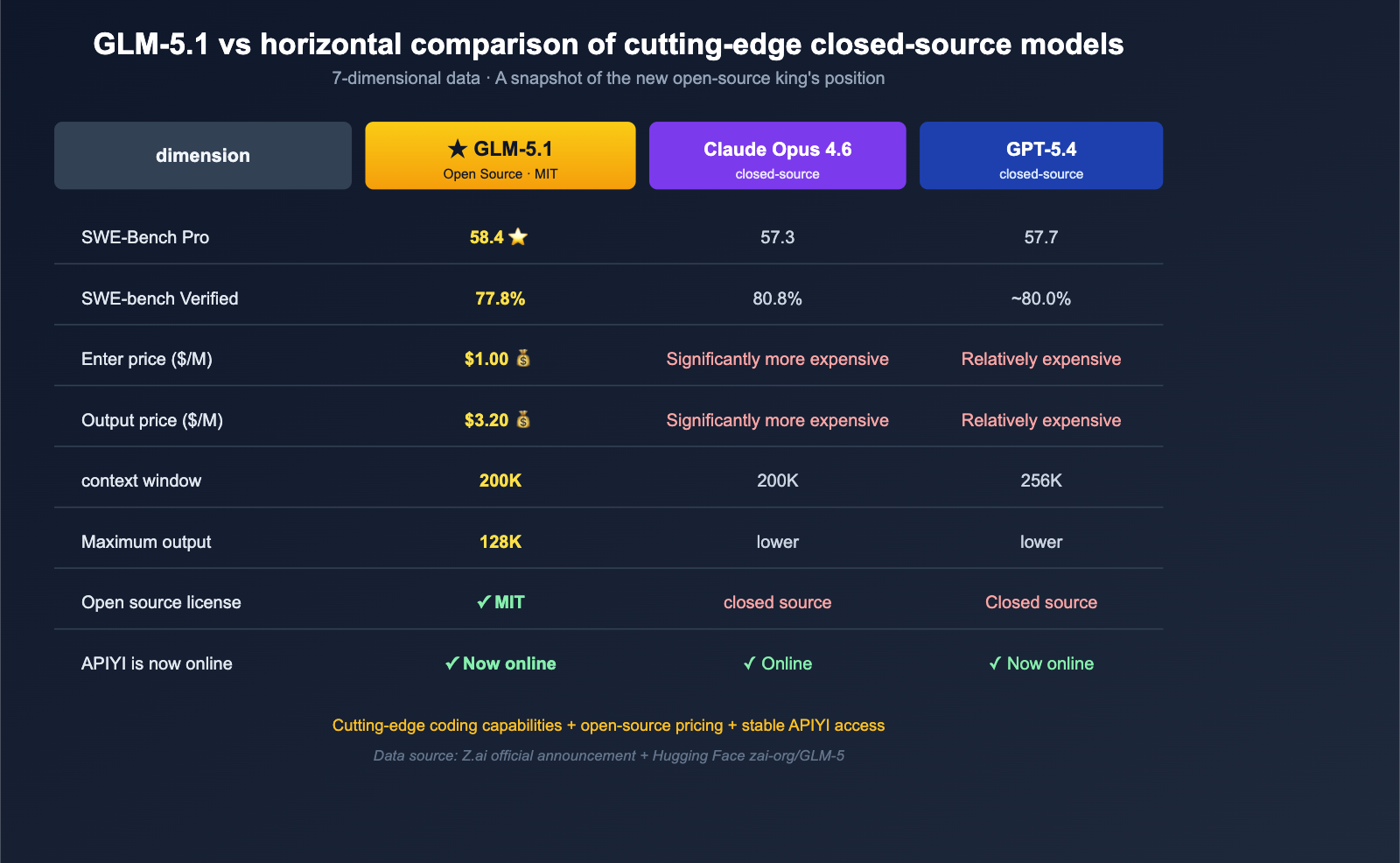
On April 7, 2026, Z.ai (formerly Zhipu AI) officially released the full weights of GLM-5.1 under the MIT license to the Hugging Face repository zai-org/GLM-5. This release immediately caused a stir in the English-speaking AI community—not just because it's "another open-source Large Language Model," but because it topped the global charts on the SWE-Bench Pro software engineering benchmark with a score of 58.4, outperforming GPT-5.4 (57.7), Claude Opus 4.6 (57.3), and Gemini 3.1 Pro (54.2). This marks the first time an open-source model has surpassed all leading closed-source models on a "real-world code repair" benchmark widely cited by the industry.
