Banyak tim yang secara otomatis memindahkan semua trafik Gemini mereka ke Gemini 3.5 Flash setelah GA pada 19 Mei 2026, termasuk untuk tugas-tugas ringan berfrekuensi tinggi seperti penerjemahan, pembuatan subtitle, dan moderasi konten. Ini sebenarnya adalah penilaian yang kurang tepat. Untuk skenario seperti penerjemahan yang input-outputnya tidak panjang, sangat sensitif terhadap harga satuan, sangat sensitif terhadap latensi, dan tidak memerlukan orkestrasi alat (Agent), Gemini 3.1 Flash-Lite adalah solusi yang jauh lebih optimal dibandingkan Gemini 3.5 Flash yang lebih mahal dan "serba bisa". Artikel ini membandingkan kedua model tersebut secara sistematis dari 6 dimensi, dengan data yang bersumber langsung dari model card resmi Google DeepMind, LLM-Stats, Artificial Analysis, dan sumber tepercaya lainnya.

Kesimpulan singkatnya: Untuk skenario ringan seperti penerjemahan, subtitle, klasifikasi batch, dan normalisasi teks, saya merekomendasikan Gemini 3.1 Flash-Lite, bukan Gemini 3.5 Flash. Alasannya ada enam: input 6 kali lebih murah, output 6 kali lebih murah, latensi token pertama 2,5 kali lebih cepat, skor multibahasa MMMLU mencapai 88,9%, penerjemahan secara resmi dikategorikan Google sebagai sweet spot-nya, dan keunggulan Agent pada 3.5 Flash sama sekali tidak terpakai dalam penerjemahan. Saya sarankan untuk mencoba menjalankan serangkaian tugas penerjemahan nyata melalui kredit gratis 0,05 USD di APIYI apiyi.com untuk perbandingan langsung; perbedaan biaya dan kualitas aktual akan jauh lebih terlihat dibandingkan angka benchmark.
Mengapa Gemini 3.1 Flash-Lite Lebih Kompeten daripada Gemini 3.5 Flash untuk Penerjemahan
Karakteristik tugas penerjemahan sangat jelas: input berupa teks pendek bahasa sumber (ratusan hingga ribuan token), output berupa teks pendek bahasa target, dan pemanggilan tunggal tidak memerlukan alur berpikir, pemanggilan alat, atau integrasi multimodal. Namun, frekuensi pemanggilan sangat tinggi dan sangat sensitif terhadap biaya serta latensi. Inilah skenario yang memang dirancang Google untuk seri Flash-Lite.
Gemini 3.1 Flash-Lite dirilis pada 3 Maret 2026. Dalam blog resmi Google, disebutkan bahwa ini adalah "model AI kami yang paling hemat biaya hingga saat ini", dan secara eksplisit mencantumkan "penerjemahan masif, klasifikasi konten, moderasi, ekstraksi data terstruktur, dan tugas agen berulang" sebagai sweet spot-nya. Model card dari DeepMind lebih lanjut menunjukkan bahwa model ini memiliki "kemampuan penerjemahan dan pemahaman multibahasa terbaik di kelasnya, dengan peningkatan yang dicatat pada skrip non-Latin", dengan skor benchmark multibahasa MMMLU sebesar 88,9%, menjadikannya pemimpin mutlak di kelas ringan.
Gemini 3.5 Flash adalah Agentic Flash yang dirilis pada 19 Mei, dengan posisi sebagai "orkestrasi alat Agent + andalan coding", yang melampaui Gemini 3.1 Pro dalam Terminal-Bench 2.1, MCP Atlas, dan Finance Agent v2. Namun, kemampuan Agent ini sama sekali tidak terpakai dalam tugas penerjemahan. Premi yang Anda bayarkan untuk kemampuan tersebut hanyalah pemborosan. Itulah sebabnya seri "Flash" dibagi lagi berdasarkan jenis tugas: gunakan 3.5 Flash untuk Agent, dan 3.1 Flash-Lite untuk penerjemahan/klasifikasi/moderasi.
