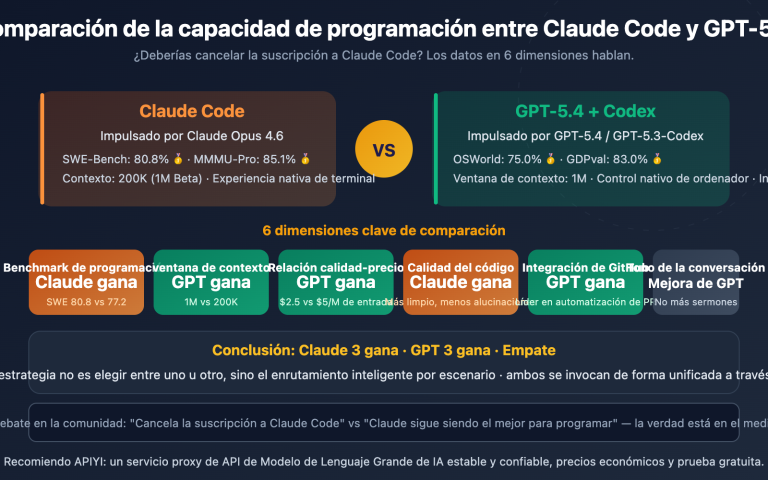
作者注:从 SWE-Bench、Multi-SWE-Bench、BFCL 工具调用、编码速度和价格 5 个维度深度对比 MiniMax-M2.5 和 Claude Opus 4.6 的编程能力差异
选择 AI 编程助手一直是开发者关注的核心问题。本文从 5 个关键维度对比 MiniMax-M2.5 和 Claude Opus 4.6 的编程能力,帮助你在性能和成本之间做出最优选择。
核心价值: 看完本文,你将清楚了解这两个模型在真实编码场景中的能力边界,明确在什么场景下选择谁更划算。

Diferencias clave en la capacidad de programación: MiniMax-M2.5 vs. Claude Opus 4.6
| Dimensión de comparación | MiniMax-M2.5 | Claude Opus 4.6 | Análisis de la brecha |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus solo lidera por un 0.6% |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 supera por un 1.0% |
| Llamadas a herramientas BFCL | 76.8% | 63.3% | M2.5 lidera por un 13.5% |
| Velocidad de salida | 50-100 TPS | ~33 TPS | M2.5 es hasta 3 veces más rápido |
| Precio de salida | $1.20/M tokens | $25/M tokens | M2.5 es unas 20 veces más barato |
Interpretación de los benchmarks de codificación: MiniMax-M2.5 vs. Opus 4.6
Si nos fijamos en SWE-Bench Verified, el benchmark de codificación más reconocido de la industria, la diferencia entre ambos es mínima: el 80.2% de MiniMax-M2.5 está solo 0.6 puntos porcentuales por detrás del 80.8% de Claude Opus 4.6. SWE-Bench Verified evalúa la capacidad del modelo para corregir errores (bugs) e implementar funcionalidades en Pull Requests reales de GitHub, lo que la convierte en la evaluación más cercana a los escenarios de desarrollo reales.
Aún más digno de mención es el benchmark Multi-SWE-Bench, que se enfoca en proyectos complejos de múltiples archivos: MiniMax-M2.5 supera con un 51.3% al 50.3% de Opus 4.6. Esto significa que, al manejar tareas de ingeniería complejas que requieren coordinar modificaciones en varios archivos, el M2.5 se comporta de manera más estable.
Los datos oficiales de MiniMax muestran que, internamente en la empresa, el 80% del código nuevo enviado ya es generado por M2.5, y el 30% de las tareas cotidianas son completadas por este modelo, lo que valida su capacidad de programación desde una perspectiva de aplicación práctica.
La brecha en llamadas a herramientas entre MiniMax-M2.5 y Opus 4.6
La mayor divergencia de capacidades entre los dos modelos en el ámbito de la programación aparece en las llamadas a herramientas (tool calling). En el benchmark BFCL Multi-Turn, MiniMax-M2.5 obtuvo una puntuación del 76.8%, mientras que Claude Opus 4.6 se quedó en un 63.3%, una diferencia abismal de 13.5 puntos porcentuales.
