radica en la velocidad de inferencia y el precio.
| Dimensión de comparación | M2.5 Estándar | M2.5-Lightning | Sugerencia de elección |
|---|---|---|---|
| ID del modelo (API) | MiniMax-M2.5 |
MiniMax-M2.5-highspeed |
— |
| Velocidad de inferencia | ~50 TPS | ~100 TPS | Elige Lightning si necesitas respuesta en tiempo real |
| Precio de entrada | $0.15/M tokens | $0.30/M tokens | Elige la versión Estándar para tareas por lotes |
| Precio de salida | $1.20/M tokens | $2.40/M tokens | La versión Estándar es un 50% más barata |
| Costo de ejecución continua | ~$0.30/hora | ~$1.00/hora | Elige la versión Estándar para tareas en segundo plano |
| Capacidad de programación | Exactamente igual | Exactamente igual | Sin diferencias entre ambos |
| Llamada a herramientas | Exactamente igual | Exactamente igual | Sin diferencias entre ambos |
Guía de escenarios para elegir la versión de MiniMax-M2.5
Cuándo elegir la versión Lightning (Alta velocidad):
- Integración de asistentes de programación en IDE, donde se requiere autocompletado de código en tiempo real y sugerencias de refactorización con baja latencia.
- Diálogo con agentes interactivos, donde el usuario espera una respuesta rápida en atención al cliente o soporte técnico.
- Aplicaciones de búsqueda mejorada en tiempo real, que necesitan navegación web y recuperación de información con feedback inmediato.
Cuándo elegir la versión Estándar:
- Revisión de código por lotes en segundo plano y corrección automática, donde no se requiere interacción en tiempo real.
- Orquestación de tareas de agentes a gran escala y flujos de trabajo asíncronos de larga duración.
- Aplicaciones de alto rendimiento sensibles al presupuesto que buscan el menor costo unitario posible.
