作者注:从 SWE-Bench、Multi-SWE-Bench、BFCL 工具调用、编码速度和价格 5 个维度深度对比 MiniMax-M2.5 和 Claude Opus 4.6 的编程能力差异
选择 AI 编程助手一直是开发者关注的核心问题。本文从 5 个关键维度对比 MiniMax-M2.5 和 Claude Opus 4.6 的编程能力,帮助你在性能和成本之间做出最优选择。
核心价值: 看完本文,你将清楚了解这两个模型在真实编码场景中的能力边界,明确在什么场景下选择谁更划算。

Основные различия в способностях к программированию: MiniMax-M2.5 против Claude Opus 4.6
| Параметр сравнения | MiniMax-M2.5 | Claude Opus 4.6 | Анализ разрыва |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus впереди всего на 0.6% |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 обходит на 1.0% |
| Вызов инструментов BFCL | 76.8% | 63.3% | M2.5 лидирует на 13.5% |
| Скорость генерации | 50-100 TPS | ~33 TPS | M2.5 быстрее почти в 3 раза |
| Стоимость (вывод) | $1.20/M токенов | $25/M токенов | M2.5 дешевле примерно в 20 раз |
Разбор бенчмарков кодинга: MiniMax-M2.5 против Opus 4.6
Если взглянуть на SWE-Bench Verified — самый признанный в индустрии бенчмарк для оценки навыков программирования, — разрыв между моделями минимален. Результат MiniMax-M2.5 (80.2%) отстает от Claude Opus 4.6 (80.8%) всего на 0.6 процентных пункта. SWE-Bench Verified проверяет способность модели исправлять баги и внедрять новые фичи в реальных Pull Request с GitHub, что максимально приближено к повседневной работе разработчика.
Еще более примечателен бенчмарк Multi-SWE-Bench, который тестирует работу со сложными многофайловыми проектами: здесь MiniMax-M2.5 с результатом 51.3% вырывается вперед, обходя Opus 4.6 (50.3%). Это означает, что в сложных инженерных задачах, требующих координации изменений сразу в нескольких файлах, M2.5 ведет себя стабильнее.
Официальные данные MiniMax подтверждают эти цифры практикой: внутри самой компании 80% нового кода уже генерируется моделью M2.5, а 30% ежедневных задач выполняется ею полностью автономно.
Разрыв в вызове инструментов (Tool Calling)
Самая большая разница в способностях этих двух моделей проявляется в работе с инструментами. В тесте BFCL Multi-Turn (многошаговые диалоги) MiniMax-M2.5 набрала 76.8%, в то время как Claude Opus 4.6 — 63.3%. Разница составляет внушительные 13.5%.
Этот разрыв критически важен для сценариев с ИИ-агентами. Когда модели нужно прочитать файл, выполнить команду в терминале, вызвать API, распарсить ответ и повторить цикл, именно навык вызова инструментов определяет, будет ли задача решена эффективно и без ошибок. M2.5 справляется с подобными задачами за меньшее количество итераций (на 20% меньше, чем предыдущая версия M2.1), делая каждый вызов более точным.
Тем не менее, Claude Opus 4.6 по-прежнему удерживает лидерство в MCP Atlas (координация крупномасштабных инструментов) с результатом 62.7%, сохраняя преимущество в сверхсложных сценариях, где требуется одновременная работа с огромным количеством инструментов.

