著者注:SWE-Bench、Multi-SWE-Bench、BFCL ツール呼び出し、コーディング速度、価格の5つの次元から、MiniMax-M2.5 と Claude Opus 4.6 のプログラミング能力の差異を深く比較します。
AIプログラミングアシスタントの選定は、開発者にとって常に核心的な課題です。本記事では、MiniMax-M2.5 と Claude Opus 4.6 のプログラミング能力を5つの重要な次元から比較し、パフォーマンスとコストのバランスを考慮した最適な選択をサポートします。
核心となる価値: 本記事を読み終える頃には、これら2つのモデルが実際のコーディングシーンでどこまで対応できるのか、そしてどのような場面でどちらを選ぶのが最も賢い選択なのかが明確になるはずです。

MiniMax-M2.5 と Claude Opus 4.6 のプログラミング能力における主な差異
| 比較次元 | MiniMax-M2.5 | Claude Opus 4.6 | 差異分析 |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus がわずか 0.6% リード |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 が 1.0% 逆転 |
| BFCL ツール呼び出し | 76.8% | 63.3% | M2.5 が 13.5% リード |
| 出力速度 | 50-100 TPS | ~33 TPS | M2.5 が最大 3 倍高速 |
| 出力価格 | $1.20/M tokens | $25/M tokens | M2.5 が約 20 倍安価 |
MiniMax-M2.5 と Opus 4.6 のコーディングベンチマーク解説
業界で最も認知されているコーディングベンチマークである SWE-Bench Verified を見ると、両者の差は極めてわずかです。MiniMax-M2.5 の 80.2% は、Claude Opus 4.6 の 80.8% に対してわずか 0.6 ポイントの差に留まっています。SWE-Bench Verified は、実際の GitHub プルリクエストにおけるバグ修正や機能実装の能力をテストするもので、最も実際の開発シーンに近い評価指標です。
さらに注目すべきは、複数ファイルにまたがる複雑なプロジェクトを対象とした Multi-SWE-Bench です。ここでは MiniMax-M2.5 が 51.3% を記録し、Opus 4.6 の 50.3% を逆転しました。これは、複数のファイル間で修正を調整する必要がある複雑なエンジニアリングタスクにおいて、M2.5 の方が安定したパフォーマンスを発揮することを意味しています。
MiniMax の公式データによると、社内の新規コミットコードの 80% が M2.5 によって生成されており、日常業務の 30% を M2.5 が完結させています。これは、実際の応用レベルにおいてもその高いコーディング能力が実証されていることを示しています。
MiniMax-M2.5 と Opus 4.6 のツール呼び出しにおける差
プログラミング領域における両モデルの最大の能力差は、ツール呼び出し(Tool Calling)において顕著に現れました。BFCL Multi-Turn ベンチマークテストでは、MiniMax-M2.5 のスコアが 76.8% だったのに対し、Claude Opus 4.6 は 63.3% と、13.5 ポイントもの大差がつきました。
