Catatan Penulis: Perbandingan mendalam perbedaan kemampuan pemrograman antara MiniMax-M2.5 dan Claude Opus 4.6 dari 5 dimensi: SWE-Bench, Multi-SWE-Bench, pemanggilan alat BFCL, kecepatan pengodean, dan harga.
Memilih asisten pemrograman AI selalu menjadi perhatian utama bagi para pengembang. Artikel ini membandingkan kemampuan pemrograman MiniMax-M2.5 dan Claude Opus 4.6 dari 5 dimensi kunci untuk membantu Anda membuat pilihan optimal antara performa dan biaya.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami dengan jelas batasan kemampuan kedua model ini dalam skenario pengodean nyata, serta mengetahui kapan pilihan yang satu lebih menguntungkan daripada yang lain.

Perbedaan Inti Kemampuan Pemrograman MiniMax-M2.5 vs Claude Opus 4.6
| Dimensi Perbandingan | MiniMax-M2.5 | Claude Opus 4.6 | Analisis Selisih |
|---|---|---|---|
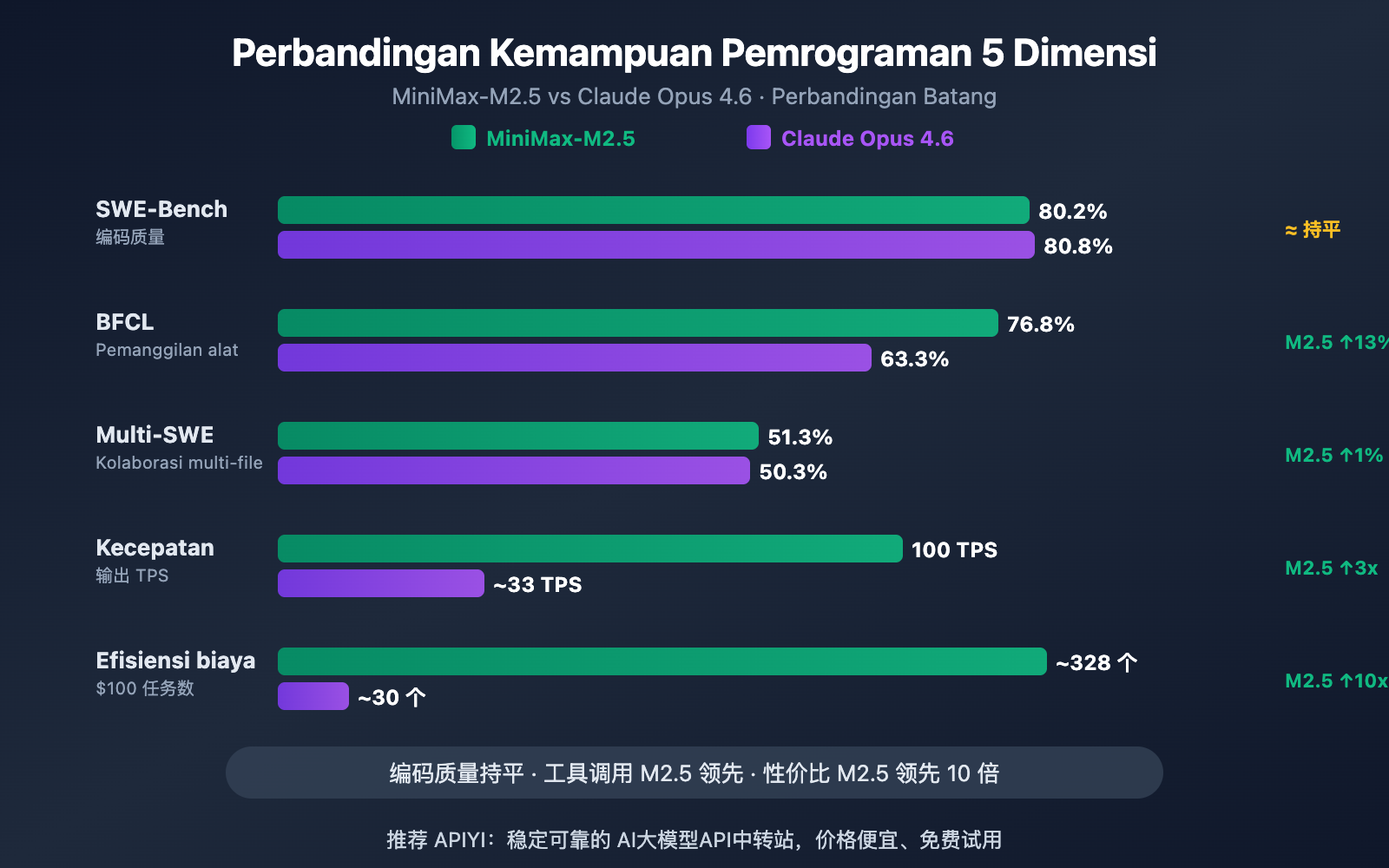
| SWE-Bench Verified | 80.2% | 80.8% | Opus hanya unggul 0.6% |
| Multi-SWE-Bench | 51.3% | 50.3% | M2.5 berbalik unggul 1.0% |
| Pemanggilan Alat BFCL | 76.8% | 63.3% | M2.5 unggul 13.5% |
| Kecepatan Output | 50-100 TPS | ~33 TPS | M2.5 hingga 3x lebih cepat |
| Harga Output | $1.20/M tokens | $25/M tokens | M2.5 sekitar 20x lebih murah |
Interpretasi Benchmark Pengodean MiniMax-M2.5 vs Opus 4.6
Dilihat dari SWE-Bench Verified, benchmark pengodean yang paling diakui di industri, selisih antara keduanya sangat kecil—skor 80.2% milik MiniMax-M2.5 hanya tertinggal 0.6 poin persentase dari skor 80.8% milik Claude Opus 4.6. SWE-Bench Verified menguji kemampuan model dalam memperbaiki bug dan mengimplementasikan fitur dalam GitHub Pull Request nyata, yang merupakan evaluasi paling mendekati skenario pengembangan asli.