MiniMax-M2.5 对比 Opus 4.6 编码速度与效率
编程不仅看准确率,速度和效率同样关键。尤其在智能体编程场景中,模型需要多轮迭代完成任务,速度直接影响开发体验和总成本。
| 效率指标 | MiniMax-M2.5 | Claude Opus 4.6 | 优势方 |
|---|---|---|---|
| 输出速度(标准版) | ~50 TPS | ~33 TPS | M2.5 快 1.5 倍 |
| 输出速度(Lightning) | ~100 TPS | ~33 TPS | M2.5 快 3 倍 |
| SWE-Bench 单任务耗时 | 22.8 分钟 | 22.9 分钟 | 基本持平 |
| SWE-Bench 单任务成本 | ~$0.15 | ~$3.00 | M2.5 便宜 20 倍 |
| 平均 Token 消耗/任务 | 3.52M tokens | 更高 | M2.5 更省 Token |
| 工具调用轮次优化 | 比 M2.1 少 20% | — | M2.5 更高效 |
MiniMax-M2.5 编码速度优势分析
MiniMax-M2.5 在 SWE-Bench Verified 评估中的单任务平均耗时为 22.8 分钟,与 Claude Opus 4.6 的 22.9 分钟几乎一致。但背后的成本结构完全不同。
M2.5 完成一个 SWE-Bench 任务的成本约为 $0.15,而 Opus 4.6 约为 $3.00——这意味着同样的编码质量,M2.5 的成本仅为 Opus 的 1/20。对于需要持续运行编码智能体的团队,这个差距会被放大为每月数千甚至数万美元的成本节约。
MiniMax-M2.5 的高效率来源于 MoE 架构(230B 总参数仅激活 10B)和 Forge RL 训练框架带来的任务分解优化。模型在编码时会先进行 "Spec-writing"——架构设计和任务分解,然后高效执行,而非盲目试错。
Claude Opus 4.6 编码能力的独特优势
尽管在成本效率上不占优,Claude Opus 4.6 有其不可替代的优势:
- Terminal-Bench 2.0: 65.4%,在终端环境下的复杂编码任务表现业界领先
- OSWorld: 72.7%,智能体计算机操作能力远超竞品
- MCP Atlas: 62.7%,大规模工具协调能力行业第一
- 1M 上下文窗口: Beta 版支持 100 万 Token 上下文,处理超大型代码库时不需要分段
- Adaptive Thinking: 支持 4 级思考力度(low/medium/high/max),可按需调节推理深度
在需要深度推理、超长代码上下文理解或极端复杂的系统级任务中,Opus 4.6 仍然是目前最强的选择。
🎯 选择建议: 两个模型各有所长,建议通过 APIYI apiyi.com 平台实际测试对比。平台同时支持 MiniMax-M2.5 和 Claude Opus 4.6,统一接口调用,只需切换 model 参数即可快速验证。
MiniMax-M2.5 与 Opus 4.6 编程场景对比推荐
