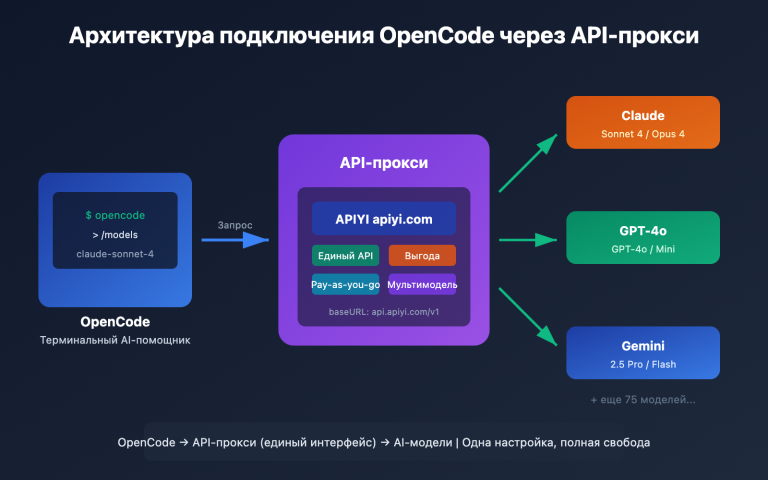
В апреле 2026 года в сообществах разработчиков в Китае самыми обсуждаемыми моделями для программирования стали GLM-5.1 и Claude Sonnet 4.6. Первая была только что выпущена компанией Z.ai (ранее Zhipu AI) под лицензией MIT и, набрав 58,4 балла в SWE-Bench Pro, обошла Claude Opus 4.6, GPT-5.4 и Gemini 3.1 Pro, мгновенно возглавив мировой рейтинг open-source моделей для кодинга. Вторая же была представлена Anthropic как «флагман среди моделей среднего уровня»: она показала 79,6% в SWE-bench Verified, почти догнав результат Opus 4.6 (80,8%), при этом стоит в разы дешевле и впервые для серии Sonnet получила контекстное окно в 1 млн токенов.
Возникает закономерный вопрос: GLM-5.1 или Claude Sonnet 4.6 — кто на самом деле круче в реальных задачах программирования? Однозначного ответа нет, так как их сильные стороны лежат в разных плоскостях: GLM-5.1 вырвалась вперед в бенчмарках по «исправлению реального промышленного кода», но в комплексных сторонних тестах Sonnet берет свое за счет более высоких средних показателей. В этой статье мы разберем реальные различия между ними по 6 критериям (бенчмарки кода, знания, цена, контекстное окно, долгосрочные задачи для агентов, совместимость с экосистемой) и дадим четкие рекомендации по выбору в зависимости от ваших бизнес-задач.

Краткий обзор ключевых данных: GLM-5.1 против Claude Sonnet 4.6
Прежде чем переходить к деталям, давайте сведем ключевые факты в одну таблицу. Все данные основаны на открытой информации от BenchLM, Z.ai, Anthropic и сторонних платформ тестирования.
| Критерий | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Разработчик | Z.ai (ранее Zhipu AI) | Anthropic |
| Дата выпуска | 07.04.2026 (open-source) | Начало 2026 г. |
| Архитектура | 754B MoE / 40B активных | Не раскрывается (уровень Sonnet) |
| Лицензия | ✅ MIT | ❌ Закрытая |
| Контекстное окно | 200K (на некоторых платформах 203K) | 200K → 1M (бета) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐ (№1 в open-source, обошла Opus 4.6) | Чуть ниже Opus 4.6 |
| BenchLM (средний балл кодинга) | 58.4 | 66.4 |
| BenchLM (средний балл знаний) | 52.3 | 73.7 |
| BenchLM (общий балл) | 79 | 80 |
| Цена входа ($/млн токенов) | $1.00 (прямая закупка Z.ai) | $3.00 |
| Цена выхода ($/млн токенов) | $3.20 (прямая закупка Z.ai) | $15.00 |
| Агентные задачи (длинные) | ~8 часов на задачу | 70% предпочтений пользователей Claude Code |
| Подключение через APIYI | ✅ Доступно https://api.apiyi.com/v1 |
✅ Доступно |
| Инструменты | Claude Code / Cline / Cursor / OpenClaw | То же + нативная экосистема Anthropic |
🎯 Совет для быстрого выбора: Разница между ними не в том, «кто сильнее», а в том, «для каких задач они лучше подходят». Если вы хотите провести быстрое сравнение, сервис-прокси API APIYI (apiyi.com) уже добавил поддержку и GLM-5.1, и Claude Sonnet 4.6. Вам достаточно просто изменить поле
modelв коде, чтобы переключаться между ними в рамках одной задачи. Так вы сможете получить более точные выводы для ваших реальных кейсов всего за 15 минут, чем из любых сторонних бенчмарков.
