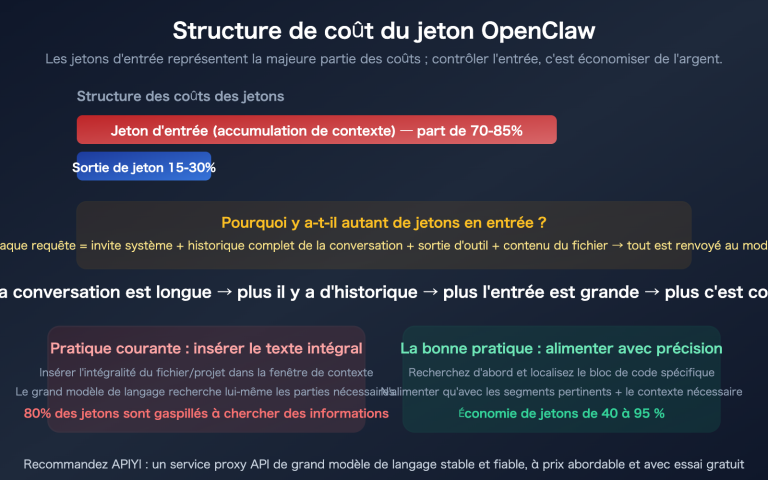
En avril 2026, les deux modèles de codage qui font le plus parler d'eux au sein de la communauté des développeurs en Chine sont GLM-5.1 et Claude Sonnet 4.6. Le premier vient d'être publié en open source sous licence MIT par Z.ai (anciennement Zhipu) ; avec un score de 58,4 sur SWE-Bench Pro, il a surpassé Claude Opus 4.6, GPT-5.4 et Gemini 3.1 Pro, se hissant instantanément au sommet du classement mondial des modèles de codage open source. Le second est qualifié par Anthropic de « niveau phare pour un modèle intermédiaire », atteignant 79,6 % sur SWE-bench Verified, soit presque autant que les 80,8 % d'Opus 4.6, tout en étant bien moins cher et en offrant, pour la première fois sur la série Sonnet, une fenêtre de contexte de 1M de tokens.
La question se pose donc : GLM-5.1 vs Claude Sonnet 4.6, lequel est le plus performant dans des scénarios de programmation réels ? Il n'y a pas de réponse simple. Leurs points forts sont très différents : GLM-5.1 a dépassé Sonnet 4.6 sur le benchmark de « correction de code réel de niveau industriel », mais Sonnet conserve une avance dans les évaluations globales tierces. Cet article décortique leurs différences réelles à travers 6 dimensions (benchmarks de code, connaissances, prix, contexte, tâches longues pour agents, compatibilité écosystémique) et vous propose des recommandations claires selon vos besoins métier.

Aperçu des données clés : GLM-5.1 vs Claude Sonnet 4.6
Avant de comparer, examinons les faits marquants côte à côte. Toutes les données proviennent d'informations publiques de BenchLM, Z.ai, Anthropic et de plateformes d'évaluation tierces.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Fournisseur | Z.ai (ex-Zhipu AI) | Anthropic |
| Date de sortie | 07/04/2026 (Open Source) | Début 2026 |
| Architecture | 754B MoE / 40B activés | Non publique (niveau Sonnet) |
| Licence Open Source | ✅ MIT | ❌ Propriétaire |
| Fenêtre de contexte | 200K (203K sur certaines plateformes) | 200K → 1M (beta) |
| SWE-bench Verified | 77,8 % | 79,6 % |
| SWE-Bench Pro | 58,4 ⭐ (Open Source #1, dépasse Opus 4.6) | Légèrement inférieur à Opus 4.6 |
| Score moyen codage BenchLM | 58,4 | 66,4 |
| Score moyen connaissances BenchLM | 52,3 | 73,7 |
| Score total BenchLM | 79 | 80 |
| Prix entrée ($/M) | 1,00 $ (achat direct Z.ai) | 3,00 $ |
| Prix sortie ($/M) | 3,20 $ (achat direct Z.ai) | 15,00 $ |
| Tâches longues pour agents | ~8 heures par tâche | 70 % de préférence utilisateur Claude Code |
| Accès via APIYI | ✅ Disponible https://api.apiyi.com/v1 |
✅ Disponible |
| Outils compatibles | Claude Code / Cline / Cursor / OpenClaw | Idem + écosystème Anthropic natif |
🎯 Conseil pour une décision rapide : La différence entre les deux n'est pas une question de « qui est le meilleur », mais de « quel scénario privilégier ». Si vous souhaitez effectuer une comparaison directe, APIYI (apiyi.com) propose déjà GLM-5.1 et Claude Sonnet 4.6. Il vous suffit de modifier le champ
modeldans votre code métier pour basculer de l'un à l'autre et obtenir, en moins de 15 minutes, un verdict plus précis pour vos tâches réelles que n'importe quel benchmark.
