En abril de 2026, los dos modelos de codificación que más curiosidad despiertan en la comunidad de desarrolladores de China son GLM-5.1 y Claude Sonnet 4.6. El primero acaba de ser liberado bajo licencia MIT por Z.ai (anteriormente Zhipu), logrando una puntuación de 58.4 en SWE-Bench Pro, superando a Claude Opus 4.6, GPT-5.4 y Gemini 3.1 Pro, y posicionándose instantáneamente como el líder mundial en codificación de código abierto. Por su parte, Anthropic describe al segundo como el "nivel insignia dentro de los modelos de gama media", alcanzando un 79.6% en SWE-bench Verified, muy cerca del 80.8% de Opus 4.6, pero a una fracción del precio y, por primera vez, ofreciendo una ventana de contexto de 1M de tokens para la serie Sonnet.
Entonces surge la pregunta: GLM-5.1 vs Claude Sonnet 4.6, ¿cuál es realmente mejor en escenarios de programación reales? No es una pregunta que se pueda responder con una sola frase. Sus fortalezas están distribuidas de forma muy distinta: GLM-5.1 ha superado a Sonnet 4.6 en el estándar de "reparación de código real a nivel industrial", pero en las evaluaciones integrales de terceros, Sonnet recupera terreno en la puntuación promedio general. Este artículo desglosará las diferencias reales en 6 dimensiones (benchmarks de código, conocimiento, precio, ventana de contexto, tareas de larga duración para agentes y compatibilidad de ecosistema) y ofrecerá recomendaciones claras de selección según el caso de uso.

Resumen de datos clave: GLM-5.1 vs Claude Sonnet 4.6
Antes de entrar en comparaciones, pongamos los hechos clave de ambos modelos en una tabla. Todos los datos provienen de información pública de BenchLM, Z.ai, Anthropic y plataformas de evaluación de terceros.
| Dimensión | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Proveedor | Z.ai (anteriormente Zhipu AI) | Anthropic |
| Fecha de lanzamiento | 07-04-2026 (código abierto) | Principios de 2026 |
| Arquitectura | 754B MoE / 40B activados | No pública (nivel Sonnet medio) |
| Licencia | ✅ MIT | ❌ Código cerrado |
| Ventana de contexto | 200K (algunas plataformas muestran 203K) | 200K → 1M (beta) |
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐ (n.º 1 en open source, supera a Opus 4.6) | Ligeramente inferior a Opus 4.6 |
| Puntuación media de código (BenchLM) | 58.4 | 66.4 |
| Puntuación media de conocimiento (BenchLM) | 52.3 | 73.7 |
| Puntuación total (BenchLM) | 79 | 80 |
| Precio de entrada ($/M) | $1.00 (directo de Z.ai) | $3.00 |
| Precio de salida ($/M) | $3.20 (directo de Z.ai) | $15.00 |
| Tareas de agente de larga duración | ~8 horas por tarea | 70% de preferencia de usuarios de Claude Code |
| Integración con APIYI | ✅ Disponible en https://api.apiyi.com/v1 |
✅ Disponible |
| Herramientas compatibles | Claude Code / Cline / Cursor / OpenClaw | Igual que el anterior + ecosistema nativo de Anthropic |
🎯 Consejo de decisión rápida: La diferencia entre ambos no es "cuál es mejor o peor", sino "en qué tipo de escenario destaca cada uno". Si quieres realizar una comparación horizontal inmediata, APIYI (apiyi.com) ya tiene integrados tanto GLM-5.1 como Claude Sonnet 4.6. Solo necesitas modificar el campo
modelpara alternar entre ambos en tu código de negocio y, en menos de 15 minutos, obtendrás una conclusión más precisa para tus tareas reales que cualquier evaluación externa.
Diferencias clave entre GLM-5.1 y Claude Sonnet 4.6: no son el mismo tipo de modelo
Lo primero que hay que dejar claro es que GLM-5.1 y Claude Sonnet 4.6, estrictamente hablando, no son modelos de la "misma categoría"; sus objetivos de diseño presentan diferencias sistemáticas.
Diferencias en el posicionamiento del modelo
| Dimensión | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Posicionamiento del fabricante | "Código abierto de vanguardia + Agente de largo alcance" | "Buque insignia de gama media · Rey de la relación calidad-precio" |
| Magnitud de parámetros | Modelo de Lenguaje Grande (754B MoE) | Modelo de tamaño medio (parámetros no públicos) |
| Objetivo de entrenamiento | Codificación + Agente + Razonamiento matemático | General + Codificación + Conocimiento + Seguridad |
| Modelo de negocio | Código abierto MIT + API propia de Z.ai | Suscripción de código cerrado + API |
| Principales competidores | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Presta atención a este punto: en el posicionamiento interno de Z.ai, el GLM-5.1 apunta en realidad al Claude Opus 4.6, no al Sonnet 4.6. Esto significa que, si comparas puramente el "límite superior de capacidad de codificación", el grupo de control del GLM-5.1 debería ser Opus, no Sonnet. Sin embargo, en términos de "precio + capacidad integral + utilidad", Sonnet 4.6 es un rival muy fuerte en el mercado de gama media, por lo que comparar ambos sigue teniendo un valor de ingeniería muy práctico.
