2026 年 4 月,中国大陆开发者群里被问得最多的两款编码模型是 GLM-5.1 和 Claude Sonnet 4.6。前者刚刚由 Z.ai(原智谱)以 MIT 协议开源,在 SWE-Bench Pro 上以 58.4 分把 Claude Opus 4.6、GPT-5.4、Gemini 3.1 Pro 全部压在身后,瞬间登顶全球开源编码榜首;后者则被 Anthropic 称为"中端模型里的旗舰水平",SWE-bench Verified 拿到了 79.6%,接近 Opus 4.6 的 80.8%,价格却只有 Opus 的几分之一,并且首次给 Sonnet 系列开放了 1M token 上下文。
那么问题来了——GLM-5.1 vs Claude Sonnet 4.6,在真正的编程场景里,到底谁更强? 这不是一个能用一句话回答的问题。两者的强项分布得非常不一样:GLM-5.1 在"工业级真实代码修复"基准上已经反超 Sonnet 4.6,但在第三方综合评测里 Sonnet 又把整体平均分拉了回来。本文将围绕 6 个维度(代码基准、知识、价格、上下文、Agent 长程任务、生态兼容性) 逐一拆解两者的真实差异,并给出按业务场景的明确选型建议。

GLM-5.1 vs Claude Sonnet 4.6 核心数据一览
在动手对比之前,我们先把两者的关键事实并排放在一张表里。所有数据均来自 BenchLM、Z.ai、Anthropic 与第三方评测平台的公开信息。
| 维度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 厂商 | Z.ai(原智谱 AI) | Anthropic |
| 发布时间 | 2026-04-07(开源) | 2026 年初 |
| 架构 | 754B MoE / 40B 激活 | 不公开(中型 Sonnet 级别) |
| 开源协议 | ✅ MIT | ❌ 闭源 |
| 上下文窗口 | 200K(部分平台显示 203K) | 200K → 1M(beta) |
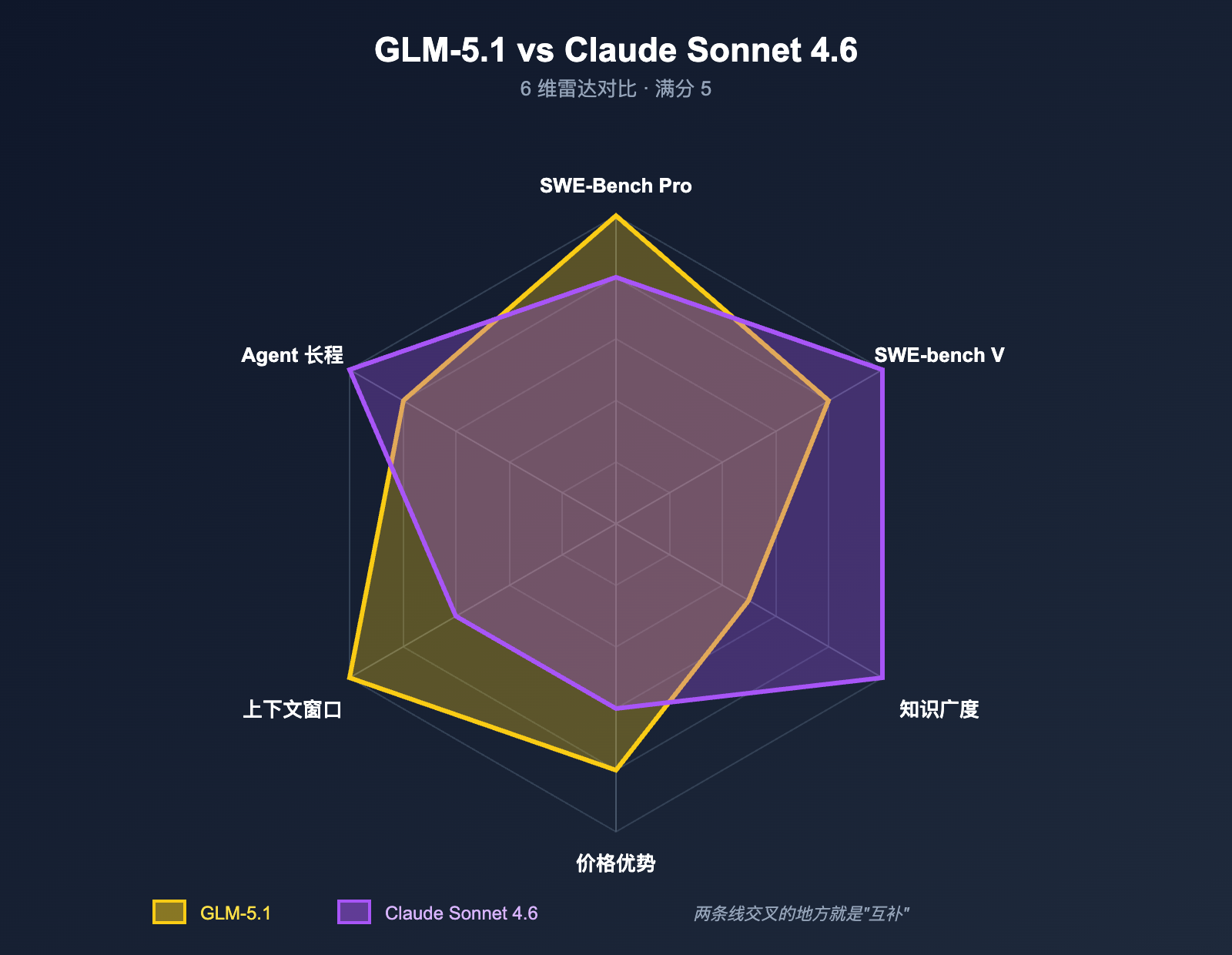
| SWE-bench Verified | 77.8% | 79.6% |
| SWE-Bench Pro | 58.4 ⭐(开源 #1,反超 Opus 4.6) | 略低于 Opus 4.6 |
| BenchLM 综合编码均分 | 58.4 | 66.4 |
| BenchLM 知识均分 | 52.3 | 73.7 |
| BenchLM 总分 | 79 | 80 |
| 输入价格 ($/M) | $1.00(Z.ai 直采) | $3.00 |
| 输出价格 ($/M) | $3.20(Z.ai 直采) | $15.00 |
| Agent 长程任务 | 单任务约 8 小时 | Claude Code 70% 用户偏好率 |
| 接入 API易 | ✅ 已上线 https://api.apiyi.com/v1 |
