Pada April 2026, dua model pemrograman yang paling banyak dibicarakan di komunitas pengembang Tiongkok adalah GLM-5.1 dan Claude Sonnet 4.6. Model pertama baru saja dirilis secara open-source dengan lisensi MIT oleh Z.ai (sebelumnya Zhipu), mencetak skor 58,4 pada SWE-Bench Pro, melampaui Claude Opus 4.6, GPT-5.4, dan Gemini 3.1 Pro, sekaligus menempati peringkat pertama di papan peringkat pemrograman open-source global. Sementara itu, model kedua disebut oleh Anthropic sebagai "level unggulan di kelas menengah", dengan skor 79,6% pada SWE-bench Verified, mendekati skor 80,8% milik Opus 4.6, namun dengan harga hanya sebagian kecil dari Opus, serta untuk pertama kalinya membuka jendela konteks 1M token untuk seri Sonnet.
Pertanyaannya adalah—GLM-5.1 vs Claude Sonnet 4.6, mana yang sebenarnya lebih kuat dalam skenario pemrograman nyata? Ini bukan pertanyaan yang bisa dijawab dengan satu kalimat. Keunggulan keduanya tersebar sangat berbeda: GLM-5.1 telah melampaui Sonnet 4.6 pada tolok ukur "perbaikan kode kelas industri", namun dalam evaluasi komprehensif pihak ketiga, Sonnet berhasil menarik kembali skor rata-rata keseluruhannya. Artikel ini akan membedah perbedaan nyata keduanya melalui 6 dimensi (tolok ukur kode, pengetahuan, harga, jendela konteks, tugas jangka panjang Agent, dan kompatibilitas ekosistem), serta memberikan saran pemilihan yang jelas berdasarkan skenario bisnis.

Sekilas Data Utama GLM-5.1 vs Claude Sonnet 4.6
Sebelum kita melakukan perbandingan, mari kita letakkan fakta kunci keduanya secara berdampingan dalam sebuah tabel. Semua data berasal dari informasi publik BenchLM, Z.ai, Anthropic, dan platform evaluasi pihak ketiga.
| Dimensi | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Vendor | Z.ai (sebelumnya Zhipu AI) | Anthropic |
| Tanggal Rilis | 07-04-2026 (Open-source) | Awal 2026 |
| Arsitektur | 754B MoE / 40B aktif | Tidak diungkap (level Sonnet menengah) |
| Lisensi Open-source | ✅ MIT | ❌ Closed-source |
| Jendela konteks | 200K (beberapa platform menampilkan 203K) | 200K → 1M (beta) |
| SWE-bench Verified | 77,8% | 79,6% |
| SWE-Bench Pro | 58,4 ⭐ (Open-source #1, melampaui Opus 4.6) | Sedikit di bawah Opus 4.6 |
| Rata-rata Pemrograman BenchLM | 58,4 | 66,4 |
| Rata-rata Pengetahuan BenchLM | 52,3 | 73,7 |
| Skor Total BenchLM | 79 | 80 |
| Harga Input ($/M) | $1,00 (Langsung dari Z.ai) | $3,00 |
| Harga Output ($/M) | $3,20 (Langsung dari Z.ai) | $15,00 |
| Tugas Jangka Panjang Agent | Sekitar 8 jam per tugas | 70% tingkat preferensi pengguna Claude Code |
| Akses APIYI | ✅ Sudah tersedia https://api.apiyi.com/v1 |
✅ Sudah tersedia |
| Alat Kompatibel | Claude Code / Cline / Cursor / OpenClaw | Sama seperti di samping + ekosistem asli Anthropic |
🎯 Saran Penilaian Cepat: Perbedaan keduanya bukan tentang "siapa yang lebih kuat atau lemah", melainkan "di skenario mana mereka lebih unggul". Jika Anda ingin segera melakukan perbandingan horizontal, APIYI apiyi.com telah meluncurkan GLM-5.1 dan Claude Sonnet 4.6 secara bersamaan. Anda hanya perlu mengubah kolom
modeluntuk beralih di antara keduanya dalam kode bisnis yang sama, dan dalam 15 menit Anda bisa mendapatkan penilaian yang lebih akurat untuk tugas nyata Anda daripada evaluasi mana pun.
Perbedaan Inti GLM-5.1 vs Claude Sonnet 4.6: Bukan Model di Kelas yang Sama
Fakta pertama yang harus diperjelas adalah—GLM-5.1 dan Claude Sonnet 4.6 secara teknis bukanlah model di "kelas yang sama", karena keduanya memiliki perbedaan sistematis dalam tujuan desainnya.
Perbedaan Posisi Model
| Dimensi | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Posisi Vendor | "Open Source Mutakhir + Pengodean Agen Jangka Panjang" | "Flagship Menengah · Raja Value-for-Money" |
| Skala Parameter | Model Bahasa Besar (754B MoE) | Model Menengah (parameter tidak diungkap) |
| Target Pelatihan | Pengodean + Agen + Penalaran Matematika | Umum + Pengodean + Pengetahuan + Keamanan |
| Model Bisnis | Open Source MIT + API mandiri Z.ai | Berlangganan Tertutup + API |
| Pesaing Utama | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Perhatikan baris ini—dalam posisi internal Z.ai, GLM-5.1 sebenarnya ditargetkan untuk menyaingi Claude Opus 4.6, bukan Sonnet 4.6. Ini berarti jika Anda hanya membandingkan "batas atas kemampuan pengodean", pembanding yang tepat untuk GLM-5.1 adalah Opus, bukan Sonnet. Namun, dalam hal "harga + kemampuan komprehensif + kegunaan", Sonnet 4.6 adalah lawan yang sangat kuat di pasar kelas menengah, sehingga membandingkan keduanya tetap memiliki nilai teknis yang sangat praktis.
