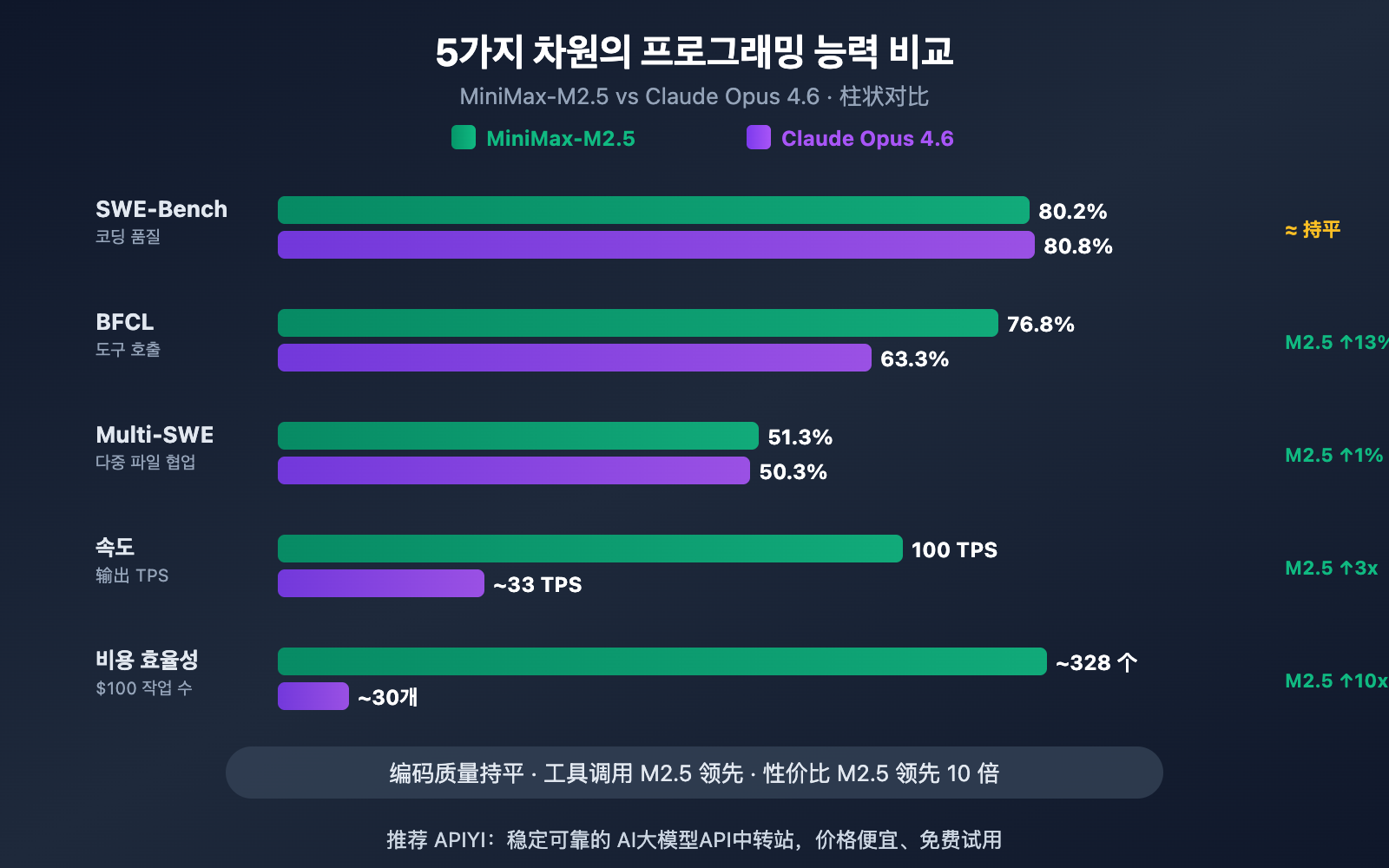
저자의 주: SWE-Bench, Multi-SWE-Bench, BFCL 도구 호출, 코딩 속도, 그리고 가격까지 5가지 차원에서 MiniMax-M2.5와 Claude Opus 4.6의 프로그래밍 능력 차이를 심층 비교합니다.