Основные различия между GLM-5.1 и Claude Sonnet 4.6: это модели разного класса
Первый факт, который нужно прояснить: GLM-5.1 и Claude Sonnet 4.6, строго говоря, не являются моделями «одного уровня», у них принципиально разные цели проектирования.
Различия в позиционировании моделей
| Параметр | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Позиционирование | «Передовой Open Source + длинные Agent-коды» | «Средний флагман · Лучшее соотношение цены и качества» |
| Масштаб параметров | Большая языковая модель (754B MoE) | Средняя модель (параметры не раскрыты) |
| Цель обучения | Кодинг + Агенты + Математические рассуждения | Универсальность + Кодинг + Знания + Безопасность |
| Бизнес-модель | MIT Open Source + API от Z.ai | Закрытый исходный код, подписка + API |
| Основные конкуренты | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Обратите внимание: внутри Z.ai модель GLM-5.1 позиционируется как конкурент Claude Opus 4.6, а не Sonnet 4.6. Это означает, что если вы сравниваете «предельные возможности кодинга», то для GLM-5.1 в качестве эталона следует брать Opus, а не Sonnet. Однако, учитывая «цену + комплексные возможности + практичность», Sonnet 4.6 является очень сильным соперником на рынке среднего сегмента, поэтому их сравнение имеет большую инженерную ценность.
Текущая ситуация по независимым комплексным тестам
Согласно промежуточному рейтингу BenchLM, опубликованному в апреле 2026 года:
- Общий балл: Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (разница в 1 балл, почти наравне)
- Средний балл по кодингу: Claude Sonnet 4.6 = 66.4, GLM-5.1 = 58.4 (Sonnet 4.6 впереди на 8 баллов)
- Средний балл по знаниям: Claude Sonnet 4.6 = 73.7, GLM-5.1 = 52.3 (Sonnet 4.6 впереди на 21.4 балла, самый большой разрыв)
Однако в другом специализированном бенчмарке ситуация кардинально меняется:
- SWE-Bench Pro (реальное исправление промышленного кода): GLM-5.1 = 58.4 ⭐, обходит Claude Opus 4.6 (57.3) и GPT-5.4 (57.7), Sonnet 4.6 также остается позади.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%, разница всего 1.8 процентных пункта.
Сопоставив эти цифры, можно сделать первый вывод: GLM-5.1 — это не «монстр, полностью превосходящий Sonnet 4.6», но в категории «сложнейшего исправления промышленного кода» он действительно занял первое место, в то время как Sonnet 4.6 сохраняет сбалансированное лидерство в более широких тестах по программированию.
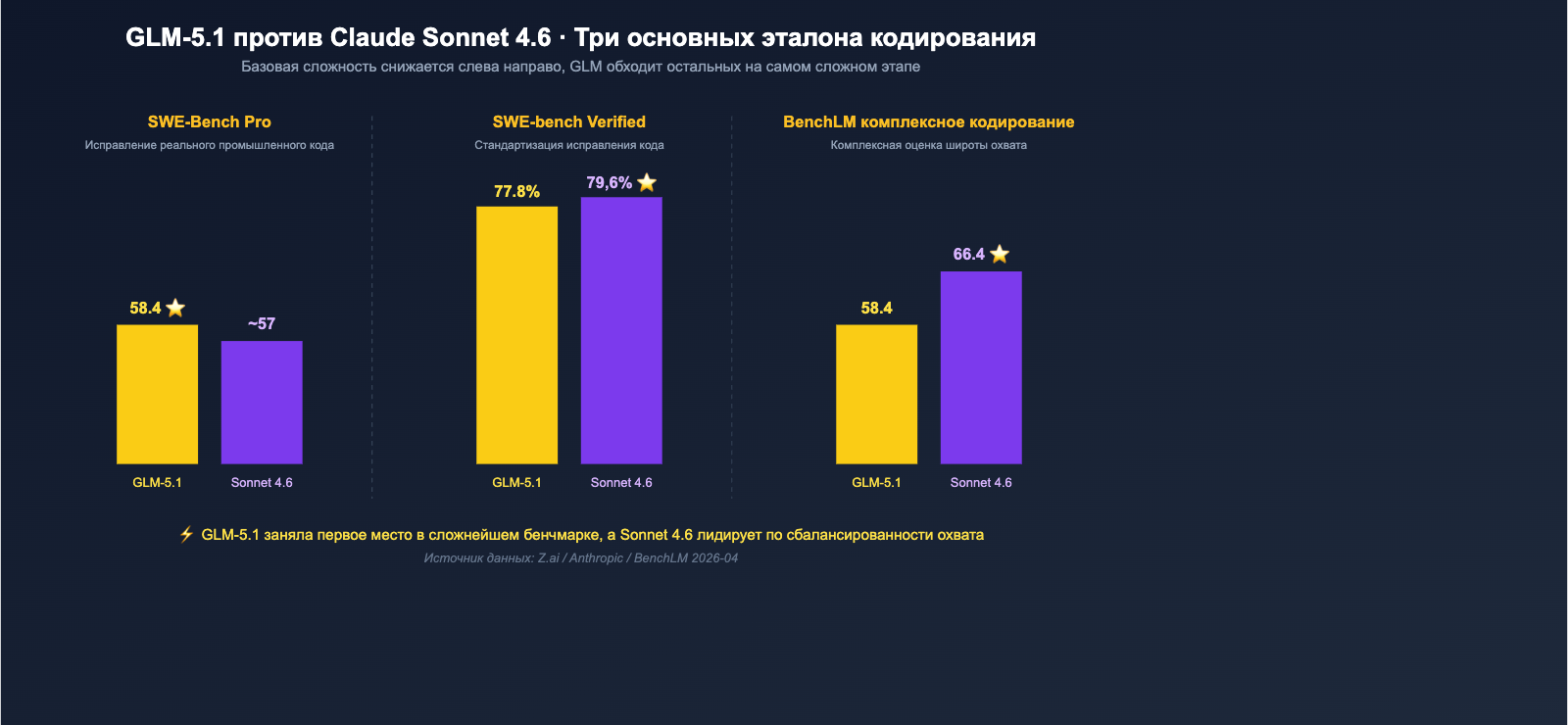
Измерение 1: Сравнение кодовых бенчмарков — реальная разница между GLM-5.1 и Sonnet 4.6
Возможности кодинга — это ядро данного сравнения и часть, где легче всего ввести в заблуждение цифрами бенчмарков. Мы собрали все соответствующие показатели в одну таблицу, а затем проанализируем их с точки зрения инженера.
Полная таблица кодовых бенчмарков
| Бенчмарк | GLM-5.1 | Claude Sonnet 4.6 | Лидер | Разница |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ балл |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| BenchLM (кодинг) | 58.4 | 66.4 | Sonnet 4.6 | 8 баллов |
