Nota del autor: Análisis profundo del contenido principal del paper técnico de Kimi K2.5, detallando la arquitectura MoE de 1T de parámetros, la configuración de 384 expertos, el mecanismo de atención MLA, y proporcionando comparativas de requisitos de hardware para despliegue local y soluciones de acceso vía API.
¿Quieres conocer los detalles técnicos de Kimi K2.5? Este artículo, basado en el paper técnico oficial de Kimi K2.5, interpreta de forma sistemática su arquitectura MoE de un billón de parámetros, sus métodos de entrenamiento y resultados de benchmarks, detallando además los requisitos de hardware para su despliegue local.
Valor principal: Al terminar de leer este artículo, dominarás los parámetros técnicos principales de Kimi K2.5, sus principios de diseño arquitectónico y tendrás la capacidad de elegir la mejor opción de despliegue según tus condiciones de hardware.
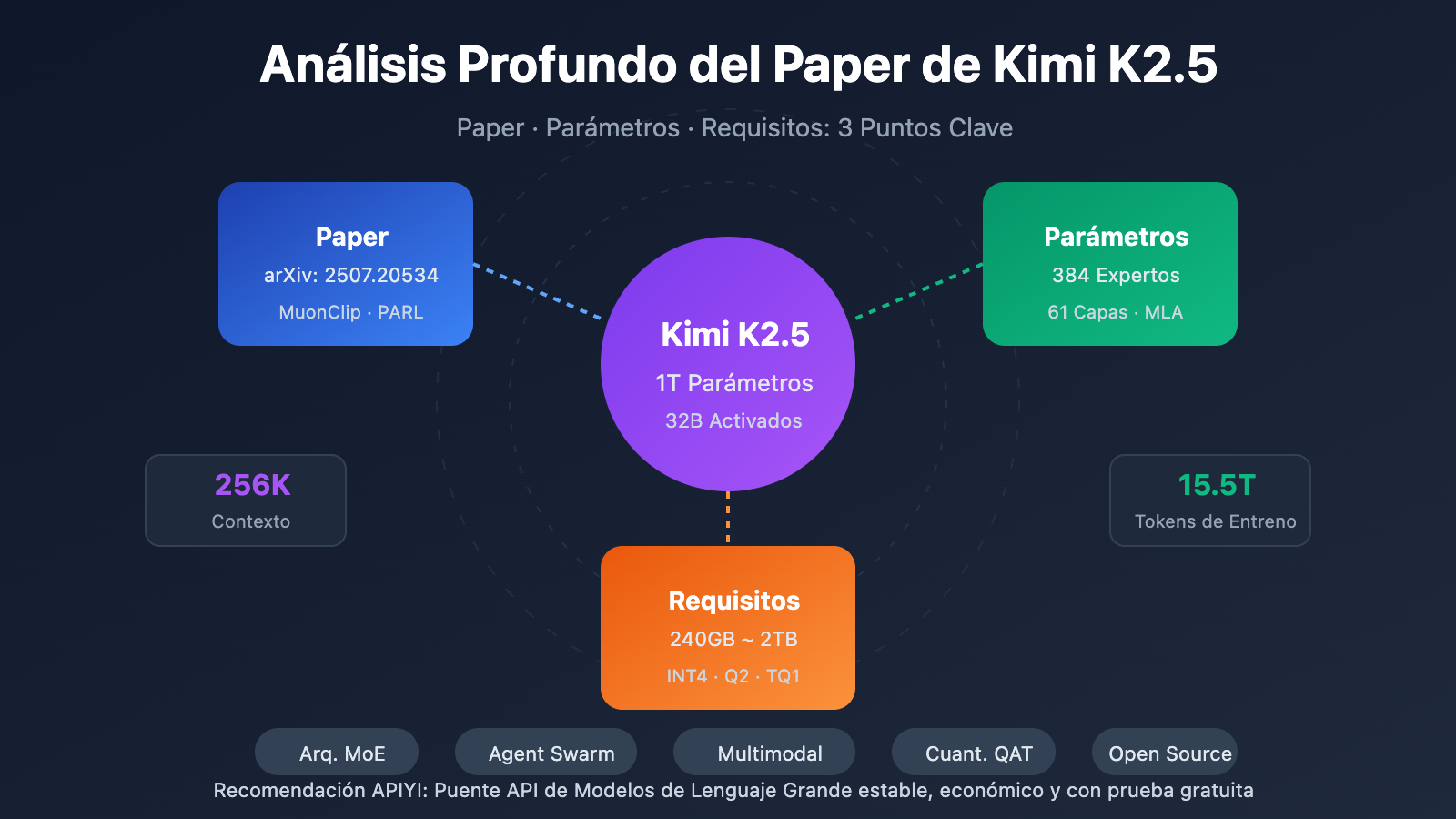
Puntos Clave del Paper Técnico de Kimi K2.5
| Punto Clave | Detalles Técnicos | Valor de Innovación |
|---|---|---|
| MoE de 1 Billón de Parámetros | 1T de parámetros totales, 32B activados | Solo activa el 3.2% en inferencia; eficiencia extrema |
| Sistema de 384 Expertos | Selección de 8 expertos + 1 compartido por Token | 50% más expertos que DeepSeek-V3 |
| Atención MLA | Multi-head Latent Attention | Reduce la KV Cache y soporta contexto de 256K |
| Optimizador MuonClip | Entrenamiento eficiente de tokens, cero Loss Spike | 15.5T de tokens entrenados sin picos de pérdida |
