Примечание автора: Глубокий разбор ключевого содержания технической статьи Kimi K2.5: подробности архитектуры MoE на 1 трлн параметров, конфигурация из 384 экспертов, механизм внимания MLA, а также требования к оборудованию для локального развертывания и сравнение вариантов доступа через API.
Хотите узнать технические подробности Kimi K2.5? В этой статье на основе официальной технической статьи Kimi K2.5 мы систематически разберем архитектуру MoE с триллионом параметров, методы обучения и результаты бенчмарков, а также подробно опишем требования к железу для локального запуска.
Ключевая ценность: прочитав этот материал, вы изучите основные технические параметры Kimi K2.5, принципы проектирования архитектуры и сможете выбрать оптимальный вариант развертывания в зависимости от вашего оборудования.
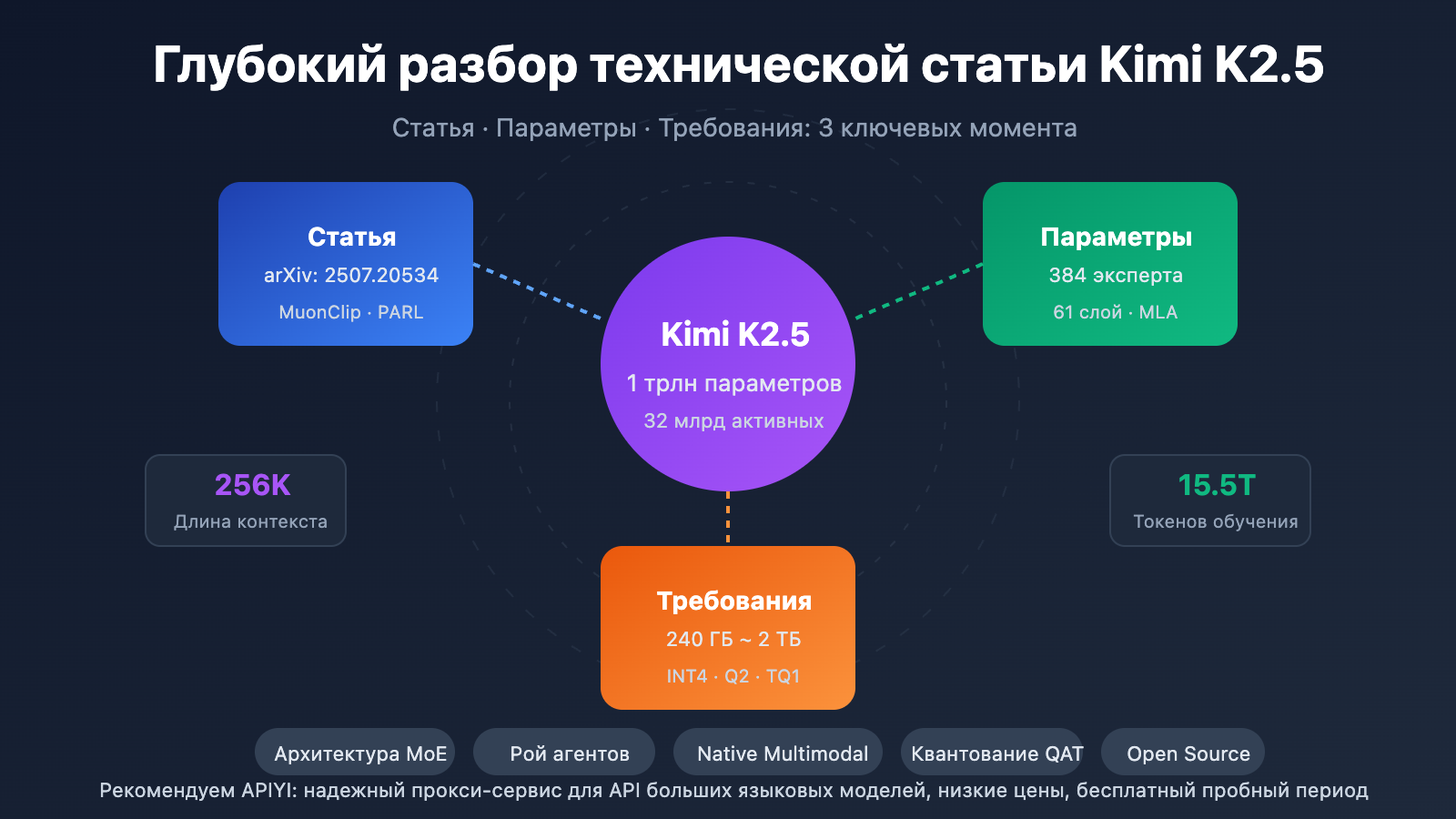
Ключевые моменты технической статьи Kimi K2.5
| Аспект | Технические детали | Инновационная ценность |
|---|---|---|
| MoE на триллион параметров | 1 трлн общих параметров, 32 млрд активных | При инференсе активируется лишь 3,2%, высочайшая эффективность |
| Система из 384 экспертов | На каждый токен выбирается 8 экспертов + 1 общий | На 50% больше экспертов, чем в DeepSeek-V3 |
| Внимание MLA | Multi-head Latent Attention | Сокращает KV Cache, поддерживает контекст до 256K |
| Оптимизатор MuonClip | Эффективное обучение на токенах, отсутствие Loss Spikes | Обучение на 15,5 трлн токенов без скачков функции потерь |
| Нативная мультимодальность | Визуальный энкодер MoonViT 400M | Смешанное обучение зрение-текст на 15 трлн токенов |
Контекст статьи Kimi K2.5
Техническая статья Kimi K2.5 была опубликована командой Moonshot AI (月之暗面), номер в arXiv: 2507.20534. В работе подробно описана техническая эволюция от Kimi K2 к K2.5, где основными вкладами стали:
- Сверхразреженная архитектура MoE: конфигурация из 384 экспертов (против 256 у DeepSeek-V3).
- Оптимизация обучения MuonClip: решение проблемы скачков лосса (Loss Spike) при крупномасштабном обучении.
- Парадигма Agent Swarm: метод обучения PARL (Parallel-Agent Reinforcement Learning).
- Нативная мультимодальная интеграция: объединение визуальных и языковых возможностей уже на этапе пре-трейна.
