Gemini 3.1 Pro Preview y Gemini 3.0 Pro Preview tienen exactamente el mismo precio: Input $2.00, Output $12.00 / millón de tokens. Entonces surge la pregunta: ¿en qué es realmente mejor el 3.1 frente al 3.0? ¿Vale la pena el cambio?
La respuesta es: vale muchísimo la pena, y no hay ninguna razón para no cambiar.
En este artículo compararemos ambos versiones punto por punto utilizando datos de benchmarks reales. Te adelanto la conclusión: la puntuación de razonamiento ARC-AGI-2 de Gemini 3.1 Pro se disparó del 31.1% al 77.1%, lo que supone un incremento de 2.5 veces; en programación (SWE-Bench) subió del 76.8% al 80.6%; y en búsqueda (BrowseComp) saltó del 59.2% al 85.9%. No es un simple ajuste fino, es un salto generacional.
Valor principal: Al terminar de leer, entenderás claramente cada mejora específica de 3.1 Pro respecto a 3.0 Pro y sabrás cómo elegir según el escenario.
Tabla comparativa de parámetros: Gemini 3.1 Pro vs 3.0 Pro
Veamos primero las diferencias a nivel de parámetros técnicos:
| Dimensión de comparación | Gemini 3.0 Pro Preview | Gemini 3.1 Pro Preview | Cambio |
|---|---|---|---|
| ID del modelo | gemini-3-pro-preview |
gemini-3.1-pro-preview |
Nueva versión |
| Fecha de lanzamiento | 18 de noviembre de 2025 | 19 de febrero de 2026 | +3 meses |
| Precio Input (≤200K) | $2.00 / M tokens | $2.00 / M tokens | Sin cambios |
| Precio Output (≤200K) | $12.00 / M tokens | $12.00 / M tokens | Sin cambios |
| Precio Input (>200K) | $4.00 / M tokens | $4.00 / M tokens | Sin cambios |
| Precio Output (>200K) | $18.00 / M tokens | $18.00 / M tokens | Sin cambios |
| Ventana de contexto | 1M tokens | 1M tokens | Sin cambios |
| Salida máxima | — | 65K tokens | Mejora clara |
| Límite de archivos | 20MB | 100MB | 5 veces más |
| Soporte YouTube URL | ❌ | ✅ | Nuevo |
| Niveles de pensamiento | 2 niveles (low/high) | 3 niveles (low/medium/high) | Nuevo nivel medium |
| Endpoint customtools | ❌ | ✅ | Nuevo |
| Corte de conocimiento | Enero de 2025 | Enero de 2025 | Sin cambios |
El precio, la ventana de contexto y el corte de conocimiento son idénticos. Todos los cambios son mejoras puras de capacidad.
🎯 Conclusión clave: El precio no sube ni un centavo, pero las funciones aumentan. Desde el punto de vista técnico, 3.1 Pro es un reemplazo directo y superior de 3.0 Pro. Si utilizas APIYI (apiyi.com), solo tienes que cambiar el parámetro
modeldegemini-3-pro-previewagemini-3.1-pro-previewpara completar la actualización.
Diferencia 1: Capacidad de razonamiento — De «excelente» a «superior»
Esta es la mejora más importante de la versión 3.0 a la 3.1, y el punto que Google más ha destacado en esta actualización.
| Referencia de razonamiento | 3.0 Pro | 3.1 Pro | Incremento | Descripción |
|---|---|---|---|---|
| ARC-AGI-2 | 31.1% | 77.1% | +148% | Razonamiento de nuevos patrones lógicos |
| GPQA Diamond | — | 94.3% | — | Razonamiento científico de nivel de posgrado |
| MMMLU | — | 92.6% | — | Comprensión multidisciplinaria y multimodal |
| LiveCodeBench Pro | — | Elo 2887 | — | Competición de programación en tiempo real |
El avance en ARC-AGI-2 es el más sorprendente: pasar del 31.1% al 77.1% no es solo duplicar la cifra, sino que se ha multiplicado por 2.5 veces. Esta prueba evalúa la capacidad del modelo para resolver nuevos patrones lógicos, es decir, problemas de razonamiento que el modelo nunca ha visto antes. La puntuación de 77.1% también supera el 68.8% de Claude Opus 4.6, estableciendo una posición de liderazgo en la dimensión del razonamiento.