Status Saat Ini pada Evaluasi Komprehensif Pihak Ketiga
Berdasarkan papan peringkat sementara yang dirilis BenchLM pada April 2026:
- Skor Total: Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (selisih 1 poin, hampir setara)
- Rata-rata Pengodean: Claude Sonnet 4.6 = 66.4, GLM-5.1 = 58.4 (Sonnet 4.6 unggul 8 poin)
- Rata-rata Pengetahuan: Claude Sonnet 4.6 = 73.7, GLM-5.1 = 52.3 (Sonnet 4.6 unggul 21.4 poin, selisih terbesar)
Namun, pada tolok ukur khusus lainnya, situasinya berbalik total:
- SWE-Bench Pro (perbaikan kode industri nyata): GLM-5.1 = 58.4 ⭐, melampaui Claude Opus 4.6 dengan 57.3 dan GPT-5.4 dengan 57.7, Sonnet 4.6 tentu saja berada di bawahnya.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%, hanya selisih 1.8 poin persentase.
Melihat angka-angka ini secara berdampingan, kita bisa menarik kesimpulan pertama: GLM-5.1 bukanlah monster yang "sepenuhnya melampaui Sonnet 4.6", tetapi ia memang meraih posisi pertama dalam "perbaikan kode industri tersulit", sementara Sonnet 4.6 tetap mempertahankan keunggulan yang seimbang dalam evaluasi pengodean komprehensif yang lebih luas.
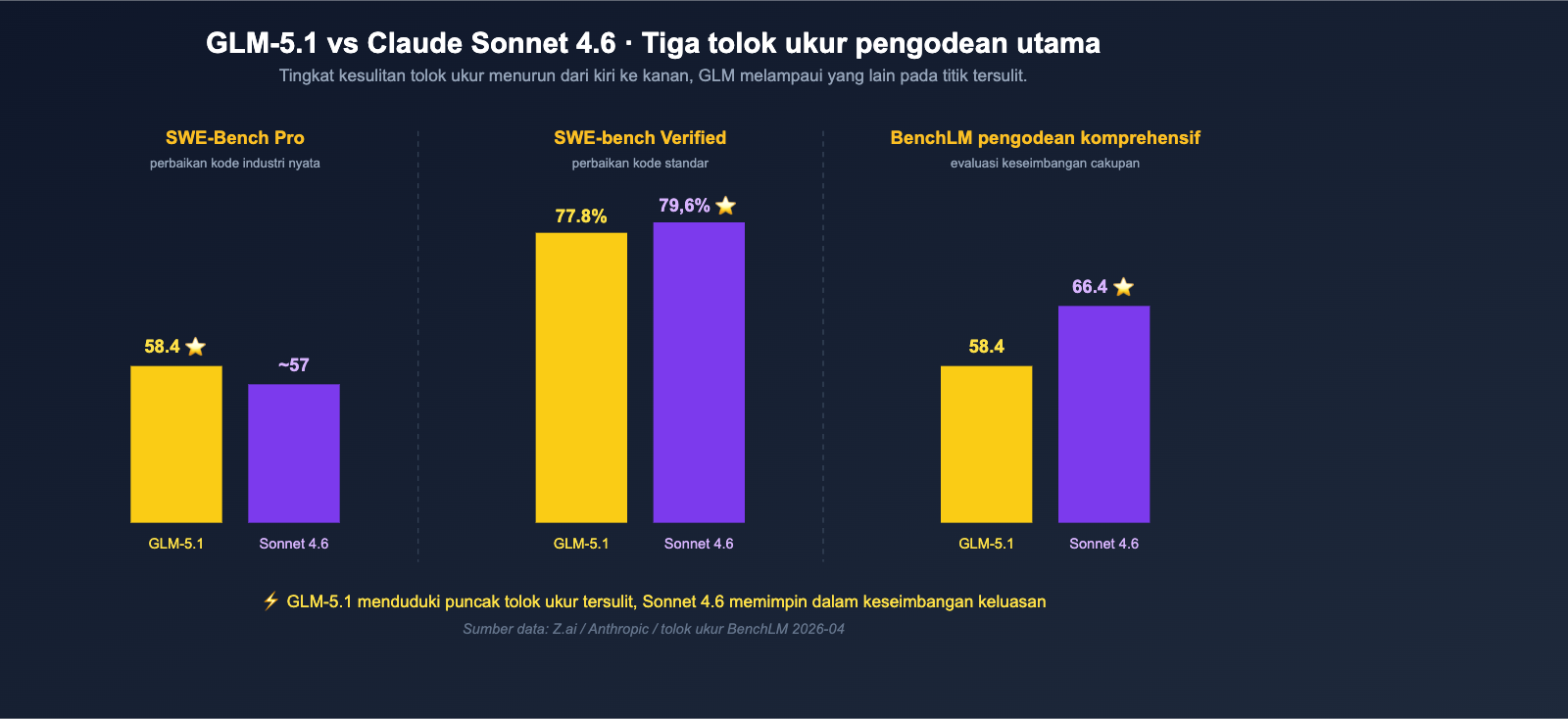
Dimensi 1: Perbandingan Tolok Ukur Kode — Kesenjangan Nyata antara GLM-5.1 dan Sonnet 4.6
Kemampuan pengodean adalah inti dari perbandingan ini, dan juga bagian yang paling mudah disalahartikan oleh angka-angka tolok ukur. Kami telah mengintegrasikan semua tolok ukur terkait ke dalam satu tabel, lalu memberikan interpretasi dari sudut pandang insinyur.
