Anmerkung des Autors: Ein tiefgehender Vergleich der Programmierfähigkeiten von MiniMax-M2.5 und Claude Opus 4.6 anhand von 5 Dimensionen: SWE-Bench, Multi-SWE-Bench, BFCL Tool-Aufrufe, Codierungsgeschwindigkeit und Preis.
Die Wahl des richtigen KI-Programmierassistenten ist für Entwickler eine zentrale Frage. In diesem Artikel vergleichen wir die Programmierfähigkeiten von MiniMax-M2.5 und Claude Opus 4.6 in 5 entscheidenden Dimensionen, um Ihnen dabei zu helfen, die optimale Wahl zwischen Leistung und Kosten zu treffen.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die Leistungsgrenzen dieser beiden Modelle in realen Codierungsszenarien genau kennen und wissen, in welcher Situation welche Wahl am wirtschaftlichsten ist.

Kernunterschiede in der Programmierleistung: MiniMax-M2.5 vs. Claude Opus 4.6
| Vergleichsdimension | MiniMax-M2.5 | Claude Opus 4.6 | Differenzanalyse |
|---|---|---|---|
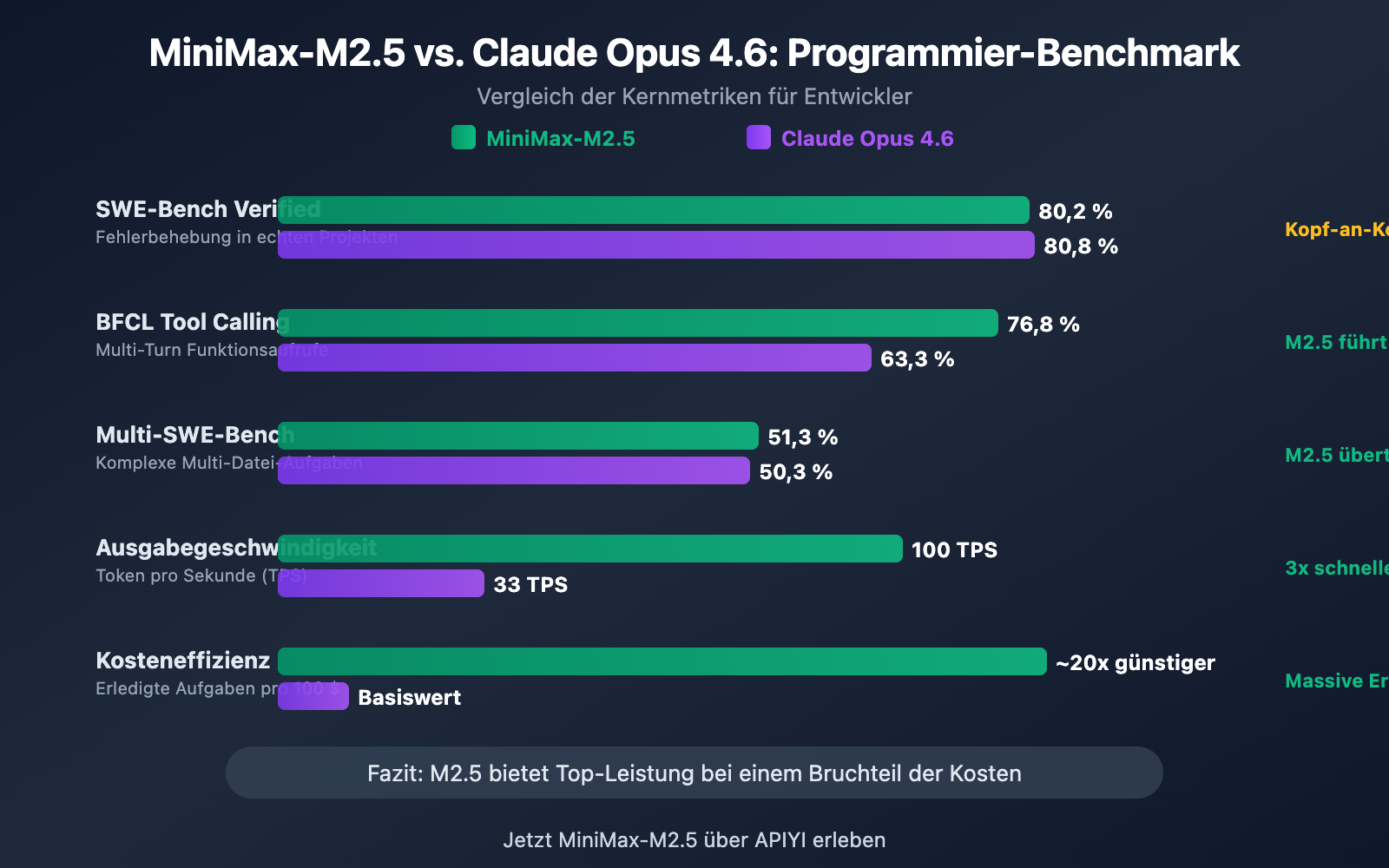
| SWE-Bench Verified | 80,2 % | 80,8 % | Opus führt nur um 0,6 % |
| Multi-SWE-Bench | 51,3 % | 50,3 % | M2.5 zieht um 1,0 % vorbei |
| BFCL Tool Calling | 76,8 % | 63,3 % | M2.5 führt mit 13,5 % |
| Ausgabegeschwindigkeit | 50-100 TPS | ~33 TPS | M2.5 bis zu 3-mal schneller |
| Ausgabepreis | 1,20 $/M Tokens | 25 $/M Tokens | M2.5 ca. 20-mal günstiger |
Interpretation der Coding-Benchmarks: MiniMax-M2.5 vs. Opus 4.6
Betrachtet man den SWE-Bench Verified, den in der Branche am meisten anerkannten Coding-Benchmark, ist der Unterschied minimal: Die 80,2 % von MiniMax-M2.5 liegen nur 0,6 Prozentpunkte hinter den 80,8 % von Claude Opus 4.6. Der SWE-Bench Verified testet die Fähigkeit eines Modells, Bugs zu beheben und Funktionen in echten GitHub Pull Requests zu implementieren – dies ist die Bewertung, die realen Entwicklungsszenarien am nächsten kommt.