Yang lebih menarik untuk diperhatikan adalah Multi-SWE-Bench, benchmark proyek kompleks multi-file: MiniMax-M2.5 berhasil menyalip Opus 4.6 dengan skor 51.3% berbanding 50.3%. Ini berarti dalam menangani tugas rekayasa kompleks yang membutuhkan koordinasi modifikasi di beberapa file, performa M2.5 lebih stabil.
Data resmi MiniMax menunjukkan bahwa di internal perusahaan mereka, 80% kode baru yang di-submit sudah dihasilkan oleh M2.5, dan 30% tugas harian diselesaikan oleh M2.5. Hal ini memvalidasi kemampuan pengodeannya dari sisi aplikasi praktis.
Selisih Pemanggilan Alat antara MiniMax-M2.5 dan Opus 4.6
Pemisah kemampuan terbesar antara kedua model ini di bidang pemrograman muncul pada pemanggilan alat (tool calling). Dalam uji benchmark BFCL Multi-Turn, MiniMax-M2.5 meraih skor 76.8%, sementara Claude Opus 4.6 hanya 63.3%, selisih yang cukup jauh sebesar 13.5 poin persentase.
Selisih ini berdampak besar dalam skenario pemrograman berbasis agen—ketika model perlu membaca file, menjalankan perintah, memanggil API, mengurai output, dan melakukan iterasi berulang, kemampuan pemanggilan alat secara langsung menentukan efisiensi dan akurasi penyelesaian tugas. M2.5 menyelesaikan tugas serupa dengan jumlah putaran pemanggilan alat 20% lebih sedikit dibandingkan generasi sebelumnya (M2.1), di mana setiap pemanggilan menjadi lebih presisi.
Namun, Claude Opus 4.6 tetap memiliki keunggulan dalam skenario super kompleks yang membutuhkan koordinasi alat dalam jumlah besar secara bersamaan, dengan skor 62.7% di MCP Atlas (koordinasi alat skala besar), yang merupakan level terdepan di industri.