В статье отмечается, что по мере дефицита качественных человеческих данных, эффективность использования токенов становится решающим коэффициентом масштабирования больших языковых моделей. Это послужило стимулом для применения оптимизатора Muon и генерации синтетических данных.

Полные технические характеристики Kimi K2.5
Основные параметры архитектуры
| Категория | Параметр | Значение | Описание |
|---|---|---|---|
| Масштаб | Общее число параметров | 1T (1,04 триллиона) | Полный размер модели |
| Масштаб | Активируемые параметры | 32B | Используются при одном проходе инференса |
| Структура | Количество слоев | 61 слой | Включая 1 плотный (Dense) слой |
| Структура | Скрытая размерность | 7168 | Основная размерность модели (hidden dimension) |
| MoE | Число экспертов | 384 | На 128 больше, чем у DeepSeek-V3 |
| MoE | Активные эксперты | 8 + 1 общий | Выбор через Top-8 роутинг |
| MoE | Скрытая размерность эксперта | 2048 | Размерность FFN для каждого эксперта |
| Внимание | Число голов внимания | 64 | В два раза меньше, чем у DeepSeek-V3 |
| Внимание | Тип механизма | MLA | Multi-head Latent Attention |
| Прочее | Размер словаря | 160K | Поддержка множества языков |
| Прочее | Длина контекста | 256K | Обработка сверхдлинных документов |
| Прочее | Функция активации | SwiGLU | Эффективное нелинейное преобразование |
Разбор характеристик Kimi K2.5
Почему выбрано 384 эксперта?
Анализ законов масштабирования (Scaling Laws) в научной статье показывает, что дальнейшее увеличение разреженности (sparsity) дает значительный прирост производительности. Команда увеличила количество экспертов с 256 (как в DeepSeek-V3) до 384, что расширило репрезентативные возможности модели.
Почему сократили число голов внимания?
Чтобы снизить вычислительные затраты при инференсе, количество голов внимания было уменьшено со 128 до 64. В сочетании с механизмом MLA это решение позволило существенно сократить объем памяти, занимаемый KV-кэшем, при сохранении высокой производительности.
Преимущества механизма внимания MLA:
Традиционный MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = слои, H = головы, D = размерность, B = Batch, C = размерность сжатия
Благодаря сжатию в латентном пространстве, MLA уменьшает KV-кэш примерно в 10 раз, что делает возможной работу с контекстом в 256K токенов.