| OSWorld (агент для десктопа) | нет данных | 72.5% | Sonnet 4.6 | — |
| Предпочтения пользователей Claude Code | нет данных | 70%(vs Sonnet 4.5), 59%(vs Opus 4.5) | Sonnet 4.6 | — |
| 8-часовые длинные задачи | ✅ фишка модели | Поддержка длинных задач | Почти наравне | — |
Интерпретация с точки зрения инженера
Изучив эту таблицу, можно сделать несколько выводов, понятных даже тем, кто не является фанатом промышленных бенчмарков:
- Если ваша работа — «исправление реальных багов в реальных репозиториях»: GLM-5.1 занимает первое место в SWE-Bench Pro. Это бенчмарк, максимально «приближенный к будням инженера», что означает, что GLM-5.1 лучше всего подходит в качестве основного движка для Coding Agent.
- Если ваша работа — «стандартное исправление кода + общее программирование»: Sonnet 4.6 показывает чуть лучшие результаты в SWE-bench Verified, а также явное лидерство в комплексном балле BenchLM. Он стабильнее в «широте» задач.
- Если вы используете Claude Code / Cursor для длинных задач: 70% предпочтений пользователей Sonnet 4.6 говорят о том, что он проверен в «реальном процессе разработки». 8-часовая способность GLM-5.1 — это главная фишка Z.ai, но ее нужно тестировать самостоятельно, чтобы подтвердить эффективность.
- Если ваша работа включает «задачи, требующие глубоких знаний» (поиск по документации, написание архитектуры, технические исследования): разрыв очевиден — 73.7 у Sonnet 4.6 против 52.3 у GLM-5.1.
Почему бенчмарки «конфликтуют» между собой?
Многие читатели спросят: почему, если речь идет об одних и тех же «способностях к кодингу», один бенчмарк говорит, что GLM-5.1 сильнее, а другой — что Sonnet 4.6? Ответ кроется в различиях дизайна бенчмарков:
- SWE-Bench Pro ориентирован на «сложнейшее исправление реального промышленного кода». Высокий порог качества задач и их небольшое количество требуют от модели максимальных способностей к «длинным рассуждениям + вызову инструментов» — это именно то, на чем специализируется GLM-5.1.
- SWE-bench Verified — это «набор проверенных человеком стандартных задач по исправлению кода», более близкий к «среднему уровню повседневных задач разработки». Здесь от модели требуется большая «широта + стабильность» — это сильная сторона Sonnet 4.6.
- Комплексный балл BenchLM рассчитывается как средневзвешенное значение нескольких бенчмарков, что более выгодно для среднего флагмана, способного справиться с «любыми задачами».
Поняв эту разницу, вы больше не будете введены в заблуждение какой-то одной изолированной цифрой.
🎯 Совет по выбору: не делайте выводов на основе одного бенчмарка. Самый прагматичный подход: соберите 5-10 типичных задач вашей команды в собственный набор тестов, а затем через APIYI (apiyi.com) вызовите GLM-5.1 и Claude Sonnet 4.6, чтобы на ваших собственных данных проверить, какая модель лучше подходит под ваш стиль работы.