Esta brecha tiene un impacto enorme en los escenarios de programación con agentes: cuando el modelo necesita leer archivos, ejecutar comandos, llamar a APIs, analizar salidas e iterar en bucles, la capacidad de llamar a herramientas determina directamente la eficiencia y precisión en la finalización de la tarea. El M2.5 completa tareas similares con un 20% menos de rondas de llamadas a herramientas que su predecesor M2.1, siendo cada llamada más precisa.
No obstante, Claude Opus 4.6 alcanza un nivel líder en la industria de 62.7% en MCP Atlas (coordinación de herramientas a gran escala), manteniendo su ventaja en escenarios ultra-complejos que requieren coordinar una gran cantidad de herramientas simultáneamente.

MiniMax-M2.5 vs. Opus 4.6: Velocidad y eficiencia en programación
La programación no solo se trata de precisión; la velocidad y la eficiencia son igualmente cruciales. Especialmente en escenarios de programación con agentes, donde el modelo requiere múltiples iteraciones para completar una tarea, la velocidad afecta directamente la experiencia de desarrollo y el costo total.
| Indicador de eficiencia | MiniMax-M2.5 | Claude Opus 4.6 | Ganador |
|---|---|---|---|
| Velocidad de salida (Estándar) | ~50 TPS | ~33 TPS | M2.5 es 1.5 veces más rápido |
| Velocidad de salida (Lightning) | ~100 TPS | ~33 TPS | M2.5 es 3 veces más rápido |
| Tiempo por tarea SWE-Bench | 22.8 minutos | 22.9 minutos | Prácticamente igual |
| Costo por tarea SWE-Bench | ~$0.15 | ~$3.00 | M2.5 es 20 veces más barato |
| Consumo promedio de Tokens/tarea | 3.52M tokens | Mayor | M2.5 ahorra más tokens |
| Optimización de rondas de llamadas | 20% menos que M2.1 | — | M2.5 es más eficiente |
Análisis de la ventaja de velocidad de MiniMax-M2.5
En la evaluación SWE-Bench Verified, MiniMax-M2.5 registró un tiempo promedio de 22.8 minutos por tarea, casi idéntico a los 22.9 minutos de Claude Opus 4.6. Sin embargo, la estructura de costos subyacente es completamente diferente.
Completar una tarea de SWE-Bench con M2.5 cuesta aproximadamente $0.15, mientras que con Opus 4.6 cuesta unos $3.00. Esto significa que, para la misma calidad de codificación, el costo de M2.5 es solo 1/20 del de Opus. Para los equipos que necesitan ejecutar agentes de programación de forma continua, esta diferencia se traduce en ahorros de miles o incluso decenas de miles de dólares al mes.
La alta eficiencia de MiniMax-M2.5 proviene de su arquitectura MoE (230B de parámetros totales con solo 10B activados) y la optimización de descomposición de tareas aportada por el marco de entrenamiento Forge RL. Al programar, el modelo primero realiza una "escritura de especificaciones" (diseño de arquitectura y descomposición de tareas) y luego ejecuta de manera eficiente, en lugar de recurrir al ensayo y error a ciegas.
Ventajas únicas de Claude Opus 4.6 en capacidad de programación
Aunque no es el líder en eficiencia de costos, Claude Opus 4.6 tiene ventajas insustituibles:
- Terminal-Bench 2.0: 65.4%, con un rendimiento líder en la industria para tareas de codificación complejas en entornos de terminal.
- OSWorld: 72.7%, con una capacidad de operación de computadoras mediante agentes que supera con creces a la competencia.
- MCP Atlas: 62.7%, ocupando el primer lugar en la industria en coordinación de herramientas a gran escala.
- Ventana de contexto de 1M: La versión Beta admite un contexto de 1 millón de tokens, lo que elimina la necesidad de segmentar al manejar bases de código extremadamente grandes.