🎯 Saran Inti Pemilihan Model: Jangan terkecoh dengan intuisi bahwa "nomor versi lebih besar berarti lebih baik". Gemini 3.5 Flash (rilis Mei) dan Gemini 3.1 Flash-Lite (rilis Maret) adalah dua lini produk paralel yang masing-masing mencakup segmen "andalan Agent" dan "ringan dengan throughput tinggi". Platform APIYI apiyi.com menyediakan kedua model tersebut secara bersamaan, sehingga Anda dapat melakukan perutean otomatis berdasarkan jenis tugas di bawah satu kunci autentikasi yang sama, tanpa perlu memilih salah satu saja.
Perbandingan Spesifikasi Gemini 3.5 Flash vs Gemini 3.1 Flash-Lite
Dengan menempatkan kedua model ini dalam satu tabel, pembagian peran lini produk dan perbedaan kemampuannya menjadi sangat jelas. Tabel di bawah merangkum spesifikasi inti kedua model, dengan semua data yang diambil dari model card Google DeepMind dan halaman publik LLM-Stats.
| Dimensi Perbandingan | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Pemenang Skenario Terjemahan |
|---|---|---|---|
| Tanggal Rilis | 19 Mei 2026 | 3 Maret 2026 | — |
| Status Rilis | GA (Versi Resmi) | Preview (Pratinjau) | — |
| ID Model | gemini-3.5-flash |
gemini-3.1-flash-lite-preview |
— |
| Posisi | Agentic Flash · Orkestrasi Alat | High-volume · Ringan & High-throughput | Flash-Lite |
| Jendela Konteks | 1M Input / 64K Output | 1M Input / 64K Output | Seri |
| Modalitas Input | Teks+Gambar+Audio+Video | Teks+Gambar+Suara+Video | Seri |
| Mode Berpikir | Berpikir dinamis aktif default | Level berpikir dapat diatur | Flash-Lite (bisa dimatikan) |
| Batas Pengetahuan | Januari 2026 | Januari 2025 | 3.5 Flash |
| Multibahasa MMMLU | Belum diumumkan (estimasi 80+) | 88.9% | Flash-Lite |
| Kecepatan Output | Sekitar 289 token/s | 45% lebih cepat dari 2.5 Flash, TTFT 2.5x lebih cepat | Flash-Lite |
| Kemampuan Alat Agen | Melampaui banyak tolok ukur 3.1 Pro | Function calling standar | Tidak diperlukan untuk terjemahan |
| Akses APIYI | Sudah tersedia | Sudah tersedia | Seri |
Saat membaca tabel ini, perhatikan tiga poin perbedaan utama. Pertama, perbedaan posisi: Flash-Lite berfokus pada "high-volume", yang berarti Google sejak tahap desain telah menetapkan "throughput lebih diutamakan daripada kecerdasan titik tunggal" dalam DNA produknya, yang sangat cocok dengan kebutuhan tugas frekuensi tinggi seperti terjemahan/klasifikasi. Kedua, angka MMMLU 88.9% adalah model ringan dengan tolok ukur multibahasa tertinggi dalam keluarga Gemini 3.x yang dipublikasikan, yang secara langsung mencerminkan kualitas terjemahan. Ketiga, "level berpikir yang dapat diatur", Flash-Lite memungkinkan fitur thinking dimatikan, sehingga untuk tugas tanpa rantai berpikir seperti terjemahan, latensi dapat ditekan lebih rendah lagi.
Perbandingan Biaya dalam Skenario Terjemahan: Selisih Harga 6 Kali Lipat antara Gemini 3.5 Flash vs 3.1 Flash-Lite
Biaya adalah indikator paling krusial dalam pemilihan model untuk skenario terjemahan. Tugas terjemahan memiliki karakteristik "input dan output tidak panjang namun frekuensinya sangat tinggi". Produk SaaS umum mungkin menjalankan puluhan juta hingga ratusan juta token terjemahan setiap hari; selisih harga 6 kali lipat berarti perbedaan tagihan bulanan bisa mencapai ribuan hingga puluhan ribu dolar AS.