✅ 已上线 |
| 兼容工具 | Claude Code / Cline / Cursor / OpenClaw | 同上 + 原生 Anthropic 生态 |
🎯 快速判断建议:两者的差异不是"谁强谁弱",而是"在哪类场景下强"。如果你想立即跑横向对比,API易 apiyi.com 已经同时上线了 GLM-5.1 与 Claude Sonnet 4.6,只需要修改
model字段就能在同一份业务代码里切换两者,15 分钟之内就能在自己的真实任务上得出比任何评测都准确的判断。
GLM-5.1 vs Claude Sonnet 4.6 的核心差异:不是同一类模型
第一个必须先讲清楚的事实是——GLM-5.1 和 Claude Sonnet 4.6 严格来说不是"同一档"模型,它们的设计目标存在系统性差异。
模型定位差异
| 维度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 厂商定位 | "前沿开源 + 长程 Agent 编码" | "中端旗舰 · 性价比之王" |
| 参数量级 | 大模型(754B MoE) | 中型模型(参数未公开) |
| 训练目标 | 编码 + Agent + 数学推理 | 通用 + 编码 + 知识 + 安全 |
| 商业模式 | MIT 开源 + Z.ai 自营 API | 闭源订阅 + API |
| 主要竞争对手 | Claude Opus 4.6 / GPT-5.4 | Claude Opus 4.5 / GPT-5 / Sonnet 4.5 |
注意这一行——GLM-5.1 在 Z.ai 的内部定位里其实是冲着 Claude Opus 4.6 去的,而不是 Sonnet 4.6。 这意味着如果你单纯比"编码能力上限",GLM-5.1 的对照组应该是 Opus,不是 Sonnet。但在"价格 + 综合能力 + 实用性" 这三件事上,Sonnet 4.6 是中端市场里非常强的一个对手,因此把两者放在一起对比仍然有非常实际的工程价值。
第三方综合评测上的现状
根据 BenchLM 在 2026 年 4 月公布的临时排行榜:
- 总分:Claude Sonnet 4.6 = 80,GLM-5.1 = 79(差 1 分,接近持平)
- 编码均分:Claude Sonnet 4.6 = 66.4,GLM-5.1 = 58.4(Sonnet 4.6 领先 8 分)
- 知识均分:Claude Sonnet 4.6 = 73.7,GLM-5.1 = 52.3(Sonnet 4.6 领先 21.4 分,差距最大)
但在另外一项专项基准上,情况完全反转:
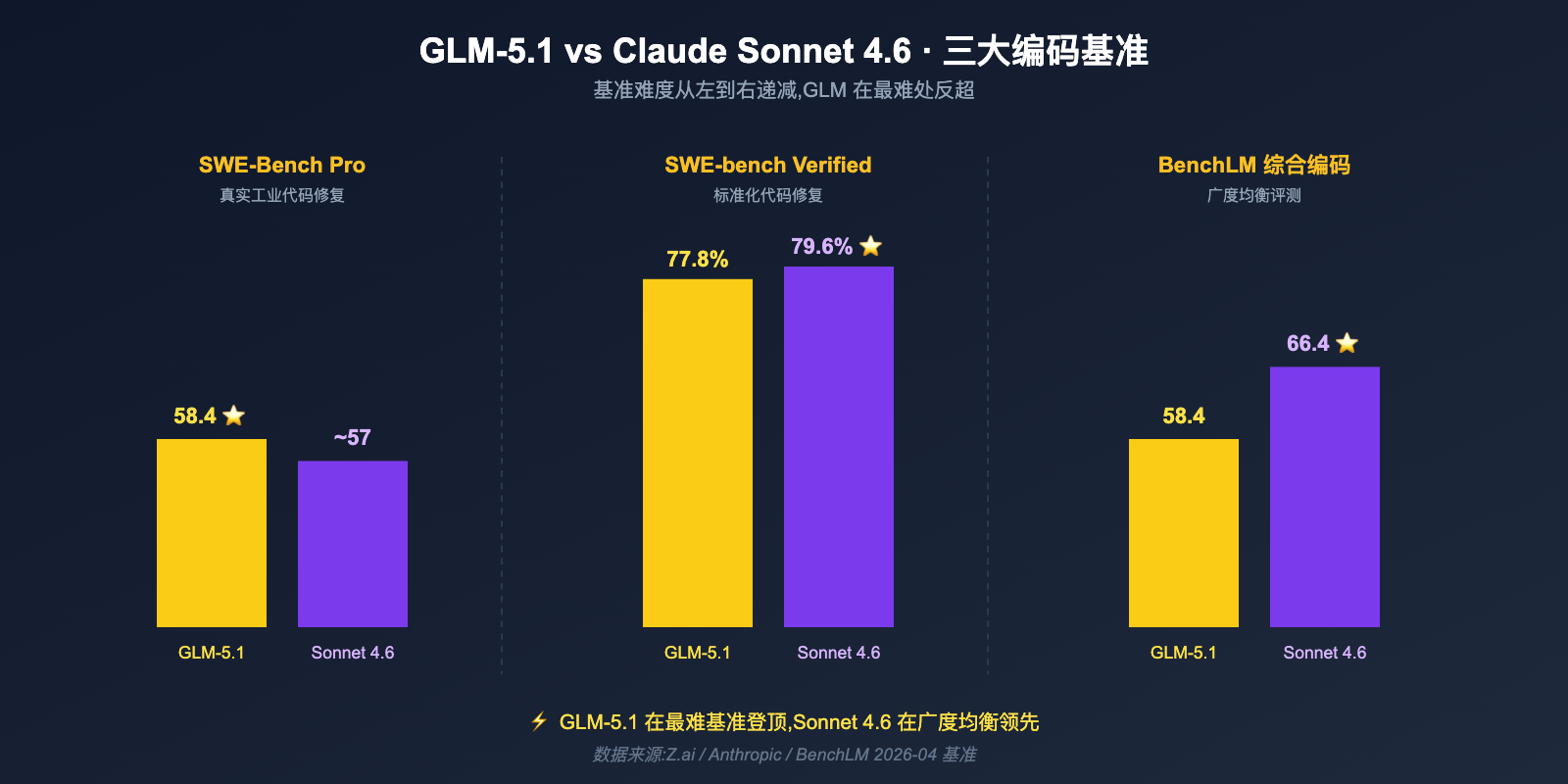
- SWE-Bench Pro(真实工业代码修复):GLM-5.1 = 58.4 ⭐,反超 Claude Opus 4.6 的 57.3 与 GPT-5.4 的 57.7,Sonnet 4.6 自然也在其下