MiniMax-M2.5 vs Opus 4.6: Kecepatan dan Efisiensi Pengodean
Pemrograman bukan hanya soal akurasi; kecepatan dan efisiensi juga sangat krusial. Terutama dalam skenario pemrograman agen (agentic programming), di mana model memerlukan beberapa iterasi untuk menyelesaikan tugas, kecepatan berdampak langsung pada pengalaman pengembangan dan total biaya.
| Metrik Efisiensi | MiniMax-M2.5 | Claude Opus 4.6 | Pihak yang Unggul |
|---|---|---|---|
| Kecepatan Output (Standar) | ~50 TPS | ~33 TPS | M2.5 1,5x lebih cepat |
| Kecepatan Output (Lightning) | ~100 TPS | ~33 TPS | M2.5 3x lebih cepat |
| Waktu per Tugas SWE-Bench | 22,8 menit | 22,9 menit | Hampir setara |
| Biaya per Tugas SWE-Bench | ~$0,15 | ~$3,00 | M2.5 20x lebih murah |
| Rata-rata Konsumsi Token/Tugas | 3,52M token | Lebih tinggi | M2.5 lebih hemat Token |
| Optimasi Putaran Tool Call | 20% lebih sedikit dari M2.1 | — | M2.5 lebih efisien |
Analisis Keunggulan Kecepatan Pengodean MiniMax-M2.5
Dalam evaluasi SWE-Bench Verified, rata-rata waktu per tugas MiniMax-M2.5 adalah 22,8 menit, hampir identik dengan Claude Opus 4.6 yang mencatat 22,9 menit. Namun, struktur biaya di baliknya sangat berbeda.
Biaya untuk menyelesaikan satu tugas SWE-Bench dengan M2.5 adalah sekitar $0,15, sedangkan Opus 4.6 sekitar $3,00—ini berarti untuk kualitas pengodean yang sama, biaya M2.5 hanya 1/20 dari Opus. Bagi tim yang perlu menjalankan agen pengodean secara terus-menerus, perbedaan ini akan terakumulasi menjadi penghematan biaya ribuan atau bahkan puluhan ribu dolar setiap bulannya.
Efisiensi tinggi MiniMax-M2.5 berasal dari arsitektur MoE (Mixture of Experts) (hanya 10B yang aktif dari total 230B parameter) dan optimasi dekomposisi tugas yang dibawa oleh kerangka pelatihan Forge RL. Saat mengode, model akan melakukan "Spec-writing" terlebih dahulu—yaitu desain arsitektur dan dekomposisi tugas—kemudian mengeksekusinya dengan efisien, alih-alih melakukan coba-coba secara membabi buta.
Keunggulan Unik Kemampuan Pengodean Claude Opus 4.6
Meskipun tidak unggul dalam efisiensi biaya, Claude Opus 4.6 memiliki keunggulan yang tak tergantikan:
- Terminal-Bench 2.0: 65,4%, performa terdepan di industri untuk tugas pengodean kompleks di lingkungan terminal.
- OSWorld: 72,7%, kemampuan operasi komputer agen yang jauh melampaui kompetitor.
- MCP Atlas: 62,7%, kemampuan koordinasi alat skala besar nomor satu di industri.
- Context Window 1M: Versi Beta mendukung konteks 1 juta Token, tidak perlu melakukan segmentasi saat menangani basis kode (codebase) yang sangat besar.
- Adaptive Thinking: Mendukung 4 tingkat intensitas berpikir (low/medium/high/max), kedalaman penalaran dapat disesuaikan sesuai kebutuhan.
Dalam tugas-tugas yang membutuhkan penalaran mendalam, pemahaman konteks kode yang sangat panjang, atau tugas tingkat sistem yang sangat kompleks, Opus 4.6 tetap menjadi pilihan terkuat saat ini.
🎯 Saran Pemilihan: Kedua model memiliki keunggulannya masing-masing. Disarankan untuk melakukan pengujian langsung melalui platform APIYI apiyi.com. Platform ini mendukung MiniMax-M2.5 dan Claude Opus 4.6 secara bersamaan dengan panggilan antarmuka (interface) terpadu; Anda hanya perlu mengganti parameter model untuk melakukan verifikasi dengan cepat.