Noch bemerkenswerter ist der Multi-SWE-Bench, ein Benchmark für komplexe Projekte mit mehreren Dateien: Hier übertrifft MiniMax-M2.5 mit 51,3 % den Wert von Opus 4.6 (50,3 %). Dies bedeutet, dass M2.5 bei komplexen Engineering-Aufgaben, die koordinierte Änderungen über mehrere Dateien hinweg erfordern, stabiler performt.
Offizielle Daten von MiniMax zeigen, dass intern bereits 80 % des neuen Codes von M2.5 generiert und 30 % der täglichen Aufgaben von M2.5 erledigt werden, was die Programmierfähigkeiten auf praktischer Ebene bestätigt.
Die Lücke beim Tool Calling zwischen MiniMax-M2.5 und Opus 4.6
Die größte Diskrepanz zwischen den beiden Modellen im Bereich Programmierung zeigt sich beim Tool Calling (Funktionsaufrufe). Im BFCL Multi-Turn Benchmark erreicht MiniMax-M2.5 einen Score von 76,8 %, während Claude Opus 4.6 bei 63,3 % liegt – ein massiver Unterschied von 13,5 Prozentpunkten.
Diese Differenz hat enorme Auswirkungen auf Agenten-Programmierszenarien: Wenn ein Modell Dateien lesen, Befehle ausführen, APIs aufrufen, Ausgaben parsen und iterieren muss, entscheidet die Tool-Calling-Fähigkeit direkt über die Effizienz und Genauigkeit der Aufgabenerfüllung. M2.5 benötigt für vergleichbare Aufgaben 20 % weniger Tool-Calling-Iterationen als der Vorgänger M2.1, wobei jeder Aufruf präziser erfolgt.
Dennoch erreicht Claude Opus 4.6 im MCP Atlas (großflächige Tool-Koordination) mit 62,7 % ein branchenführendes Niveau und behält in extrem komplexen Szenarien, die die gleichzeitige Koordination einer Vielzahl von Werkzeugen erfordern, weiterhin Vorteile.