La razón técnica detrás: Google describe oficialmente al 3.1 Pro con una «unprecedented depth and nuance» (profundidad y matices sin precedentes), mientras que la descripción del 3.0 Pro era «advanced intelligence» (inteligencia avanzada). No se trata solo de un cambio en el lenguaje de marketing; los datos de ARC-AGI-2 demuestran que la profundidad del razonamiento ha dado un salto cualitativo.
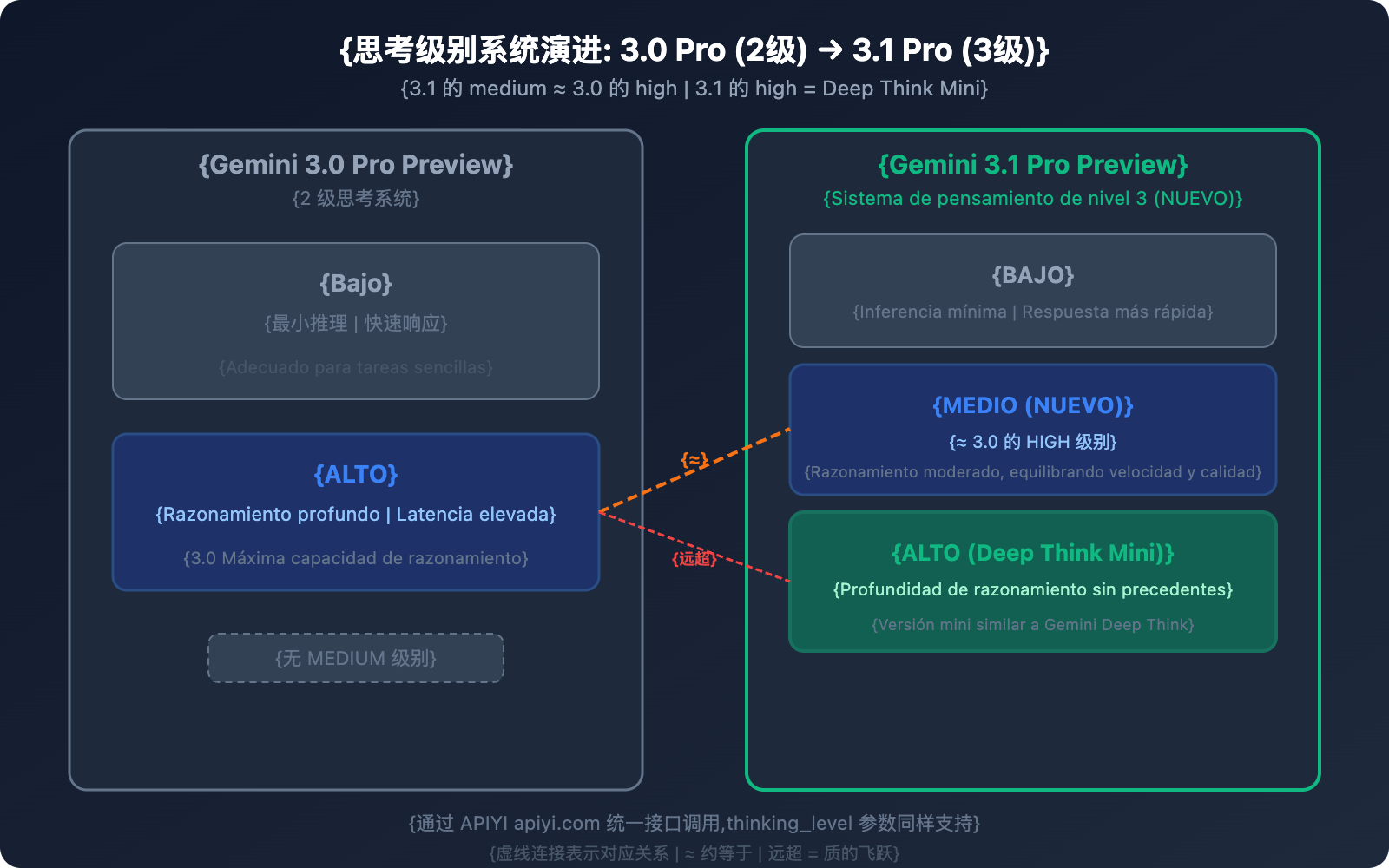
Diferencia 2: Sistema de niveles de pensamiento — De 2 a 3 niveles
Esta es una de las mejoras más prácticas del 3.1 Pro.
