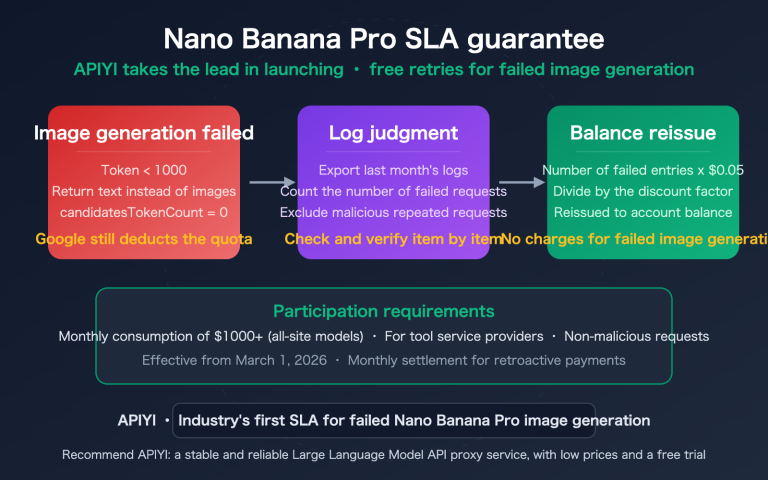
Gemini 3.1 Pro Preview and Gemini 3.0 Pro Preview are priced exactly the same—Input $2.00, Output $12.00 / million tokens. So the question is: where exactly is 3.1 better than 3.0? Is it worth the switch?
The answer is: Absolutely, and there's really no reason not to switch.
In this post, we'll use real benchmark data to compare the differences between the two versions. Spoiler alert—the ARC-AGI-2 reasoning score for 3.1 Pro skyrocketed from 31.1% to 77.1%, a 2.5x increase; SWE-Bench coding improved from 76.8% to 80.6%; and BrowseComp search jumped from 59.2% to 85.9%. This isn't just a minor tweak; it's a generational leap.
Core Value: By the end of this article, you'll have a clear understanding of every specific improvement in 3.1 Pro compared to 3.0 Pro, and how to choose between them for different scenarios.

Gemini 3.1 Pro vs. 3.0 Pro: Comparison Table
First, let's look at the differences in technical specs:
| Dimension | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | Change |
|---|---|---|---|
| Model ID | gemini-3-pro-preview |
gemini-3.1-pro-preview |
New Version |
| Release Date | Nov 18, 2025 | Feb 19, 2026 | +3 Months |
| Input Price (≤200K) | $2.00 / M tokens | $2.00 / M tokens | Unchanged |
| Output Price (≤200K) | $12.00 / M tokens | $12.00 / M tokens | Unchanged |
| Input Price (>200K) | $4.00 / M tokens | $4.00 / M tokens | Unchanged |
| Output Price (>200K) | $18.00 / M tokens | $18.00 / M tokens | Unchanged |
| Context Window | 1M tokens | 1M tokens | Unchanged |
| Max Output | — | 65K tokens | Clear Improvement |
| File Upload Limit | 20MB | 100MB | 5x Increase |
| YouTube URL Support | ❌ | ✅ | New |
| Thinking Levels | 2 levels (low/high) | 3 levels (low/medium/high) | New Medium Level |
| customtools Endpoint | ❌ | ✅ | New |
| Knowledge Cutoff | Jan 2025 | Jan 2025 | Unchanged |
Price, context window, and knowledge cutoff remain exactly the same. All changes are pure capability enhancements.
🎯 Core Conclusion: You don't pay a penny more, but you get significantly more features. Technically speaking, 3.1 Pro is a strict upgrade over 3.0 Pro. When calling via APIYI (apiyi.com), simply change the
modelparameter fromgemini-3-pro-previewtogemini-3.1-pro-previewto complete the upgrade.