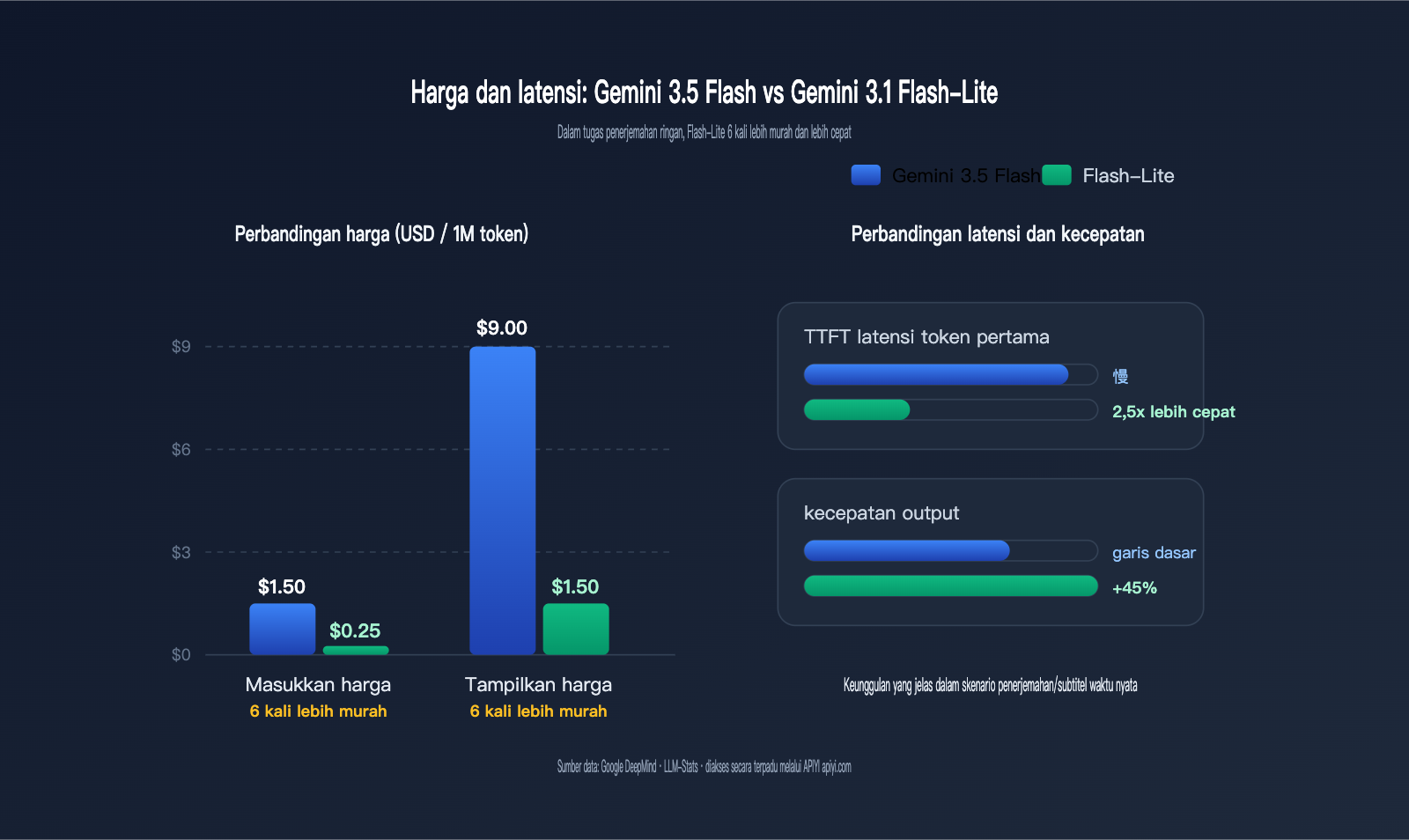
Tabel di bawah membandingkan dimensi biaya paling krusial dari kedua model dalam skenario terjemahan, dengan semua harga dihitung per 1 juta token dalam dolar AS.
