Anmerkung des Autors: Tiefgehende Analyse der Kerninhalte des Kimi K2.5 Technical Papers, detaillierte Erläuterung der 1T-Parameter MoE-Architektur, der Konfiguration mit 384 Experten, des MLA-Attention-Mechanismus sowie Bereitstellung der Hardwareanforderungen für das lokale Deployment und eines Vergleichs von API-Anbindungslösungen.
Möchten Sie die technischen Details von Kimi K2.5 verstehen? Dieser Artikel basiert auf dem offiziellen Kimi K2.5 Technical Paper und bietet eine systematische Interpretation der Billionen-Parameter MoE-Architektur, der Trainingsmethoden und Benchmark-Ergebnisse sowie detaillierte Hardwareanforderungen für die lokale Bereitstellung.
Kernwert: Nach der Lektüre dieses Artikels werden Sie die zentralen technischen Parameter von Kimi K2.5, die Prinzipien des Architekturdesigns und die Fähigkeit beherrschen, die optimale Deployment-Lösung basierend auf Ihren Hardwarebedingungen auszuwählen.
Kernpunkte des Kimi K2.5 Technical Papers
| Punkt | Technische Details | Innovationswert |
|---|---|---|
| Billionen-Parameter-MoE | 1T Gesamtparameter, 32B aktivierte Parameter | Nur 3,2 % bei Inferenz aktiviert, extrem effizient |
| 384-Expertensystem | 8 Experten pro Token + 1 gemeinsamer Experte | 50 % mehr Experten als DeepSeek-V3 |
| MLA Attention | Multi-head Latent Attention | Reduziert KV-Cache, unterstützt 256K Kontext |
| MuonClip Optimizer | Token-effizientes Training, keine Loss Spikes | 15,5T Token Training ohne Verlustspitzen |
| Nativ Multimodal | MoonViT 400M Vision-Encoder | 15T gemischtes Vision-Text-Training |
Hintergrund des Kimi K2.5 Papers
Das Kimi K2.5 Technical Paper wurde vom Team von Moonshot AI veröffentlicht (arXiv-Nummer 2507.20534). Das Paper beschreibt detailliert die technische Evolution von Kimi K2 zu K2.5. Die zentralen Beiträge umfassen:
- Supersparse MoE-Architektur: Konfiguration mit 384 Experten, was 50 % mehr ist als die 256 Experten von DeepSeek-V3.
- MuonClip Trainingsoptimierung: Lösung der Loss-Spike-Problematik bei大规模 Training.
- Agent Swarm Paradigma: PARL (Parallel-Agent Reinforcement Learning) Trainingsmethode.