- SWE-bench Verified:Claude Sonnet 4.6 = 79.6%,GLM-5.1 = 77.8%,仅差 1.8 个百分点
把这几组数字对照看就能得出第一个结论:GLM-5.1 不是"全面超越 Sonnet 4.6"的怪兽,但在"难度最高的工业代码修复"这一项上确实拿到了第一名,而 Sonnet 4.6 在更广泛的综合编码评测里仍然保持均衡领先。
维度一:代码基准对比 — GLM-5.1 与 Sonnet 4.6 的真实差距
代码能力是这次对比的核心,也是最容易被基准数字误导的部分。我们把所有相关基准整合到一张表里,然后再做工程师视角的解读。
代码相关基准完整对照
| 基准 | GLM-5.1 | Claude Sonnet 4.6 | 领先方 | 差距 |
|---|---|---|---|---|
| SWE-Bench Pro | 58.4 | < 57.3 | GLM-5.1 | ~1+ 分 |
| SWE-bench Verified | 77.8% | 79.6% | Sonnet 4.6 | 1.8% |
| BenchLM 编码均分 | 58.4 | 66.4 | Sonnet 4.6 | 8 分 |
| OSWorld(智能体桌面) | 未公开同口径 | 72.5% | Sonnet 4.6 | — |
| Claude Code 用户偏好率 | 未参与 | 70%(对 Sonnet 4.5)、59%(对 Opus 4.5) | Sonnet 4.6 | — |
| 8 小时长程任务 | ✅ 官方主打 | 已支持 Claude Code 长程 | 接近持平 | — |
工程视角解读
把这张表读三遍之后,可以提炼出几条非工业基准爱好者也能听懂的结论:
- 如果你的工作是"修真实仓库的真实 bug":GLM-5.1 在 SWE-Bench Pro 上排第一,这是一个非常"贴近一线工程师日常"的基准,它意味着 GLM-5.1 最适合作为 Coding Agent 的核心引擎;
- 如果你的工作是"标准化的代码修复 + 通用编程":Sonnet 4.6 的 SWE-bench Verified 略高,且 BenchLM 综合编码均分明显领先,它在"广度"上更稳;
- 如果你的工作是 Claude Code / Cursor 内长程任务:Sonnet 4.6 的 70% 用户偏好率说明它在"实际开发流"里被验证过;GLM-5.1 的 8 小时长程能力是 Z.ai 主打卖点,但需要你自己跑过才能确认效果;
- 如果你的工作里包含"知识密集型问题"(查文档、写设计、做技术调研):Sonnet 4.6 的 73.7 vs GLM-5.1 的 52.3,差距非常明显。
为什么会出现这种"基准互相打架"的情况
很多读者会问:为什么同样是"编码能力",一个基准说 GLM-5.1 更强、另一个说 Sonnet 4.6 更强?答案在于基准设计的差异:
- SWE-Bench Pro 偏向"难度极高的真实工业代码修复",任务质量门槛高、数量少,对模型的'长程推理 + 工具调用'能力要求极致——这正是 GLM-5.1 主打的方向;