Измерение 2: Знания и логические рассуждения — явное преимущество Sonnet 4.6
Если на уровне написания кода модели идут «ноздря в ноздрю», то в категории знаний, логических рассуждений и общего понимания преимущество Sonnet 4.6 становится очевидным.
| Измерение | GLM-5.1 | Claude Sonnet 4.6 | Разрыв |
|---|---|---|---|
| Средний балл знаний BenchLM | 52.3 | 73.7 | 21.4 балла |
| Понимание длинных документов | Сильно | Сильнее (с учетом контекстного окна 1M) | |
| Написание на естественном языке | Отлично на кит. | Сбалансировано для многих языков | |
| Безопасность и логика соответствия | Средне | Явно сильнее (сильная сторона Anthropic) |
Это означает, что для следующих задач Sonnet 4.6 будет более надежным выбором:
- Написание технических отчетов, проектной документации и архитектурных решений;
- Кросс-языковое резюмирование документов и анализ на соответствие требованиям;
- Гибридные задачи, требующие «понимания и кода, и бизнес-логики»;
- Генерация контента для прямого взаимодействия с клиентами, где требуются строгие фильтры безопасности.
Относительное отставание GLM-5.1 в плане знаний связано не с «недостаточным обучением», а с тем, что его обучающие данные и цели больше ориентированы на код, математику и использование инструментов, поэтому в плане «общих знаний» он менее сбалансирован, чем Sonnet 4.6.
Измерение 3: Сравнение цен — козырь GLM-5.1
Если смотреть только на один показатель, то цена — это самое мощное оружие GLM-5.1 в противостоянии с Sonnet 4.6.
Прямое сравнение стоимости токенов
| Измерение | GLM-5.1 (прямая закупка Z.ai) | Claude Sonnet 4.6 | Преимущество GLM-5.1 |
|---|---|---|---|
| Вход ($/млн) | $1.00 | $3.00 | Дешевле в 3 раза |
| Выход ($/млн) | $3.20 | $15.00 | Дешевле в ~4.7 раза |
| Итого (соотношение 2:1) | ~$1.73 | ~$7.00 | Дешевле в ~4 раза |
Важные примечания:
- Цены на GLM-5.1 на сторонних платформах (например, BenchLM) немного выше ($1.40 за вход / $4.40 за выход), так как включают наценку перекупщиков, в то время как официальная цена прямой закупки Z.ai составляет $1.00 / $3.20;
- Цена Sonnet 4.6 в $3 / $15 — это официальный прайс Anthropic, который уже в 5 раз дешевле Opus 4.6, что делает его «королем соотношения цены и качества» в среднем сегменте;
- Несмотря на это, преимущество GLM-5.1 в стоимости выходных токенов остается на уровне 4-5 раз, что имеет огромное значение для задач генерации кода, где объем вывода превышает объем ввода.
Пример реальных затрат
Чтобы наглядно показать разницу, возьмем типичную задачу «повседневного агента по написанию кода»: 5 тыс. токенов на входе, 20 тыс. токенов на выходе, 1000 вызовов в день.
| Модель | Стоимость входа/день | Стоимость выхода/день | Итого/день | Итого/месяц |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
Разрыв: месячные затраты на Sonnet 4.6 примерно в 4.5 раза выше, чем на GLM-5.1.
Для среднего SaaS-проекта с «1000 вызовов агента в день» только на одних токенах можно экономить почти 7000 долларов в месяц — этих денег хватит, чтобы нанять еще пол-инженера.
🎯 Совет по оптимизации затрат: командам, которые уже используют Claude Sonnet 4.6, мы рекомендуем сначала перенаправить 20% трафика на GLM-5.1 через APIYI (apiyi.com) для A/B-тестирования. Если результаты приемлемы, перенесите всю «некритичную генерацию кода» на GLM-5.1, оставив Sonnet 4.6 только для ключевых вызовов, ориентированных на клиентов. Это позволит значительно сократить счета без потери общего качества.
Измерение 4: Контекстное окно — ответный удар Sonnet 4.6
По цене GLM-5.1 выигрывает с большим отрывом, но в плане контекстного окна инициативу перехватывает Sonnet 4.6.
| Измерение | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Стандартный контекст | 200K (на некоторых платформах 203K) | 200K |
| Beta-контекст | — | 1M токенов (beta) |
| Максимальный вывод | 128K | ниже |
| Сжатие контекста | нет | ✅ автоматическое сжатие старого контекста |
1M токенов — это знаковое обновление для Sonnet 4.6. Оно означает, что вы можете загрузить целый средний репозиторий кода прямо в промпт без необходимости использования RAG-поиска. Для таких задач, как «рефакторинг всего репозитория / поиск багов между файлами / полное понимание кодовой базы», Sonnet 4.6 в апреле 2026 года практически незаменим.
