The official xAI announcement has just dropped: 8 legacy Grok models will be officially retired on May 15, 2026, at 12:00 PM PT. Requests will be automatically redirected to grok-4.3, but billing will be calculated based on the new model's pricing. This article provides a quick breakdown of what this means for AI developers and enterprise users.
Key Takeaways: Get up to speed in 3 minutes on the Grok retirement list, redirection rules, cost changes, and how to update your code under the APIYI synchronized deprecation strategy.

Quick Overview: Grok Model Retirement
xAI has provided a clear timeline and scope in their migration documentation. This isn't just a cleanup of a few obscure models; it covers the primary reasoning, non-reasoning, coding, and image generation models used over the past six months. For teams relying on these slugs in production, May 15 is the hard deadline to complete your code migration.
| Information Item | Details |
|---|---|
| Retirement Date | 2026-05-15 12:00 PT |
| Source | Official xAI (docs.x.ai) |
| Number of Models | 8 |
| Redirection Target | grok-4.3 / grok-imagine-image-quality |
| New Model Pricing | $1.25 / 1M input, $2.50 / 1M output |
| Context Window | 1,000,000 tokens |
| Source Link | docs.x.ai/developers/migration/may-15-retirement |
Detailed List of Retired Grok Models
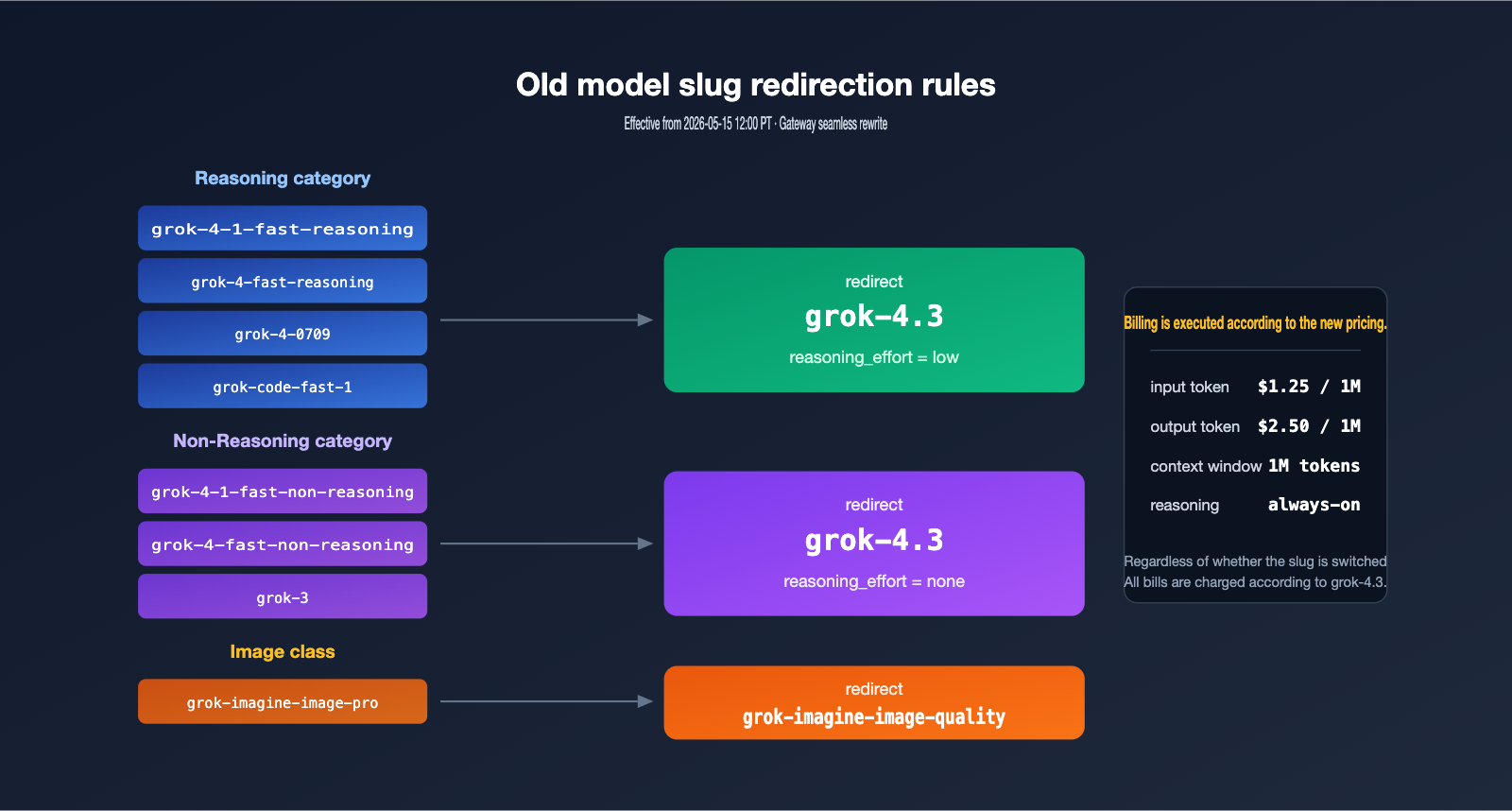
The 8 models being sunset cover four typical workloads: the fast-reasoning series (including grok-4-1-fast-reasoning and grok-4-fast-reasoning) for high-throughput inference; the fast-non-reasoning series (including grok-4-1-fast-non-reasoning and grok-4-fast-non-reasoning) for low-latency chat; grok-4-0709 and grok-3 as early flagship general-purpose models; and grok-code-fast-1 and grok-imagine-image-pro for code and image generation, respectively.