Sistema de pensamiento del 3.0 Pro (2 niveles)
| Nivel | Comportamiento |
|---|---|
| low | Razonamiento mínimo, respuesta rápida |
| high | Razonamiento profundo, mayor latencia |
Sistema de pensamiento del 3.1 Pro (3 niveles)
| Nivel | Comportamiento | Relación de equivalencia |
|---|---|---|
| low | Razonamiento mínimo, respuesta rápida | Similar al low de 3.0 |
| medium (Nuevo) | Razonamiento moderado, equilibrio entre velocidad y calidad | ≈ high de 3.0 |
| high | Modo Deep Think Mini, razonamiento más profundo | Muy superior al high de 3.0 |
Información clave: El nivel medium de 3.1 Pro ≈ el nivel high de 3.0 Pro. Esto significa que:
- Con el nivel medium de 3.1, obtienes la misma calidad de razonamiento que el nivel más alto de 3.0.
- El nivel high de 3.1 es una categoría totalmente nueva, similar a una versión mini de Gemini Deep Think.
- Para la misma calidad de razonamiento (medium), la latencia es menor que en el nivel high de 3.0.
💡 Consejo práctico: Si antes solías usar el modo high de 3.0 Pro, al cambiar a 3.1 Pro te recomendamos empezar con el nivel medium; la calidad de razonamiento es equivalente, pero con menor latencia. Reserva el nivel high (Deep Think Mini) solo para tareas de razonamiento verdaderamente complejas. De esta forma, obtendrás una mejor experiencia general sin aumentar los costes. La plataforma APIYI (apiyi.com) permite configurar el parámetro
thinking_level.
Diferencia 3: Capacidad de programación — Entrando en el primer nivel
| Benchmark de programación | 3.0 Pro | 3.1 Pro | Mejora | Comparativa del sector |
|---|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.6% | +3.8% | Claude Opus 4.6: 80.9% |
| Terminal-Bench 2.0 | 56.9% | 68.5% | +11.6% | Programación en terminal para Agentes |
| LiveCodeBench Pro | — | Elo 2887 | — | Competición de programación en tiempo real |
A simple vista, la mejora en SWE-Bench Verified es de solo 3.8 puntos porcentuales (del 76.8% al 80.6%), pero en este nivel de puntuación, cada 1% de mejora es extremadamente difícil de conseguir. Este resultado del 80.6% reduce la distancia entre Gemini 3.1 Pro y Claude Opus 4.6 (80.9%) a tan solo un 0.3%, pasando de ser "líder del segundo nivel" a "competir de tú a tú en el primer nivel".
La mejora en Terminal-Bench 2.0 es aún más notable: del 56.9% al 68.5%, lo que supone un incremento del 20.4%. Este benchmark evalúa específicamente la capacidad de un Agente para ejecutar tareas de programación en entornos de terminal; un aumento de 11.6 puntos porcentuales significa que la fiabilidad de 3.1 Pro en escenarios de programación automatizada se ha fortalecido considerablemente.
Diferencia 4: Capacidades de Agentes y búsqueda — Un salto cualitativo
| Benchmark de Agentes | 3.0 Pro | 3.1 Pro | Magnitud de la mejora |
|---|---|---|---|
| BrowseComp | 59.2% | 85.9% | +45.1% |
| MCP Atlas | 54.1% | 69.2% | +27.9% |
Estos dos son los benchmarks donde se observa el mayor salto de la versión 3.0 a la 3.1:
BrowseComp evalúa la capacidad de búsqueda web de los Agentes: se disparó del 59.2% al 85.9%, una mejora de 26.7 puntos porcentuales. Esto tiene una importancia enorme para construir Agentes de asistencia en investigación, análisis de competencia o recuperación de información en tiempo real.
MCP Atlas mide la capacidad de gestionar flujos de trabajo de varios pasos utilizando el Model Context Protocol: subió del 54.1% al 69.2%. El MCP es el estándar de protocolo para Agentes impulsado por Google, y esta mejora indica que la capacidad de coordinación y ejecución de 3.1 Pro en flujos de trabajo complejos de Agentes se ha potenciado significativamente.
