Note de l'auteur : Comparaison approfondie des capacités de programmation entre MiniMax-M2.5 et Claude Opus 4.6 à travers 5 dimensions : SWE-Bench, Multi-SWE-Bench, appels d'outils BFCL, vitesse de codage et prix.
Choisir un assistant de programmation IA est devenu une question centrale pour les développeurs. Cet article compare les capacités de codage de MiniMax-M2.5 et Claude Opus 4.6 selon 5 dimensions clés, afin de vous aider à faire le meilleur choix entre performance et coût.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez clairement les limites de ces deux modèles dans des scénarios de codage réels et saurez quel modèle est le plus rentable selon votre situation.

Différences clés de capacités de programmation : MiniMax-M2.5 vs Claude Opus 4.6
| Dimension de comparaison | MiniMax-M2.5 | Claude Opus 4.6 | Analyse de l'écart |
|---|---|---|---|
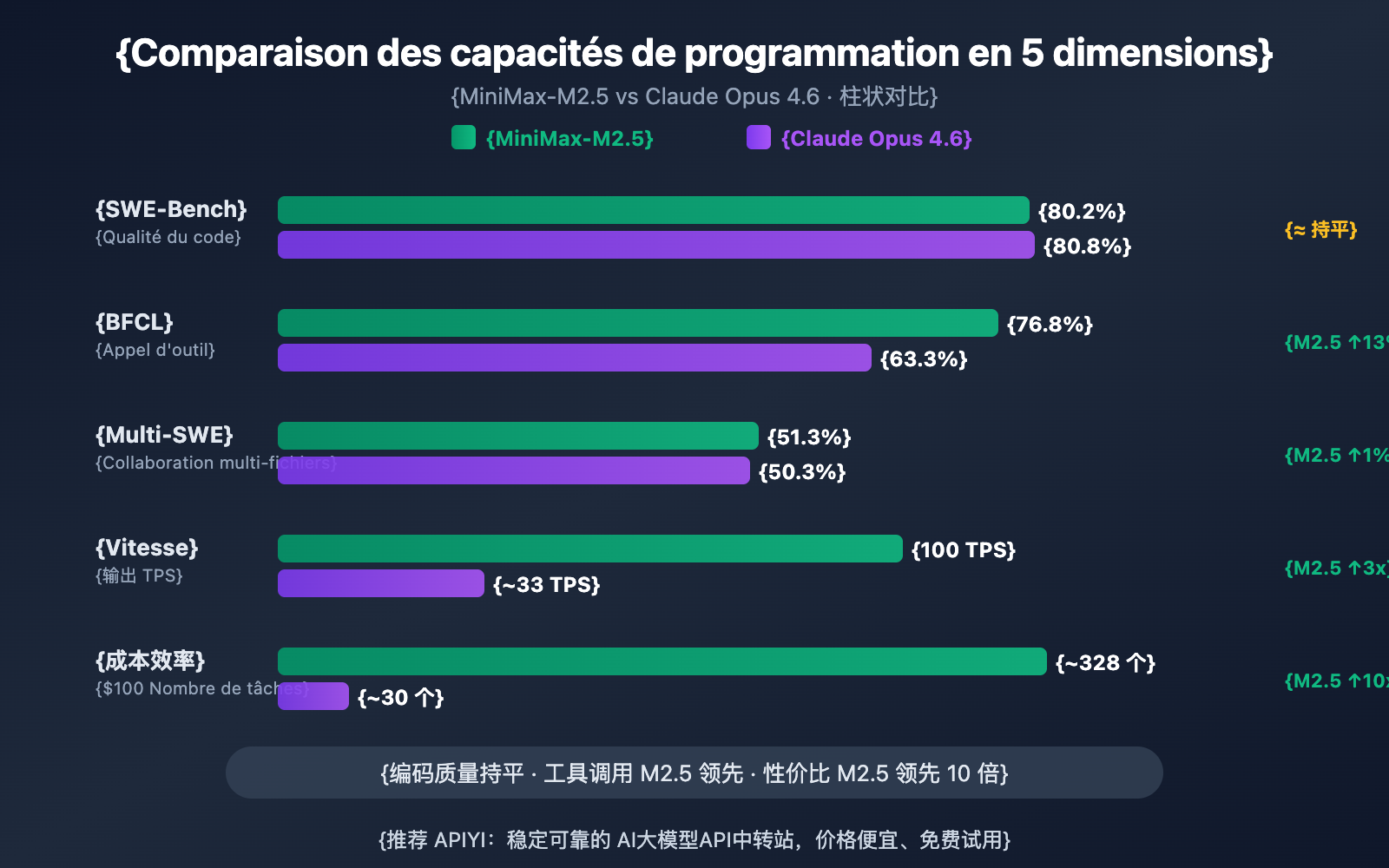
| SWE-Bench Verified | 80,2 % | 80,8 % | Opus ne mène que de 0,6 % |
| Multi-SWE-Bench | 51,3 % | 50,3 % | M2.5 repasse devant de 1,0 % |
| Appels d'outils BFCL | 76,8 % | 63,3 % | M2.5 mène de 13,5 % |
| Vitesse de sortie | 50-100 TPS | ~33 TPS | M2.5 est jusqu'à 3 fois plus rapide |
| Prix de sortie | 1,20 $ / M tokens | 25 $ / M tokens | M2.5 est environ 20 fois moins cher |
Analyse des benchmarks de codage : MiniMax-M2.5 vs Opus 4.6
Si l'on regarde le SWE-Bench Verified, le benchmark de codage le plus reconnu par l'industrie, l'écart entre les deux est infime : les 80,2 % de MiniMax-M2.5 ne sont qu'à 0,6 point de pourcentage derrière les 80,8 % de Claude Opus 4.6. Le SWE-Bench Verified évalue la capacité du modèle à corriger des bugs et à implémenter des fonctionnalités dans de véritables Pull Requests GitHub, ce qui constitue l'évaluation la plus proche des scénarios de développement réels.