| Multimodal Nativo | Codificador visual MoonViT 400M | 15T de entrenamiento híbrido visión-texto |
Contexto del Paper de Kimi K2.5
El paper técnico de Kimi K2.5 fue publicado por el equipo de Moonshot AI, con el código arXiv 2507.20534. El documento detalla la evolución técnica de Kimi K2 a K2.5, destacando como contribuciones principales:
- Arquitectura MoE Ultra Dispersa: Configuración de 384 expertos, un 50% superior a los 256 de DeepSeek-V3.
- Optimización de Entrenamiento MuonClip: Resuelve el problema de los Loss Spikes (picos de pérdida) en entrenamientos a gran escala.
- Paradigma Agent Swarm: Método de entrenamiento PARL (Parallel-Agent Reinforcement Learning).
- Fusión Multimodal Nativa: Integración de capacidades de visión y lenguaje desde la etapa de pre-entrenamiento.
El paper señala que, ante la creciente escasez de datos humanos de alta calidad, la eficiencia de los tokens se está convirtiendo en el factor crítico para escalar Modelos de Lenguaje Grande, lo que ha impulsado la aplicación del optimizador Muon y la generación de datos sintéticos.
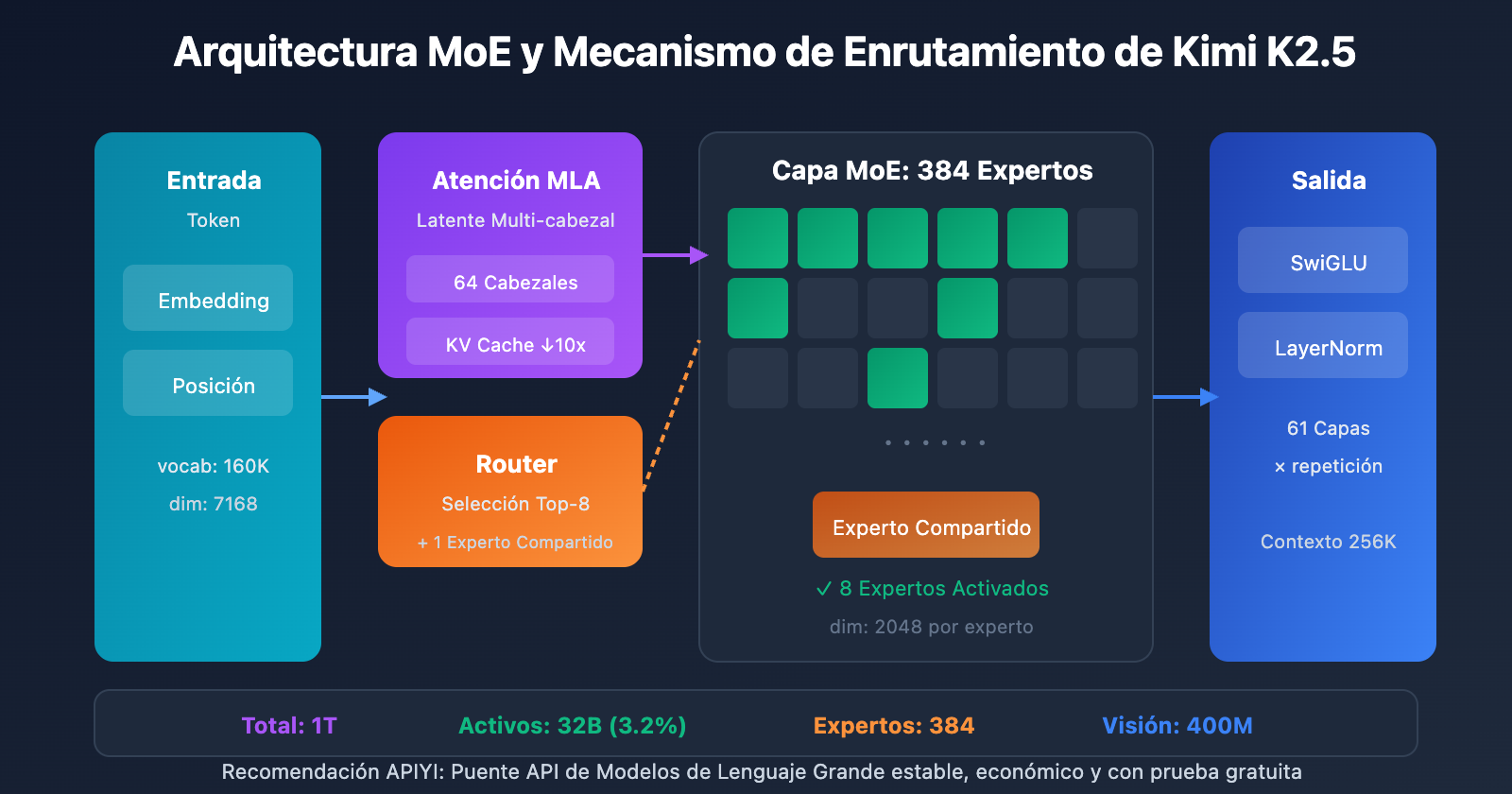
Especificaciones completas de los parámetros de Kimi K2.5
Parámetros de la arquitectura central
| Categoría | Nombre del parámetro | Valor | Descripción |
|---|---|---|---|
| Escala | Parámetros totales | 1T (1,04 billones) | Tamaño total del modelo |
| Escala | Parámetros activos | 32B | Uso real en una sola inferencia |
| Estructura | Capas | 61 capas | Incluye 1 capa densa |
| Estructura | Dimensión oculta | 7168 | Dimensión del backbone del modelo |
