Im April 2026 waren die beiden am häufigsten diskutierten Codierungsmodelle in der Entwickler-Community auf dem chinesischen Festland GLM-5.1 und Claude Sonnet 4.6. Ersteres wurde gerade von Z.ai (ehemals Zhipu) unter der MIT-Lizenz als Open Source veröffentlicht und setzte sich mit 58,4 Punkten auf dem SWE-Bench Pro vor Claude Opus 4.6, GPT-5.4 und Gemini 3.1 Pro an die Spitze der weltweiten Open-Source-Coding-Rankings. Letzteres wird von Anthropic als „Flaggschiff-Niveau für Mittelklasse-Modelle“ bezeichnet; es erreichte 79,6 % im SWE-bench Verified, was fast den 80,8 % von Opus 4.6 entspricht, kostet jedoch nur einen Bruchteil und bietet erstmals für die Sonnet-Serie ein 1M-Token-Kontextfenster.
Die Frage lautet also: GLM-5.1 vs. Claude Sonnet 4.6 – wer ist in realen Programmierszenarien wirklich stärker? Das lässt sich nicht mit einem Satz beantworten. Die Stärken beider Modelle sind sehr unterschiedlich verteilt: GLM-5.1 hat Sonnet 4.6 beim Benchmark für „reale industrielle Code-Reparaturen“ überholt, während Sonnet in unabhängigen Gesamttests den Durchschnittswert wieder nach oben gezogen hat. Dieser Artikel analysiert die Unterschiede anhand von 6 Dimensionen (Code-Benchmarks, Wissen, Preis, Kontext, Agenten-Langzeitaufgaben, Ökosystem-Kompatibilität) und gibt klare Empfehlungen für die Modellauswahl je nach Geschäftsszenario.

GLM-5.1 vs. Claude Sonnet 4.6: Die wichtigsten Daten im Überblick
Bevor wir mit dem Vergleich beginnen, stellen wir die wichtigsten Fakten beider Modelle in einer Tabelle gegenüber. Alle Daten stammen aus öffentlichen Informationen von BenchLM, Z.ai, Anthropic und Drittanbieter-Bewertungsplattformen.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Hersteller | Z.ai (ehemals Zhipu AI) | Anthropic |
| Veröffentlichungsdatum | 07.04.2026 (Open Source) | Anfang 2026 |
| Architektur | 754B MoE / 40B aktiv | Nicht öffentlich (mittlere Sonnet-Klasse) |
| Open-Source-Lizenz | ✅ MIT | ❌ Proprietär |
| Kontextfenster | 200K (auf einigen Plattformen 203K) | 200K → 1M (Beta) |
| SWE-bench Verified | 77,8 % | 79,6 % |
| SWE-Bench Pro | 58,4 ⭐ (Open Source #1, übertrifft Opus 4.6) | Etwas niedriger als Opus 4.6 |
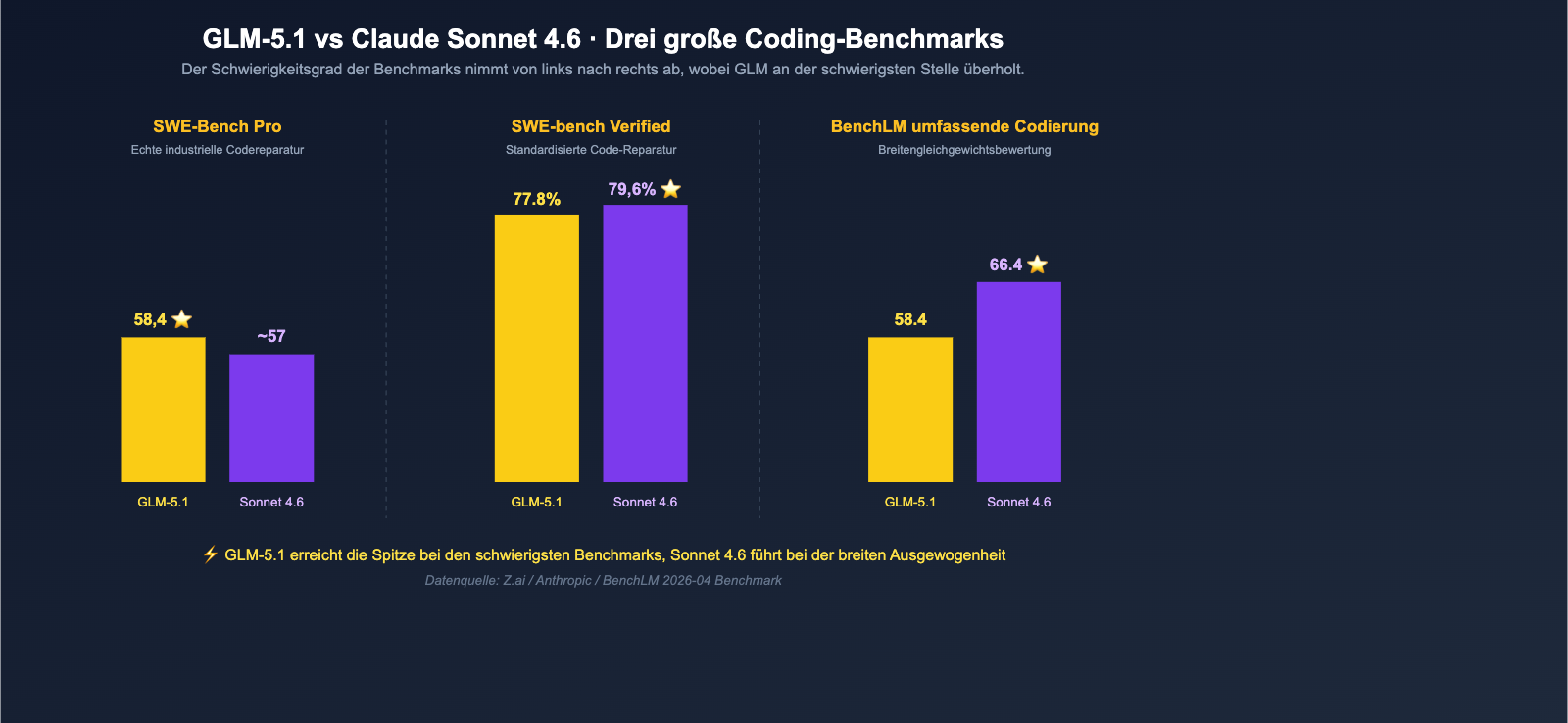
| BenchLM Coding-Durchschnitt | 58,4 | 66,4 |
| BenchLM Wissens-Durchschnitt | 52,3 | 73,7 |
| BenchLM Gesamtpunktzahl | 79 | 80 |
| Eingabepreis ($/M) | $1,00 (Z.ai direkt) | $3,00 |
| Ausgabepreis ($/M) | $3,20 (Z.ai direkt) | $15,00 |
| Agenten-Langzeitaufgaben | ca. 8 Stunden pro Aufgabe | 70 % Präferenzrate bei Claude Code-Nutzern |
| APIYI-Anbindung | ✅ Verfügbar https://api.apiyi.com/v1 |
✅ Verfügbar |
| Kompatible Tools | Claude Code / Cline / Cursor / OpenClaw | Wie links + natives Anthropic-Ökosystem |
🎯 Kurzempfehlung: Der Unterschied zwischen beiden ist nicht „wer ist besser“, sondern „in welchem Szenario sind sie stark“. Wenn Sie sofort einen direkten Vergleich durchführen möchten: APIYI (apiyi.com) hat sowohl GLM-5.1 als auch Claude Sonnet 4.6 integriert. Sie müssen lediglich das Feld
