ملاحظة المؤلف: قراءة عميقة للمحتوى الأساسي للورقة التقنية لـ Kimi K2.5، شرح مفصل لمعمارية MoE ذات الـ 1T معلمة، وتكوين الـ 384 خبيراً، وآلية انتباه MLA، مع تقديم متطلبات الأجهزة للنشر المحلي ومقارنة حلول الوصول عبر واجهة برمجة التطبيقات (API).
هل تريد معرفة التفاصيل التقنية لـ Kimi K2.5؟ تستند هذه المقالة إلى الورقة التقنية الرسمية لـ Kimi K2.5، لتقدم قراءة منظمة لمعمارية MoE ذات تريليون معلمة، وطرق التدريب، ونتائج الاختبارات المعيارية، مع توضيح مفصل لمتطلبات الأجهزة للنشر المحلي.
القيمة الأساسية: بعد قراءة هذا المقال، ستتقن المعلمات التقنية الأساسية لـ Kimi K2.5، ومبادئ تصميم المعمارية، وستمتلك القدرة على اختيار أفضل خطة نشر بناءً على إمكانيات الأجهزة المتوفرة لديك.
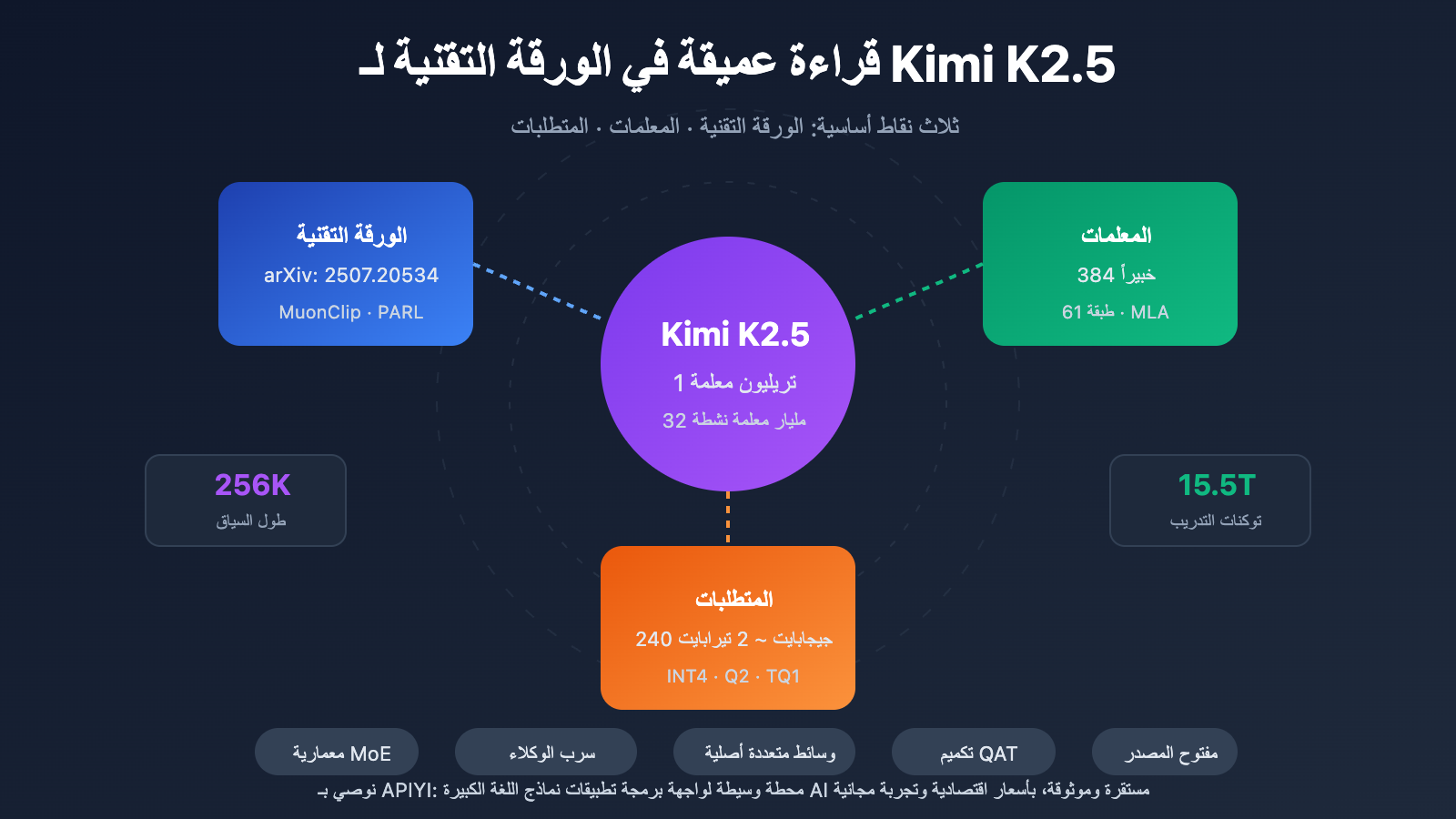
النقاط الأساسية في الورقة التقنية لـ Kimi K2.5
| النقاط الأساسية | التفاصيل التقنية | القيمة الابتكارية |
|---|---|---|
| MoE بترليون معلمة | إجمالي المعلمات 1T، المعلمات النشطة 32B | كفاءة عالية للغاية مع تنشيط 3.2% فقط أثناء الاستنتاج |
| نظام 384 خبيراً | اختيار 8 خبراء + خبير واحد مشترك لكل رمز (Token) | خبراء أكثر بنسبة 50% من DeepSeek-V3 |