| MoE | Cantidad de expertos | 384 | 128 más que DeepSeek-V3 |
| MoE | Expertos activos | 8 + 1 compartido | Enrutamiento Top-8 |
| MoE | Dimensión oculta del experto | 2048 | Dimensión FFN de cada experto |
| Atención | Cabezales de atención | 64 | La mitad que DeepSeek-V3 |
| Atención | Tipo de mecanismo | MLA | Multi-head Latent Attention |
| Otros | Tamaño del vocabulario | 160K | Soporte multilingüe |
| Otros | Longitud de contexto | 256K | Procesamiento de documentos extralargos |
| Otros | Función de activación | SwiGLU | Transformación no lineal eficiente |
Interpretación del diseño de parámetros de Kimi K2.5
¿Por qué elegir 384 expertos?
El análisis de la Ley de Escalamiento (Scaling Law) en el artículo técnico indica que aumentar continuamente la dispersión (sparsity) aporta mejoras de rendimiento significativas. El equipo aumentó el número de expertos de 256 (en DeepSeek-V3) a 384, mejorando la capacidad de representación del modelo.
¿Por qué reducir los cabezales de atención?
Para reducir los costos computacionales durante la inferencia, el número de cabezales de atención se redujo de 128 a 64. Combinado con el mecanismo MLA, este diseño reduce drásticamente la ocupación de memoria de la KV Cache manteniendo el rendimiento.
Ventajas del mecanismo de atención MLA:
传统 MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = 层数, H = 头数, D = 维度, B = Batch, C = 压缩维度
MLA, a través de la compresión del espacio latente, reduce la KV Cache aproximadamente 10 veces, haciendo posible un contexto de 256K.