modelanpassen, um in Ihrem eigenen Geschäftscode zwischen beiden zu wechseln. Innerhalb von 15 Minuten erhalten Sie ein präziseres Urteil für Ihre spezifischen Aufgaben als durch jeden Benchmark.
Die Kernunterschiede zwischen GLM-5.1 und Claude Sonnet 4.6: Keine Modelle der gleichen Klasse
Das erste, was man klarstellen muss: GLM-5.1 und Claude Sonnet 4.6 gehören streng genommen nicht zur "gleichen Klasse" von Modellen, da ihre Designziele systematisch unterschiedlich sind.
Unterschiede in der Modellpositionierung
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Hersteller-Positionierung | "Open-Source-Vorreiter + Langstrecken-Agent-Codierung" | "Mittelklasse-Flaggschiff · Preis-Leistungs-Sieger" |
| Parameter-Größenordnung | Großes Sprachmodell (754B MoE) | Mittelgroßes Modell (Parameter nicht öffentlich) |
| Trainingsziel | Codierung + Agent + mathematische Schlussfolgerung | Allgemein + Codierung + Wissen + Sicherheit |
| Geschäftsmodell | MIT Open Source + Z.ai eigene API | Closed Source Abo + API |
| Hauptkonkurrenten | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
Beachten Sie diese Zeile – GLM-5.1 zielt in der internen Positionierung von Z.ai eigentlich auf Claude Opus 4.6 ab, nicht auf Sonnet 4.6. Das bedeutet, wenn man rein die "Obergrenze der Codierfähigkeit" vergleicht, sollte die Vergleichsgruppe für GLM-5.1 Opus sein, nicht Sonnet. Aber in den Punkten "Preis + Gesamtleistung + Praktikabilität" ist Sonnet 4.6 ein sehr starker Gegner im Mittelklassesegment, weshalb ein Vergleich beider Modelle einen sehr praktischen technischen Mehrwert bietet.
Status Quo bei unabhängigen Gesamtbewertungen
Laut der vorläufigen Rangliste von BenchLM vom April 2026:
- Gesamtpunktzahl: Claude Sonnet 4.6 = 80, GLM-5.1 = 79 (1 Punkt Differenz, nahezu gleichauf)
- Durchschnitt Codierung: Claude Sonnet 4.6 = 66,4, GLM-5.1 = 58,4 (Sonnet 4.6 führt mit 8 Punkten)
- Durchschnitt Wissen: Claude Sonnet 4.6 = 73,7, GLM-5.1 = 52,3 (Sonnet 4.6 führt mit 21,4 Punkten, größter Abstand)
Bei einem anderen spezialisierten Benchmark kehrt sich die Situation jedoch komplett um:
- SWE-Bench Pro (reale industrielle Code-Reparatur): GLM-5.1 = 58,4 ⭐, übertrifft damit Claude Opus 4.6 mit 57,3 und GPT-5.4 mit 57,7, Sonnet 4.6 liegt natürlich ebenfalls darunter.
- SWE-bench Verified: Claude Sonnet 4.6 = 79,6 %, GLM-5.1 = 77,8 %, nur 1,8 Prozentpunkte Differenz.
Wenn man diese Zahlen vergleicht, lässt sich die erste Schlussfolgerung ziehen: GLM-5.1 ist kein Monster, das "Sonnet 4.6 in allen Bereichen übertrifft", aber es hat bei der "schwierigsten industriellen Code-Reparatur" tatsächlich den ersten Platz belegt, während Sonnet 4.6 bei breiteren, umfassenden Codierungs-Benchmarks weiterhin ausgeglichen führt.