200K у GLM-5.1 тоже вполне достаточно для 90% повседневных сценариев, но в экстремальных случаях с «супердлинным контекстом» модель всё же немного отстает.
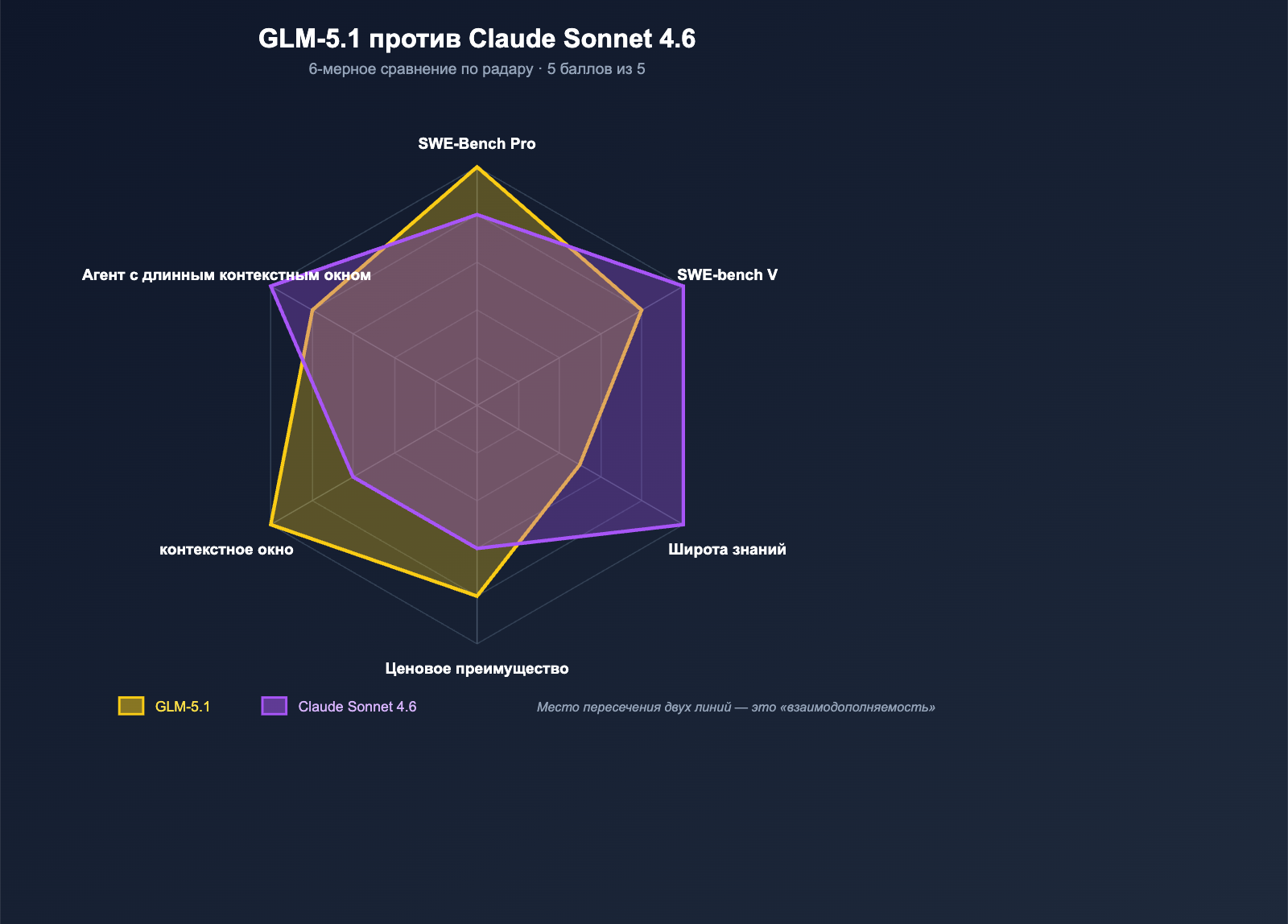
Измерение 5: Долгосрочные задачи Agent — дуэль двух подходов
Пятое измерение — это способность Agent к выполнению долгосрочных задач, направление, в котором соревнуются все топовые модели для кодинга в 2026 году.
Разные подходы к «долгосрочности»
- GLM-5.1: Z.ai делает ставку на «8-часовую непрерывную работу над одной задачей», подчеркивая сквозной цикл планирование → выполнение → тестирование → исправление → вторичная оптимизация. Всё держится на глубине рассуждений самой модели и стабильности вызова инструментов;
- Claude Sonnet 4.6: Anthropic делает ставку на «практический опыт Claude Code». 70% пользователей Sonnet 4.5 в ходе внутреннего тестирования отдали предпочтение Sonnet 4.6. Успех обеспечивается инженерным рабочим процессом Claude Code + 1M контекста + сжатие контекста.