Parámetros del codificador visual
| Componente | Parámetro | Valor |
|---|---|---|
| Nombre | MoonViT | Codificador visual de desarrollo propio |
| Parámetros | – | 400M |
| Características | Pooling espacio-temporal | Soporte para comprensión de video |
| Integración | Fusión nativa | Integrado en la fase de pre-entrenamiento |
Requisitos de hardware para el despliegue de Kimi K2.5
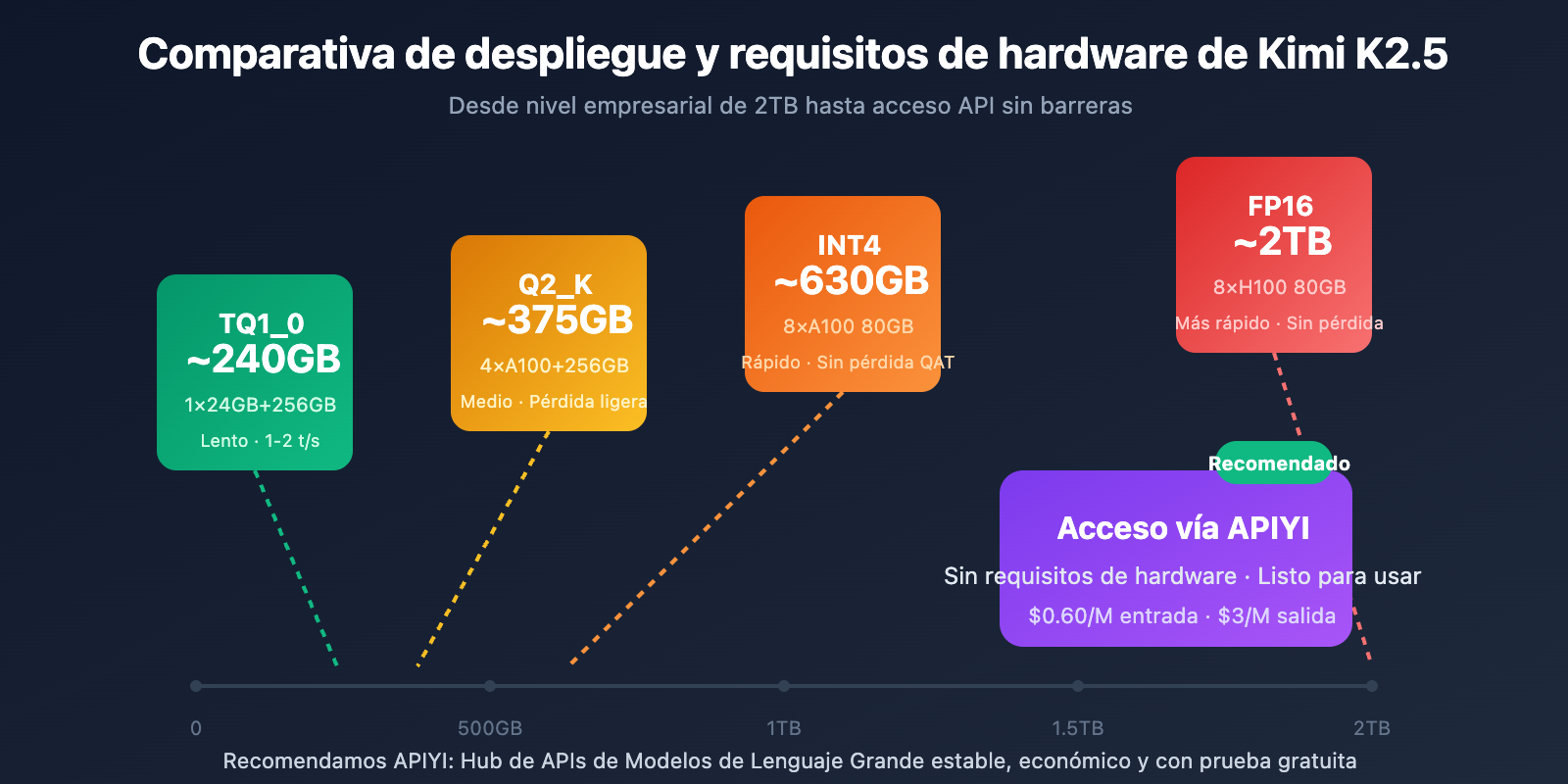
Requisitos de hardware para despliegue local
| Precisión de cuantización | Requisitos de almacenamiento | Hardware mínimo | Velocidad de inferencia | Pérdida de precisión |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | La más rápida | Ninguna |
| INT4 (QAT) | ~630GB | 8×A100 80GB | Rápida | Casi nula |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | Media | Ligera |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | Lenta (1-2 t/s) | Notoria |
Detalles de los requisitos de Kimi K2.5
Despliegue de nivel empresarial (Recomendado)
Configuración de hardware: 2× NVIDIA H100 80GB u 8× A100 80GB
Requisitos de almacenamiento: 630GB+ (Cuantización INT4)
Rendimiento esperado: 50-100 tokens/s
Escenario de uso: Entornos de producción, servicios de alta concurrencia
Despliegue con compresión extrema
Configuración de hardware: 1× RTX 4090 24GB + 256GB de memoria de sistema
Requisitos de almacenamiento: 240GB (Cuantización de 1.58 bits)
Rendimiento esperado: 1-2 tokens/s
Escenario de uso: Investigación y pruebas, verificación de funciones
Nota: Las capas MoE se descargan completamente a la RAM, lo que ralentiza la velocidad.
