In April 2026, the two coding models most frequently discussed among developers in mainland China were GLM-5.1 and Claude Sonnet 4.6. The former was just open-sourced by Z.ai (formerly Zhipu) under the MIT license, topping the global open-source coding leaderboard by scoring 58.4 on SWE-Bench Pro, surpassing Claude Opus 4.6, GPT-5.4, and Gemini 3.1 Pro. The latter, described by Anthropic as "flagship-level performance in a mid-sized model," achieved 79.6% on SWE-bench Verified—nearly matching the 80.8% of Opus 4.6—while costing a fraction of the price and introducing a 1M token context window to the Sonnet series for the first time.
So, the question is—GLM-5.1 vs. Claude Sonnet 4.6: which one is actually better for real-world programming? This isn't a question with a one-sentence answer. Their strengths are distributed quite differently: GLM-5.1 has overtaken Sonnet 4.6 in "industrial-grade real-world code repair" benchmarks, yet Sonnet pulls ahead in overall average scores across third-party evaluations. This article will break down the real differences across 6 dimensions (code benchmarks, knowledge, pricing, context window, agentic long-range tasks, and ecosystem compatibility) and provide clear selection advice based on your business scenarios.

GLM-5.1 vs. Claude Sonnet 4.6: Core Data Overview
Before we dive into the comparison, let's lay out the key facts side-by-side. All data is sourced from public information provided by BenchLM, Z.ai, Anthropic, and third-party evaluation platforms.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Vendor | Z.ai (formerly Zhipu AI) | Anthropic |
| Release Date | 2026-04-07 (Open Source) | Early 2026 |
| Architecture | 754B MoE / 40B active | Undisclosed (Mid-tier Sonnet level) |
| License | ✅ MIT | ❌ Closed Source |
| Context Window | 200K (some platforms show 203K) | 200K → 1M (beta) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐ (Open Source #1, beats Opus 4.6) | Slightly lower than Opus 4.6 |
| BenchLM Coding Avg | 58.4 | 66.4 |
| BenchLM Knowledge Avg | 52.3 | 73.7 |
| BenchLM Total Score | 79 | 80 |
| Input Price ($/M) | $1.00 (Direct via Z.ai) | $3.00 |
| Output Price ($/M) | $3.20 (Direct via Z.ai) | $15.00 |
| Agent Long-range Tasks | ~8 hours per task | 70% user preference in Claude Code |
| APIYI Integration | ✅ Available at https://api.apiyi.com/v1 |
✅ Available |
| Compatible Tools | Claude Code / Cline / Cursor / OpenClaw | Same as left + Native Anthropic ecosystem |
🎯 Quick Decision Advice: The difference between the two isn't about "who is better," but rather "which scenario they excel in." If you want to run a head-to-head comparison immediately, APIYI (apiyi.com) has already launched both GLM-5.1 and Claude Sonnet 4.6. You only need to change the
modelfield to switch between them in your existing business code, allowing you to reach a more accurate conclusion for your specific tasks in under 15 minutes than any benchmark could provide.
Core Differences Between GLM-5.1 and Claude Sonnet 4.6: They Aren't the Same Class of Model
The first thing we need to clear up is this: GLM-5.1 and Claude Sonnet 4.6 are not strictly in the same "weight class." Their design goals are fundamentally different.
Model Positioning Differences
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Market Positioning | "Cutting-edge Open Source + Long-range Agent Coding" | "Mid-range Flagship · King of Cost-Performance" |
| Parameter Scale | Large Language Model (754B MoE) | Mid-sized Model (Parameters undisclosed) |
| Training Goal | Coding + Agent + Mathematical Reasoning | General + Coding + Knowledge + Safety |
| Business Model | MIT Open Source + Z.ai Self-operated API | Closed-source Subscription + API |
| Main Competitors | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Note this point: In Z.ai's internal positioning, GLM-5.1 is actually aimed at Claude Opus 4.6, not Sonnet 4.6. This means if you're strictly comparing "coding capability ceilings," the benchmark for GLM-5.1 should be Opus, not Sonnet. However, when it comes to the combination of "price + comprehensive capability + practicality," Sonnet 4.6 is a formidable opponent in the mid-range market, making a direct comparison highly valuable from an engineering perspective.