MiniMax-M2.5 vs. Opus 4.6: Codiergeschwindigkeit und Effizienz im Vergleich
Beim Programmieren zählt nicht nur die Genauigkeit, auch Geschwindigkeit und Effizienz sind entscheidend. Besonders in Szenarien mit KI-Agenten, in denen das Modell Aufgaben in mehreren Iterationen erledigt, beeinflusst die Geschwindigkeit direkt das Entwicklererlebnis und die Gesamtkosten.
| Effizienzkennzahlen | MiniMax-M2.5 | Claude Opus 4.6 | Vorteil |
|---|---|---|---|
| Ausgabegeschwindigkeit (Standard) | ~50 TPS | ~33 TPS | M2.5 ist 1,5x schneller |
| Ausgabegeschwindigkeit (Lightning) | ~100 TPS | ~33 TPS | M2.5 ist 3x schneller |
| SWE-Bench Zeit pro Aufgabe | 22,8 Min. | 22,9 Min. | Nahezu gleichauf |
| SWE-Bench Kosten pro Aufgabe | ~$0,15 | ~$3.00 | M2.5 ist 20x günstiger |
| Durchschnittlicher Token-Verbrauch | 3,52M Tokens | Höher | M2.5 spart mehr Tokens |
| Optimierung der Tool-Aufrufe | 20% weniger als M2.1 | — | M2.5 ist effizienter |
Analyse der Codiergeschwindigkeit von MiniMax-M2.5
MiniMax-M2.5 benötigt in der SWE-Bench Verified-Evaluierung durchschnittlich 22,8 Minuten pro Aufgabe, was fast identisch mit den 22,9 Minuten von Claude Opus 4.6 ist. Die dahinterstehende Kostenstruktur ist jedoch völlig unterschiedlich.
Die Kosten für die Erledigung einer SWE-Bench-Aufgabe liegen bei M2.5 bei etwa 0,15 $, während sie bei Opus 4.6 etwa 3,00 $ betragen – das bedeutet, dass M2.5 bei gleicher Codierqualität nur 1/20 der Kosten von Opus verursacht. Für Teams, die kontinuierlich Codier-Agenten einsetzen, summiert sich dieser Unterschied auf monatliche Einsparungen von Tausenden oder sogar Zehntausenden Dollar.
Die hohe Effizienz von MiniMax-M2.5 resultiert aus der MoE-Architektur (von 230 Mrd. Gesamtparametern werden nur 10 Mrd. aktiviert) und der durch das Forge RL-Framework optimierten Aufgabenzerlegung. Beim Codieren führt das Modell zunächst ein "Spec-writing" durch – Architekturdesign und Aufgabenzerlegung –, um anschließend effizient in die Ausführung zu gehen, anstatt blindlings nach dem Prinzip "Trial-and-Error" vorzugehen.
Die einzigartigen Vorteile von Claude Opus 4.6 beim Programmieren
Obwohl Claude Opus 4.6 in Bezug auf die Kosteneffizienz nicht im Vorteil ist, bietet es unersetzliche Stärken:
- Terminal-Bench 2.0: 65,4 %, branchenführend bei komplexen Codieraufgaben in Terminal-Umgebungen.
- OSWorld: 72,7 %, die Fähigkeit zur Computerbedienung durch Agenten übertrifft die Konkurrenz bei weitem.
- MCP Atlas: 62,7 %, die Nummer eins in der Branche bei der Koordination großflächiger Tools.
- 1M Kontextfenster: Die Beta-Version unterstützt einen Kontext von 1 Million Tokens, was das Verarbeiten riesiger Codebasen ohne Segmentierung ermöglicht.
- Adaptive Thinking: Unterstützt 4 Stufen der Denkintensität (low/medium/high/max), wodurch die Tiefe der Schlussfolgerungen je nach Bedarf angepasst werden kann.
Bei Aufgaben, die tiefgreifendes logisches Denken, extrem lange Code-Kontexte oder hochkomplexe Systemaufgaben erfordern, bleibt Opus 4.6 die derzeit stärkste Wahl.
🎯 Empfehlung: Beide Modelle haben ihre Stärken. Wir empfehlen einen praktischen Vergleichstest über die Plattform APIYI (apiyi.com). Die Plattform unterstützt sowohl MiniMax-M2.5 als auch Claude Opus 4.6 über eine einheitliche Schnittstelle – Sie müssen lediglich den Parameter
modeländern, um die Ergebnisse schnell zu validieren.