この差は、AI エージェントによるプログラミングシーンで多大な影響を及ぼします。モデルがファイルを読み込み、コマンドを実行し、API を呼び出し、出力を解析してループを回す際、ツール呼び出し能力がタスク完了の効率と正確性を直接左右するからです。M2.5 は、同種のタスクを完了するためのツール呼び出し回数が前世代の M2.1 より 20% 減少しており、一回一回の呼び出しがより正確になっています。
ただし、Claude Opus 4.6 は MCP Atlas(大規模ツール調整)において 62.7% という業界トップクラスの水準に達しており、大量のツールを同時に調整する必要がある超複雑なシナリオでは、依然として優位性を持っています。
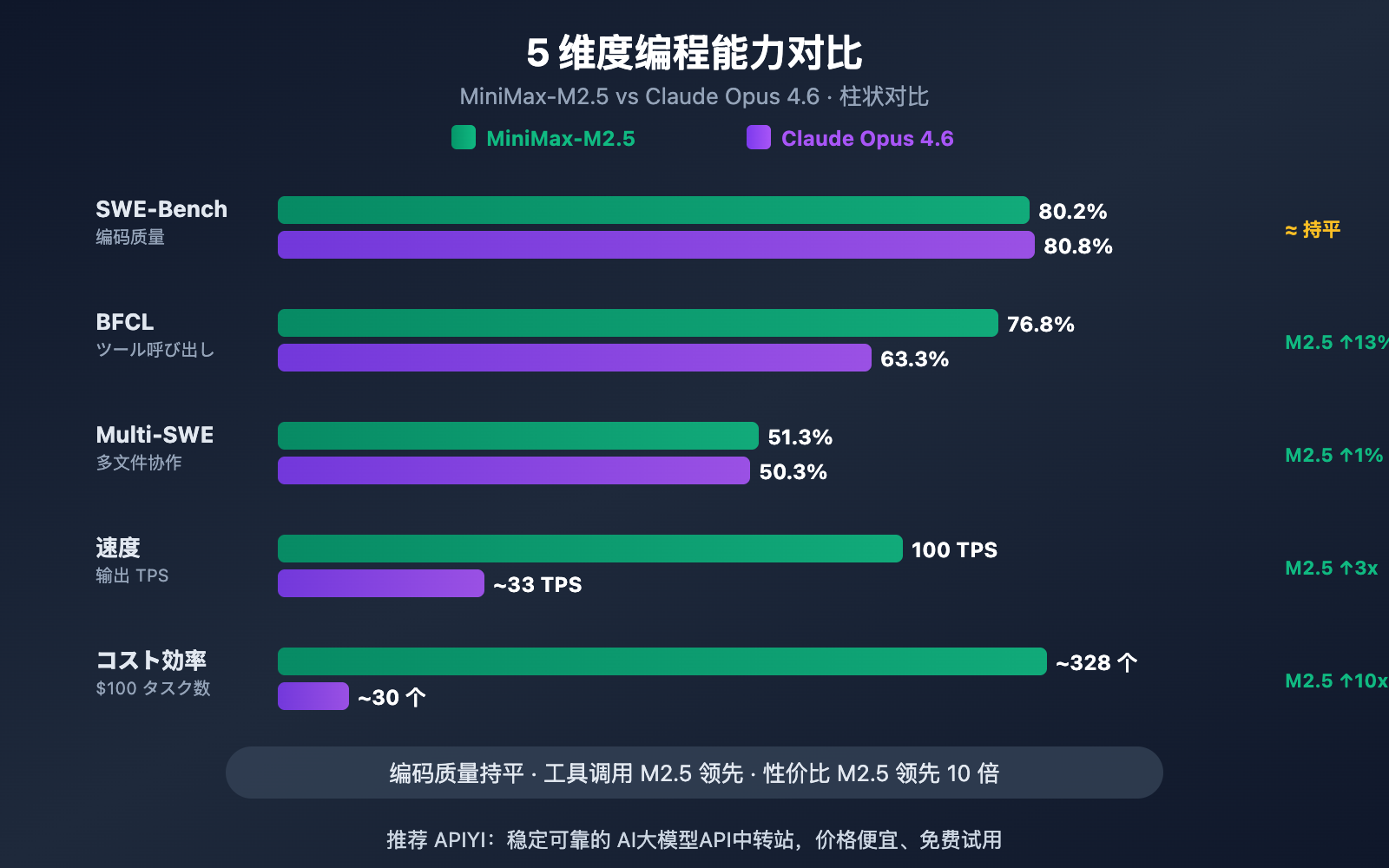
MiniMax-M2.5 対 Opus 4.6:コーディング速度と効率の比較
プログラミングにおいて、正確性はもちろん重要ですが、速度と効率も同様に不可欠です。特にAIエージェントによるプログラミングシーンでは、モデルがタスクを完了するために何度も反復(イテレーション)を行う必要があり、速度は開発体験と総コストに直結します。
| 効率指標 | MiniMax-M2.5 | Claude Opus 4.6 | 優位性 |
|---|---|---|---|
| 出力速度(標準版) | ~50 TPS | ~33 TPS | M2.5が1.5倍高速 |
| 出力速度(Lightning) | ~100 TPS | ~33 TPS | M2.5が3倍高速 |
| SWE-Bench 単一タスク所要時間 | 22.8分 | 22.9分 | ほぼ同等 |
| SWE-Bench 単一タスクコスト | ~$0.15 | ~$3.00 | M2.5が20倍安価 |
| 平均トークン消費量/タスク | 3.52M tokens | より高い | M2.5の方がトークンを節約 |
| ツール呼び出しターンの最適化 | M2.1より20%削減 | — | M2.5の方が高効率 |
MiniMax-M2.5 のコーディング速度における優位性分析
MiniMax-M2.5 は、SWE-Bench Verified 評価において、1タスクあたりの平均所要時間が22.8分となっており、Claude Opus 4.6 の22.9分とほぼ一致しています。しかし、その背景にあるコスト構造は全く異なります。
M2.5 で SWE-Bench の1タスクを完了するコストは約0.15ドルであるのに対し、Opus 4.6 は約3.00ドルです。これは、同等のコーディング品質でありながら、M2.5 のコストは Opus のわずか20分の1であることを意味します。コーディングエージェントを継続的に稼働させるチームにとって、この差は月間数千ドル、あるいは数万ドルのコスト削減につながります。
MiniMax-M2.5 の高効率は、MoE(混合専門家)アーキテクチャ(総パラメータ数230Bのうち、アクティブなのは10Bのみ)と、Forge RL 学習フレームワークによるタスク分解の最適化から生まれています。モデルはコーディングの際、まず「Spec-writing(仕様作成)」、つまりアーキテクチャ設計とタスク分解を行い、その後効率的に実行します。闇雲な試行錯誤は行いません。