Если кратко:
| Подход | Ключевое преимущество | Подходящие сценарии |
|---|---|---|
| GLM-5.1 | Глубина рассуждений + стабильность вызова инструментов | Фоновые автоматизированные Agent / задачи без присмотра |
| Sonnet 4.6 | Рабочий процесс Claude Code + 1M контекста | Интерактивное кодирование для разработчиков / интеграция в IDE |
Если вы занимаетесь «фоновыми Agent, которые сами разрабатывают функции» в режиме без присмотра, то 8-часовая долгосрочная способность GLM-5.1 подходит идеально. Если же вы — «инженер, который общается с моделью в IDE для написания кода», то интеграция Claude Code в Sonnet 4.6 будет гораздо более зрелым решением.
Измерение 6: Экосистемная совместимость — преимущество инструментария Sonnet 4.6
Последний критерий — экосистема. Здесь Sonnet 4.6 по-прежнему уверенно лидирует, хотя GLM-5.1 уже наступает на пятки.
| Измерение | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Совместимость с Claude Code | ✅ (через шлюз OpenAI) | ✅ Нативная |
| Cline / Cursor | ✅ (через шлюз OpenAI) | ✅ Нативная |
| OpenClaw | ✅ | ✅ |
| Вызов инструментов Anthropic | Стиль OpenAI | ✅ Нативная |
| Сторонние Agent-фреймворки | Большинство через OpenAI | Большинство через Anthropic |
| Гибкость развертывания | ✅ MIT self-hosted / APIYI / Z.ai | APIYI / Официально Anthropic |
Важно отметить, что APIYI (apiyi.com) поддерживает сразу три нативных формата: OpenAI, Claude Native и Gemini Native. Это значит, что какой бы стиль SDK вы ни выбрали для вызова GLM-5.1 или Sonnet 4.6, всё можно настроить под одним API-ключом. В сравнительных тестах это крайне полезная деталь — вам не нужно поддерживать две системы аутентификации, два мониторинга и две разные биллинговые системы.
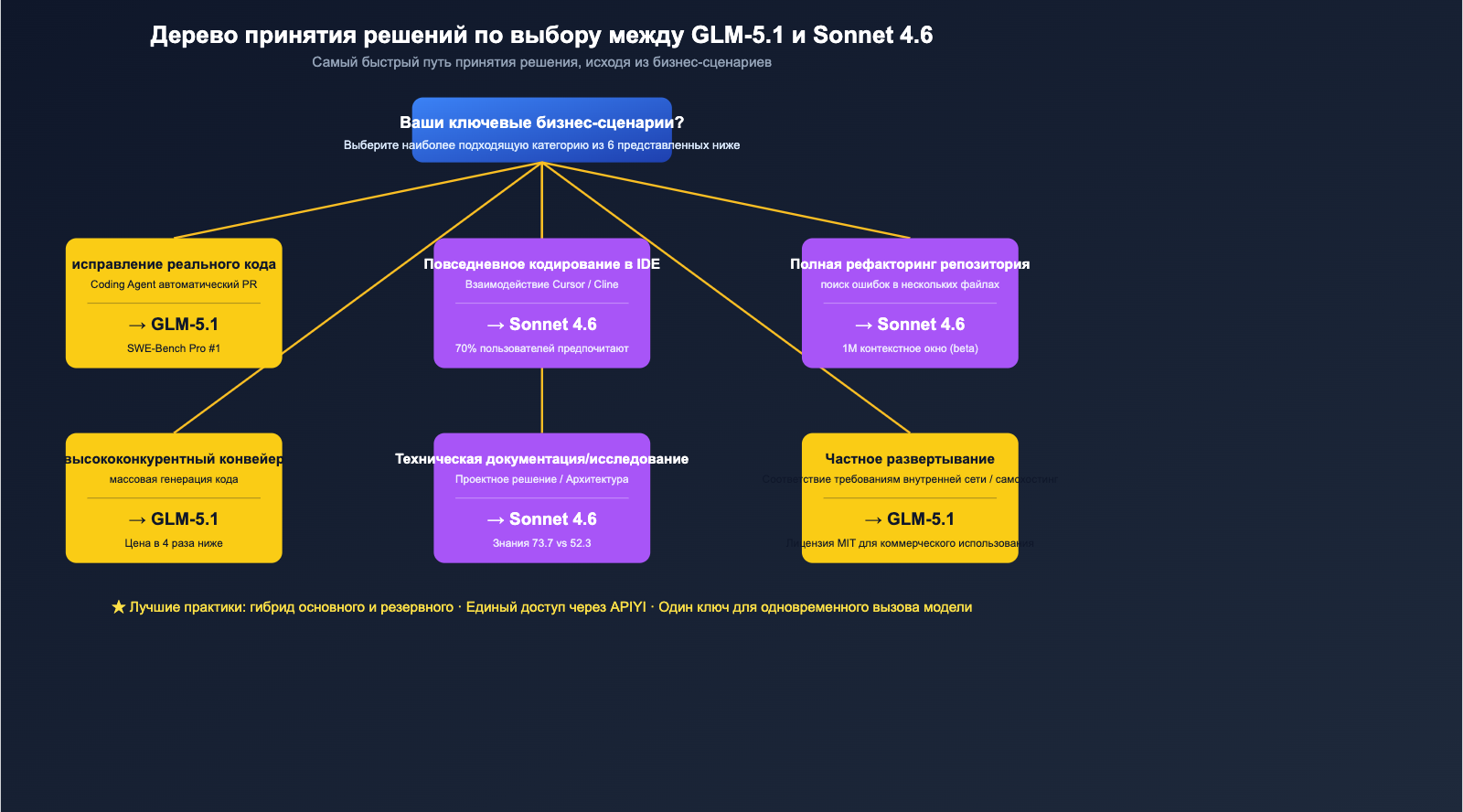
Рекомендации по выбору модели для разных сценариев
Собрав все 6 измерений воедино, мы можем дать конкретные рекомендации по выбору модели в зависимости от ваших бизнес-задач.