Différences fondamentales entre GLM-5.1 et Claude Sonnet 4.6 : ils ne jouent pas dans la même catégorie
Le premier fait qu'il faut clarifier est le suivant : le GLM-5.1 et le Claude Sonnet 4.6 ne sont pas, à proprement parler, des modèles de la "même gamme", leurs objectifs de conception diffèrent systématiquement.
Différences de positionnement des modèles
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Positionnement éditeur | "Open source de pointe + Codage Agent longue durée" | "Flagship milieu de gamme · Le meilleur rapport qualité-prix" |
| Ordre de grandeur des paramètres | Grand modèle de langage (754B MoE) | Modèle intermédiaire (paramètres non publics) |
| Objectif d'entraînement | Codage + Agent + Raisonnement mathématique | Généraliste + Codage + Connaissances + Sécurité |
| Modèle économique | Open source MIT + API propriétaire Z.ai | Abonnement fermé + API |
| Concurrents principaux | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Notez bien ce point : dans le positionnement interne de Z.ai, le GLM-5.1 vise en réalité le Claude Opus 4.6, et non le Sonnet 4.6. Cela signifie que si vous comparez simplement le "plafond des capacités de codage", le groupe de contrôle du GLM-5.1 devrait être l'Opus, pas le Sonnet. Cependant, sur le triptyque "prix + capacités globales + praticité", le Sonnet 4.6 est un adversaire très coriace sur le marché du milieu de gamme, ce qui rend la comparaison entre les deux très pertinente d'un point de vue ingénierie.
État des lieux des évaluations tierces globales
Selon le classement provisoire publié par BenchLM en avril 2026 :
- Score total : Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (1 point d'écart, quasi égalité)
- Moyenne de codage : Claude Sonnet 4.6 = 66,4, GLM-5.1 = 58,4 (Le Sonnet 4.6 mène de 8 points)
- Moyenne de connaissances : Claude Sonnet 4.6 = 73,7, GLM-5.1 = 52,3 (Le Sonnet 4.6 mène de 21,4 points, l'écart le plus important)
Mais sur un autre benchmark spécialisé, la situation s'inverse totalement :
- SWE-Bench Pro (correction de code industriel réel) : GLM-5.1 = 58,4 ⭐, surpassant le Claude Opus 4.6 (57,3) et le GPT-5.4 (57,7), le Sonnet 4.6 se situant naturellement en dessous.
- SWE-bench Verified : Claude Sonnet 4.6 = 79,6 %, GLM-5.1 = 77,8 %, seulement 1,8 point de pourcentage d'écart.
En comparant ces chiffres, on arrive à une première conclusion : le GLM-5.1 n'est pas un monstre qui "surpasse totalement le Sonnet 4.6", mais il a effectivement décroché la première place sur la "correction de code industriel complexe", tandis que le Sonnet 4.6 conserve une avance équilibrée sur les évaluations de codage plus larges.
