Note de l'auteur : décryptage approfondi du contenu de l'article technique sur Kimi K2.5, explication détaillée de l'architecture MoE à 1T de paramètres, de la configuration à 384 experts, du mécanisme d'attention MLA, ainsi que des exigences matérielles pour le déploiement local et une comparaison des solutions d'accès aux API.
Envie d'en savoir plus sur les détails techniques de Kimi K2.5 ? Cet article, basé sur le document technique officiel de Kimi K2.5, décrypte systématiquement son architecture MoE à mille milliards de paramètres, ses méthodes d'entraînement et ses résultats de référence (benchmarks), tout en détaillant la configuration matérielle requise pour un déploiement local.
Valeur ajoutée : à la fin de cette lecture, vous maîtriserez les paramètres techniques clés de Kimi K2.5, les principes de conception de son architecture, et vous saurez choisir la meilleure option de déploiement selon votre matériel.
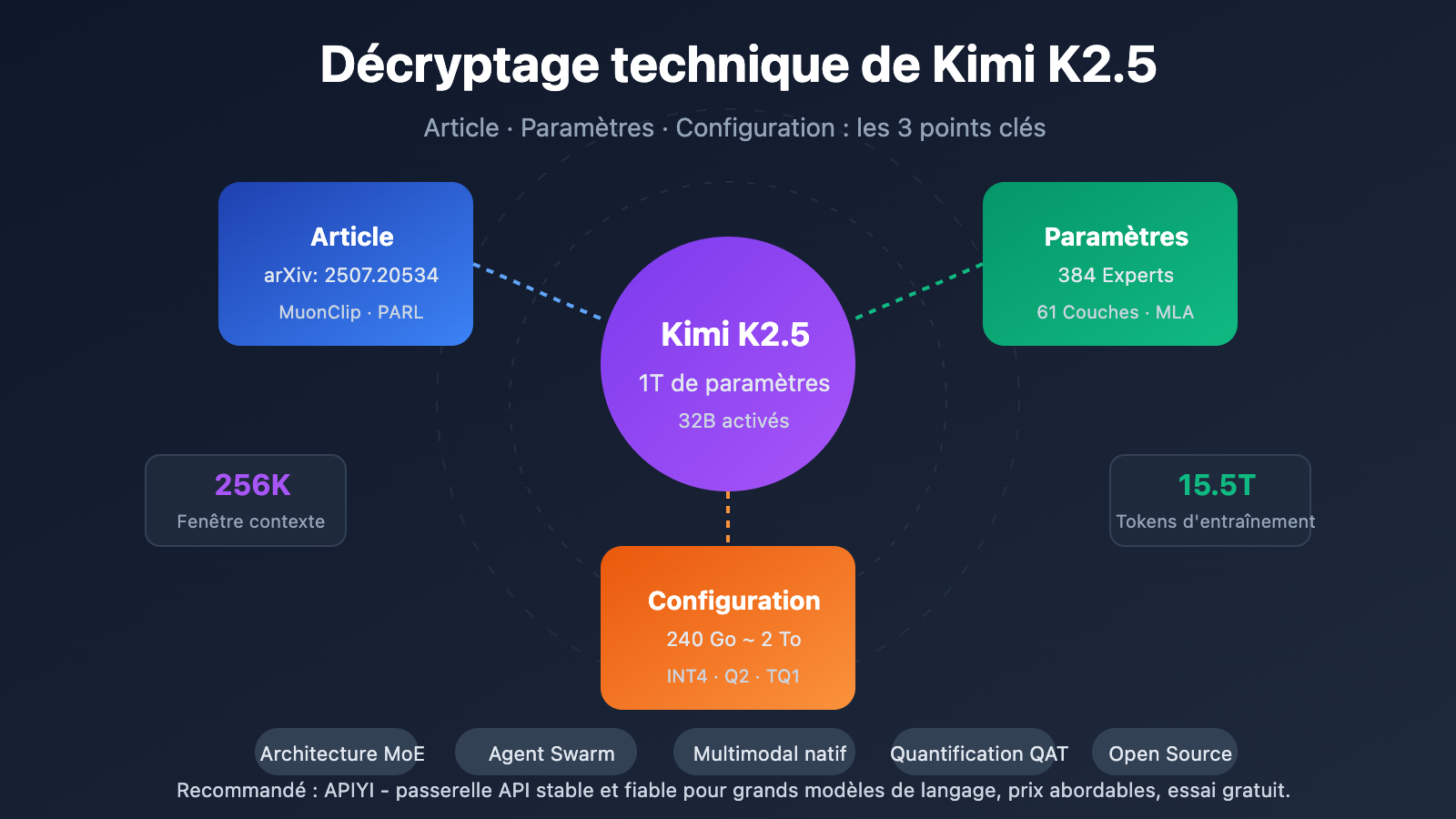
Points clés du document technique Kimi K2.5
| Point clé | Détails techniques | Valeur d'innovation |
|---|---|---|
| MoE à mille milliards de paramètres | 1T de paramètres totaux, 32B activés | Seulement 3,2 % d'activation en inférence, efficacité extrême |
| Système à 384 experts | Sélection de 8 experts + 1 expert partagé par token | 50 % d'experts en plus que DeepSeek-V3 |
| Attention MLA | Multi-head Latent Attention | Réduction du KV Cache, support du contexte 256K |
| Optimiseur MuonClip | Entraînement efficace par token, zéro pic de perte | 15,5T de tokens entraînés sans pic de perte (Loss Spike) |