Current Status in Third-Party Benchmarks
According to the provisional leaderboard published by BenchLM in April 2026:
- Total Score: Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (1-point difference, nearly tied)
- Coding Average: Claude Sonnet 4.6 = 66.4, GLM-5.1 = 58.4 (Sonnet 4.6 leads by 8 points)
- Knowledge Average: Claude Sonnet 4.6 = 73.7, GLM-5.1 = 52.3 (Sonnet 4.6 leads by 21.4 points, the largest gap)
However, in another specialized benchmark, the situation is completely reversed:
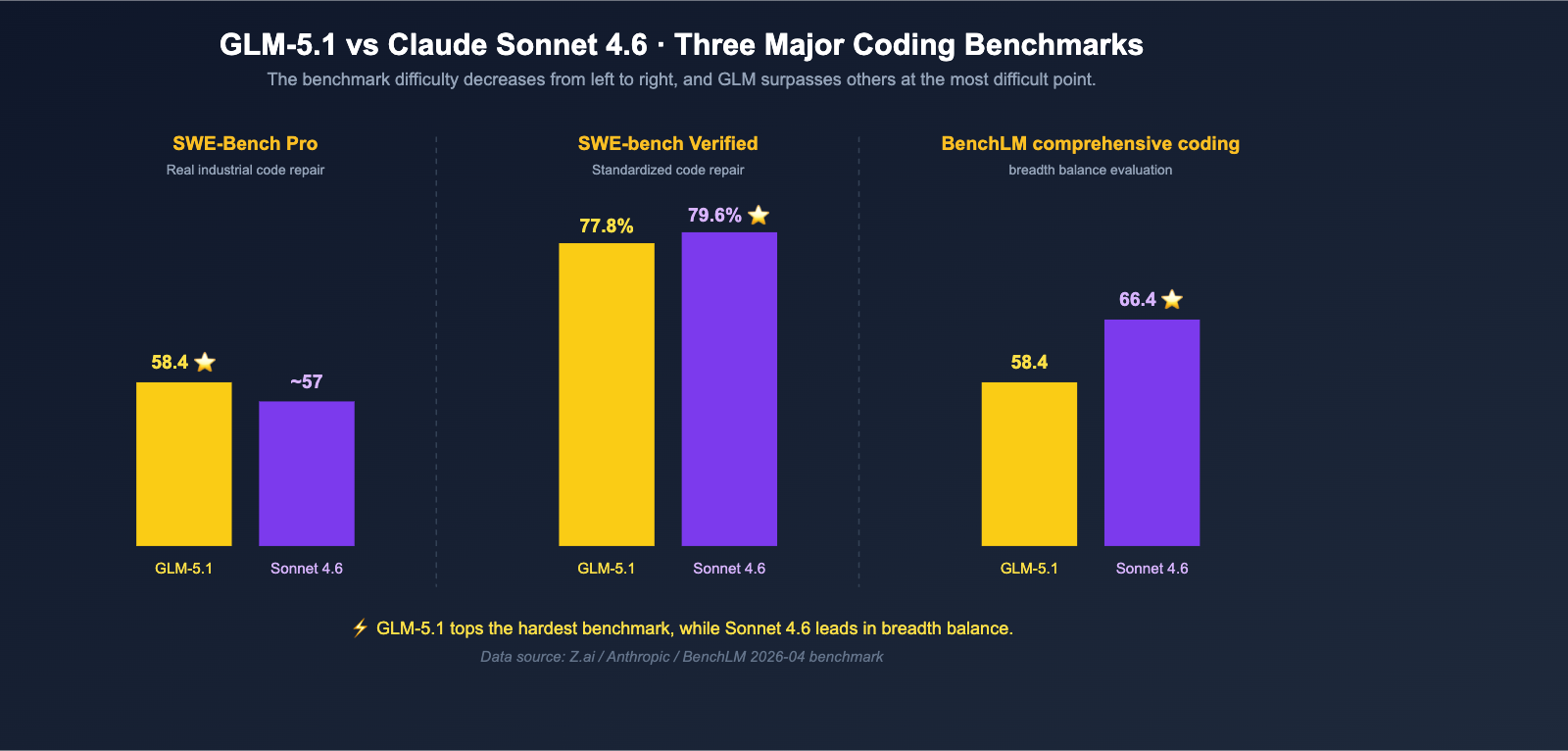
- SWE-Bench Pro (Real-world industrial code repair): GLM-5.1 = 58.4 ⭐, outperforming Claude Opus 4.6's 57.3 and GPT-5.4's 57.7, with Sonnet 4.6 naturally trailing behind.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%, a difference of only 1.8 percentage points.
