Nota do autor: Uma comparação profunda das diferenças de capacidade de programação entre o MiniMax-M2.5 e o Claude Opus 4.6 em 5 dimensões: SWE-Bench, Multi-SWE-Bench, chamadas de ferramentas BFCL, velocidade de codificação e preço.
Escolher um assistente de programação de IA sempre foi uma questão central para os desenvolvedores. Este artigo compara as capacidades de programação do MiniMax-M2.5 e do Claude Opus 4.6 em 5 dimensões cruciais, ajudando você a fazer a melhor escolha entre desempenho e custo.
Valor principal: Ao terminar de ler este artigo, você entenderá claramente os limites de capacidade desses dois modelos em cenários reais de codificação e saberá exatamente qual deles vale mais a pena para cada situação.

Diferenças Principais de Capacidade de Programação: MiniMax-M2.5 vs. Claude Opus 4.6
| Dimensão de Comparação | MiniMax-M2.5 | Claude Opus 4.6 | Análise de Diferença |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 80.8% | Opus lidera por apenas 0,6% |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 supera em 1,0% |
| Chamada de Ferramentas BFCL | 76.8% | 63.3% | M2.5 lidera por 13,5% |
| Velocidade de Saída | 50-100 TPS | ~33 TPS | M2.5 é até 3x mais rápido |
| Preço de Saída | $1.20/M tokens | $25/M tokens | M2.5 é cerca de 20x mais barato |
Interpretação dos Benchmarks de Codificação: MiniMax-M2.5 vs. Opus 4.6
Olhando para o SWE-Bench Verified, que é o benchmark de codificação mais reconhecido do setor, a diferença entre os dois é mínima — os 80,2% do MiniMax-M2.5 estão apenas 0,6 pontos percentuais atrás dos 80,8% do Claude Opus 4.6. O SWE-Bench Verified testa a capacidade do modelo de corrigir bugs e implementar funcionalidades em Pull Requests reais do GitHub, sendo a avaliação que mais se aproxima de cenários reais de desenvolvimento.
Ainda mais digno de nota é o Multi-SWE-Bench, um benchmark para projetos complexos com múltiplos arquivos: o MiniMax-M2.5 superou o Opus 4.6 com uma pontuação de 51,3% contra 50,3%. Isso significa que, ao lidar com tarefas de engenharia complexas que exigem a coordenação de modificações em vários arquivos, o M2.5 apresenta um desempenho mais estável.
Dados oficiais da MiniMax mostram que, internamente na empresa, 80% do novo código submetido já é gerado pelo M2.5, e 30% das tarefas diárias são concluídas por ele, o que valida sua capacidade de codificação em um nível de aplicação prática.
A Lacuna entre MiniMax-M2.5 e Opus 4.6 em Chamada de Ferramentas
A maior divergência de capacidade entre os dois modelos no campo da programação aparece na chamada de ferramentas (tool calling). No benchmark BFCL Multi-Turn, o MiniMax-M2.5 obteve 76,8%, enquanto o Claude Opus 4.6 ficou com 63,3% — uma diferença impressionante de 13,5 pontos percentuais.
Essa diferença tem um impacto enorme em cenários de programação com agentes — quando o modelo precisa ler arquivos, executar comandos, chamar APIs, analisar saídas e iterar em loops, a capacidade de chamada de ferramentas determina diretamente a eficiência e a precisão da conclusão da tarefa. O M2.5 reduziu em 20% as rodadas de chamadas de ferramentas para tarefas semelhantes em comparação com a geração anterior M2.1, tornando cada chamada mais precisa.
No entanto, o Claude Opus 4.6 ainda mantém uma vantagem em cenários ultra-complexos que exigem a coordenação simultânea de uma vasta quantidade de ferramentas, atingindo um nível de liderança no setor de 62,7% no MCP Atlas (coordenação de ferramentas em larga escala).

MiniMax-M2.5 vs. Opus 4.6: Velocidade e Eficiência de Codificação
Na programação, não conta apenas a precisão; a velocidade e a eficiência também são fundamentais. Especialmente em cenários de programação com agentes, onde o modelo precisa de várias iterações para concluir uma tarefa, a velocidade afeta diretamente a experiência de desenvolvimento e o custo total.