Dimension 1: Code-Benchmark-Vergleich — Der reale Unterschied zwischen GLM-5.1 und Sonnet 4.6
Die Codierfähigkeit ist der Kern dieses Vergleichs und der Teil, der durch Benchmark-Zahlen am leichtesten missverstanden werden kann. Wir fassen alle relevanten Benchmarks in einer Tabelle zusammen und interpretieren sie dann aus der Perspektive eines Ingenieurs.
Vollständiger Vergleich der Code-Benchmarks
| Benchmark | GLM-5.1 | Claude Sonnet 4.6 | Führend | Differenz |
|---|---|---|---|---|
| SWE-Bench Pro | 58,4 | < 57,3 | GLM-5.1 | ~1+ Punkt |
| SWE-bench Verified | 77,8 % | 79,6 % | Sonnet 4.6 | 1,8 % |
| BenchLM Codierung Ø | 58,4 | 66,4 | Sonnet 4.6 | 8 Punkte |
| OSWorld (Agenten-Desktop) | Nicht öffentlich | 72,5 % | Sonnet 4.6 | — |
| Claude Code Nutzerpräferenz | Nicht teilgenommen | 70 % (vs. Sonnet 4.5), 59 % (vs. Opus 4.5) | Sonnet 4.6 | — |
| 8-Stunden-Langstreckenaufgabe | ✅ Offizielles Hauptmerkmal | Unterstützt Claude Code Langstrecke | Nahezu gleichauf | — |
Interpretation aus technischer Sicht
Nachdem man diese Tabelle dreimal gelesen hat, lassen sich einige Schlussfolgerungen ziehen, die auch für Nicht-Benchmark-Enthusiasten verständlich sind:
- Wenn Ihre Arbeit darin besteht, "echte Bugs in echten Repositories zu beheben": GLM-5.1 belegt bei SWE-Bench Pro den ersten Platz. Dies ist ein Benchmark, der "sehr nah am Alltag eines Ingenieurs" liegt und bedeutet, dass GLM-5.1 am besten als Kern-Engine für einen Coding-Agenten geeignet ist.
- Wenn Ihre Arbeit "standardisierte Code-Reparaturen + allgemeine Programmierung" umfasst: Sonnet 4.6 schneidet bei SWE-bench Verified etwas besser ab und führt bei der BenchLM-Gesamtbewertung deutlich; es ist in der "Breite" stabiler.
- Wenn Ihre Arbeit Langstreckenaufgaben in Claude Code / Cursor umfasst: Die Nutzerpräferenz von 70 % für Sonnet 4.6 zeigt, dass es sich im "tatsächlichen Entwicklungsfluss" bewährt hat. Die 8-Stunden-Langstreckenfähigkeit von GLM-5.1 ist ein Hauptverkaufsargument von Z.ai, muss aber von Ihnen selbst getestet werden, um die Wirkung zu bestätigen.
- Wenn Ihre Arbeit "wissensintensive Fragen" beinhaltet (Dokumentation lesen, Design schreiben, technische Recherche): Der Unterschied von 73,7 (Sonnet 4.6) zu 52,3 (GLM-5.1) ist sehr deutlich.
Warum gibt es diese "widersprüchlichen Benchmarks"?
Viele Leser fragen: Warum sagt ein Benchmark, GLM-5.1 sei stärker, und ein anderer, Sonnet 4.6 sei besser? Die Antwort liegt in den Unterschieden im Benchmark-Design:
- SWE-Bench Pro konzentriert sich auf "extrem schwierige, reale industrielle Code-Reparaturen", hat hohe Qualitätsanforderungen und eine geringe Anzahl an Aufgaben. Es stellt extreme Anforderungen an die 'Langstrecken-Schlussfolgerung + Werkzeugnutzung' des Modells – genau das, worauf GLM-5.1 spezialisiert ist.
- SWE-bench Verified ist eine "von Menschen verifizierte Sammlung von Standard-Code-Reparaturaufgaben", die eher dem "Durchschnittsniveau des täglichen Entwicklungsalltags" entspricht. Es stellt höhere Anforderungen an die 'Breite + Stabilität' des Modells – das ist die Stärke von Sonnet 4.6.
- BenchLM Codierung Ø bildet den gewichteten Durchschnitt mehrerer Benchmarks und ist freundlicher gegenüber mittelgroßen Flaggschiffen, die 'alle Arten von Aufgaben bewältigen können'.
Wenn Sie diesen Unterschied verstehen, werden Sie nicht mehr von einer isolierten Zahl in die Irre geführt.
🎯 Empfehlung zur Benchmark-Auswahl: Verlassen Sie sich nicht auf einen einzigen Benchmark. Das pragmatischste Vorgehen ist: Stellen Sie die 5-10 häufigsten echten Codieraufgaben Ihres Teams als internes Benchmark-Set zusammen und rufen Sie diese über den API-Proxy-Dienst APIYI (apiyi.com) sowohl mit GLM-5.1 als auch mit Claude Sonnet 4.6 ab. Validieren Sie mit Ihren eigenen Daten, welches Modell besser zu Ihrem Geschäftsstil passt.