Perbandingan Lengkap Tolok Ukur Terkait Kode
| Tolok Ukur | GLM-5.1 | Claude Sonnet 4.6 | Pihak Unggul | Selisih |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ poin |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| Rata-rata Pengodean BenchLM | 58.4 | 66.4 | Sonnet 4.6 | 8 poin |
| OSWorld (Desktop Agen) | Tidak diungkap | 72.5% | Sonnet 4.6 | — |
| Tingkat Preferensi Pengguna Claude Code | Tidak berpartisipasi | 70% (vs Sonnet 4.5), 59% (vs Opus 4.5) | Sonnet 4.6 | — |
| Tugas Jangka Panjang 8 Jam | ✅ Fokus utama resmi | Sudah mendukung Claude Code | Hampir setara | — |
Interpretasi Sudut Pandang Teknik
Setelah membaca tabel ini tiga kali, Anda bisa menarik beberapa kesimpulan yang dapat dipahami bahkan oleh mereka yang bukan penggemar tolok ukur industri:
- Jika pekerjaan Anda adalah "memperbaiki bug nyata di repositori nyata": GLM-5.1 menempati peringkat pertama di SWE-Bench Pro, tolok ukur yang sangat "dekat dengan keseharian insinyur lapangan", ini berarti GLM-5.1 paling cocok sebagai mesin inti Coding Agent;
- Jika pekerjaan Anda adalah "perbaikan kode standar + pemrograman umum": SWE-bench Verified untuk Sonnet 4.6 sedikit lebih tinggi, dan rata-rata pengodean komprehensif BenchLM jelas lebih unggul, ia lebih stabil dalam hal "cakupan";
- Jika pekerjaan Anda melibatkan tugas jangka panjang di Claude Code / Cursor: Tingkat preferensi pengguna 70% untuk Sonnet 4.6 menunjukkan bahwa model ini telah teruji dalam "alur pengembangan nyata"; kemampuan jangka panjang 8 jam GLM-5.1 adalah nilai jual utama Z.ai, namun Anda perlu mencobanya sendiri untuk memastikan hasilnya;
- Jika pekerjaan Anda mencakup "masalah berbasis pengetahuan" (mencari dokumentasi, menulis desain, melakukan riset teknis): 73.7 untuk Sonnet 4.6 vs 52.3 untuk GLM-5.1, selisihnya sangat terlihat.
Mengapa Terjadi Situasi "Saling Bertabrakan" pada Tolok Ukur?
Banyak pembaca bertanya: mengapa jika sama-sama "kemampuan pengodean", satu tolok ukur mengatakan GLM-5.1 lebih kuat, sementara yang lain mengatakan Sonnet 4.6 lebih kuat? Jawabannya terletak pada perbedaan desain tolok ukur:
- SWE-Bench Pro condong ke "perbaikan kode industri nyata dengan tingkat kesulitan sangat tinggi", ambang batas kualitas tugas tinggi, jumlah sedikit, menuntut kemampuan 'penalaran jangka panjang + pemanggilan alat' yang ekstrem dari model—inilah arah utama GLM-5.1;
- SWE-bench Verified adalah "kumpulan tugas perbaikan kode standar yang telah diverifikasi manusia", lebih mendekati "tingkat rata-rata skenario pengembangan sehari-hari", menuntut 'cakupan + stabilitas' yang lebih tinggi dari model—ini adalah keunggulan Sonnet 4.6;
- Rata-rata Pengodean BenchLM melakukan pembobotan rata-rata dari berbagai tolok ukur, lebih ramah bagi model flagship menengah yang 'dapat menangani berbagai jenis tugas'.
Setelah memahami perbedaan ini, Anda tidak akan lagi disesatkan oleh angka tunggal mana pun.
🎯 Saran Pemilihan Tolok Ukur: Jangan mengambil kesimpulan hanya dengan melihat satu tolok ukur. Cara yang paling pragmatis adalah: susun 5-10 tugas pengodean nyata yang paling sering dihadapi tim Anda menjadi satu set tolok ukur internal, lalu gunakan layanan proksi API APIYI (apiyi.com) untuk memanggil GLM-5.1 dan Claude Sonnet 4.6 secara bersamaan, dan verifikasi secara terbalik dengan data Anda sendiri mana yang lebih cocok dengan gaya bisnis Anda.
Dimensi 2: Pengetahuan & Penalaran — Area Keunggulan Mutlak Sonnet 4.6
Jika pada level pengodean hasilnya "saling mengungguli", maka pada dimensi Pengetahuan / Penalaran / Pemahaman Umum, Sonnet 4.6 memiliki keunggulan yang sangat jelas.
| Dimensi | GLM-5.1 | Claude Sonnet 4.6 | Selisih |
|---|---|---|---|
| Rata-rata Pengetahuan BenchLM | 52,3 | 73,7 | 21,4 poin |
| Pemahaman dokumen panjang | Kuat | Lebih Kuat (dengan jendela konteks 1M) | |
| Penulisan bahasa alami | Bahasa Mandarin unggul | Seimbang di berbagai bahasa | |
| Penalaran keamanan & kepatuhan | Menengah | Jauh lebih kuat (Kekuatan Anthropic) |
Ini berarti untuk skenario berikut, Sonnet 4.6 adalah pilihan yang lebih aman:
- Menulis laporan riset teknis / dokumen desain / proposal arsitektur;
- Ringkasan dokumen lintas bahasa, analisis kepatuhan;
- Tugas campuran yang membutuhkan pemahaman "kode sekaligus bisnis";
- Pembuatan konten yang berhadapan langsung dengan klien, yang menuntut pagar pengaman (safety guardrails) yang lebih ketat.