- Adaptive Thinking: Admite 4 niveles de intensidad de pensamiento (bajo/medio/alto/máximo), permitiendo ajustar la profundidad del razonamiento según sea necesario.
Para tareas que requieren un razonamiento profundo, comprensión de contextos de código ultra largos o sistemas extremadamente complejos, Opus 4.6 sigue siendo la opción más potente en la actualidad.
🎯 Sugerencia de selección: Ambos modelos tienen sus fortalezas. Se recomienda realizar pruebas comparativas reales a través de la plataforma APIYI (apiyi.com). La plataforma admite tanto MiniMax-M2.5 como Claude Opus 4.6 con una interfaz unificada; solo necesitas cambiar el parámetro
modelpara verificar los resultados rápidamente.
Recomendaciones de escenarios de programación: MiniMax-M2.5 vs. Opus 4.6
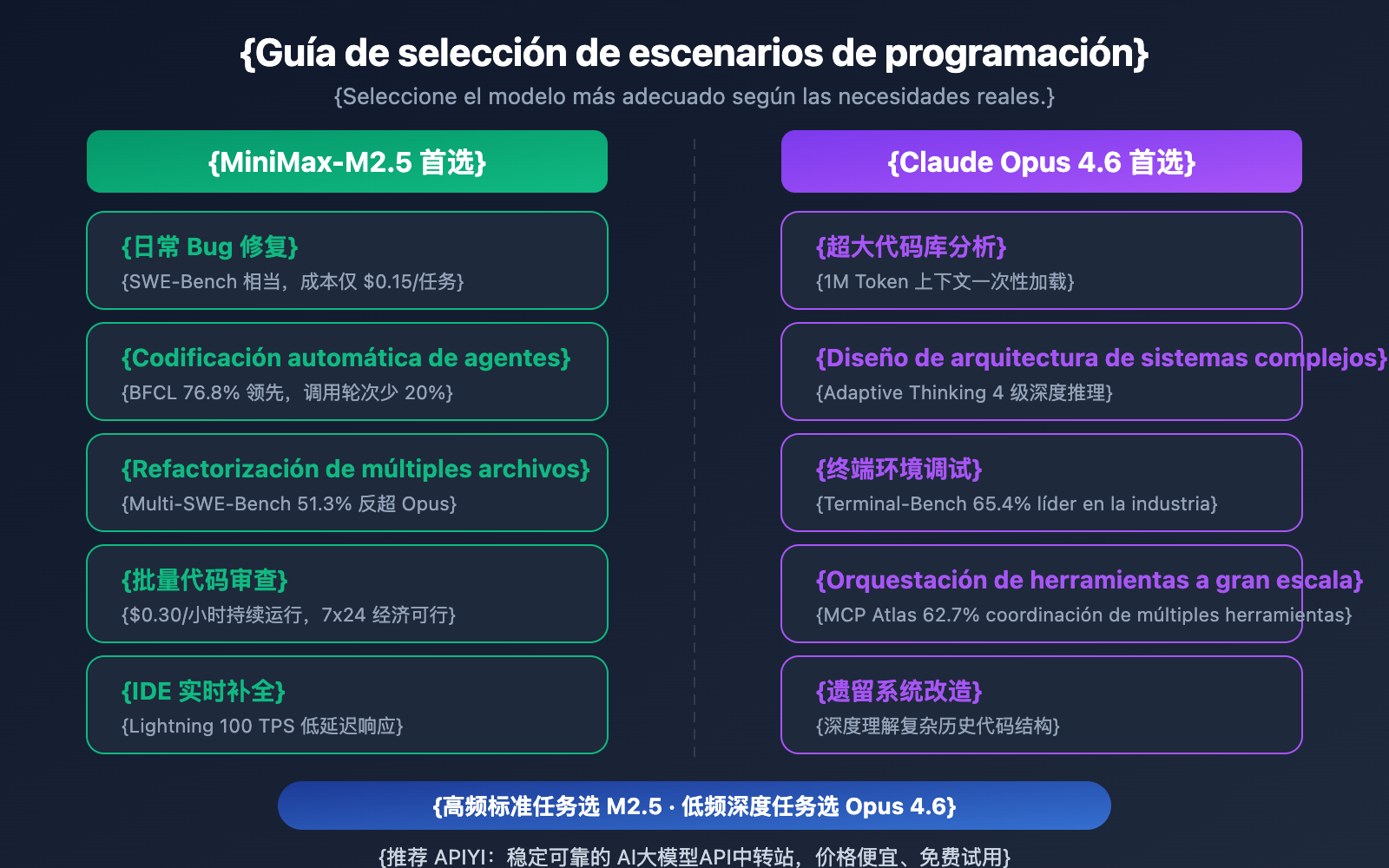
| Escenario de programación | Modelo recomendado | Razón de la recomendación |
|---|---|---|
| Reparación de bugs diarios | MiniMax-M2.5 | Rendimiento SWE-Bench similar, costo 20 veces menor |
| Refactorización multiarchivo | MiniMax-M2.5 | Liderazgo del 1% en Multi-SWE-Bench |
| Codificación automática con agentes | MiniMax-M2.5 | Liderazgo del 13.5% en BFCL, $0.15 por tarea |
| Revisión de código por lotes | MiniMax-M2.5 | Alto rendimiento y bajo costo, versión estándar a $0.30/hora |
| Autocompletado en tiempo real (IDE) | MiniMax-M2.5 Lightning | Baja latencia con 100 TPS |
| Análisis de repositorios masivos | Claude Opus 4.6 | Ventana de contexto de 1M de tokens |
| Diseño de arquitectura compleja | Claude Opus 4.6 | Razonamiento profundo con Adaptive Thinking |
| Operaciones complejas en terminal | Claude Opus 4.6 | Liderazgo con 65.4% en Terminal-Bench |
| Orquestación de herramientas a gran escala | Claude Opus 4.6 | Liderazgo con 62.7% en MCP Atlas |