- SWE-bench Verified 是"经过人工验证的标准代码修复任务集",更接近"日常开发场景的平均水平",对模型的'广度 + 稳定性'要求更高——这是 Sonnet 4.6 的强项;
- BenchLM 综合编码均分 把多个基准做加权平均,对'各类任务都能应对'的中型旗舰更友好。
理解了这层差异,你就不会再被任何一个孤立的数字误导。
🎯 基准选型建议:不要只看一个基准下结论。最务实的做法是:把你团队最常见的 5-10 个真实编码任务整理成一个内部基准集,然后通过 API易 apiyi.com 同时调用 GLM-5.1 与 Claude Sonnet 4.6 各跑一遍,用你自己的数据反向验证哪一个更适合你的业务画风。
维度二:知识与推理 — Sonnet 4.6 的明显优势区
如果说代码层面是"互有胜负",那么在 知识 / 推理 / 通用理解 这一维度,Sonnet 4.6 的优势非常明显。
| 维度 | GLM-5.1 | Claude Sonnet 4.6 | 差距 |
|---|---|---|---|
| BenchLM 知识均分 | 52.3 | 73.7 | 21.4 分 |
| 长文档理解 | 强 | 更强(配合 1M 上下文) | |
| 自然语言写作 | 中文优秀 | 多语种均衡 | |
| 安全与合规推理 | 中等 | 明显更强(Anthropic 强项) |
这意味着在以下场景中,Sonnet 4.6 是更稳妥的选择:
- 写技术调研报告 / 设计文档 / 架构方案;
- 跨语言文档摘要、合规分析;
- 需要"既懂代码又懂业务"的混合任务;
- 客户面对面的内容生成,要求更稳的安全护栏。
GLM-5.1 在知识维度上的相对弱势并不是"训练不到位",而是它的训练数据与目标更倾向 Coding + 数学 + 工具使用,在"通识知识"这一项上相对没有 Sonnet 4.6 那么均衡。
维度三:价格对比 — GLM-5.1 的杀手锏
如果只看一项,价格是 GLM-5.1 对比 Sonnet 4.6 时最锐利的武器。
Token 单价直接对比
| 维度 | GLM-5.1(Z.ai 直采) | Claude Sonnet 4.6 | GLM-5.1 性价比优势 |
|---|---|---|---|
| 输入 ($/M) | $1.00 | $3.00 | 便宜 3 倍 |
| 输出 ($/M) | $3.20 | $15.00 | 便宜 ~4.7 倍 |
| 综合(2:1 比例) | ~$1.73 | ~$7.00 | 便宜 ~4 倍 |
注意几件事:
- 第三方平台(如 BenchLM)统计的 GLM-5.1 价格略高($1.40 输入 / $4.40 输出),包含了一定的转售加成,Z.ai 官方公布的直采价格是 $1.00 / $3.20;
- Sonnet 4.6 的 $3 / $15 是 Anthropic 官方价,已经比 Opus 4.6 便宜 5 倍,在中端市场已属"性价比之王";