| Dimensi Biaya/Performa | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Selisih |
|---|---|---|---|
| Harga Input | $1.50 | $0.25 | Flash-Lite 6x lebih murah |
| Harga Output | $9.00 | $1.50 | Flash-Lite 6x lebih murah |
| Input Cache Hit | $0.15 | $0.025 (estimasi) | Flash-Lite 6x lebih murah |
| TTFT (Latensi token pertama) | Lebih rendah | 2.5x lebih cepat dari 2.5 Flash | Flash-Lite |
| Kecepatan Output | Sekitar 289 token/s | 45% lebih cepat dari 2.5 Flash | Seri/Sedikit unggul Flash-Lite |
| Default Mode Berpikir | Aktif default, ada biaya thinking | Bisa dimatikan, latensi berpikir nol | Flash-Lite |
Mari kita buat simulasi tagihan nyata. Misalkan sebuah produk terjemahan SaaS memproses 10 juta token input dan 5 juta token output setiap hari (skala aplikasi B2C menengah), bagaimana tagihannya jika menggunakan kedua model tersebut selama sebulan?
| Tagihan Bulanan (10jt input / 5jt output per hari) | Gemini 3.5 Flash | Gemini 3.1 Flash-Lite | Penghematan |
|---|---|---|---|
| Biaya input harian | $15.00 | $2.50 | $12.50 |
| Biaya output harian | $45.00 | $7.50 | $37.50 |
| Total harian | $60.00 | $10.00 | $50 |
| Total bulanan (30 hari) | $1,800 | $300 | $1,500 / bulan |
| Total tahunan | $21,600 | $3,600 | $18,000 / tahun |
💡 Saran Estimasi Biaya: Masukkan angka dari tabel ini ke dalam trafik nyata Anda, selisih bulanan biasanya mencapai empat digit dolar AS atau lebih. Disarankan untuk mendaftar akun di APIYI apiyi.com untuk mendapatkan kredit gratis sebesar 0,05 dolar AS, gunakan sampel terjemahan yang sama untuk memanggil
gemini-3.5-flashdangemini-3.1-flash-lite-preview. Dengan cara ini, Anda tidak hanya dapat memverifikasi perbedaan kualitas, tetapi juga mendapatkan data selisih harga nyata untuk bisnis Anda sendiri.
Analisis Uji Coba Kecepatan dan Kualitas Terjemahan Gemini 3.1 Flash-Lite
Harga murah tidak ada gunanya jika kualitas terjemahan tidak memadai. Data uji coba Gemini 3.1 Flash-Lite dalam hal penerjemahan sebenarnya sangat solid. Di sebagian besar skenario, kualitas terjemahannya tidak akan membuat pengguna merasa "jauh lebih buruk daripada Flash". Berikut adalah empat kelompok data sebagai bukti utamanya.
Pertama, skor 88,9% pada tolok ukur multibahasa MMMLU. MMMLU (Multilingual MMLU) menguji kemampuan model dalam memahami pengetahuan profesional dan penalaran dalam lebih dari 15 bahasa. Flash-Lite mencapai 88,9% dalam pengujian ini, yang menjadikannya berada di jajaran teratas di antara semua model kelas Flash-Lite. Ini berarti model ini tetap mampu menjaga kualitas tinggi dalam bahasa non-Latin seperti Mandarin, Jepang, Korea, Arab, dan lainnya.
Kedua, pernyataan eksplisit dari Google DeepMind dalam model card mereka: "best-in-class translation and multilingual understanding, with noted improvements in non-Latin scripts". Ini adalah dukungan resmi dari Google untuk kemampuan terjemahan Flash-Lite, yang secara khusus menekankan peningkatan pada "skrip non-Latin"—yang sangat krusial bagi SaaS berbahasa Mandarin.
Ketiga, kesimpulan pengujian komparatif dari Lara Translate dalam Translation Model Benchmark Februari 2026: Varian seri Flash diposisikan sebagai pilihan utama untuk "lower latency and higher throughput workflows". Kendala utama tugas penerjemahan (latensi rendah + throughput tinggi + sensitivitas biaya) sangat selaras dengan tujuan desain Flash-Lite.
Keempat, Time-to-First-Token (TTFT) dan kecepatan output. TTFT Flash-Lite 2,5 kali lebih cepat daripada Gemini 2.5 Flash, dengan peningkatan kecepatan output sebesar 45%. Kedua indikator ini secara langsung menentukan pengalaman pengguna dalam skenario yang "sensitif terhadap real-time" seperti penerjemahan. Kami menyarankan Anda mencoba mengukur waktu yang dibutuhkan untuk menerjemahkan 5.000 karakter Mandarin ke bahasa Inggris di APIYI apiyi.com; perbedaannya sangat terlihat jelas.