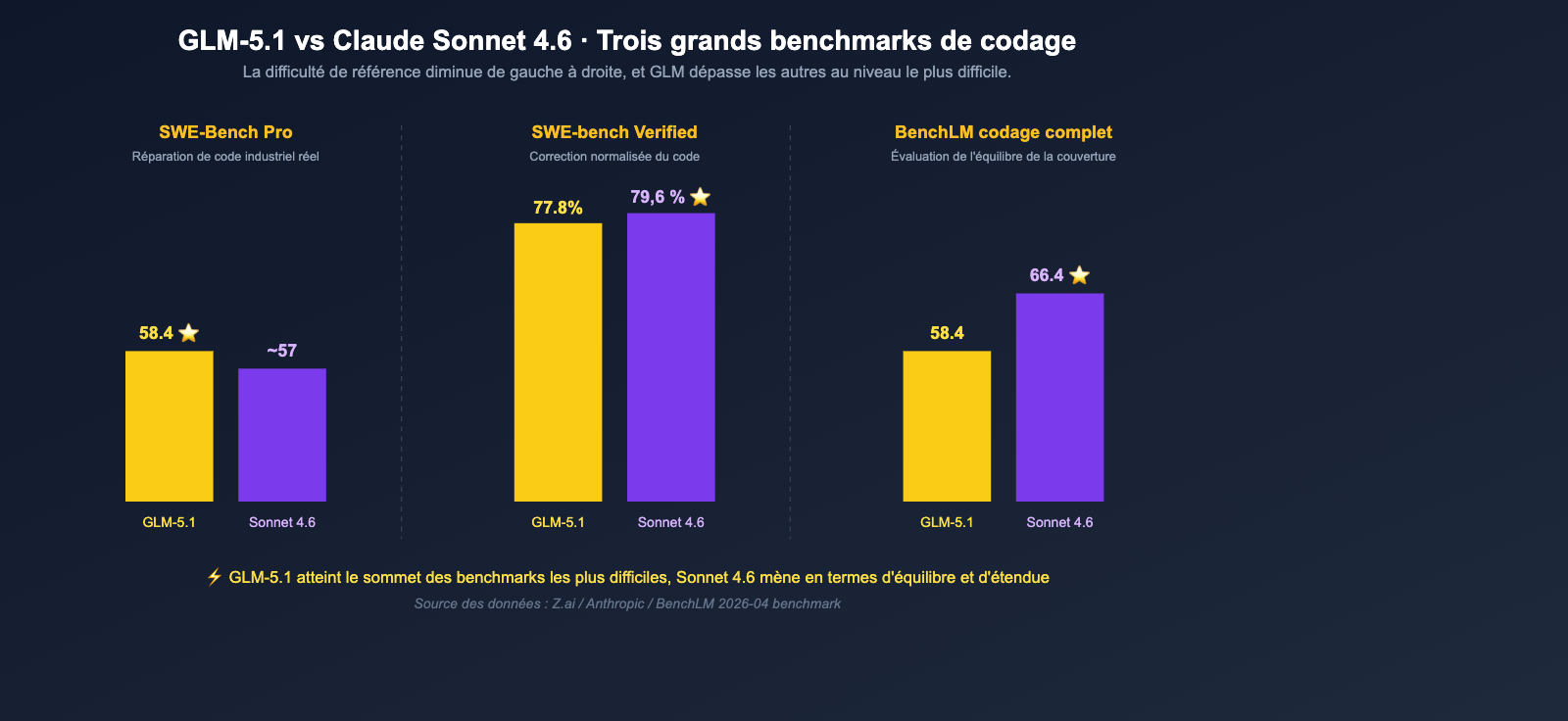
Dimension 1 : Comparaison des benchmarks de code — L'écart réel entre GLM-5.1 et Sonnet 4.6
La capacité de codage est au cœur de cette comparaison, et c'est aussi la partie la plus susceptible d'être mal interprétée par les chiffres. Nous avons regroupé tous les benchmarks pertinents dans un tableau, puis nous les analyserons du point de vue d'un ingénieur.
Comparaison complète des benchmarks liés au code
| Benchmark | GLM-5.1 | Claude Sonnet 4.6 | Leader | Écart |
|---|---|---|---|---|
| SWE-Bench Pro | 58,4 | < 57,3 | GLM-5.1 | ~1+ point |
| SWE-bench Verified | 77,8 % | 79,6 % | Sonnet 4.6 | 1,8 % |
| Moyenne de codage BenchLM | 58,4 | 66,4 | Sonnet 4.6 | 8 points |
| OSWorld (Agent de bureau) | Non public | 72,5 % | Sonnet 4.6 | — |
| Taux de préférence utilisateur Claude Code | Non testé | 70 % (vs Sonnet 4.5), 59 % (vs Opus 4.5) | Sonnet 4.6 | — |
| Tâches longue durée (8h) | ✅ Argument marketing | Supporté par Claude Code | Quasi égalité | — |
Analyse sous l'angle de l'ingénierie
Après avoir lu ce tableau, on peut en tirer quelques conclusions accessibles même aux non-spécialistes des benchmarks :
- Si votre travail consiste à "corriger de vrais bugs dans de vrais dépôts" : le GLM-5.1 est premier sur SWE-Bench Pro. C'est un benchmark très "proche du quotidien des ingénieurs", ce qui signifie que le GLM-5.1 est le plus adapté comme moteur principal pour un Agent de codage.
- Si votre travail consiste en de la "correction de code standardisée + programmation générale" : le score SWE-bench Verified du Sonnet 4.6 est légèrement supérieur, et sa moyenne globale de codage BenchLM est nettement en tête, il est donc plus stable en termes de "polyvalence".
- Si vous utilisez Claude Code / Cursor pour des tâches de longue durée : le taux de préférence utilisateur de 70 % pour le Sonnet 4.6 prouve qu'il a fait ses preuves dans les "flux de développement réels". La capacité de 8 heures du GLM-5.1 est un argument de vente majeur de Z.ai, mais vous devrez le tester vous-même pour confirmer les résultats.
- Si votre travail inclut des "problèmes à forte intensité de connaissances" (consulter la documentation, concevoir, réaliser des études techniques) : l'écart est flagrant (73,7 pour le Sonnet 4.6 contre 52,3 pour le GLM-5.1).
Pourquoi ces benchmarks semblent-ils se contredire ?
