作者注:深度解读 Kimi K2.5 技术论文核心内容,详解 1T 参数 MoE 架构、384 专家配置、MLA 注意力机制,并提供本地部署硬件要求和 API 接入方案对比
想了解 Kimi K2.5 的技术细节?本文基于 Kimi K2.5 官方技术论文,系统解读其万亿参数 MoE 架构、训练方法和基准测试结果,并详细说明本地部署的硬件要求。
核心价值:读完本文,你将掌握 Kimi K2.5 的核心技术参数、架构设计原理,以及根据硬件条件选择最佳部署方案的能力。
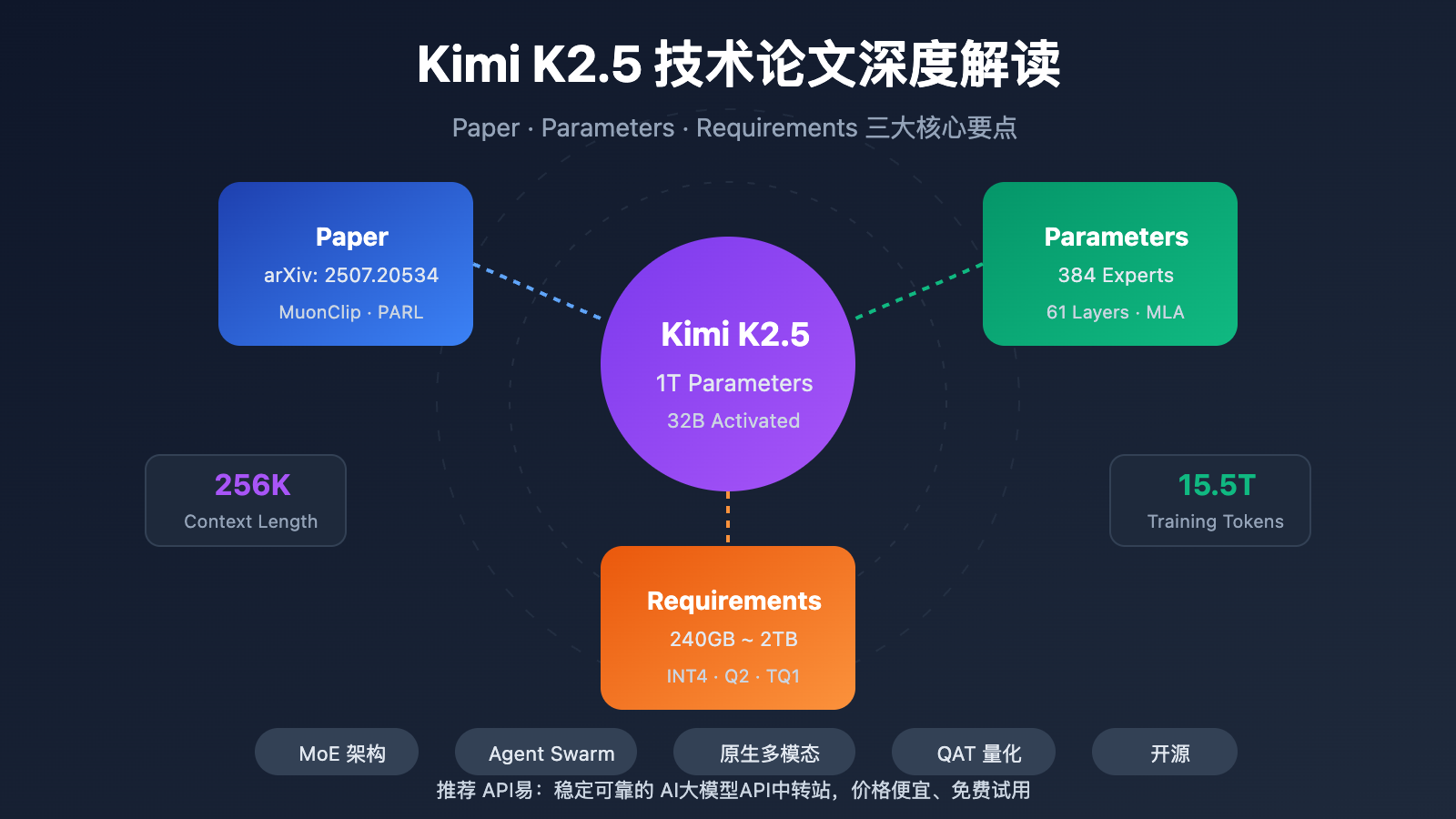
Kimi K2.5 Paper 技术论文核心要点
| 要点 | 技术细节 | 创新价值 |
|---|---|---|
| 万亿参数 MoE | 1T 总参数,32B 激活参数 | 推理时仅激活 3.2%,效率极高 |
| 384 专家系统 | 每 Token 选 8 专家 + 1 共享专家 | 比 DeepSeek-V3 多 50% 专家 |
| MLA 注意力 | Multi-head Latent Attention | 减少 KV Cache,支持 256K 上下文 |
| MuonClip 优化器 | Token 高效训练,零 Loss Spike | 15.5T Token 训练无损失尖峰 |