Looking at these figures together leads to our first conclusion: GLM-5.1 isn't a monster that "comprehensively surpasses Sonnet 4.6," but it does take the top spot in "the most difficult industrial code repairs," while Sonnet 4.6 maintains a balanced lead in broader coding benchmarks.
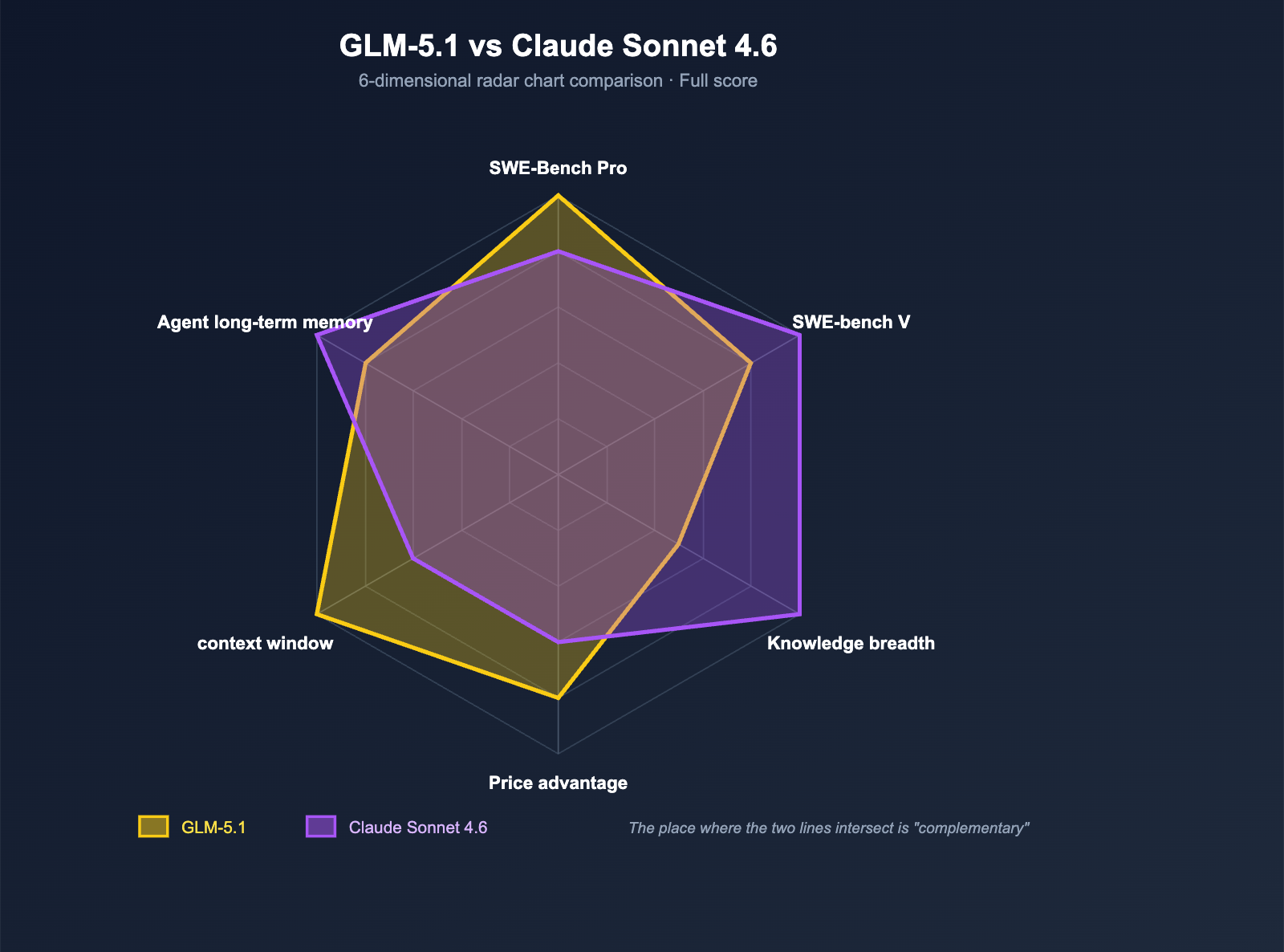
Dimension 1: Code Benchmark Comparison — The Real Gap Between GLM-5.1 and Sonnet 4.6
Coding capability is the core of this comparison and the area most easily misrepresented by benchmark numbers. We've consolidated all relevant benchmarks into a table, followed by an analysis from an engineer's perspective.