Endpoint dedicado customtools: 3.1 Pro también introduce el endpoint específico gemini-3.1-pro-preview-customtools, optimizado para escenarios donde se mezclan comandos de bash y llamadas a funciones personalizadas. Este endpoint ajusta específicamente la prioridad de llamada de herramientas comunes para desarrolladores como view_file o search_code, siendo más estable y fiable que el endpoint general en escenarios de Agentes como mantenimiento automatizado (DevOps) o asistentes de programación con IA.
🎯 Atención, desarrolladores de Agentes: Si estás construyendo bots de revisión de código, Agentes de despliegue automatizado u otras herramientas similares, te recomendamos encarecidamente usar el endpoint
customtools. Puedes llamar a este endpoint directamente a través de APIYI (apiyi.com), simplemente rellenando el parámetromodelcongemini-3.1-pro-preview-customtools.
Diferencia 5: Capacidad de salida y características de la API
| Característica | 3.0 Pro | 3.1 Pro | Cambio |
|---|---|---|---|
| Máximo de tokens de salida | No especificado | 65,000 | Etiquetado claramente como 65K |
| Límite de subida de archivos | 20MB | 100MB | Incremento de 5 veces |
| URL de YouTube | ❌ No soportado | ✅ Entrada directa | Nuevo |
| Endpoint de customtools | ❌ | ✅ | Nuevo |
| Eficiencia de salida | Base | +15% | Mejores resultados con menos tokens |
Límite de salida de 65K: Permite generar de una sola vez documentos largos completos, grandes bloques de código o informes de análisis detallados, sin necesidad de dividir la solicitud en varias partes y luego juntarlas.
Subida de archivos de 100MB: La expansión de 20MB a 100MB significa que puedes subir directamente repositorios de código más grandes, colecciones de documentos PDF o archivos multimedia para su análisis.
Entrada directa de URL de YouTube: Al pasar directamente un enlace de YouTube en la indicación, el modelo analizará y procesará automáticamente el contenido del video, sin necesidad de descargarlo, transcodificarlo o subirlo manualmente.
Mejora del 15% en la eficiencia de salida: Según el feedback real del Director de IA de JetBrains, el modelo 3.1 Pro produce resultados más fiables utilizando menos tokens. Esto significa que, para la misma tarea, el consumo real de tokens es menor y el costo es más óptimo.
Valor de cada característica para diferentes usuarios
| Característica | Valor para desarrolladores individuales | Valor para equipos empresariales |
|---|---|---|
| Salida de 65K | Generar archivos de código completos de una vez | Generación por lotes de documentación técnica e informes |
| Subida de 100MB | Subir proyectos completos para análisis | Auditoría de grandes repositorios de código |
| URL de YouTube | Análisis rápido de videos tutoriales | Análisis de demostraciones de productos de la competencia |
| customtools | Desarrollo de asistentes de programación con IA | Agentes de operaciones y mantenimiento automatizados |
| Eficiencia +15% | Reducción de costos de llamadas individuales | Optimización de costos significativa en escenarios a gran escala |
💰 Prueba de costos real: En la misma tarea, el consumo real de tokens de salida de 3.1 Pro es, en promedio, entre un 10% y un 15% menor que el de 3.0 Pro. Para aplicaciones empresariales con un volumen de millones de tokens diarios, el cambio puede ahorrar cientos de dólares al mes. Puedes comparar esto con precisión a través de la función de estadísticas de uso de APIYI (apiyi.com).
Diferencia 6: Eficiencia de salida — Mejores resultados con menos tokens
Esta es una mejora que suele pasar desapercibida pero que tiene un gran impacto real. Vladislav Tankov, Director de IA en JetBrains, comentó tras sus pruebas: el 3.1 Pro ofrece una mejora del 15% en calidad, consumiendo al mismo tiempo menos tokens de salida que el 3.0 Pro.
¿Qué significa esto?
Menor costo de uso real: Aunque el precio unitario sea el mismo, el 3.1 Pro consume menos tokens para completar la misma tarea, por lo que la factura final será más baja. Supongamos una aplicación con un promedio de 1 millón de tokens de salida al día; una mejora del 15% en la eficiencia significa un ahorro diario de aproximadamente $1.80 en costos de salida.