Rekomendasi Skenario Pemrograman MiniMax-M2.5 vs Opus 4.6
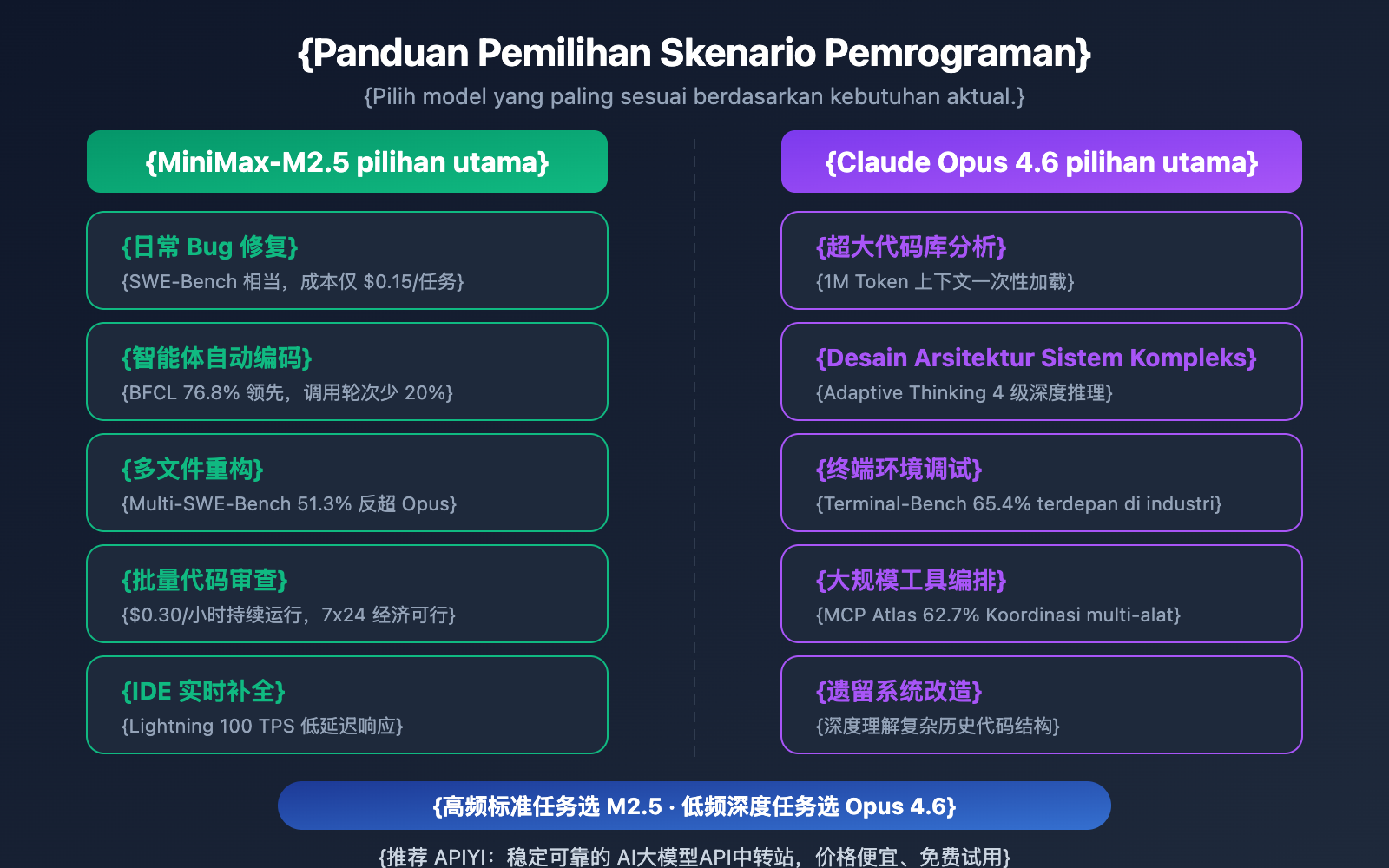
| Skenario Pemrograman | Model yang Direkomendasikan | Alasan Rekomendasi |
|---|---|---|
| Perbaikan Bug Harian | MiniMax-M2.5 | Setara SWE-Bench, biaya 20x lebih rendah |
| Refactoring Multi-file | MiniMax-M2.5 | Unggul 1% di Multi-SWE-Bench |
| Pengodean Agen Otomatis | MiniMax-M2.5 | Unggul 13,5% di BFCL, $0,15 per tugas |
| Code Review Massal | MiniMax-M2.5 | Throughput tinggi biaya rendah, versi standar $0,30/jam |
| Code Completion Real-time IDE | MiniMax-M2.5 Lightning | Latensi rendah 100 TPS |
| Analisis Basis Kode Raksasa | Claude Opus 4.6 | Context Window 1M Token |
| Desain Arsitektur Sistem Kompleks | Claude Opus 4.6 | Penalaran mendalam Adaptive Thinking |
| Operasi Kompleks Lingkungan Terminal | Claude Opus 4.6 | Unggul di Terminal-Bench dengan 65,4% |
| Orkestrasi Alat Skala Besar | Claude Opus 4.6 | Unggul di MCP Atlas dengan 62,7% |
Skenario Pemrograman Terbaik untuk MiniMax-M2.5
Keunggulan MiniMax-M2.5 terfokus pada tugas pemrograman yang "berfrekuensi tinggi, terstandarisasi, dan sensitif biaya":
- Perbaikan Otomatis CI/CD: Menjalankan agen secara terus-menerus untuk memantau dan memperbaiki pipeline. Biaya $0,30/jam membuatnya ekonomis untuk dijalankan 24/7.