| Multimodalité native | Encodeur visuel MoonViT 400M | Entraînement mixte vision-texte de 15T |
Contexte de l'article technique Kimi K2.5
Le document technique Kimi K2.5 a été publié par l'équipe Moonshot AI, sous la référence arXiv 2507.20534. L'article détaille l'évolution technologique de Kimi K2 vers K2.5, dont les contributions majeures incluent :
- Architecture MoE ultra-sparse : configuration à 384 experts, soit 50 % de plus que les 256 experts de DeepSeek-V3.
- Optimisation d'entraînement MuonClip : résolution des problèmes de pics de perte (Loss Spikes) lors des entraînements à grande échelle.
- Paradigme Agent Swarm : méthode d'entraînement PARL (Parallel-Agent Reinforcement Learning).
- Fusion multimodale native : intégration des capacités vision-langage dès la phase de pré-entraînement.
L'article souligne qu'avec la raréfaction des données humaines de haute qualité, l'efficacité des tokens devient le facteur clé du passage à l'échelle (scaling), ce qui a stimulé l'utilisation de l'optimiseur Muon et de la génération de données synthétiques.
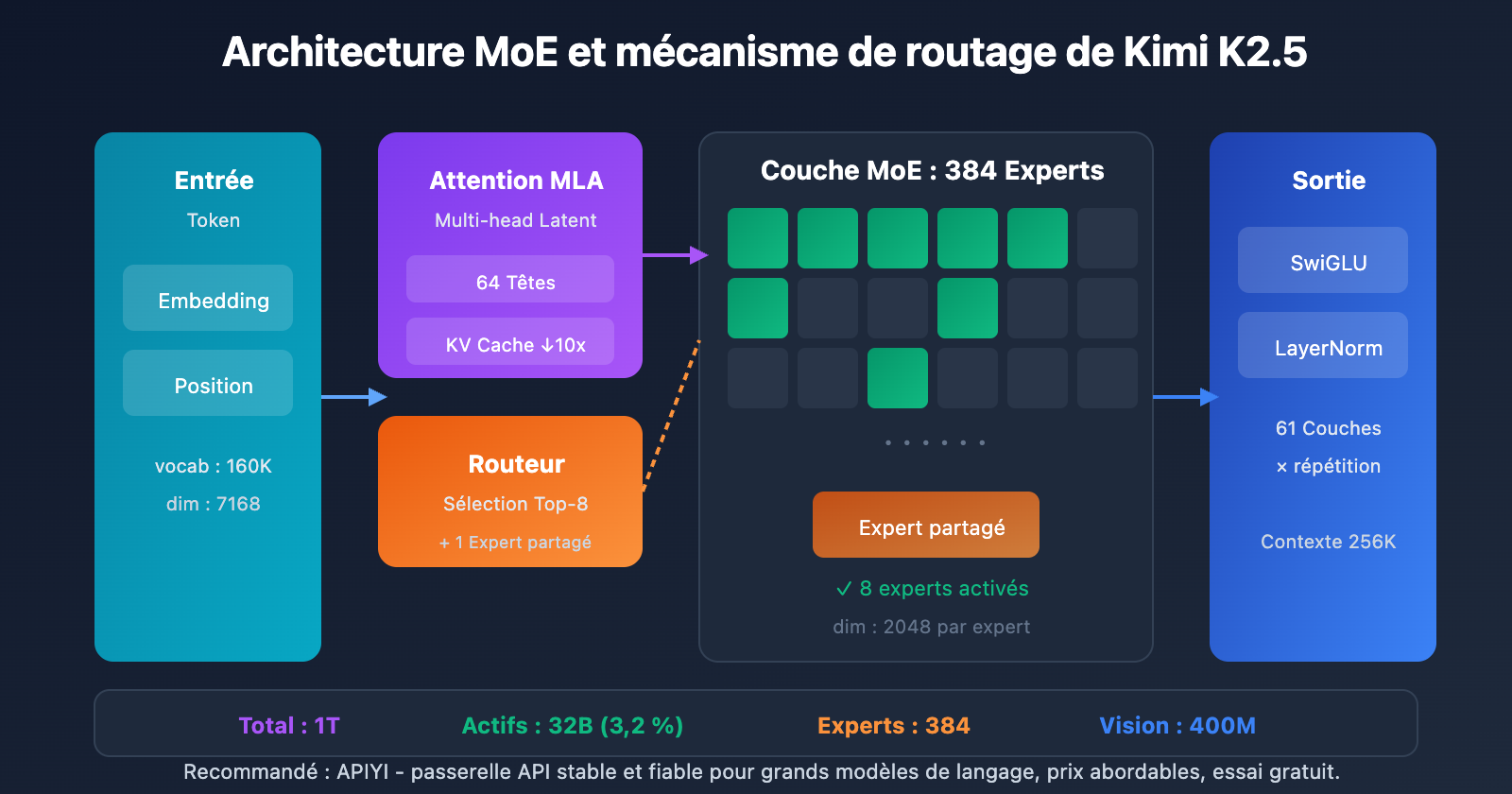
Spécifications complètes des paramètres de Kimi K2.5
Paramètres de l'architecture centrale
| Catégorie | Paramètre | Valeur | Description |
|---|---|---|---|
| Échelle | Paramètres totaux | 1T (1,04 billion) | Taille totale du modèle |
| Échelle | Paramètres activés | 32B | Utilisés réellement lors d'une inférence |
| Structure | Couches | 61 couches | Inclut 1 couche dense |
| Structure | Dimension cachée | 7168 | Dimension du backbone du modèle |