MiniMax-M2.5 vs. Opus 4.6: Empfohlene Programmierszenarien

| Programmierszenario | Empfohlenes Modell | Grund der Empfehlung |
|---|---|---|
| Tägliche Bugfixes | MiniMax-M2.5 | SWE-Bench vergleichbar, 20x günstigere Kosten |
| Multi-Datei-Refactoring | MiniMax-M2.5 | Multi-SWE-Bench Führung mit 1% Vorsprung |
| KI-Agenten-Codierung | MiniMax-M2.5 | BFCL Führung mit 13,5%, $0.15 pro Aufgabe |
| Batch-Code-Reviews | MiniMax-M2.5 | Hoher Durchsatz, niedrige Kosten ($0.30/Std. Standard) |
| IDE-Echtzeit-Vervollständigung | MiniMax-M2.5 Lightning | 100 TPS für extrem niedrige Latenz |
| Analyse riesiger Codebasen | Claude Opus 4.6 | 1M Token Kontextfenster |
| Komplexe Systemarchitektur | Claude Opus 4.6 | Adaptive Thinking für tiefgreifende Logik |
| Komplexe Terminal-Operationen | Claude Opus 4.6 | Terminal-Bench 65,4% (branchenführend) |
| Großflächige Tool-Orchestrierung | Claude Opus 4.6 | MCP Atlas 62,7% (branchenführend) |
Die besten Programmierszenarien für MiniMax-M2.5
Die Stärken von MiniMax-M2.5 liegen bei "hochfrequenten, standardisierten und kostensensiblen" Programmieraufgaben:
- CI/CD Auto-Fix: Kontinuierlich laufende Agenten-Pipelines zur Überwachung und Behebung von Fehlern; Kosten von $0.30/Stunde machen einen 24/7-Betrieb wirtschaftlich rentabel.
- PR Review Bot: Automatische Überprüfung von Pull Requests; BFCL von 76,8 % gewährleistet präzise Tool-Interaktionen über mehrere Runden.
- Mehrsprachige Full-Stack-Entwicklung: Unterstützung für über 10 Programmiersprachen (Python, Go, Rust, TypeScript, Java etc.), deckt Web/Android/iOS/Windows ab.
- Batch-Code-Migration: Nutzung der Multi-file-Kollaborationsfähigkeit (51,3 % im Multi-SWE-Bench) für großflächige Refactorings.
Die besten Programmierszenarien für Claude Opus 4.6
Die Stärken von Claude Opus 4.6 liegen bei "weniger häufigen, hochkomplexen Aufgaben mit tiefem logischem Anspruch":
- Unterstützung bei Architektur-Entscheidungen: Nutzung von Adaptive Thinking (Max-Modus) für tiefgehende Analysen technischer Konzepte.
- Modernisierung von Legacy-Systemen: Das 1M Token Kontextfenster ermöglicht das Laden einer kompletten, riesigen Codebasis in einem Rutsch.
- System-Level Debugging: Terminal-Bench 65,4 % zur Lokalisierung und Lösung komplexer Systemprobleme direkt in der Terminal-Umgebung.
- Plattformen zur Tool-Orchestrierung: MCP Atlas 62,7 % zur Koordination von IDE, Git, CI/CD, Monitoring und weiteren Tools.
Hinweis zum Vergleich: Die obigen Szenario-Empfehlungen basieren auf Benchmark-Daten und praktischem Feedback von Entwicklern. Die tatsächlichen Ergebnisse können je nach Projekt variieren. Wir empfehlen eine Validierung in Ihrem spezifischen Szenario über APIYI (apiyi.com).
MiniMax-M2.5 vs. Opus 4.6: Umfassender Vergleich der Programmierungskosten
Für Entwicklungsteams sind die langfristigen Kosten von KI-Programmierassistenten ein entscheidender Faktor bei der Entscheidungsfindung.
| Kostenszenario | MiniMax-M2.5 Standard | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Eingabepreis / Mio. Token | 0,15 $ | 0,30 $ | 5,00 $ |
| Ausgabepreis / Mio. Token | 1,20 $ | 2,40 $ | 25,00 $ |
| Einzelne SWE-Bench-Aufgabe | ~0,15 $ | ~0,30 $ | ~3,00 $ |
| Kontinuierlicher Betrieb (1 Std.) | 0,30 $ | 1,00 $ | ~30 $ + |
| Monatlicher Betrieb (24/7) | ~216 $ | ~720 $ | ~21.600 $ + |
| Aufgaben pro 100 $ Budget | ~328 | ~164 | ~30 |
Nehmen wir ein mittelgroßes Entwicklungsteam als Beispiel: Wenn täglich 50 Programmieraufgaben (Bugfixes, Code-Reviews, Feature-Implementierungen) anfallen, belaufen sich die monatlichen Kosten für die MiniMax-M2.5 Standard-Version auf etwa 225 $ und für die Lightning-Version auf etwa 450 $, während Claude Opus 4.6 rund 4.500 $ kosten würde. Die Qualität der Aufgabenerledigung ist auf SWE-Bench-Niveau bei allen drei Modellen nahezu identisch.
