On May 6, 2026, xAI sent an official email to all API users titled "Grok 4.3 release and xAI API model retirement." The message delivered two critical updates for developers: Grok 4.3 is now fully available via the API, and eight legacy models—including grok-4-fast, grok-4-0709, grok-3, grok-code-fast-1, and grok-imagine-image-pro—will be retired on May 15, 2026, at 12:00 PM PT. This announcement marks both a major version upgrade and a migration countdown that must be completed within just nine days.

The most noteworthy aspect of the Grok 4.3 release isn't just the name change, but the combination of a 1M token context window, pricing at $1.25/$2.50 (input/output), and three adjustable reasoning intensity levels. This pricing tier places Grok 4.3 in direct competition with mainstream reasoning models like Gemini 3.1 Pro and GPT-5.4, while maintaining xAI's signature high token throughput. We recommend that teams relying on the Grok series begin testing via the APIYI (apiyi.com) platform as soon as possible; the unified OpenAI-compatible interface helps minimize migration costs when switching between models.
Comprehensive Breakdown of Grok 4.3 Specifications and Pricing
Grok 4.3 is the latest flagship model, which xAI explicitly describes in its email as "the fastest, most intelligent model we've ever built." It ranks at the top of leaderboards for agentic tool calling and instruction following, positioning it as a general-purpose flagship model for code, agents, and complex reasoning. In terms of specifications, Grok 4.3 expands the context window from the 256K of the Grok 4 era to 1M tokens—matching the tier of Gemini 3 Pro and Claude 4.7—meaning you can feed entire codebases or long technical documents into it in a single pass.
The table below summarizes the core parameters of Grok 4.3 on the xAI API, with data sourced from the official xAI email and third-party benchmarks from Artificial Analysis.
| Parameter | Grok 4.3 Value | Notes |
|---|---|---|
| Context Window | 1,000,000 tokens | Shared input + output |
| Input Pricing | $1.25 / 1M tokens | 50% lower than GPT-5.4, on par with Gemini 3.1 Pro |
| Output Pricing | $2.50 / 1M tokens | ~83% reduction from the $15 rate of the Grok 4 era |
| Reasoning Intensity | 3 levels: low / medium / high | Control deep reasoning budget via parameters |
| Input Modality | Text + Image | Supports visual understanding |
| Output Modality | Text | No direct image generation |
| Tool Calling | Native function calling | Supports structured output and parallel calls |
| Output Speed | ~207 tokens/s | Artificial Analysis benchmark |