| 原生多模态 | MoonViT 400M 视觉编码器 | 15T 视觉-文本混合训练 |
Kimi K2.5 Paper 论文背景
Kimi K2.5 技术论文由月之暗面 (Moonshot AI) 团队发布,arXiv 编号为 2507.20534。论文详细介绍了从 Kimi K2 到 K2.5 的技术演进,核心贡献包括:
- 超稀疏 MoE 架构:384 专家配置,比 DeepSeek-V3 的 256 专家多 50%
- MuonClip 训练优化:解决大规模训练中的 Loss Spike 问题
- Agent Swarm 范式:PARL (Parallel-Agent Reinforcement Learning) 训练方法
- 原生多模态融合:从预训练阶段就整合视觉-语言能力
论文指出,随着高质量人类数据日益稀缺,Token 效率正成为大模型扩展的关键系数,这推动了 Muon 优化器和合成数据生成的应用。
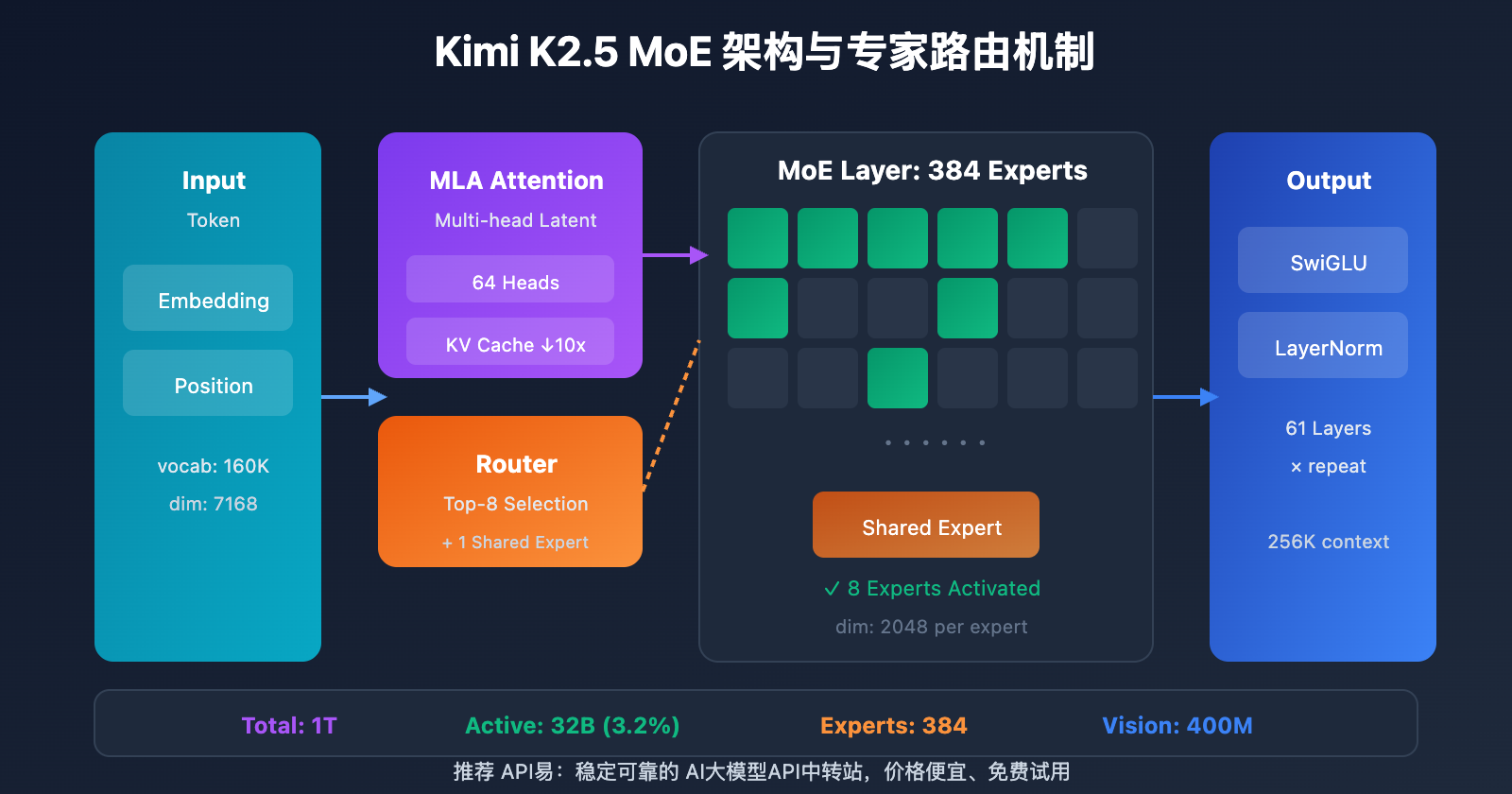
Kimi K2.5 Parameters 完整参数规格
核心架构参数
| 参数类别 | 参数名 | 数值 | 说明 |
|---|---|---|---|
| 规模 | 总参数量 | 1T (1.04 万亿) | 完整模型大小 |
| 规模 | 激活参数 | 32B | 单次推理实际使用 |
| 结构 | 层数 | 61 层 | 含 1 个 Dense 层 |
| 结构 | 隐藏维度 | 7168 | 模型主干维度 |
| MoE | 专家数量 | 384 | 比 DeepSeek-V3 多 128 |
| MoE | 激活专家 | 8 + 1 共享 | Top-8 路由选择 |
| MoE | 专家隐藏维度 | 2048 | 每个专家的 FFN 维度 |
| 注意力 | 注意力头数 | 64 | 比 DeepSeek-V3 少一半 |
| 注意力 | 机制类型 | MLA | Multi-head Latent Attention |
| 其他 | 词汇表大小 | 160K | 支持多语言 |
| 其他 | 上下文长度 | 256K | 超长文档处理 |
| 其他 | 激活函数 | SwiGLU | 高效非线性变换 |
Kimi K2.5 Parameters 设计解读
为什么选择 384 专家?
论文中的 Scaling Law 分析表明,持续增加稀疏性能带来显著的性能提升。团队将专家数从 DeepSeek-V3 的 256 增加到 384,提升了模型的表示能力。
为什么减少注意力头?