AI 코딩 어시스턴트를 선택하는 것은 개발자들에게 항상 중요한 고민거리죠. 이번 포스팅에서는 MiniMax-M2.5와 Claude Opus 4.6의 코딩 능력을 5가지 핵심 지표로 비교하여, 성능과 비용 사이에서 여러분이 최선의 선택을 내릴 수 있도록 도와드리겠습니다.
핵심 포인트: 이 글을 읽고 나면 두 모델이 실제 코딩 환경에서 어떤 강점과 한계를 가졌는지, 그리고 어떤 상황에서 어떤 모델을 선택하는 것이 더 경제적인지 명확하게 알게 되실 거예요.

MiniMax-M2.5 vs Claude Opus 4.6 프로그래밍 능력 핵심 차이
| 비교 항목 | MiniMax-M2.5 | Claude Opus 4.6 | 차이 분석 |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus가 단 0.6% 우세 |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5가 1.0% 역전 |
| BFCL 도구 호출 | 76.8% | 63.3% | M2.5가 13.5% 앞섬 |
| 출력 속도 | 50-100 TPS | ~33 TPS | M2.5가 최대 3배 빠름 |
| 출력 가격 | $1.20/M 토큰 | $25/M 토큰 | M2.5가 약 20배 저렴 |
MiniMax-M2.5 vs Opus 4.6 코딩 벤치마크 해석
업계에서 가장 신뢰받는 코딩 벤치마크인 SWE-Bench Verified를 살펴보면, 두 모델의 격차는 매우 미미합니다. MiniMax-M2.5는 80.2%를 기록하며 Claude Opus 4.6의 80.8%를 0.6%포인트 차이로 바짝 추격하고 있습니다. SWE-Bench Verified는 실제 GitHub Pull Request에서 버그를 수정하고 기능을 구현하는 능력을 테스트하므로, 실제 개발 환경에 가장 가까운 평가 지표라고 할 수 있습니다.
더 주목할 만한 점은 다중 파일 기반의 복잡한 프로젝트 벤치마크인 Multi-SWE-Bench입니다. 여기서 MiniMax-M2.5는 51.3%의 점수를 기록하며 Opus 4.6(50.3%)을 역전했습니다. 이는 여러 파일에 걸쳐 수정을 조율해야 하는 복잡한 엔지니어링 작업에서 M2.5가 더 안정적인 성능을 보여준다는 것을 의미합니다.
MiniMax 공식 데이터에 따르면, 이미 사내 신규 커밋 코드의 80%가 M2.5에 의해 생성되고 있으며, 일상적인 업무의 30%를 M2.5가 처리하고 있다고 합니다. 이는 실제 응용 측면에서도 그 코딩 능력이 검증되었음을 보여줍니다.
MiniMax-M2.5와 Opus 4.6의 도구 호출 능력 차이
두 모델의 프로그래밍 분야에서 가장 큰 차이가 나타나는 지점은 바로 도구 호출(Tool Calling)입니다. BFCL Multi-Turn 벤치마크 테스트에서 MiniMax-M2.5는 76.8%를 기록한 반면, Claude Opus 4.6은 63.3%에 그쳐 13.5%포인트라는 큰 격차를 보였습니다.
이러한 차이는 AI 에이전트 프로그래밍 시나리오에서 엄청난 영향을 미칩니다. 모델이 파일을 읽고, 명령을 실행하고, API를 호출하고, 출력을 분석하여 반복적으로 작업을 수행해야 할 때, 도구 호출 능력은 작업 완료의 효율성과 정확도를 직접적으로 결정하기 때문입니다. M2.5는 유사한 작업을 완료하는 데 필요한 도구 호출 횟수를 이전 세대인 M2.1보다 20% 줄였으며, 매 호출마다 더 정밀한 결과를 내놓습니다.
다만, Claude Opus 4.6은 대규모 도구 조율 능력을 평가하는 MCP Atlas에서 62.7%라는 업계 최고 수준을 기록하고 있어, 수많은 도구를 동시에 조율해야 하는 초복합 시나리오에서는 여전히 강점을 가지고 있습니다.