Таблица соответствия сценариям
| Бизнес-сценарий | Рекомендуемая модель | Ключевое обоснование |
|---|---|---|
| Исправление реального промышленного кода (авто-PR) | GLM-5.1 | №1 в мире по SWE-Bench Pro + 8-часовое контекстное окно |
| Повседневная разработка в Cursor / Cline | Claude Sonnet 4.6 | 70% предпочтений пользователей Claude Code, зрелый воркфлоу |
| Рефакторинг всего репозитория / поиск багов | Claude Sonnet 4.6 | Контекстное окно 1М (beta) — главное оружие |
| Стандартная генерация кода + высокая нагрузка | GLM-5.1 | В 4 раза дешевле, идеально для конвейерного производства |
| Технический обзор / архитектурные решения | Claude Sonnet 4.6 | Значительный отрыв в знаниях (73.7 против 52.3) |
| Математические рассуждения / олимпиадные задачи | GLM-5.1 | AIME 2026: 95.3 + GPQA-Diamond: 86.2 |
| Генерация кода в клиентском SaaS | Sonnet 4.6 (осн.) + GLM-5.1 (резерв) | Sonnet для качества, GLM для экономии и страховки |
| Приватное развертывание / комплаенс | GLM-5.1 | Лицензия MIT + возможность self-hosting |
| Взаимодействие на китайском языке | GLM-5.1 | Модель лучше понимает китайские промпты |
| Сложные разовые задачи + длинные цепочки инструментов | Ничья, нужно тестировать | Обе справляются, разница в пределах 5% |
Рекомендуемая гибридная стратегия
Для большинства средних команд мы рекомендуем стратегию «основная + резервная» вместо выбора чего-то одного:
- Основная модель: выберите ту, что лучше подходит под ваш главный сценарий (GLM-5.1 для фикса кода, Sonnet 4.6 для IDE).
- Резервная модель: подключите вторую для A/B-тестирования и плавного переключения (канареечный релиз).
- Единый уровень доступа: используйте APIYI (apiyi.com) с одним API-ключом. В коде достаточно менять только поле
model, не нужно плодить логику аутентификации. - Мониторинг затрат: в консоли APIYI можно раздельно отслеживать расходы по моделям, чтобы понимать, какая из них эффективнее для вашего бизнеса, и динамически распределять трафик.
🎯 Совет по внедрению: через APIYI (apiyi.com) вы можете бесшовно переключаться между GLM-5.1 и Claude Sonnet 4.6, меняя лишь одну строку в коде. Мы советуем направлять 70% трафика «некритичной генерации» на GLM-5.1, а 30% «клиентских задач и сложных рассуждений» — на Sonnet 4.6. Это позволит использовать ценовое преимущество GLM-5.1, сохраняя стабильность в критических узлах.
FAQ: GLM-5.1 против Claude Sonnet 4.6
Q1: Действительно ли GLM-5.1 превзошел Claude Sonnet 4.6 в написании кода?
Частично превзошел, но в чем-то все еще отстает. В самом сложном бенчмарке SWE-Bench Pro (реальное исправление промышленного кода) GLM-5.1 набрал 58,4 балла, заняв первое место в мире. Он обошел Claude Opus 4.6 (57,3) и GPT-5.4 (57,7), а значит, и Sonnet 4.6. Однако в SWE-bench Verified (стандартизированное исправление кода) Sonnet 4.6 все еще впереди: 79,6% против 77,8% у GLM-5.1. В комплексном рейтинге кодинга BenchLM модель Sonnet 4.6 также лидирует с результатом 66,4 балла против 58,4 у GLM-5.1. Итог: GLM-5.1 берет «пиковую сложность», но Sonnet 4.6 выигрывает за счет «сбалансированности и широты охвата».
Q2: Насколько GLM-5.1 дешевле, чем Claude Sonnet 4.6?