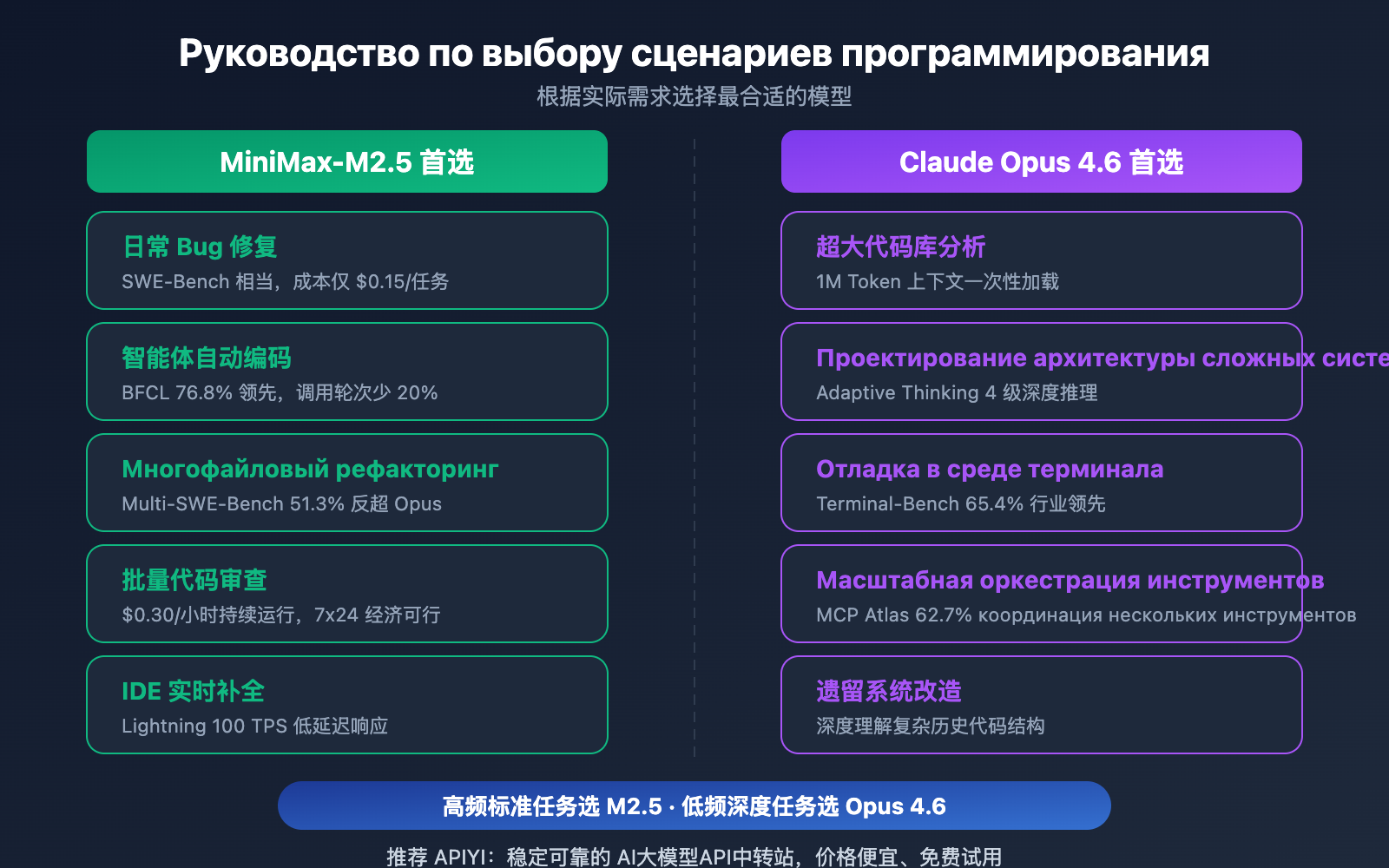
| 编程场景 | 推荐模型 | 推荐理由 |
|---|---|---|
| 日常 Bug 修复 | MiniMax-M2.5 | SWE-Bench 相当,成本低 20 倍 |
| 多文件重构 | MiniMax-M2.5 | Multi-SWE-Bench 领先 1% |
| 智能体自动编码 | MiniMax-M2.5 | BFCL 领先 13.5%,每任务 $0.15 |
| 批量代码审查 | MiniMax-M2.5 | 高吞吐低成本,标准版 $0.30/小时 |
| IDE 实时代码补全 | MiniMax-M2.5 Lightning | 100 TPS 低延迟 |
| 超大代码库分析 | Claude Opus 4.6 | 1M Token 上下文窗口 |
| 复杂系统架构设计 | Claude Opus 4.6 | Adaptive Thinking 深度推理 |
| 终端环境复杂操作 | Claude Opus 4.6 | Terminal-Bench 65.4% 领先 |
| 大规模工具编排 | Claude Opus 4.6 | MCP Atlas 62.7% 领先 |
MiniMax-M2.5 最佳编程场景
MiniMax-M2.5 的优势集中在"高频、标准化、成本敏感"的编程任务:
- CI/CD 自动修复: 持续运行的智能体监控和修复流水线,$0.30/小时的成本使 7×24 运行经济可行
- PR Review Bot: 自动审查 Pull Request,BFCL 76.8% 确保多轮工具交互精准
- 多语言全栈开发: 支持 10+ 编程语言(Python、Go、Rust、TypeScript、Java 等),覆盖 Web/Android/iOS/Windows
- 批量代码迁移: 利用 Multi-SWE-Bench 51.3% 的多文件协作能力处理大规模重构
Claude Opus 4.6 最佳编程场景
Claude Opus 4.6 的优势集中在"低频、高复杂度、深度推理"的编程任务:
- 架构决策辅助: 利用 Adaptive Thinking(max 模式)进行深度技术方案分析
- 遗留系统改造: 1M Token 上下文一次性加载整个大型代码库
- 系统级调试: Terminal-Bench 65.4% 在终端环境下定位和解决复杂系统问题
- 多工具编排平台: MCP Atlas 62.7% 协调 IDE、Git、CI/CD、监控等多工具协同
对比说明: 以上场景推荐基于基准测试数据和实际开发者反馈。不同项目的实际效果可能有所差异,建议通过 APIYI apiyi.com 进行实际场景验证。
Полное сравнение затрат на программирование: MiniMax-M2.5 против Opus 4.6
Для команд разработчиков долгосрочные затраты на AI-помощников — ключевой фактор при принятии решения.