Situación actual en evaluaciones integrales de terceros
Según la clasificación provisional publicada por BenchLM en abril de 2026:
- Puntuación total: Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (diferencia de 1 punto, casi un empate)
- Promedio de codificación: Claude Sonnet 4.6 = 66.4, GLM-5.1 = 58.4 (Sonnet 4.6 lidera por 8 puntos)
- Promedio de conocimiento: Claude Sonnet 4.6 = 73.7, GLM-5.1 = 52.3 (Sonnet 4.6 lidera por 21.4 puntos, la mayor brecha)
Pero en otra evaluación de referencia específica, la situación se invierte por completo:
- SWE-Bench Pro (reparación de código industrial real): GLM-5.1 = 58.4 ⭐, superando al Claude Opus 4.6 con 57.3 y al GPT-5.4 con 57.7, dejando al Sonnet 4.6 naturalmente por debajo.
- SWE-bench Verified: Claude Sonnet 4.6 = 79.6%, GLM-5.1 = 77.8%, una diferencia de solo 1.8 puntos porcentuales.
Al comparar estos grupos de números, se llega a la primera conclusión: GLM-5.1 no es un monstruo que "supere totalmente al Sonnet 4.6", pero sí obtuvo el primer lugar en la "reparación de código industrial de mayor dificultad", mientras que Sonnet 4.6 mantiene una ventaja equilibrada en evaluaciones de codificación integral más amplias.
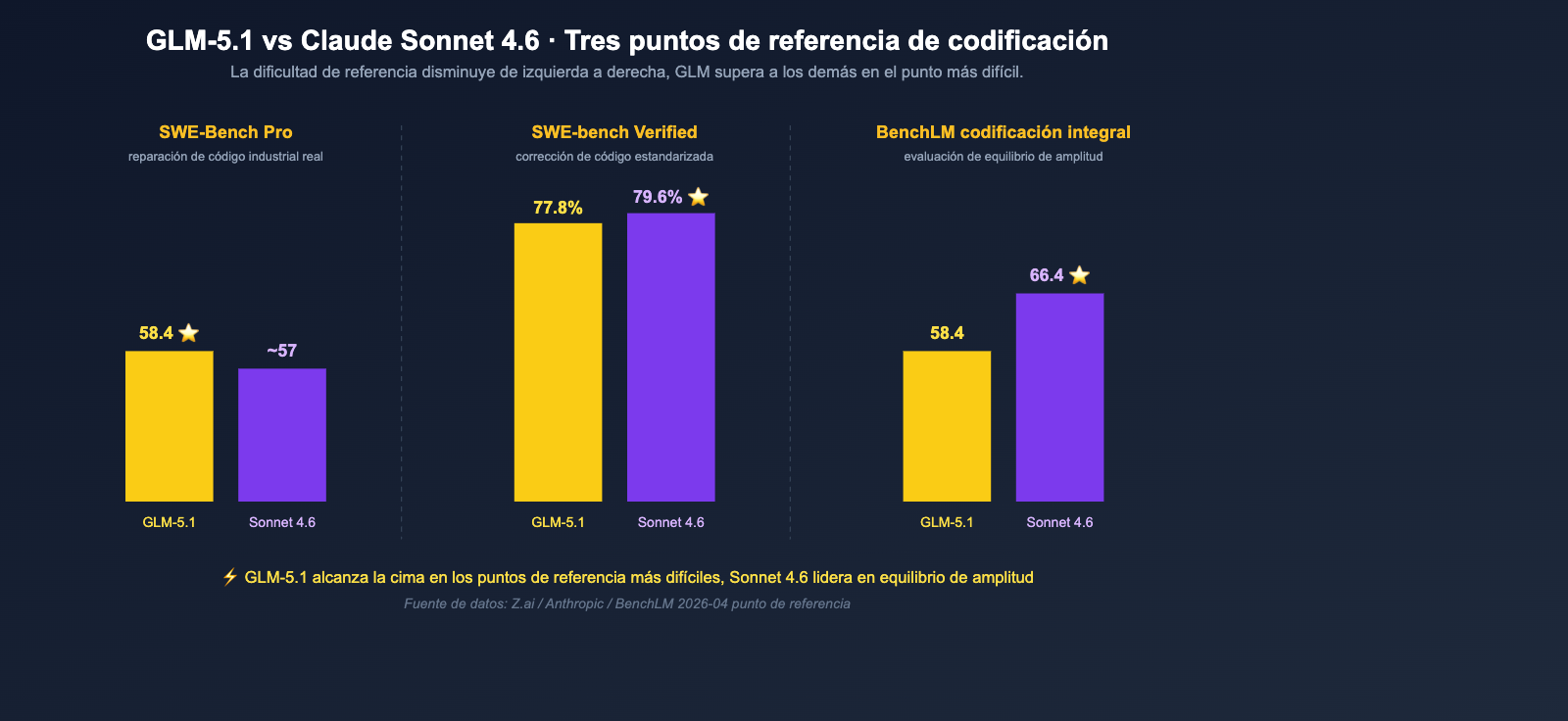
Dimensión 1: Comparativa de referencia de código — La brecha real entre GLM-5.1 y Sonnet 4.6
La capacidad de codificación es el núcleo de esta comparación y la parte más propensa a ser malinterpretada por las cifras de referencia. Hemos consolidado todas las referencias relevantes en una tabla para luego interpretarlas desde la perspectiva de un ingeniero.