- Native multimodale Fusion: Integration von Vision-Language-Fähigkeiten bereits ab der Pre-Training-Phase.
Das Paper stellt fest, dass mit zunehmender Knappheit hochwertiger menschlicher Daten die Token-Effizienz zum entscheidenden Faktor für die Skalierung von Großen Sprachmodellen wird, was den Einsatz des Muon-Optimierers und der Generierung synthetischer Daten vorangetrieben hat.
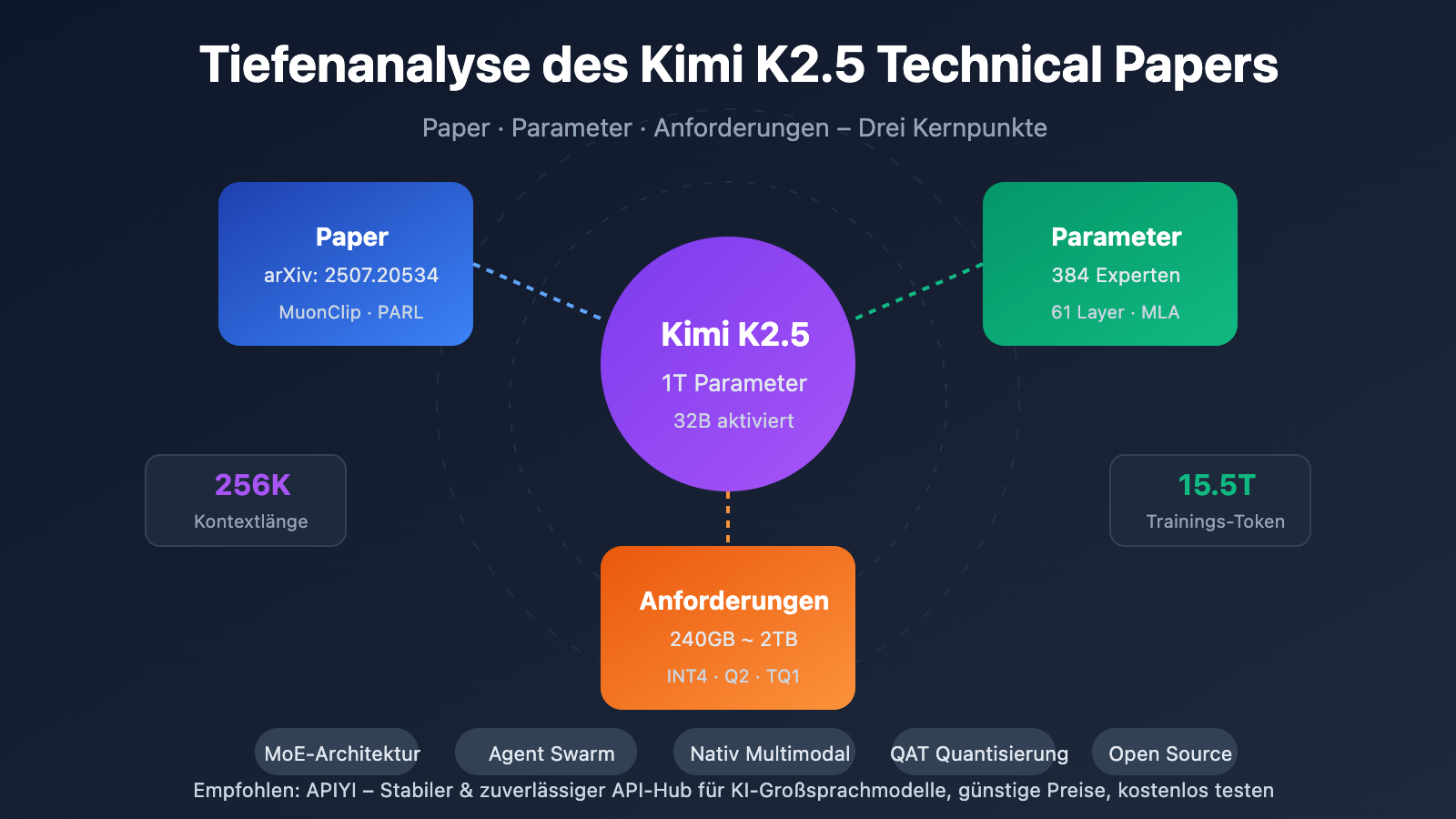
Kimi K2.5 Parameters 完整参数规格
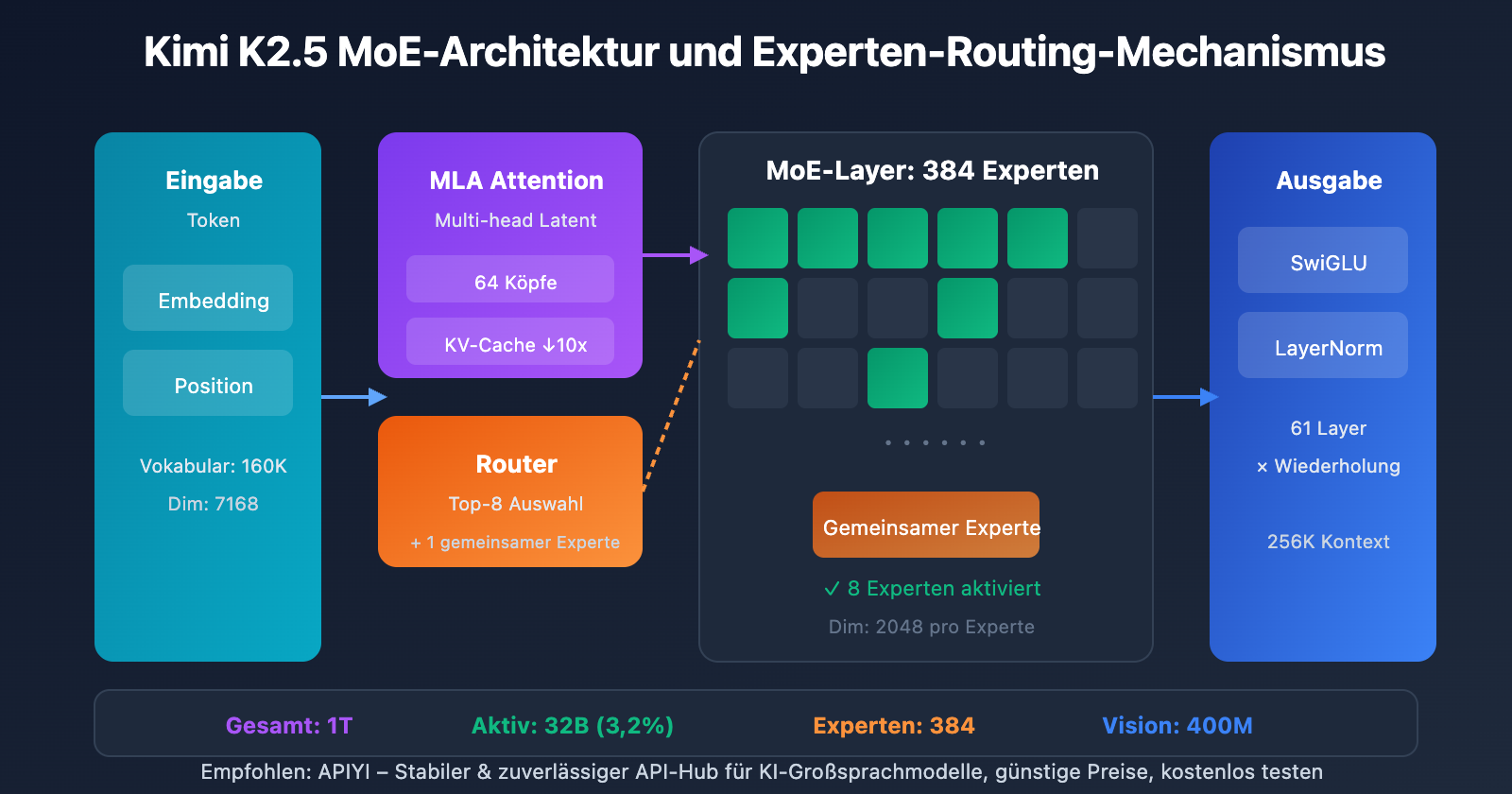
核心架构参数
| 参数类别 | 参数名 | 数值 | 说明 |
|---|---|---|---|
| 规模 | 总参数量 | 1T (1.04 万亿) | 完整模型大小 |
| 规模 | 激活参数 | 32B | 单次推理实际使用 |
| 结构 | 层数 | 61 层 | 含 1 个 Dense 层 |
| 结构 | 隐藏维度 | 7168 | 模型主干维度 |
| MoE | 专家数量 | 384 | 比 DeepSeek-V3 多 128 |
| MoE | 激活专家 | 8 + 1 共享 | Top-8 路由选择 |
| MoE | 专家隐藏维度 | 2048 | 每个专家的 FFN 维度 |
| 注意力 | 注意力头数 | 64 | 比 DeepSeek-V3 少一半 |
| 注意力 | 机制类型 | MLA | Multi-head Latent Attention |
| 其他 | 词汇表大小 | 160K | 支持多语言 |
| 其他 | 上下文长度 | 256K | 超长文档处理 |
| 其他 | 激活函数 | SwiGLU | 高效非线性变换 |
Kimi K2.5 Parameters 设计解读
为什么选择 384 专家?
论文中的 Scaling Law 分析表明,持续增加稀疏性能带来显著的性能提升。团队将专家数从 DeepSeek-V3 的 256 增加到 384,提升了模型的表示能力。
为什么减少注意力头?