🎯 Kostentipp: Für die meisten Standard-Programmieraufgaben bietet MiniMax-M2.5 einen deutlichen Preis-Leistungs-Vorteil. Wir empfehlen einen Praxistest über die Plattform APIYI (apiyi.com). Die Plattform unterstützt den flexiblen Wechsel zwischen Modellen, ohne dass die Code-Architektur geändert werden muss. Durch die Teilnahme an Auflade-Aktionen können Sie zudem von noch attraktiveren Preisen profitieren.
MiniMax-M2.5 vs. Opus 4.6: Schnelle Integration für die Programmierung
Der folgende Code zeigt, wie Sie über eine einheitliche Schnittstelle schnell zwischen den beiden Modellen wechseln können, um sie zu vergleichen:
from openai import OpenAI
client = OpenAI(
api_key="IHR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Test MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "Implementiere einen thread-sicheren LRU-Cache in Go"}]
)
# Test Claude Opus 4.6 - einfach den model-Parameter ändern
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "Implementiere einen thread-sicheren LRU-Cache in Go"}]
)
Vollständigen Vergleichs-Testcode anzeigen
from openai import OpenAI
import time
client = OpenAI(
api_key="IHR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
Testet die Programmierfähigkeiten eines einzelnen Modells.
Args:
model_name: Modell-ID
prompt: Eingabeaufforderung für die Programmieraufgabe
Returns:
Dictionary mit Antwortinhalt und Zeitaufwand
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Du bist ein erfahrener Softwareentwickler."},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# Programmieraufgabe
task = "Refaktoriere die folgende Funktion, um Thread-Sicherheit, Timeout-Steuerung und Graceful Degradation zu unterstützen."
# Vergleichstest
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} Tokens in {result['time']}s")
Empfehlung: Über APIYI (apiyi.com) können Sie mit nur einem API-Key gleichzeitig auf MiniMax-M2.5 und Claude Opus 4.6 zugreifen. So lässt sich schnell vergleichen, wie sich beide Modelle in Ihren realen Programmierszenarien schlagen.
Häufig gestellte Fragen
Q1: Kann MiniMax-M2.5 Claude Opus 4.6 beim Programmieren vollständig ersetzen?
Nicht vollständig, aber in den meisten Szenarien schon. Der Unterschied im SWE-Bench beträgt lediglich 0,6 %, und im Multi-SWE-Bench liegt M2.5 sogar um 1 % vorn. Bei Standardaufgaben wie Bugfixes, Code-Reviews und der Implementierung von Funktionen gibt es fast keinen Unterschied zwischen den beiden. In Szenarien wie der Analyse extrem großer Codebasen (erfordert 1M Kontext) oder komplexem Debugging auf Systemebene (Terminal-Bench) behält Opus 4.6 jedoch weiterhin Vorteile. Wir empfehlen einen hybriden Einsatz je nach spezifischem Anwendungsfall.
Q2: Warum ist der BFCL-Wert von M2.5 viel höher als der von Opus 4.6, obwohl die Coding-Scores so nah beieinander liegen?
Der BFCL testet die Fähigkeit zu mehrstufigen Funktionsaufrufen (Function Calling), während der SWE-Bench die End-to-End-Programmierfähigkeit bewertet. Obwohl Opus 4.6 bei einzelnen Funktionsaufrufen vielleicht weniger präzise ist als M2.5, gleicht es diese Effizienzdefizite durch seine enormen Deep-Reasoning-Fähigkeiten aus, was letztlich zu einer ähnlichen Gesamtqualität beim Coding führt. In Szenarien für KI-Agenten (Agentic Programming) bedeutet der hohe BFCL-Score von M2.5 jedoch weniger Aufrufzyklen und damit deutlich geringere Gesamtkosten.