差异 1: 推理能力——从「优秀」到「顶尖」
这是 3.0 → 3.1 最大的改进,也是谷歌官方最强调的升级点。
| 推理基准 | 3.0 Pro | 3.1 Pro | 提升幅度 | 说明 |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | 全新逻辑模式推理 |
| GPQA Diamond | — | 94.3% | — | 研究生级科学推理 |
| MMMLU | — | 92.6% | — | 多学科多模态理解 |
| LiveCodeBench Pro | — | Elo 2887 | — | 实时编程竞赛 |
ARC-AGI-2 的提升最为惊人: 从 31.1% 到 77.1%,不是翻倍而是翻了 2.5 倍。这个基准测试评估的是模型解决全新逻辑模式的能力——即模型从未见过的推理题型。77.1% 的分数也超越了 Claude Opus 4.6 的 68.8%,在推理维度上确立了领先地位。
背后的技术原因: 谷歌官方将 3.1 Pro 描述为拥有「unprecedented depth and nuance」(前所未有的深度和细腻度),而 3.0 Pro 的描述是「advanced intelligence」(高级智能)。这不仅是营销措辞的变化,ARC-AGI-2 的数据证明了推理深度确实有质的飞跃。
差异 2: 思考级别系统——从 2 级到 3 级
这是 3.1 Pro 最具实操意义的改进之一。
3.0 Pro 的思考系统 (2 级)
| 级别 | 行为 |
|---|---|
| low | 最小推理,快速响应 |
| high | 深度推理,较高延迟 |
3.1 Pro 的思考系统 (3 级)
| 级别 | 行为 | 对应关系 |
|---|---|---|
| low | 最小推理,快速响应 | 类似 3.0 的 low |
| medium (新增) | 适度推理,平衡速度和质量 | ≈ 3.0 的 high |
| high | Deep Think Mini 模式,最深推理 | 远超 3.0 的 high |
关键信息: 3.1 Pro 的 medium ≈ 3.0 Pro 的 high。这意味着:
- 用 3.1 的 medium 就能获得 3.0 最高级别的推理质量
- 3.1 的 high 是全新档次——类似 Gemini Deep Think 的迷你版
- 同样的推理质量 (medium),延迟比 3.0 的 high 更低
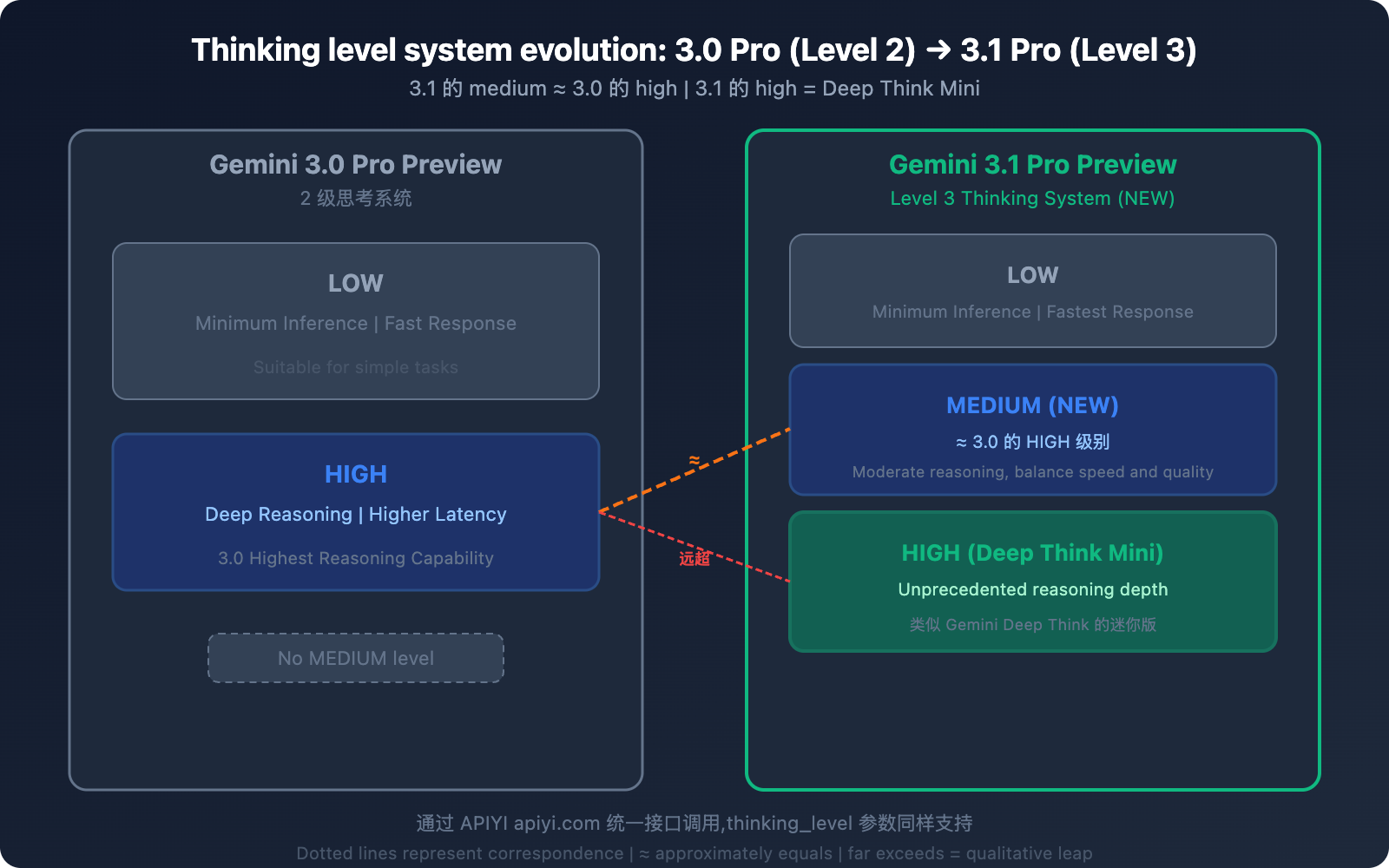
💡 实战建议: 如果你之前一直用 3.0 Pro 的 high 模式,切换到 3.1 Pro 后建议先用 medium——推理质量相当,但延迟更低。只在遇到真正复杂的推理任务时才切换到 high (Deep Think Mini),这样可以在不增加成本的前提下获得更好的整体体验。APIYI apiyi.com 平台支持传递 thinking_level 参数。
Difference 3: Coding Capabilities—Joining the Top Tier
| Coding Benchmark | 3.0 Pro | 3.1 Pro | Improvement | Industry Comparison |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | Agent Terminal Coding |