MiniMax-M2.5 vs Opus 4.6 코딩 속도 및 효율성 비교
프로그래밍은 정확도뿐만 아니라 속도와 효율성도 매우 중요합니다. 특히 에이전트 프로그래밍 시나리오에서는 모델이 여러 차례 반복하며 작업을 완료해야 하므로, 속도가 개발 경험과 총 비용에 직접적인 영향을 미칩니다.
| 효율성 지표 | MiniMax-M2.5 | Claude Opus 4.6 | 우세 모델 |
|---|---|---|---|
| 출력 속도 (표준 버전) | ~50 TPS | ~33 TPS | M2.5가 1.5배 빠름 |
| 출력 속도 (Lightning) | ~100 TPS | ~33 TPS | M2.5가 3배 빠름 |
| SWE-Bench 단일 작업 소요 시간 | 22.8분 | 22.9분 | 거의 대등 |
| SWE-Bench 단일 작업 비용 | 약 $0.15 | 약 $3.00 | M2.5가 20배 저렴 |
| 작업당 평균 토큰 소모량 | 3.52M 토큰 | 더 높음 | M2.5가 토큰 절약에 유리 |
| 도구 호출 라운드 최적화 | M2.1 대비 20% 감소 | — | M2.5가 더 효율적 |
MiniMax-M2.5 코딩 속도 우위 분석
MiniMax-M2.5는 SWE-Bench Verified 평가에서 단일 작업 평균 소요 시간 22.8분을 기록하며, Claude Opus 4.6의 22.9분과 거의 동일한 성능을 보여주었습니다. 하지만 그 이면의 비용 구조는 완전히 다릅니다.
M2.5로 SWE-Bench 작업을 하나 완료하는 데 드는 비용은 약 $0.15인 반면, Opus 4.6은 약 $3.00가 소요됩니다. 즉, 동일한 코딩 품질을 얻는 데 M2.5의 비용이 Opus의 20분의 1 수준이라는 뜻입니다. 코딩 에이전트를 지속적으로 운영해야 하는 팀에게 이 차이는 매달 수천, 수만 달러의 비용 절감으로 이어질 수 있습니다.
MiniMax-M2.5의 높은 효율성은 MoE 아키텍처(총 230B 파라미터 중 10B만 활성화)와 Forge RL 훈련 프레임워크를 통한 작업 분해 최적화에서 비롯됩니다. 모델은 코딩 시 무작정 시도하는 것이 아니라, 먼저 아키텍처 설계와 작업 분해를 수행하는 'Spec-writing' 단계를 거친 후 효율적으로 실행합니다.
Claude Opus 4.6 코딩 능력의 독보적인 장점
비용 효율성 면에서는 다소 밀릴 수 있지만, Claude Opus 4.6은 대체 불가능한 강점을 가지고 있습니다.
- Terminal-Bench 2.0: 65.4%를 기록하며 터미널 환경에서의 복잡한 코딩 작업 성능이 업계 최고 수준입니다.
- OSWorld: 72.7%로, 에이전트의 컴퓨터 조작 능력이 경쟁 모델을 압도합니다.
- MCP Atlas: 62.7%를 기록하며 대규모 도구 협업 능력 분야에서 1위를 차지했습니다.
- 1M 컨텍스트 윈도우: 베타 버전에서 100만 토큰 컨텍스트를 지원하여, 초대형 코드베이스를 처리할 때 분할할 필요가 없습니다.
- Adaptive Thinking: 4단계 사고 강도(low/medium/high/max)를 지원하여 필요에 따라 추론 깊이를 조절할 수 있습니다.
심층적인 추론, 초장문 코드 컨텍스트 이해 또는 극도로 복잡한 시스템 레벨의 작업이 필요한 경우, Opus 4.6은 여전히 현존하는 가장 강력한 선택지입니다.