Q3: Wie lassen sich die Programmierergebnisse der beiden Modelle schnell vergleichen?
Wir empfehlen einen Vergleichstest über APIYI (apiyi.com):
- Registrieren Sie ein Konto und rufen Sie Ihren API-Key ab.
- Nutzen Sie die Code-Beispiele aus diesem Artikel, um beide Modelle für dieselbe Programmieraufgabe aufzurufen.
- Vergleichen Sie die Qualität des generierten Codes, die Antwortgeschwindigkeit und den Token-Verbrauch.
- Dank der einheitlichen OpenAI-kompatiblen Schnittstelle müssen Sie für den Modellwechsel lediglich den
model-Parameter anpassen.
Fazit
Hier sind die Kernpunkte zum Vergleich der Programmierfähigkeiten von MiniMax-M2.5 und Claude Opus 4.6:
- Programmierqualität fast gleichauf: SWE-Bench 80,2 % vs. 80,8 % (nur 0,6 % Differenz); im Multi-SWE-Bench liegt M2.5 sogar mit 1 % vorn.
- Werkzeugaufrufe (Tool Calling) bei M2.5 deutlich überlegen: BFCL 76,8 % vs. 63,3 % – damit ist M2.5 die erste Wahl für Agentic-Programming-Szenarien.
- Massiver Kostenunterschied: M2.5 kostet pro Aufgabe ca. 0,15 $, während Opus mit 3,00 $ zu Buche schlägt. Mit demselben Budget lassen sich also mehr als 10-mal so viele Aufgaben erledigen.
- Opus 4.6 bleibt bei komplexen Aufgaben unersetzlich: In Szenarien mit 1M Kontextfenster, Terminal-Bench oder MCP Atlas hat es weiterhin die Nase vorn.
Für die meisten alltäglichen Programmieraufgaben bietet MiniMax-M2.5 eine Coding-Qualität, die fast das Niveau von Opus 4.6 erreicht, jedoch zu einem weitaus besseren Preis-Leistungs-Verhältnis. Wir empfehlen, dies in realen Projekten über APIYI (apiyi.com) zu validieren. Die Plattform unterstützt eine einheitliche Schnittstelle für beide Modelle und bietet zudem attraktive Bonusaktionen bei der Kontoaufladung.
📚 Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name der Quelle: domain.com. Dies erleichtert das Kopieren, verhindert jedoch anklickbare Links, um den Verlust von SEO-Gewichtung zu vermeiden.
-
Offizielle Ankündigung von MiniMax M2.5: Details zu den Kernfunktionen von M2.5 und Coding-Benchmarks
- Link:
minimax.io/news/minimax-m25 - Beschreibung: Enthält vollständige Daten zu SWE-Bench, Multi-SWE-Bench, BFCL usw.
- Link:
-
Offizielle Veröffentlichung von Claude Opus 4.6: Technische Details zu Opus 4.6 von Anthropic
- Link:
anthropic.com/news/claude-opus-4-6 - Beschreibung: Erläuterungen zu Funktionen wie Terminal-Bench, MCP Atlas, Adaptive Thinking usw.
- Link:
-
OpenHands M2.5 Review: Praxistest der Codierungsfähigkeiten von M2.5 durch eine unabhängige Entwicklerplattform
- Link:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Beschreibung: Praxisanalyse des ersten Open-Source-Modells, das Claude Sonnet übertrifft.
- Link:
-
VentureBeat Tiefenvergleich: Analyse des Preis-Leistungs-Verhältnisses von M2.5 und Opus 4.6
- Link:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Beschreibung: Analyse der Kosten-Nutzen-Unterschiede aus Unternehmensperspektive.
- Link:
-
Vellum Opus 4.6 Benchmark-Analyse: Umfassende Interpretation der Benchmarks von Claude Opus 4.6
- Link:
vellum.ai/blog/claude-opus-4-6-benchmarks - Beschreibung: Detaillierte Analyse zentraler Coding-Benchmarks wie Terminal-Bench, SWE-Bench usw.
- Link:
Autor: APIYI Team
Technischer Austausch: Teilen Sie gerne Ihre Testergebnisse zum Modellvergleich im Kommentarbereich. Weitere Tutorials zur Integration von KI-Programmiermodellen finden Sie in der APIYI-Tech-Community unter apiyi.com.