| انتباه MLA | انتباه كامن متعدد الرؤوس (Multi-head Latent Attention) | تقليل ذاكرة KV Cache، ودعم سياق يصل إلى 256K |
| مُحسّن MuonClip | تدريب عالي الكفاءة للرموز، انعدام قفزات الخسارة | تدريب على 15.5T رمز بدون أي قفزات في الخسارة (Loss Spike) |
| وسائط متعددة أصلية | مشفر بصري MoonViT بـ 400M معلمة | تدريب هجين بصري-نصي على 15T رمز |
خلفية الورقة البحثية لـ Kimi K2.5
تم إصدار الورقة التقنية لـ Kimi K2.5 من قبل فريق "Moonshot AI" (Yuezhi Anmian)، وهي تحمل الرقم 2507.20534 في أرشيف arXiv. توضح الورقة بالتفصيل التطور التقني من Kimi K2 إلى K2.5، وتشمل المساهمات الأساسية ما يلي:
- بنية MoE فائقة الندرة: إعداد 384 خبيراً، وهو ما يزيد بنسبة 50% عن الـ 256 خبيراً في DeepSeek-V3.
- تحسين التدريب عبر MuonClip: حل مشكلة قفزات الخسارة (Loss Spike) في التدريب واسع النطاق.
- نموذج Agent Swarm: طريقة تدريب PARL (التعلم التعزيزي المتوازي للوكلاء).
- دمج الوسائط المتعددة الأصلي: دمج قدرات الرؤية واللغة منذ مرحلة ما قبل التدريب.
تشير الورقة إلى أنه مع تزايد ندرة البيانات البشرية عالية الجودة، أصبحت كفاءة الرموز (Token Efficiency) عاملاً حاسماً في توسيع نطاق نماذج اللغة الكبيرة، مما دفع إلى استخدام مُحسّن Muon وتوليد البيانات الاصطناعية.