For developers in mainland China, the rapid rollout of the GLM-5.1 API is particularly exciting—APIYI (apiyi.com) has already integrated it, meaning you no longer need to pull the 754B parameter weights from Hugging Face or apply for an official Z.ai account. You can simply use your existing OpenAI SDK and update the base_url to start making model invocations. In this article, we’ll cover GLM-5.1 across seven dimensions—architecture, benchmarks, training hardware, pricing, and integration methods—and provide a minimal code example for calling GLM-5.1 via APIYI.

GLM-5.1 Key Information Overview (April 2026 Edition)
Before we dive into the details, let's summarize all the key facts about GLM-5.1 in a single table.
| Dimension | GLM-5.1 Known Information |
|---|---|
| Developer | Z.ai (formerly Zhipu AI, listed on HKEX in Jan 2026, valuation ~$31.3B) |
| Release Date | April 7, 2026 |
| License | MIT (allows commercial use + modification + closed-source derivatives) |
| Repository | huggingface.co/zai-org/GLM-5 |
| Architecture | MoE (Mixture of Experts), 754B total parameters / 40B active parameters |
| Context Window | 200,000 tokens |
| Max Output | 128,000 tokens |
| Training Data | 28.5T tokens (increased from 23T in GLM-5) |
| Training Hardware | Entirely Huawei Ascend 910B + MindSpore framework (no Nvidia / AMD) |
| Deployment Framework | vLLM / SGLang / KTransformers |
| Flagship Capability | Long-range Agent coding (single task can work for ~8 hours) |
| Pricing (Direct API) | Input $1.00 / 1M tokens, Output $3.20 / 1M tokens |
| Coding Plan | GLM Coding Plan starts at ~$3/month |
| APIYI Integration | ✅ Live, call via https://api.apiyi.com/v1 |
| Compatible Tools | Claude Code / OpenClaw / Cline / Any OpenAI-compatible editor |
🎯 Quick Start Tip: GLM-5.1 is already available on APIYI (apiyi.com). You only need to change the
base_urlof your existing OpenAI SDK tohttps://api.apiyi.com/v1and set themodelto the corresponding GLM-5.1 model name. You can immediately replace your primary model in your Agent / Cursor / Cline workflows without rewriting any business code.
Why GLM-5.1 Is an "Open-Source Turning Point"
To understand why GLM-5.1 is being hailed by the English-speaking AI community as an "open-source turning point," you have to look at a few key facts side-by-side.
First: The Open-Source Model That Topped SWE-Bench Pro
SWE-Bench Pro is currently recognized as one of the industry's toughest benchmarks for real-world code repair. The tasks are pulled entirely from industrial-grade code repositories. A model must understand the context, locate the bug, and write a fix that passes tests—this is on a completely different level than just "solving a LeetCode problem." Before the release of GLM-5.1, this leaderboard was dominated by the GPT-5.x and Claude Opus series, with open-source models never really coming close to the top three.
But this time, GLM-5.1 took the top spot with a score of 58.4:
| Model | SWE-Bench Pro Score | Open Source |
|---|---|---|
| GLM-5.1 | 58.4 ⭐ | ✅ MIT Licensed |
| GPT-5.4 | 57.7 | ❌ |
| Claude Opus 4.6 | 57.3 | ❌ |
| Gemini 3.1 Pro | 54.2 | ❌ |
This isn't a marginal 0.x gain; it effectively erases the gap between "open-source vs. closed-source" on the most difficult industrial benchmark. Even if you account for the disclaimer that "the benchmark was self-reported by Z.ai and independent evaluation is still pending," the industrial significance of this event cannot be ignored: for the first time, the open-source community has a free model that can compete head-to-head with cutting-edge closed-source models in "real-world code repair."