Claude Opus 4.6 のコーディング能力における独自の強み
コスト効率の面では劣るものの、Claude Opus 4.6 には代替不可能な強みがあります。
- Terminal-Bench 2.0: 65.4% を記録し、ターミナル環境下での複雑なコーディングタスクにおいて業界をリードするパフォーマンスを発揮します。
- OSWorld: 72.7% と、エージェントによるコンピュータ操作能力で競合製品を大きく引き離しています。
- MCP Atlas: 62.7% を達成し、大規模なツール連携能力において業界トップです。
- 1M コンテキストウィンドウ: Beta版では100万トークンのコンテキストをサポートしており、超大規模なコードベースを扱う際も分割の必要がありません。
- Adaptive Thinking: 4段階の思考レベル(low/medium/high/max)をサポートし、必要に応じて推論の深さを調整可能です。
深い推論、超長文のコードコンテキストの理解、あるいは極めて複雑なシステムレベルのタスクが必要な場合、Opus 4.6 は依然として現在最強の選択肢です。
🎯 選択のアドバイス: 両モデルにはそれぞれの長所があります。APIYI (apiyi.com) プラットフォームで実際にテストして比較することをお勧めします。このプラットフォームは MiniMax-M2.5 と Claude Opus 4.6 の両方をサポートしており、統一されたインターフェースで
modelパラメータを切り替えるだけで、素早く検証が可能です。
MiniMax-M2.5 と Opus 4.6 プログラミング利用シーン比較推奨
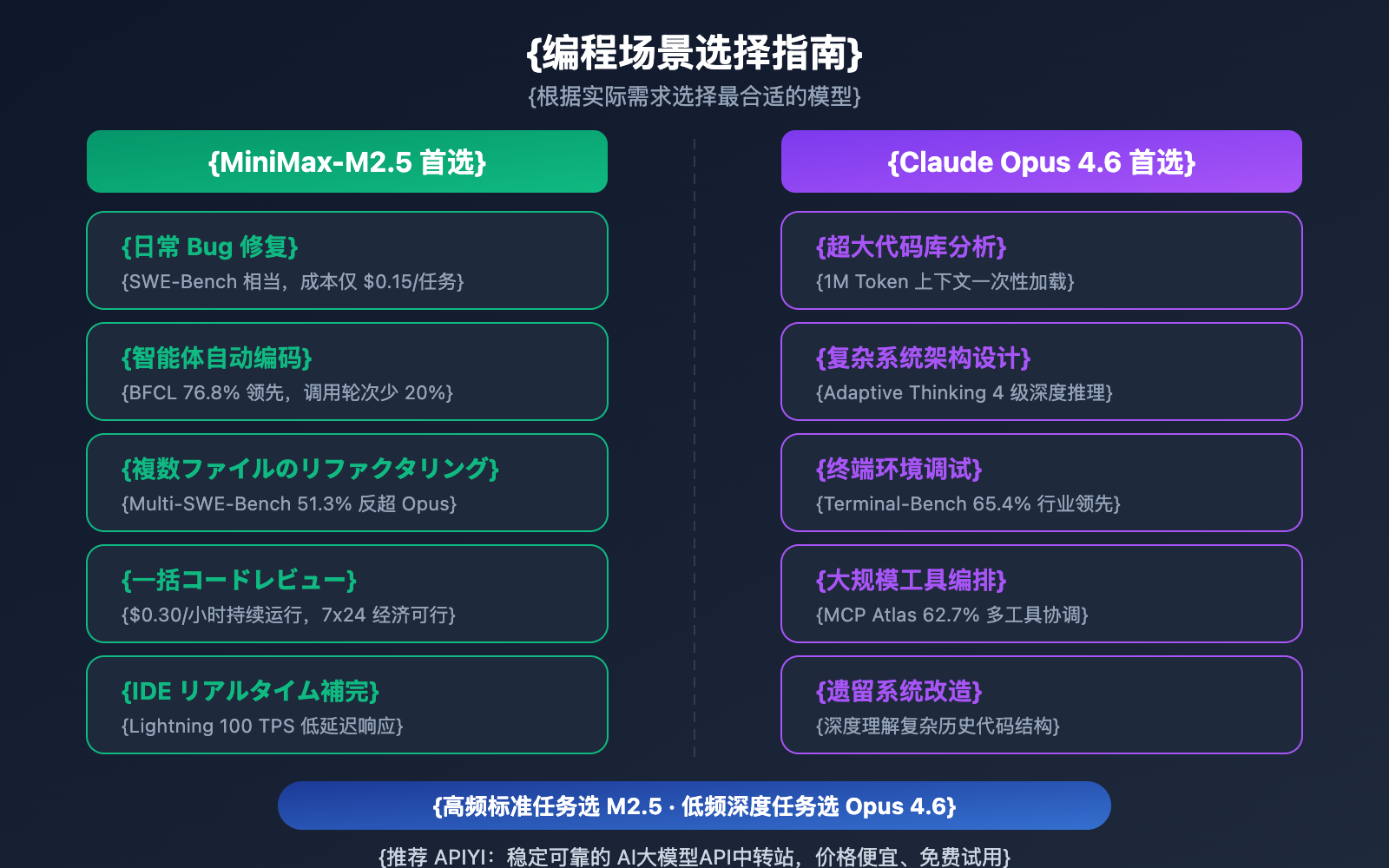
| プログラミングシーン | 推奨モデル | 推奨理由 |
|---|---|---|
| 日常的なバグ修正 | MiniMax-M2.5 | SWE-Bench は同等、コストは20分の1 |
| 複数ファイルのレファクタリング | MiniMax-M2.5 | Multi-SWE-Bench で1%リード |
| エージェントによる自動コーディング | MiniMax-M2.5 | BFCL で13.5%リード、1タスク0.15ドル |
| 一括コードレビュー | MiniMax-M2.5 | 高スループットかつ低コスト、標準版0.30ドル/時 |
| IDE リアルタイムコード補完 | MiniMax-M2.5 Lightning | 100 TPS の低遅延 |
| 巨大なコードベースの分析 | Claude Opus 4.6 | 1M トークンのコンテキストウィンドウ |
| 複雑なシステムアーキテクチャ設計 | Claude Opus 4.6 | Adaptive Thinking による深い推論 |
| ターミナル環境での複雑な操作 | Claude Opus 4.6 | Terminal-Bench 65.4% でリード |
| 大規模なツールオーケストレーション | Claude Opus 4.6 | MCP Atlas 62.7% でリード |
MiniMax-M2.5 に最適なプログラミングシーン
MiniMax-M2.5 の強みは、「高頻度、標準化、コスト重視」のプログラミングタスクに集中しています。