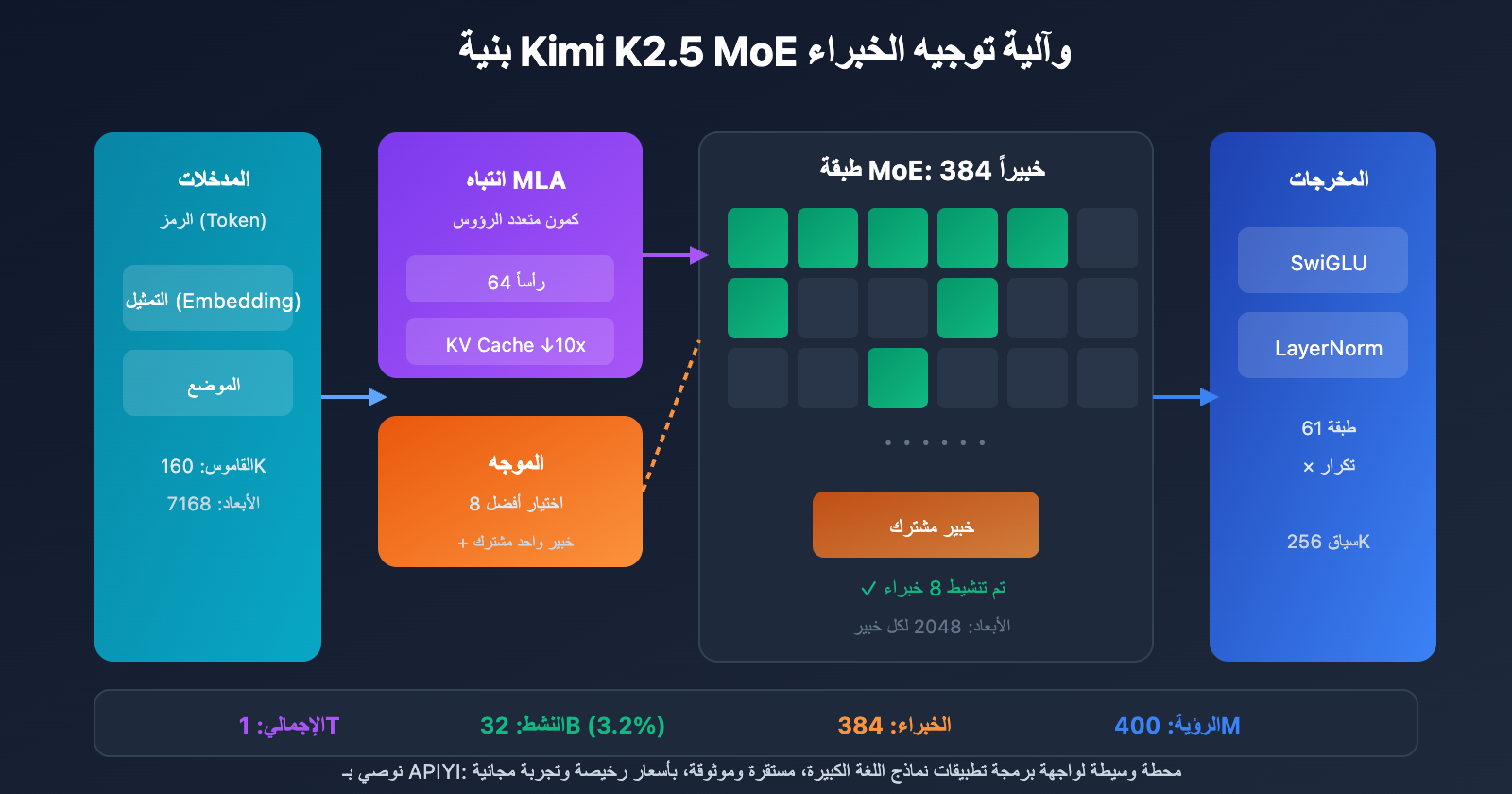
المواصفات الكاملة لمعلمات Kimi K2.5
معلمات الهيكل الأساسي
| فئة المعلمة | اسم المعلمة | القيمة | التوضيح |
|---|---|---|---|
| الحجم | إجمالي عدد المعلمات | 1T (1.04 تريليون) | الحجم الكامل للنموذج |
| الحجم | المعلمات النشطة | 32B | المستخدمة فعلياً في عملية الاستنتاج الواحدة |
| الهيكل | عدد الطبقات | 61 طبقة | تتضمن طبقة كثيفة (Dense) واحدة |
| الهيكل | الأبعاد المخفية | 7168 | أبعاد العمود الفقري للنموذج |
| MoE | عدد الخبراء | 384 | أكثر بـ 128 خبيراً من DeepSeek-V3 |
| MoE | الخبراء النشطون | 8 + 1 مشترك | اختيار التوجيه من نوع Top-8 |
| MoE | الأبعاد المخفية للخبراء | 2048 | أبعاد FFN لكل خبير |
| الانتباه | عدد رؤوس الانتباه | 64 | نصف عدد رؤوس DeepSeek-V3 |
| الانتباه | نوع الآلية | MLA | انتباه كامن متعدد الرؤوس (Multi-head Latent Attention) |
| أخرى | حجم القاموس | 160K | يدعم لغات متعددة |
| أخرى | طول السياق | 256K | معالجة المستندات الطويلة جداً |
| أخرى | دالة التنشيط | SwiGLU | تحويل غير خطي عالي الكفاءة |
قراءة في تصميم معلمات Kimi K2.5
لماذا تم اختيار 384 خبيراً؟
أظهر تحليل قانون التوسع (Scaling Law) في الورقة البحثية أن الزيادة المستمرة في "التشتت" (Sparsity) تؤدي إلى تحسن ملحوظ في الأداء. قام الفريق بزيادة عدد الخبراء من 256 في DeepSeek-V3 إلى 384، مما عزز قدرة النموذج على التمثيل.