- 即便如此,GLM-5.1 在输出 token 上的优势仍然在 4-5 倍,这对"输出量大于输入量"的代码生成场景来说意义巨大。
真实成本举例
为了让差距更直观,假设一个"日常 Coding Agent" 的典型任务:输入 5K token、输出 20K token,日均 1000 次调用。
| 模型 | 输入成本/天 | 输出成本/天 | 合计/天 | 合计/月 |
|---|---|---|---|---|
| GLM-5.1 | $5 | $64 | $69 | ~$2,070 |
| Claude Sonnet 4.6 | $15 | $300 | $315 | ~$9,450 |
差距:Sonnet 4.6 月成本约为 GLM-5.1 的 4.5 倍。
对一个"日均 1000 次 Agent 调用"的中型 SaaS 来说,仅 Token 成本一项就能差出近 7000 美元/月——这笔钱足够再雇半个工程师。
🎯 成本优化建议:对于已经在使用 Claude Sonnet 4.6 的团队,我们建议先在 API易 apiyi.com 上把 20% 流量 切到 GLM-5.1 做 A/B,如果效果可接受,就把"非关键业务的代码生成"全部迁到 GLM-5.1,只保留"客户面对面"的关键调用走 Sonnet 4.6——这样能在不损失整体质量的前提下把账单砍掉一大截。
维度四:上下文窗口 — Sonnet 4.6 的反击
价格上 GLM-5.1 完胜,但上下文窗口这一项,Sonnet 4.6 反过来掌握了主动权。
| 维度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| 标准上下文 | 200K(部分平台 203K) | 200K |
| Beta 上下文 | — | 1M token(beta) |
| 最大输出 | 128K | 较低 |
| 上下文压缩 | 否 | ✅ 自动压缩老上下文 |
1M token 是 Sonnet 4.6 的标志性升级——它意味着你可以把一个完整的中型代码仓库一次性塞进 prompt 而不需要 RAG 检索。对"全仓库重构 / 跨文件 bug 定位 / 完整 codebase 理解"这类任务,Sonnet 4.6 在 2026 年 4 月几乎是无可替代的。
GLM-5.1 的 200K 也已经够用 90% 的日常场景,但在"超长上下文"的极限场景上确实落后一截。
维度五:Agent 长程任务 — 两种打法的对决
第五个维度是 Agent 长程任务能力——这是 2026 年所有头部编码模型都在角力的方向。
两者的"长程"路线不同
- GLM-5.1:Z.ai 主打"单任务 8 小时持续工作",强调 规划 → 执行 → 测试 → 修复 → 二次优化 的端到端循环,靠的是模型本身的推理深度与工具调用稳定性;