| LiveCodeBench Pro | — | Elo 2887 | — | Real-time Programming Competitions |
On the surface, the SWE-Bench Verified improvement is only 3.8 percentage points (76.8% → 80.6%), but at this scoring level, every 1% gain is incredibly tough. This 80.6% score narrows the gap between Gemini 3.1 Pro and Claude Opus 4.6 (80.9%) to just 0.3%—moving it from "leading the second tier" to "standing shoulder-to-shoulder with the first tier."
The jump in Terminal-Bench 2.0 is even more striking: 56.9% → 68.5%, a 20.4% relative improvement. This benchmark specifically evaluates an Agent's ability to execute coding tasks in a terminal environment. An 11.6 percentage point increase means 3.1 Pro's reliability in automated programming scenarios has been significantly bolstered.
Difference 4: Agent and Search Capabilities—A Quantum Leap
| Agent Benchmark | 3.0 Pro | 3.1 Pro | Improvement |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
These two benchmarks show the most dramatic improvements from 3.0 to 3.1:
BrowseComp evaluates an Agent's web search capabilities—it skyrocketed from 59.2% to 85.9%, a 26.7 percentage point jump. This is a big deal for building research assistants, competitive analysis tools, or any Agent that needs real-time information retrieval.
MCP Atlas measures multi-step workflow capabilities using the Model Context Protocol—rising from 54.1% to 69.2%. MCP is the Agent protocol standard pushed by Google, and this boost shows that 3.1 Pro's coordination and execution in complex Agent workflows have been significantly enhanced.