为了降低推理时的计算开销,注意力头数从 128 减少到 64。结合 MLA 机制,这一设计在保持性能的同时大幅减少了 KV Cache 的内存占用。
MLA 注意力机制优势:
传统 MHA: KV Cache = 2 × L × H × D × B
MLA: KV Cache = 2 × L × C × B (C << H × D)
L = 层数, H = 头数, D = 维度, B = Batch, C = 压缩维度
MLA 通过潜在空间压缩,将 KV Cache 减少约 10 倍,使 256K 上下文成为可能。
视觉编码器参数
| 组件 | 参数 | 数值 |
|---|---|---|
| 名称 | MoonViT | 自研视觉编码器 |
| 参数量 | – | 400M |
| 特性 | 时空池化 | 视频理解支持 |
| 集成方式 | 原生融合 | 预训练阶段整合 |
Kimi K2.5 Requirements 部署硬件要求
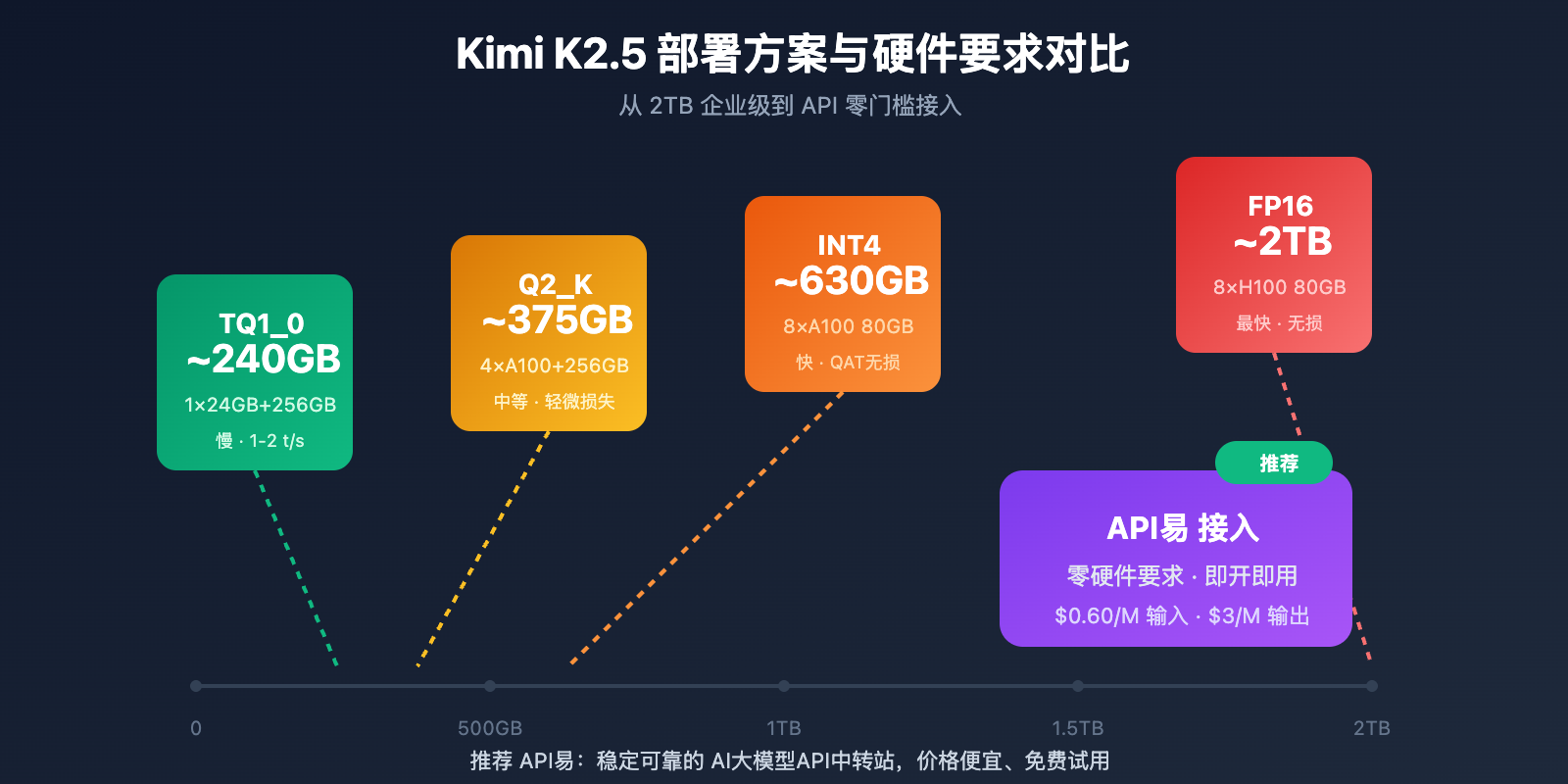
本地部署硬件需求
| 量化精度 | 存储需求 | 最低硬件 | 推理速度 | 精度损失 |
|---|---|---|---|---|
| FP16 | ~2TB | 8×H100 80GB | 最快 | 无 |
| INT4 (QAT) | ~630GB | 8×A100 80GB | 快 | 几乎无损 |
| Q2_K_XL | ~375GB | 4×A100 + 256GB RAM | 中等 | 轻微 |
| TQ1_0 (1.58-bit) | ~240GB | 1×24GB GPU + 256GB RAM | 慢 (1-2 t/s) | 明显 |
Kimi K2.5 Requirements 详细说明
企业级部署 (推荐)
硬件配置: 2× NVIDIA H100 80GB 或 8× A100 80GB
存储需求: 630GB+ (INT4 量化)
预期性能: 50-100 tokens/s
适用场景: 生产环境、高并发服务
极限压缩部署
硬件配置: 1× RTX 4090 24GB + 256GB 系统内存
存储需求: 240GB (1.58-bit 量化)
预期性能: 1-2 tokens/s
适用场景: 研究测试、功能验证
注意事项: MoE 层完全卸载到 RAM,速度较慢
为什么需要这么多内存?
虽然 MoE 架构每次推理只激活 32B 参数,但模型需要将完整的 1T 参数保持在内存中,以便根据输入动态路由到正确的专家。这是 MoE 模型的固有特性。
更实用的方案:API 接入
对于大多数开发者,本地部署 Kimi K2.5 的硬件门槛较高。通过 API 接入是更实用的选择:
| 方案 | 成本 | 优势 |
|---|---|---|
| API易 (推荐) | $0.60/M 输入,$3/M 输出 | 统一接口,多模型切换,免费额度 |
| 官方 API | 同上 | 功能最全,第一时间更新 |
| 本地 1-bit | 硬件成本 + 电费 | 数据本地化 |
部署建议:除非有严格的数据本地化要求,建议通过 API易 apiyi.com 接入 Kimi K2.5,避免高昂的硬件投入。
Kimi K2.5 Paper 基准测试结果
核心能力评测