Согласно официальным ценам Z.ai, GLM-5.1 стоит $1,00 за вход / $3,20 за выход, тогда как Claude Sonnet 4.6 — $3,00 / $15,00. Вход дешевле в 3 раза, а выход — примерно в 4,7 раза. В типичном сценарии «1000 вызовов Coding Agent в день + 5K вход / 20K выход» ежемесячный счет за Sonnet 4.6 будет примерно в 4,5 раза выше, чем за GLM-5.1. Если в вашем бизнесе объем исходящих данных значительно превышает входящие, преимущество GLM-5.1 в цене будет еще заметнее.
Q3: У кого из них больше контекстное окно?
У Claude Sonnet 4.6 оно больше. У GLM-5.1 это 200K (на некоторых платформах отображается как 203K), а у Sonnet 4.6 — от 200K до 1M токенов (бета). Контекст в 1M означает, что Sonnet 4.6 может за один раз «проглотить» средний репозиторий кода, что является его главным козырем в задачах вроде «рефакторинга всего проекта» или «поиска багов между файлами». Если вам критически важен сверхдлинный контекст, Sonnet 4.6 — более надежный выбор.
Q4: Я сейчас использую Claude Sonnet 4.6 в Cursor / Cline, стоит ли переходить на GLM-5.1?
Зависит от ваших приоритетов. Если вас больше всего волнует «счет за API», то GLM-5.1 поможет сократить расходы вдвое или даже больше — переходить стоит. Если же вы цените «стабильность повседневного кодинга», то 70% предпочтений пользователей в пользу Sonnet 4.6 говорят о том, что модель уже отлично зарекомендовала себя в рабочих процессах Claude Code, и риски при миграции могут перевесить выгоду. Самый разумный подход: сначала через APIYI (apiyi.com) переключить 20% трафика на GLM-5.1 для A/B-тестирования, и через неделю решить, стоит ли увеличивать долю.
Q5: Можно ли вызывать и GLM-5.1, и Sonnet 4.6 через APIYI?
Да, обе модели уже доступны. APIYI (apiyi.com) поддерживает три нативных формата: OpenAI, Claude Native и Gemini Native. Вам достаточно изменить base_url в SDK OpenAI на https://api.apiyi.com/v1 и переключать model между glm-5.1 и claude-sonnet-4-6 (или аналогичным ID). Это позволяет запускать обе модели в одном и том же коде, что крайне удобно для проведения сравнительного анализа.
Q6: Что выбрать независимому разработчику?
Если нужно выбрать что-то одно, посмотрите на свой рабочий процесс: для Coding Agent / автоматизации бэкенда / массовой генерации кода — выбирайте GLM-5.1; для интерактивного программирования в IDE / рефакторинга всего репозитория / генерации контента для клиентов — выбирайте Sonnet 4.6. Если не хотите делать сложный выбор, подключите обе модели и управляйте ими через APIYI — это лучшая практика для разработчика в 2026 году. Ваши расходы будут автоматически оптимизироваться в зависимости от выбранной модели, и вы не будете привязаны к одному вендору.
Итог: Вердикт по GLM-5.1 vs Claude Sonnet 4.6
Сложив все 6 измерений, итоговый вердикт по GLM-5.1 vs Claude Sonnet 4.6 можно сформулировать так: GLM-5.1 обладает структурным преимуществом в «сложнейшем промышленном исправлении кода + цене + отечественном open-source + долгосрочных агентах», а Claude Sonnet 4.6 лидирует в «сбалансированности, глубине знаний, контексте 1M и зрелости рабочих процессов в IDE». Это не отношения «кто кого заменит», а пара инструментов, дополняющих друг друга в разных бизнес-сценариях.
Для команд разработчиков в Китае во второй половине 2026 года самая умная стратегия — не «или-или», а «гибрид + единый уровень доступа»: используйте GLM-5.1 для задач, чувствительных к стоимости, долгосрочной автоматизации и соблюдения требований приватности, а Sonnet 4.6 — для клиентских задач, сложного контекста и технического письма. Объединив их под одним API-ключом через сервис-прокси APIYI и динамически регулируя трафик на основе реальных данных по счетам, вы сможете значительно сократить ежемесячные расходы без потери качества.
🎯 Финальный совет: GLM-5.1 и Claude Sonnet 4.6 уже доступны на APIYI (apiyi.com). Мы рекомендуем создать API-ключ на apiyi.com прямо сегодня, изменить
base_urlв SDK OpenAI наhttps://api.apiyi.com/v1, запустить 5 задач на GLM-5.1, а затем те же 5 задач с тем же промптом на Sonnet 4.6. Никакие обзоры не заменят личного тестирования, но этот 30-минутный эксперимент даст вам реальное понимание того, как работают две лучшие модели для кодинга 2026 года.
Автор: Команда APIYI | Мы следим за внедрением больших языковых моделей и оценкой инструментов для кодинга. Больше сравнений моделей и практических кейсов вызовов — на APIYI (apiyi.com).