Dedicated customtools endpoint: 3.1 Pro also introduces the gemini-3.1-pro-preview-customtools endpoint, specifically optimized for scenarios mixing bash commands and custom function calls. This endpoint fine-tunes the priority for common developer tools like view_file and search_code, making it more stable and reliable for Agent scenarios like automated O&M or AI coding assistants compared to the general-purpose endpoint.
🎯 Note for Agent Developers: If you're building code review bots, automated deployment Agents, or similar tools, I highly recommend using the
customtoolsendpoint. You can call this directly via APIYI (apiyi.com) by setting the model parameter togemini-3.1-pro-preview-customtools.
Difference 5: Output Capabilities and API Features
| Feature | 3.0 Pro | 3.1 Pro | Change |
|---|---|---|---|
| Max Output Tokens | Not specified | 65,000 | Explicitly 65K |
| File Upload Limit | 20MB | 100MB | 5x Increase |
| YouTube URL | ❌ Not supported | ✅ Direct Pass-through | New |
| customtools Endpoint | ❌ | ✅ | New |
| Output Efficiency | Baseline | +15% | Fewer tokens, better results |
65K Output Limit: You can now generate full-length documents, massive code blocks, or detailed analysis reports in one go without having to stitch together multiple requests.
100MB File Upload: Expanding from 20MB to 100MB means you can directly upload larger code repositories, PDF collections, or media files for analysis.
Direct YouTube URL Pass-through: Just drop a YouTube link into your prompt, and the model will automatically parse and analyze the video content—no downloading, transcoding, or manual uploading required.
15% Output Efficiency Boost: Real-world feedback from the JetBrains AI Director shows that 3.1 Pro produces more reliable results with fewer tokens. This means for the same task, your actual token consumption is lower, making it more cost-effective.
Value of Features for Different Users
| Feature | Value for Individual Developers | Value for Enterprise Teams |
|---|---|---|
| 65K Output | Generate complete code files at once | Batch generate technical docs and reports |
| 100MB Upload | Upload entire projects for analysis | Large-scale codebase audits |
| YouTube URL | Quickly analyze tutorial videos | Competitor product demo analysis |
| customtools | AI coding assistant development | Automated DevOps Agents |
| +15% Efficiency | Lower personal API costs | Significant cost optimization at scale |
💰 Cost Test: In identical tasks, 3.1 Pro's actual output token consumption is 10-15% lower on average than 3.0 Pro. For enterprise apps hitting millions of tokens daily, switching could save hundreds of dollars a month. You can track this precisely using the usage stats on APIYI (apiyi.com).
Difference 6: Output Efficiency—Better Results with Fewer Tokens
This is an improvement that's easy to overlook but has a huge practical impact. Feedback from JetBrains AI Director Vladislav Tankov indicates that 3.1 Pro offers a 15% quality boost while consuming fewer output tokens compared to 3.0 Pro.
What does this actually mean?
Lower actual usage costs: Even though the unit price is the same, 3.1 Pro uses fewer tokens to finish the same task, so your actual bill will be lower. For an app using 1 million output tokens a day, a 15% efficiency gain saves about $1.80 in output fees daily.
Faster response times: Fewer output tokens mean shorter generation times. This is a big win for latency-sensitive real-time apps.
More concise output quality: 3.1 Pro isn't just "saying less"; it's "saying it better." It conveys the same or even more information using more compact language, cutting out the fluff and redundancy.
Difference 7: Safety and Reliability
| Safety Dimension | 3.0 Pro | 3.1 Pro | Change |
|---|---|---|---|
| Text Safety | Baseline | +0.10% | Slight improvement |
| Multilingual Safety | Baseline | +0.11% | Slight improvement |
| False Refusal Rate | Baseline | Maintains low level | Unchanged |
| Long-task Stability | Baseline | Improved | More reliable |
While the safety improvements aren't massive in terms of raw numbers, the direction is spot on—boosting capabilities without sacrificing safety. The boost in long-task stability is particularly crucial for Agent applications, meaning 3.1 Pro is less likely to "go off the rails" or generate unreliable outputs during multi-step workflows.