Dimension 2: Wissen und Schlussfolgerung — Der klare Vorteil von Sonnet 4.6
Während das Coding-Niveau ein „Kopf-an-Kopf-Rennen“ ist, zeigt sich bei Wissen / Schlussfolgerung / allgemeinem Verständnis ein deutlicher Vorsprung von Sonnet 4.6.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 | Differenz |
|---|---|---|---|
| BenchLM Wissensdurchschnitt | 52,3 | 73,7 | 21,4 Punkte |
| Verständnis langer Dokumente | Stark | Stärker (mit 1M Kontextfenster) | |
| Natürlichsprachliches Schreiben | Chinesisch exzellent | Multilingual ausgewogen | |
| Sicherheit & Compliance-Logik | Mittel | Deutlich stärker (Anthropic-Stärke) |
Das bedeutet, dass Sonnet 4.6 in folgenden Szenarien die sicherere Wahl ist:
- Erstellung von technischen Forschungsberichten / Designdokumenten / Architekturplänen;
- Sprachübergreifende Dokumentenzusammenfassung und Compliance-Analyse;
- Hybride Aufgaben, die „sowohl Code- als auch Geschäftsverständnis“ erfordern;
- Content-Generierung im direkten Kundenkontakt, die strengere Sicherheitsleitplanken erfordert.
Die relative Schwäche von GLM-5.1 bei der Wissensdimension liegt nicht an einer „mangelhaften Schulung“, sondern daran, dass die Trainingsdaten stärker auf Coding + Mathematik + Werkzeugnutzung ausgerichtet sind und im Bereich „Allgemeinwissen“ nicht so ausgewogen sind wie bei Sonnet 4.6.
Dimension 3: Preisvergleich — Das Ass im Ärmel von GLM-5.1
Wenn man nur einen Faktor betrachtet, ist der Preis die schärfste Waffe von GLM-5.1 im Vergleich zu Sonnet 4.6.
Direkter Vergleich der Token-Preise
| Dimension | GLM-5.1 (Z.ai Direktbezug) | Claude Sonnet 4.6 | GLM-5.1 Preis-Leistungs-Vorteil |
|---|---|---|---|
| Input ($/M) | $1,00 | $3,00 | 3-mal günstiger |
| Output ($/M) | $3,20 | $15,00 | ~4,7-mal günstiger |
| Gesamt (2:1 Verhältnis) | ~$1,73 | ~$7,00 | ~4-mal günstiger |
Ein paar Dinge sind zu beachten:
- Die von Drittplattformen (wie BenchLM) statistisch erfassten Preise für GLM-5.1 sind etwas höher ($1,40 Input / $4,40 Output), da sie einen Wiederverkaufsaufschlag enthalten. Die offiziellen Direktbezugspreise von Z.ai liegen bei $1,00 / $3,20;
- Die $3 / $15 für Sonnet 4.6 sind die offiziellen Preise von Anthropic. Dies ist bereits 5-mal günstiger als Opus 4.6 und gilt im Mittelklasse-Segment bereits als „Preis-Leistungs-König“;
- Dennoch bleibt der Vorteil von GLM-5.1 bei den Output-Token mit dem Faktor 4-5 bestehen, was für Coding-Szenarien, bei denen die Ausgabemenge größer als die Eingabemenge ist, von enormer Bedeutung ist.
Beispiel für reale Kosten
Um den Unterschied zu verdeutlichen, nehmen wir eine typische Aufgabe eines „Coding-Agenten“ an: 5K Token Input, 20K Token Output, 1000 Aufrufe pro Tag.
| Modell | Input-Kosten/Tag | Output-Kosten/Tag | Gesamt/Tag | Gesamt/Monat |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2.070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9.450 |
Differenz: Die monatlichen Kosten für Sonnet 4.6 sind etwa 4,5-mal so hoch wie bei GLM-5.1.
Für ein mittelständisches SaaS-Unternehmen mit „1000 Agent-Aufrufen pro Tag“ bedeutet das eine Differenz von fast 7000 US-Dollar pro Monat allein bei den Token-Kosten – genug Geld, um einen halben zusätzlichen Ingenieur einzustellen.
🎯 Empfehlung zur Kostenoptimierung: Für Teams, die bereits Claude Sonnet 4.6 nutzen, empfehlen wir, zunächst 20 % des Traffics über APIYI (apiyi.com) auf GLM-5.1 für A/B-Tests umzuleiten. Wenn die Ergebnisse akzeptabel sind, können „nicht-kritische Coding-Aufgaben“ vollständig auf GLM-5.1 migriert werden, während nur „kritische Aufrufe mit Kundenkontakt“ bei Sonnet 4.6 verbleiben. So lässt sich die Rechnung erheblich senken, ohne die Gesamtqualität zu beeinträchtigen.
Dimension 4: Kontextfenster — Der Gegenschlag von Sonnet 4.6
Beim Preis hat GLM-5.1 klar die Nase vorn, doch beim Thema Kontextfenster hat Sonnet 4.6 das Ruder wieder in die Hand genommen.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Standard-Kontext | 200K (auf manchen Plattformen 203K) | 200K |
| Beta-Kontext | — | 1M Token (Beta) |
| Maximale Ausgabe | 128K | Niedriger |
| Kontextkomprimierung | Nein | ✅ Automatische Komprimierung alter Kontexte |
1M Token sind das Markenzeichen des Upgrades von Sonnet 4.6 – das bedeutet, Sie können ein komplettes mittelgroßes Code-Repository auf einmal in die Eingabeaufforderung laden, ohne auf RAG-Abfragen angewiesen zu sein. Für Aufgaben wie "Refactoring des gesamten Repositorys / Bug-Lokalisierung über Dateien hinweg / Verständnis der gesamten Codebasis" ist Sonnet 4.6 im April 2026 nahezu unersetzlich.