Kelemahan relatif GLM-5.1 dalam dimensi pengetahuan bukanlah karena "pelatihan yang kurang", melainkan karena data pelatihannya lebih condong ke arah Coding + Matematika + penggunaan alat, sehingga dalam hal "pengetahuan umum" tidak seimbang seperti Sonnet 4.6.
Dimensi 3: Perbandingan Harga — Kartu As GLM-5.1
Jika hanya melihat satu poin, harga adalah senjata paling tajam GLM-5.1 saat dibandingkan dengan Sonnet 4.6.
Perbandingan Langsung Harga Token
| Dimensi | GLM-5.1 (Pembelian langsung Z.ai) | Claude Sonnet 4.6 | Keunggulan Efisiensi Biaya GLM-5.1 |
|---|---|---|---|
| Input ($/M) | $1,00 | $3,00 | Lebih murah 3 kali |
| Output ($/M) | $3,20 | $15,00 | Lebih murah ~4,7 kali |
| Gabungan (rasio 2:1) | ~$1,73 | ~$7,00 | Lebih murah ~4 kali |
Beberapa hal yang perlu diperhatikan:
- Harga GLM-5.1 yang tercatat di platform pihak ketiga (seperti BenchLM) sedikit lebih tinggi ($1,40 input / $4,40 output) karena mencakup margin pengecer, harga pembelian langsung resmi dari Z.ai adalah $1,00 / $3,20;
- Harga $3 / $15 untuk Sonnet 4.6 adalah harga resmi Anthropic, yang sudah 5 kali lebih murah daripada Opus 4.6, dan sudah dianggap sebagai "raja efisiensi biaya" di pasar kelas menengah;
- Meskipun demikian, keunggulan GLM-5.1 pada token output masih berada di kisaran 4-5 kali lipat, yang sangat signifikan untuk skenario pembuatan kode di mana "volume output lebih besar daripada volume input".
Contoh Biaya Nyata
Agar perbedaannya lebih terlihat, mari kita asumsikan tugas tipikal "Coding Agent harian": input 5K token, output 20K token, dengan 1000 pemanggilan per hari.
| Model | Biaya Input/hari | Biaya Output/hari | Total/hari | Total/bulan |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2.070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9.450 |
Selisihnya: Biaya bulanan Sonnet 4.6 sekitar 4,5 kali lipat dari GLM-5.1.
Bagi perusahaan SaaS menengah dengan "1000 pemanggilan agen per hari", penghematan biaya token saja bisa mencapai hampir 7000 dolar AS per bulan—jumlah yang cukup untuk menggaji setengah insinyur tambahan.
🎯 Saran Optimalisasi Biaya: Bagi tim yang sudah menggunakan Claude Sonnet 4.6, kami sarankan untuk mencoba mengalihkan 20% lalu lintas ke GLM-5.1 di APIYI apiyi.com untuk melakukan A/B testing. Jika hasilnya dapat diterima, pindahkan semua "pembuatan kode untuk bisnis non-kritis" ke GLM-5.1, dan hanya simpan pemanggilan kritis yang "berhadapan langsung dengan klien" di Sonnet 4.6—dengan cara ini, Anda bisa memangkas tagihan secara signifikan tanpa mengorbankan kualitas secara keseluruhan.
Dimensi Empat: Jendela Konteks — Serangan Balik Sonnet 4.6
Dari segi harga, GLM-5.1 memang menang telak, namun untuk urusan jendela konteks, Sonnet 4.6 justru mengambil alih kendali.
| Dimensi | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Konteks Standar | 200K (203K di beberapa platform) | 200K |
| Konteks Beta | — | 1M token (beta) |
| Output Maksimum | 128K | Lebih rendah |
| Kompresi Konteks | Tidak | ✅ Kompresi otomatis untuk konteks lama |
1M token adalah peningkatan ikonik dari Sonnet 4.6—ini artinya Anda bisa memasukkan seluruh repositori kode berukuran menengah ke dalam petunjuk sekaligus tanpa perlu pencarian RAG. Untuk tugas seperti "refaktorisasi seluruh repositori / pelacakan bug lintas file / pemahaman basis kode secara utuh", Sonnet 4.6 hampir tak tergantikan pada April 2026.
Konteks 200K milik GLM-5.1 memang sudah cukup untuk 90% skenario harian, namun untuk skenario ekstrem dengan "konteks super panjang", ia memang tertinggal satu langkah.