| Сценарий затрат | MiniMax-M2.5 Standard | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Цена за вход / 1 млн токенов | $0.15 | $0.30 | $5.00 |
| Цена за выход / 1 млн токенов | $1.20 | $2.40 | $25.00 |
| Одна задача SWE-Bench | ~$0.15 | ~$0.30 | ~$3.00 |
| 1 час непрерывной работы | $0.30 | $1.00 | ~$30+ |
| Работа 24/7 в течение месяца | ~$216 | ~$720 | ~$21,600+ |
| Кол-во задач на бюджет $100 | ~328 | ~164 | ~30 |
Возьмем в качестве примера среднюю команду разработчиков: если ежедневно нужно выполнять 50 задач по кодингу (исправление багов, код-ревью, реализация фич), то при использовании MiniMax-M2.5 Standard ежемесячные затраты составят около $225, для версии Lightning — около $450, в то время как Claude Opus 4.6 обойдется примерно в $4 500. При этом качество выполнения задач на уровне SWE-Bench у всех трех моделей практически одинаковое.
🎯 Совет по экономии: Для большинства стандартных задач программирования MiniMax-M2.5 предлагает очевидное преимущество по соотношению цены и качества. Рекомендуем провести реальные тесты на платформе APIYI (apiyi.com). Она позволяет гибко переключаться между моделями без изменения архитектуры кода. А при участии в акциях по пополнению баланса можно получить еще более выгодные условия.
Быстрая интеграция для сравнения MiniMax-M2.5 и Opus 4.6
Ниже приведен код, показывающий, как быстро переключаться между двумя моделями через единый интерфейс для сравнения:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 测试 MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
# 测试 Claude Opus 4.6 - 只需切换 model 参数
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
Посмотреть полный код для сравнительного тестирования
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
对单个模型进行编码能力测试
Args:
model_name: 模型 ID
prompt: 编码任务提示词
Returns:
包含响应内容、耗时的字典
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# 编码任务
task = "重构以下函数,使其支持并发安全、超时控制和优雅降级"
# 对比测试
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens in {result['time']}s")
Рекомендация: С помощью одного API-ключа от APIYI (apiyi.com) вы можете получить доступ одновременно к MiniMax-M2.5 и Claude Opus 4.6, чтобы быстро сравнить их производительность в ваших реальных сценариях кодинга.
Часто задаваемые вопросы
Q1: Может ли MiniMax-M2.5 полностью заменить Claude Opus 4.6 в программировании?
Не совсем, но в большинстве сценариев — да. Разрыв в SWE-Bench составляет всего 0.6%, а в Multi-SWE-Bench M2.5 даже лидирует на 1%. В стандартных задачах, таких как исправление багов, код-ревью или реализация новых функций, разницы между ними почти нет. Однако в специфических случаях, например, при анализе сверхбольших кодовых баз (где нужен контекст 1M) или сложной системной отладке (Terminal-Bench), Opus 4.6 всё еще сохраняет преимущество. Рекомендуем комбинировать их в зависимости от конкретной задачи.
Q2: Почему показатель BFCL у M2.5 намного выше, чем у Opus 4.6, хотя баллы за кодинг почти одинаковые?