Second: A Truly Commercial-Friendly MIT License
Another critical fact about GLM-5.1 is its open-source license—MIT. This isn't the common Apache 2.0, and it's certainly not one of those restrictive "research-only / non-commercial" licenses. The meaning of MIT is straightforward: anyone can download, modify, fine-tune, deploy, commercialize, create closed-source derivatives, and sell it without any restrictions, provided the copyright notice is retained.
For enterprise users, this means GLM-5.1 can be used without any hesitation for:
- Internal Coding Agents for self-developed products;
- Code generation/review modules in commercial SaaS;
- Privately deployed IDE plugins;
- Any compliance-sensitive scenario where you can't rely on a specific vendor's API.
As of April 2026, GLM-5.1 is almost the only choice that simultaneously meets the criteria of "cutting-edge performance + MIT open-source + industrial benchmark leader."

GLM-5.1 Architecture and Training: 754B MoE + Huawei Full-Stack
The second fact that sets GLM-5.1 apart is its training stack.
MoE Architecture: 754B Total Parameters / 40B Active
GLM-5.1 uses a Mixture-of-Experts (MoE) architecture with a total of 754B parameters, activating only about 40B per inference. This "Large Language Model + Sparse Activation" design has been repeatedly validated by open-source models like DeepSeek, Qwen, and Mixtral. The core benefits are:
- Large model capacity during training, allowing it to absorb more knowledge (28.5T tokens of pre-training data);
- Only a small fraction of experts are activated during inference, keeping VRAM usage and latency close to a 40B Dense model;
- Different expert paths for conversation and coding tasks, leading to better coherence in long-range tasks.
| Dimension | GLM-5 (Previous Gen) | GLM-5.1 (Current) |
|---|---|---|
| Total Parameters | 355B | 754B |
| Active Parameters | 32B | 40B |
| Pre-training Data | 23T tokens | 28.5T tokens |
| Context Window | Limited | 200K |
| Max Output | Limited | 128K |
| Coding Specialization | Yes | ✅ Significantly Enhanced |
| Agent Long-range Tasks | Yes | ✅ ~8 hours per task |
Key Engineering Highlight: 8-Hour Long-Range Agent
In their announcement, Z.ai repeatedly emphasized the "8-hour single-task" capability of GLM-5.1. This means: you can hand a real engineering task to GLM-5.1 (such as fixing a cross-file bug, migrating a legacy library, or adding a test suite), and it can continuously plan → execute → test → fix → optimize without human intervention until it provides a production-ready result, with the entire process lasting up to 8 hours. This "endurance-type Agent" capability curve was previously only stably replicated in the industry by the Claude Opus series—GLM-5.1 is the first model in the open-source world to reach this level.
Training Hardware: Full Huawei Stack, No U.S. Chips
The third fact worth highlighting is the training hardware for GLM-5.1—it was completed entirely using Huawei Ascend 910B chips + the MindSpore framework, without using any Nvidia or AMD GPUs. This has sparked significant discussion in the English-speaking AI community because it directly proves that: in an environment where Hopper/Blackwell chips are restricted, teams in mainland China are already capable of pre-training models at the 754B MoE scale on domestic hardware. This is not just a technical victory for the model itself, but an industrial-scale showcase of AI training infrastructure in mainland China.