Velocidad de respuesta más rápida: Menos tokens de salida se traducen en un tiempo de generación más corto. En aplicaciones en tiempo real sensibles a la latencia, esta mejora es muy valiosa.
Calidad de salida más concisa: El 3.1 Pro no es que simplemente "hable menos", sino que "habla con más precisión". Utiliza expresiones más compactas para transmitir la misma o incluso más información, reduciendo la redundancia y el relleno innecesario.
Diferencia 7: Seguridad y confiabilidad
| Dimensión de seguridad | 3.0 Pro | 3.1 Pro | Cambio |
|---|---|---|---|
| Seguridad de texto | Base | +0.10% | Mejora leve |
| Seguridad multilingüe | Base | +0.11% | Mejora leve |
| Tasa de rechazo erróneo | Base | Mantiene niveles bajos | Sin cambios |
| Estabilidad en tareas largas | Base | Mejora | Más confiable |
Aunque la mejora en seguridad no es enorme en términos numéricos, la dirección es la correcta: se han potenciado las capacidades sin sacrificar la seguridad. La mejora en la estabilidad para tareas largas es especialmente importante para aplicaciones de Agentes, lo que significa que en flujos de trabajo de varios pasos, el 3.1 Pro es menos propenso a "perder el hilo" o generar resultados poco fiables.
Diferencia 8: Cambios en la descripción del posicionamiento oficial
| Dimensión | Descripción de 3.0 Pro | Descripción de 3.1 Pro |
|---|---|---|
| Posicionamiento central | advanced intelligence | unprecedented depth and nuance |
| Características de razonamiento | advanced reasoning | SOTA reasoning |
| Características de programación | agentic and vibe coding | powerful coding |
| Multimodalidad | multimodal understanding | powerful multimodal understanding |
De "advanced" a "unprecedented", de "agentic and vibe coding" a "powerful coding": el cambio en la redacción refleja una evolución en su posicionamiento. Mientras que el 3.0 Pro destacaba lo "avanzado" y lo "innovador" (vibe coding), el 3.1 Pro pone el foco en la "profundidad" y la "potencia".
Diferencia 9: Recomendaciones de uso — ¿Cuándo usar cuál?

Ejemplo de código para migración
import openai
client = openai.OpenAI(
api_key="TU_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
# 3.0 Pro → 3.1 Pro solo cambia un parámetro
# Versión antigua: model="gemini-3-pro-preview"
# Versión nueva: model="gemini-3.1-pro-preview"
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # El único lugar que necesita modificación
messages=[{"role": "user", "content": "Analiza los cuellos de botella de rendimiento de este código"}]
)
Ver código de prueba comparativa A/B
import openai
import time
client = openai.OpenAI(
api_key="TU_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
test_prompt = "Dado el array [3,1,4,1,5,9,2,6], usa merge sort y analiza la complejidad temporal"
# Probando 3.0 Pro
start = time.time()
resp_30 = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_30 = time.time() - start
# Probando 3.1 Pro
start = time.time()
resp_31 = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": test_prompt}]
)
time_31 = time.time() - start
print(f"3.0 Pro: {time_30:.2f}s, {resp_30.usage.total_tokens} tokens")
print(f"3.1 Pro: {time_31:.2f}s, {resp_31.usage.total_tokens} tokens")
print(f"\nRespuesta 3.0:\n{resp_30.choices[0].message.content[:300]}...")
print(f"\nRespuesta 3.1:\n{resp_31.choices[0].message.content[:300]}...")
Notas de migración y mejores prácticas
Paso 1: Probar escenarios principales
Compara la salida de 3.0 y 3.1 en tus 3 a 5 indicaciones más utilizadas. Enfócate en la calidad del razonamiento, la precisión del código y el formato de salida.
Paso 2: Ajustar el nivel de razonamiento
Si antes usabas el modo "high" en 3.0, al cambiar a 3.1 se recomienda empezar con "medium" (la calidad de razonamiento es equivalente pero más rápida). Usa "high" (Deep Think Mini) solo cuando realmente necesites un razonamiento profundo.