Complete Code Benchmark Comparison
| Benchmark | GLM-5.1 | Claude Sonnet 4.6 | Leader | Gap |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ pts |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| BenchLM Coding Avg | 58.4 | 66.4 | Sonnet 4.6 | 8 pts |
| OSWorld (Agent Desktop) | N/A | 72.5% | Sonnet 4.6 | — |
| Claude Code User Preference | N/A | 70% (vs Sonnet 4.5), 59% (vs Opus 4.5) | Sonnet 4.6 | — |
| 8-Hour Long-range Task | ✅ Official Focus | Supported in Claude Code | Nearly Tied | — |
Engineering Perspective
After reading this table a few times, we can distill a few conclusions that even non-benchmark enthusiasts can grasp:
- If your job is "fixing real bugs in real repositories": GLM-5.1 ranks first on SWE-Bench Pro. This is a benchmark that is "very close to the daily life of frontline engineers," meaning GLM-5.1 is best suited as the core engine for a Coding Agent.
- If your job is "standardized code repair + general programming": Sonnet 4.6 has a slightly higher score on SWE-bench Verified and a clear lead in the BenchLM coding average, making it more stable in terms of "breadth."
- If your job involves long-range tasks in Claude Code / Cursor: Sonnet 4.6's 70% user preference rate shows it's been validated in "actual development workflows." GLM-5.1's 8-hour long-range capability is a key selling point for Z.ai, but you'll need to test it yourself to confirm the results.
- If your work includes "knowledge-intensive tasks" (checking documentation, writing designs, technical research): The gap is significant, with Sonnet 4.6 at 73.7 vs. GLM-5.1 at 52.3.
Why Do These Benchmarks "Clash"?
Many readers ask: Why, if both are "coding capabilities," does one benchmark say GLM-5.1 is stronger while another says Sonnet 4.6 is? The answer lies in the differences in benchmark design:
- SWE-Bench Pro leans toward "highly difficult, real-world industrial code repairs." It has a high quality threshold and fewer tasks, demanding extreme 'long-range reasoning + tool calling' capabilities—which is exactly what GLM-5.1 focuses on.
- SWE-bench Verified is a "human-verified set of standard code repair tasks" that is closer to the "average level of daily development scenarios," requiring higher 'breadth + stability'—this is Sonnet 4.6's strength.
- BenchLM Coding Average takes a weighted average of multiple benchmarks, making it friendlier to mid-range flagships that can handle a wide variety of tasks.
Once you understand these differences, you won't be misled by any single isolated number.
🎯 Benchmark Selection Advice: Don't draw conclusions from just one benchmark. The most pragmatic approach is to compile 5-10 of your team's most common real-world coding tasks into an internal benchmark set. Then, use APIYI (apiyi.com) to invoke both GLM-5.1 and Claude Sonnet 4.6 to run them, and use your own data to verify which one better fits your business needs.
Dimension 2: Knowledge and Reasoning — Where Sonnet 4.6 Truly Shines
If the coding aspect is a "toss-up," then in the dimensions of knowledge, reasoning, and general understanding, Sonnet 4.6 holds a clear advantage.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 | Gap |
|---|---|---|---|
| BenchLM Knowledge Avg | 52.3 | 73.7 | 21.4 pts |
| Long Document Understanding | Strong | Stronger (w/ 1M context) | – |
| Natural Language Writing | Excellent (CN) | Balanced (Multi-lingual) | – |
| Safety & Compliance Reasoning | Moderate | Significantly Stronger (Anthropic's forte) | – |
This makes Sonnet 4.6 the safer, more reliable choice for scenarios like:
- Writing technical research reports, design documents, or architectural proposals;
- Cross-lingual document summarization and compliance analysis;
- Hybrid tasks that require "both coding and business logic" expertise;
- Customer-facing content generation that demands stricter safety guardrails.
The relative weakness of GLM-5.1 in the knowledge dimension isn't due to "poor training," but rather because its training data and objectives are heavily skewed toward coding, mathematics, and tool usage. It's simply not as balanced as Sonnet 4.6 when it comes to "general knowledge."