| 基准测试 | Kimi K2.5 | GPT-5.2 | Claude Opus 4.5 | 说明 |
|---|---|---|---|---|
| AIME 2025 | 96.1% | – | – | 数学竞赛 (avg@32) |
| HMMT 2025 | 95.4% | 93.3% | – | 数学竞赛 (avg@32) |
| GPQA-Diamond | 87.6% | – | – | 科学推理 (avg@8) |
| SWE-Bench Verified | 76.8% | – | 80.9% | 代码修复 |
| SWE-Bench Multi | 73.0% | – | – | 多语言代码 |
| HLE-Full | 50.2% | – | – | 综合推理 (with tools) |
| BrowseComp | 60.2% | 54.9% | 24.1% | 网页交互 |
| MMMU-Pro | 78.5% | – | – | 多模态理解 |
| MathVision | 84.2% | – | – | 视觉数学 |
训练数据与方法
| 阶段 | 数据量 | 方法 |
|---|---|---|
| K2 Base 预训练 | 15.5T tokens | MuonClip 优化器,零 Loss Spike |
| K2.5 继续预训练 | 15T 视觉-文本混合 | 原生多模态融合 |
| Agent 训练 | – | PARL (并行 Agent 强化学习) |
| 量化训练 | – | QAT (量化感知训练) |
论文特别强调,MuonClip 优化器使得整个 15.5T Token 的预训练过程 完全没有出现 Loss Spike,这在万亿参数规模的训练中是重要突破。
Kimi K2.5 快速接入示例
极简调用代码
通过 API易 平台,10 行代码即可调用 Kimi K2.5:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY", # 在 apiyi.com 获取
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "解释 MoE 架构的工作原理"}]
)
print(response.choices[0].message.content)
查看 Thinking 模式调用代码
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Thinking 模式 - 深度推理
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "system", "content": "你是 Kimi,请详细分析问题"},
{"role": "user", "content": "证明根号2是无理数"}
],
temperature=1.0, # Thinking 模式推荐
top_p=0.95,
max_tokens=8192
)
# 获取推理过程和最终答案
reasoning = getattr(response.choices[0].message, "reasoning_content", None)
answer = response.choices[0].message.content