| Indicadores de Eficiência | MiniMax-M2.5 | Claude Opus 4.6 | Vantagem |
|---|---|---|---|
| Velocidade de Saída (Padrão) | ~50 TPS | ~33 TPS | M2.5 é 1.5x mais rápido |
| Velocidade de Saída (Lightning) | ~100 TPS | ~33 TPS | M2.5 é 3x mais rápido |
| Tempo por Tarefa SWE-Bench | 22.8 minutos | 22.9 minutos | Praticamente igual |
| Custo por Tarefa SWE-Bench | ~$0.15 | ~$3.00 | M2.5 é 20x mais barato |
| Consumo Médio de Tokens/Tarefa | 3.52M tokens | Superior | M2.5 economiza mais Tokens |
| Otimização de Rodadas de Chamada | 20% menos que M2.1 | — | M2.5 é mais eficiente |
Análise da Vantagem de Velocidade do MiniMax-M2.5
O tempo médio por tarefa do MiniMax-M2.5 na avaliação SWE-Bench Verified foi de 22.8 minutos, quase idêntico aos 22.9 minutos do Claude Opus 4.6. No entanto, a estrutura de custos por trás disso é completamente diferente.
O custo para o M2.5 concluir uma tarefa do SWE-Bench é de cerca de $0.15, enquanto o Opus 4.6 custa cerca de $3.00 — isso significa que, para a mesma qualidade de codificação, o custo do M2.5 é apenas 1/20 do Opus. Para equipes que precisam rodar agentes de codificação continuamente, essa diferença se traduz em uma economia de milhares ou até dezenas de milhares de dólares por mês.
A alta eficiência do MiniMax-M2.5 vem da sua arquitetura MoE (230B de parâmetros totais, mas apenas 10B ativados) e da otimização de decomposição de tarefas trazida pelo framework de treinamento Forge RL. Ao codificar, o modelo primeiro realiza o "Spec-writing" — design de arquitetura e decomposição de tarefas — e depois executa de forma eficiente, em vez de seguir uma tentativa e erro cega.
Vantagens Exclusivas da Capacidade de Codificação do Claude Opus 4.6
Embora não seja tão vantajoso em termos de custo-benefício, o Claude Opus 4.6 possui pontos fortes insubstituíveis:
- Terminal-Bench 2.0: 65.4%, com desempenho líder na indústria em tarefas complexas de codificação em ambiente de terminal.
- OSWorld: 72.7%, com capacidade de operação de computador por agentes muito superior aos concorrentes.
- MCP Atlas: 62.7%, ocupando o primeiro lugar na indústria em coordenação de ferramentas em larga escala.
- Janela de Contexto de 1M: A versão Beta suporta 1 milhão de tokens de contexto, eliminando a necessidade de segmentação ao lidar com bases de código gigantescas.
- Adaptive Thinking: Suporta 4 níveis de intensidade de pensamento (low/medium/high/max), permitindo ajustar a profundidade do raciocínio conforme a necessidade.
Em tarefas que exigem raciocínio profundo, compreensão de contextos de código ultralongos ou sistemas extremamente complexos, o Opus 4.6 continua sendo a escolha mais robusta atualmente.
🎯 Sugestão de Escolha: Ambos os modelos têm seus pontos fortes. Recomendamos realizar testes práticos na plataforma APIYI (apiyi.com). A plataforma suporta simultaneamente o MiniMax-M2.5 e o Claude Opus 4.6 com uma interface unificada; basta alterar o parâmetro
modelpara validar rapidamente.