Dimension 3: Price Comparison — GLM-5.1's Killer Feature
If you look at only one thing, price is GLM-5.1's sharpest weapon against Sonnet 4.6.
Direct Token Price Comparison
| Dimension | GLM-5.1 (Z.ai Direct) | Claude Sonnet 4.6 | GLM-5.1 Cost Advantage |
|---|---|---|---|
| Input ($/M) | $1.00 | $3.00 | 3x cheaper |
| Output ($/M) | $3.20 | $15.00 | ~4.7x cheaper |
| Combined (2:1 ratio) | ~$1.73 | ~$7.00 | ~4x cheaper |
A few things to note:
- Prices for GLM-5.1 on third-party platforms (like BenchLM) are slightly higher ($1.40 input / $4.40 output) due to reseller markups; Z.ai's official direct pricing is $1.00 / $3.20.
- The $3 / $15 pricing for Sonnet 4.6 is the official Anthropic rate. It's already 5x cheaper than Opus 4.6, making it the "king of cost-performance" in the mid-range market.
- Even so, GLM-5.1's advantage in output tokens remains 4-5x, which is huge for code generation scenarios where "output volume exceeds input volume."
Real-World Cost Example
To make the gap more tangible, let's assume a typical "Daily Coding Agent" task: 5K tokens input, 20K tokens output, with 1,000 calls per day.
| Model | Input Cost/Day | Output Cost/Day | Total/Day | Total/Month |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
The gap: Sonnet 4.6's monthly cost is about 4.5x that of GLM-5.1.
For a mid-sized SaaS with "1,000 daily Agent calls," the token cost alone creates a difference of nearly $7,000 per month—enough to hire half an engineer.
🎯 Cost Optimization Tip: For teams already using Claude Sonnet 4.6, we recommend starting by routing 20% of traffic to GLM-5.1 via APIYI (apiyi.com) for A/B testing. If the results are acceptable, migrate all "non-critical code generation tasks" to GLM-5.1, keeping only "customer-facing" critical calls on Sonnet 4.6. This way, you can slash your bill significantly without sacrificing overall quality.
Dimension 4: Context Window — Sonnet 4.6 Strikes Back
While GLM-5.1 wins hands down on price, Sonnet 4.6 takes the initiative when it comes to the context window.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Standard Context | 200K (203K on some platforms) | 200K |
| Beta Context | — | 1M tokens (beta) |
| Max Output | 128K | Lower |
| Context Compression | No | ✅ Automatic compression of older context |
The 1M token capacity is a signature upgrade for Sonnet 4.6—it means you can stuff an entire mid-sized code repository into a prompt at once without needing RAG retrieval. For tasks like "full-repo refactoring / cross-file bug localization / complete codebase understanding," Sonnet 4.6 is virtually irreplaceable as of April 2026.
GLM-5.1's 200K is already sufficient for 90% of daily scenarios, but it does fall a bit short in "ultra-long context" edge cases.
Dimension 5: Agent Long-Run Tasks — A Clash of Two Approaches
The fifth dimension is Agent long-run task capability—this is the arena where all top-tier coding models are competing in 2026.
Different "Long-Run" Strategies
- GLM-5.1: Z.ai focuses on "8-hour continuous single-task performance," emphasizing an end-to-end loop of planning → execution → testing → fixing → secondary optimization. It relies on the model's inherent reasoning depth and tool-calling stability.
- Claude Sonnet 4.6: Anthropic focuses on the "Claude Code real-world experience." In internal testing, 70% of Sonnet 4.5 users preferred Sonnet 4.6, relying on the engineered Claude Code workflow + 1M context + context compression.
In short:
| Strategy | Core Advantage | Best For |
|---|---|---|
| GLM-5.1 | Model reasoning depth + tool-calling stability | Backend automated agents / unattended tasks |
| Sonnet 4.6 | Claude Code workflow + 1M context | Developer interactive coding / IDE integration |
If you're building "backend agents that develop features on their own" in an unattended scenario, GLM-5.1's 8-hour long-run capability is a natural fit. If you're an engineer chatting with a model in an IDE to write code, Sonnet 4.6's Claude Code integration offers a more mature experience.