Mejores escenarios para MiniMax-M2.5
Las ventajas de MiniMax-M2.5 se concentran en tareas de programación de "alta frecuencia, estandarizadas y sensibles al costo":
- Autoreparación en CI/CD: Ejecución continua de agentes para monitorear y reparar flujos de trabajo; el costo de $0.30/hora hace que la operación 24/7 sea económicamente viable.
- Bot de revisión de PR: Revisión automática de Pull Requests; el 76.8% en BFCL asegura precisión en interacciones de herramientas de múltiples rondas.
- Desarrollo Full-stack multilenguaje: Soporte para más de 10 lenguajes de programación (Python, Go, Rust, TypeScript, Java, etc.), cubriendo Web/Android/iOS/Windows.
- Migración de código masiva: Aprovecha la capacidad de colaboración multiarchivo del 51.3% en Multi-SWE-Bench para manejar refactorizaciones a gran escala.
Mejores escenarios para Claude Opus 4.6
Las ventajas de Claude Opus 4.6 se centran en tareas de programación de "baja frecuencia, alta complejidad y razonamiento profundo":
- Asistencia en decisiones de arquitectura: Uso de Adaptive Thinking (modo máximo) para análisis profundo de soluciones técnicas.
- Modernización de sistemas legados: Carga de bases de código completas y masivas de una sola vez gracias a su contexto de 1M de tokens.
- Depuración a nivel de sistema: Resolución de problemas complejos en entornos de terminal con un 65.4% en Terminal-Bench.
- Plataformas de orquestación multiherramienta: Coordinación de IDE, Git, CI/CD, monitoreo y otras herramientas mediante MCP Atlas (62.7%).
Nota comparativa: Las recomendaciones anteriores se basan en datos de pruebas de referencia (benchmarks) y comentarios reales de desarrolladores. Los resultados reales pueden variar según el proyecto; se recomienda realizar validaciones en escenarios reales a través de APIYI (apiyi.com).