为了降低推理时的计算开销,注意力头数从 128 减少到 64。结合 MLA 机制,这一设计在保持性能的同时大幅减少了 KV Cache 的内存占用。
MLA 注意力机制优势:
传统 MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = 层数, H = 头数, D = 维度, B = Batch, C = 压缩维度
MLA 通过潜在空间压缩,将 KV Cache 减少约 10 倍,使 256K 上下文成为可能。
视觉编码器参数
| 组件 | 参数 | 数值 |
|---|---|---|
| 名称 | MoonViT | 自研视觉编码器 |
| 参数量 | – | 400M |
| 特性 | 时空池化 | 视频理解支持 |
| 集成方式 | 原生融合 | 预训练阶段整合 |
Kimi K2.5 Requirements 部署硬件要求
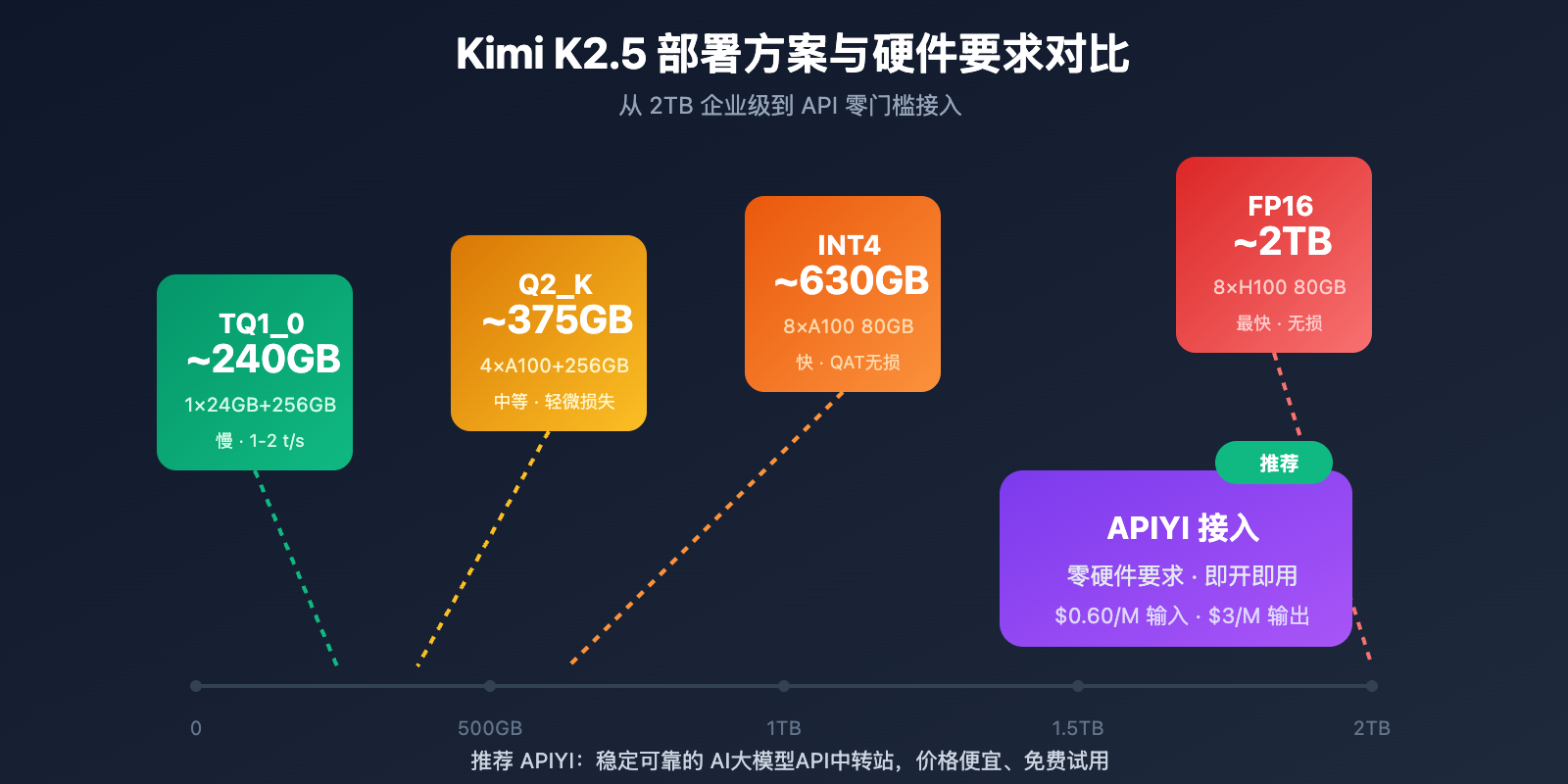
本地部署硬件需求
| 量化精度 | 存储需求 | 最低硬件 | 推理速度 | 精度损失 |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | 最快 | 无 |
| INT4 (QAT) | ~630GB | 8×A100 80GB | 快 | 几乎无损 |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | 中等 | 轻微 |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | 慢 (1-2 t/s) | 明显 |
Kimi K2.5 Requirements 详细说明
企业级部署 (推荐)
硬件配置: 2× NVIDIA H100 80GB 或 8× A100 80GB
存储需求: 630GB+ (INT4 量化)
预期性能: 50-100 tokens/s
适用场景: 生产环境、高并发服务
极限压缩部署
硬件配置: 1× RTX 4090 24GB + 256GB 系统内存
存储需求: 240GB (1.58-bit 量化)
预期性能: 1-2 tokens/s
适用场景: 研究测试、功能验证
注意事项: MoE 层完全卸载到 RAM,速度较慢
为什么需要这么多内存?