- CI/CD 自動修正: 継続的に稼働するエージェントによる監視とパイプラインの修正。0.30ドル/時というコストにより、24時間365日の稼働が経済的に可能です。
- PR Review Bot: プルリクエストの自動レビュー。BFCL 76.8% により、複数回のツール操作を正確に行います。
- 多言語フルスタック開発: 10以上のプログラミング言語(Python、Go、Rust、TypeScript、Javaなど)をサポートし、Web/Android/iOS/Windowsをカバーします。
- 大規模コード移行: Multi-SWE-Bench 51.3% の複数ファイル連携能力を活かし、大規模なレファクタリングを処理します。
Claude Opus 4.6 に最適なプログラミングシーン
Claude Opus 4.6 の強みは、「低頻度、高複雑度、深い推論」を必要とするプログラミングタスクに集中しています。
- アーキテクチャ決定補助: Adaptive Thinking(maxモード)を利用した、深い技術スキームの分析。
- レガシーシステムの刷新: 1M トークンのコンテキストにより、大規模なコードベース全体を一度に読み込みます。
- システムレベルのデバッグ: Terminal-Bench 65.4% を活かし、ターミナル環境で複雑なシステム問題を特定・解決します。
- マルチツール・オーケストレーション: MCP Atlas 62.7% により、IDE、Git、CI/CD、監視などの複数ツールの高度な連携を実現します。
比較に関する注記: 上記のシーン別推奨は、ベンチマークデータと実際の開発者からのフィードバックに基づいています。プロジェクトごとの実際の効果は異なる場合があるため、APIYI (apiyi.com) を通じて実際の利用シーンで検証することをお勧めします。
MiniMax-M2.5 対 Opus 4.6 プログラミングコスト徹底比較
開発チームにとって、AIプログラミングアシスタントの長期的なコストは、意思決定における重要な要素です。
| コストシナリオ | MiniMax-M2.5 標準版 | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| 入力価格 / 100万 tokens | $0.15 | $0.30 | $5.00 |
| 出力価格 / 100万 tokens | $1.20 | $2.40 | $25.00 |
| SWE-Bench 1タスクあたり | ~$0.15 | ~$0.30 | ~$3.00 |
| 1時間連続稼働 | $0.30 | $1.00 | ~$30+ |
| 毎月24時間稼働 | ~$216 | ~$720 | ~$21,600+ |
| $100の予算で完了できるタスク数 | ~328 個 | ~164 個 | ~30 個 |
中規模の開発チームを例に挙げると、1日に50件のコーディングタスク(バグ修正、コードレビュー、機能実装)を処理する場合、MiniMax-M2.5 標準版の月間コストは約225ドル、Lightning版は約450ドルですが、Claude Opus 4.6では約4,500ドルが必要になります。SWE-Benchのスコアで見ると、これら3つのモデルがタスクを完了する品質はほぼ同等です。