if reasoning:
print(f"推理过程:\n{reasoning}\n")
print(f"最终答案:\n{answer}")
建议:通过 API易 apiyi.com 获取免费测试额度,体验 Kimi K2.5 的 Thinking 模式深度推理能力。
常见问题
Q1: Kimi K2.5 paper 技术论文在哪里可以获取?
Kimi K2 系列的官方技术论文发布在 arXiv,编号为 2507.20534,可通过 arxiv.org/abs/2507.20534 访问。Kimi K2.5 的技术报告发布在官方博客 kimi.com/blog/kimi-k2-5.html。
Q2: Kimi K2.5 本地部署的最低 requirements 是什么?
极限压缩方案需要:1 张 24GB 显存 GPU + 256GB 系统内存 + 240GB 存储空间。但这种配置下推理速度仅 1-2 tokens/s。推荐配置是 2×H100 或 8×A100,使用 INT4 量化可达到生产级性能。
Q3: 如何快速验证 Kimi K2.5 的能力?
无需本地部署,通过 API 即可快速测试:
- 访问 API易 apiyi.com 注册账号
- 获取 API Key 和免费额度
- 使用本文代码示例,模型名填
kimi-k2.5 - 体验 Thinking 模式的深度推理能力
总结
Kimi K2.5 技术论文的核心要点:
- Kimi K2.5 Paper 核心创新:384 专家 MoE 架构 + MLA 注意力 + MuonClip 优化器,实现万亿参数无损失尖峰训练
- Kimi K2.5 Parameters 关键参数:1T 总参数、32B 激活参数、61 层、256K 上下文,每次推理仅激活 3.2% 参数
- Kimi K2.5 Requirements 部署要求:本地部署门槛高(最低 240GB+),API 接入是更实用的选择
Kimi K2.5 已上线 API易 apiyi.com,建议通过 API 快速验证模型能力,评估是否适合你的业务场景。
参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
Kimi K2 arXiv 论文: 官方技术报告,详解架构和训练方法
- 链接:
arxiv.org/abs/2507.20534 - 说明: 获取完整的技术细节和实验数据
- 链接:
-
Kimi K2.5 技术博客: 官方发布的 K2.5 技术报告
- 链接:
kimi.com/blog/kimi-k2-5.html - 说明: 了解 Agent Swarm 和多模态能力
- 链接:
-
HuggingFace 模型卡: 模型权重和使用说明
- 链接:
huggingface.co/moonshotai/Kimi-K2.5 - 说明: 下载模型权重,查看部署指南
- 链接:
-
Unsloth 本地部署指南: 量化部署详细教程
- 链接:
unsloth.ai/docs/models/kimi-k2.5 - 说明: 了解各种量化精度的硬件要求
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区讨论 Kimi K2.5 的技术细节,更多模型解读可访问 API易 apiyi.com 技术社区