Recomendações de Cenários de Programação: MiniMax-M2.5 vs. Opus 4.6
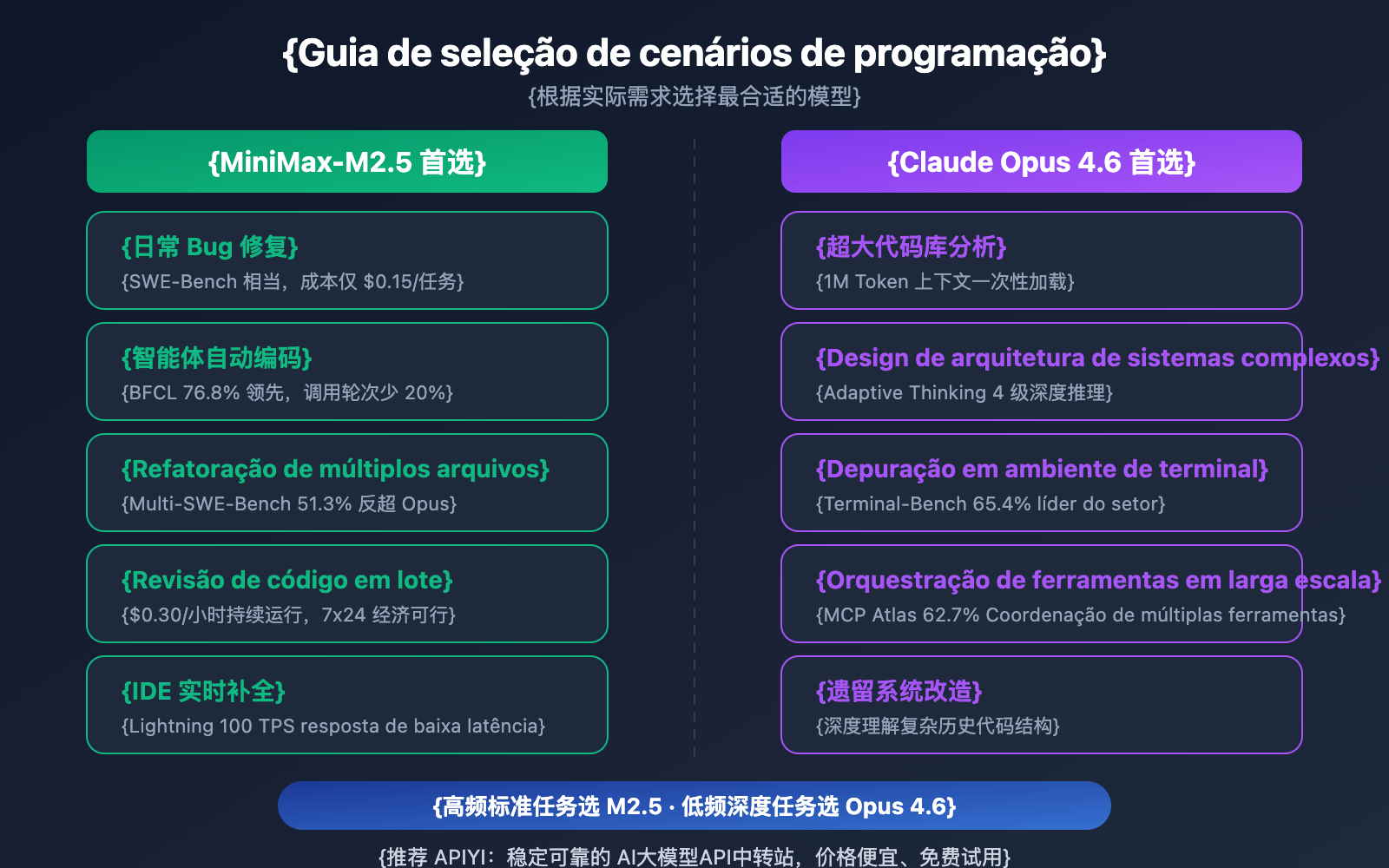
| Cenário de Programação | Modelo Recomendado | Motivo da Recomendação |
|---|---|---|
| Correção diária de Bugs | MiniMax-M2.5 | Desempenho SWE-Bench equivalente, custo 20x menor |
| Refatoração de múltiplos arquivos | MiniMax-M2.5 | Liderança de 1% no Multi-SWE-Bench |
| Codificação automática por agentes | MiniMax-M2.5 | Liderança de 13.5% no BFCL, $0.15 por tarefa |
| Revisão de código em lote | MiniMax-M2.5 | Alta taxa de transferência e baixo custo ($0.30/hora na versão padrão) |
| Autocompletar código em tempo real (IDE) | MiniMax-M2.5 Lightning | Baixa latência com 100 TPS |
| Análise de grandes bases de código | Claude Opus 4.6 | Janela de contexto de 1M de Tokens |
| Design de arquitetura de sistemas complexos | Claude Opus 4.6 | Raciocínio profundo com Adaptive Thinking |
| Operações complexas em terminal | Claude Opus 4.6 | Liderança com 65.4% no Terminal-Bench |
| Orquestração de ferramentas em larga escala | Claude Opus 4.6 | Liderança com 62.7% no MCP Atlas |
Melhores Cenários para o MiniMax-M2.5
A força do MiniMax-M2.5 está em tarefas de programação de "alta frequência, padronizadas e sensíveis ao custo":
- Correção automática em CI/CD: Pipelines de monitoramento e correção de agentes em execução contínua; o custo de $0.30/hora torna a operação 24/7 economicamente viável.
- Bot de Revisão de PR: Revisão automática de Pull Requests; a pontuação de 76.8% no BFCL garante precisão em interações de ferramentas em várias rodadas.
- Desenvolvimento Full Stack Multilingue: Suporte para mais de 10 linguagens (Python, Go, Rust, TypeScript, Java, etc.), cobrindo Web/Android/iOS/Windows.