Rekomendasi Skenario: Kapan Memilih Flash-Lite dan Kapan Menggunakan 3.5 Flash
Dengan mengubah perbandingan 6 dimensi menjadi saran pemilihan tugas yang konkret, kita dapat merangkumnya ke dalam tabel rekomendasi berikut. Tabel ini tidak menjawab "model mana yang lebih kuat", melainkan "siapa yang harus digunakan untuk setiap tugas spesifik".
| Jenis Tugas | Model Rekomendasi | Alasan Utama |
|---|---|---|
| Terjemahan teks umum (Mandarin-Inggris/Mandarin-Jepang, dll.) | Gemini 3.1 Flash-Lite | MMMLU 88,9% + harga 6x lebih murah |
| Terjemahan subtitle / Terjemahan real-time | Gemini 3.1 Flash-Lite | TTFT 2,5x lebih cepat + output 45% lebih cepat |
| Moderasi konten / Klasifikasi teks | Gemini 3.1 Flash-Lite | Sweet spot resmi Google, optimal untuk tugas batch |
| Ekstraksi data terstruktur | Gemini 3.1 Flash-Lite | Cocok untuk ekstraksi JSON skala besar |
| Chatbot multibahasa | Gemini 3.1 Flash-Lite | Kualitas multibahasa + latensi rendah + biaya murah |
| Terjemahan + Agent pasca-pemrosesan | Gemini 3.5 Flash | Membutuhkan function calling untuk merangkai banyak alat |
| Terjemahan + Pemanggilan alat | Gemini 3.5 Flash | Kemampuan Agent melampaui 3.1 Pro |
| Asisten kode / Pelengkapan IDE | Gemini 3.5 Flash | Terminal-Bench 2.1 = 76,2% |
| Tanya jawab RAG dokumen panjang | Gemini 3.5 Flash | Cache hit + jendela konteks 1M |
| Alur kerja Agent kompleks | Gemini 3.5 Flash | MCP Atlas 83,6% |
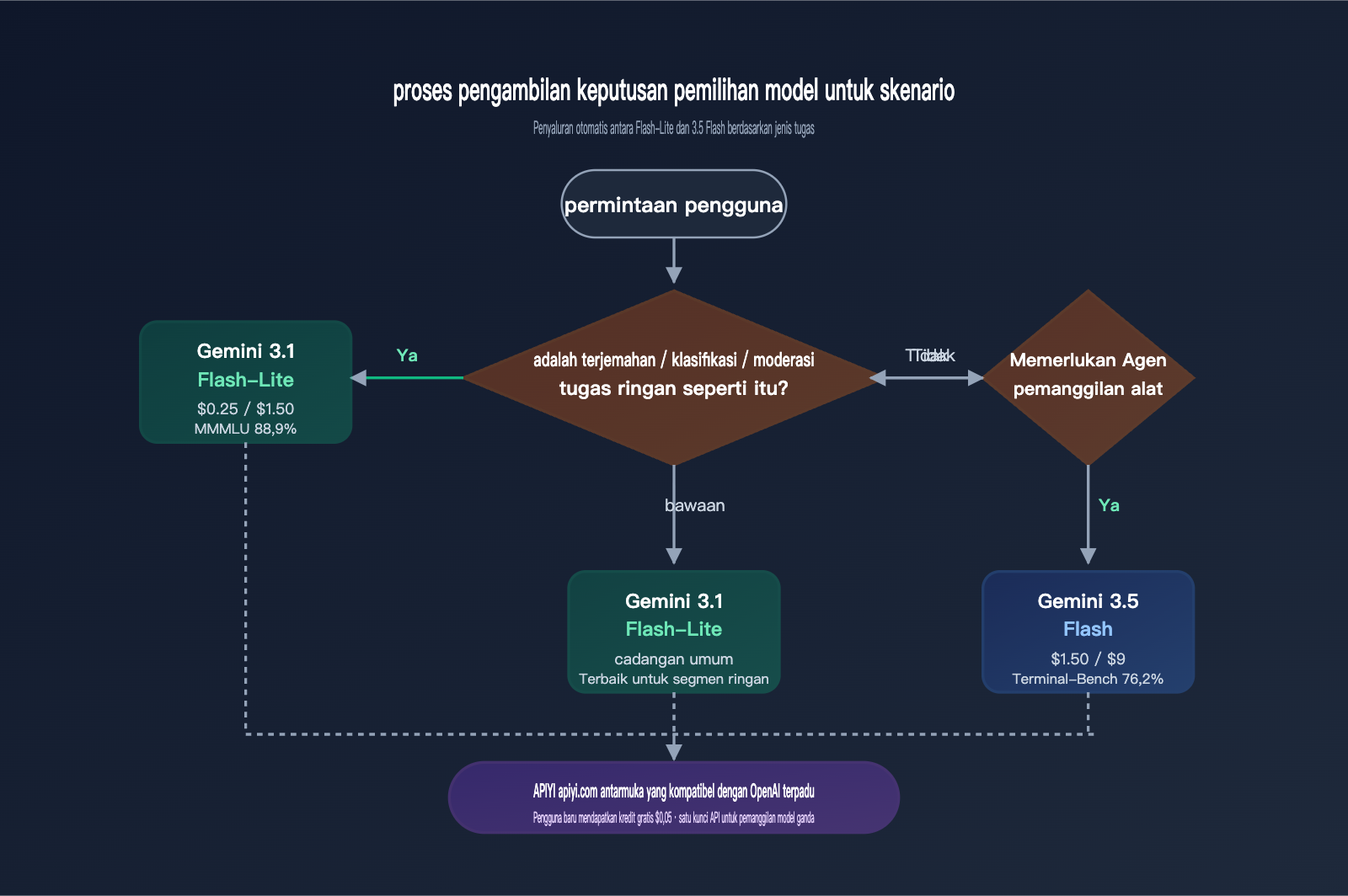