🎯 Recomendación: Si no estás seguro de qué versión elegir, te sugerimos probar ambas simultáneamente en la plataforma APIYI (apiyi.com). Puedes alternar entre la versión Estándar y la Lightning bajo la misma interfaz simplemente cambiando el parámetro
modelpara comparar rápidamente la latencia y los resultados.
MiniMax-M2.5 frente a la competencia en capacidad de programación
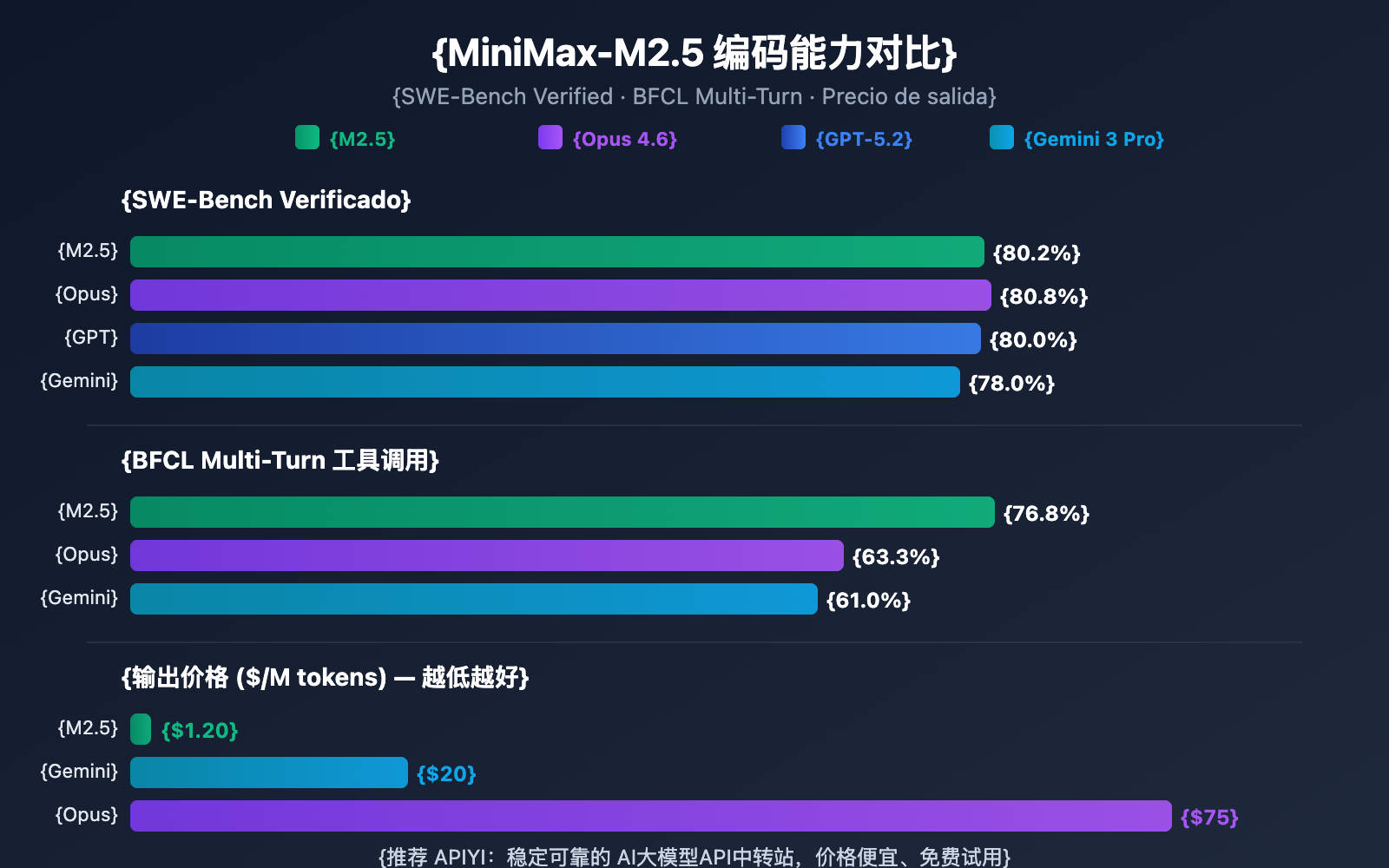
| Modelo | SWE-Bench Verified | BFCL Multi-Turn | Precio de salida/M | Tareas completadas por cada $100 |
|---|---|---|---|---|
| MiniMax-M2.5 | 80.2% | 76.8% | $1.20 | ~328 |
| MiniMax-M2.5-Lightning | 80.2% | 76.8% | $2.40 | ~164 |
| Claude Opus 4.6 | 80.8% | 63.3% | ~$75 | ~30 |
| GPT-5.2 | 80.0% | — | ~$60 | ~30 |
| Gemini 3 Pro | 78.0% | 61.0% | ~$20 | ~90 |
A juzgar por los datos, MiniMax-M2.5 ha alcanzado un nivel de vanguardia en cuanto a capacidad de programación. Su puntuación del 80.2% en SWE-Bench Verified es solo un 0.6% inferior a la de Opus 4.6, pero con una diferencia de precio de más de 60 veces. En cuanto a la capacidad de llamada a herramientas, el 76.8% de M2.5 en BFCL supera con creces a todos sus competidores.
Para los equipos que necesitan desplegar agentes de programación a gran escala, la ventaja de costos de M2.5 significa que, con el mismo presupuesto de $100, se pueden completar aproximadamente 328 tareas, mientras que con Opus 4.6 solo se completarían unas 30.
Nota sobre la comparativa: Los datos de los benchmarks anteriores provienen de cifras oficiales publicadas por cada modelo y de la agencia de evaluación externa Artificial Analysis. El rendimiento real puede variar según el escenario específico de la tarea; se recomienda realizar pruebas en escenarios reales a través de APIYI (apiyi.com).