Die 200K von GLM-5.1 reichen zwar für 90 % der täglichen Szenarien aus, aber bei extremen Anforderungen an ein "überlanges Kontextfenster" liegt das Modell ein Stück zurück.
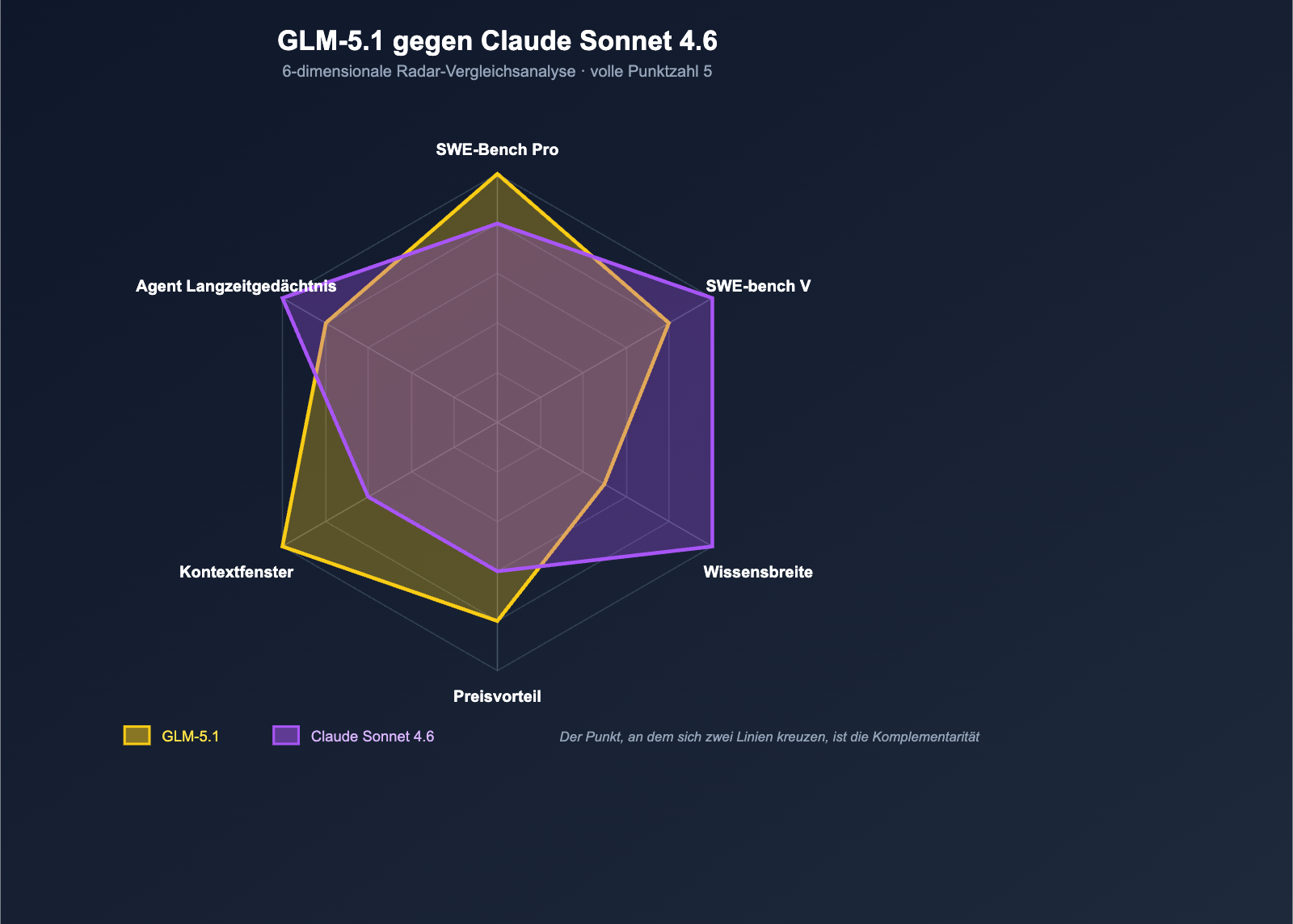
Dimension 5: Langzeitaufgaben für Agenten — Das Duell der Strategien
Die fünfte Dimension ist die Fähigkeit zur Bewältigung von Langzeitaufgaben durch Agenten – ein Bereich, in dem sich 2026 alle führenden Programmiermodelle messen.
Unterschiedliche Ansätze für "Langzeitaufgaben"
- GLM-5.1: Z.ai setzt auf "8 Stunden kontinuierliche Arbeit an einer Einzelaufgabe" und betont den End-to-End-Zyklus aus Planung → Ausführung → Test → Reparatur → Optimierung. Dies basiert auf der logischen Tiefe des Modells und der Stabilität beim Aufruf von Werkzeugen.
- Claude Sonnet 4.6: Anthropic setzt auf die "Claude Code Praxiserfahrung". 70 % der Nutzer von Sonnet 4.5 bevorzugten in internen Tests Sonnet 4.6, was auf den technisch ausgereiften Claude Code-Workflow + 1M Kontext + Kontextkomprimierung zurückzuführen ist.