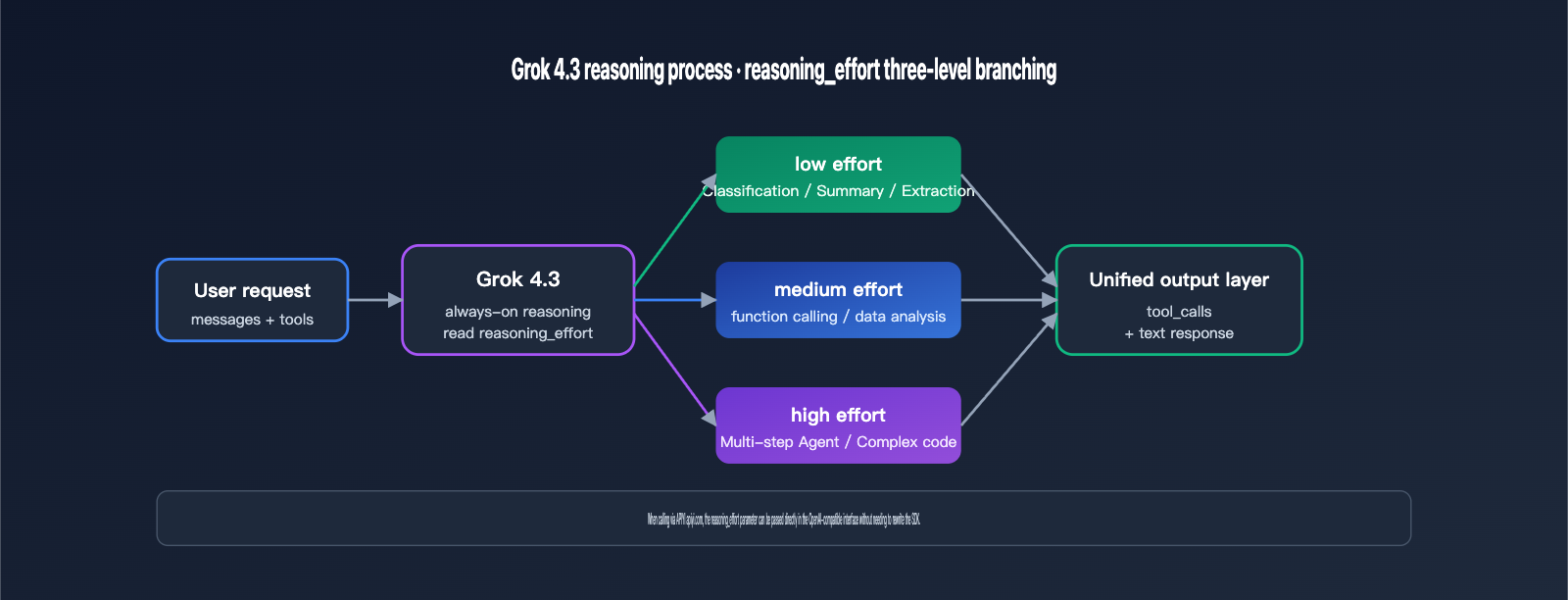
The three levels of "reasoning effort" are a key new feature that distinguishes Grok 4.3 from its predecessor. It allows developers to adjust the model's "thinking" depth based on task complexity, which directly impacts latency and cost. This mechanism is inspired by OpenAI's reasoning_effort design, though xAI has set the reasoning itself to an "always-on" state, simply allowing for depth adjustments. The table below outlines the typical use cases and impacts of these three intensity levels.
| Reasoning Intensity | Typical Scenarios | Latency Characteristics | Cost Impact |
|---|---|---|---|
| low | Simple classification, summarization, rule-based extraction | Near non-reasoning models | Minimal output tokens |
| medium | Function calling, data analysis, code completion | Balanced latency and quality | Default recommended level |
| high | Multi-step agents, complex math, long-chain code | Longer "thinking" phase | Significantly increased output tokens |
🎯 Integration Tip: For teams unsure which level to choose, we recommend running a set of real business samples on the APIYI (apiyi.com) platform using the
mediumlevel, then deciding whether to upgrade tohighbased on accuracy and cost-efficiency. The unified interface allows you to toggle thereasoning_effortparameter across different models with one click, without needing to rewrite your SDK.
Grok 4.3 Performance in Agentic and Instruction Following Benchmarks
The reason xAI highlighted "tops leaderboards in agentic tool calling and instruction following" in their recent email is due to core data from third-party benchmarks like Artificial Analysis, τ²-Bench, IFBench, and GDPval-AA. The Artificial Analysis Intelligence Index gives it a composite score of 53.2, with the total cost to run the full evaluation suite being approximately $395—about 20% cheaper than Grok 4.20. On the τ²-Bench Telecom benchmark (which simulates two-way tool calling for telecom customer service), arguably the scenario closest to real-world agent use cases, Grok 4.3 achieved a 98% score, a 5-percentage-point improvement over Grok 4.20, putting it on par with GLM-5.1.
For developers, the GDPval-AA benchmark, which measures real-world economic value in workflows, is even more noteworthy. Grok 4.3 hit 1500 ELO on GDPval-AA, a massive 321-point jump over the previous generation Grok 4.20 0309 v2 (1179 ELO), surpassing models like Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh), and Kimi K2.5. Regarding instruction following, Grok 4.3 maintained an 81% score on IFBench, matching the performance of Grok 4.20 0309 v2.