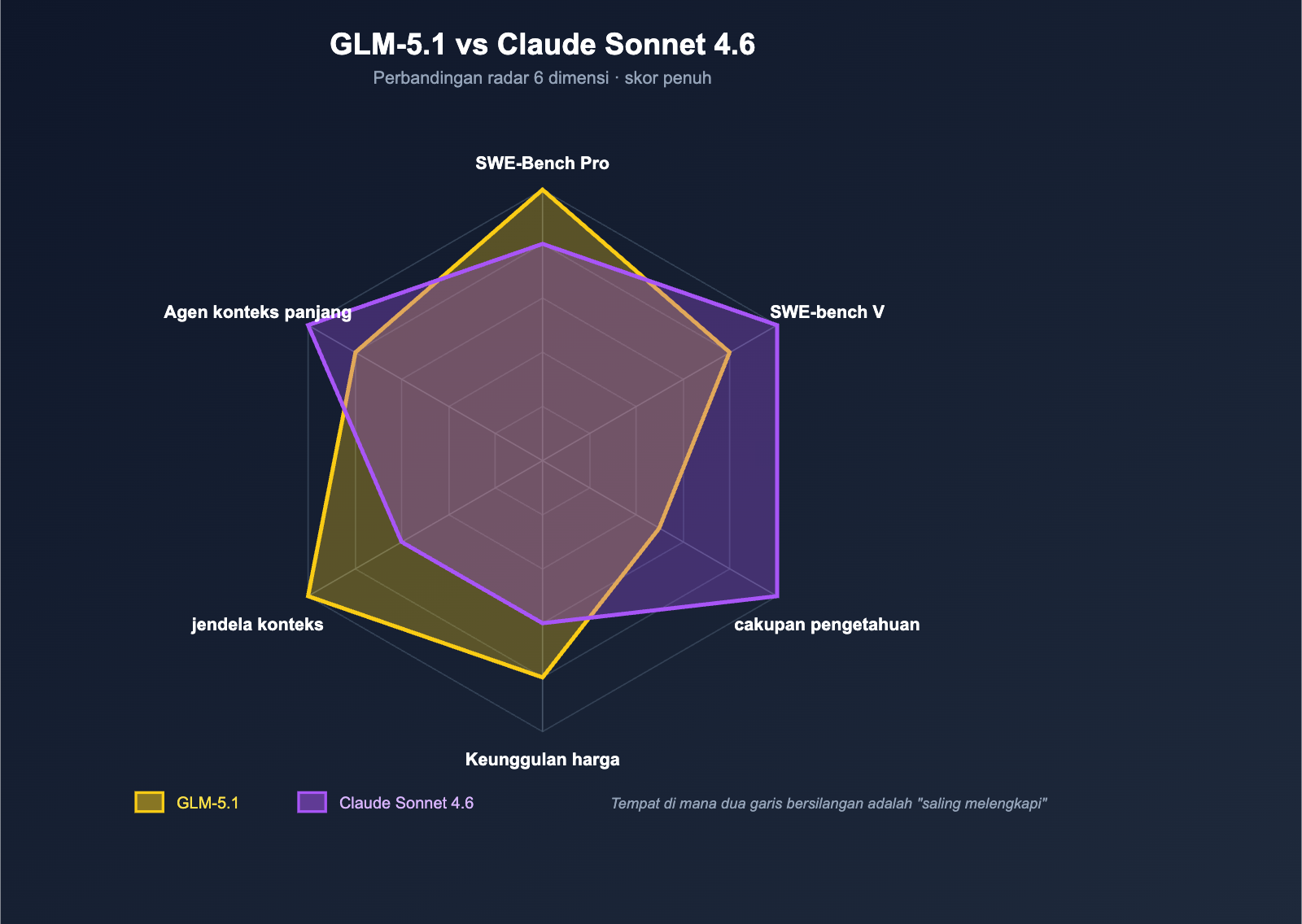
Dimensi Lima: Tugas Jangka Panjang Agent — Duel Dua Pendekatan
Dimensi kelima adalah kemampuan tugas jangka panjang Agent—ini adalah arah yang sedang diperebutkan oleh semua model pengodean papan atas pada tahun 2026.
Rute "Jangka Panjang" Keduanya Berbeda
- GLM-5.1: Z.ai mengunggulkan "pekerjaan berkelanjutan 8 jam per tugas", menekankan siklus perencanaan → eksekusi → pengujian → perbaikan → optimasi sekunder secara end-to-end, mengandalkan kedalaman penalaran model itu sendiri dan stabilitas pemanggilan alat;
- Claude Sonnet 4.6: Anthropic mengunggulkan "pengalaman praktis Claude Code", 70% pengguna Sonnet 4.5 dalam pengujian internal lebih memilih Sonnet 4.6, mengandalkan alur kerja Claude Code yang ter-rekayasa + konteks 1M + kompresi konteks.
Bisa dipahami sebagai berikut:
| Rute | Keunggulan Utama | Skenario yang Cocok |
|---|---|---|
| GLM-5.1 | Kedalaman penalaran model + stabilitas pemanggilan alat | Agent otomatisasi latar belakang / tugas tanpa pengawasan |
| Sonnet 4.6 | Alur kerja Claude Code + konteks 1M | Pengodean interaktif pengembang / integrasi IDE |
Jika Anda mengerjakan skenario tanpa pengawasan seperti "Agent berjalan di latar belakang untuk mengembangkan fitur sendiri", kemampuan jangka panjang 8 jam GLM-5.1 sangat cocok; jika Anda adalah "insinyur yang berdialog dengan model di IDE untuk menulis kode", pengalaman integrasi Claude Code pada Sonnet 4.6 jauh lebih matang.