Zusammenfassend lässt sich sagen:
| Ansatz | Kernvorteil | Geeignete Szenarien |
|---|---|---|
| GLM-5.1 | Logische Tiefe + Stabilität bei Werkzeugaufrufen | Hintergrund-Automatisierungs-Agenten / unbeaufsichtigte Aufgaben |
| Sonnet 4.6 | Claude Code-Workflow + 1M Kontext | Interaktive Programmierung für Entwickler / IDE-Integration |
Wenn Sie Szenarien haben, in denen "Agenten im Hintergrund selbstständig Funktionen entwickeln" (unbeaufsichtigt), ist die 8-Stunden-Langzeitfähigkeit von GLM-5.1 ideal. Wenn Sie hingegen als "Entwickler in einer IDE mit dem Modell chatten, um Code zu schreiben", ist die Claude Code-Integrationserfahrung von Sonnet 4.6 ausgereifter.
Dimension 6: Ökosystem-Kompatibilität — Der Toolchain-Vorteil von Sonnet 4.6
Die letzte Dimension ist das Ökosystem. Hier liegt Sonnet 4.6 nach wie vor deutlich vorn, aber GLM-5.1 holt rasant auf.
| Dimension | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Claude Code Kompatibilität | ✅ (OpenAI-kompatibler Einstieg) | ✅ Nativ |
| Cline / Cursor | ✅ (OpenAI-kompatibler Einstieg) | ✅ Nativ |
| OpenClaw | ✅ | ✅ |
| Anthropic Tool-Aufruf | OpenAI-Stil | ✅ Nativ |
| Drittanbieter-Agent-Frameworks | Die meisten unterstützen OpenAI-Kompatibilität | Die meisten unterstützen Anthropic nativ |
| Bereitstellungsflexibilität | ✅ MIT selbst gehostet / APIYI / Z.ai Eigenbetrieb | APIYI / Anthropic offiziell |
Es ist erwähnenswert, dass APIYI (apiyi.com) gleichzeitig die drei nativen Formate OpenAI / Claude Native / Gemini Native unterstützt. Das bedeutet, dass Sie GLM-5.1 und Sonnet 4.6 mit demselben API-Schlüssel aufrufen können, unabhängig davon, welchen SDK-Stil Sie bevorzugen. Ein äußerst praktisches Detail im direkten Vergleich: Sie müssen während der Testphase nicht zwei Sätze an Authentifizierungen, Monitoring-Systemen oder Abrechnungen verwalten.
Empfehlungen zur Modellauswahl nach Szenario
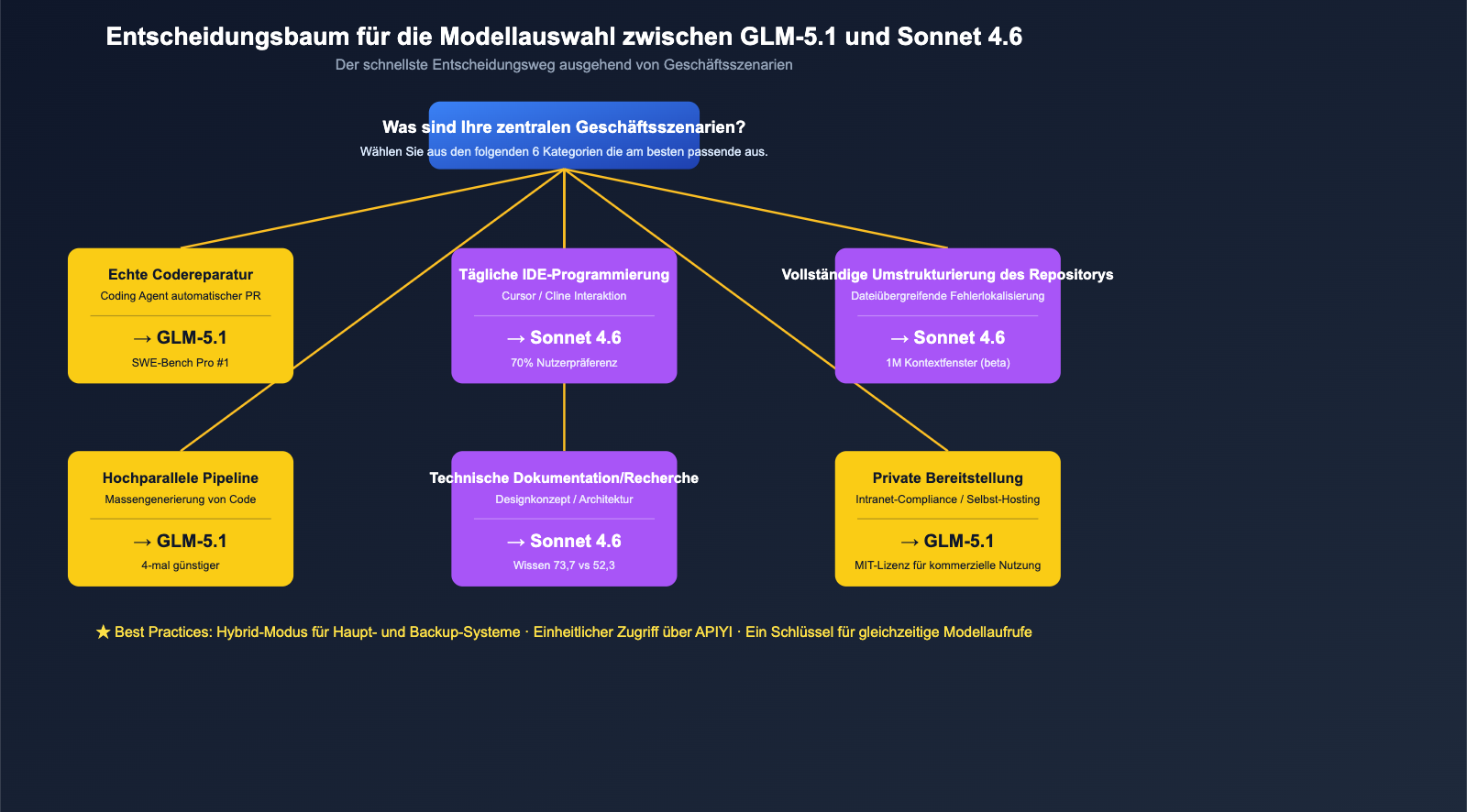
Wenn wir alle 6 Dimensionen zusammenführen, können wir sehr konkrete Empfehlungen für die Modellauswahl je nach Geschäftsszenario geben.