Comparativa completa de referencias relacionadas con el código
| Referencia | GLM-5.1 | Claude Sonnet 4.6 | Lado líder | Brecha |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ punto |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| Promedio de codificación BenchLM | 58.4 | 66.4 | Sonnet 4.6 | 8 puntos |
| OSWorld (Escritorio de agente) | No público | 72.5% | Sonnet 4.6 | — |
| Tasa de preferencia de usuario Claude Code | No participa | 70% (vs Sonnet 4.5), 59% (vs Opus 4.5) | Sonnet 4.6 | — |
| Tareas de largo alcance de 8 horas | ✅ Destacado oficial | Soporta largo alcance en Claude Code | Casi empate | — |
Interpretación desde la perspectiva de ingeniería
Después de leer esta tabla tres veces, se pueden extraer varias conclusiones que cualquier persona, incluso si no es fanático de las referencias industriales, puede entender:
- Si tu trabajo es "reparar errores reales en repositorios reales": GLM-5.1 ocupa el primer lugar en SWE-Bench Pro. Esta es una referencia muy "cercana al día a día de un ingeniero de primera línea", lo que significa que GLM-5.1 es el más adecuado como motor central de un Agente de Codificación.
- Si tu trabajo es "reparación de código estandarizada + programación general": El SWE-bench Verified de Sonnet 4.6 es ligeramente superior y su promedio de codificación integral en BenchLM es claramente líder; es más estable en cuanto a "amplitud".
- Si tu trabajo incluye tareas de largo alcance en Claude Code / Cursor: La tasa de preferencia de usuario del 70% de Sonnet 4.6 demuestra que ha sido validado en el "flujo de desarrollo real"; la capacidad de largo alcance de 8 horas de GLM-5.1 es un punto de venta clave de Z.ai, pero necesitas probarlo tú mismo para confirmar los resultados.
- Si tu trabajo incluye "problemas intensivos en conocimiento" (consultar documentación, escribir diseños, realizar investigación técnica): La diferencia es muy evidente, con 73.7 de Sonnet 4.6 frente a 52.3 de GLM-5.1.
¿Por qué ocurren estas "contradicciones entre referencias"?
Muchos lectores preguntarán: ¿por qué, siendo ambos "capacidad de codificación", una referencia dice que GLM-5.1 es más fuerte y otra dice que Sonnet 4.6 lo es? La respuesta radica en las diferencias en el diseño de las referencias:
- SWE-Bench Pro se inclina hacia la "reparación de código industrial real de altísima dificultad", con un alto umbral de calidad de tareas y menor cantidad, exigiendo al máximo la capacidad de 'razonamiento de largo alcance + invocación de herramientas' del modelo, que es precisamente la dirección en la que destaca GLM-5.1.
- SWE-bench Verified es un "conjunto de tareas de reparación de código estándar verificadas por humanos", más cercano al "nivel promedio de escenarios de desarrollo diario", exigiendo mayor 'amplitud + estabilidad' del modelo, que es el punto fuerte de Sonnet 4.6.
- El promedio de codificación integral de BenchLM realiza un promedio ponderado de múltiples referencias, siendo más amigable con los buques insignia de tamaño medio que pueden manejar 'todo tipo de tareas'.
Al entender esta capa de diferencia, ya no te dejarás engañar por ninguna cifra aislada.
🎯 Sugerencia de selección de referencia: No saques conclusiones basándote en una sola referencia. La práctica más pragmática es: organiza las 5-10 tareas de codificación reales más comunes de tu equipo en un conjunto de referencia interno y, a través del servicio proxy de API APIYI (apiyi.com), invoca tanto a GLM-5.1 como a Claude Sonnet 4.6 para ejecutar una prueba, verificando con tus propios datos cuál se adapta mejor al estilo de tu negocio.
Dimensión 2: Conocimiento y razonamiento — El área de ventaja clara de Sonnet 4.6
Si bien en el nivel de código podemos decir que están "muy igualados", en la dimensión de conocimiento / razonamiento / comprensión general, la ventaja de Sonnet 4.6 es muy evidente.
| Dimensión | GLM-5.1 | Claude Sonnet 4.6 | Diferencia |
|---|---|---|---|
| Puntuación media de conocimiento BenchLM | 52.3 | 73.7 | 21.4 puntos |
| Comprensión de documentos largos | Fuerte | Más fuerte (con ventana de contexto de 1M) | |
| Escritura en lenguaje natural | Excelente en chino | Equilibrado en múltiples idiomas | |
| Razonamiento de seguridad y cumplimiento | Medio | Claramente superior (punto fuerte de Anthropic) |
Esto significa que, en los siguientes escenarios, Sonnet 4.6 es la opción más segura:
- Redacción de informes de investigación técnica / documentos de diseño / propuestas de arquitectura;
- Resumen de documentos y análisis de cumplimiento entre idiomas;
- Tareas híbridas que requieren "entender tanto el código como el negocio";
- Generación de contenido cara al cliente, que requiere barreras de seguridad más robustas.