| MoE | Nombre d'experts | 384 | 128 de plus que DeepSeek-V3 |
| MoE | Experts activés | 8 + 1 partagé | Sélection par routage Top-8 |
| MoE | Dimension cachée des experts | 2048 | Dimension FFN de chaque expert |
| Attention | Têtes d'attention | 64 | Moitié moins que DeepSeek-V3 |
| Attention | Type de mécanisme | MLA | Multi-head Latent Attention |
| Autres | Taille du vocabulaire | 160K | Support multilingue |
| Autres | Longueur du contexte | 256K | Traitement de documents ultra-longs |
| Autres | Fonction d'activation | SwiGLU | Transformation non-linéaire efficace |
Analyse de la conception des paramètres de Kimi K2.5
Pourquoi choisir 384 experts ?
L'analyse de la "Scaling Law" (loi de mise à l'échelle) dans l'article montre qu'augmenter continuellement la parcimonie apporte des gains de performance significatifs. L'équipe a fait passer le nombre d'experts de 256 (chez DeepSeek-V3) à 384, renforçant ainsi la capacité de représentation du modèle.
Pourquoi réduire les têtes d'attention ?
Afin de réduire la charge de calcul lors de l'inférence, le nombre de têtes d'attention a été ramené de 128 à 64. Combiné au mécanisme MLA, ce choix permet de maintenir les performances tout en réduisant considérablement l'empreinte mémoire du KV Cache.
Avantages du mécanisme d'attention MLA :
MHA traditionnel : KV Cache = 2 × L × H × D × B
MLA : KV Cache = 2 × L × C × B (C << H × D)
L = Couches, H = Têtes, D = Dimension, B = Batch, C = Dimension de compression
Grâce à la compression dans l'espace latent, le MLA réduit le KV Cache d'environ 10 fois, rendant possible un contexte de 256K.