Szenario-Vergleichstabelle
| Geschäftsszenario | Empfohlenes Modell | Hauptgrund |
|---|---|---|
| Echte industrielle Code-Reparatur (Agent-gestützte PRs) | GLM-5.1 | SWE-Bench Pro weltweit Platz 1 + 8 Stunden Kontext |
| Tägliche IDE-Programmierung (Cursor / Cline) | Claude Sonnet 4.6 | 70 % Nutzerpräferenz bei Claude Code, ausgereifter Workflow |
| Refactoring ganzer Repositories / Bug-Lokalisierung | Claude Sonnet 4.6 | 1M Kontextfenster (Beta) als Kernvorteil |
| Standardisierte Codegenerierung + hohe Last | GLM-5.1 | 4x günstiger, ideal für die Fließbandproduktion |
| Technische Recherche / Design-Dokumente / Architektur | Claude Sonnet 4.6 | Wissensvorsprung (73,7 vs. 52,3) |
| Mathematische Schlussfolgerungen / Algorithmen-Wettbewerbe | GLM-5.1 | AIME 2026 95,3 + GPQA-Diamond 86,2 |
| Codegenerierungs-Modul in Kunden-SaaS | Sonnet 4.6(Haupt) + GLM-5.1(Backup) | Sonnet als Hauptmodell, GLM als Fallback für Kosten/Qualität |
| Private Bereitstellung / Intranet-Compliance | GLM-5.1 | MIT-Lizenz + selbst hostbar |
| Chinesische Coding-Interaktion | GLM-5.1 | Lokale Modelle sind bei chinesischen Eingabeaufforderungen besser |
| Einmalige, hochkomplexe Schlussfolgerungen | Unentschieden, selbst testen | Beide performant, Unterschiede unter 5 % |
Empfohlene Hybrid-Strategie
Für die meisten mittelgroßen Teams empfehlen wir eher eine "Haupt-Backup-Hybridstrategie" als eine "Entweder-oder"-Entscheidung:
- Hauptmodell: Wählen Sie eines basierend auf Ihrem primären Szenario (GLM-5.1 für Code-Reparaturen, Sonnet 4.6 für IDE-Integration).
- Backup-Modell: Binden Sie das andere Modell für A/B-Tests und schrittweise Migrationen ein.
- Einheitliche Schnittstelle: Nutzen Sie APIYI (apiyi.com) mit einem einzigen API-Schlüssel für beide Modelle. Ihr Code muss nur das Feld
modelanpassen, ohne zwei Authentifizierungslogiken zu pflegen. - Kosten-Monitoring: Überwachen Sie die Abrechnungen beider Modelle im APIYI-Dashboard, um regelmäßig zu entscheiden, welches Modell ein besseres Preis-Leistungs-Verhältnis bietet, und passen Sie die Traffic-Verteilung dynamisch an.
🎯 Umsetzung der Hybrid-Strategie: Über APIYI (apiyi.com) können Sie nahtlos zwischen GLM-5.1 und Claude Sonnet 4.6 wechseln, indem Sie lediglich einen String in Ihrem Code ändern. Wir empfehlen, 70 % des Traffics für "nicht-kritische Codegenerierung" auf GLM-5.1 zu legen und 30 % für "kundenorientierte Aufgaben + komplexe Schlussfolgerungen" bei Sonnet 4.6 zu belassen. So profitieren Sie von den Preisvorteilen von GLM-5.1 und sichern gleichzeitig die Stabilität in kritischen Szenarien.
GLM-5.1 vs. Claude Sonnet 4.6: Häufig gestellte Fragen (FAQ)
F1: Übertrifft GLM-5.1 wirklich Claude Sonnet 4.6 beim Programmieren?
Teilweise ja, teilweise liegt es noch zurück. Beim SWE-Bench Pro (reale industrielle Fehlerbehebung), einem der anspruchsvollsten Benchmarks, erreichte GLM-5.1 mit 58,4 Punkten den weltweiten Spitzenplatz und übertrifft damit Claude Opus 4.6 (57,3) sowie GPT-5.4 (57,7) und natürlich auch Sonnet 4.6. Beim SWE-bench Verified (standardisierte Fehlerbehebung) liegt Sonnet 4.6 mit 79,6 % jedoch weiterhin etwa 1,8 Prozentpunkte vor den 77,8 % von GLM-5.1. Beim BenchLM-Gesamt-Coding-Score führt Sonnet 4.6 mit 66,4 Punkten ebenfalls mit etwa 8 Punkten Vorsprung vor GLM-5.1 (58,4). Fazit: GLM-5.1 übertrifft Sonnet 4.6 bei "extrem schwierigen Aufgaben", liegt aber bei der "breiten Ausgewogenheit" noch zurück.
F2: Wie viel günstiger ist GLM-5.1 im Vergleich zu Claude Sonnet 4.6?