- Claude Sonnet 4.6:Anthropic 主打"Claude Code 实战体验",70% 的 Sonnet 4.5 用户在内部测试中偏好 Sonnet 4.6,靠的是工程化的 Claude Code 工作流 + 1M 上下文 + 上下文压缩。
可以理解为:
| 路线 | 核心优势 | 适合场景 |
|---|---|---|
| GLM-5.1 | 模型推理深度 + 工具调用稳定性 | 后台自动化 Agent / 无人值守任务 |
| Sonnet 4.6 | Claude Code 工作流 + 1M 上下文 | 开发者交互式编码 / IDE 集成 |
如果你做的是"后台跑 Agent 自己开发功能"这类无人值守场景,GLM-5.1 的 8 小时长程能力天然适合;如果你做的是"工程师在 IDE 里和模型对话写代码",Sonnet 4.6 的 Claude Code 集成体验更成熟。
维度六:生态兼容性 — Sonnet 4.6 的工具链优势
最后一个维度是生态。这一项 Sonnet 4.6 仍然处于明显领先位置,但 GLM-5.1 已经追得很快。
| 维度 | GLM-5.1 | Claude Sonnet 4.6 |
|---|---|---|
| Claude Code 兼容 | ✅(OpenAI 兼容入口) | ✅ 原生 |
| Cline / Cursor | ✅(OpenAI 兼容入口) | ✅ 原生 |
| OpenClaw | ✅ | ✅ |
| Anthropic 工具调用 | OpenAI 风格 | ✅ 原生 |
| 第三方 Agent 框架 | 大多数支持 OpenAI 兼容 | 大多数支持 Anthropic 原生 |
| 部署灵活度 | ✅ MIT 自托管 / API易 / Z.ai 自营 | API易 / Anthropic 官方 |
值得注意的是,API易 apiyi.com 同时支持 OpenAI / Claude Native / Gemini Native 三种原生格式,这意味着无论你想用哪种风格的 SDK 调用 GLM-5.1 与 Sonnet 4.6,都可以在同一个 API Key 下完成。这在两者的对比测试里是一个非常实用的细节——你不需要在测试期间维护两套认证、两套监控、两套账单。
按场景给出最终选型建议
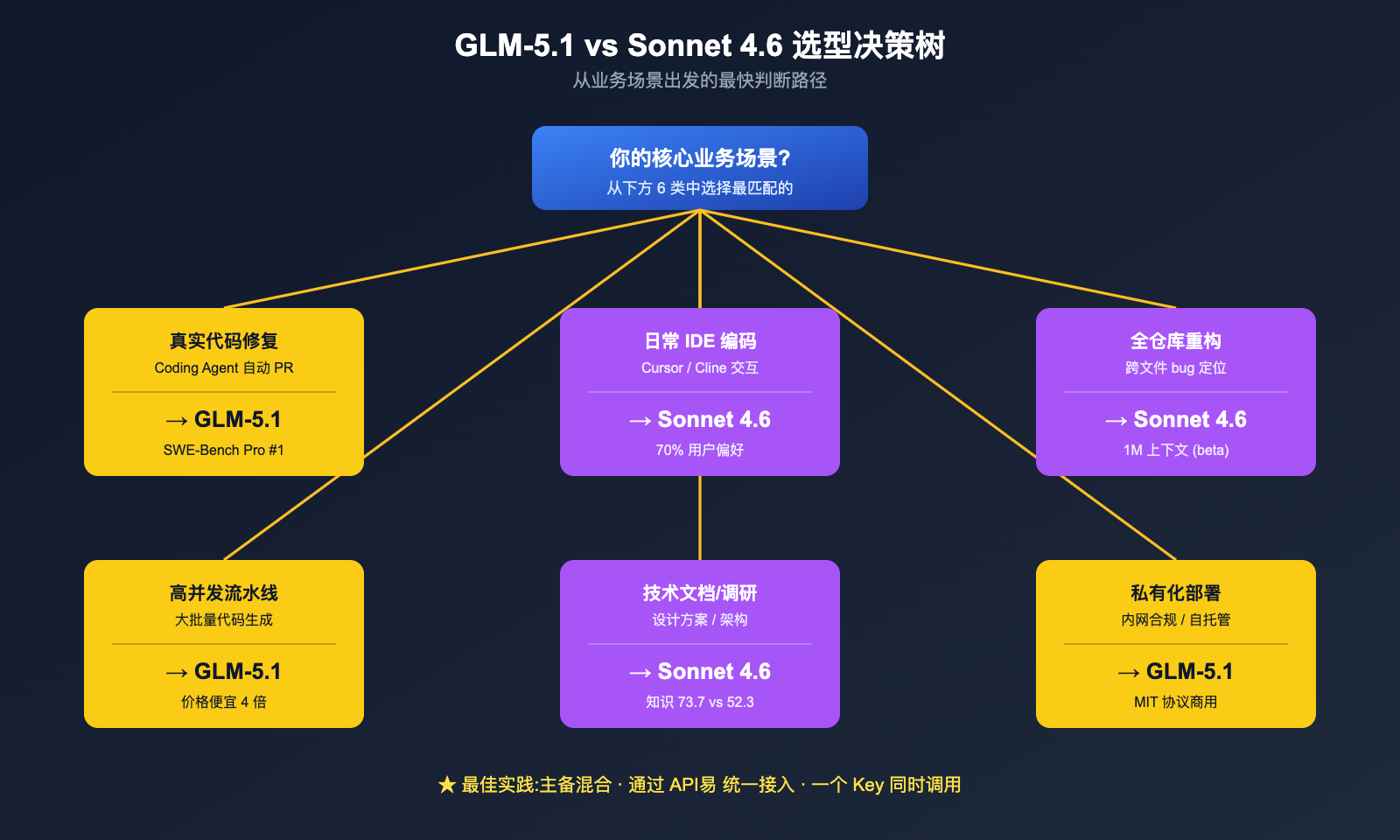
把 6 个维度全部串起来,我们可以给出非常具体的"按业务场景选模型"建议。
场景对照表
| 业务场景 | 推荐模型 | 关键理由 |
|---|---|---|
| 真实工业代码修复(Agent 自动 PR) | GLM-5.1 | SWE-Bench Pro 全球第一 + 8 小时长程 |
| Cursor / Cline 日常 IDE 编码 | Claude Sonnet 4.6 | Claude Code 用户偏好率 70%,工作流成熟 |
| 全仓库重构 / 跨文件 bug 定位 | Claude Sonnet 4.6 | 1M 上下文(beta)是核心武器 |