Strategi paling ideal dalam praktiknya tetaplah "perutean berdasarkan tugas": terjemahan/klasifikasi/moderasi menggunakan gemini-3.1-flash-lite-preview, sedangkan Agent / pengodean / RAG dokumen panjang menggunakan gemini-3.5-flash. Kedua model tersebut dapat diakses di bawah satu kunci API APIYI apiyi.com yang sama untuk memudahkan peralihan. Dengan cara ini, Anda bisa mendapatkan keuntungan biaya 6x lipat dari Flash-Lite untuk tugas ringan, sekaligus mempertahankan batas kemampuan 3.5 Flash untuk Agent yang berat.
Skenario Tipikal untuk Memilih Gemini 3.1 Flash-Lite
Jika produk Anda memiliki salah satu karakteristik berikut, Flash-Lite hampir pasti merupakan solusi yang lebih baik: jumlah panggilan harian melebihi 100.000 kali, input/output tunggal dalam batas 5K token, sensitif terhadap latensi P95, tidak memerlukan pemanggilan alat, dan perlu mendukung berbagai bahasa. Skenario tipikal mencakup terjemahan produk e-commerce lintas batas, layanan pelanggan multibahasa SaaS, alur kerja moderasi konten, pembuatan subtitle, normalisasi setelah OCR massal, dll. Dengan antarmuka yang kompatibel dengan OpenAI dari APIYI apiyi.com, biaya migrasi hampir nol.
Skenario Tipikal yang Tetap Merekomendasikan Gemini 3.5 Flash
Jika tugas Anda memiliki kebutuhan untuk "memanggil alat setelah menerjemahkan" atau "terjemahan yang disematkan dalam rantai Agent yang kompleks", maka Gemini 3.5 Flash lebih masuk akal. Contohnya: terjemahan + pencarian basis pengetahuan + memanggil API eksternal, atau pengguna mengirimkan teks bahasa asing → model menerjemahkannya terlebih dahulu → kemudian memanggil alat kalkulator/pencarian/eksekusi kode. Tugas-tugas seperti ini akan sering mengalami kesalahan jika menggunakan Flash-Lite karena kurangnya kemampuan Agent, yang justru akan membuat biaya menjadi lebih tinggi.