La relativa debilidad de GLM-5.1 en la dimensión de conocimiento no se debe a una "falta de entrenamiento", sino a que sus datos de entrenamiento y objetivos están más orientados a la codificación, matemáticas y uso de herramientas, por lo que no es tan equilibrado en "conocimiento general" como Sonnet 4.6.
Dimensión 3: Comparativa de precios — El as bajo la manga de GLM-5.1
Si solo nos fijamos en un aspecto, el precio es el arma más afilada de GLM-5.1 frente a Sonnet 4.6.
Comparativa directa del precio por token
| Dimensión | GLM-5.1 (Compra directa Z.ai) | Claude Sonnet 4.6 | Ventaja de coste de GLM-5.1 |
|---|---|---|---|
| Entrada ($/M) | $1.00 | $3.00 | 3 veces más barato |
| Salida ($/M) | $3.20 | $15.00 | ~4.7 veces más barato |
| Global (proporción 2:1) | ~$1.73 | ~$7.00 | ~4 veces más barato |
Ten en cuenta un par de cosas:
- Los precios de GLM-5.1 reportados por plataformas de terceros (como BenchLM) son ligeramente más altos ($1.40 entrada / $4.40 salida) debido a los márgenes de reventa; el precio oficial de compra directa de Z.ai es de $1.00 / $3.20;
- Los precios de $3 / $15 de Sonnet 4.6 son los oficiales de Anthropic, ya 5 veces más baratos que Opus 4.6, lo que lo convierte en el "rey de la relación calidad-precio" en el mercado de gama media;
- Aun así, la ventaja de GLM-5.1 en los tokens de salida sigue siendo de 4 a 5 veces, lo cual es extremadamente significativo para escenarios de generación de código donde el "volumen de salida es mayor que el de entrada".
Ejemplo de coste real
Para que la diferencia sea más intuitiva, imaginemos una tarea típica de un "Agente de codificación diario": 5K tokens de entrada, 20K tokens de salida, con 1000 invocaciones diarias.
| Modelo | Coste entrada/día | Coste salida/día | Total/día | Total/mes |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
Diferencia: El coste mensual de Sonnet 4.6 es aproximadamente 4.5 veces mayor que el de GLM-5.1.
Para una empresa SaaS mediana con "1000 invocaciones de agente al día", solo en costes de tokens la diferencia puede ser de casi 7000 dólares al mes, dinero suficiente para contratar a medio ingeniero adicional.
🎯 Sugerencia de optimización de costes: Para los equipos que ya utilizan Claude Sonnet 4.6, recomendamos empezar derivando el 20% del tráfico a GLM-5.1 a través de APIYI (apiyi.com) para realizar una prueba A/B. Si los resultados son aceptables, trasladen toda la "generación de código para tareas no críticas" a GLM-5.1 y reserven las invocaciones críticas "cara al cliente" para Sonnet 4.6. De esta forma, podrán reducir drásticamente la factura sin sacrificar la calidad general.
Dimensión 4: Ventana de contexto — El contraataque de Sonnet 4.6
En cuanto a precio, GLM-5.1 gana por goleada, pero en el apartado de la ventana de contexto, Sonnet 4.6 recupera la iniciativa.
| Dimensión | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Contexto estándar | 200K (203K en algunas plataformas) | 200K |
| Contexto Beta | — | 1M de tokens (beta) |
| Salida máxima | 128K | Más baja |
| Compresión de contexto | No | ✅ Compresión automática de contexto antiguo |
1M de tokens es la mejora insignia de Sonnet 4.6; esto significa que puedes meter un repositorio de código mediano completo en una sola indicación sin necesidad de recurrir a la recuperación RAG. Para tareas como "refactorización de todo el repositorio / localización de errores entre archivos / comprensión completa del código base", Sonnet 4.6 es prácticamente insustituible en abril de 2026.
Los 200K de GLM-5.1 ya son suficientes para el 90% de los escenarios diarios, pero se quedan un paso atrás en los casos límite de "contexto ultralargo".