Dimension 6: Ecosystem Compatibility — The Toolchain Advantage of Sonnet 4.6
The final dimension is the ecosystem. Sonnet 4.6 still holds a clear lead here, but GLM-5.1 is catching up fast.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Claude Code Compatibility | ✅ (OpenAI compatible endpoint) | ✅ Native |
| Cline / Cursor | ✅ (OpenAI compatible endpoint) | ✅ Native |
| OpenClaw | ✅ | ✅ |
| Anthropic Tool Use | OpenAI style | ✅ Native |
| Third-party Agent Frameworks | Mostly support OpenAI compatibility | Mostly support Anthropic native |
| Deployment Flexibility | ✅ MIT self-hosted / APIYI / Z.ai self-operated | APIYI / Anthropic official |
It's worth noting that APIYI (apiyi.com) supports all three native formats: OpenAI, Claude Native, and Gemini Native. This means that regardless of which style of SDK you prefer to use for your model invocations with GLM-5.1 and Sonnet 4.6, you can handle everything under a single API key. This is a highly practical detail in comparative testing—you don't need to maintain two sets of authentication, two monitoring systems, and two separate bills during your evaluation.
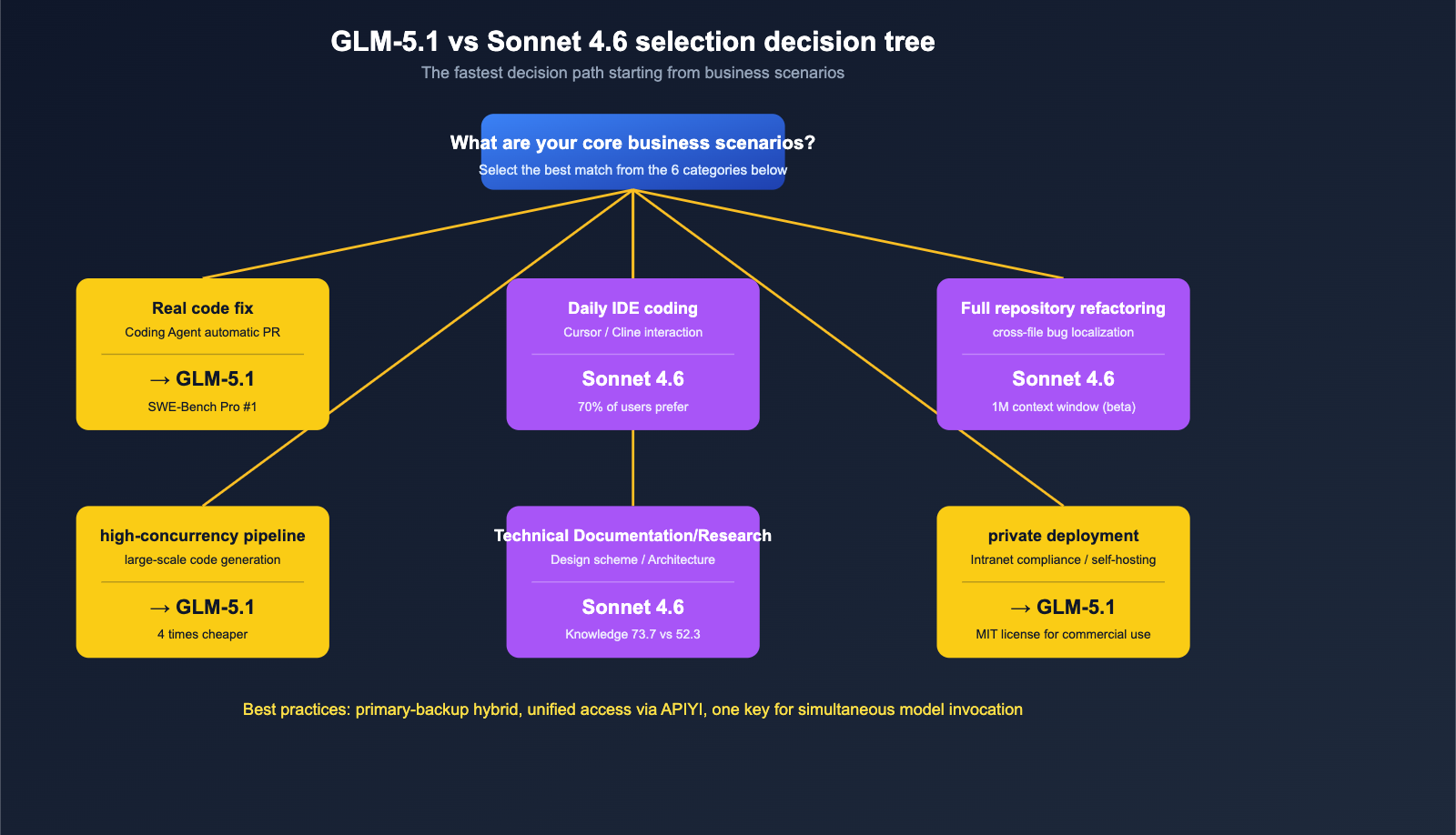
Final Selection Recommendations by Scenario
By connecting all six dimensions, we can provide specific "model selection by business scenario" recommendations.