Plus intéressant encore, le benchmark Multi-SWE-Bench, qui porte sur des projets complexes multi-fichiers : MiniMax-M2.5 dépasse Opus 4.6 avec un score de 51,3 % contre 50,3 %. Cela signifie que pour les tâches d'ingénierie complexes nécessitant une coordination des modifications sur plusieurs fichiers, le M2.5 se montre plus stable.
Les données officielles de MiniMax indiquent qu'en interne, 80 % du nouveau code soumis est déjà généré par M2.5, et 30 % des tâches quotidiennes sont accomplies par ce modèle, validant ainsi ses capacités de codage par une application concrète.
L'écart entre MiniMax-M2.5 et Opus 4.6 sur les appels d'outils
La plus grande différence de capacité entre les deux modèles dans le domaine de la programmation réside dans l'appel d'outils (tool calling). Dans le benchmark BFCL Multi-Turn, MiniMax-M2.5 obtient un score de 76,8 %, tandis que Claude Opus 4.6 plafonne à 63,3 %, soit un écart massif de 13,5 points.
Cette différence a un impact énorme dans les scénarios de programmation d'agents : lorsque le modèle doit lire des fichiers, exécuter des commandes, appeler des API, analyser les sorties et itérer en boucle, la capacité d'appel d'outils détermine directement l'efficacité et la précision de l'exécution de la tâche. Le M2.5 réduit de 20 % le nombre de tours d'appels d'outils par rapport à la génération précédente M2.1 pour des tâches similaires, chaque appel étant plus précis.
Cependant, Claude Opus 4.6 conserve un avantage dans les scénarios ultra-complexes nécessitant la coordination simultanée d'un grand nombre d'outils, atteignant un niveau de 62,7 % dans le MCP Atlas (coordination d'outils à grande échelle), ce qui reste une référence dans l'industrie.