- Migração de código em lote: Utiliza a capacidade de colaboração em múltiplos arquivos de 51.3% do Multi-SWE-Bench para lidar com refatorações em larga escala.
Melhores Cenários para o Claude Opus 4.6
A força do Claude Opus 4.6 está em tarefas de programação de "baixa frequência, alta complexidade e raciocínio profundo":
- Auxílio em decisões de arquitetura: Uso do Adaptive Thinking (modo max) para análises profundas de soluções técnicas.
- Modernização de sistemas legados: A janela de contexto de 1M de Tokens permite carregar uma base de código inteira de uma só vez.
- Depuração de nível de sistema: 65.4% no Terminal-Bench para localizar e resolver problemas complexos em ambientes de terminal.
- Plataformas de orquestração de múltiplas ferramentas: 62.7% no MCP Atlas para coordenar IDE, Git, CI/CD, monitoramento e outras ferramentas simultaneamente.
Nota de Comparação: As recomendações acima são baseadas em dados de benchmarks e feedback real de desenvolvedores. Os resultados práticos podem variar dependendo do projeto; recomendamos a validação em cenários reais através do APIYI (apiyi.com).
Comparação completa de custos de programação: MiniMax-M2.5 vs. Opus 4.6
Para equipes de desenvolvimento, o custo a longo prazo de um assistente de programação com IA é um fator determinante na tomada de decisão.
| Cenário de Custo | MiniMax-M2.5 Padrão | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Preço de Entrada/M tokens | $0.15 | $0.30 | $5.00 |
| Preço de Saída/M tokens | $1.20 | $2.40 | $25.00 |
| Tarefa única SWE-Bench | ~$0.15 | ~$0.30 | ~$3.00 |
| Execução contínua por 1 hora | $0.30 | $1.00 | ~$30+ |
| Execução 24/7 por mês | ~$216 | ~$720 | ~$21,600+ |
| Tarefas com orçamento de $100 | ~328 tarefas | ~164 tarefas | ~30 tarefas |
Tomando como exemplo uma equipe de desenvolvimento de médio porte: se for necessário processar 50 tarefas de codificação por dia (correções de bugs, revisões de código, implementação de funcionalidades), o custo mensal usando a versão padrão do MiniMax-M2.5 seria de cerca de $225, a versão Lightning cerca de $450, enquanto o Claude Opus 4.6 exigiria cerca de $4.500. A qualidade da conclusão das tarefas no nível SWE-Bench é quase idêntica entre os três.
🎯 Sugestão de custo: Para a maioria das tarefas de programação padrão, a vantagem de custo-benefício do MiniMax-M2.5 é óbvia. Recomendamos realizar testes práticos através da plataforma APIYI (apiyi.com) antes de escolher; a plataforma permite alternar modelos de forma flexível sem alterar a arquitetura do código. Ao participar de campanhas de recarga, você ainda pode aproveitar preços ainda mais competitivos.
Integração rápida para programação: MiniMax-M2.5 vs. Opus 4.6
O código abaixo mostra como alternar rapidamente entre os dois modelos através de uma interface unificada para comparação:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Testando o MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "Implemente um cache LRU thread-safe em Go"}]
)
# Testando o Claude Opus 4.6 - basta trocar o parâmetro model
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "Implemente um cache LRU thread-safe em Go"}]
)
Ver código completo do teste de benchmark
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
Testa a capacidade de codificação de um único modelo
Args:
model_name: ID do modelo
prompt: Comando (prompt) da tarefa de codificação
Returns:
Dicionário contendo o conteúdo da resposta, tokens e tempo gasto
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Você é um engenheiro de software sênior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# Tarefa de codificação
task = "Refatore a seguinte função para que ela suporte segurança de concorrência, controle de timeout e degradação suave (graceful degradation)"
# Teste comparativo
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens em {result['time']}s")
Sugestão: Através da APIYI (apiyi.com), com apenas uma chave de API, você pode acessar simultaneamente o MiniMax-M2.5 e o Claude Opus 4.6, comparando rapidamente a diferença de desempenho entre os dois em seus cenários reais de codificação.
Perguntas Frequentes
Q1: O MiniMax-M2.5 pode substituir completamente o Claude Opus 4.6 para programação?
Não totalmente, mas na maioria dos cenários, sim. A diferença no SWE-Bench é de apenas 0,6%, e no Multi-SWE-Bench o M2.5 chega a liderar por 1%. Em tarefas padrão como correção de bugs, revisão de código e implementação de funcionalidades, quase não há diferença entre os dois. No entanto, em análises de bases de código gigantescas (que exigem 1M de contexto) ou depuração complexa em nível de sistema (Terminal-Bench), o Opus 4.6 ainda leva vantagem. A recomendação é usar ambos de forma híbrida, dependendo do cenário.