🎯 선택 가이드: 두 모델은 각기 다른 장점을 가지고 있습니다. APIYI apiyi.com 플랫폼에서 직접 테스트하고 비교해 보시는 것을 추천해요. 이 플랫폼은 MiniMax-M2.5와 Claude Opus 4.6을 모두 지원하며, 통일된 인터페이스를 제공하므로 model 파라미터만 변경하여 빠르게 검증할 수 있습니다.
MiniMax-M2.5 및 Opus 4.6 프로그래밍 시나리오별 추천
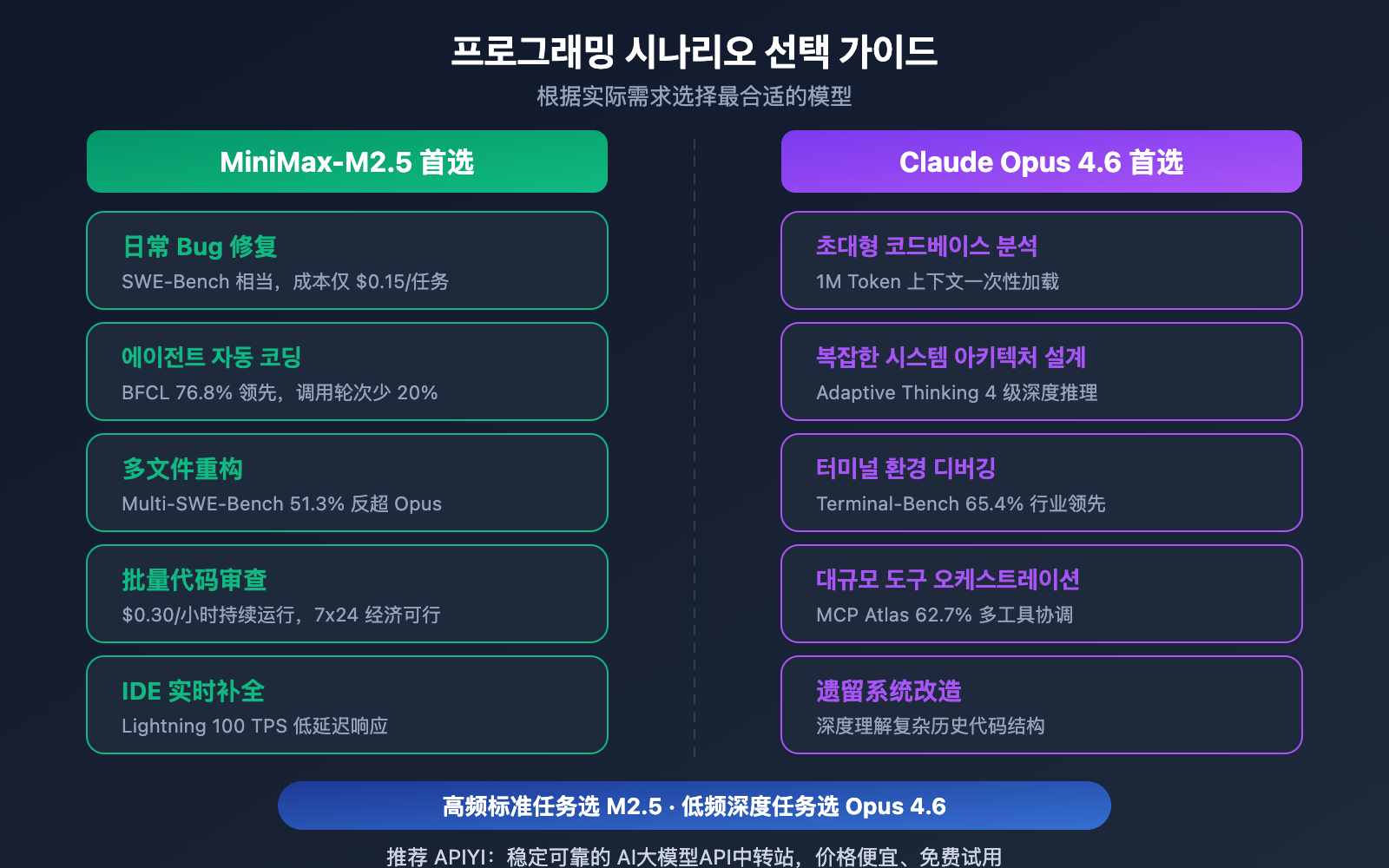
| 프로그래밍 시나리오 | 추천 모델 | 추천 이유 |
|---|---|---|
| 일상적인 버그 수정 | MiniMax-M2.5 | SWE-Bench 성능은 비슷하면서 비용은 20배 저렴 |
| 다중 파일 리팩토링 | MiniMax-M2.5 | Multi-SWE-Bench에서 1% 앞선 성능 |
| 에이전트 자동 코딩 | MiniMax-M2.5 | BFCL 13.5% 우위, 작업당 비용 $0.15 |
| 대량의 코드 리뷰 | MiniMax-M2.5 | 높은 처리량과 낮은 비용, 표준 버전 $0.30/시간 |
| IDE 실시간 코드 완성 | MiniMax-M2.5 Lightning | 100 TPS의 초저지연 응답 |
| 초대형 코드베이스 분석 | Claude Opus 4.6 | 1M 토큰 컨텍스트 윈도우 지원 |
| 복잡한 시스템 아키텍처 설계 | Claude Opus 4.6 | Adaptive Thinking을 통한 심층 추론 |
| 터미널 환경 복합 조작 | Claude Opus 4.6 | Terminal-Bench 65.4%로 업계 선두 |
| 대규모 도구 오케스트레이션 | Claude Opus 4.6 | MCP Atlas 62.7%로 업계 선두 |
MiniMax-M2.5 최적 프로그래밍 시나리오