- PR Review Bot: Meninjau Pull Request secara otomatis. Skor BFCL 76,8% memastikan interaksi alat multi-putaran yang akurat.
- Pengembangan Full-stack Multi-bahasa: Mendukung 10+ bahasa pemrograman (Python, Go, Rust, TypeScript, Java, dll.), mencakup Web/Android/iOS/Windows.
- Migrasi Kode Massal: Memanfaatkan kemampuan kolaborasi multi-file 51,3% dari Multi-SWE-Bench untuk menangani refactoring skala besar.
Skenario Pemrograman Terbaik untuk Claude Opus 4.6
Keunggulan Claude Opus 4.6 terfokus pada tugas pemrograman yang "berfrekuensi rendah, kompleksitas tinggi, dan penalaran mendalam":
- Asisten Keputusan Arsitektur: Menggunakan Adaptive Thinking (mode max) untuk analisis solusi teknis yang mendalam.
- Transformasi Sistem Legacy: Memuat seluruh basis kode besar sekaligus dengan konteks 1M Token.
- Debugging Tingkat Sistem: Skor Terminal-Bench 65,4% untuk melacak dan menyelesaikan masalah sistem yang kompleks di lingkungan terminal.
- Platform Orkestrasi Multi-alat: Skor MCP Atlas 62,7% untuk mengoordinasikan IDE, Git, CI/CD, pemantauan, dan berbagai alat lainnya secara sinergis.
Catatan Perbandingan: Rekomendasi skenario di atas didasarkan pada data benchmark dan umpan balik pengembang nyata. Hasil aktual untuk proyek yang berbeda mungkin bervariasi. Disarankan untuk melakukan verifikasi skenario nyata melalui APIYI apiyi.com.
Perbandingan Biaya Pemrograman Menyeluruh: MiniMax-M2.5 vs Opus 4.6
Bagi tim pengembang, biaya jangka panjang dari asisten pemrograman AI adalah faktor kunci dalam pengambilan keputusan.
| Skenario Biaya | MiniMax-M2.5 Standar | MiniMax-M2.5 Lightning | Claude Opus 4.6 |
|---|---|---|---|
| Harga Input/M tokens | $0.15 | $0.30 | $5.00 |
| Harga Output/M tokens | $1.20 | $2.40 | $25.00 |
| Satu tugas SWE-Bench | ~$0.15 | ~$0.30 | ~$3.00 |
| Berjalan terus-menerus 1 jam | $0.30 | $1.00 | ~$30+ |
| Berjalan 24/7 per bulan | ~$216 | ~$720 | ~$21,600+ |
| Jumlah tugas dengan anggaran $100 | ~328 tugas | ~164 tugas | ~30 tugas |
Sebagai contoh untuk tim pengembang skala menengah: Jika setiap hari perlu menangani 50 tugas pengkodean (perbaikan bug, peninjauan kode, implementasi fitur), biaya bulanan menggunakan MiniMax-M2.5 versi Standar adalah sekitar $225, versi Lightning sekitar $450, sedangkan Claude Opus 4.6 membutuhkan sekitar $4,500. Kualitas penyelesaian tugas dari ketiganya hampir sama pada level SWE-Bench.