Paramètres de l'encodeur visuel
| Composant | Paramètre | Valeur |
|---|---|---|
| Nom | MoonViT | Encodeur visuel maison |
| Paramètres | – | 400M |
| Caractéristiques | Pooling spatio-temporel | Support de la compréhension vidéo |
| Intégration | Fusion native | Intégré dès la phase de pré-entraînement |
Configuration matérielle requise pour Kimi K2.5
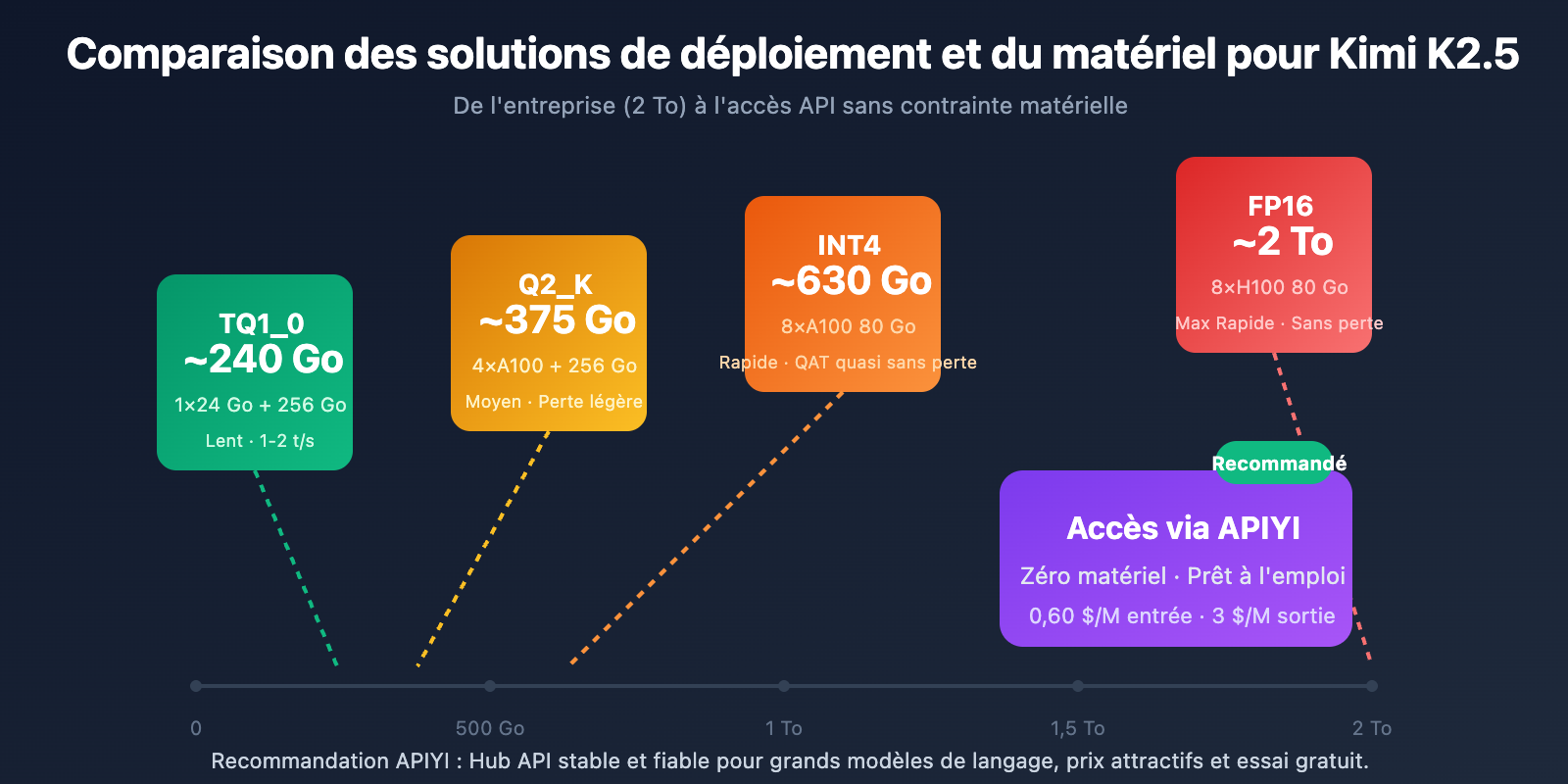
Matériel requis pour le déploiement local
| Précision de quantification | Stockage requis | Matériel minimum | Vitesse d'inférence | Perte de précision |
|---|---|---|---|---|
| FP16 | ~2 To | 8×H100 80 Go | Maximale | Aucune |
| INT4 (QAT) | ~630 Go | 8×A100 80 Go | Rapide | Presque nulle |
| Q2_K_XL | ~375 Go | 4×A100 + 256 Go RAM | Moyenne | Légère |
| TQ1_0 (1.58-bit) | ~240 Go | 1× GPU 24 Go + 256 Go RAM | Lente (1-2 t/s) | Significative |
Détails techniques de la configuration Kimi K2.5
Déploiement niveau entreprise (Recommandé)
Configuration matérielle : 2× NVIDIA H100 80 Go ou 8× A100 80 Go
Stockage requis : 630 Go+ (Quantification INT4)
Performance attendue : 50-100 tokens/s
Scénarios : Environnement de production, services à haute concurrence
Déploiement avec compression extrême
Configuration matérielle : 1× RTX 4090 24 Go + 256 Go de RAM système
Stockage requis : 240 Go (Quantification 1.58-bit)
Performance attendue : 1-2 tokens/s
Scénarios : Recherche et tests, validation de fonctionnalités
Note : Les couches MoE sont entièrement déchargées dans la RAM, ce qui ralentit la vitesse.
Pourquoi autant de mémoire ?
Bien que l'architecture MoE n'active que 32 milliards de paramètres par inférence, le modèle doit maintenir l'intégralité des 1 000 milliards de paramètres en mémoire pour router dynamiquement vers les bons experts en fonction de l'entrée. C'est une caractéristique inhérente aux modèles MoE.
La solution la plus pratique : l'accès via API
Pour la plupart des développeurs, la barrière matérielle pour déployer localement Kimi K2.5 est très élevée. L'accès via API est un choix bien plus pragmatique :