¿Por qué se necesita tanta memoria?
Aunque la arquitectura MoE solo activa 32B de parámetros por cada inferencia, el modelo necesita mantener los 1T de parámetros completos en la memoria para poder enrutar dinámicamente al experto correcto según la entrada. Esta es una característica intrínseca de los modelos MoE.
Una solución más práctica: Acceso vía API
Para la mayoría de los desarrolladores, la barrera de hardware para el despliegue local de Kimi K2.5 es muy alta. El acceso a través de API es la opción más práctica:
| Plan | Costo | Ventajas |
|---|---|---|
| APIYI (Recomendado) | $0.60/M entrada, $3/M salida | Interfaz unificada, cambio entre múltiples modelos, cuota gratuita |
| API Oficial | Igual al anterior | Funcionalidad completa, actualizaciones inmediatas |
| Local 1-bit | Costo de hardware + electricidad | Localización de datos |
Sugerencia de despliegue: A menos que existan requisitos estrictos de localización de datos, se recomienda acceder a Kimi K2.5 a través de APIYI (apiyi.com) para evitar la enorme inversión en hardware.
Resultados de los benchmarks del Paper de Kimi K2.5
Evaluación de capacidades principales
| Benchmark | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | Descripción |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | Competición de matemáticas (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | Competición de matemáticas (avg@32) |
| GPQA-Diamond | 87.6% | – | – | Razonamiento científico (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | Reparación de código |
| SWE-Bench Multi | 73.0% | – | – | Código multilingüe |
| HLE-Full | 50.2% | – | – | Razonamiento integral (con herramientas) |
| BrowseComp | 60.2% | 54.9% | 24.1% | Interacción web |
| MMMU-Pro | 78.5% | – | – | Comprensión multimodal |
| MathVision | 84.2% | – | – | Matemáticas visuales |
Datos y métodos de entrenamiento
| Fase | Volumen de datos | Método |
|---|---|---|
| Preentrenamiento de K2 Base | 15.5T tokens | Optimizador MuonClip, cero Loss Spike |
| Preentrenamiento continuo K2.5 | 15T mezcla visión-texto | Fusión multimodal nativa |
| Entrenamiento de Agent | – | PARL (Aprendizaje por Refuerzo de Agentes Paralelos) |
| Entrenamiento de cuantización | – | QAT (Entrenamiento consciente de la cuantización) |
El artículo destaca especialmente que el optimizador MuonClip permitió que todo el proceso de preentrenamiento de 15.5T de tokens se realizara sin que apareciera ni un solo Loss Spike (pico de pérdida), lo cual es un avance significativo en entrenamientos a escala de billones de parámetros.
Ejemplo de acceso rápido a Kimi K2.5
Código de llamada minimalista
A través de la plataforma APIYI, puedes llamar a Kimi K2.5 con solo 10 líneas de código:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # Consíguela en apiyi.com
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "Explica el principio de funcionamiento de la arquitectura MoE"}]
)
print(response.choices[0].message.content)
Ver código de llamada para el modo Thinking
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Modo Thinking - Razonamiento profundo
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "Eres Kimi, por favor analiza el problema en detalle"},
{"role": "user", "content": "Demuestra que la raíz cuadrada de 2 es irracional"}
],
temperature=1.0, # Recomendado para el modo Thinking
top_p=0.95,
max_tokens=8192
)
# Obtener el proceso de razonamiento y la respuesta final
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"Proceso de razonamiento:\n{reasoning}\n")
print(f"Respuesta final:\n{answer}")
Sugerencia: Obtén cuotas de prueba gratuitas en APIYI (apiyi.com) para experimentar la capacidad de razonamiento profundo del modo Thinking de Kimi K2.5.