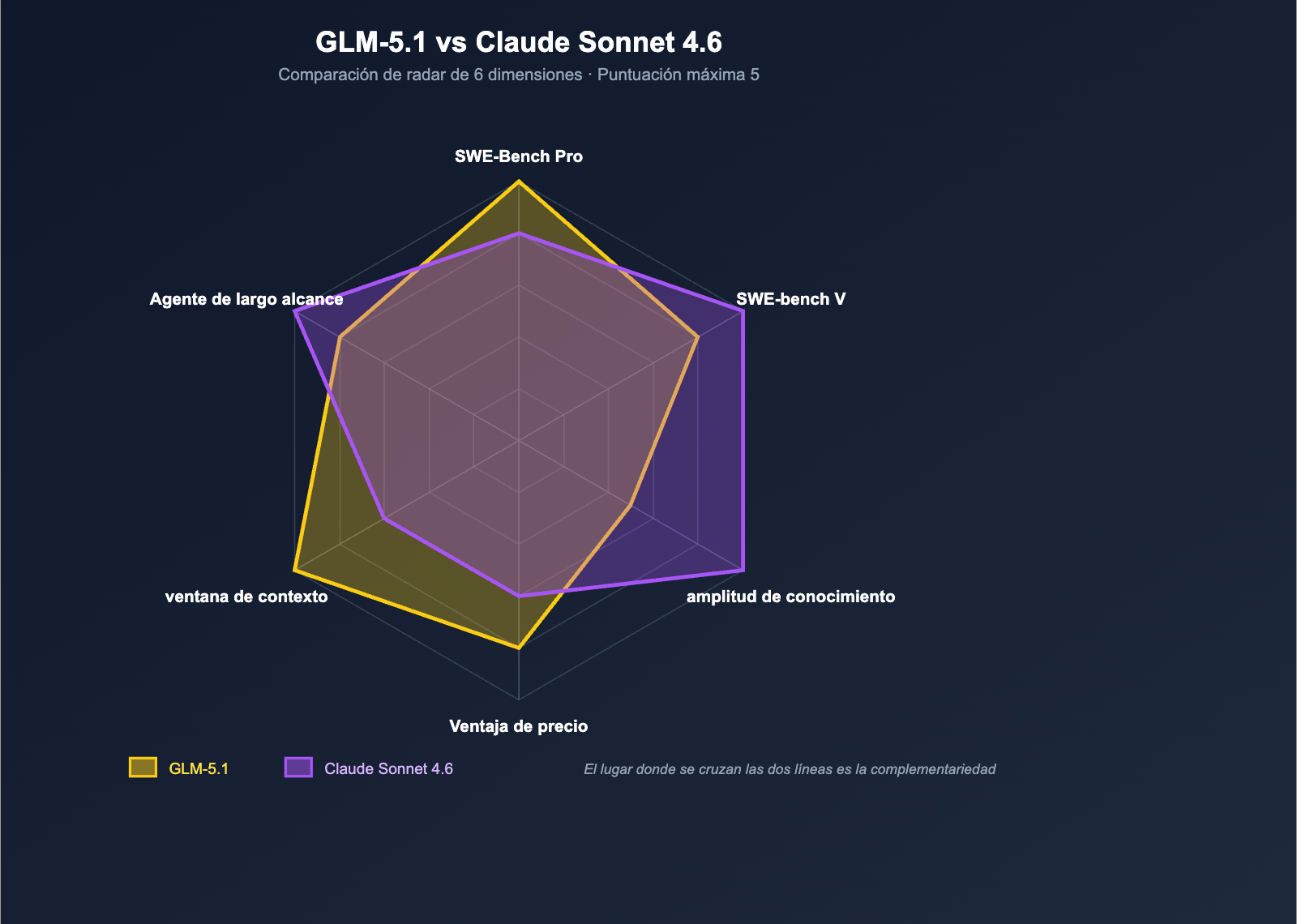
Dimensión 5: Tareas de larga duración de agentes — El duelo de dos enfoques
El quinto punto es la capacidad de tareas de larga duración de los agentes, que es el campo de batalla donde compiten todos los modelos de codificación líderes en 2026.
Dos rutas distintas para el "largo alcance"
- GLM-5.1: Z.ai apuesta por el "trabajo continuo de 8 horas por tarea", enfatizando un ciclo integral de planificación → ejecución → prueba → reparación → optimización secundaria, basándose en la profundidad de razonamiento del modelo y la estabilidad en la invocación de herramientas.
- Claude Sonnet 4.6: Anthropic apuesta por la "experiencia práctica de Claude Code". El 70% de los usuarios de Sonnet 4.5 prefieren Sonnet 4.6 en las pruebas internas, gracias al flujo de trabajo de ingeniería de Claude Code + 1M de contexto + compresión de contexto.
Podemos resumirlo así:
| Ruta | Ventaja principal | Escenario ideal |
|---|---|---|
| GLM-5.1 | Profundidad de razonamiento + estabilidad de herramientas | Agentes de automatización en segundo plano / tareas desatendidas |
| Sonnet 4.6 | Flujo de trabajo Claude Code + 1M de contexto | Programación interactiva para desarrolladores / integración en IDE |
Si lo que haces es "ejecutar agentes en segundo plano para desarrollar funciones" en escenarios desatendidos, la capacidad de larga duración de 8 horas de GLM-5.1 es ideal. Si, por el contrario, eres un "ingeniero que dialoga con el modelo en el IDE para escribir código", la experiencia de integración de Claude Code en Sonnet 4.6 es mucho más madura.