Paso 3: Explorar nuevas capacidades
Prueba funciones exclusivas de 3.1 como la subida de archivos de 100MB, el análisis de URLs de YouTube o la salida larga de 65K; podrías descubrir nuevos casos de uso.
Paso 4: Cambio total
Una vez confirmado el rendimiento, cambia todas las llamadas de gemini-3-pro-preview a gemini-3.1-pro-preview. Se recomienda mantener 3.0 como respaldo (fallback) hasta que 3.1 funcione de manera estable en tu entorno durante al menos una semana.
🚀 Migración rápida: A través de la plataforma APIYI (apiyi.com), la migración de 3.0 → 3.1 solo requiere cambiar un parámetro. Se sugiere realizar primero pruebas A/B en escenarios clave para confirmar los resultados antes del cambio total.
Preguntas frecuentes
P1: ¿Son 3.1 Pro y 3.0 Pro totalmente compatibles? ¿Debo cambiar mis indicaciones?
La interfaz de la API es totalmente compatible, solo necesitas modificar el parámetro model. Sin embargo, dado que el método de razonamiento de 3.1 Pro ha mejorado, algunas indicaciones (prompts) meticulosamente ajustadas podrían comportarse de forma ligeramente distinta en 3.1 (generalmente mejor), por lo que se recomienda realizar pruebas de regresión en escenarios críticos. A través de APIYI (apiyi.com) puedes llamar a ambas versiones simultáneamente para compararlas.
P2: ¿Se seguirá manteniendo 3.0 Pro? ¿Cuándo dejará de estar disponible?
Como modelo Preview, Google suele avisar con al menos 2 semanas de antelación antes de retirarlo. Actualmente, 3.0 Pro sigue disponible, pero considerando que 3.1 Pro es un reemplazo superior en todas las dimensiones, se recomienda migrar lo antes posible. Las llamadas a través de APIYI (apiyi.com) no se ven afectadas por los ajustes de versión del lado de Google, ya que la plataforma gestiona automáticamente el enrutamiento del modelo.
P3: ¿El modo de razonamiento «high» de 3.1 Pro consume muchos tokens?
El modo "high" (Deep Think Mini) consume efectivamente más tokens de salida porque el modelo genera una cadena de razonamiento interna más profunda. Se recomienda usar "medium" para tareas cotidianas (equivalente a la calidad "high" de 3.0) y reservar "high" para escenarios como razonamiento matemático o depuración compleja. De esta forma, puedes mantener o incluso reducir costos en la mayoría de las tareas.
P4: ¿Están ambas versiones disponibles en APIYI?
Sí, ambas están disponibles. APIYI (apiyi.com) admite tanto gemini-3-pro-preview como gemini-3.1-pro-preview utilizando la misma API Key y base_url, lo que facilita las pruebas comparativas A/B y el cambio flexible entre modelos.
Sugerencias de actualización a Gemini 3.1 Pro para diferentes perfiles de usuario
Los desarrolladores de distintos perfiles obtendrán beneficios variados con la actualización de la versión 3.0 a la 3.1. Aquí tienes algunas recomendaciones específicas:
| Tipo de usuario | Diferencia más beneficiosa | Prioridad de actualización | Acción recomendada |
|---|---|---|---|
| Desarrolladores de Agentes de IA | Agente/Búsqueda +45%, MCP Atlas +28% | ⭐⭐⭐⭐⭐ | Cambiar de inmediato, la mejora es muy notable |
| Herramientas de asistencia de código | SWE-Bench +5%, Terminal-Bench +20% | ⭐⭐⭐⭐ | Recomendado, basta con usar el modo "medium" |
| Analistas de datos | Razonamiento ARC-AGI-2 +148%, carga de 100MB | ⭐⭐⭐⭐⭐ | Prioridad alta, la capacidad de análisis de archivos grandes mejora drásticamente |
| Creadores de contenido | Salida larga de 65K, análisis de URL de YouTube | ⭐⭐⭐⭐ | Recomendado, las nuevas funciones son muy prácticas |
| Usuarios de API ligera | Eficiencia de salida +15%, costo sin cambios | ⭐⭐⭐ | Cambiar cuando sea conveniente, mejor rendimiento al mismo precio |
| Aplicaciones sensibles a la seguridad | Mejora en seguridad y confiabilidad, estabilidad en tareas largas | ⭐⭐⭐⭐ | Realizar pruebas de regresión antes de cambiar |
💡 Sugerencia general: Independientemente de tu perfil, puedes usar APIYI (apiyi.com) para mantener las versiones 3.0 y 3.1 simultáneamente. Esto te permite realizar pruebas A/B para confirmar los resultados antes de la migración total. Costo de migración cero, riesgo cero.