| Model Slug | Category | Typical Use Case | Redirection Target |
|---|---|---|---|
| grok-4-1-fast-reasoning | reasoning | High-throughput inference | grok-4.3 (low effort) |
| grok-4-1-fast-non-reasoning | non-reasoning | Low-latency chat | grok-4.3 (none effort) |
| grok-4-fast-reasoning | reasoning | Fast inference | grok-4.3 (low effort) |
| grok-4-fast-non-reasoning | non-reasoning | Real-time Q&A | grok-4.3 (none effort) |
| grok-4-0709 | reasoning | General flagship | grok-4.3 (low effort) |
| grok-code-fast-1 | coding | Intelligent coding | grok-4.3 (low effort) |
| grok-3 | non-reasoning | Long-term production | grok-4.3 (none effort) |
| grok-imagine-image-pro | image | High-quality images | grok-imagine-image-quality |
According to the official documentation, all reasoning models will be served by grok-4.3 with low reasoning effort, while all non-reasoning models will switch to none effort to ensure latency remains as close to the original models as possible. Image generation requests will be uniformly switched to grok-imagine-image-quality.
Grok Model Retirement: Redirection Rules Explained
After 12:00 PM PT on May 15, old slugs won't immediately return a 404 error. Instead, the gateway will silently rewrite them to grok-4.3. While this "smooth transition" is great for compatibility, it’s also a potential cost trap—many teams assume that "if the request succeeds, everything is fine," only to discover at the end of the month that the unit price has quietly increased.
Changes in Grok Model Reasoning Behavior
The biggest difference between grok-4.3 and the old fast-reasoning series is the "always-on reasoning" design. grok-4.3 makes reasoning (chain-of-thought) a standard behavior rather than an optional toggle. Developers can choose between low, medium, and high reasoning intensity, but there is no option to disable reasoning entirely. The old fast-non-reasoning models simply skipped the reasoning process; while the redirected none effort allows grok-4.3 to simulate the original "direct answer" experience, the actual execution path still consumes a small amount of internal reasoning tokens.
It's worth noting that xAI hasn't provided a "compatibility mode parameter" in the SDK. This means that code with model="grok-4-fast-reasoning" hardcoded will continue to run, but you won't be able to precisely control the reasoning intensity. If your application is sensitive to latency and consistency, you must explicitly pass the reasoning_effort field; otherwise, you'll be stuck with the default setting and won't be able to replicate the performance curve of the old model.
For real-time applications that demand ultra-low latency, we recommend using APIYI (apiyi.com) to test the latency differences between the two effort levels before deciding whether to adjust your prompt design. Once you switch to a unified interface, you can quickly compare the throughput and time-to-first-token (TTFT) for different reasoning efforts without needing to modify extra parameters.
Changes in Grok Image Models
grok-imagine-image-pro has been xAI's flagship image generation model over the past six months, focusing on high-resolution output. With the transition to grok-imagine-image-quality, the new model offers further optimizations in image detail and prompt adherence, though the cost per image and latency characteristics have also shifted.
🎯 Migration Advice: We recommend that projects currently using
grok-imagine-image-proimmediately run regression tests on common prompts in a sandbox environment. Compare the visual differences, generation speed, and cost per image between the new and old models to avoid any unexpected disruptions in your production environment.