Тест BFCL проверяет способность к многократному вызову инструментов (Function Calling), в то время как SWE-Bench оценивает сквозные навыки программирования (end-to-end). Хотя Opus 4.6 может быть менее точен в разовых вызовах инструментов по сравнению с M2.5, его мощные способности к глубоким рассуждениям компенсируют это, что в итоге дает схожее общее качество кода. Тем не менее, в сценариях с автономными ИИ-агентами высокий балл BFCL у M2.5 означает меньшее количество итераций и, как следствие, более низкую итоговую стоимость.
Q3: Как быстро сравнить результаты программирования этих двух моделей?
Рекомендуем провести сравнительное тестирование через APIYI (apiyi.com):
- Зарегистрируйтесь и получите API Key.
- Используйте примеры кода из этой статьи, чтобы отправить одну и ту же задачу обеим моделям.
- Сравните качество сгенерированного кода, скорость ответа и расход токенов.
- Благодаря единому интерфейсу, совместимому с OpenAI, для переключения между моделями достаточно просто изменить параметр
model.
Итоги
Основные выводы по сравнению навыков программирования MiniMax-M2.5 и Claude Opus 4.6:
- Качество кодинга почти на одном уровне: SWE-Bench 80.2% против 80.8% (разница 0.6%); в Multi-SWE-Bench M2.5 даже вырывается вперед на 1%.
- M2.5 значительно впереди по вызову инструментов: BFCL 76.8% против 63.3%, что делает M2.5 приоритетным выбором для разработки ИИ-агентов.
- Колоссальная разница в цене: $0.15 за задачу у M2.5 против $3.00 у Opus. При том же бюджете можно выполнить в 20 раз больше задач.
- Opus 4.6 незаменим в «тяжелых» задачах: контекст 1M, Terminal-Bench и MCP Atlas всё еще остаются его сильными сторонами.
Для большинства повседневных задач программирования MiniMax-M2.5 предлагает качество кода, сопоставимое с Opus 4.6, при гораздо более выгодном соотношении цены и производительности. Советуем проверить это на практике через APIYI (apiyi.com) — платформа поддерживает единый интерфейс для обеих моделей, а участие в акциях при пополнении баланса сделает тесты еще выгоднее.
📚 Справочные материалы
⚠️ Примечание по формату ссылок: Все внешние ссылки указаны в формате
Название: domain.com. Это сделано для удобства копирования, но ссылки не кликабельны, чтобы избежать потери SEO-веса.
-
Официальный анонс MiniMax M2.5: Подробности об основных возможностях M2.5 и бенчмарках кодинга
- Ссылка:
minimax.io/news/minimax-m25 - Описание: Содержит полные данные по SWE-Bench, Multi-SWE-Bench, BFCL и др.
- Ссылка:
-
Официальный релиз Claude Opus 4.6: Технические детали Opus 4.6, опубликованные Anthropic
- Ссылка:
anthropic.com/news/claude-opus-4-6 - Описание: Описание возможностей Terminal-Bench, MCP Atlas, Adaptive Thinking и др.
- Ссылка:
-
Оценка M2.5 от OpenHands: Реальное тестирование кодинга M2.5 на платформе независимых разработчиков
- Ссылка:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Описание: Практический анализ первой модели с открытыми весами, которая догнала и перегнала Claude Sonnet.
- Ссылка:
-
Глубокое сравнение от VentureBeat: Анализ соотношения цены и качества M2.5 и Opus 4.6
- Ссылка:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Описание: Анализ разницы в экономической эффективности обоих решений с точки зрения бизнеса.
- Ссылка:
-
Анализ бенчмарков Opus 4.6 от Vellum: Разбор полных результатов тестирования Claude Opus 4.6
- Ссылка:
vellum.ai/blog/claude-opus-4-6-benchmarks - Описание: Детальный анализ ключевых бенчмарков кодинга, таких как Terminal-Bench и SWE-Bench.
- Ссылка:
Автор: Команда APIYI
Техническое сообщество: Делитесь результатами своих сравнительных тестов моделей в комментариях. Больше руководств по интеграции моделей для ИИ-программирования доступно в техническом сообществе APIYI на сайте apiyi.com.