Scenario Comparison Table
| Business Scenario | Recommended Model | Key Reason |
|---|---|---|
| Real-world industrial code repair (Agent auto-PR) | GLM-5.1 | #1 in SWE-Bench Pro globally + 8-hour long context |
| Daily IDE coding (Cursor / Cline) | Claude Sonnet 4.6 | 70% user preference for Claude Code, mature workflow |
| Full repository refactoring / Cross-file bug location | Claude Sonnet 4.6 | 1M context window (beta) is the ultimate weapon |
| Standardized code generation + High concurrency | GLM-5.1 | 4x cheaper, perfect for assembly-line production |
| Technical research / Design docs / Architecture | Claude Sonnet 4.6 | Knowledge score 73.7 vs 52.3, significant lead |
| Math reasoning / Algorithmic competitions | GLM-5.1 | AIME 2026 95.3 + GPQA-Diamond 86.2 |
| Code generation module in customer-facing SaaS | Sonnet 4.6 (Main) + GLM-5.1 (Backup) | Sonnet for primary, GLM as fallback; cut costs while maintaining quality |
| Private deployment / Intranet compliance | GLM-5.1 | MIT license + self-hostable |
| Chinese language coding interaction | GLM-5.1 | Domestic model is more friendly to Chinese prompts |
| One-off complex reasoning + Long-chain tool use | Tie, requires self-testing | Both perform well, differences within 5% |
Recommended Hybrid Strategy
For the vast majority of mid-sized teams, we recommend a "Main + Backup Hybrid" strategy rather than choosing just one:
- Primary Model: Pick one based on your most frequent business scenario (GLM-5.1 for code repair, Sonnet 4.6 for IDE integration).
- Backup Model: Integrate the other one for A/B testing and canary releases on critical business tasks.
- Unified Access Layer: Use APIYI (apiyi.com) to call both with the same API key. Your business code only needs to change the
modelfield; no need to maintain two sets of authentication logic. - Cost Monitoring: View bills for both models separately in the APIYI dashboard to periodically determine which model offers better "price-performance" for your specific business, then dynamically adjust traffic ratios.
🎯 Hybrid Strategy Implementation Tip: On APIYI (apiyi.com), you can switch seamlessly between GLM-5.1 and Claude Sonnet 4.6 using the same API key—your code only needs to change one string. We suggest routing 70% of "non-critical code generation" traffic to GLM-5.1, while reserving 30% for "customer-facing + high-difficulty reasoning" tasks on Sonnet 4.6. This lets you enjoy the cost advantages of GLM-5.1 while ensuring stability in critical scenarios.
GLM-5.1 vs. Claude Sonnet 4.6 FAQ
Q1: Has GLM-5.1 really surpassed Claude Sonnet 4.6 in coding?
Partially, but it still lags in some areas. On the SWE-Bench Pro benchmark (which tests real-world industrial code repair), GLM-5.1 hit a score of 58.4, taking the global top spot. It has surpassed Claude Opus 4.6 (57.3) and GPT-5.4 (57.7), and naturally, Sonnet 4.6 as well. However, on SWE-bench Verified (standardized code repair), Sonnet 4.6 still leads with 79.6% compared to GLM-5.1’s 77.8%—a gap of about 1.8 percentage points. In terms of the BenchLM comprehensive coding average, Sonnet 4.6 leads with 66.4, about 8 points ahead of GLM-5.1’s 58.4. The verdict: GLM-5.1 has surpassed Sonnet 4.6 at the "peak of difficulty," but it still trails in "breadth and balance."