Comparativa completa de costes de programación: MiniMax-M2.5 vs. Opus 4.6
Para los equipos de desarrollo, el coste a largo plazo de un asistente de programación con IA es un factor determinante en la toma de decisiones.
| Escenario de coste | MiniMax-M2.5 Estándar | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Precio de entrada/M tokens | $0.15 | $0.30 | $5.00 |
| Precio de salida/M tokens | $1.20 | $2.40 | $25.00 |
| Tarea individual de SWE-Bench | ~$0.15 | ~$0.30 | ~$3.00 |
| 1 hora de ejecución continua | $0.30 | $1.00 | ~$30+ |
| Ejecución 24/7 mensual | ~$216 | ~$720 | ~$21,600+ |
| Tareas con presupuesto de $100 | ~328 tareas | ~164 tareas | ~30 tareas |
Tomando como ejemplo un equipo de desarrollo de tamaño medio: si se necesitan procesar 50 tareas de codificación al día (corrección de errores, revisión de código, implementación de funciones), el coste mensual con MiniMax-M2.5 Estándar sería de unos $225, con la versión Lightning unos $450, mientras que con Claude Opus 4.6 ascendería a unos $4,500. La calidad en la resolución de tareas a nivel de SWE-Bench es prácticamente la misma en los tres.
🎯 Sugerencia de costes: Para la mayoría de las tareas de programación estándar, la ventaja en la relación calidad-precio de MiniMax-M2.5 es evidente. Te recomendamos realizar pruebas reales a través de la plataforma APIYI (apiyi.com) antes de elegir; la plataforma permite cambiar de modelo de forma flexible sin necesidad de modificar la arquitectura de tu código. Además, puedes disfrutar de precios aún más competitivos participando en sus promociones de recarga.
Integración rápida para programación: MiniMax-M2.5 vs. Opus 4.6
El siguiente código muestra cómo alternar rápidamente entre ambos modelos para compararlos utilizando una interfaz unificada:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Probar MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "Implementa un caché LRU seguro para concurrencia en Go"}]
)
# Probar Claude Opus 4.6 - solo hay que cambiar el parámetro model
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "Implementa un caché LRU seguro para concurrencia en Go"}]
)
Ver código completo de la prueba comparativa
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
Realiza una prueba de capacidad de codificación en un solo modelo
Args:
model_name: ID del modelo
prompt: Indicación de la tarea de codificación
Returns:
Diccionario con el contenido de la respuesta y el tiempo transcurrido
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Eres un ingeniero de software senior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# Tarea de codificación
task = "Refactoriza la siguiente función para que soporte seguridad en concurrencia, control de tiempo de espera y degradación progresiva"
# Prueba comparativa
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens en {result['time']}s")
Sugerencia: A través de APIYI (apiyi.com), con una sola API Key puedes acceder simultáneamente a MiniMax-M2.5 y Claude Opus 4.6, permitiéndote comparar rápidamente las diferencias de rendimiento entre ambos en tus escenarios reales de programación.
Preguntas frecuentes
Q1: ¿Puede MiniMax-M2.5 sustituir por completo a Claude Opus 4.6 para programar?
No del todo, pero sí en la mayoría de los escenarios. La diferencia en SWE-Bench es de solo el 0.6%, e incluso en Multi-SWE-Bench el M2.5 lidera por un 1%. En tareas estándar como corrección de errores, revisión de código e implementación de funciones, casi no hay diferencia entre ambos. Sin embargo, en escenarios de análisis de bases de código masivas (que requieren un contexto de 1M) o depuración compleja a nivel de sistema (Terminal-Bench), Opus 4.6 sigue teniendo ventaja. Se recomienda un uso híbrido según el caso real.
Q2: ¿Por qué el BFCL de M2.5 es mucho más alto que el de Opus 4.6, pero sus puntuaciones en codificación son similares?
El BFCL evalúa la capacidad de llamada a herramientas en múltiples turnos (Function Calling), mientras que SWE-Bench mide la capacidad de codificación de extremo a extremo. Aunque las llamadas a herramientas de Opus 4.6 en un solo turno no son tan precisas como las de M2.5, su potente capacidad de razonamiento profundo compensa esa eficiencia, logrando una calidad de codificación global similar. No obstante, en escenarios de programación autónoma con agentes, la alta puntuación BFCL de M2.5 se traduce en menos turnos de llamada y un coste total inferior.