MiniMax-M2.5의 강점은 '고빈도, 표준화, 비용 민감형' 프로그래밍 작업에 집중되어 있습니다.
- CI/CD 자동 복구: 지속적으로 실행되는 에이전트가 파이프라인을 모니터링하고 수정합니다. 시간당 $0.30의 비용으로 24시간 내내 경제적인 운영이 가능해요.
- PR 리뷰 봇: Pull Request를 자동으로 검토합니다. BFCL 76.8%의 정확도로 다중 도구 상호작용을 정밀하게 수행합니다.
- 다국어 풀스택 개발: Python, Go, Rust, TypeScript, Java 등 10개 이상의 언어를 지원하며 Web, Android, iOS, Windows를 아우릅니다.
- 대규모 코드 마이그레이션: Multi-SWE-Bench 51.3%의 다중 파일 협업 능력을 활용해 대규모 리팩토링을 처리합니다.
Claude Opus 4.6 최적 프로그래밍 시나리오
Claude Opus 4.6의 강점은 '저빈도, 고복잡도, 심층 추론' 프로그래밍 작업에 집중되어 있습니다.
- 아키텍처 의사결정 보조: Adaptive Thinking(max 모드)을 사용하여 심층적인 기술 솔루션 분석을 수행합니다.
- 레거시 시스템 현대화: 1M 토큰 컨텍스트를 통해 대규모 코드베이스 전체를 한 번에 로드하여 분석합니다.
- 시스템 레벨 디버깅: Terminal-Bench 65.4%의 성능으로 터미널 환경에서 복잡한 시스템 문제를 진단하고 해결합니다.
- 다중 도구 오케스트레이션 플랫폼: MCP Atlas 62.7%의 성능으로 IDE, Git, CI/CD, 모니터링 등 다양한 도구 간의 협업을 조정합니다.
비교 설명: 위 시나리오 추천은 벤치마크 데이터와 실제 개발자 피드백을 바탕으로 작성되었습니다. 프로젝트마다 실제 효과는 다를 수 있으니, APIYI apiyi.com에서 실제 시나리오를 직접 검증해 보시는 것을 권장합니다.