| 标准化代码生成 + 高并发调用 | GLM-5.1 | 价格便宜 4 倍,适合流水线生产 |
| 技术调研 / 设计文档 / 架构方案 | Claude Sonnet 4.6 | 知识均分 73.7 vs 52.3 大幅领先 |
| 数学推理 / 算法竞赛风格 | GLM-5.1 | AIME 2026 95.3 + GPQA-Diamond 86.2 |
| 客户面向 SaaS 中的代码生成模块 | Sonnet 4.6(主) + GLM-5.1(备份) | Sonnet 主、GLM 兜底,降本同时保质 |
| 私有化部署 / 内网合规 | GLM-5.1 | MIT 协议 + 可自托管 |
| 中文 Coding 交互 | GLM-5.1 | 国产模型对中文 Prompt 更友好 |
| 一次性高难度推理 + 长链路工具调用 | 平手,需自测 | 两者都能跑,差异在 5% 以内 |
推荐的混合策略
对于绝大多数中型团队,我们更推荐"主备混合"的策略,而不是"二选一":
- 主力模型:根据你最多的业务场景挑一个(代码修复选 GLM-5.1,IDE 集成选 Sonnet 4.6);
- 备份模型:把另一个挂上,用于关键业务的 A/B 验证 + 灰度切换;
- 统一接入层:通过 API易 apiyi.com 用同一个 API Key 调用两者,业务代码只改 model 字段,不需要维护两套认证逻辑;
- 成本监控:在 API易 控制台里把两个模型的账单分开看,定期判断哪个模型在你业务上的"性价比"更高,动态调整流量比。
🎯 混合策略落地建议:在 API易 apiyi.com 上,你可以用同一个 API Key 在 GLM-5.1 与 Claude Sonnet 4.6 之间无缝切换,业务代码只需要改一个字符串。我们建议先把"非关键代码生成" 70% 流量切到 GLM-5.1,把"客户面向 + 高难度推理" 30% 流量留给 Sonnet 4.6,这样既能享受 GLM-5.1 的价格优势,也能保证关键场景的稳定性。
GLM-5.1 vs Claude Sonnet 4.6 常见问题 FAQ
Q1:GLM-5.1 真的在编码上超过 Claude Sonnet 4.6 了吗?
部分超过,部分仍落后。在 SWE-Bench Pro(真实工业代码修复)这一项最难的基准上,GLM-5.1 拿下 58.4 全球第一,已经超过 Claude Opus 4.6 的 57.3 与 GPT-5.4 的 57.7,自然也超过 Sonnet 4.6。但在 SWE-bench Verified(标准化代码修复)上,Sonnet 4.6 79.6% 仍然领先 GLM-5.1 77.8% 约 1.8 个百分点;在 BenchLM 综合编码均分上,Sonnet 4.6 的 66.4 也领先 GLM-5.1 的 58.4 约 8 分。结论是:GLM-5.1 在"难度顶峰"超过了 Sonnet 4.6,但在"广度均衡"上仍然落后。
Q2:GLM-5.1 比 Claude Sonnet 4.6 便宜多少?