MiniMax-M2.5 vs Opus 4.6 : Vitesse et efficacité de codage
En programmation, la précision ne fait pas tout : la vitesse et l'efficacité sont tout aussi cruciales. C'est particulièrement vrai dans les scénarios de programmation par agents, où le modèle doit effectuer plusieurs itérations pour accomplir une tâche. La vitesse impacte directement l'expérience de développement et le coût total.
| Indicateur d'efficacité | MiniMax-M2.5 | Claude Opus 4.6 | Avantage |
|---|---|---|---|
| Vitesse de sortie (Standard) | ~50 TPS | ~33 TPS | M2.5 est 1,5x plus rapide |
| Vitesse de sortie (Lightning) | ~100 TPS | ~33 TPS | M2.5 est 3x plus rapide |
| Temps par tâche SWE-Bench | 22,8 minutes | 22,9 minutes | Quasiment identique |
| Coût par tâche SWE-Bench | ~$0,15 | ~$3,00 | M2.5 est 20x moins cher |
| Consommation moyenne de Tokens/tâche | 3,52M tokens | Plus élevé | M2.5 est plus économe |
| Optimisation des cycles d'appels d'outils | 20% de moins que M2.1 | — | M2.5 est plus efficace |
Analyse de l'avantage de vitesse de codage de MiniMax-M2.5
Dans l'évaluation SWE-Bench Verified, le temps moyen par tâche de MiniMax-M2.5 est de 22,8 minutes, ce qui est presque identique aux 22,9 minutes de Claude Opus 4.6. Cependant, la structure des coûts derrière ces chiffres est radicalement différente.
Réaliser une tâche SWE-Bench avec M2.5 coûte environ 0,15 $, contre environ 3,00 $ pour Opus 4.6. Cela signifie que pour une qualité de codage équivalente, le coût de M2.5 ne représente que 1/20ème de celui d'Opus. Pour les équipes qui font tourner des agents de codage en continu, cet écart se traduit par des économies de milliers, voire de dizaines de milliers de dollars par mois.
La haute efficacité de MiniMax-M2.5 provient de son architecture MoE (230 milliards de paramètres au total, mais seulement 10 milliards activés) et de l'optimisation de la décomposition des tâches apportée par le cadre d'entraînement Forge RL. Lors du codage, le modèle commence par une phase de "Spec-writing" (conception de l'architecture et décomposition des tâches) avant de passer à une exécution efficace, plutôt que de procéder par essais et erreurs à l'aveugle.
Les avantages uniques de Claude Opus 4.6 en programmation
Bien qu'il soit moins compétitif sur le plan du rapport coût-efficacité, Claude Opus 4.6 possède des atouts irremplaçables :
- Terminal-Bench 2.0 : 65,4 %, une performance de pointe pour les tâches de codage complexes en environnement terminal.
- OSWorld : 72,7 %, une capacité de manipulation informatique par agent qui dépasse de loin la concurrence.
- MCP Atlas : 62,7 %, leader du secteur pour la coordination d'outils à grande échelle.
- Fenêtre de contexte de 1M : La version Beta prend en charge un contexte de 1 million de tokens, ce qui permet de traiter d'énormes bases de code sans segmentation.
- Adaptive Thinking : Propose 4 niveaux d'intensité de réflexion (low/medium/high/max), permettant d'ajuster la profondeur du raisonnement selon les besoins.
Pour les tâches nécessitant un raisonnement profond, la compréhension d'un contexte de code ultra-long ou des opérations système extrêmement complexes, Opus 4.6 reste actuellement le choix le plus puissant.
🎯 Conseil de sélection : Ces deux modèles ont chacun leurs points forts. Nous vous recommandons de les tester concrètement via la plateforme APIYI (apiyi.com). La plateforme prend en charge simultanément MiniMax-M2.5 et Claude Opus 4.6 avec une interface unifiée ; il vous suffit de changer le paramètre
modelpour valider rapidement vos cas d'usage.