Beaucoup de lecteurs se demanderont : pourquoi, pour une même "capacité de codage", un benchmark donne l'avantage au GLM-5.1 et un autre au Sonnet 4.6 ? La réponse réside dans les différences de conception des benchmarks :
- SWE-Bench Pro privilégie la "correction de code industriel réel de haute difficulté". Le seuil de qualité des tâches est élevé, leur nombre est restreint, et il exige une capacité extrême de "raisonnement longue durée + appel d'outils" — c'est précisément le domaine de prédilection du GLM-5.1.
- SWE-bench Verified est un "ensemble de tâches de correction de code standardisées et vérifiées par des humains", plus proche de la "moyenne des scénarios de développement quotidiens". Il exige une plus grande "polyvalence + stabilité" — c'est le point fort du Sonnet 4.6.
- La moyenne de codage BenchLM calcule une moyenne pondérée de plusieurs benchmarks, ce qui favorise les flagships intermédiaires capables de gérer "tous types de tâches".
Une fois cette distinction comprise, vous ne vous laisserez plus induire en erreur par un chiffre isolé.
🎯 Conseil pour le choix de vos benchmarks : Ne tirez pas de conclusions basées sur un seul indicateur. La méthode la plus pragmatique est la suivante : compilez 5 à 10 tâches de codage réelles les plus fréquentes dans votre équipe pour créer un jeu de données interne, puis utilisez APIYI (apiyi.com) pour invoquer à la fois le GLM-5.1 et le Claude Sonnet 4.6, et vérifiez par vous-même lequel correspond le mieux à votre style de travail.
Dimension 2 : Connaissances et raisonnement — Le terrain de prédilection de Sonnet 4.6
Si l'on peut dire que les deux modèles sont au coude-à-coude sur le plan du code, l'avantage de Sonnet 4.6 est flagrant dès que l'on aborde les dimensions connaissances, raisonnement et compréhension générale.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 | Écart |
|---|---|---|---|
| Score moyen de connaissances BenchLM | 52,3 | 73,7 | 21,4 pts |
| Compréhension de documents longs | Fort | Plus fort (avec 1M de fenêtre de contexte) | |
| Rédaction en langage naturel | Excellent en chinois | Équilibré en multilingue | |
| Raisonnement sécurité et conformité | Moyen | Net avantage (point fort d'Anthropic) |
Cela signifie que Sonnet 4.6 est le choix le plus sûr pour les scénarios suivants :
- Rédaction de rapports d'études techniques, de documents de conception ou d'architectures ;
- Résumé de documents multilingues et analyse de conformité ;
- Tâches hybrides nécessitant à la fois des compétences en code et une compréhension métier ;
- Génération de contenu en contact direct avec les clients, exigeant des garde-fous de sécurité plus stricts.
La faiblesse relative de GLM-5.1 sur le plan des connaissances ne signifie pas un "manque d'entraînement", mais plutôt que ses données d'entraînement sont davantage orientées vers le codage, les mathématiques et l'utilisation d'outils, ce qui le rend moins polyvalent que Sonnet 4.6 en termes de "culture générale".
Dimension 3 : Comparaison des prix — L'atout maître de GLM-5.1
S'il ne fallait retenir qu'un seul critère, le prix est l'arme la plus redoutable de GLM-5.1 face à Sonnet 4.6.
Comparaison directe du prix des jetons (tokens)
| Dimension | GLM-5.1 (achat direct Z.ai) | Claude Sonnet 4.6 | Avantage coût GLM-5.1 |
|---|---|---|---|
| Entrée ($/M) | 1,00 $ | 3,00 $ | 3 fois moins cher |
| Sortie ($/M) | 3,20 $ | 15,00 $ | ~4,7 fois moins cher |
| Global (ratio 2:1) | ~1,73 $ | ~7,00 $ | ~4 fois moins cher |
Quelques points à noter :
- Les prix de GLM-5.1 relevés par des plateformes tierces (comme BenchLM) sont légèrement plus élevés (1,40 $ en entrée / 4,40 $ en sortie) car ils incluent une marge de revente. Le prix officiel de l'achat direct chez Z.ai est de 1,00 $ / 3,20 $ ;
- Les tarifs de 3 $ / 15 $ pour Sonnet 4.6 sont les prix officiels d'Anthropic. Ils sont déjà 5 fois moins chers qu'Opus 4.6, ce qui en fait le "roi du rapport qualité-prix" sur le marché intermédiaire ;
- Malgré cela, l'avantage de GLM-5.1 sur les jetons de sortie reste de 4 à 5 fois supérieur, ce qui est crucial pour les tâches de génération de code où le volume de sortie dépasse souvent celui de l'entrée.