Difference 8: Changes in Official Positioning Descriptions
| Dimension | 3.0 Pro Description | 3.1 Pro Description |
|---|---|---|
| Core Positioning | advanced intelligence | unprecedented depth and nuance |
| Reasoning Features | advanced reasoning | SOTA reasoning |
| Coding Features | agentic and vibe coding | powerful coding |
| Multimodal | multimodal understanding | powerful multimodal understanding |
Moving from "advanced" to "unprecedented," and from "agentic and vibe coding" to "powerful coding"—these wording shifts reflect a clear upgrade in positioning. While 3.0 Pro focused on being "advanced" and "innovative" (vibe coding), 3.1 Pro doubles down on "depth" and "power."
Difference 9: Usage Recommendations—Which One Should You Use?

Migration Code Example
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI Unified Interface
)
# 3.0 Pro → 3.1 Pro: Just swap one parameter
# Old: model="gemini-3-pro-preview"
# New: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # The only line you need to touch
messages=[{"role": "user", "content": "Analyze the performance bottlenecks in this code"}]
)
View A/B Comparison Test Code
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI Unified Interface
)
test_prompt = "Given the array [3,1,4,1,5,9,2,6], use merge sort and analyze the time complexity"
# Testing 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# Testing 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\n3.0 Response:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\n3.1 Response:\n{resp_31.choices[0].message.content[:300]}...")
Migration Notes and Best Practices
Step 1: Test Core Scenarios
Compare the outputs of 3.0 and 3.1 using your 3-5 most common prompts. Focus on reasoning quality, code accuracy, and output formatting.
Step 2: Adjust Thinking Levels
If you previously used the "high" mode in 3.0, try starting with "medium" in 3.1 (the reasoning quality is comparable but it's faster). Only use "high" (Deep Think Mini) when you truly need deep reasoning.
Step 3: Explore New Capabilities
Try out 3.1-exclusive features like 100MB file uploads, YouTube URL analysis, and 65K long outputs. You might discover entirely new use cases.
Step 4: Full Switch
Once you've confirmed the results, update all calls from gemini-3-pro-preview to gemini-3.1-pro-preview. It's a good idea to keep 3.0 as a fallback until 3.1 has been running stably in your environment for at least a week.
🚀 Quick Migration: On the APIYI (apiyi.com) platform, migrating from 3.0 to 3.1 is as simple as changing one parameter. We recommend running A/B tests on a few core scenarios first, then doing a full switch.
FAQ
Q1: Are 3.1 Pro and 3.0 Pro fully compatible? Do I need to change my prompts after switching?
The API interface is fully compatible; you only need to change the model parameter. However, since 3.1 Pro has improved reasoning methods, some finely-tuned prompts might behave slightly differently—usually better, but we recommend performing regression tests on core scenarios. You can use APIYI (apiyi.com) to call both versions simultaneously for comparison.
Q2: Will 3.0 Pro continue to be maintained? When will it be deprecated?
As a Preview model, Google typically provides at least 2 weeks' notice before deprecation. While 3.0 Pro is still available, 3.1 Pro is a strict superior upgrade in almost every dimension, so we recommend migrating early. Calling through APIYI (apiyi.com) protects you from version adjustments on Google's side, as the platform handles model routing automatically.
Q3: Does the “high” thinking mode in 3.1 Pro consume a lot of tokens?
The "high" mode (Deep Think Mini) does consume more output tokens because the model generates a deeper internal reasoning chain. We suggest using "medium" (equivalent to 3.0's "high" quality) for daily tasks and reserving "high" for mathematical reasoning or complex debugging. This helps maintain or even reduce costs for most tasks.
Q4: Are both versions available on APIYI?
Yes, both are available. APIYI (apiyi.com) supports both gemini-3-pro-preview and gemini-3.1-pro-preview using the same API Key and base_url, making it easy to perform A/B testing and switch flexibly.