Q2: Por que o BFCL do M2.5 é muito superior ao do Opus 4.6, mas a pontuação de codificação é próxima?
O BFCL testa a capacidade de chamadas de ferramentas em múltiplas rodadas (Function Calling), enquanto o SWE-Bench testa a capacidade de codificação de ponta a ponta. Embora o Opus 4.6 não seja tão preciso em chamadas de ferramentas individuais quanto o M2.5, sua poderosa capacidade de raciocínio profundo compensa essa eficiência, resultando em uma qualidade final de codificação semelhante. Contudo, em cenários de programação autônoma com agentes (AI Agents), o BFCL alto do M2.5 significa menos rodadas de interação e um custo total bem menor.
Q3: Como comparar rapidamente o desempenho de programação dos dois modelos?
Recomendamos realizar testes comparativos através do APIYI (apiyi.com):
- Crie uma conta e obtenha sua API Key.
- Use os exemplos de código deste artigo para chamar os dois modelos na mesma tarefa de programação.
- Compare a qualidade do código gerado, a velocidade de resposta e o consumo de Tokens.
- Com a interface compatível com OpenAI, você só precisa alterar o parâmetro
modelpara alternar entre eles.
Conclusão
As principais conclusões da comparação entre MiniMax-M2.5 e Claude Opus 4.6 em programação são:
- Qualidade de codificação quase idêntica: SWE-Bench 80,2% vs 80,8% (diferença de 0,6%); no Multi-SWE-Bench, o M2.5 supera por 1%.
- M2.5 lidera com folga em chamadas de ferramentas: BFCL 76,8% vs 63,3%, tornando o M2.5 a escolha ideal para cenários de programação com agentes.
- Diferença de custo abismal: O M2.5 custa cerca de $0,15 por tarefa contra $3,00 do Opus; com o mesmo orçamento, você realiza mais de 10 vezes mais tarefas.
- Opus 4.6 ainda é insubstituível em tarefas profundas: Contexto de 1M, Terminal-Bench e cenários como MCP Atlas ainda são seus pontos fortes.
Para a maioria das tarefas diárias de programação, o MiniMax-M2.5 oferece uma qualidade de codificação próxima à do Opus 4.6 com um custo-benefício muito superior. Sugerimos validar na prática através do APIYI (apiyi.com), que suporta uma interface unificada para ambos os modelos e oferece promoções de recarga para economizar ainda mais.
📚 Referências
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
Nome do Recurso: domain.compara facilitar a cópia, mas não são clicáveis para evitar a perda de autoridade de SEO.
-
Anúncio Oficial do MiniMax M2.5: Detalhes sobre as capacidades principais e benchmarks de codificação do M2.5
- Link:
minimax.io/news/minimax-m25 - Descrição: Inclui dados completos de SWE-Bench, Multi-SWE-Bench, BFCL, etc.
- Link:
-
Lançamento Oficial do Claude Opus 4.6: Detalhes técnicos do Opus 4.6 publicados pela Anthropic
- Link:
anthropic.com/news/claude-opus-4-6 - Descrição: Explicações sobre capacidades como Terminal-Bench, MCP Atlas, Adaptive Thinking, entre outras.
- Link:
-
Avaliação do OpenHands M2.5: Testes práticos de codificação do M2.5 realizados por uma plataforma de desenvolvedores independentes
- Link:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Descrição: Análise prática do primeiro modelo de pesos abertos a superar o Claude Sonnet.
- Link:
-
Comparação Profunda da VentureBeat: Análise de custo-benefício entre o M2.5 e o Opus 4.6
- Link:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Descrição: Análise das diferenças de custo-benefício sob a perspectiva empresarial.
- Link:
-
Análise de Benchmark do Vellum Opus 4.6: Interpretação completa dos testes de benchmark do Claude Opus 4.6
- Link:
vellum.ai/blog/claude-opus-4-6-benchmarks - Descrição: Análise detalhada de benchmarks de codificação essenciais como Terminal-Bench e SWE-Bench.
- Link:
Autor: Equipe APIYI
Troca de Conhecimento: Sinta-se à vontade para compartilhar os resultados dos seus testes comparativos de modelos na seção de comentários. Para mais tutoriais de integração de modelos de programação de IA, visite a comunidade técnica APIYI em apiyi.com.