Dimensi Keenam: Kompatibilitas Ekosistem — Keunggulan Rantai Alat Sonnet 4.6
Dimensi terakhir adalah ekosistem. Dalam poin ini, Sonnet 4.6 masih memegang keunggulan yang jelas, namun GLM-5.1 sudah mengejar dengan sangat cepat.
| Dimensi | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Kompatibilitas Claude Code | ✅(Gerbang kompatibilitas OpenAI) | ✅ Native |
| Cline / Cursor | ✅(Gerbang kompatibilitas OpenAI) | ✅ Native |
| OpenClaw | ✅ | ✅ |
| Pemanggilan Alat Anthropic | Gaya OpenAI | ✅ Native |
| Kerangka Kerja Agen Pihak Ketiga | Sebagian besar mendukung kompatibilitas OpenAI | Sebagian besar mendukung Native Anthropic |
| Fleksibilitas Deployment | ✅ MIT Self-hosted / APIYI / Z.ai | APIYI / Resmi Anthropic |
Perlu dicatat bahwa APIYI apiyi.com mendukung tiga format native sekaligus: OpenAI / Claude Native / Gemini Native. Artinya, tidak peduli gaya SDK apa yang ingin Anda gunakan untuk memanggil GLM-5.1 dan Sonnet 4.6, semuanya bisa diselesaikan di bawah satu kunci API yang sama. Ini adalah detail yang sangat praktis dalam pengujian perbandingan keduanya—Anda tidak perlu mengelola dua set autentikasi, dua set pemantauan, dan dua set tagihan selama masa pengujian.
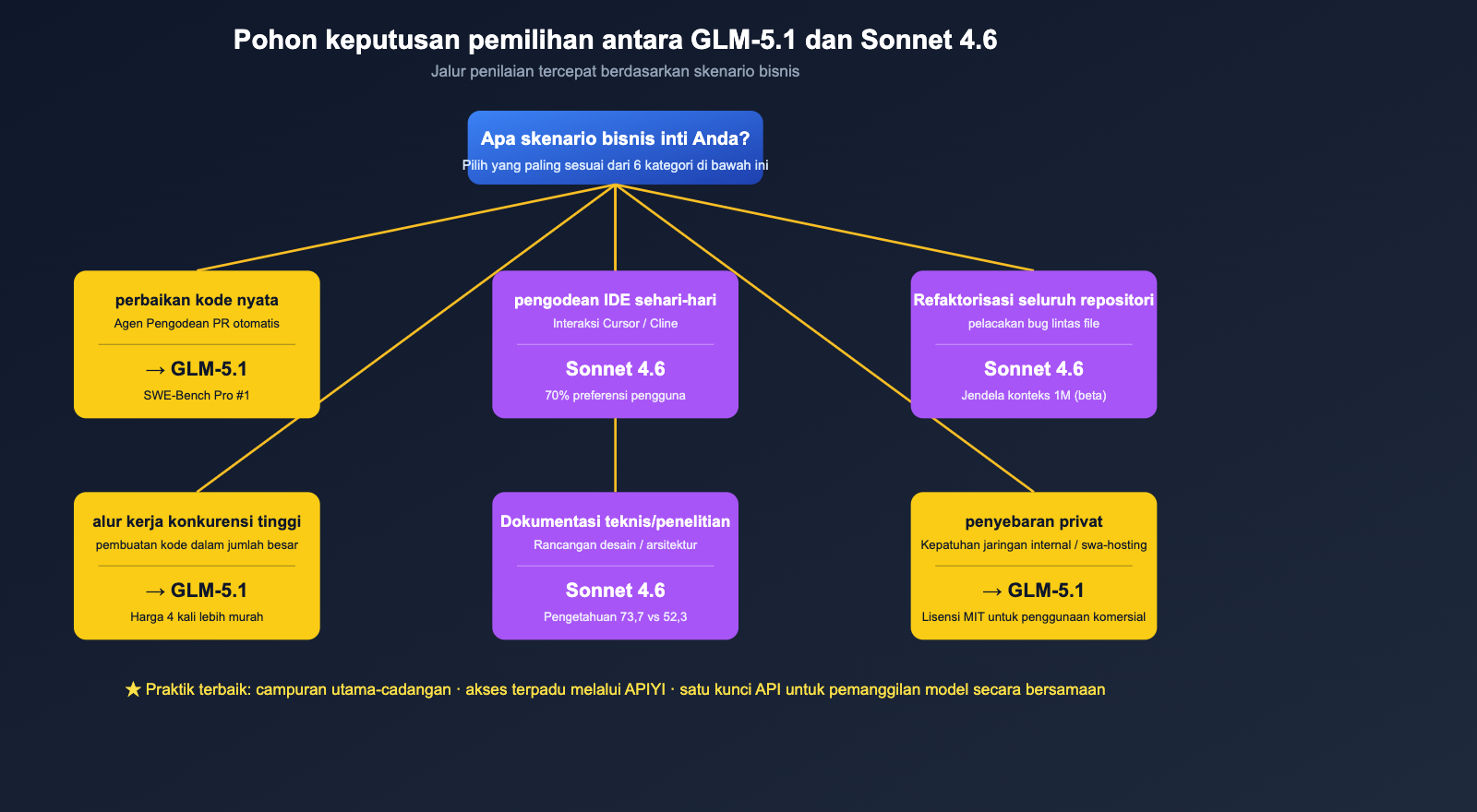
Saran Pemilihan Model Berdasarkan Skenario
Dengan menghubungkan keenam dimensi tersebut, kami dapat memberikan saran "pemilihan model berdasarkan skenario bisnis" yang sangat spesifik.