Gemini 3.1 Pro Upgrade Advice for Different Users
Different types of developers will see different gains from the 3.0 → 3.1 upgrade. Here are some specific recommendations:
| User Type | Most Beneficial Difference | Upgrade Priority | Recommended Action |
|---|---|---|---|
| AI Agent Developers | Agent/Search +45%, MCP Atlas +28% | ⭐⭐⭐⭐⭐ | Switch immediately; the improvement is most noticeable here. |
| Coding Assistant Tools | SWE-Bench +5%, Terminal-Bench +20% | ⭐⭐⭐⭐ | Recommended switch; using "medium" mode is sufficient. |
| Data Analysts | Reasoning ARC-AGI-2 +148%, 100MB uploads | ⭐⭐⭐⭐⭐ | Priority switch; big file analysis capabilities are significantly boosted. |
| Content Creators | 65K long output, YouTube URL analysis | ⭐⭐⭐⭐ | Recommended switch; the new features are super practical. |
| Lightweight API Users | Output efficiency +15%, cost unchanged | ⭐⭐⭐ | Switch whenever you like; it's better performance for the same price. |
| Security-Sensitive Apps | Improved safety/reliability, long-task stability | ⭐⭐⭐⭐ | Run regression tests before switching. |
💡 General Advice: No matter what type of user you are, you can use APIYI (apiyi.com) to keep both 3.0 and 3.1 versions active simultaneously. Run A/B tests to confirm the results before fully committing. Zero migration cost, zero risk.
Gemini 3.1 Pro Version Switching Decision Flow
Follow these steps to decide if you should switch:
- Does your app rely on reasoning accuracy? → Yes → Switch immediately (ARC-AGI-2 improved by 148%).
- Does your app involve Agents or Search? → Yes → Highly recommended (BrowseComp +45%).
- Are your prompts highly customized? → Yes → Test with "medium" mode first, then switch once you've confirmed the output is consistent.
- Do you only handle simple Q&A or translation? → Yes → Switch anytime; performance is at least equal and efficiency is higher.
- Not sure? → Run an A/B test with 5 core prompts on APIYI (apiyi.com) and get your answer in 10 minutes.
Summary: 9 Key Differences
| # | Dimension | 3.0 Pro → 3.1 Pro | Switching Value |
|---|---|---|---|
| 1 | Reasoning | ARC-AGI-2: 31.1% → 77.1% | Extremely High |
| 2 | Thinking System | Level 2 → Level 3 (incl. Deep Think Mini) | High |
| 3 | Coding | SWE-Bench: 76.8% → 80.6% | High |
| 4 | Agent/Search | BrowseComp: 59.2% → 85.9% | Extremely High |
| 5 | Output/API Features | 65K output, 100MB upload, YouTube URL | High |
| 6 | Output Efficiency | Better results with fewer tokens (+15%) | High |
| 7 | Safety & Reliability | Slight safety boost, better long-task stability | Medium |
| 8 | Official Positioning | advanced → unprecedented depth | Signal |
| 9 | Use Cases | Should switch for almost all scenarios | Clear |
The Bottom Line: Same price, API compatible, and every metric is stronger—Gemini 3.1 Pro Preview is a free generational upgrade for 3.0 Pro Preview. There's really no reason not to switch.
We recommend migrating quickly via APIYI (apiyi.com); you just need to update a single model parameter.
References
-
Google Official Blog: Gemini 3.1 Pro Launch Announcement
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Description: Official benchmarks and feature overview
- Link:
-
Google DeepMind Model Card: 3.1 Pro Technical Details and Safety Assessment
- Link:
deepmind.google/models/model-cards/gemini-3-1-pro - Description: Safety data and detailed parameters
- Link:
-
VentureBeat First Look: Deep Dive into Deep Think Mini Features
- Link:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Description: Hands-on report of the three-level thinking system
- Link:
-
Artificial Analysis: 3.1 Pro vs 3.0 Pro Comparison Data
- Link:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - Description: Third-party benchmark comparisons and performance analysis
- Link:
📝 Author: APIYI Team | For technical discussions, visit APIYI at apiyi.com
📅 Updated: February 20, 2026
🏷️ Keywords: Gemini 3.1 Pro vs 3.0 Pro, Model Comparison, Doubled Reasoning, SWE-Bench, ARC-AGI-2, Deep Think Mini