🎯 Saran Biaya: Untuk sebagian besar tugas pemrograman standar, keunggulan rasio performa-harga (value for money) MiniMax-M2.5 sangat jelas. Disarankan untuk memilih setelah melakukan pengujian nyata melalui platform APIYI (apiyi.com). Platform ini mendukung peralihan model yang fleksibel tanpa perlu mengubah arsitektur kode. Anda juga bisa menikmati harga yang lebih hemat dengan mengikuti promo pengisian saldo.
Integrasi Cepat Pemrograman: MiniMax-M2.5 vs Opus 4.6
Kode berikut menunjukkan cara beralih dengan cepat di antara kedua model melalui antarmuka terpadu untuk perbandingan:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Uji MiniMax-M2.5
m25_response = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": "Implementasikan LRU cache yang aman secara konkuren menggunakan Go"}]
)
# Uji Claude Opus 4.6 - Cukup ganti parameter model
opus_response = client.chat.completions.create(
model="claude-opus-4-6-20250205",
messages=[{"role": "user", "content": "Implementasikan LRU cache yang aman secara konkuren menggunakan Go"}]
)
Lihat kode pengujian perbandingan lengkap
from openai import OpenAI
import time
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model_name: str, prompt: str) -> dict:
"""
Menguji kemampuan pengkodean pada satu model
Args:
model_name: ID Model
prompt: Petunjuk tugas pengkodean
Returns:
Dictionary yang berisi konten respons dan waktu yang dihabiskan
"""
start = time.time()
response = client.chat.completions.create(
model=model_name,
messages=[
{"role": "system", "content": "Anda adalah seorang software engineer senior"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
elapsed = time.time() - start
return {
"model": model_name,
"content": response.choices[0].message.content,
"tokens": response.usage.completion_tokens,
"time": round(elapsed, 2)
}
# Tugas pengkodean
task = "Refaktor fungsi berikut agar mendukung keamanan konkuren, kontrol timeout, dan graceful degradation"
# Pengujian perbandingan
models = ["MiniMax-M2.5", "MiniMax-M2.5-Lightning", "claude-opus-4-6-20250205"]
for m in models:
result = benchmark_model(m, task)
print(f"[{result['model']}] {result['tokens']} tokens dalam {result['time']} detik")
Saran: Melalui satu API Key dari APIYI (apiyi.com), Anda dapat mengakses MiniMax-M2.5 dan Claude Opus 4.6 secara bersamaan untuk membandingkan perbedaan performa keduanya dalam skenario pengkodean nyata Anda dengan cepat.
Pertanyaan yang Sering Diajukan
Q1: Apakah MiniMax-M2.5 bisa sepenuhnya menggantikan Claude Opus 4.6 untuk pemrograman?
Tidak sepenuhnya, tetapi bisa di sebagian besar skenario. Selisih skor SWE-Bench hanya 0,6%, bahkan M2.5 unggul 1% di Multi-SWE-Bench. Untuk tugas standar seperti perbaikan bug harian, peninjauan kode, dan implementasi fitur, hampir tidak ada perbedaan di antara keduanya. Namun, dalam skenario analisis basis kode super besar (membutuhkan konteks 1M) atau debugging tingkat sistem yang kompleks (Terminal-Bench), Opus 4.6 masih memiliki keunggulan. Disarankan untuk menggunakan keduanya secara campuran sesuai dengan kebutuhan skenario nyata.
Q2: Mengapa skor BFCL M2.5 jauh lebih tinggi dari Opus 4.6, tetapi skor pengodeannya hampir sama?
BFCL menguji kemampuan pemanggilan alat multi-putaran (Function Calling), sedangkan SWE-Bench menguji kemampuan pengodean end-to-end. Meskipun pemanggilan alat satu putaran Opus 4.6 tidak seakurat M2.5, kemampuan penalaran mendalamnya yang kuat menutupi kurangnya efisiensi pemanggilan alat, sehingga kualitas pengodean secara keseluruhan tetap mendekati. Namun, dalam skenario pemrograman otomatis berbasis agen, skor BFCL M2.5 yang tinggi berarti putaran pemanggilan yang lebih sedikit dan total biaya yang lebih rendah.