Exemple de coût réel
Pour rendre cet écart plus concret, prenons une tâche typique d'un "Agent de codage quotidien" : 5 000 jetons en entrée, 20 000 jetons en sortie, pour 1 000 invocations par jour.
| Modèle | Coût entrée/jour | Coût sortie/jour | Total/jour | Total/mois |
|---|---|---|---|---|
| GLM-5.1 | 5 $ | 64 $ | 69 $ | ~2 070 $ |
| Claude Sonnet 4.6 | 15 $ | 300 $ | 315 $ | ~9 450 $ |
Écart : Le coût mensuel de Sonnet 4.6 est environ 4,5 fois supérieur à celui de GLM-5.1.
Pour une PME SaaS réalisant 1 000 invocations d'agent par jour, la différence sur la seule facture de jetons s'élève à près de 7 000 $ par mois — de quoi financer le salaire d'un demi-ingénieur supplémentaire.
🎯 Conseil d'optimisation des coûts : Pour les équipes utilisant déjà Claude Sonnet 4.6, nous recommandons de basculer 20 % du trafic vers GLM-5.1 via APIYI apiyi.com pour effectuer un test A/B. Si les résultats sont satisfaisants, migrez toute la "génération de code non critique" vers GLM-5.1 et ne gardez les invocations critiques "face au client" que sur Sonnet 4.6. Vous pourrez ainsi réduire considérablement votre facture sans sacrifier la qualité globale.
Dimension 4 : Fenêtre de contexte — La contre-attaque de Sonnet 4.6
En termes de prix, GLM-5.1 l'emporte haut la main, mais sur le plan de la fenêtre de contexte, Sonnet 4.6 reprend l'avantage.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Contexte standard | 200K (203K sur certaines plateformes) | 200K |
| Contexte Beta | — | 1M de jetons (beta) |
| Sortie maximale | 128K | Plus faible |
| Compression de contexte | Non | ✅ Compression automatique de l'ancien contexte |
1M de jetons est l'amélioration emblématique de Sonnet 4.6 : cela signifie que vous pouvez intégrer un dépôt de code complet de taille moyenne directement dans une invite sans avoir recours à la recherche RAG. Pour des tâches telles que "la refactorisation complète d'un dépôt / la localisation de bugs inter-fichiers / la compréhension globale d'une base de code", Sonnet 4.6 est presque irremplaçable en avril 2026.
Les 200K de GLM-5.1 suffisent déjà pour 90 % des scénarios quotidiens, mais il accuse un retard certain sur les cas d'usage extrêmes nécessitant un "contexte ultra-long".
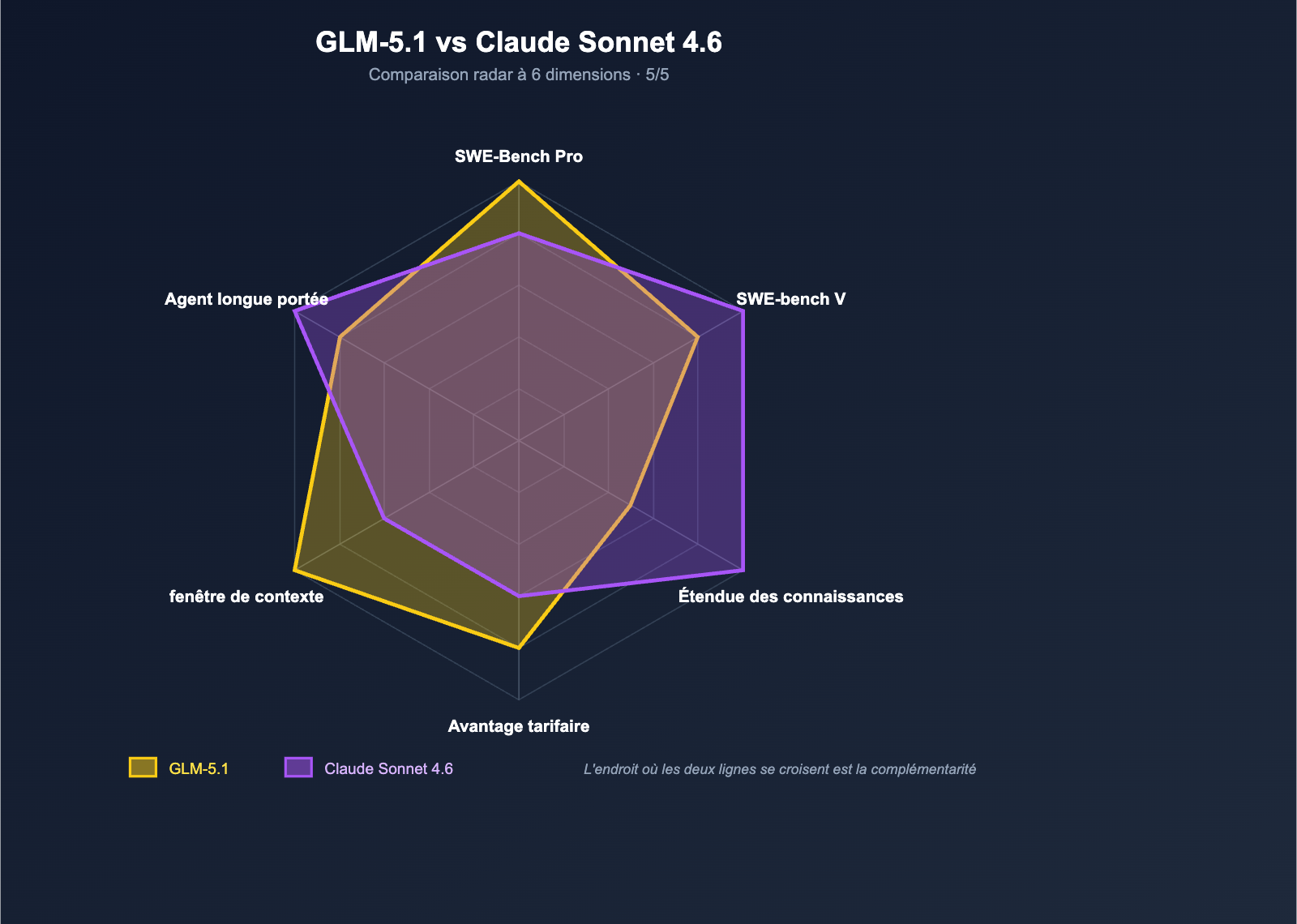
Dimension 5 : Tâches longue durée pour Agent — Le duel des deux approches
Le cinquième axe est la capacité des agents à gérer des tâches de longue durée — c'est le terrain sur lequel tous les principaux modèles de codage s'affrontent en 2026.
Deux approches différentes du "long terme"