Acceso rápido a la API de MiniMax-M2.5
Ejemplo minimalista
Esta es la forma más sencilla de acceder a MiniMax-M2.5 a través de la plataforma APIYI; solo necesitas 10 líneas de código para ponerlo en marcha:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="MiniMax-M2.5", # Cambia a MiniMax-M2.5-Lightning para usar la versión de alta velocidad
messages=[{"role": "user", "content": "Implementa un caché LRU en Python"}]
)
print(response.choices[0].message.content)
Ver el código de implementación completo (incluye salida en streaming y llamadas a herramientas)
from openai import OpenAI
from typing import Optional
def call_minimax_m25(
prompt: str,
model: str = "MiniMax-M2.5",
system_prompt: Optional[str] = None,
max_tokens: int = 4096,
stream: bool = False
) -> str:
"""
Llamada a la API de MiniMax-M2.5
Argumentos:
prompt: Entrada del usuario
model: MiniMax-M2.5 o MiniMax-M2.5-Lightning
system_prompt: Indicación del sistema
max_tokens: Número máximo de tokens de salida
stream: Si se habilita la salida en streaming
Retorna:
Contenido de la respuesta del modelo
"""
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
stream=stream
)
if stream:
result = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
result += content
print(content, end="", flush=True)
print()
return result
else:
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Ejemplo de uso: Tarea de programación
result = call_minimax_m25(
prompt="Refactoriza el siguiente código para mejorar el rendimiento y añadir manejo de errores",
model="MiniMax-M2.5-Lightning",
system_prompt="Eres un ingeniero full-stack senior, experto en refactorización de código y optimización de rendimiento",
stream=True
)
Sugerencia: Obtén créditos de prueba gratuitos en APIYI (apiyi.com) para validar rápidamente el rendimiento de MiniMax-M2.5 en tus proyectos reales. La plataforma es compatible con la interfaz de OpenAI, por lo que solo necesitas cambiar los parámetros
base_urlymodelen tu código actual para empezar.
Análisis de la arquitectura técnica de MiniMax-M2.5
La competitividad principal de MiniMax-M2.5 proviene de dos innovaciones técnicas: la arquitectura eficiente MoE (Mezcla de Expertos) y el marco de entrenamiento Forge RL.
Ventajas de la arquitectura MoE de MiniMax-M2.5
| Parámetro de arquitectura | MiniMax-M2.5 | Modelo denso tradicional | Descripción de ventajas |
|---|---|---|---|
| Parámetros totales | 230B | Generalmente 70B-200B | Mayor capacidad de conocimiento |
| Parámetros activos | 10B | Igual a los parámetros totales | Costo de inferencia extremadamente bajo |
| Eficiencia de inferencia | 50-100 TPS | 10-30 TPS | Velocidad 3-10 veces mayor |
| Costo unitario | $1.20/M de salida | $20-$75/M de salida | Reducción de costo de 20 a 60 veces |
La idea central de la arquitectura MoE es la "división del trabajo entre expertos": el modelo contiene múltiples grupos de redes expertas y, en cada inferencia, solo se activa el subconjunto de expertos más relevante para la tarea actual. Con solo 10B de parámetros activos, M2.5 logra resultados cercanos a un modelo denso de 230B, lo que lo convierte en la opción más compacta y económica entre los modelos Tier 1 actuales.
Marco de entrenamiento Forge RL de MiniMax-M2.5
Otra tecnología clave de M2.5 es el marco de aprendizaje por refuerzo Forge:
- Escala del entorno de entrenamiento: Más de 200,000 entornos del mundo real, que incluyen repositorios de código, navegadores web y aplicaciones de oficina.
- Algoritmo de entrenamiento: CISPO (Clipped Importance Sampling Policy Optimization), diseñado específicamente para tareas de decisión de múltiples pasos.
- Eficiencia de entrenamiento: Logra una aceleración de entrenamiento de 40 veces en comparación con los métodos de RL estándar.
- Mecanismo de recompensa: Sistema de recompensa basado en resultados, en lugar de la tradicional retroalimentación de preferencia humana (RLHF).
Este método de entrenamiento hace que M2.5 sea más robusto en tareas de programación real y agentes inteligentes, permitiéndole realizar de manera eficiente la descomposición de tareas, la selección de herramientas y la ejecución de múltiples pasos.
🎯 Sugerencia práctica: MiniMax-M2.5 ya está disponible en la plataforma APIYI (apiyi.com). Se recomienda a los desarrolladores usar los créditos gratuitos para probar escenarios de programación y agentes, y elegir entre la versión estándar o Lightning según sus necesidades reales de latencia y rendimiento.
Preguntas frecuentes
Q1: ¿Hay alguna diferencia de capacidades entre la versión estándar de MiniMax-M2.5 y la versión Lightning?
No hay diferencias. Las capacidades de ambos modelos son exactamente iguales; obtienen las mismas puntuaciones en todos los benchmarks como SWE-Bench y BFCL. La única diferencia radica en la velocidad de inferencia (50 TPS para la versión estándar frente a 100 TPS para la Lightning) y sus respectivos precios. Al elegir, solo necesitas considerar tus requisitos de latencia y tu presupuesto.