Recommandations de scénarios de programmation : MiniMax-M2.5 vs Opus 4.6
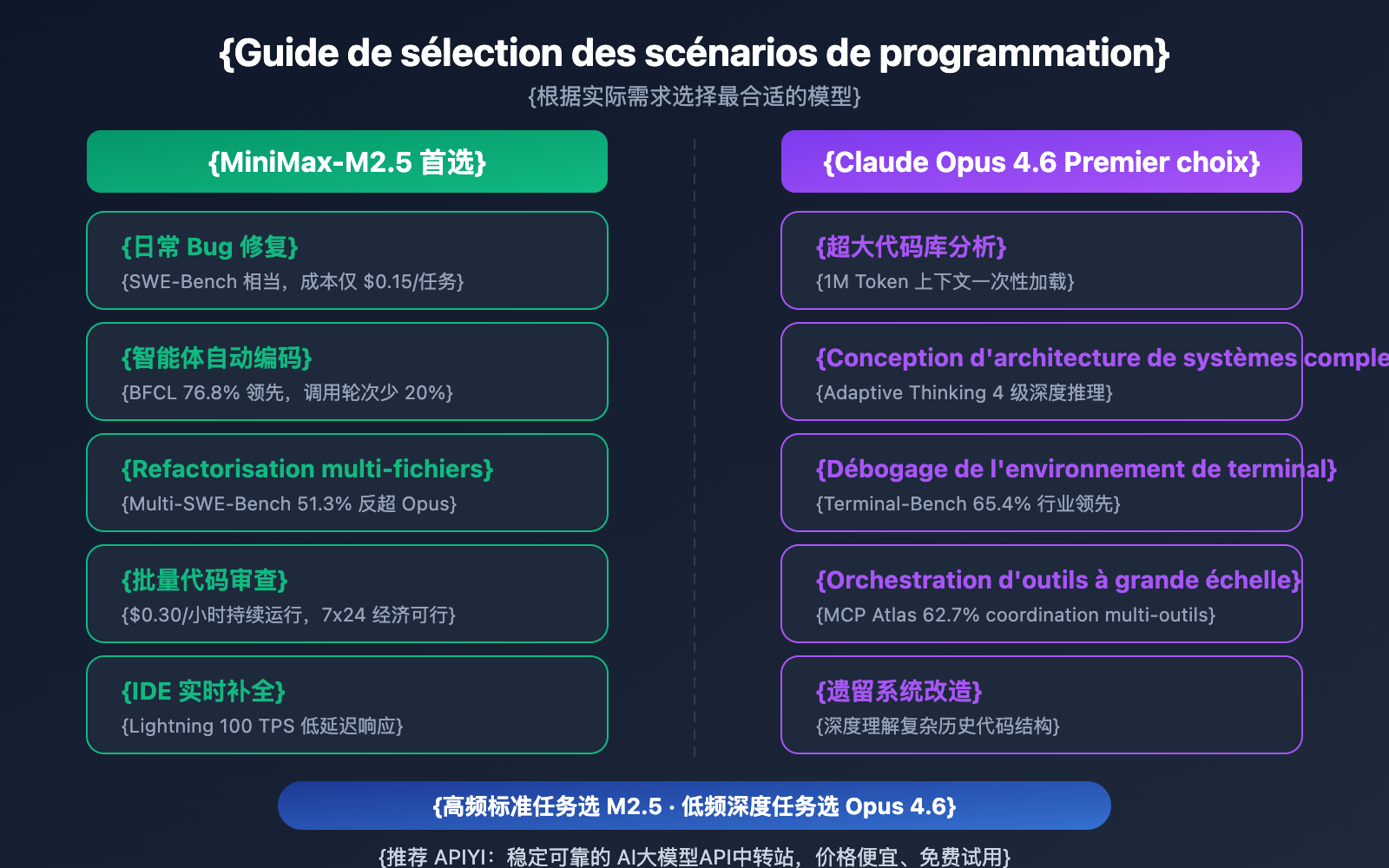
| Scénario de programmation | Modèle recommandé | Raison de la recommandation |
|---|---|---|
| Correction de bugs quotidiens | MiniMax-M2.5 | Performance SWE-Bench équivalente, coût 20x moindre |
| Refactorisation multi-fichiers | MiniMax-M2.5 | Leader sur Multi-SWE-Bench (+1%) |
| Codage automatique par agent | MiniMax-M2.5 | BFCL en tête (+13,5%), 0,15 $ par tâche |
| Revue de code par lots | MiniMax-M2.5 | Haut débit et bas coût, version Standard à 0,30 $/heure |
| Complétion de code IDE en temps réel | MiniMax-M2.5 Lightning | Faible latence avec 100 TPS |
| Analyse de bases de code géantes | Claude Opus 4.6 | Fenêtre de contexte de 1M de tokens |
| Conception d'architecture complexe | Claude Opus 4.6 | Raisonnement profond avec Adaptive Thinking |
| Opérations complexes en terminal | Claude Opus 4.6 | Leader sur Terminal-Bench (65,4%) |
| Orchestration d'outils à grande échelle | Claude Opus 4.6 | Leader sur MCP Atlas (62,7%) |
Meilleurs scénarios pour MiniMax-M2.5
L'avantage de MiniMax-M2.5 se concentre sur les tâches de programmation "à haute fréquence, standardisées et sensibles au coût" :
- Auto-réparation CI/CD : Pipelines de surveillance et de réparation par agents tournant en continu ; le coût de 0,30 $/heure rend une exploitation 24h/24 et 7j/7 économiquement viable.