- GLM-5.1 : Z.ai mise sur "8 heures de travail continu sur une seule tâche", en insistant sur un cycle de bout en bout de planification → exécution → test → correction → optimisation secondaire, en s'appuyant sur la profondeur de raisonnement du modèle et la stabilité de l'invocation des outils ;
- Claude Sonnet 4.6 : Anthropic mise sur "l'expérience pratique de Claude Code". 70 % des utilisateurs de Sonnet 4.5 préfèrent Sonnet 4.6 lors des tests internes, grâce au flux de travail ingénierisé de Claude Code + 1M de contexte + la compression de contexte.
En résumé :
| Approche | Avantage clé | Scénarios adaptés |
|---|---|---|
| GLM-5.1 | Profondeur de raisonnement + stabilité des outils | Agent d'automatisation en arrière-plan / Tâches sans surveillance |
| Sonnet 4.6 | Flux de travail Claude Code + 1M de contexte | Codage interactif pour développeurs / Intégration IDE |
Si vous travaillez sur des scénarios sans surveillance où "l'agent tourne en arrière-plan pour développer des fonctionnalités", la capacité de longue durée de 8 heures de GLM-5.1 est naturellement adaptée. Si vous êtes un ingénieur qui dialogue avec le modèle dans un IDE pour écrire du code, l'expérience d'intégration de Claude Code avec Sonnet 4.6 est plus mature.
Dimension 6 : Compatibilité écosystémique — L'avantage de la chaîne d'outils de Sonnet 4.6
Le dernier point est celui de l'écosystème. Sur ce terrain, Sonnet 4.6 conserve une avance notable, bien que GLM-5.1 rattrape rapidement son retard.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Compatibilité Claude Code | ✅ (Entrée compatible OpenAI) | ✅ Natif |
| Cline / Cursor | ✅ (Entrée compatible OpenAI) | ✅ Natif |
| OpenClaw | ✅ | ✅ |
| Appel d'outils Anthropic | Style OpenAI | ✅ Natif |
| Frameworks Agent tiers | Majorité compatible OpenAI | Majorité compatible Anthropic |
| Flexibilité de déploiement | ✅ MIT auto-hébergé / APIYI / Z.ai | APIYI / Anthropic officiel |
Il est intéressant de noter qu'APIYI (apiyi.com) prend en charge simultanément les trois formats natifs : OpenAI, Claude et Gemini. Cela signifie que, peu importe le style de SDK que vous utilisez pour invoquer GLM-5.1 ou Sonnet 4.6, tout peut être centralisé sous une seule et même clé API. C'est un détail extrêmement pratique lors de vos tests comparatifs : vous n'avez pas besoin de gérer deux systèmes d'authentification, deux outils de monitoring ou deux facturations distinctes.
Recommandations de sélection par scénario
En combinant ces 6 dimensions, nous pouvons vous proposer des recommandations très concrètes pour choisir votre modèle en fonction de vos besoins métier.