GLM-5.1 Complete Benchmark Report
To ensure we don't miss any key data points, we've compiled the GLM-5.1 benchmark report released by Z.ai into the table below.
| Benchmark | GLM-5.1 Score | Meaning |
|---|---|---|
| SWE-Bench Pro | 58.4 ⭐ | Real-world code repair, #1 globally (open source) |
| SWE-bench Verified | 77.8% | General code repair, ~94.6% of Claude Opus 4.6 (80.8%) |
| CyberGym | 68.7 | Security/CTF reasoning (1507 tasks) |
| MCP-Atlas | 71.8 | MCP tool invocation benchmark |
| T3-Bench | 70.6 | Tool usage and Agent tasks |
| Humanity's Last Exam | 31.0 / 52.3 | Extremely difficult reasoning (no tools / with tools) |
| AIME 2026 | 95.3 | American Invitational Mathematics Examination level |
| GPQA-Diamond | 86.2 | Expert-level scientific reasoning |
Here’s a quick breakdown of the highlights:
- Code Capabilities: It has topped the SWE-Bench Pro, and its SWE-bench Verified score reaches 94.6% of Claude Opus 4.6—meaning for the vast majority of daily engineering tasks, GLM-5.1's coding ability is in the same tier as the current top-performing Claude Opus.
- Mathematical Reasoning: With a 95.3 on AIME 2026 and 86.2 on GPQA-Diamond, it sits firmly at the "frontier level."
- Agent and Tool Usage: Scores of 71.8 on MCP-Atlas and 70.6 on T3-Bench confirm its capability for long-range tasks.
- Honest Assessment: This data currently comes entirely from Z.ai's self-reporting. As of this writing, there hasn't been a fully independent third-party lab verification, so treat these figures as a reference rather than "absolute truth."
🎯 Benchmark Verification Tip: When dealing with self-reported benchmarks, the most pragmatic approach is to run your own real-world business tasks. GLM-5.1 is now live on APIYI (apiyi.com). You can take 5-10 of your team's most common coding prompts and run them through GLM-5.1, Claude Opus 4.6, and GPT-5.4 to cross-verify the SWE-Bench Pro findings with your own data.
GLM-5.1 Pricing Structure: Why It's a "Price-Performance Dark Horse"
Another feature of GLM-5.1 that's hard to ignore is its price. Let's compare it directly with other mainstream frontier models.
Token Price Comparison
| Model | Input ($/M) | Output ($/M) | Open Source |
|---|---|---|---|
| GLM-5.1 | $1.00 | $3.20 | ✅ MIT |
| Claude Opus 4.6 | Significantly higher | Significantly higher | ❌ |
| GPT-5.4 | Higher | Higher | ❌ |
| Gemini 3.1 Pro | Moderate | Moderate | ❌ |
The $1.00 / $3.20 price point is essentially the "floor price" in the "frontier coding model" category. Compared to closed-source models like Claude Opus 4.6, GLM-5.1's actual unit price is only a fraction of the cost, while Z.ai markets its "94.6% of Claude Opus 4.6 coding performance" as a core selling point.
GLM Coding Plan and Subscription Options
Beyond pay-as-you-go token pricing, Z.ai has introduced the GLM Coding Plan—a fixed-rate subscription designed for "heavy coding scenarios" like Cursor, Cline, and Claude Code. Starting at about $3/month for 120 prompts, it's far cheaper than similar closed-source coding plans. These plans are usually tiered (Max / Pro / Lite), allowing you to achieve "Opus-level coding power at a near-free cost" for daily developer workflows where calls are frequent but individual tasks are inexpensive.
🎯 Pricing Strategy Tip: For teams that want "Claude Opus-level coding power without the Opus price tag," we recommend calling GLM-5.1 directly via APIYI (apiyi.com). You'll benefit from a unified interface and local currency settlement, and you can easily switch between GPT-5.4 and Claude Opus 4.6 within the same codebase to perform A/B testing and determine which model offers the best ROI based on your actual bills.
description: GLM-5.1 is now available on APIYI. Learn how to integrate it into your workflow with our minimal Python examples and coding tool configurations.
GLM-5.1 is Now Live on APIYI: Minimal Invocation Example
Finally, here’s the part Chinese developers care about most—GLM-5.1 is now live on APIYI (apiyi.com). You can call it directly using existing OpenAI-compatible SDKs, meaning there’s absolutely no need to deploy the 754B parameter weights yourself on Hugging Face.