Basierend auf den offiziellen Z.ai-Preisen kostet GLM-5.1 $1,00 für Input / $3,20 für Output, während Claude Sonnet 4.6 bei $3,00 / $15,00 liegt – der Input ist also 3-mal günstiger, der Output etwa 4,7-mal. In einem typischen Szenario mit "1000 Coding-Agent-Aufrufen pro Tag + 5K Input / 20K Output" ist die monatliche Rechnung für Sonnet 4.6 etwa 4,5-mal so hoch wie für GLM-5.1. Wenn Ihr Geschäft "deutlich mehr Output als Input" erzeugt, ist der Kostenvorteil von GLM-5.1 noch deutlicher.
F3: Welches Modell hat das größere Kontextfenster?
Claude Sonnet 4.6 ist größer. GLM-5.1 bietet 200K (auf einigen Plattformen als 203K angezeigt), während Sonnet 4.6 von 200K auf 1M Token (Beta) skaliert. Ein 1M-Kontextfenster bedeutet, dass Sonnet 4.6 ein mittelgroßes Code-Repository auf einmal erfassen kann – das ist seine Kernstärke bei Aufgaben wie "Repository-weites Refactoring / Bug-Lokalisierung über Dateien hinweg". Wenn Sie zwingend auf extrem lange Kontexte angewiesen sind, ist Sonnet 4.6 die sicherere Wahl.
F4: Ich nutze aktuell Claude Sonnet 4.6 mit Cursor / Cline – lohnt sich der Wechsel zu GLM-5.1?
Das hängt von Ihren Prioritäten ab. Wenn Sie primär auf die "Kosten" achten, kann GLM-5.1 Ihre Rechnung halbieren oder sogar noch stärker senken – ein Wechsel lohnt sich. Wenn Ihnen die "Stabilität im täglichen Coding-Workflow" am wichtigsten ist, zeigt die 70%ige Nutzerpräferenz für Sonnet 4.6, dass es sich im Claude-Code-Workflow bereits bewährt hat; das Migrationsrisiko könnte hier den Nutzen überwiegen. Der sicherste Weg: Nutzen Sie APIYI (apiyi.com), um 20 % Ihres Traffics für einen A/B-Test auf GLM-5.1 umzuleiten und entscheiden Sie nach einer Woche.
F5: Können beide Modelle über APIYI aufgerufen werden?
Ja, beide sind verfügbar. APIYI (apiyi.com) unterstützt gleichzeitig die nativen Formate von OpenAI, Claude und Gemini. Sie müssen lediglich die base_url Ihres OpenAI-SDKs auf https://api.apiyi.com/v1 ändern und das model zwischen glm-5.1 und claude-sonnet-4-6 (oder einer ähnlichen ID) wechseln. So können Sie beide Modelle im selben Code ausführen und sehr effizient direkte Vergleiche anstellen.
F6: Welches Modell sollte ich als unabhängiger Entwickler wählen?
Wenn Sie sich für eines entscheiden müssen, schauen Sie auf Ihren Workflow: Für Coding-Agenten / Backend-Automatisierung / massenhafte Code-Generierung → wählen Sie GLM-5.1; für interaktive Programmierung in der IDE / Repository-weites Refactoring / kundenorientierte Inhalte → wählen Sie Sonnet 4.6. Wenn Sie sich nicht festlegen wollen, ist die Anbindung beider Modelle über APIYI die Best Practice für Entwickler im Jahr 2026 – Ihre Kosten optimieren sich automatisch mit der Modellwahl, ohne dass Sie an einen einzigen Anbieter gebunden sind.
Zusammenfassung: Das finale Urteil zu GLM-5.1 vs. Claude Sonnet 4.6
Zusammenfassend lässt sich sagen: GLM-5.1 hat strukturelle Vorteile bei "hochkomplexer industrieller Fehlerbehebung, Preis, lokaler Open-Source-Verfügbarkeit und Langzeit-Agenten", während Claude Sonnet 4.6 bei "breiter Ausgewogenheit, Wissenstiefe, 1M-Kontext und IDE-Workflow-Reife" führt. Die Modelle ersetzen sich nicht gegenseitig, sondern ergänzen sich für unterschiedliche Geschäftsszenarien.
Für Entwicklungsteams in Festlandchina ist die klügste Strategie im Jahr 2026 nicht "entweder oder", sondern "Hybrid-Ansatz + einheitliche API-Schicht": Nutzen Sie GLM-5.1 für kostenintensive, automatisierte und datenschutzrelevante Aufgaben und Sonnet 4.6 für kundenorientierte, kontextintensive und technische Schreibaufgaben. Durch die Bündelung über APIYI unter einem einzigen API-Schlüssel können Sie die monatlichen Kosten bei gleichbleibender Qualität drastisch senken.
🎯 Empfehlung: GLM-5.1 und Claude Sonnet 4.6 sind beide auf APIYI (apiyi.com) verfügbar. Wir empfehlen Ihnen, noch heute einen API-Schlüssel auf apiyi.com zu erstellen, die
base_urlIhres OpenAI-SDKs aufhttps://api.apiyi.com/v1zu setzen und 5 Aufgaben mit GLM-5.1 sowie dieselben 5 Aufgaben mit Sonnet 4.6 zu testen. Kein Benchmark ersetzt die eigene Erfahrung – dieser 30-minütige Test wird Ihnen ein echtes Gefühl für die beiden stärksten Coding-Modelle des Jahres 2026 vermitteln.
Autor: APIYI Team | Wir konzentrieren uns auf die Implementierung großer Sprachmodelle und die Evaluierung von Coding-Toolchains. Weitere Modellvergleiche und Praxisbeispiele finden Sie unter APIYI (apiyi.com).