Analysis of Cost Impacts Following Grok Model Retirement
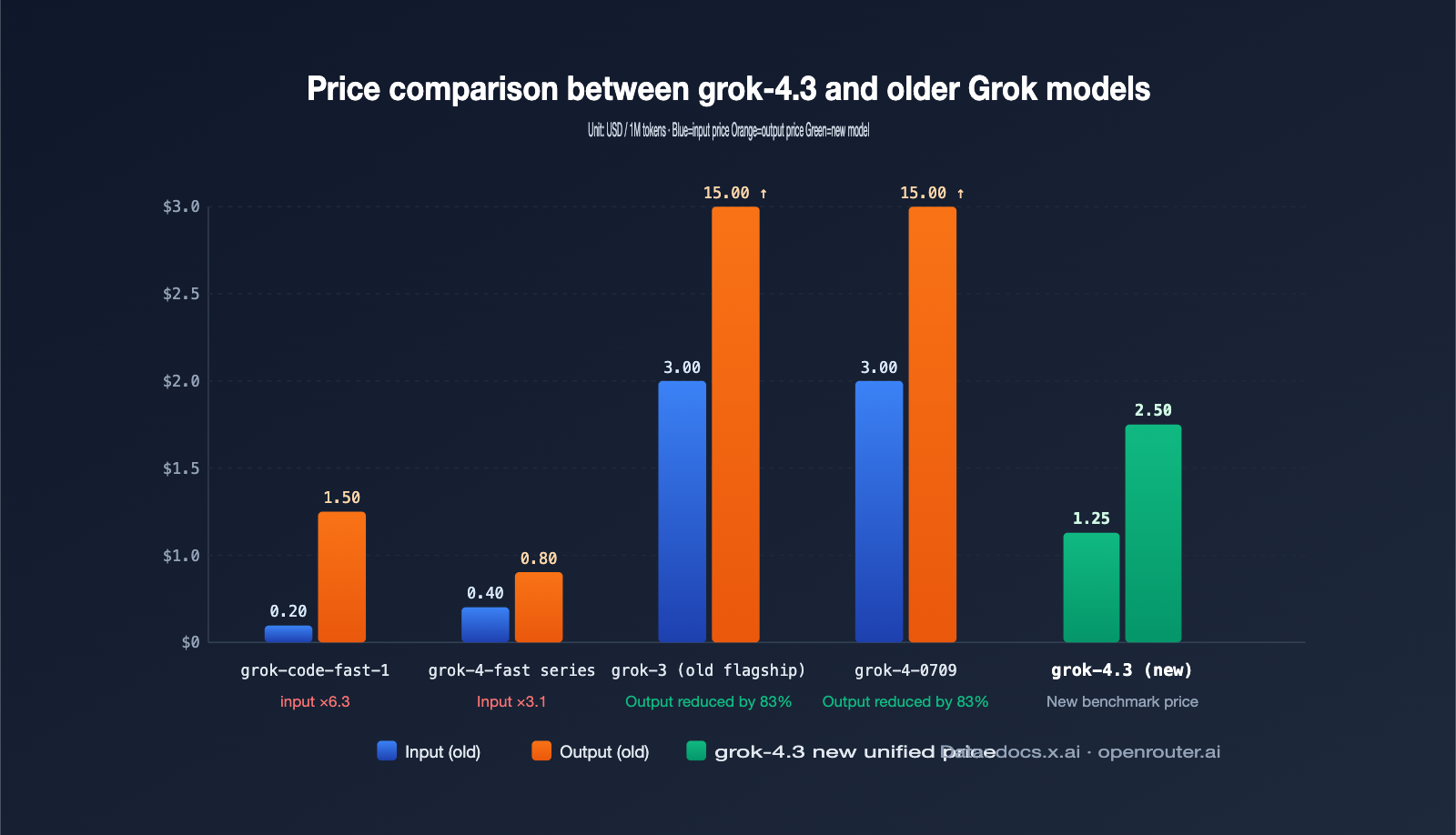
The shift in costs is a critical, yet often underestimated, aspect of the recent retirement announcement. With grok-4.3 priced at a flat $1.25/1M input and $2.50/1M output, teams already utilizing grok-4-0709 or grok-3 won't feel much of a change. However, for projects relying on the lower-cost slugs—fast-reasoning, fast-non-reasoning, and grok-code-fast-1—the price hike will be significant.