Параметры визуального энкодера
| Компонент | Параметр | Значение |
|---|---|---|
| Название | MoonViT | Собственный визуальный энкодер |
| Количество параметров | — | 400M |
| Особенности | Пространственно-временной пулинг | Поддержка понимания видео |
| Тип интеграции | Нативная интеграция | Интегрирован на этапе претрейна |
Требования к оборудованию для развертывания Kimi K2.5
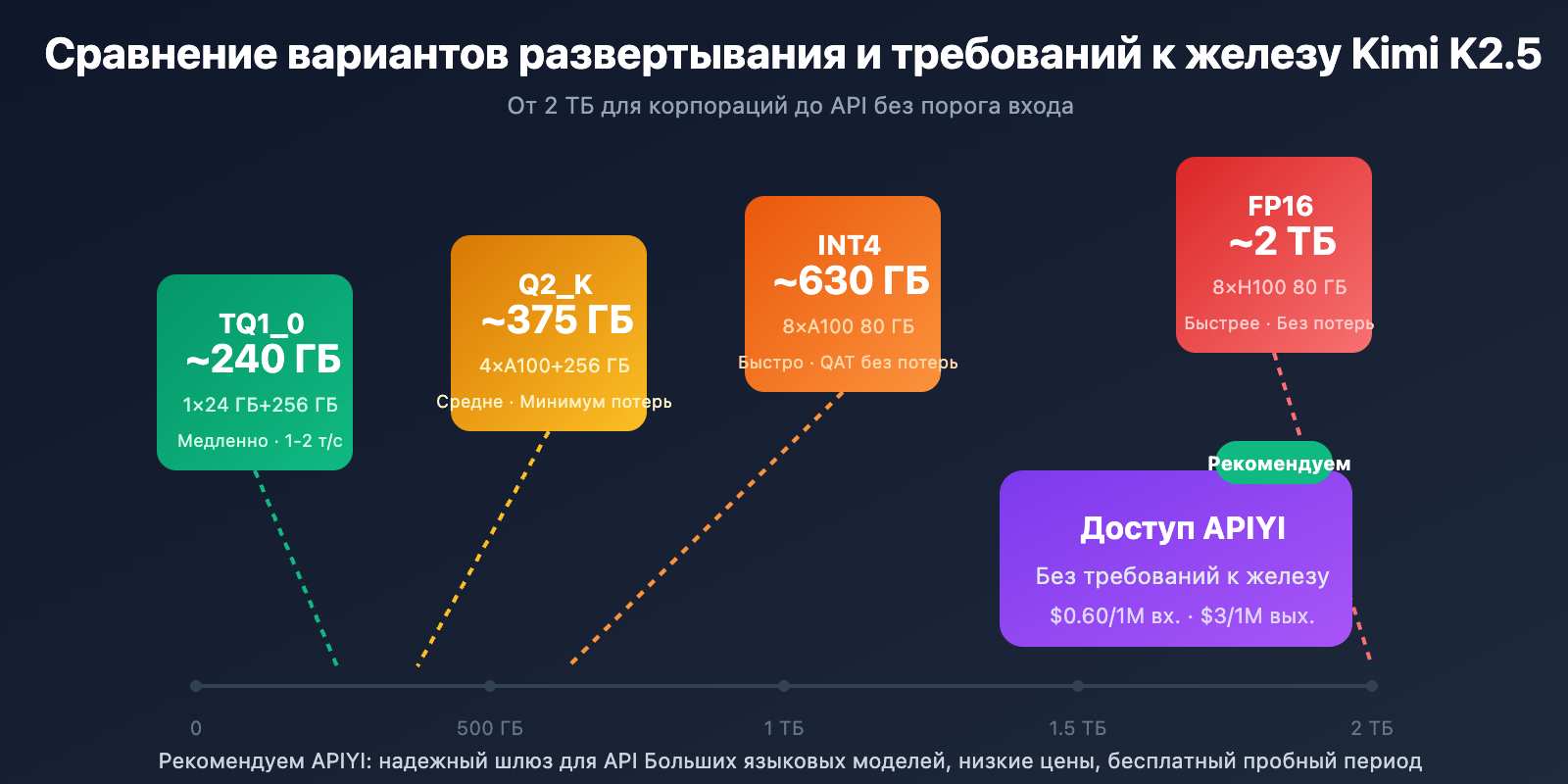
Требования для локального развертывания
| Точность квантования | Требуемая память | Минимум железа | Скорость инференса | Потеря точности |
|---|---|---|---|---|
| FP16 | ~2 ТБ | 8×H100 80 ГБ | Быстрее всего | Нет |
| INT4 (QAT) | ~630 ГБ | 8×A100 80 ГБ | Быстро | Почти без потерь |
| Q2_K_XL | ~375 ГБ | 4×A100 + 256 ГБ RAM | Средне | Незначительная |
| TQ1_0 (1.58-bit) | ~240 ГБ | 1×24 ГБ GPU + 256 ГБ RAM | Медленно (1-2 токена/сек) | Заметная |
Подробное пояснение требований Kimi K2.5
Корпоративное развертывание (рекомендуется)
Конфигурация: 2× NVIDIA H100 80 ГБ или 8× A100 80 ГБ
Память: 630 ГБ+ (квантование INT4)
Ожидаемая скорость: 50-100 токенов/сек
Применение: Продакшн, высоконагруженные сервисы
Развертывание с экстремальным сжатием
Конфигурация: 1× RTX 4090 24 ГБ + 256 ГБ оперативной памяти (RAM)
Память: 240 ГБ (квантование 1.58-bit)
Ожидаемая скорость: 1-2 токена/сек
Применение: Исследования, тесты, проверка функционала
Важно: Слои MoE полностью выгружаются в RAM, что сильно замедляет работу
Почему нужно так много памяти?
Хотя архитектура MoE при каждом проходе активирует только 32B параметров, модель должна удерживать в памяти все 1T параметров. Это необходимо для того, чтобы система могла динамически перенаправлять запрос (роутить) к нужным экспертам в зависимости от входных данных. Это фундаментальная особенность моделей типа Mixture of Experts.
Более практичное решение: подключение через API
Для большинства разработчиков порог входа для локального запуска Kimi K2.5 слишком высок. Использование API — гораздо более разумный выбор:
| Вариант | Стоимость | Преимущества |
|---|---|---|
| APIYI (рекомендуется) | $0.60/1M вх., $3/1M вых. | Единый интерфейс, переключение между моделями, бесплатные токены |
| Официальный API | Аналогично | Полный функционал, обновления в первую очередь |
| Локально (1-bit) | Стоимость железа + счета за свет | Полная конфиденциальность данных |
Совет по развертыванию: Если у вас нет строгих требований к локальному хранению данных, рекомендуем использовать Kimi K2.5 через APIYI (apiyi.com). Это позволит избежать огромных затрат на оборудование.
Результаты бенчмарков из статьи Kimi K2.5
Оценка ключевых возможностей
| Бенчмарк | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Описание |
|---|---|---|---|---|
| AIME 2025 | 96.1% | — | — | Математическая олимпиада (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | — | Математическая олимпиада (avg@32) |
| GPQA-Diamond | 87.6% | — | — | Научные рассуждения (avg@8) |
| SWE-Bench Verified | 76.8% | — | 80.9% | Исправление багов в коде |
| SWE-Bench Multi | 73.0% | — | — | Мультиязычный код |
| HLE-Full | 50.2% | — | — | Комплексные рассуждения (с инструментами) |
| BrowseComp | 60.2% | 54.9% | 24.1% | Взаимодействие с веб-страницами |
| MMMU-Pro | 78.5% | — | — | Мультимодальное понимание |
| MathVision | 84.2% | — | — | Визуальная математика |
Данные и методы обучения
| Этап | Объем данных | Метод |
|---|---|---|
| K2 Base (Предобучение) | 15.5T токенов | Оптимизатор MuonClip, отсутствие Loss Spike |
| K2.5 (Дообучение) | 15T (смесь визуал/текст) | Нативная мультимодальная интеграция |
| Обучение агентов | — | PARL (параллельное обучение агентов с подкреплением) |
| Квантование | — | QAT (обучение с учетом квантования) |
В статье особо подчеркивается, что использование оптимизатора MuonClip позволило провести предобучение на 15.5T токенов вообще без скачков функции потерь (Loss Spike). Для моделей с триллионами параметров это серьезный технологический прорыв.