Q3: Bagaimana cara membandingkan efek pemrograman kedua model dengan cepat?
Direkomendasikan untuk melakukan pengujian perbandingan melalui APIYI apiyi.com:
- Daftar akun dan dapatkan API Key.
- Gunakan contoh kode dalam artikel ini untuk memanggil kedua model pada tugas pengodean yang sama.
- Bandingkan kualitas kode yang dihasilkan, kecepatan respons, dan konsumsi Token.
- Antarmuka yang kompatibel dengan OpenAI, cukup ubah parameter
modeluntuk beralih model.
Kesimpulan
Berikut adalah kesimpulan utama perbandingan kemampuan pemrograman MiniMax-M2.5 dengan Claude Opus 4.6:
- Kualitas pengodean hampir setara: SWE-Bench 80,2% vs 80,8%, selisih hanya 0,6%; M2.5 bahkan unggul 1% di Multi-SWE-Bench.
- Pemanggilan alat M2.5 unggul jauh: BFCL 76,8% vs 63,3%, M2.5 menjadi pilihan utama untuk skenario pemrograman berbasis agen.
- Perbedaan biaya yang sangat besar: $0,15 per tugas untuk M2.5 vs $3,00 untuk Opus. Dengan anggaran yang sama, Anda bisa menyelesaikan tugas 10 kali lipat lebih banyak.
- Opus 4.6 tak tergantikan dalam tugas mendalam: Masih memiliki keunggulan dalam skenario konteks 1M, Terminal-Bench, dan MCP Atlas.
Untuk sebagian besar tugas pemrograman harian, MiniMax-M2.5 menawarkan kualitas pengodean yang mendekati Opus 4.6 dengan rasio performa-harga yang jauh lebih baik. Disarankan untuk melakukan verifikasi perbandingan dalam proyek nyata melalui APIYI apiyi.com. Platform ini mendukung pemanggilan antarmuka terpadu untuk kedua model, dan Anda juga bisa mengikuti promo pengisian saldo untuk mendapatkan penawaran menarik.
📚 Referensi
⚠️ Catatan Format Tautan: Semua tautan luar menggunakan format
Nama Referensi: domain.comagar mudah disalin tetapi tidak dapat diklik secara langsung, guna menghindari hilangnya bobot SEO.
-
Pengumuman Resmi MiniMax M2.5: Detail kemampuan inti dan benchmark pengodean M2.5
- Tautan:
minimax.io/news/minimax-m25 - Keterangan: Berisi data lengkap SWE-Bench, Multi-SWE-Bench, BFCL, dll.
- Tautan:
-
Rilis Resmi Claude Opus 4.6: Detail teknis Opus 4.6 yang dirilis oleh Anthropic
- Tautan:
anthropic.com/news/claude-opus-4-6 - Keterangan: Penjelasan kemampuan Terminal-Bench, MCP Atlas, Adaptive Thinking, dll.
- Tautan:
-
Evaluasi OpenHands M2.5: Evaluasi pengodean nyata M2.5 oleh platform pengembang independen
- Tautan:
openhands.dev/blog/minimax-m2-5-open-weights-models-catch-up-to-claude - Keterangan: Analisis pengujian nyata model open-source pertama yang melampaui Claude Sonnet.
- Tautan:
-
Perbandingan Mendalam VentureBeat: Analisis rasio performa-harga antara M2.5 dan Opus 4.6
- Tautan:
venturebeat.com/technology/minimaxs-new-open-m2-5-and-m2-5-lightning-near-state-of-the-art-while - Keterangan: Analisis perbedaan efisiensi biaya keduanya dari perspektif perusahaan.
- Tautan:
-
Analisis Benchmark Vellum Opus 4.6: Interpretasi pengujian benchmark komprehensif Claude Opus 4.6
- Tautan:
vellum.ai/blog/claude-opus-4-6-benchmarks - Keterangan: Analisis mendalam tentang benchmark pengodean inti seperti Terminal-Bench, SWE-Bench, dll.
- Tautan:
Penulis: APIYI Team
Diskusi Teknis: Jangan ragu untuk membagikan hasil pengujian perbandingan model Anda di kolom komentar. Untuk tutorial integrasi model pemrograman AI lainnya, silakan kunjungi komunitas teknis APIYI apiyi.com.