5 Key Cost Changes After Grok Model Retirement
The table below summarizes the 5 most common cost pitfalls developers will face after May 15th. We recommend checking your setup against these points before migrating.
| Cost Change Point | Legacy Model Performance | grok-4.3 Performance | Risk Level |
|---|---|---|---|
| Input Unit Price | Fast series generally < $0.5/1M | Flat $1.25/1M | High |
| Output Unit Price | grok-code-fast-1 only $1.50/1M | Flat $2.50/1M | High |
| Reasoning Token Billing | Not billed for some models | Reasoning tokens billed at output rate | Medium |
| Context Window | 256K~512K | 1M full billing | Medium |
| Cache & Tool Calls | Fragmented pricing | $0.20/1M prompt cache + per-call billing | Low |
A special note: grok-4.3 defaults to "always-on reasoning." Even if you select "low effort," every request will consume more reasoning tokens than the legacy fast-non-reasoning models. These tokens are billed at the output rate, making them the most easily overlooked "hidden increase" in your monthly bill. In our internal testing, we observed that the same set of short Q&A prompts, when switched to grok-4.3 (low effort), resulted in a 20%–35% increase in average output tokens compared to fast-non-reasoning. This means that even if the unit price were identical, your monthly bill would still naturally climb.
Take a typical customer service Agent scenario: originally, with 1 million daily calls (800 input + 400 output tokens each), the monthly cost was roughly $4,000 using grok-4-fast-non-reasoning. Switching the same workload to grok-4.3, based on official pricing, would push the monthly cost to approximately $13,500. Once you add the reasoning token overhead, the actual bill approaches $17,000. A difference of this magnitude is enough to warrant a formal budget review by your operations and finance teams in May.
Another often underestimated cost is the effort required for prompt refactoring. grok-4.3’s reasoning behavior tends to "derive answers step-by-step." Prompt templates previously optimized for grok-3 may now result in "verbose output with no conclusion in the first paragraph." To restore the "direct answer + short conclusion" style of the older models, you’ll either need to explicitly constrain the output structure via system prompts or set the reasoning effort to "none." Both approaches will require additional engineering hours for regression testing and prompt library iteration.
💰 Cost Control: During the migration phase, we recommend using the request log dashboard on APIYI (apiyi.com) to aggregate token usage by model slug. This will help you determine, based on your actual use cases, whether you need to switch to "medium effort" to improve quality or lock it to "none effort" to keep costs in check.
Impact Analysis of the Grok Model Retirement
Impact on Developers
The mass retirement of these models most directly affects grok-code-fast-1 users. Previously, this model was a go-to for its incredible value, scoring 80.0% on LiveCodeBench at a price point of $0.20/$1.50. Migrating to grok-4.3 effectively doubles the unit cost. Teams will need to re-evaluate their cost budgets for high-frequency tasks like code completion, PR reviews, and Agent orchestration. Workflows that previously relied on "inline completion + long context retrieval" might now need to be broken down into multi-step processes to keep token consumption in check.
For those using Agent frameworks, the chains that relied on the "fast" series for tool-calling decisions will also be impacted. While grok-4.3 offers stronger tool-calling capabilities, its time-to-first-token (TTFT) is slightly higher, meaning engineers will need to re-tune timeout, retry, and concurrency parameters. We recommend running regression tests in the staging environment on APIYI (apiyi.com) first to ensure that success rates and latency distributions are within acceptable limits before initiating a full-scale switch.
Impact on Enterprise Users
Enterprise users are primarily focused on SLA and compliance. The grok-4.3 upgrade consolidates the capabilities of eight previous models into one, simplifying the model selection matrix—which is actually a win for enterprise governance (model registry, auditing, and security compliance). However, the finance department will need to re-examine existing budgets and discount rules, especially regarding monthly token packages and committed spend discounts, to see if they remain valid under the unified pricing. On the operations side, alert thresholds should be updated to prevent unexpected spikes in the May bill that might otherwise go unnoticed.
For scenarios involving cross-model orchestration, we suggest aggregating Grok, Claude, and GPT models into a unified billing view. By attributing costs by department or business line, you can mitigate the impact of frequent model iterations on budget control. This mass retirement also serves as a reminder to enterprises that the risk of vendor lock-in isn't just about service outages—it's also about the hidden costs that arise when a provider "swaps the engine" behind the same slug.
Impact on the Industry
xAI’s decision to retire eight models at once signals that the grok-4.3 "always-on reasoning + 1M context" combination is now versatile enough to handle reasoning, conversation, coding, and tool-calling workloads simultaneously. This aligns with the trend seen from Claude and OpenAI, where "reasoning models" and "instruct models" are gradually converging. It suggests that Large Language Model productization is entering a phase of "one flagship to rule them all." While the model matrix developers face will become more streamlined, the capability boundaries and price elasticity of individual models will be significantly amplified.