Contoh Integrasi Gemini 3.1 Flash-Lite di APIYI untuk Skenario Penerjemahan
Berikut adalah contoh integrasi Python paling sederhana yang dioptimalkan untuk skenario penerjemahan, yang menunjukkan cara memanggil Gemini 3.1 Flash-Lite di APIYI (apiyi.com) dengan tetap mempertahankan kompatibilitas penuh dengan OpenAI.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
def translate(text: str, target_lang: str = "English") -> str:
resp = client.chat.completions.create(
model="gemini-3.1-flash-lite-preview",
messages=[
{"role": "system", "content": f"Terjemahkan input pengguna ke {target_lang}. Hanya keluarkan hasil terjemahan, tanpa penjelasan."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return resp.choices[0].message.content
print(translate("人工智能正在改变软件工程的协作模式。", "English"))
Lihat implementasi lengkap dengan konkurensi batch dan rute fallback
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
)
PRIMARY_MODEL = "gemini-3.1-flash-lite-preview"
FALLBACK_MODEL = "gemini-3.5-flash"
async def translate_one(text: str, target_lang: str) -> dict:
try:
resp = await client.chat.completions.create(
model=PRIMARY_MODEL,
messages=[
{"role": "system", "content": f"Terjemahkan ke {target_lang}. Hanya keluarkan hasil terjemahan."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": PRIMARY_MODEL, "text": resp.choices[0].message.content}
except Exception as e:
resp = await client.chat.completions.create(
model=FALLBACK_MODEL,
messages=[
{"role": "system", "content": f"Terjemahkan ke {target_lang}. Hanya keluarkan hasil terjemahan."},
{"role": "user", "content": text},
],
temperature=0.2,
)
return {"model": FALLBACK_MODEL, "text": resp.choices[0].message.content, "fallback_reason": str(e)}
async def batch_translate(items: list[str], target_lang: str, concurrency: int = 20):
sem = asyncio.Semaphore(concurrency)
async def worker(text):
async with sem:
return await translate_one(text, target_lang)
return await asyncio.gather(*[worker(t) for t in items])
if __name__ == "__main__":
samples = ["你好,世界。", "人工智能正在改变行业。", "请帮我订一张明天去东京的机票。"]
results = asyncio.run(batch_translate(samples, "English"))
for r in results:
print(r)
💡 Saran Optimasi Penerjemahan Batch: Skenario penerjemahan cocok menggunakan konkurensi tinggi (
concurrency=20~50) + temperature rendah (0.1-0.3) + petunjuk sistem yang singkat. Platform APIYI (apiyi.com) telah mengoptimalkan rute untuk skenario throughput tinggi. Pengguna baru mendapatkan kredit gratis sebesar $0,05, yang dengan harga Flash-Lite $0,25/$1,50 dapat menerjemahkan sekitar 50 ribu-100 ribu token konten nyata, cukup untuk melakukan stress test pada pipeline penerjemahan batch Anda.
FAQ: Gemini 3.5 Flash vs 3.1 Flash-Lite untuk Penerjemahan
Q1: Gemini 3.1 Flash-Lite adalah versi Preview, apakah aman digunakan di lingkungan produksi?
Bisa digunakan, tetapi siapkan rencana cadangan. Flash-Lite telah berada dalam tahap Preview sejak diluncurkan pada 3 Maret 2026. Google belum memberikan tanggal GA (General Availability) yang pasti, namun antarmuka API dan harganya sudah stabil. Disarankan untuk menggunakan strategi dua model di lingkungan produksi: "Rute utama Flash-Lite + Fallback 3.5 Flash" melalui antarmuka terpadu APIYI (apiyi.com) untuk menghindari ketergantungan pada satu titik. Saat Google meningkatkannya ke GA atau merilis 3.5 Flash-Lite, Anda hanya perlu mengganti kolom model untuk migrasi yang mulus.
Q2: Apakah kualitas terjemahan Flash-Lite benar-benar bisa mengejar Flash?
Untuk 90% lebih tugas penerjemahan umum, jawabannya ya. Kartu model Google DeepMind menyatakan dengan jelas bahwa Flash-Lite memiliki "kemampuan penerjemahan dan pemahaman multibahasa terbaik di kelasnya", dengan skor MMMLU multibahasa sebesar 88,9%. Namun, 3.5 Flash tetap unggul dalam dua skenario: pertama, penerjemahan teks panjang yang melibatkan istilah teknis (medis, hukum, keuangan); kedua, penerjemahan + penalaran konteks (misalnya menentukan referensi kata ganti berdasarkan konteks). Disarankan untuk menjalankan serangkaian sampel bisnis nyata di APIYI (apiyi.com) untuk perbandingan, daripada hanya melihat angka benchmark.