Tableau de correspondance par scénario
| Scénario métier | Modèle recommandé | Raison clé |
|---|---|---|
| Correction de code industriel (Agent PR auto) | GLM-5.1 | N°1 mondial sur SWE-Bench Pro + fenêtre de 8h |
| Codage quotidien IDE (Cursor / Cline) | Claude Sonnet 4.6 | 70 % de préférence utilisateur, workflow mature |
| Refactorisation complète / Débogage multi-fichiers | Claude Sonnet 4.6 | Contexte de 1M (beta) comme atout majeur |
| Génération de code standard + fort débit | GLM-5.1 | 4 fois moins cher, idéal pour la production |
| Veille technologique / Architecture | Claude Sonnet 4.6 | Score de connaissances 73,7 vs 52,3 |
| Raisonnement mathématique / Compétition | GLM-5.1 | AIME 2026 95,3 + GPQA-Diamond 86,2 |
| Module de génération de code SaaS | Sonnet 4.6 (Principal) + GLM-5.1 (Backup) | Sonnet en priorité, GLM en secours pour optimiser les coûts |
| Déploiement privé / Conformité réseau interne | GLM-5.1 | Licence MIT + auto-hébergement possible |
| Interaction de codage en chinois | GLM-5.1 | Modèle local plus adapté aux invites en chinois |
| Raisonnement complexe + appels d'outils longs | Égalité, à tester | Les deux fonctionnent, écart inférieur à 5 % |
Stratégie hybride recommandée
Pour la grande majorité des équipes de taille moyenne, nous recommandons une stratégie « Principal/Backup » plutôt qu'un choix exclusif :
- Modèle principal : Choisissez-en un selon votre scénario métier dominant (GLM-5.1 pour la correction, Sonnet 4.6 pour l'IDE).
- Modèle de secours : Configurez le second pour effectuer des tests A/B et des basculements progressifs sur vos processus critiques.
- Couche d'accès unifiée : Utilisez APIYI (apiyi.com) avec une seule clé API pour appeler les deux. Votre code métier n'a qu'à modifier le champ
model, sans changer la logique d'authentification. - Monitoring des coûts : Séparez les factures des deux modèles dans le tableau de bord APIYI pour évaluer régulièrement le rapport coût-efficacité et ajuster la répartition du trafic.
🎯 Conseil pour la mise en œuvre : Sur APIYI (apiyi.com), vous pouvez basculer de manière transparente entre GLM-5.1 et Claude Sonnet 4.6 avec la même clé API. Nous suggérons d'orienter 70 % du trafic de « génération de code non critique » vers GLM-5.1, et de réserver 30 % pour les tâches « orientées client + raisonnement complexe » sur Sonnet 4.6. Vous profiterez ainsi de l'avantage tarifaire de GLM-5.1 tout en garantissant la stabilité sur vos scénarios clés.
FAQ : GLM-5.1 vs Claude Sonnet 4.6
Q1 : GLM-5.1 a-t-il vraiment surpassé Claude Sonnet 4.6 en matière de codage ?
En partie oui, mais il reste à la traîne sur certains points. Sur le benchmark SWE-Bench Pro (réparation de code industriel réel), qui est l'un des plus exigeants, le GLM-5.1 a atteint un score de 58,4, se classant premier mondial. Il dépasse ainsi le Claude Opus 4.6 (57,3) et le GPT-5.4 (57,7), et par extension le Sonnet 4.6. Cependant, sur le SWE-bench Verified (réparation de code standardisée), le Sonnet 4.6 reste en tête avec 79,6 % contre 77,8 % pour le GLM-5.1, soit une avance d'environ 1,8 point. De même, sur le score global de codage BenchLM, le Sonnet 4.6 affiche 66,4 points, devançant le GLM-5.1 de 8 points. Conclusion : le GLM-5.1 surpasse le Sonnet 4.6 sur les tâches les plus complexes, mais reste derrière en termes de polyvalence.
Q2 : De combien le GLM-5.1 est-il moins cher que le Claude Sonnet 4.6 ?
Selon les tarifs officiels de Z.ai, le GLM-5.1 est facturé 1,00 $ en entrée / 3,20 $ en sortie, tandis que le Claude Sonnet 4.6 est à 3,00 $ / 15,00 $. L'entrée est 3 fois moins chère et la sortie environ 4,7 fois moins chère. Dans un scénario typique de "1 000 invocations de modèle par jour pour un agent de codage avec 5K en entrée / 20K en sortie", la facture mensuelle du Sonnet 4.6 est environ 4,5 fois plus élevée que celle du GLM-5.1. Si votre activité génère un volume de sortie nettement supérieur au volume d'entrée, le rapport coût-efficacité du GLM-5.1 sera encore plus avantageux.
Q3 : Lequel du GLM-5.1 ou du Sonnet 4.6 possède la plus grande fenêtre de contexte ?