Another trend to watch is that "always-on reasoning + effort tiers" is becoming the new industry standard. This design shifts the trade-off between latency and cost back to the developer, provided that SDKs and monitoring platforms natively support the effort field. For API proxy services and aggregation platforms, model lifecycle management is becoming a new core competency. APIYI (apiyi.com) has already synced the Grok migration documentation to the product console and pushed deprecation notices for affected slugs to help developers avoid any oversights.
APIYI Synchronization and Deprecation Notice
To stay aligned with xAI’s official strategy and avoid billing confusion, APIYI (apiyi.com) has established a deprecation plan to provide a smooth transition for users still calling legacy slugs. The console will track the call volume and cost share of each retired slug over the past 30 days by account, giving team leads a clear, global view of affected business modules before they migrate.
| Phase | Date | APIYI Action |
|---|---|---|
| Warning Period | Before 2026-05-15 | Console banner alerts and email notifications to affected accounts |
| Redirect Period | Starting 2026-05-15 12:00 PT | Legacy slugs automatically forwarded to grok-4.3, with deprecated marked in response headers |
| Full Retirement | Per xAI schedule | Legacy slug options removed from the console |
Developers do not need to change the base_url; simply replace the model field in your request parameters with grok-4.3. If your business utilizes both reasoning and non-reasoning calls, we recommend adding an effort configuration item to your SDK wrapper to facilitate unified scheduling during stress testing and A/B experiments. A complete example is provided below, which you can copy directly into your existing project to verify.
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Explain always-on reasoning in 200 words"}
],
extra_body={"reasoning_effort": "low"}
)
print(response.choices[0].message.content)
View Node.js / TypeScript Version
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "grok-4.3",
messages: [{ role: "user", content: "Summarize the key points of the grok-4.3 migration" }],
// @ts-expect-error xAI extra field
reasoning_effort: "low",
});
console.log(completion.choices[0].message.content);
🚀 Migration Tip: Before migrating, we recommend using the "Model Comparison" panel on APIYI (apiyi.com) to send the same prompt to both
grok-4.3and your original model. Compare the response quality and time-to-first-token to determine the optimalreasoning_efforttier for your needs.
FAQ
Q1: Can I still use the old slugs after May 15th?
Yes, you can. However, the actual model executed will be grok-4.3, and billing will follow the new grok-4.3 pricing of $1.25/$2.50. We recommend updating the model field in your code to grok-4.3 as soon as possible to avoid unexpected increases in your monthly bill.
Q2: Is it still suitable for code completion after migrating from grok-code-fast-1?
grok-4.3 shows improvements over grok-code-fast-1 in benchmarks like LiveCodeBench and SWE-bench, offering stronger overall coding capabilities. However, it comes with higher latency and a higher unit price. We suggest testing your P95 latency and average token consumption per PR with real business samples before deciding if it's still the right fit for inline completion.
Q3: Do I need to request a new API key for the APIYI platform?
No, you don't. Your existing APIYI key is fully compatible with new models like grok-4.3, and the base_url remains unchanged. You only need to update the model name in your request body. You can view the full list of models and their statuses in the APIYI apiyi.com console.
Q4: Are there any precautions for migrating to the image generation model `grok-imagine-image-pro`?
Requests will be redirected to grok-imagine-image-quality. Please note that the visual style, sampling seeds, and default parameters may differ. We recommend running your historical prompts in a sandbox environment first to ensure consistent results before going live, preventing any sudden changes in your application's output.
Summary
xAI is retiring eight of its primary models, including fast-reasoning, fast-non-reasoning, grok-code-fast-1, grok-3, and grok-imagine-image-pro. Starting May 15th at 12:00 PM PT, all traffic will be switched to grok-4.3 and grok-imagine-image-quality. While the migration itself isn't a heavy engineering lift, the changes in unit pricing and reasoning token billing will significantly impact cost-sensitive businesses. We recommend prioritizing three tasks: updating the model field in your production code to grok-4.3, explicitly passing reasoning_effort to control latency and costs, and performing an end-to-end cost analysis using real business data.
Our advice is to treat this model upgrade as an opportunity for better governance: use APIYI apiyi.com to compare latency and costs across multiple models like grok-4.3, Claude, and GPT. Shifting your model selection strategy from "following the vendor's pace" to "selecting based on business metrics" will lead to more stability in the long run and ensure that you can handle similar mass-retirement announcements in just a few hours.
Author: APIYI Team — APIYI apiyi.com, an enterprise-grade Large Language Model API proxy service, supporting unified access to mainstream models including Grok, Claude, GPT, and Gemini.