Dimensión 6: Compatibilidad del ecosistema — La ventaja de la cadena de herramientas de Sonnet 4.6
La última dimensión es el ecosistema. En este apartado, Sonnet 4.6 sigue manteniendo una ventaja clara, aunque GLM-5.1 ha recortado distancias rápidamente.
| Dimensión | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Compatibilidad con Claude Code | ✅ (Entrada compatible con OpenAI) | ✅ Nativa |
| Cline / Cursor | ✅ (Entrada compatible con OpenAI) | ✅ Nativa |
| OpenClaw | ✅ | ✅ |
| Invocación de herramientas de Anthropic | Estilo OpenAI | ✅ Nativa |
| Frameworks de agentes de terceros | Mayoría con soporte compatible con OpenAI | Mayoría con soporte nativo de Anthropic |
| Flexibilidad de despliegue | ✅ MIT autoalojado / APIYI / Z.ai propio | APIYI / Oficial de Anthropic |
Cabe destacar que APIYI (apiyi.com) admite simultáneamente los tres formatos nativos: OpenAI / Claude Native / Gemini Native, lo que significa que, independientemente del estilo de SDK que desees utilizar para la invocación del modelo de GLM-5.1 y Sonnet 4.6, puedes hacerlo bajo la misma clave API. Este es un detalle muy práctico en las pruebas comparativas entre ambos: no necesitas gestionar dos conjuntos de autenticación, dos sistemas de monitoreo ni dos facturas durante el periodo de pruebas.
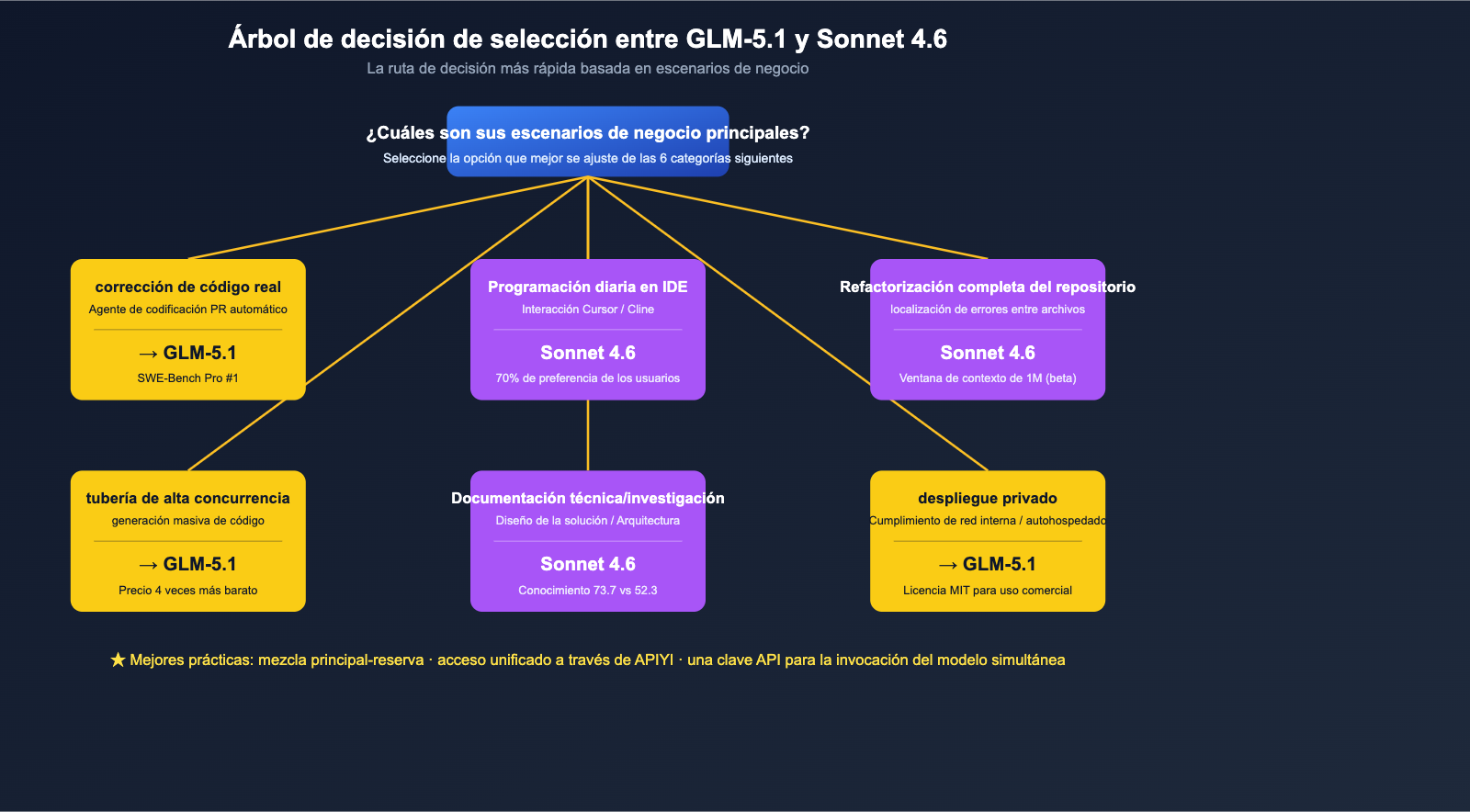
Recomendaciones de selección final según el escenario
Al conectar las 6 dimensiones, podemos ofrecer recomendaciones muy concretas sobre "cómo elegir un modelo según el escenario de negocio".