- Bot de revue de PR : Examen automatique des Pull Requests ; le score BFCL de 76,8 % garantit la précision des interactions multi-outils.
- Développement Full-stack multilingue : Prise en charge de plus de 10 langages (Python, Go, Rust, TypeScript, Java, etc.), couvrant le Web, Android, iOS et Windows.
- Migration de code massive : Utilisation de la capacité de collaboration multi-fichiers (51,3 % sur Multi-SWE-Bench) pour gérer des refactorisations à grande échelle.
Meilleurs scénarios pour Claude Opus 4.6
L'avantage de Claude Opus 4.6 se concentre sur les tâches de programmation "à basse fréquence, haute complexité et raisonnement profond" :
- Aide à la décision d'architecture : Utilisation du mode Adaptive Thinking (max) pour des analyses approfondies de solutions techniques.
- Modernisation de systèmes hérités (Legacy) : Chargement d'une base de code entière grâce au contexte de 1M de tokens.
- Débogage au niveau système : Utilisation de Terminal-Bench (65,4 %) pour localiser et résoudre des problèmes complexes dans l'environnement terminal.
- Plateforme d'orchestration multi-outils : Coordination via MCP Atlas (62,7 %) entre l'IDE, Git, la CI/CD et les outils de monitoring.
Note comparative : Ces recommandations de scénarios sont basées sur des données de tests de référence (benchmarks) et les retours réels des développeurs. Les résultats effectifs peuvent varier selon les projets. Nous vous conseillons d'effectuer vos propres tests en situation réelle via APIYI (apiyi.com).