Minimal Python Example
Below is a minimal Python example showing how to call GLM-5.1 using the official OpenAI SDK:
from openai import OpenAI
# Change base_url to APIYI and replace api_key with your own APIYI Key
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_APIYI_KEY"
)
resp = client.chat.completions.create(
model="glm-5.1", # Specify the GLM-5.1 model ID directly
messages=[
{"role": "system", "content": "You are an expert software engineer."},
{"role": "user", "content": "Write a Python LRU cache with expiration time and capacity limits."}
],
max_tokens=4096
)
print(resp.choices[0].message.content)
Your business logic remains completely unchanged—the same logic you used for GPT-4, Claude, or DeepSeek works perfectly for GLM-5.1.
Integrating with Cursor / Cline / Claude Code
Z.ai has explicitly confirmed that GLM-5.1 is compatible with all OpenAI-standard coding tools, including Claude Code, OpenClaw, and Cline. Simply point the OpenAI-compatible endpoint to https://api.apiyi.com/v1 in these tools and select the GLM-5.1 model. You can switch your primary coding model from Opus or GPT-5 to GLM-5.1 without modifying any of your existing workflows. The process is identical for IDEs like Cursor that support OpenAI Custom Endpoints.
Streaming and Long Context Example
GLM-5.1 on APIYI fully retains its 200K context window and 128K output capability. For long-running Agent tasks, you can enable stream mode to achieve lower time-to-first-token latency:
stream = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "Conduct a full review of this 5,000-line Python repository and list potential bugs and refactoring suggestions."}
],
stream=True,
max_tokens=128000
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
print(delta.content, end="", flush=True)
🎯 Integration Tip: GLM-5.1 on APIYI (apiyi.com) already supports OpenAI-compatible interfaces, streaming output, and a full 200K context window. We recommend pointing your team's Cursor, Cline, or Claude Code tool entries to APIYI today. Try using GLM-5.1 as your primary coding model for a week to see if it can replace the Opus or GPT-5 models you're currently using for real-world engineering tasks.
Who is GLM-5.1 For (and Who is it Not For)?
Who Should Use It
| User Group | Why It's a Good Fit |
|---|---|
| Heavy Coding Agent Users | Top of the SWE-Bench Pro leaderboard; handles 8-hour long-range tasks. |
| Teams on a Budget | Pricing at $1.00/$3.20 is significantly lower than Opus / GPT-5. |
| Enterprises Needing MIT-Licensed Deployment | Completely unrestricted; suitable for commercial use and closed-source derivatives. |
| Cursor / Cline / Claude Code Users | Native compatibility with OpenAI interfaces; one-click replacement. |
| Researchers Interested in Domestic AI Stacks | Trained entirely on Huawei Ascend 910B + MindSpore. |
| Math / Scientific Reasoning Enthusiasts | AIME 2026 95.3 / GPQA-Diamond 86.2 scores. |
Who Might Want to Look Elsewhere
| User Group | Reason |
|---|---|
| Users who prioritize "Independent Third-Party Benchmarks" | Current data is self-reported by Z.ai; independent verification is recommended. |
| Tasks focused on Multimodal (Image/Video) | GLM-5.1 is optimized for text and code; it is not a multimodal powerhouse. |
| Users fully dependent on Anthropic / OpenAI tool ecosystems | Some advanced features still rely on native vendor APIs. |
GLM-5.1 FAQ
Q1: Is GLM-5.1 really open source? Can I use it commercially?
Yes. GLM-5.1 was fully open-sourced by Z.ai on April 7, 2026, via Hugging Face (zai-org/GLM-5) under the MIT License. It allows for commercial use, closed-source derivatives, and secondary fine-tuning; you only need to retain the copyright notice. This is one of the most permissive open-source licenses available, meaning you can integrate GLM-5.1 directly into your commercial products, SaaS, or private deployments without paying any licensing fees.
Q2: Is GLM-5.1 really better than GPT-5.4 and Claude Opus 4.6?