| Benchmark | Grok 4.3 Score | Comparison | Key Capability |
|---|---|---|---|
| AA Intelligence Index | 53.2 | Outperforms 98% of models | General Intelligence |
| AA Coding Index | 41.0 | Outperforms 89% of models | Coding & Refactoring |
| τ²-Bench Telecom | 98% | On par with GLM-5.1 | Tool Calling + User Collaboration |
| IFBench | 81% | On par with Grok 4.20 | Complex Instruction Following |
| GDPval-AA | ELO 1500 | Surpasses Gemini 3.1 Pro Preview | Real-world Workflow Value |
It's important to note that Grok 4.3’s strengths lie in agentic workflows and tool calling, rather than pure algorithmic competitions. For applications like code agents, browser agents, or customer service bots that require stable JSON output and multi-turn tool calling, Grok 4.3 offers significantly better reliability than the previous generation. However, if your team's core scenario is pure code synthesis (like SWE-bench), we recommend using the APIYI (apiyi.com) platform to run Grok 4.3, Claude 4.7 Opus, and GPT-5.4 against the same test set, and then deciding on your primary model based on the pass rate.
xAI API Model Deprecation List and Migration Recommendations
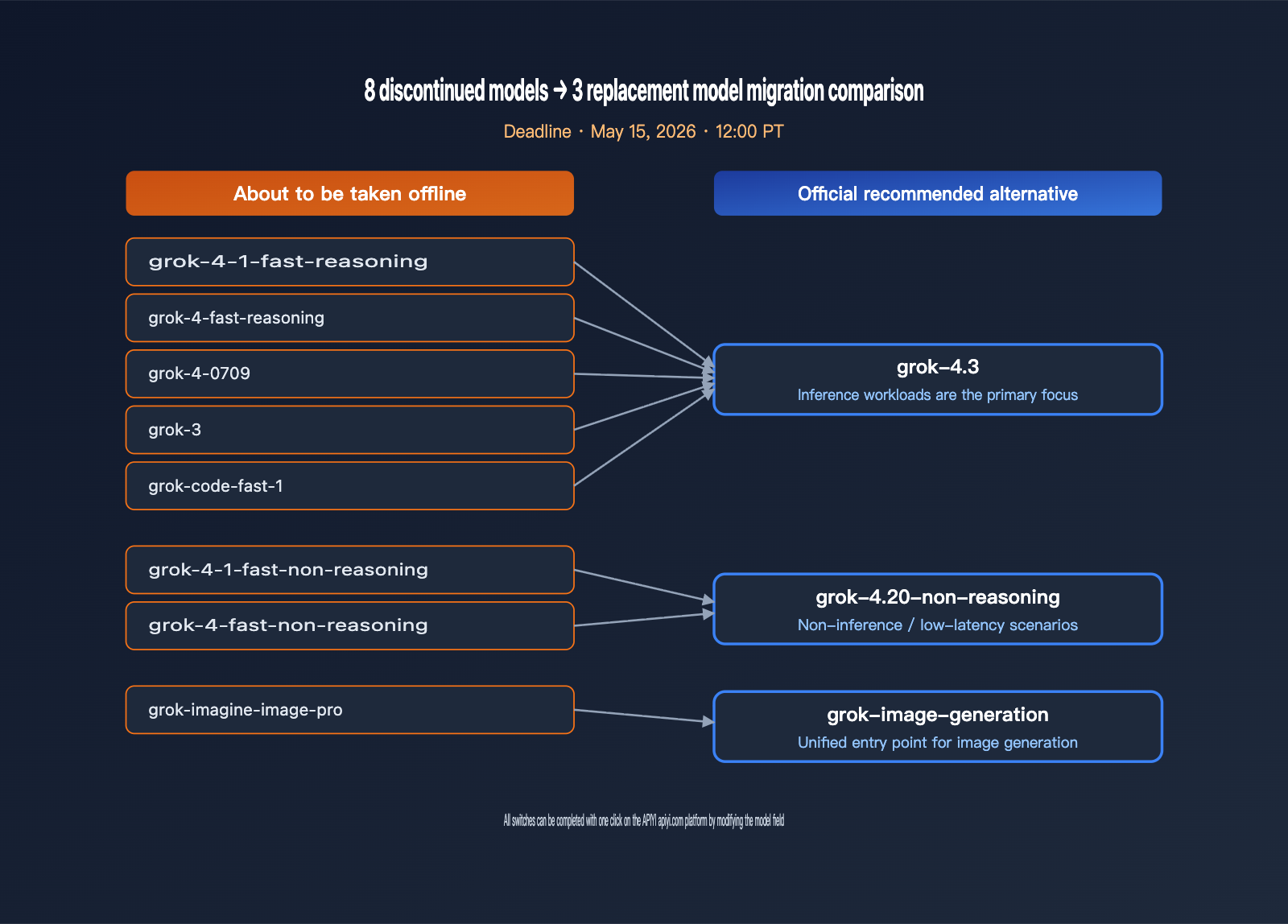
xAI is deprecating 8 models simultaneously, spanning text reasoning, code models, and image generation, effectively clearing out the entire Grok 4-era SKU lineup. For teams that have hard-coded model names directly into their business logic, this is a hard deadline that requires code updates within 9 days. The table below summarizes all affected models and the official recommended migration paths.