لماذا تم تقليل رؤوس الانتباه؟
بهدف خفض التكاليف الحسابية أثناء الاستنتاج، تم تقليل عدد رؤوس الانتباه من 128 إلى 64. وبالتكامل مع آلية MLA، ينجح هذا التصميم في تقليل استهلاك الذاكرة لـ KV Cache بشكل كبير مع الحفاظ على الأداء.
مزايا آلية الانتباه MLA:
MHA التقليدي: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = عدد الطبقات, H = عدد الرؤوس, D = الأبعاد, B = الدفعة (Batch), C = أبعاد الضغط
من خلال ضغط الفضاء الكامن، تقلل آلية MLA من حجم KV Cache بحوالي 10 مرات، مما يجعل التعامل مع سياق بطول 256K أمراً ممكناً.
معلمات المشفر البصري (Vision Encoder)
| المكون | المعلمة | القيمة |
|---|---|---|
| الاسم | MoonViT | مشفر بصري مطور ذاتياً |
| عدد المعلمات | – | 400M |
| المميزات | تجميع مكاني وزماني | دعم فهم الفيديو |
| طريقة التكامل | دمج أصلي | مدمج في مرحلة التدريب المسبق |
متطلبات تشغيل Kimi K2.5 (Hardware Requirements)
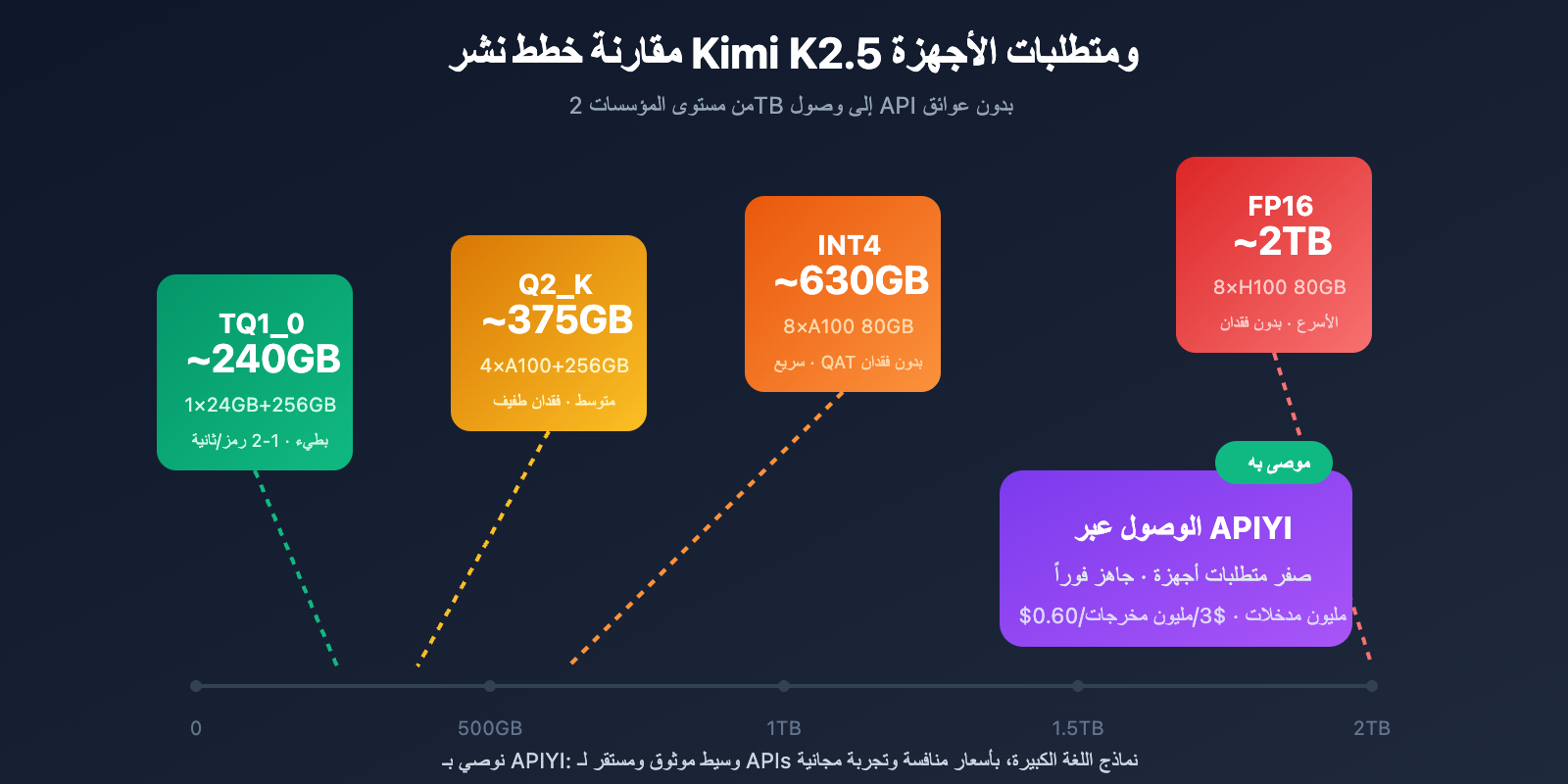
متطلبات الأجهزة للنشر المحلي
| دقة التكميم | متطلبات التخزين | الحد الأدنى من الأجهزة | سرعة الاستنتاج | فقدان الدقة |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | الأسرع | لا يوجد |