On the SWE-Bench Pro benchmark, the score reported by Z.ai (58.4) does indeed surpass GPT-5.4 (57.7) and Claude Opus 4.6 (57.3). However, please note: these figures are currently self-reported by Z.ai and have not yet been fully replicated by independent third-party labs. We recommend that you don't treat these numbers as "absolute truth," but rather run your own real-world business tasks through it—you can do this right now via GLM-5.1 on APIYI (apiyi.com) without needing to deploy it yourself.
Q3: Is the GLM-5.1 API available on APIYI? How do I call it?
It is already live. You simply need to change the base_url in your official OpenAI SDK to https://api.apiyi.com/v1, replace the api_key with your APIYI Key, and set the model to the corresponding GLM-5.1 model ID. You can start calling it immediately without rewriting any of your business code. The "Minimal Invocation Example" in the article provides a Python version, and it works just as well for Node, Go, or Rust SDKs.
Q4: Is GLM-5.1 better than other domestic open-source models like DeepSeek, Qwen, or Kimi?
The biggest differentiator for GLM-5.1 is its "Long-range Agent Coding + topping the SWE-Bench Pro leaderboard"—a direction that DeepSeek, Qwen, and Kimi haven't tackled head-on. If your business focuses on "daily conversation + RAG," DeepSeek and Qwen remain highly competitive. However, if your business involves Coding Agents, IDE integration, or code repair, GLM-5.1 is currently the top choice in the open-source world. On APIYI, you can put these models into a side-by-side comparison test and form your own judgment in 15 minutes.
Q5: What hardware is required for local deployment of GLM-5.1?
GLM-5.1 features a 754B total parameter / 40B active MoE architecture. Local deployment requires a professional-grade multi-GPU cluster, which is virtually unrealistic for the average team. Z.ai officially recommends using vLLM, SGLang, or KTransformers for large-scale inference service deployment. If you just want to use GLM-5.1 rather than research it, the most efficient way is to call it directly via APIYI (apiyi.com)—no GPU required, no maintenance, and you only pay for what you use.
Q6: Was GLM-5.1 really trained without Nvidia GPUs?
Yes. Z.ai publicly disclosed that GLM-5.1 was trained entirely on Huawei Ascend 910B chips using the MindSpore framework, without using any Nvidia or AMD GPUs. This is the first case in the 2026 open-source Large Language Model field to achieve training of a "fully domestic hardware + 754B MoE model," which carries significant industrial symbolic meaning.
Summary: GLM-5.1 is a Turning Point for Open-Source AI in 2026
After connecting the architecture, benchmarks, pricing, training stack, and API access path, the position of GLM-5.1 as of April 2026 is clear: it's not just another routine open-source model upgrade, but a landmark event proving that "open source can truly outperform closed-source frontiers." The world-leading SWE-Bench Pro score of 58.4, the total openness of the MIT license, the extremely low price of $1.00/$3.20, 200K context + 128K output, 8-hour long-range Agent capabilities, and the full Huawei Ascend 910B training stack—any one of these facts would be worth a report, but combined, they represent an "open-source turning point."
The even better news for developers in mainland China is that the GLM-5.1 API is already live on APIYI: you don't need to deploy 754B weights yourself, you don't need an overseas credit card, and you don't need to wait for any approvals. Just change the base_url to https://api.apiyi.com/v1 and the model to GLM-5.1, and you can replace your primary coding model in Cursor, Cline, or Claude Code with this new open-source king today. If you're still struggling with Opus/GPT-5 bills, this is a prime opportunity to spend an afternoon testing it out.
🎯 Final Recommendation: To experience the "frontier coding capabilities + open-source pricing + stable APIYI access" of GLM-5.1 firsthand, we suggest you create an API Key on apiyi.com today, update your existing OpenAI SDK
base_urltohttps://api.apiyi.com/v1, set themodelto GLM-5.1, and run it against your team's daily coding tasks for a week. Regardless of whether you ultimately decide to switch your primary model, this week of testing will give you first-hand insight into the true level of open-source AI in 2026.
Author: APIYI Team | Focusing on AI Large Language Model implementation and the open-source ecosystem. For more GLM-5.1 / Claude / GPT-5 practical invocation and comparisons, please visit APIYI at apiyi.com.