Tabel Perbandingan Skenario
| Skenario Bisnis | Model Rekomendasi | Alasan Utama |
|---|---|---|
| Perbaikan kode industri nyata (Agen PR otomatis) | GLM-5.1 | Peringkat 1 dunia di SWE-Bench Pro + jendela konteks 8 jam |
| Coding IDE harian (Cursor / Cline) | Claude Sonnet 4.6 | Tingkat preferensi pengguna Claude Code 70%, alur kerja matang |
| Refaktorisasi seluruh repositori / pelacakan bug lintas file | Claude Sonnet 4.6 | Konteks 1M (beta) adalah senjata utama |
| Pembuatan kode standar + pemanggilan konkurensi tinggi | GLM-5.1 | Harga 4x lebih murah, cocok untuk produksi massal |
| Riset teknis / dokumen desain / skema arsitektur | Claude Sonnet 4.6 | Skor rata-rata pengetahuan 73,7 vs 52,3, unggul jauh |
| Penalaran matematika / gaya kompetisi algoritma | GLM-5.1 | AIME 2026 95,3 + GPQA-Diamond 86,2 |
| Modul pembuatan kode dalam SaaS yang menghadap pelanggan | Sonnet 4.6(Utama) + GLM-5.1(Cadangan) | Sonnet utama, GLM cadangan, hemat biaya sekaligus jaga kualitas |
| Deployment privat / kepatuhan jaringan internal | GLM-5.1 | Lisensi MIT + bisa di-host sendiri |
| Interaksi coding bahasa Mandarin | GLM-5.1 | Model domestik lebih ramah terhadap petunjuk bahasa Mandarin |
| Penalaran sulit satu kali + pemanggilan alat rantai panjang | Seri, perlu tes mandiri | Keduanya bisa, perbedaan di bawah 5% |
Strategi Hibrida yang Direkomendasikan
Untuk sebagian besar tim skala menengah, kami lebih menyarankan strategi "Utama-Cadangan Hibrida" daripada harus memilih salah satu:
- Model Utama: Pilih satu berdasarkan skenario bisnis terbanyak Anda (perbaikan kode pilih GLM-5.1, integrasi IDE pilih Sonnet 4.6);
- Model Cadangan: Pasang model lainnya untuk verifikasi A/B + peralihan bertahap (gray release) pada bisnis utama;
- Lapisan Akses Terpadu: Gunakan APIYI apiyi.com untuk memanggil keduanya dengan kunci API yang sama. Kode bisnis hanya perlu mengubah kolom model, tidak perlu mengelola dua logika autentikasi;
- Pemantauan Biaya: Lihat tagihan kedua model secara terpisah di dasbor APIYI, tentukan secara berkala model mana yang memiliki "efisiensi biaya" lebih baik untuk bisnis Anda, lalu sesuaikan rasio lalu lintas secara dinamis.
🎯 Saran Implementasi Strategi Hibrida: Di APIYI apiyi.com, Anda dapat beralih dengan mulus antara GLM-5.1 dan Claude Sonnet 4.6 menggunakan kunci API yang sama, kode bisnis hanya perlu mengubah satu string. Kami menyarankan untuk mengalihkan 70% lalu lintas "pembuatan kode non-kritis" ke GLM-5.1, dan menyisakan 30% lalu lintas "menghadap pelanggan + penalaran sulit" untuk Sonnet 4.6. Dengan cara ini, Anda bisa menikmati keunggulan harga GLM-5.1 sekaligus menjamin stabilitas di skenario krusial.
FAQ GLM-5.1 vs Claude Sonnet 4.6
Q1: Apakah GLM-5.1 benar-benar mengungguli Claude Sonnet 4.6 dalam hal pengodean?
Sebagian unggul, sebagian masih tertinggal. Pada tolok ukur tersulit, yaitu SWE-Bench Pro (perbaikan kode industri nyata), GLM-5.1 meraih skor 58,4 dan menempati peringkat pertama di dunia, melampaui Claude Opus 4.6 dengan 57,3 dan GPT-5.4 dengan 57,7, yang otomatis juga mengungguli Sonnet 4.6. Namun, pada SWE-bench Verified (perbaikan kode terstandarisasi), Sonnet 4.6 masih memimpin dengan 79,6% dibandingkan GLM-5.1 yang mencapai 77,8% (selisih sekitar 1,8 poin persentase). Pada rata-rata skor pengodean komprehensif BenchLM, Sonnet 4.6 juga unggul sekitar 8 poin dengan skor 66,4 dibandingkan GLM-5.1 yang meraih 58,4. Kesimpulannya: GLM-5.1 mengungguli Sonnet 4.6 pada "tingkat kesulitan puncak", namun masih tertinggal dalam hal "keseimbangan cakupan".
Q2: Berapa selisih harga antara GLM-5.1 dan Claude Sonnet 4.6?
Berdasarkan harga beli langsung resmi Z.ai, GLM-5.1 dibanderol $1,00 untuk input / $3,20 untuk output, sedangkan Claude Sonnet 4.6 adalah $3,00 / $15,00—input lebih murah 3 kali lipat, dan output lebih murah sekitar 4,7 kali lipat. Dalam skenario tipikal "1.000 pemanggilan Coding Agent per hari + input 5K / output 20K", tagihan bulanan Sonnet 4.6 sekitar 4,5 kali lipat lebih mahal daripada GLM-5.1. Jika bisnis Anda memiliki "volume output yang jauh lebih besar daripada input", keunggulan efisiensi biaya GLM-5.1 akan jauh lebih terasa.
Q3: Mana yang memiliki jendela konteks lebih besar, GLM-5.1 atau Sonnet 4.6?