| INT4 (QAT) | ~630GB | 8×A100 80GB | سريع | تقريباً بدون فقدان |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | متوسط | طفيف |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | بطيء (1-2 رمز/ث) | ملحوظ |
تفاصيل متطلبات Kimi K2.5
النشر على مستوى المؤسسات (موصى به)
تكوين الأجهزة: 2× NVIDIA H100 80GB أو 8× A100 80GB
متطلبات التخزين: +630GB (تكميم INT4)
الأداء المتوقع: 50-100 رمز/ثانية
سيناريوهات الاستخدام: بيئات الإنتاج، الخدمات ذات الكثافة العالية
النشر بضغط أقصى
تكوين الأجهزة: 1× RTX 4090 24GB + 256GB ذاكرة النظام
متطلبات التخزين: 240GB (تكميم 1.58-bit)
الأداء المتوقع: 1-2 رمز/ثانية
سيناريوهات الاستخدام: الاختبارات البحثية، التحقق من الوظائف
ملاحظة: يتم تحميل طبقات MoE بالكامل على RAM، مما يجعل السرعة بطيئة
لماذا نحتاج إلى كل هذه الذاكرة؟
على الرغم من أن هيكل MoE ينشط 32B معلمة فقط في كل استنتاج، إلا أن النموذج يحتاج للحفاظ على الـ 1T معلمة كاملة في الذاكرة ليتمكن من توجيه المدخلات ديناميكياً إلى الخبراء المناسبين. هذه خاصية جوهرية في نماذج MoE.