Comparaison complète des coûts de programmation : MiniMax-M2.5 vs Opus 4.6
Pour les équipes de développement, le coût à long terme des assistants de programmation IA est un facteur de décision crucial.
| Scénario de coût | MiniMax-M2.5 Standard | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Prix entrée / M tokens | 0,15 $ | 0,30 $ | 5,00 $ |
| Prix sortie / M tokens | 1,20 $ | 2,40 $ | 25,00 $ |
| Tâche SWE-Bench unique | ~0,15 $ | ~0,30 $ | ~3,00 $ |
| Fonctionnement continu (1h) | 0,30 $ | 1,00 $ | ~30 $ + |
| Fonctionnement 24/7 par mois | ~216 $ | ~720 $ | ~21 600 $ + |
| Nombre de tâches pour 100 $ | ~328 | ~164 | ~30 |
Prenons l'exemple d'une équipe de développement de taille moyenne : si vous devez traiter 50 tâches de codage par jour (corrections de bugs, revues de code, implémentations de fonctionnalités), le coût mensuel avec MiniMax-M2.5 Standard est d'environ 225 $, environ 450 $ pour la version Lightning, alors que Claude Opus 4.6 nécessiterait environ 4 500 $. La qualité d'exécution des tâches sur SWE-Bench est quasiment identique pour les trois modèles.
🎯 Conseil sur les coûts : Pour la plupart des tâches de programmation standard, l'avantage du rapport qualité-prix de MiniMax-M2.5 est évident. Nous vous suggérons de faire des tests réels via la plateforme APIYI (apiyi.com) avant de choisir. La plateforme permet de basculer de manière flexible entre les modèles sans modifier l'architecture de votre code. En participant aux campagnes de recharge, vous pouvez également bénéficier de tarifs encore plus avantageux.
Intégration rapide pour comparer MiniMax-M2.5 et Opus 4.6
Le code suivant montre comment basculer rapidement entre les deux modèles via une interface unifiée pour comparer les résultats :
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Test de MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "Implémenter un cache LRU thread-safe en Go"}]
)
# Test de Claude Opus 4.6 - il suffit de changer le paramètre model
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "Implémenter un cache LRU thread-safe en Go"}]
)
Voir le code de test comparatif complet
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
Teste les capacités de codage d'un modèle unique
Args:
model_name: ID du modèle
prompt: Invite de la tâche de codage
Returns:
Dictionnaire contenant le contenu de la réponse, les tokens et le temps écoulé
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Tu es un ingénieur logiciel senior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# Tâche de codage
task = "Réécris la fonction suivante pour qu'elle supporte la sécurité concurrentielle, le contrôle du délai d'expiration (timeout) et la dégradation gracieuse"
# Test comparatif
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens en {result['time']}s")
Conseil : Avec une seule clé API sur APIYI (apiyi.com), vous pouvez accéder simultanément à MiniMax-M2.5 et Claude Opus 4.6 pour comparer rapidement leurs performances dans vos scénarios de codage réels.
Questions Fréquemment Posées
Q1 : Est-ce que MiniMax-M2.5 peut remplacer complètement Claude Opus 4.6 pour la programmation ?
Pas totalement, mais dans la plupart des cas, oui. L'écart sur SWE-Bench n'est que de 0,6 %, et sur Multi-SWE-Bench, le M2.5 mène même de 1 %. Pour les tâches standard comme la correction de bugs, la revue de code ou l'implémentation de fonctionnalités, il n'y a quasiment aucune différence entre les deux. Cependant, pour l'analyse de bases de code massives (nécessitant un contexte de 1M) ou le débogage système complexe (Terminal-Bench), l'Opus 4.6 garde l'avantage. On recommande une utilisation hybride selon vos besoins réels.
Q2 : Pourquoi le score BFCL du M2.5 est-il bien plus élevé que celui de l’Opus 4.6, alors que leurs scores en codage sont proches ?
Le BFCL teste la capacité d'appel d'outils multi-tours (Function Calling), tandis que le SWE-Bench évalue la capacité de codage de bout en bout. Bien que l'Opus 4.6 soit moins précis que le M2.5 sur l'appel d'outils en un seul tour, sa puissante capacité de raisonnement profond compense ce manque d'efficacité, ce qui donne une qualité de codage globale très proche. Cela dit, dans des scénarios de programmation par agents autonomes, le score BFCL élevé du M2.5 se traduit par moins d'itérations et un coût total réduit.