Claude Sonnet 4.6 lebih besar. GLM-5.1 memiliki 200K (beberapa platform menampilkan 203K), sementara Sonnet 4.6 memiliki 200K → 1M token (beta). Konteks 1M berarti Sonnet 4.6 dapat membaca seluruh repositori kode berukuran sedang dalam sekali jalan, yang menjadi senjata utamanya dalam tugas "refaktorisasi seluruh repositori / pelacakan bug lintas file". Jika tugas Anda sangat bergantung pada konteks super panjang, Sonnet 4.6 adalah pilihan yang lebih aman.
Q4: Saya saat ini menggunakan Claude Sonnet 4.6 untuk menjalankan Cursor / Cline, apakah layak beralih ke GLM-5.1?
Tergantung pada masalah utama Anda. Jika Anda paling peduli dengan "tagihan", GLM-5.1 dapat memangkas biaya hingga setengahnya atau lebih, sehingga layak dicoba. Jika Anda paling peduli dengan "stabilitas pengalaman pengodean sehari-hari", tingkat preferensi pengguna sebesar 70% untuk Sonnet 4.6 menunjukkan bahwa model ini telah teruji secara luas dalam alur kerja Claude Code, sehingga risiko migrasi mungkin lebih besar daripada keuntungannya. Cara paling aman adalah menggunakan APIYI apiyi.com untuk mengalihkan 20% lalu lintas ke GLM-5.1 guna melakukan A/B testing, lalu putuskan apakah akan memperbesar proporsinya setelah satu minggu.
Q5: Apakah GLM-5.1 dan Sonnet 4.6 keduanya bisa dipanggil melalui APIYI?
Ya, keduanya sudah tersedia. APIYI apiyi.com mendukung tiga format asli sekaligus: OpenAI / Claude Native / Gemini Native. Anda hanya perlu mengubah base_url pada SDK OpenAI menjadi https://api.apiyi.com/v1 dan mengganti model antara glm-5.1 dan claude-sonnet-4-6 (atau ID serupa). Dengan cara ini, Anda bisa menjalankan keduanya dalam kode yang sama, sehingga efisiensi perbandingan horizontal sangat tinggi.
Q6: Sebagai pengembang independen, mana yang harus saya pilih?
Jika Anda hanya bisa memilih satu, lihat alur kerja Anda: untuk Coding Agent / otomatisasi backend / pembuatan kode dalam jumlah besar → pilih GLM-5.1; untuk pemrograman interaktif di dalam IDE / refaktorisasi seluruh repositori / pembuatan konten yang berorientasi pada pelanggan → pilih Sonnet 4.6. Jika Anda tidak ingin pusing memilih, menghubungkan keduanya dan mengelolanya secara terpadu melalui APIYI adalah praktik terbaik bagi pengembang di tahun 2026—tagihan akan otomatis teroptimasi seiring dengan pemilihan model, tanpa terikat pada satu vendor saja.
Kesimpulan: Penilaian Akhir GLM-5.1 vs Claude Sonnet 4.6
Dengan menggabungkan perbandingan dari 6 dimensi, penilaian akhir untuk GLM-5.1 vs Claude Sonnet 4.6 dapat dirangkum sebagai berikut: GLM-5.1 memiliki keunggulan struktural dalam 4 aspek: "perbaikan kode industri dengan tingkat kesulitan tinggi + harga + open source domestik + Agent jangka panjang", sementara Claude Sonnet 4.6 tetap unggul dalam 4 aspek: "keseimbangan cakupan + kedalaman pengetahuan + konteks 1M + kematangan alur kerja IDE". Keduanya bukanlah hubungan "siapa menggantikan siapa", melainkan sepasang alat yang saling melengkapi untuk skenario bisnis yang berbeda.
Bagi tim pengembang di Tiongkok daratan pada pertengahan hingga akhir tahun 2026, strategi paling cerdas bukanlah memilih salah satu, melainkan "campuran utama-cadangan + lapisan akses terpadu": biarkan GLM-5.1 menangani bagian yang sensitif terhadap biaya, otomatisasi jangka panjang, dan kepatuhan privasi, sementara Sonnet 4.6 menangani bagian yang berorientasi pada pengguna, konteks kompleks, dan penulisan teknis. Dengan menggunakan layanan proksi API seperti APIYI untuk menempatkan keduanya di bawah satu kunci API, lalu menyesuaikan rasio lalu lintas secara dinamis berdasarkan data tagihan bisnis nyata, Anda dapat memangkas tagihan bulanan secara signifikan tanpa mengorbankan kualitas.
🎯 Saran Akhir: GLM-5.1 dan Claude Sonnet 4.6 keduanya sudah tersedia di APIYI apiyi.com. Kami menyarankan Anda membuat kunci API di apiyi.com hari ini, ubah
base_urlSDK OpenAI Anda menjadihttps://api.apiyi.com/v1, lalu jalankan 5 tugas GLM-5.1 dengan kode yang sama, kemudian jalankan 5 tugas Sonnet 4.6 dengan petunjuk yang sama untuk memverifikasi sendiri semua kesimpulan dalam artikel ini. Tidak ada evaluasi yang bisa menggantikan pengujian langsung Anda, tetapi validasi minimal selama 30 menit ini akan memberi Anda pemahaman nyata tentang dua model pengodean terkuat di tahun 2026.
Penulis: Tim APIYI | Fokus pada implementasi Model Bahasa Besar AI dan evaluasi rantai alat pengodean. Untuk perbandingan model dan pemanggilan praktis lainnya, silakan kunjungi APIYI apiyi.com.