الحل الأكثر عملية: الوصول عبر API
بالنسبة لغالبية المطورين، تعتبر عتبة الأجهزة للنشر المحلي لـ Kimi K2.5 مرتفعة جداً. يعد الوصول عبر API خياراً أكثر واقعية:
| الخيار | التكلفة | المزايا |
|---|---|---|
| APIYI (موصى به) | $0.60/M مدخلات، $3/M مخرجات | واجهة موحدة، تبديل بين نماذج متعددة، رصيد مجاني |
| الـ API الرسمي | نفس التكلفة | كامل الوظائف، تحديثات فورية |
| تكميم 1-bit محلي | تكلفة الأجهزة + الكهرباء | توطين البيانات |
نصيحة للنشر: ما لم تكن هناك متطلبات صارمة لتوطين البيانات، ننصح بالوصول إلى Kimi K2.5 عبر APIYI (apiyi.com) لتجنب الاستثمارات الباهظة في الأجهزة.
نتائج اختبارات القياس الخاصة بورقة Kimi K2.5 البحثية
تقييم القدرات الجوهرية
| اختبار القياس | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | الوصف |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | مسابقات الرياضيات (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | مسابقات الرياضيات (avg@32) |
| GPQA-Diamond | 87.6% | – | – | الاستنتاج العلمي (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | إصلاح الأكواد |
| SWE-Bench Multi | 73.0% | – | – | أكواد متعددة اللغات |
| HLE-Full | 50.2% | – | – | الاستنتاج الشامل (باستخدام الأدوات) |
| BrowseComp | 60.2% | 54.9% | 24.1% | التفاعل مع صفحات الويب |
| MMMU-Pro | 78.5% | – | – | الفهم متعدد الوسائط |
| MathVision | 84.2% | – | – | الرياضيات البصرية |
بيانات وطرق التدريب
| المرحلة | كمية البيانات | الطريقة |
|---|---|---|
| التدريب المسبق لنموذج K2 الأساسي | 15.5T tokens | مُحسّن MuonClip، صفر ارتفاع مفاجئ في الخسارة (Loss Spike) |
| مواصلة التدريب المسبق لـ K2.5 | 15T مزيج نصوص وصور | دمج أصيل متعدد الوسائط |
| تدريب الوكيل (Agent) | – | PARL (التعلم التعزيزي المتوازي للوكلاء) |
| التدريب على التكميم | – | QAT (التدريب الواعي بالتكميم) |
تؤكد الورقة البحثية بشكل خاص أن مُحسّن MuonClip جعل عملية التدريب المسبق لـ 15.5 تريليون رمز (Token) بالكامل تخلو تماماً من أي "Loss Spike" (ارتفاع مفاجئ في الخسارة)، وهو ما يُعد اختراقاً تقنياً مهماً في تدريب النماذج ذات نطاق تريليونات المعلمات.
مثال على الوصول السريع لـ Kimi K2.5
كود استدعاء بسيط للغاية
عبر منصة APIYI، يمكنك استدعاء Kimi K2.5 بـ 10 أسطر برمجية فقط:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "解释 MoE 架构的工作原理"}]
)
print(response.choices[0].message.content)
عرض كود استدعاء نمط التفكير (Thinking Mode)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 模式 - 深度推理
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "你是 Kimi,请详细分析问题"},
{"role": "user", "content": "证明根号2是无理数"}
],
temperature=1.0, # Thinking 模式推荐
top_p=0.95,
max_tokens=8192
)
# 获取推理过程和最终答案
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"推理过程:\n{reasoning}\n")
print(f"最终答案:\n{answer}")
نصيحة: احصل على رصيد اختبار مجاني عبر APIYI (apiyi.com) لتجربة قدرات الاستنتاج العميق لنموذج Kimi K2.5 في نمط التفكير (Thinking Mode).
الأسئلة الشائعة
س1: أين يمكنني الحصول على الورقة البحثية التقنية (Paper) لـ Kimi K2.5؟
تم نشر الورقة التقنية الرسمية لسلسلة Kimi K2 على arXiv تحت الرقم 2507.20534 ويمكن الوصول إليها عبر الرابط arxiv.org/abs/2507.20534. أما التقرير التقني لنموذج Kimi K2.5 فقد نُشر على المدونة الرسمية في kimi.com/blog/kimi-k2-5.html.