Tabla comparativa de escenarios
| Escenario de negocio | Modelo recomendado | Razón clave |
|---|---|---|
| Corrección de código industrial real (PR automático de agentes) | GLM-5.1 | #1 mundial en SWE-Bench Pro + ventana larga de 8 horas |
| Programación diaria en IDE (Cursor / Cline) | Claude Sonnet 4.6 | 70% de preferencia de usuarios de Claude Code, flujo de trabajo maduro |
| Refactorización de repositorio completo / localización de bugs entre archivos | Claude Sonnet 4.6 | 1M de ventana de contexto (beta) es su arma principal |
| Generación de código estandarizado + invocación de alta concurrencia | GLM-5.1 | 4 veces más barato, ideal para producción en cadena |
| Investigación técnica / Documentos de diseño / Arquitectura | Claude Sonnet 4.6 | Liderazgo claro con 73.7 vs 52.3 en conocimientos |
| Razonamiento matemático / Estilo de competición algorítmica | GLM-5.1 | 95.3 en AIME 2026 + 86.2 en GPQA-Diamond |
| Módulo de generación de código en SaaS orientado al cliente | Sonnet 4.6(principal) + GLM-5.1(respaldo) | Sonnet como principal, GLM como respaldo; reduce costos y asegura calidad |
| Despliegue privado / Cumplimiento en red interna | GLM-5.1 | Licencia MIT + posibilidad de autoalojamiento |
| Interacción de codificación en chino | GLM-5.1 | El modelo nacional es más amigable con la indicación en chino |
| Razonamiento complejo único + invocación de herramientas de cadena larga | Empate, requiere prueba propia | Ambos funcionan, la diferencia es menor al 5% |
Estrategia híbrida recomendada
Para la gran mayoría de los equipos medianos, recomendamos una estrategia de "principal y respaldo" en lugar de elegir solo uno:
- Modelo principal: Elige uno según tu escenario de negocio más frecuente (GLM-5.1 para corrección de código, Sonnet 4.6 para integración en IDE);
- Modelo de respaldo: Configura el otro para realizar validaciones A/B y cambios graduales en negocios críticos;
- Capa de acceso unificada: Utiliza APIYI (apiyi.com) para invocar a ambos con la misma clave API. El código de negocio solo necesita cambiar el campo
model, sin necesidad de mantener dos lógicas de autenticación; - Monitoreo de costos: Observa las facturas de ambos modelos por separado en el panel de control de APIYI para determinar periódicamente cuál ofrece una mejor "relación calidad-precio" en tu negocio y ajusta el tráfico dinámicamente.
🎯 Consejo para implementar la estrategia híbrida: En APIYI (apiyi.com), puedes alternar sin problemas entre GLM-5.1 y Claude Sonnet 4.6 usando la misma clave API; el código de negocio solo requiere modificar una cadena de texto. Sugerimos dirigir el 70% del tráfico de "generación de código no crítico" a GLM-5.1 y reservar el 30% del tráfico de "cara al cliente + razonamiento de alta dificultad" para Sonnet 4.6. Así, disfrutarás de la ventaja de precio de GLM-5.1 y garantizarás la estabilidad en escenarios críticos.
title: "GLM-5.1 vs Claude Sonnet 4.6: Preguntas frecuentes (FAQ)"
description: "Comparamos GLM-5.1 y Claude Sonnet 4.6: rendimiento en código, costes, ventana de contexto y cómo integrarlos fácilmente con APIYI."
FAQ: GLM-5.1 vs Claude Sonnet 4.6
Q1: ¿Realmente GLM-5.1 supera a Claude Sonnet 4.6 en programación?
En parte sí, pero en otros aspectos sigue por detrás. En SWE-Bench Pro (la prueba más difícil de reparación de código en entornos industriales reales), GLM-5.1 alcanzó una puntuación de 58.4, situándose como el número uno mundial. Esto supera al 57.3 de Claude Opus 4.6 y al 57.7 de GPT-5.4, y por supuesto, al Sonnet 4.6. Sin embargo, en SWE-bench Verified (reparación de código estandarizada), Sonnet 4.6 sigue liderando con un 79.6% frente al 77.8% de GLM-5.1, una diferencia de 1.8 puntos porcentuales. Además, en la puntuación media de codificación integral de BenchLM, Sonnet 4.6 obtiene 66.4 puntos frente a los 58.4 de GLM-5.1. Conclusión: GLM-5.1 supera a Sonnet 4.6 en los retos de mayor dificultad, pero sigue por detrás en cuanto a equilibrio y versatilidad.
Q2: ¿Cuánto más barato es GLM-5.1 que Claude Sonnet 4.6?
Según los precios oficiales de Z.ai, GLM-5.1 cuesta $1.00 por entrada / $3.20 por salida, mientras que Claude Sonnet 4.6 cuesta $3.00 / $15.00. Esto significa que la entrada es 3 veces más barata y la salida es aproximadamente 4.7 veces más económica. En un escenario típico de "1000 invocaciones de Coding Agent al día + 5K de entrada / 20K de salida", la factura mensual de Sonnet 4.6 es aproximadamente 4.5 veces mayor que la de GLM-5.1. Si tu negocio tiene un volumen de salida significativamente mayor que el de entrada, la ventaja en relación calidad-precio de GLM-5.1 será mucho más notable.