按 Z.ai 官方直采价,GLM-5.1 的输入 $1.00 / 输出 $3.20,而 Claude Sonnet 4.6 是 $3.00 / $15.00——输入便宜 3 倍,输出便宜约 4.7 倍。在"日均 1000 次 Coding Agent 调用 + 输入 5K / 输出 20K" 的典型场景下,Sonnet 4.6 的月账单大约是 GLM-5.1 的 4.5 倍。如果你的业务"输出量明显大于输入量",GLM-5.1 的性价比优势会更显著。
Q3:GLM-5.1 和 Sonnet 4.6 的上下文窗口哪个更大?
Claude Sonnet 4.6 更大。GLM-5.1 是 200K(部分平台显示 203K),Sonnet 4.6 是 200K → 1M token(beta)。1M 上下文意味着 Sonnet 4.6 可以一次性读完一个中型代码仓库,这是它在"全仓库重构 / 跨文件 bug 定位"这类任务上的核心武器。如果你的任务对超长上下文有刚需,Sonnet 4.6 是更稳妥的选择。
Q4:我现在用 Claude Sonnet 4.6 跑 Cursor / Cline,值得切换到 GLM-5.1 吗?
取决于你的痛点。如果你最在意"账单",GLM-5.1 能砍掉一半甚至更多成本,值得切换;如果你最在意"日常编码体验的稳定性",Sonnet 4.6 的 70% 用户偏好率说明它在 Claude Code 工作流里已经被广泛验证,迁移收益可能小于风险。最稳妥的做法是先用 API易 apiyi.com 把 20% 流量切到 GLM-5.1 做 A/B,跑一周后再决定是否扩大比例。
Q5:GLM-5.1 和 Sonnet 4.6 都能在 API易 上调用吗?
是的,两者都已上线。API易 apiyi.com 同时支持 OpenAI / Claude Native / Gemini Native 三种原生格式,你只需要把 OpenAI SDK 的 base_url 改成 https://api.apiyi.com/v1、model 在 glm-5.1 与 claude-sonnet-4-6(或类似 ID)之间切换,就能在同一份代码里同时跑两者,做横向对比的效率非常高。
Q6:作为独立开发者,我应该选哪个?
如果你只能选一个,先看你的工作流:做 Coding Agent / 后台自动化 / 大批量代码生成 → 选 GLM-5.1;做 IDE 内交互式编程 / 全仓库重构 / 客户面向的内容生成 → 选 Sonnet 4.6。如果你不想做艰难的二选一,两个都接上、用 API易 统一管理才是 2026 年开发者的最佳实践——账单会随着模型选型自动优化,而不是被任何一家厂商绑架。
总结:GLM-5.1 vs Claude Sonnet 4.6 的最终判断
把 6 个维度的对比拼在一起,GLM-5.1 vs Claude Sonnet 4.6 的最终判断可以归纳成下面这段话:GLM-5.1 在"难度极高的工业代码修复 + 价格 + 国产开源 + 长程 Agent" 4 项上拥有结构性优势,Claude Sonnet 4.6 在"广度均衡 + 知识深度 + 1M 上下文 + IDE 工作流成熟度" 4 项上保持领先。两者不是"谁取代谁"的关系,而是一对"针对不同业务场景互补"的工具。
对 2026 年中后期的中国大陆开发团队而言,最聪明的玩法不是非此即彼,而是 "主备混合 + 统一接入层":让 GLM-5.1 承担成本敏感、长程自动化、私有化合规的部分,让 Sonnet 4.6 承担用户面向、复杂上下文、技术写作的部分。通过 API易 这种统一中转把两者放在同一个 API Key 下,再用真实业务账单数据动态调整流量比,就能在不牺牲质量的前提下把月度账单大幅压缩。
🎯 最终建议:GLM-5.1 与 Claude Sonnet 4.6 都已在 API易 apiyi.com 上线。我们建议你今天就在 apiyi.com 创建一个 API Key,把 OpenAI SDK 的
base_url改成https://api.apiyi.com/v1,用同一份代码先跑 5 个 GLM-5.1 任务,再用同样的 prompt 跑 5 个 Sonnet 4.6 任务,亲手验证本文 6 个维度的所有结论。任何评测都不能替代你的实测,但这个 30 分钟的最小验证会让你建立起对 2026 年最强两款 Coding 模型的真实手感。
作者:APIYI Team | 关注 AI 大模型落地与编码工具链评测,更多模型对比与实战调用请访问 API易 apiyi.com。