| Model to be Deprecated | Type | Official Recommended Alternative | Migration Notes |
|---|---|---|---|
| grok-4-1-fast-reasoning | Reasoning | grok-4.3 | Improved reasoning quality, lower price |
| grok-4-1-fast-non-reasoning | Non-reasoning | grok-4.20-non-reasoning | Retains low-latency characteristics |
| grok-4-fast-reasoning | Reasoning | grok-4.3 | Includes 1M context window |
| grok-4-fast-non-reasoning | Non-reasoning | grok-4.20-non-reasoning | Maintains API compatibility |
| grok-4-0709 | Reasoning | grok-4.3 | Early Grok 4 snapshot deprecation |
| grok-code-fast-1 | Code | grok-4.3 | Consolidating code scenarios to 4.3 |
| grok-3 | General | grok-4.3 | Official end of the Grok 3 era |
| grok-imagine-image-pro | Image Gen | grok-imagine-image | Simplified image generation SKU |
The deprecation date is May 15, 2026, at 12:00 PM PT (May 16, 3:00 AM Beijing Time). Once this deadline passes, all requests sent to these 8 model IDs will return errors. Counting from the email sent on May 6, developers have a 9-day window, which is a very tight schedule for medium-to-large scale operations. We suggest breaking the migration into 3 steps: first, locate all hard-coded model IDs in your codebase; second, run a canary test on the APIYI (apiyi.com) platform; and third, switch the actual model field via environment variables rather than modifying business logic directly.
As a final reminder, grok-code-fast-1 has been the default model for many code agent projects over the past six months. Its deprecation means that all Cursor-like tools, IDE plugins, and CLI agents relying on this ID will need to switch to grok-4.3. In coding scenarios, Grok 4.3 offers better tool-calling stability than grok-code-fast-1, though the cost per token is slightly higher, so you'll need to re-evaluate your invocation budget.
Cross-Comparison: Grok 4.3 vs. GPT-5.4, Claude 4.7, and Gemini 3.1 Pro
With the arrival of Grok 4.3 in Q2 2026, the frontier model market is in the midst of its most intense competition to date. Claude 4.7 Opus maintains an 87.6% lead on SWE-bench Verified, Gemini 3.1 Pro has hit 94.3% on GPQA Diamond, and GPT-5.4 remains the baseline reference for long-text reasoning stability. Grok 4.3 has carved out a niche as the "mid-tier intelligence + ultra-low price + powerful Agent toolchain" option, specifically targeting cost-sensitive, high-frequency invocation scenarios.
The table below compares key metrics for these four flagship models. Prices are in USD per million tokens.
| Model | Input Price | Output Price | Context Window | Primary Use Case |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M | Agent toolchains, high-frequency calls, mid-tier reasoning |
| GPT-5.4 | $2.50 | $15.00 | 400K | Long-text consistency, complex planning |
| Claude 4.7 Opus | $15.00 | $75.00 | 1M | Top-tier coding, document writing, deep analysis |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | Multimodal, video understanding, massive documents |
A quick glance at this table reveals a clear fact: Grok 4.3's output token price is 30 times cheaper than Claude 4.7 Opus and about 4.8 times cheaper than Gemini 3.1 Pro. For businesses relying on high-frequency customer service agents, code linters, or bulk data cleaning, the unit cost advantage of Grok 4.3 is massive. However, for tasks requiring peak coding quality or advanced multimodal understanding, Claude 4.7 Opus and Gemini 3.1 Pro remain irreplaceable.