Q3: ¿Cuál de los dos tiene una ventana de contexto mayor?
Claude Sonnet 4.6 es mayor. GLM-5.1 cuenta con 200K (algunas plataformas muestran 203K), mientras que Sonnet 4.6 ofrece de 200K a 1M de tokens (beta). Una ventana de 1M significa que Sonnet 4.6 puede leer un repositorio de código de tamaño medio de una sola vez, lo cual es su arma secreta para tareas de "refactorización de todo el repositorio / localización de errores entre archivos". Si tus tareas requieren contextos extremadamente largos, Sonnet 4.6 es la opción más segura.
Q4: Actualmente uso Claude Sonnet 4.6 en Cursor / Cline, ¿vale la pena cambiar a GLM-5.1?
Depende de tus prioridades. Si lo que más te preocupa es la factura, GLM-5.1 puede reducir tus costes a la mitad o incluso más, por lo que vale la pena el cambio. Si priorizas la estabilidad en tu experiencia de programación diaria, la tasa de preferencia del 70% de los usuarios de Sonnet 4.6 demuestra que ya está ampliamente validado en los flujos de trabajo de Claude Code, y el beneficio de la migración podría ser menor que el riesgo. La estrategia más prudente es usar APIYI (apiyi.com) para desviar el 20% del tráfico a GLM-5.1 y realizar una prueba A/B durante una semana antes de decidir si aumentar la proporción.
Q5: ¿Se pueden invocar tanto GLM-5.1 como Sonnet 4.6 a través de APIYI?
Sí, ambos están disponibles. APIYI (apiyi.com) admite los formatos nativos de OpenAI, Claude y Gemini. Solo necesitas cambiar el base_url del SDK de OpenAI a https://api.apiyi.com/v1 y alternar el model entre glm-5.1 y claude-sonnet-4-6 (o el ID correspondiente). Esto te permite ejecutar ambos modelos con el mismo código, lo que hace que realizar comparaciones horizontales sea extremadamente eficiente.
Q6: Como desarrollador independiente, ¿cuál debería elegir?
Si solo puedes elegir uno, mira tu flujo de trabajo: si te dedicas a Coding Agents / automatización de backend / generación masiva de código, elige GLM-5.1. Si te enfocas en programación interactiva dentro del IDE / refactorización de repositorios completos / generación de contenido orientado al cliente, elige Sonnet 4.6. Si no quieres tomar una decisión difícil, conectar ambos y gestionarlos de forma unificada a través de APIYI es la mejor práctica para los desarrolladores en 2026. Tu factura se optimizará automáticamente según la elección del modelo, sin quedar atado a un solo proveedor.
Resumen: Veredicto final sobre GLM-5.1 vs Claude Sonnet 4.6
Al combinar los 6 puntos de comparación, el veredicto final entre GLM-5.1 y Claude Sonnet 4.6 se puede resumir así: GLM-5.1 tiene una ventaja estructural en "reparación de código industrial de alta dificultad + precio + código abierto nacional + agentes de larga duración", mientras que Claude Sonnet 4.6 mantiene el liderazgo en "equilibrio general + profundidad de conocimiento + 1M de contexto + madurez en flujos de trabajo de IDE". No se trata de quién reemplaza a quién, sino de dos herramientas complementarias para diferentes escenarios de negocio.
Para los equipos de desarrollo en China continental a finales de 2026, la estrategia más inteligente no es elegir uno u otro, sino aplicar un "modelo mixto principal-secundario + capa de acceso unificada": deja que GLM-5.1 se encargue de las tareas sensibles al coste, la automatización de larga duración y el cumplimiento de privacidad, mientras que Sonnet 4.6 maneja el contenido orientado al usuario, contextos complejos y redacción técnica. Al utilizar un servicio proxy de API como APIYI para centralizar ambos bajo una misma clave API y ajustar dinámicamente el tráfico basándose en datos reales de costes, podrás reducir drásticamente tu factura mensual sin sacrificar la calidad.
🎯 Recomendación final: Tanto GLM-5.1 como Claude Sonnet 4.6 ya están disponibles en APIYI (apiyi.com). Te sugerimos crear una clave API en apiyi.com hoy mismo, cambiar el
base_urldel SDK de OpenAI ahttps://api.apiyi.com/v1, y ejecutar 5 tareas con GLM-5.1 y otras 5 con la misma indicación usando Sonnet 4.6 para verificar personalmente todas las conclusiones de este artículo. Ninguna evaluación sustituye a tu propia prueba, y estos 30 minutos de validación te darán una sensación real sobre los dos modelos de programación más potentes de 2026.
Autor: Equipo APIYI | Enfocados en la implementación de modelos de lenguaje grandes y la evaluación de herramientas de codificación. Para más comparativas y llamadas prácticas, visita APIYI en apiyi.com.