Q3 : Comment comparer rapidement les performances de programmation des deux modèles ?
On vous recommande de passer par APIYI (apiyi.com) pour vos tests comparatifs :
- Créez un compte et récupérez votre clé API.
- Utilisez les exemples de code de cet article pour appeler les deux modèles sur une même tâche de codage.
- Comparez la qualité du code généré, la vitesse de réponse et la consommation de tokens.
- Grâce à l'interface compatible OpenAI, il suffit de changer le paramètre
modelpour basculer de l'un à l'autre.
Conclusion
Voici les points clés à retenir de la comparaison entre MiniMax-M2.5 et Claude Opus 4.6 pour la programmation :
- Qualité de codage quasi identique : 80,2 % contre 80,8 % sur SWE-Bench (écart de 0,6 %) ; le M2.5 repasse même devant de 1 % sur Multi-SWE-Bench.
- Appel d'outils : le M2.5 est largement en tête : 76,8 % contre 63,3 % au BFCL, ce qui en fait le premier choix pour les scénarios de programmation par agents.
- Écart de coût abyssal : 0,15 $ par tâche pour le M2.5 contre 3,00 $ pour l'Opus. À budget égal, vous pouvez accomplir plus de 10 fois plus de tâches.
- L'Opus 4.6 reste indispensable pour les tâches de fond : Contexte de 1M, Terminal-Bench, MCP Atlas… il garde l'avantage sur ces environnements spécifiques.
Pour la plupart des tâches de programmation quotidiennes, le MiniMax-M2.5 offre une qualité de codage proche de celle de l'Opus 4.6 avec un rapport qualité-prix bien supérieur. On vous suggère de vérifier cela par vous-même sur vos projets via APIYI (apiyi.com). La plateforme supporte une interface unique pour les deux modèles et propose des promotions sur les recharges.
📚 Références
⚠️ Note sur le format des liens : Tous les liens externes utilisent le format
Nom de la ressource : domain.com. Ce format facilite le copier-coller tout en évitant les liens cliquables pour préserver le référencement (SEO).
-
Annonce officielle de MiniMax M2.5 : Détails sur les capacités de base et les benchmarks de codage du M2.5.
- Lien :
minimax.io/news/minimax-m25 - Description : Contient les données complètes pour SWE-Bench, Multi-SWE-Bench, BFCL, etc.
- Lien :
-
Lancement officiel de Claude Opus 4.6 : Détails techniques d'Opus 4.6 publiés par Anthropic.
- Lien :
anthropic.com/news/claude-opus-4-6 - Description : Explications sur les capacités Terminal-Bench, MCP Atlas, Adaptive Thinking, etc.
- Lien :
-
Évaluation OpenHands de M2.5 : Test de codage en conditions réelles du M2.5 par une plateforme de développeurs indépendants.
- Lien :
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Description : Analyse du premier modèle open-weights à surpasser Claude Sonnet en conditions réelles.
- Lien :
-
Comparaison approfondie de VentureBeat : Analyse du rapport qualité-prix entre M2.5 et Opus 4.6.
- Lien :
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Description : Analyse des différences de rentabilité du point de vue de l'entreprise.
- Lien :
-
Analyse des benchmarks Vellum pour Opus 4.6 : Interprétation complète des tests de performance de Claude Opus 4.6.
- Lien :
vellum.ai/blog/claude-opus-4-6-benchmarks - Description : Analyse détaillée des principaux benchmarks de codage comme Terminal-Bench et SWE-Bench.
- Lien :
Auteur : Équipe APIYI
Échanges techniques : N'hésitez pas à partager vos résultats de tests comparatifs dans les commentaires. Pour plus de tutoriels sur l'intégration de modèles de programmation IA, visitez la communauté technique APIYI sur apiyi.com.