Q3: ¿Cómo puedo comparar rápidamente el rendimiento de programación de ambos modelos?
Te recomendamos usar APIYI (apiyi.com) para realizar pruebas comparativas:
- Regístrate y obtén tu API Key.
- Utiliza los ejemplos de código de este artículo para llamar a ambos modelos con la misma tarea de programación.
- Compara la calidad del código generado, la velocidad de respuesta y el consumo de tokens.
- Gracias a la interfaz compatible con OpenAI, solo necesitas cambiar el parámetro
modelpara alternar entre ellos.
Resumen
Conclusiones clave de la comparativa entre MiniMax-M2.5 y Claude Opus 4.6 en programación:
- Calidad de codificación casi a la par: SWE-Bench 80.2% vs 80.8% (una diferencia de apenas el 0.6%); en Multi-SWE-Bench, el M2.5 incluso supera por un 1%.
- Llamada a herramientas: M2.5 lidera con creces: BFCL 76.8% vs 63.3%, lo que convierte al M2.5 en la opción preferida para escenarios de programación con agentes.
- Diferencia de costes abismal: $0.15 por tarea en M2.5 frente a los $3.00 de Opus; con el mismo presupuesto, puedes completar más de 10 veces el número de tareas.
- Opus 4.6 sigue siendo insustituible en tareas profundas: Mantiene su ventaja en escenarios que requieren 1M de contexto, Terminal-Bench o MCP Atlas.
Para la mayoría de las tareas de programación cotidianas, MiniMax-M2.5 ofrece una calidad de codificación cercana a la de Opus 4.6 con una relación calidad-precio muy superior. Te sugerimos verificarlo en tus propios proyectos a través de APIYI (apiyi.com), donde podrás usar ambos modelos con una interfaz unificada y aprovechar sus promociones de recarga.
📚 Referencias
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos utilizan el formato
Nombre del recurso: domain.compara facilitar la copia, pero no son clicables para evitar la pérdida de autoridad SEO.
-
Anuncio oficial de MiniMax M2.5: Detalles sobre las capacidades principales y benchmarks de codificación de M2.5
- Enlace:
minimax.io/news/minimax-m25 - Descripción: Incluye datos completos de SWE-Bench, Multi-SWE-Bench, BFCL, etc.
- Enlace:
-
Lanzamiento oficial de Claude Opus 4.6: Detalles técnicos de Opus 4.6 publicados por Anthropic
- Enlace:
anthropic.com/news/claude-opus-4-6 - Descripción: Explicación de capacidades como Terminal-Bench, MCP Atlas, Adaptive Thinking, etc.
- Enlace:
-
Evaluación de OpenHands sobre M2.5: Pruebas reales de codificación de M2.5 por una plataforma de desarrolladores independientes
- Enlace:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Descripción: Análisis práctico del primer modelo de pesos abiertos que supera a Claude Sonnet.
- Enlace:
-
Comparativa profunda de VentureBeat: Análisis de relación calidad-precio entre M2.5 y Opus 4.6
- Enlace:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Descripción: Análisis de la diferencia en rentabilidad entre ambos desde una perspectiva empresarial.
- Enlace:
-
Análisis de benchmarks de Vellum sobre Opus 4.6: Interpretación exhaustiva de las pruebas de rendimiento de Claude Opus 4.6
- Enlace:
vellum.ai/blog/claude-opus-4-6-benchmarks - Descripción: Análisis detallado de benchmarks clave de codificación como Terminal-Bench, SWE-Bench, etc.
- Enlace:
Autor: Equipo APIYI
Intercambio técnico: Te invitamos a compartir los resultados de tus pruebas comparativas de modelos en la sección de comentarios. Para más tutoriales sobre cómo integrar modelos de programación de IA, puedes visitar la comunidad técnica de APIYI en apiyi.com.