虽然 MoE 架构每次推理只激活 32B 参数,但模型需要将完整的 1T 参数保持在内存中,以便根据输入动态路由到正确的专家。这是 MoE 模型的固有特性。
更实用的方案:API 接入
对于大多数开发者,本地部署 Kimi K2.5 的硬件门槛较高。通过 API 接入是更实用的选择:
| 方案 | 成本 | 优势 |
|---|---|---|
| APIYI (推荐) | $0.60/M 输入,$3/M 输出 | 统一接口,多模型切换,免费额度 |
| 官方 API | 同上 | 功能最全,第一时间更新 |
| 本地 1-bit | 硬件成本 + 电费 | 数据本地化 |
部署建议:除非有严格的数据本地化要求,建议通过 APIYI apiyi.com 接入 Kimi K2.5,避免高昂的硬件投入。
Kimi K2.5 Paper Benchmark-Ergebnisse
Bewertung der Kernkompetenzen
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Erläuterung |
|---|---|---|---|---|
| AIME 2025 | 96,1 % | – | – | Mathematik-Wettbewerb (avg@32) |
| HMMT 2025 | 95,4 % | 93,3 % | – | Mathematik-Wettbewerb (avg@32) |
| GPQA-Diamond | 87,6 % | – | – | Wissenschaftliches Schlussfolgern (avg@8) |
| SWE-Bench Verified | 76,8 % | – | 80,9 % | Code-Fehlerbehebung |
| SWE-Bench Multi | 73,0 % | – | – | Mehrsprachiger Code |
| HLE-Full | 50,2 % | – | – | Umfassendes Schlussfolgern (mit Tools) |
| BrowseComp | 60,2 % | 54,9 % | 24,1 % | Web-Interaktion |
| MMMU-Pro | 78,5 % | – | – | Multimodales Verständnis |
| MathVision | 84,2 % | – | – | Visuelle Mathematik |
Trainingsdaten und -methoden
| Phase | Datenmenge | Methode |
|---|---|---|
| K2 Base Pre-Training | 15,5T Tokens | MuonClip-Optimierer, Null Loss Spikes |
| K2.5 Kontinuierliches Pre-Training | 15T Vision-Text-Mix | Native multimodale Fusion |
| Agent-Training | – | PARL (Paralleles Agent Reinforcement Learning) |
| Quantisierungs-Training | – | QAT (Quantization-Aware Training) |
Das Paper betont besonders, dass der MuonClip-Optimierer den gesamten Pre-Training-Prozess von 15,5T Tokens völlig ohne Loss Spikes ermöglichte. Dies stellt einen wichtigen Durchbruch beim Training von Modellen im Billionen-Parameter-Maßstab dar.
Kimi K2.5 Schnellstart-Beispiel
Minimalistischer Aufruf-Code
Über die Plattform APIYI lässt sich Kimi K2.5 mit nur 10 Zeilen Code aufrufen:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # Erhältlich unter apiyi.com
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "Erkläre die Funktionsweise der MoE-Architektur"}]
)
print(response.choices[0].message.content)
Aufruf-Code für den Thinking-Modus anzeigen
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking-Modus - Tiefgehendes Schlussfolgern
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "Du bist Kimi, bitte analysiere die Frage im Detail"},
{"role": "user", "content": "Beweise, dass die Wurzel aus 2 irrational ist"}
],
temperature=1.0, # Empfohlen für den Thinking-Modus
top_p=0.95,
max_tokens=8192
)
# Abrufen des Denkprozesses und der finalen Antwort
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"Denkprozess:\n{reasoning}\n")
print(f"Finale Antwort:\n{answer}")
Empfehlung: Sichern Sie sich über APIYI (apiyi.com) ein kostenloses Testkontingent, um die tiefgehenden Reasoning-Fähigkeiten des Thinking-Modus von Kimi K2.5 zu erleben.
Häufig gestellte Fragen (FAQ)
Q1: Wo ist das technische Paper (Technical Paper) zu Kimi K2.5 verfügbar?