MiniMax-M2.5 vs Opus 4.6 프로그래밍 비용 전격 비교
개발 팀에게 있어 AI 프로그래밍 어시스턴트의 장기적인 비용은 의사 결정의 핵심 요소입니다.
| 비용 시나리오 | MiniMax-M2.5 표준 버전 | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| 입력 가격/1M 토큰 | $0.15 | $0.30 | $5.00 |
| 출력 가격/1M 토큰 | $1.20 | $2.40 | $25.00 |
| 단일 SWE-Bench 작업 | ~$0.15 | ~$0.30 | ~$3.00 |
| 1시간 연속 실행 | $0.30 | $1.00 | ~$30+ |
| 매월 24시간 상시 실행 | ~$216 | ~$720 | ~$21,600+ |
| $100 예산으로 완료 가능한 작업 수 | ~328 개 | ~164 개 | ~30 개 |
중간 규모의 개발 팀을 예로 들어보겠습니다. 매일 50개의 코딩 작업(버그 수정, 코드 리뷰, 기능 구현)을 처리해야 한다면, MiniMax-M2.5 표준 버전의 월 비용은 약 $225, Lightning 버전은 약 $450인 반면, Claude Opus 4.6은 약 $4,500가 필요합니다. 세 모델 모두 SWE-Bench 수준에서 작업 완료 품질은 거의 동일합니다.
🎯 비용 관련 제언: 대부분의 표준 프로그래밍 작업에서 MiniMax-M2.5의 가성비 우위는 뚜렷합니다. APIYI(apiyi.com) 플랫폼을 통해 실제 테스트를 거친 후 선택하는 것을 추천하며, 이 플랫폼은 코드 구조 변경 없이 모델을 유연하게 전환할 수 있도록 지원합니다. 충전 이벤트에 참여하면 더욱 저렴한 가격으로 이용할 수 있습니다.
MiniMax-M2.5 vs Opus 4.6 프로그래밍 빠른 연동
다음 코드는 통합 인터페이스를 통해 두 모델 간에 신속하게 전환하며 비교하는 방법을 보여줍니다.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 테스트 MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
# 테스트 Claude Opus 4.6 - 只需切换 model 参数
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
전체 비교 테스트 코드 보기
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
对单个模型进行编码能力测试
Args:
model_name: 模型 ID
prompt: 编码任务提示词
Returns:
包含响应内容、耗时的字典
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# 编码任务
task = "重构以下函数,使其支持并发安全、超时控制和优雅降级"
# 对比测试
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens in {result['time']}s")
제언: APIYI(apiyi.com)를 통해 하나의 API 키로 MiniMax-M2.5와 Claude Opus 4.6에 동시에 접근할 수 있습니다. 실제 코딩 시나리오에서 두 모델의 성능 차이를 빠르게 비교해 보세요.
자주 묻는 질문(FAQ)
Q1: MiniMax-M2.5가 코딩 작업에서 Claude Opus 4.6을 완전히 대체할 수 있을까요?
완전히 대체하기는 어렵지만, 대부분의 상황에서는 가능합니다. SWE-Bench 점수 차이는 0.6%에 불과하며, Multi-SWE-Bench에서는 M2.5가 오히려 1% 앞서고 있습니다. 일상적인 버그 수정, 코드 리뷰, 기능 구현 등 표준적인 작업에서는 두 모델 간의 차이가 거의 없습니다. 하지만 초거대 코드베이스 분석(1M 컨텍스트 필요)이나 복잡한 시스템 레벨 디버깅(Terminal-Bench) 같은 환경에서는 여전히 Opus 4.6이 우위에 있습니다. 실제 사용 환경에 맞춰 혼용하는 것을 추천드려요.
Q2: 왜 M2.5의 BFCL 점수는 Opus 4.6보다 훨씬 높은데, 코딩 점수는 비슷하게 나오나요?
BFCL은 다회차 도구 호출(Function Calling) 능력을 테스트하는 반면, SWE-Bench는 엔드 투 엔드(End-to-End) 코딩 능력을 테스트하기 때문입니다. Opus 4.6은 단일 회차 도구 호출이 M2.5만큼 정교하지는 않더라도, 강력한 심층 추론 능력을 통해 도구 호출의 효율성 부족을 보완하며 최종적인 코딩 품질을 비슷하게 유지합니다. 다만, AI 에이전트를 활용한 자동 프로그래밍 시나리오에서는 M2.5의 높은 BFCL 점수가 호출 횟수 감소와 전체 비용 절감으로 이어지는 장점이 있습니다.