Q2: ¿Es MiniMax-M2.5 un buen sustituto para Claude Opus 4.6?
Es una opción a considerar en escenarios de programación y agentes. La puntuación de M2.5 en SWE-Bench (80.2%) es solo 0.6 puntos porcentuales inferior a la de Opus 4.6, mientras que su capacidad de llamada a herramientas (BFCL 76.8%) es significativamente superior. En cuanto al precio, la versión estándar de M2.5 cuesta solo 1/63 de lo que cuesta Opus. Te recomendamos realizar pruebas comparativas en proyectos reales a través de APIYI apiyi.com para decidir según tu caso de uso específico.
Q3: ¿Cómo puedo empezar a probar MiniMax-M2.5 rápidamente?
Recomendamos usar la plataforma APIYI para una integración rápida:
- Visita APIYI apiyi.com y regístrate para obtener una cuenta.
- Obtén tu API Key y créditos de prueba gratuitos.
- Usa los ejemplos de código de este artículo, cambiando el parámetro
modelaMiniMax-M2.5oMiniMax-M2.5-Lightning. - Al ser una interfaz compatible con OpenAI, en proyectos existentes solo necesitas modificar la
base_url.
Resumen
Puntos clave de MiniMax-M2.5:
- Liderazgo en programación: Con un 80.2% en SWE-Bench Verified y un 51.3% en Multi-SWE-Bench, lidera la industria y es el primer modelo de código abierto que supera a Claude Sonnet.
- El mejor en capacidades de agentes: Su puntuación de 76.8% en BFCL Multi-Turn supera ampliamente a todos sus competidores, reduciendo las rondas de llamadas a herramientas en un 20% respecto a la generación anterior.
- Relación calidad-precio extrema: El costo de salida de la versión estándar es de solo $1.20/M tokens, lo que supone 1/63 del costo de Opus 4.6; con el mismo presupuesto puedes completar más de 10 veces el número de tareas.
- Elección flexible entre dos versiones: La versión estándar es ideal para procesamiento por lotes y escenarios donde prima el costo, mientras que la Lightning es perfecta para interacciones en tiempo real y baja latencia.
MiniMax-M2.5 ya está disponible en la plataforma APIYI y admite llamadas mediante la interfaz compatible con OpenAI. Te recomendamos obtener créditos gratuitos en APIYI apiyi.com para realizar pruebas reales; solo tienes que cambiar el parámetro model para alternar y comparar entre ambas versiones.
📚 Referencias
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos utilizan el formato
Nombre del recurso: domain.com. Esto facilita la copia pero evita que sean clicables, previniendo la pérdida de autoridad SEO.
-
Anuncio oficial de MiniMax M2.5: Introducción detallada a las capacidades principales y detalles técnicos de M2.5.
- Enlace:
minimax.io/news/minimax-m25 - Descripción: Documento oficial de lanzamiento que incluye datos completos de benchmarks e introducción a los métodos de entrenamiento.
- Enlace:
-
Documentación de la API de MiniMax: Guía oficial de integración de la API y especificaciones del modelo.
- Enlace:
platform.minimax.io/docs/guides/text-generation - Descripción: Incluye especificaciones técnicas como IDs de modelo, ventana de contexto y ejemplos de llamadas a la API.
- Enlace:
-
Evaluación de Artificial Analysis: Análisis de rendimiento y evaluación de modelos por parte de terceros independientes.
- Enlace:
artificialanalysis.ai/models/minimax-m2-5 - Descripción: Proporciona rankings de benchmarks estandarizados, pruebas de velocidad reales y comparativas de precios.
- Enlace:
-
MiniMax en HuggingFace: Descarga de pesos de modelos de código abierto.
- Enlace:
huggingface.co/MiniMaxAI - Descripción: Código abierto bajo licencia MIT, compatible con despliegues privados en vLLM/SGLang.
- Enlace:
Autor: Equipo Técnico
Intercambio técnico: Te invitamos a comentar tu experiencia de uso con MiniMax-M2.5 en la sección de comentarios. Para más tutoriales sobre integración de APIs de Modelos de Lenguaje Grande, visita la comunidad técnica de APIYI en apiyi.com.