Die offiziellen technischen Paper der Kimi K2-Serie sind auf arXiv unter der Nummer 2507.20534 veröffentlicht und über arxiv.org/abs/2507.20534 abrufbar. Der technische Bericht zu Kimi K2.5 wurde im offiziellen Blog unter kimi.com/blog/kimi-k2-5.html veröffentlicht.
Q2: Was sind die Mindestanforderungen (Requirements) für ein lokales Deployment von Kimi K2.5?
Für eine extrem komprimierte Lösung benötigen Sie: 1 Grafikkarte mit 24 GB VRAM + 256 GB Arbeitsspeicher + 240 GB Speicherplatz. In dieser Konfiguration beträgt die Inferenzgeschwindigkeit jedoch nur etwa 1-2 Tokens/s. Die empfohlene Konfiguration ist 2×H100 oder 8×A100; mit INT4-Quantisierung kann eine Performance auf Produktionsniveau erreicht werden.
Q3: Wie kann ich die Fähigkeiten von Kimi K2.5 schnell testen?
Ein lokales Deployment ist nicht zwingend erforderlich. Über die API lässt sich das Modell schnell testen:
- Besuchen Sie APIYI (apiyi.com) und registrieren Sie ein Konto.
- Erhalten Sie Ihren API-Key und ein kostenloses Startguthaben.
- Verwenden Sie das Code-Beispiel aus diesem Artikel und geben Sie als Modellnamen
kimi-k2.5an. - Erleben Sie die tiefgehenden Denkfähigkeiten im „Thinking“-Modus.
Fazit
Die Kernpunkte des technischen Papers zu Kimi K2.5 im Überblick:
- Zentrale Innovationen (Kimi K2.5 Paper): Eine MoE-Architektur mit 384 Experten + MLA-Attention + MuonClip-Optimierer ermöglichen ein verlustfreies Spitzen-Training für Modelle mit Billionen von Parametern.
- Wichtige Parameter (Kimi K2.5 Parameters): 1 Billion (1T) Gesamtparameter, 32 Milliarden (32B) aktivierte Parameter, 61 Layer, 256K Kontextfenster – bei jeder Inferenz werden lediglich 3,2 % der Parameter aktiviert.
- Bereitstellungsanforderungen (Kimi K2.5 Requirements): Die Hürden für ein lokales Deployment sind hoch (mindestens 240 GB+ Speicher), weshalb die API-Anbindung die praktischere Wahl darstellt.
Kimi K2.5 ist ab sofort auf APIYI (apiyi.com) verfügbar. Wir empfehlen, die Fähigkeiten des Modells schnell per API zu validieren, um zu prüfen, ob es für Ihre spezifischen Business-Szenarien geeignet ist.
Referenzen
⚠️ Hinweis zum Linkformat: Alle externen Links verwenden das Format
Name der Ressource: domain.com. Dies erleichtert das Kopieren, verhindert jedoch die direkte Verlinkung, um den SEO-Wert zu erhalten.
-
Kimi K2 arXiv Paper: Offizieller technischer Bericht mit detaillierter Erläuterung von Architektur und Trainingsmethoden
- Link:
arxiv.org/abs/2507.20534 - Beschreibung: Vollständige technische Details und experimentelle Daten abrufen
- Link:
-
Kimi K2.5 Technik-Blog: Offizieller technischer Bericht zu K2.5
- Link:
kimi.com/blog/kimi-k2-5.html - Beschreibung: Erfahren Sie mehr über Agent Swarm und multimodale Fähigkeiten
- Link:
-
HuggingFace Model Card: Modellgewichte und Nutzungshinweise
- Link:
huggingface.co/moonshotai/Kimi-K2.5 - Beschreibung: Modellgewichte herunterladen und Bereitstellungsleitfaden einsehen
- Link:
-
Unsloth Local Deployment Guide: Detailliertes Tutorial zur quantisierten Bereitstellung
- Link:
unsloth.ai/docs/models/kimi-k2.5 - Beschreibung: Erfahren Sie mehr über die Hardwareanforderungen für verschiedene Quantisierungsstufen
- Link:
Autor: Technik-Team
Technischer Austausch: Gerne können Sie die technischen Details von Kimi K2.5 in den Kommentaren diskutieren. Weitere Analysen zu Großen Sprachmodellen finden Sie in der APIYI apiyi.com Technik-Community.