🎯 コストに関するアドバイス: ほとんどの標準的なプログラミングタスクにおいて、MiniMax-M2.5のコストパフォーマンスの高さは明らかです。APIYI (apiyi.com) プラットフォームで実際にテストしてから選択することをお勧めします。このプラットフォームでは、コードのアーキテクチャを変更することなく、モデルを柔軟に切り替えることができます。また、チャージキャンペーンを利用することで、さらにお得な価格で利用可能です。
MiniMax-M2.5 対 Opus 4.6 プログラミングへのクイック導入
以下のコードは、統一されたインターフェースを介して2つのモデルを素早く切り替え、比較する方法を示しています。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# MiniMax-M2.5 をテスト
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
# Claude Opus 4.6 をテスト - model パラメータを切り替えるだけ
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "用 Go 实现一个并发安全的 LRU 缓存"}]
)
完全な比較テストコードを表示
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
単一モデルのコーディング能力テストを実行
Args:
model_name: モデル ID
prompt: コーディングタスクのプロンプト
Returns:
レスポンス内容と所要時間を含む辞書
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "你是一位资深软件工程师"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# コーディングタスク
task = "重构以下函数,使其支持并发安全、超时控制和优雅降级"
# 比較テスト
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens in {result['time']}s")
アドバイス: APIYI (apiyi.com) なら、1つのAPIキーでMiniMax-M2.5とClaude Opus 4.6の両方にアクセスできます。実際のコーディング環境で、両者のパフォーマンスの違いを素早く比較してみてください。
よくある質問
Q1: MiniMax-M2.5は、プログラミングにおいてClaude Opus 4.6を完全に置き換えることができますか?
完全に置き換えることはできませんが、ほとんどのシーンで可能です。SWE-Benchの差はわずか0.6%であり、Multi-SWE-BenchではM2.5が1%リードしています。日常的なバグ修正、コードレビュー、機能実装などの標準的なタスクでは、両者にほとんど差はありません。ただし、超大規模なコードベースの分析(1Mコンテキストが必要な場合)や、複雑なシステムレベルのデバッグ(Terminal-Bench)などのシーンでは、依然としてOpus 4.6に優位性があります。実際の利用シーンに合わせて併用することをお勧めします。
Q2: なぜM2.5のBFCLはOpus 4.6より大幅に高いのに、コーディングのスコアは近いのですか?