| Solution | Coût | Avantages |
|---|---|---|
| APIYI (Recommandé) | 0,60 $/M entrée, 3 $/M sortie | Interface unifiée, changement de modèle facile, crédits gratuits |
| API Officielle | Identique | Fonctionnalités complètes, mises à jour immédiates |
| Local 1-bit | Coût matériel + Électricité | Localisation des données |
Conseil de déploiement : À moins d'avoir des exigences strictes en matière de souveraineté des données, nous vous conseillons de passer par APIYI (apiyi.com) pour utiliser Kimi K2.5, afin d'éviter des investissements matériels colossaux.
Résultats des benchmarks du papier Kimi K2.5
Évaluation des capacités clés
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Description |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | Concours de mathématiques (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | Concours de mathématiques (avg@32) |
| GPQA-Diamond | 87.6% | – | – | Raisonnement scientifique (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | Correction de code |
| SWE-Bench Multi | 73.0% | – | – | Code multilingue |
| HLE-Full | 50.2% | – | – | Raisonnement complexe (avec outils) |
| BrowseComp | 60.2% | 54.9% | 24.1% | Interaction Web |
| MMMU-Pro | 78.5% | – | – | Compréhension multimodale |
| MathVision | 84.2% | – | – | Mathématiques visuelles |
Données et méthodes d'entraînement
| Étape | Volume de données | Méthode |
|---|---|---|
| Pré-entraînement K2 Base | 15.5T tokens | Optimiseur MuonClip, zéro Loss Spike |
| Pré-entraînement continu K2.5 | 15T mélange vision-texte | Fusion multimodale native |
| Entraînement de l'Agent | – | PARL (Apprentissage par renforcement d'agents parallèles) |
| Entraînement à la quantification | – | QAT (Entraînement sensible à la quantification) |
Le papier souligne particulièrement que l'optimiseur MuonClip a permis au processus de pré-entraînement de 15,5 T tokens de se dérouler sans aucune explosion de la perte (Loss Spike), ce qui constitue une avancée majeure pour un entraînement à l'échelle de milliers de milliards de paramètres.