Flujo de decisión para el cambio de versión de Gemini 3.1 Pro
Sigue estos pasos para decidir si actualizar:
- ¿Tu aplicación depende de la precisión del razonamiento? → Sí → Cambia de inmediato (mejora del 148% en ARC-AGI-2).
- ¿Tu aplicación involucra Agentes o Búsqueda? → Sí → Muy recomendado (BrowseComp +45%).
- ¿Tus indicaciones (prompts) están muy personalizadas? → Sí → Prueba primero con el modo "medium" para asegurar consistencia antes de migrar.
- ¿Solo haces preguntas y respuestas simples o traducciones? → Sí → Cambia en cualquier momento; el rendimiento será igual o mejor y más eficiente.
- ¿No estás seguro? → Ejecuta una prueba A/B con tus 5 indicaciones principales en APIYI (apiyi.com); tendrás una conclusión en 10 minutos.
Resumen: 9 diferencias clave
| # | Dimensión de la diferencia | 3.0 Pro → 3.1 Pro | Valor del cambio |
|---|---|---|---|
| 1 | Capacidad de razonamiento | ARC-AGI-2: 31.1% → 77.1% | Muy alto |
| 2 | Sistema de pensamiento | Nivel 2 → Nivel 3 (incluye Deep Think Mini) | Alto |
| 3 | Capacidad de codificación | SWE-Bench: 76.8% → 80.6% | Alto |
| 4 | Agente/Búsqueda | BrowseComp: 59.2% → 85.9% | Muy alto |
| 5 | Características de salida/API | Salida de 65K, carga de 100MB, URL de YouTube | Alto |
| 6 | Eficiencia de salida | Mejores resultados con menos tokens (+15%) | Alto |
| 7 | Seguridad y confiabilidad | Ligera mejora en seguridad, mayor estabilidad en tareas largas | Medio |
| 8 | Posicionamiento oficial | advanced → unprecedented depth | Señal clara |
| 9 | Escenarios de uso | Debería cambiarse en casi todos los casos | Definido |
Resumen en una frase: Mismo precio, compatibilidad de API y mejores métricas en todos los aspectos: Gemini 3.1 Pro Preview es la actualización generacional gratuita de la 3.0 Pro Preview. No hay ninguna razón para no cambiar.
Te recomendamos realizar la migración rápidamente a través de APIYI (apiyi.com); solo necesitas modificar el parámetro del modelo.
Referencias
-
Blog oficial de Google: Anuncio del lanzamiento de Gemini 3.1 Pro
- Enlace:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro - Descripción: Resultados oficiales de benchmarks e introducción de funciones.
- Enlace:
-
Model Card de Google DeepMind: Detalles técnicos y evaluación de seguridad de 3.1 Pro
- Enlace:
deepmind.google/models/model-cards/gemini-3-1-pro - Descripción: Datos de seguridad y parámetros detallados.
- Enlace:
-
Primera reseña de VentureBeat: Experiencia profunda de las características de Deep Think Mini
- Enlace:
venturebeat.com/technology/google-gemini-3-1-pro-first-impressions - Descripción: Informe de experiencia real del sistema de pensamiento de tres niveles.
- Enlace:
-
Artificial Analysis: Datos comparativos entre 3.1 Pro y 3.0 Pro
- Enlace:
artificialanalysis.ai/models/comparisons/gemini-3-1-pro-preview-vs-gemini-3-pro - Descripción: Comparativa de benchmarks de terceros y análisis de rendimiento.
- Enlace:
📝 Autor: APIYI Team | Para intercambio técnico, visita APIYI apiyi.com
📅 Fecha de actualización: 20 de febrero de 2026
🏷️ Palabras clave: Gemini 3.1 Pro vs 3.0 Pro, comparativa de modelos, razonamiento duplicado, SWE-Bench, ARC-AGI-2, Deep Think Mini