Q2: How much cheaper is GLM-5.1 compared to Claude Sonnet 4.6?
Based on official Z.ai direct pricing, GLM-5.1 costs $1.00 for input and $3.20 for output, while Claude Sonnet 4.6 is $3.00 for input and $15.00 for output. That makes input 3 times cheaper and output about 4.7 times cheaper. In a typical scenario involving "1,000 Coding Agent model invocations per day + 5K input / 20K output," Sonnet 4.6's monthly bill is roughly 4.5 times that of GLM-5.1. If your business involves "output volume significantly higher than input volume," the cost-effectiveness of GLM-5.1 becomes even more pronounced.
Q3: Which has a larger context window, GLM-5.1 or Sonnet 4.6?
Claude Sonnet 4.6 is larger. GLM-5.1 offers 200K (some platforms show 203K), while Sonnet 4.6 offers 200K → 1M tokens (beta). A 1M context window means Sonnet 4.6 can read a medium-sized code repository in one go, which is its core weapon for tasks like "full-repo refactoring / cross-file bug localization." If your tasks have a hard requirement for ultra-long context, Sonnet 4.6 is the safer choice.
Q4: I’m currently using Claude Sonnet 4.6 for Cursor / Cline. Is it worth switching to GLM-5.1?
It depends on your pain points. If you care most about your "bill," GLM-5.1 can cut your costs by half or more, making it worth the switch. If you care most about the "stability of your daily coding experience," Sonnet 4.6’s 70% user preference rate suggests it’s already well-validated in Claude Code workflows, and the migration gains might be outweighed by the risks. The safest approach is to use APIYI (apiyi.com) to route 20% of your traffic to GLM-5.1 for A/B testing, and decide whether to increase the ratio after a week.
Q5: Can both GLM-5.1 and Sonnet 4.6 be called via APIYI?
Yes, both are live. APIYI (apiyi.com) supports OpenAI, Claude Native, and Gemini Native formats simultaneously. You only need to change the base_url in your OpenAI SDK to https://api.apiyi.com/v1 and toggle the model between glm-5.1 and claude-sonnet-4-6 (or similar IDs). This allows you to run both in the same codebase, making horizontal comparisons highly efficient.
Q6: As an independent developer, which one should I choose?
If you can only pick one, look at your workflow first: If you're doing Coding Agent tasks / backend automation / large-scale code generation, choose GLM-5.1. If you're doing interactive IDE-based programming / full-repo refactoring / customer-facing content generation, choose Sonnet 4.6. If you don't want to make a difficult choice, connecting both and using APIYI for unified management is the best practice for developers in 2026—your bill will automatically optimize based on your model selection, and you won't be locked into any single vendor.
Summary: Final Verdict on GLM-5.1 vs. Claude Sonnet 4.6
Combining the six dimensions of comparison, the final verdict on GLM-5.1 vs. Claude Sonnet 4.6 can be summarized as follows: GLM-5.1 holds structural advantages in "high-difficulty industrial code repair + price + domestic open-source + long-range agents," while Claude Sonnet 4.6 maintains the lead in "breadth and balance + depth of knowledge + 1M context window + IDE workflow maturity." They aren't in a "who replaces whom" relationship, but rather act as complementary tools for different business scenarios.
For development teams in mainland China in late 2026, the smartest strategy isn't "either/or," but "primary-backup hybrid + unified access layer": Let GLM-5.1 handle cost-sensitive, long-range automation, and private compliance tasks, while letting Sonnet 4.6 handle user-facing, complex context, and technical writing tasks. By using a unified API proxy service like APIYI to put both under the same API key, and dynamically adjusting traffic ratios based on real business billing data, you can significantly slash your monthly bill without sacrificing quality.
🎯 Final Recommendation: Both GLM-5.1 and Claude Sonnet 4.6 are live on APIYI (apiyi.com). We suggest you create an API key at apiyi.com today, change your OpenAI SDK
base_urltohttps://api.apiyi.com/v1, and run 5 GLM-5.1 tasks, followed by 5 Sonnet 4.6 tasks using the same prompt to verify the conclusions in this article yourself. No benchmark can replace your own testing, but this 30-minute validation will give you a real feel for the two strongest coding models of 2026.
Author: APIYI Team | Focusing on AI Large Language Model implementation and coding toolchain evaluation. For more model comparisons and practical integration, please visit APIYI at apiyi.com.