Exemple d'accès rapide à Kimi K2.5
Code d'appel minimaliste
Via la plateforme APIYI, 10 lignes de code suffisent pour appeler Kimi K2.5 :
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "解释 MoE 架构的工作原理"}]
)
print(response.choices[0].message.content)
Voir le code pour le mode Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 模式 - 深度推理
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "你是 Kimi,请详细分析问题"},
{"role": "user", "content": "证明根号2是无理数"}
],
temperature=1.0, # Thinking 模式推荐
top_p=0.95,
max_tokens=8192
)
# 获取推理过程和最终答案
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"推理过程:\n{reasoning}\n")
print(f"最终答案:\n{answer}")
Conseil : Obtenez des crédits de test gratuits sur APIYI (apiyi.com) pour tester les capacités de raisonnement approfondi du mode Thinking de Kimi K2.5.
FAQ
Q1 : Où peut-on obtenir le papier technique (white paper) de Kimi K2.5 ?
Le papier technique officiel de la série Kimi K2 est publié sur arXiv sous le numéro 2507.20534. Il est accessible via arxiv.org/abs/2507.20534. Le rapport technique de Kimi K2.5 est quant à lui disponible sur le blog officiel : kimi.com/blog/kimi-k2-5.html.
Q2 : Quelles sont les configurations minimales (requirements) pour un déploiement local de Kimi K2.5 ?
Une solution de compression extrême nécessite : 1 GPU avec 24 Go de VRAM + 256 Go de RAM système + 240 Go d'espace de stockage. Cependant, avec cette configuration, la vitesse d'inférence n'est que de 1 à 2 tokens/s. La configuration recommandée est de 2×H100 ou 8×A100 ; l'utilisation de la quantification INT4 permet d'atteindre des performances de niveau production.
Q3 : Comment tester rapidement les capacités de Kimi K2.5 ?
Pas besoin de déploiement local, vous pouvez tester le modèle rapidement via API :
- Rendez-vous sur APIYI (apiyi.com) pour créer un compte.
- Obtenez votre clé API et vos crédits gratuits.
- Utilisez les exemples de code de cet article en renseignant
kimi-k2.5comme nom de modèle. - Découvrez les capacités de raisonnement approfondi du mode "Thinking".
En résumé
Voici les points clés à retenir du papier technique de Kimi K2.5 :
- Innovations majeures du papier Kimi K2.5 : Architecture MoE à 384 experts + attention MLA + optimisateur MuonClip, permettant un entraînement sans perte de performance pour des modèles de mille milliards de paramètres.
- Paramètres clés de Kimi K2.5 : 1T de paramètres au total, 32B de paramètres activés, 61 couches, contexte de 256K. Seulement 3,2 % des paramètres sont activés à chaque inférence.
- Configurations requises (Requirements) pour Kimi K2.5 : Le seuil pour le déploiement local est élevé (minimum 240 Go+), l'accès via API reste donc l'option la plus pragmatique.
Kimi K2.5 est déjà disponible sur APIYI (apiyi.com). Nous vous conseillons de valider rapidement les capacités du modèle via l'API pour évaluer s'il correspond à vos besoins métier.
Ressources de référence
⚠️ Note sur le format des liens : Tous les liens externes utilisent le format
Nom de la ressource : domain.com. Cela facilite le copier-coller sans créer de lien cliquable, évitant ainsi la perte de poids SEO.
-
Papier arXiv Kimi K2 : Rapport technique officiel, détaillant l'architecture et les méthodes d'entraînement
- Lien :
arxiv.org/abs/2507.20534 - Description : Pour accéder à l'intégralité des détails techniques et des données expérimentales.
- Lien :
-
Blog technique Kimi K2.5 : Rapport technique officiel publié pour la version K2.5
- Lien :
kimi.com/blog/kimi-k2-5.html - Description : Pour découvrir l'Agent Swarm et les capacités multimodales.
- Lien :
-
Carte de modèle HuggingFace : Poids du modèle et instructions d'utilisation
- Lien :
huggingface.co/moonshotai/Kimi-K2.5 - Description : Téléchargez les poids du modèle et consultez le guide de déploiement.
- Lien :
-
Guide de déploiement local Unsloth : Tutoriel détaillé sur le déploiement quantifié
- Lien :
unsloth.ai/docs/models/kimi-k2.5 - Description : Comprendre les exigences matérielles selon les différentes précisions de quantification.
- Lien :
Auteur : Équipe Technique
Échanges techniques : N'hésitez pas à venir discuter des détails techniques de Kimi K2.5 dans l'espace commentaires. Pour plus d'analyses de modèles, vous pouvez visiter la communauté technique APIYI sur apiyi.com.