Preguntas frecuentes
Q1: ¿Dónde se puede conseguir el artículo técnico (paper) de Kimi K2.5?
El artículo técnico oficial de la serie Kimi K2 está publicado en arXiv bajo el número 2507.20534, y se puede acceder a través de arxiv.org/abs/2507.20534. El informe técnico específico de Kimi K2.5 está disponible en el blog oficial: kimi.com/blog/kimi-k2-5.html.
Q2: ¿Cuáles son los requisitos mínimos (requirements) para el despliegue local de Kimi K2.5?
Para una solución de compresión extrema, se necesita: 1 GPU con 24GB de VRAM + 256GB de memoria de sistema + 240GB de espacio en disco. Sin embargo, en esta configuración, la velocidad de inferencia es de apenas 1-2 tokens/s. La configuración recomendada es de 2×H100 u 8×A100, utilizando cuantización INT4 para alcanzar un rendimiento de nivel de producción.
Q3: ¿Cómo puedo validar rápidamente las capacidades de Kimi K2.5?
No es necesario realizar un despliegue local; puedes probarlo rápidamente a través de la API:
- Visita APIYI apiyi.com y registra una cuenta.
- Obtén tu API Key y saldo gratuito.
- Utiliza el ejemplo de código de este artículo, introduciendo
kimi-k2.5como nombre del modelo. - Experimenta la capacidad de razonamiento profundo del modo Thinking.
Resumen
Estos son los puntos clave del artículo técnico de Kimi K2.5:
- Innovaciones principales del Paper de Kimi K2.5: Arquitectura MoE de 384 expertos + atención MLA + optimizador MuonClip, logrando un entrenamiento de un billón de parámetros sin picos de pérdida.
- Parámetros clave (Parameters) de Kimi K2.5: 1 billón de parámetros totales, 32 mil millones de parámetros activos, 61 capas, 256K de contexto; solo se activa el 3.2% de los parámetros en cada inferencia.
- Requisitos de despliegue (Requirements) de Kimi K2.5: El umbral para el despliegue local es elevado (mínimo 240GB+), por lo que el acceso vía API resulta la opción más práctica.
Kimi K2.5 ya está disponible en APIYI apiyi.com. Te recomendamos validar las capacidades del modelo a través de su API para evaluar si se ajusta a tus necesidades de negocio.
Referencias
⚠️ Nota sobre el formato de los enlaces: Todos los enlaces externos utilizan el formato
Nombre del recurso: dominio.com, lo que facilita la copia pero evita clics directos para prevenir la pérdida de autoridad SEO.
-
Artículo de arXiv de Kimi K2: Informe técnico oficial que detalla la arquitectura y los métodos de entrenamiento.
- Enlace:
arxiv.org/abs/2507.20534 - Descripción: Obtén los detalles técnicos completos y los datos experimentales.
- Enlace:
-
Blog técnico de Kimi K2.5: Informe técnico oficial publicado sobre K2.5.
- Enlace:
kimi.com/blog/kimi-k2-5.html - Descripción: Conoce más sobre Agent Swarm y sus capacidades multimodales.
- Enlace:
-
Tarjeta de modelo en HuggingFace: Pesos del modelo e instrucciones de uso.
- Enlace:
huggingface.co/moonshotai/Kimi-K2.5 - Descripción: Descarga los pesos del modelo y consulta la guía de despliegue.
- Enlace:
-
Guía de despliegue local de Unsloth: Tutorial detallado sobre despliegue con cuantización.
- Enlace:
unsloth.ai/docs/models/kimi-k2.5 - Descripción: Conoce los requisitos de hardware para las distintas precisiones de cuantización.
- Enlace:
Autor: Equipo Técnico
Intercambio Técnico: Te invitamos a discutir los detalles técnicos de Kimi K2.5 en la sección de comentarios. Para más análisis de modelos, puedes visitar la comunidad técnica de APIYI apiyi.com.