Q3: 두 모델의 코딩 성능을 빠르게 비교해 보려면 어떻게 해야 하나요?
**APIYI(apiyi.com)**를 통해 비교 테스트를 해보시는 것을 추천드립니다:
- 계정을 등록하고 API Key를 발급받습니다.
- 본문의 코드 예시를 활용해 동일한 코딩 작업에 대해 두 모델을 각각 호출해 봅니다.
- 생성된 코드의 품질, 응답 속도, 그리고 토큰 소모량을 비교합니다.
- 통합된 OpenAI 호환 인터페이스를 제공하므로,
model파라미터만 수정하면 간편하게 모델을 전환할 수 있습니다.
요약
Claude Opus 4.6 대비 MiniMax-M2.5의 코딩 능력에 대한 핵심 결론은 다음과 같습니다.
- 코딩 품질 거의 대등: SWE-Bench 80.2% vs 80.8%로 차이는 0.6%에 불과하며, Multi-SWE-Bench에서는 M2.5가 1% 앞섭니다.
- 도구 호출 능력 M2.5 압승: BFCL 76.8% vs 63.3%로, 에이전트 기반 코딩 시나리오에서는 M2.5가 최적의 선택입니다.
- 압도적인 비용 효율성: 단일 작업당 비용이 M2.5는 $0.15, Opus는 $3.00로, 동일한 예산으로 M2.5를 사용하면 10배 이상의 작업을 수행할 수 있습니다.
- 심층 작업에서의 Opus 4.6 우위: 1M 컨텍스트, Terminal-Bench, MCP Atlas 등 고도의 복잡성이 요구되는 시나리오에서는 여전히 Opus 4.6이 대체 불가능한 강점을 가집니다.
대부분의 일상적인 프로그래밍 작업에서 MiniMax-M2.5는 Opus 4.6에 근접하는 품질과 훨씬 뛰어난 가성비를 제공합니다. **APIYI(apiyi.com)**에서 두 모델의 통합 인터페이스를 활용해 실제 프로젝트에 적용해 보시고 성능을 직접 검증해 보세요. 현재 플랫폼에서 진행 중인 충전 이벤트 등을 활용하면 더욱 경제적으로 이용하실 수 있습니다.
📚 참고 자료
⚠️ 링크 형식 안내: 모든 외부 링크는 SEO 가중치 유실을 방지하기 위해 복사는 쉽지만 클릭은 되지 않는
자료명: domain.com형식을 사용합니다.
-
MiniMax M2.5 공식 발표: M2.5 핵심 역량 및 코딩 벤치마크 테스트 상세 정보
- 링크:
minimax.io/news/minimax-m25 - 설명: SWE-Bench, Multi-SWE-Bench, BFCL 등 전체 데이터 포함
- 링크:
-
Claude Opus 4.6 공식 출시: Anthropic이 발표한 Opus 4.6 기술 세부 정보
- 링크:
anthropic.com/news/claude-opus-4-6 - 설명: Terminal-Bench, MCP Atlas, Adaptive Thinking 등 기능 설명
- 링크:
-
OpenHands M2.5 평가: 독립 개발자 플랫폼의 M2.5 실제 코딩 평가
- 링크:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - 설명: Claude Sonnet을 뛰어넘은 최초의 오픈 소스 모델 실측 분석
- 링크:
-
VentureBeat 심층 비교: M2.5와 Opus 4.6의 가성비 분석
- 링크:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - 설명: 기업 관점에서의 비용 효율성 차이 분석
- 링크:
-
Vellum Opus 4.6 벤치마크 분석: Claude Opus 4.6 전체 벤치마크 테스트 해석
- 링크:
vellum.ai/blog/claude-opus-4-6-benchmarks - 설명: Terminal-Bench, SWE-Bench 등 핵심 코딩 벤치마크 상세 분석
- 링크:
작성자: APIYI Team
기술 교류: 댓글을 통해 여러분의 모델 비교 테스트 결과를 공유해 주세요. 더 많은 AI 프로그래밍 모델 연동 튜토리얼은 APIYI apiyi.com 기술 커뮤니티에서 확인하실 수 있습니다.