س2: ما هي أدنى المتطلبات (Requirements) لتشغيل Kimi K2.5 محلياً؟
تتطلب خطة الضغط القصوى: بطاقة رسومية (GPU) بذاكرة فيديو 24 جيجابايت + ذاكرة نظام 256 جيجابايت + مساحة تخزين 240 جيجابايت. ولكن في ظل هذا الإعداد، ستكون سرعة الاستنتاج حوالي 1-2 توكن في الثانية فقط. الإعداد الموصى به هو بطاقتي H100 أو 8 بطاقات A100، مع استخدام تكميم (Quantization) من نوع INT4 للوصول إلى أداء مناسب لمستوى الإنتاج.
س3: كيف يمكنني التحقق من قدرات Kimi K2.5 بسرعة؟
لا حاجة للنشر المحلي، يمكنك الاختبار بسرعة عبر واجهة برمجة التطبيقات (API):
- قم بزيارة موقع APIYI (apiyi.com) وسجل حساباً جديداً.
- احصل على مفتاح API ورصيد مجاني.
- استخدم أمثلة الأكواد البرمجية المذكورة في هذا المقال، مع كتابة
kimi-k2.5في حقل اسم النموذج. - استكشف قدرات الاستنتاج العميق في وضع التفكير (Thinking mode).
الخلاصة
أبرز النقاط الواردة في الورقة البحثية لـ Kimi K2.5:
- الابتكار الأساسي في Kimi K2.5: بنية MoE بـ 384 خبيراً + آلية انتباه MLA + مُحسّن MuonClip، مما مكّن من تدريب نموذج بترليون معلمة بنجاح دون فقدان في الجودة وبكفاءة عالية.
- المعلمات الرئيسية (Parameters) لـ Kimi K2.5: إجمالي المعلمات 1T، والمعلمات النشطة 32B، مع 61 طبقة، وسياق يصل إلى 256K؛ حيث يتم تنشيط 3.2% فقط من المعلمات في كل عملية استنتاج.
- متطلبات التشغيل (Requirements): عتبة التشغيل المحلي مرتفعة جداً (تتطلب مساحة تخزين 240 جيجابايت فأكثر)، لذا يُعد الوصول عبر الـ API هو الخيار الأكثر واقعية وعملية.
نموذج Kimi K2.5 متاح الآن على منصة APIYI (apiyi.com). نقترح عليك تجربة قدرات النموذج بسرعة عبر الـ API لتقييم مدى ملاءمته لاحتياجات عملك.
المراجع
⚠️ توضيح تنسيق الروابط: جميع الروابط الخارجية تستخدم تنسيق
اسم المرجع: domain.comلتسهيل النسخ ومنع الانتقال المباشر عبر النقر، وذلك لتجنب فقدان قوة تحسين محركات البحث (SEO).
-
ورقة بحث Kimi K2 على arXiv: التقرير التقني الرسمي، يشرح بالتفصيل البنية وطرق التدريب
- الرابط:
arxiv.org/abs/2507.20534 - الوصف: للحصول على التفاصيل التقنية الكاملة والبيانات التجريبية
- الرابط:
-
مدونة Kimi K2.5 التقنية: التقرير التقني الصادر رسميًا حول K2.5
- الرابط:
kimi.com/blog/kimi-k2-5.html - الوصف: للتعرف على أسراب الوكلاء (Agent Swarm) والقدرات متعددة الوسائط
- الرابط:
-
بطاقة نموذج HuggingFace: أوزان النموذج وتعليمات الاستخدام
- الرابط:
huggingface.co/moonshotai/Kimi-K2.5 - الوصف: لتنزيل أوزان النموذج والاطلاع على دليل النشر
- الرابط:
-
دليل Unsloth للنشر المحلي: برامج تعليمية مفصلة حول النشر المكمم
- الرابط:
unsloth.ai/docs/models/kimi-k2.5 - الوصف: للتعرف على متطلبات الأجهزة لمختلف مستويات دقة التكميم (Quantization)
- الرابط:
المؤلف: الفريق التقني
التبادل التقني: نرحب بمناقشة التفاصيل التقنية لـ Kimi K2.5 في قسم التعليقات. لمزيد من شروحات النماذج، يمكنك زيارة المجتمع التقني APIYI عبر الموقع apiyi.com