Пример быстрого подключения Kimi K2.5
Минималистичный код для вызова
Через платформу APIYI вызвать Kimi K2.5 можно буквально в 10 строчек кода:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # Получите на apiyi.com
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "解释 MoE 架构的工作原理"}]
)
print(response.choices[0].message.content)
Посмотреть код для вызова в режиме Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Режим Thinking — глубокие рассуждения
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "Ты Kimi, пожалуйста, подробно проанализируй вопрос"},
{"role": "user", "content": "Докажи, что корень из 2 — иррациональное число"}
],
temperature=1.0, # Рекомендуется для режима Thinking
top_p=0.95,
max_tokens=8192
)
# Получение процесса рассуждения и финального ответа
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"Процесс рассуждения:\n{reasoning}\n")
print(f"Финальный ответ:\n{answer}")
Совет: Загляните на APIYI (apiyi.com), чтобы получить бесплатные тестовые лимиты и лично опробовать возможности глубоких рассуждений Kimi K2.5 в режиме Thinking.
Часто задаваемые вопросы
Q1: Где можно найти техническую статью (paper) по Kimi K2.5?
Официальная техническая статья по серии Kimi K2 опубликована на arXiv под номером 2507.20534, она доступна по адресу arxiv.org/abs/2507.20534. Технический отчет по конкретной модели Kimi K2.5 опубликован в официальном блоге: kimi.com/blog/kimi-k2-5.html.
Q2: Каковы минимальные системные требования (requirements) для локального развертывания Kimi K2.5?
Для схемы с максимальным сжатием потребуются: 1 видеокарта с 24 ГБ видеопамяти (VRAM) + 256 ГБ системной оперативной памяти + 240 ГБ свободного места на диске. Однако при такой конфигурации скорость генерации составит всего 1-2 токена в секунду. Рекомендуемая конфигурация — 2×H100 или 8×A100; использование квантования INT4 позволит добиться производительности уровня продакшена.
Q3: Как быстро проверить возможности Kimi K2.5?
Вместо сложного локального развертывания можно быстро провести тесты через API:
- Зайдите на сайт APIYI (apiyi.com) и зарегистрируйте аккаунт.
- Получите API-ключ и бесплатные бонусные баллы.
- Используйте примеры кода из этой статьи, указав в качестве названия модели
kimi-k2.5. - Оцените возможности глубокого рассуждения в режиме Thinking.
Итоги
Ключевые моменты технического отчета Kimi K2.5:
- Основные инновации Kimi K2.5 Paper: архитектура MoE с 384 экспертами + механизм внимания MLA + оптимизатор MuonClip, что позволило реализовать стабильное обучение модели с триллионом параметров без потери качества на пиковых нагрузках.
- Ключевые параметры Kimi K2.5: 1 трлн общих параметров, 32 млрд активных параметров, 61 слой, контекстное окно 256K. При каждом запросе активируется всего 3,2% параметров.
- Требования к развертыванию Kimi K2.5: порог для локального запуска очень высок (минимум 240 ГБ+ памяти), поэтому подключение через API — гораздо более практичный вариант.
Kimi K2.5 уже доступна на платформе APIYI (apiyi.com). Рекомендуем быстро протестировать возможности модели через API, чтобы оценить, насколько она подходит для ваших задач.
Полезные ссылки
⚠️ Примечание к формату ссылок: Все внешние ссылки указаны в формате
Название ресурса: domain.com. Их удобно копировать, но они не являются кликабельными, чтобы избежать потери SEO-веса.
-
Статья Kimi K2 на arXiv: официальный технический отчет с подробным описанием архитектуры и методов обучения.
- Ссылка:
arxiv.org/abs/2507.20534 - Описание: Полная техническая информация и экспериментальные данные.
- Ссылка:
-
Технический блог Kimi K2.5: официальный отчет о Kimi K2.5, опубликованный разработчиками.
- Ссылка:
kimi.com/blog/kimi-k2-5.html - Описание: Информация об Agent Swarm и мультимодальных возможностях.
- Ссылка:
-
Карточка модели на HuggingFace: веса модели и инструкции по использованию.
- Ссылка:
huggingface.co/moonshotai/Kimi-K2.5 - Описание: Скачивание весов и руководство по развертыванию.
- Ссылка:
-
Руководство по локальному развертыванию от Unsloth: подробный туториал по квантованию и запуску.
- Ссылка:
unsloth.ai/docs/models/kimi-k2.5 - Описание: Требования к железу для разных уровней точности квантования.
- Ссылка:
Автор: Техническая команда
Обсуждение: Приглашаем обсудить технические детали Kimi K2.5 в комментариях. Еще больше разборов моделей можно найти в техническом сообществе APIYI (apiyi.com).