BFCLはマルチターンのツール呼び出し能力(Function Calling)をテストするものであり、SWE-Benchはエンドツーエンドのコーディング能力をテストするものです。Opus 4.6は単発のツール呼び出し精度ではM2.5に及びませんが、その強力な深い推論能力がツール呼び出しの効率不足を補い、最終的なコーディング品質全体では拮抗しています。ただし、AIエージェントによる自動プログラミングのシーンでは、M2.5の高いBFCLスコアは、より少ない呼び出し回数とより低い総コストを意味します。
Q3: 2つのモデルのプログラミング効果を素早く比較するにはどうすればよいですか?
APIYI(apiyi.com)を通じた比較テストをお勧めします:
- アカウントを登録し、APIキーを取得します。
- 本記事のコード例を使用して、同一のコーディングタスクに対して2つのモデルをそれぞれ呼び出します。
- 生成されたコードの品質、レスポンス速度、トークン消費量を比較します。
- OpenAI互換の統一インターフェースを採用しているため、modelパラメータを変更するだけでモデルを切り替えられます。
まとめ
MiniMax-M2.5とClaude Opus 4.6のプログラミング能力に関する比較の核心的な結論は以下の通りです:
- コーディング品質はほぼ互角: SWE-Bench 80.2% vs 80.8%で、差はわずか0.6%。Multi-SWE-BenchではM2.5が1%上回っています。
- ツール呼び出しはM2.5が大幅にリード: BFCL 76.8% vs 63.3%で、AIエージェントによるプログラミングシーンではM2.5が第一候補となります。
- コストの差が圧倒的: 1タスクあたりM2.5が0.15ドルに対し、Opusは3.00ドル。同じ予算で10倍以上のタスクを完了できます。
- Opus 4.6は高度なタスクで代替不可: 1Mコンテキスト、Terminal-Bench、MCP Atlasなどのシーンでは依然として優位性があります。
ほとんどの日常的なプログラミングタスクにおいて、MiniMax-M2.5はOpus 4.6に近いコーディング品質と、それを遥かに凌駕するコストパフォーマンスを提供します。APIYI(apiyi.com)を通じて実際のプロジェクトで比較検証することをお勧めします。このプラットフォームは2つのモデルの統一インターフェース呼び出しをサポートしており、チャージキャンペーンでお得に利用することも可能です。
📚 参考資料
⚠️ リンク形式に関する説明: すべての外部リンクは
資料名: domain.comの形式を使用しています。コピーしやすく、かつSEO評価の流出を防ぐために、クリック可能なリンクにはしていません。
-
MiniMax M2.5 公式発表: M2.5のコア能力とコーディング・ベンチマークの詳細
- リンク:
minimax.io/news/minimax-m25 - 説明: SWE-Bench、Multi-SWE-Bench、BFCLなどの完全なデータが含まれています。
- リンク:
-
Claude Opus 4.6 公式リリース: Anthropicが発表したOpus 4.6の技術的な詳細
- リンク:
anthropic.com/news/claude-opus-4-6 - 説明: Terminal-Bench、MCP Atlas、Adaptive Thinkingなどの機能説明。
- リンク:
-
OpenHands M2.5 レビュー: 独立系開発者プラットフォームによるM2.5の実践的なコーディング評価
- リンク:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - 説明: Claude Sonnetを超えた初のオープンモデルの実測分析。
- リンク:
-
VentureBeat 詳細比較: M2.5とOpus 4.6のコストパフォーマンス分析
- リンク:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - 説明: 企業視点での両者の費用対効果の差を分析。
- リンク:
-
Vellum Opus 4.6 ベンチマーク分析: Claude Opus 4.6の包括的なベンチマークテストの解説
- リンク:
vellum.ai/blog/claude-opus-4-6-benchmarks - 説明: Terminal-Bench、SWE-Benchなどの主要なコーディング・ベンチマークの詳細分析。
- リンク:
著者: APIYI Team
技術交流: コメント欄であなたのモデル比較テストの結果をぜひ共有してください。AIプログラミングモデルの導入チュートリアルについては、APIYI apiyi.com 技術コミュニティをご覧ください。