Le Claude Sonnet 4.6 l'emporte. Le GLM-5.1 propose 200K (certaines plateformes indiquent 203K), tandis que le Sonnet 4.6 monte jusqu'à 1M de tokens (en version bêta). Une fenêtre de 1M signifie que le Sonnet 4.6 peut analyser l'intégralité d'un dépôt de code de taille moyenne en une seule fois, ce qui constitue son arme maîtresse pour la refactorisation complète de dépôts ou la localisation de bugs entre plusieurs fichiers. Si vos tâches nécessitent impérativement un contexte ultra-long, le Sonnet 4.6 est le choix le plus sûr.
Q4 : J'utilise actuellement Claude Sonnet 4.6 avec Cursor / Cline, est-ce que ça vaut le coup de passer au GLM-5.1 ?
Tout dépend de vos priorités. Si votre préoccupation principale est la facture, le GLM-5.1 peut réduire vos coûts de moitié, voire plus, et mérite le détour. Si vous privilégiez la stabilité de votre expérience de codage quotidienne, le taux de préférence de 70 % des utilisateurs pour le Sonnet 4.6 prouve qu'il a fait ses preuves dans les flux de travail Claude Code ; le gain lié à la migration pourrait être inférieur aux risques. La méthode la plus prudente consiste à utiliser APIYI (apiyi.com) pour basculer 20 % de votre trafic vers le GLM-5.1 pour un test A/B, et de décider après une semaine si vous souhaitez augmenter cette proportion.
Q5 : Le GLM-5.1 et le Sonnet 4.6 sont-ils tous deux disponibles sur APIYI ?
Oui, les deux sont déjà en ligne. APIYI (apiyi.com) prend en charge simultanément les formats natifs OpenAI, Claude et Gemini. Il vous suffit de modifier le base_url du SDK OpenAI en https://api.apiyi.com/v1 et de basculer le paramètre model entre glm-5.1 et claude-sonnet-4-6 (ou un identifiant similaire). Vous pouvez ainsi faire tourner les deux modèles dans le même code, ce qui rend l'efficacité des comparaisons horizontales très élevée.
Q6 : En tant que développeur indépendant, lequel choisir ?
Si vous ne devez en choisir qu'un, analysez votre flux de travail : pour des agents de codage, de l'automatisation backend ou de la génération de code en masse, choisissez le GLM-5.1. Pour de la programmation interactive dans un IDE, de la refactorisation de dépôts ou de la génération de contenu orienté client, choisissez le Sonnet 4.6. Si vous ne voulez pas faire de choix difficile, les utiliser tous les deux via la gestion unifiée d'APIYI est la meilleure pratique pour un développeur en 2026 : votre facture s'optimise automatiquement en fonction du modèle sélectionné, sans dépendre d'un seul fournisseur.
Résumé : Verdict final sur le GLM-5.1 vs Claude Sonnet 4.6
En combinant ces 6 dimensions, le verdict final sur le GLM-5.1 vs Claude Sonnet 4.6 peut se résumer ainsi : le GLM-5.1 possède un avantage structurel sur la réparation de code industriel complexe, le prix, l'open source local et les agents à long terme. Le Claude Sonnet 4.6 reste en tête sur la polyvalence, la profondeur des connaissances, la fenêtre de contexte de 1M et la maturité des flux de travail IDE. Il ne s'agit pas de savoir qui remplace qui, mais de voir ces outils comme complémentaires pour différents cas d'usage.
Pour les équipes de développement en Chine continentale fin 2026, la stratégie la plus intelligente n'est pas l'exclusion, mais le "mixte principal/secondaire + couche d'accès unifiée" : utilisez le GLM-5.1 pour les tâches sensibles aux coûts, l'automatisation longue durée et la conformité privée, et le Sonnet 4.6 pour les besoins orientés utilisateur, les contextes complexes et la rédaction technique. En utilisant un service proxy API comme APIYI pour centraliser les deux sous une même clé API, et en ajustant dynamiquement le trafic selon les données réelles de facturation, vous pouvez réduire considérablement vos factures mensuelles sans sacrifier la qualité.
🎯 Conseil final : Le GLM-5.1 et le Claude Sonnet 4.6 sont disponibles sur APIYI (apiyi.com). Nous vous recommandons de créer une clé API sur apiyi.com dès aujourd'hui, de modifier le
base_urlde votre SDK OpenAI enhttps://api.apiyi.com/v1, et de lancer 5 tâches avec le GLM-5.1, puis les mêmes avec le Sonnet 4.6 en utilisant la même invite. Aucune évaluation ne remplace votre propre test, et ces 30 minutes de vérification vous donneront une réelle maîtrise des deux modèles de codage les plus puissants de 2026.
Auteur : APIYI Team | Spécialistes de l'implémentation des grands modèles de langage et de l'évaluation des outils de codage. Pour plus de comparaisons de modèles et d'invocations pratiques, visitez APIYI (apiyi.com).