Q3: Apakah cocok mengganti GPT-4o-mini atau Claude Haiku 4.5 dengan Flash-Lite untuk penerjemahan?
Cocok, dan biasanya lebih murah serta lebih cepat. Harga $0,25/$1,50 untuk Gemini 3.1 Flash-Lite lebih rendah daripada GPT-4o-mini (yang mungkin terlihat lebih murah di $0,15/$0,60, namun kualitas terjemahannya terbukti di bawah Flash-Lite), dan juga lebih rendah daripada Claude Haiku 4.5. Pada benchmark multibahasa, skor MMMLU 88,9% milik Flash-Lite lebih tinggi daripada kompetitor di kelas yang sama. Disarankan untuk mencoba ketiga model tersebut di APIYI (apiyi.com) di bawah satu kunci API yang sama untuk perbandingan A/B guna mengetahui mana yang paling cocok untuk pasangan bahasa spesifik Anda.
Q4: Apakah jendela konteks 1M milik Flash-Lite benar-benar bisa digunakan untuk penerjemahan?
Bisa, dan ini adalah kemampuan yang paling diremehkan. 1M token setara dengan sekitar 700 ribu-800 ribu kata bahasa Inggris atau 300 ribu-400 ribu karakter bahasa Mandarin, cukup untuk menerjemahkan seluruh buku berukuran sedang atau satu set dokumen perusahaan sekaligus. Dengan mode thinking dimatikan, biaya penerjemahan sekali jalan untuk konteks 1M adalah sekitar $0,25 input + $1,50 output, jauh lebih murah daripada memecah konten yang sama untuk 3.5 Flash atau GPT-5.5. APIYI (apiyi.com) telah membuka akses penuh ke jendela konteks 1M Flash-Lite, sehingga Anda bisa langsung memanggilnya.
Kesimpulan: Gemini 3.1 Flash-Lite adalah Solusi Paling Efisien dengan Rasio Harga-Performa 6 Kali Lipat untuk Skenario Penerjemahan
Kembali ke poin utama artikel ini: Untuk tugas ringan dengan frekuensi tinggi seperti penerjemahan, Gemini 3.1 Flash-Lite bukanlah "versi downgrade" dari Gemini 3.5 Flash, melainkan solusi optimal yang dirancang khusus oleh Google untuk skenario tersebut. Lima fakta berikut menegaskan dominasinya dalam skenario penerjemahan: harga input 6 kali lebih murah, harga output 6 kali lebih murah, latensi token pertama 2,5 kali lebih cepat, skor multibahasa MMMLU yang mencapai 88,9%, dan fakta bahwa Google secara resmi menempatkan penerjemahan sebagai keunggulan utamanya (sweet spot). Keunggulan Gemini 3.5 Flash dalam hal Agent dan pengodean tidak memberikan manfaat apa pun dalam penerjemahan, sehingga biaya tambahan yang Anda keluarkan untuk kemampuan tersebut hanyalah pemborosan.
Strategi yang paling bijak adalah menggunakan perutean model ganda: gunakan gemini-3.1-flash-lite-preview untuk penerjemahan, klasifikasi, dan moderasi, sementara untuk Agent, pengodean, dan RAG dokumen panjang, gunakan gemini-3.5-flash. Anda dapat beralih antar model dengan mudah melalui antarmuka yang kompatibel dengan OpenAI dari APIYI (apiyi.com) di bawah satu kunci API yang sama. Pengguna baru akan mendapatkan kredit gratis sebesar 0,05 USD saat mendaftar, yang cukup untuk melakukan stress test penuh pada pipeline penerjemahan massal Anda guna mengetahui berapa besar penghematan biaya nyata yang bisa didapatkan untuk bisnis Anda.
Penulis: Tim Teknis APIYI · apiyi.com
Tanggal Publikasi: 20 Mei 2026
Referensi: Google DeepMind Model Card, Google Blog, LLM-Stats, Artificial Analysis, DevTK, AIMLAPI, Lara Translate Benchmark, Emelia Hub