🎯 Multi-Model Strategy Recommendation: We suggest using Grok 4.3 for high-frequency general tasks, Claude 4.7 Opus for complex code and document generation, and Gemini 3.1 Pro for multimodal tasks. By using the unified interface at APIYI (apiyi.com) for business routing, you can enjoy the cost benefits of Grok 4.3 while still leveraging more powerful models at critical junctures.
Grok 4.3 API Migration Guide and Code Examples
Migrating to Grok 4.3 is straightforward from an engineering perspective. xAI provides an OpenAI-compatible chat completions interface, so most of the work involves simply updating the base_url and model fields. For projects already using the OpenAI SDK, the minimal Python example below provides the complete integration code.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Explain reasoning effort in one sentence."},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
By pointing the base_url to the APIYI (apiyi.com) platform, your business gains a unified entry point for Grok 4.3, Claude 4.7, GPT-5.4, and Gemini 3.1 Pro. Switching models later only requires changing the model parameter, with no need to rewrite authentication or routing logic. This unified abstraction significantly reduces migration risks ahead of the May 15th sunset deadline.
For legacy model migrations, we've compiled a minimal change reference guide for switching from old model IDs to new ones, which you can apply directly to your code.
| Old Model Field | New Model Field | Other Parameters Needed? |
|---|---|---|
| grok-3 | grok-4.3 | Optional: add reasoning_effort |
| grok-4-0709 | grok-4.3 | Optional: add reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | Optional: add reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | No other changes needed |
| grok-code-fast-1 | grok-4.3 | Recommended: reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | Image API endpoint remains consistent |
Grok 4.3 FAQ
Q1: Does Grok 4.3 really support a 1M context window? Will performance degrade with long text?
Yes, Grok 4.3 officially provides a 1M token context window via the xAI API, putting it in the same tier as Claude 4.7 Opus. However, like all long-context models, you might notice some degradation in requirement understanding beyond 600K tokens. We recommend placing critical information in the first half of your documents. You can use the APIYI (apiyi.com) platform to run a retrieval recall test with your actual long-form business documents before deciding whether to make Grok 4.3 your primary model for long-text tasks.
Q2: How should I choose between low, medium, and high inference intensity?
Use "low" for low-risk tasks (classification, summarization, rule extraction), "medium" for standard business operations (customer service, function calling, data analysis), and "high" for complex reasoning (multi-step Agents, long-chain code, complex mathematics). The "high" setting significantly increases output tokens and latency, so we suggest evaluating it against your budget and latency SLAs.
Q3: Can I still use the old models after 12:00 PM PT on May 15?
No. The xAI email explicitly states, "After May 15, 2026, requests to these models will no longer work." Expired requests will return an error. Any code with hard-coded old model IDs must be updated before the deadline.
Q4: How can I minimize migration costs?
The safest approach is to abstract the model field into an environment variable or configuration item within your business logic, rather than hard-coding it. By using the OpenAI-compatible endpoint provided by APIYI (apiyi.com), migration becomes as simple as a one-line configuration change and a single regression test.
Q5: Is Grok 4.3 suitable for Coding Agents?
It is. Grok 4.3 scored 98% on the τ²-Bench Telecom, showing better stability in tool calling and multi-turn conversations compared to grok-code-fast-1. Plus, its unit cost is extremely low, making it perfect for high-frequency IDE plugins, CLI Agents, and automated DevOps scripts.
Summary: Key Takeaways for the Grok 4.3 Launch and xAI API Migration
The biggest highlight of the Grok 4.3 release isn't just that it's "smarter"—it's that it's "smarter while being cheaper." With pricing at $1.25/$2.50, xAI has brought a 1M context window and high-quality Agent tool calling into the same price bracket as Gemini 3.1 Pro, effectively redefining the cost-performance baseline for high-frequency general-purpose layers. Meanwhile, the scheduled retirement of eight older models on May 15 serves as a reminder to all teams: model IDs should never be hard-coded into business logic; instead, they should be abstracted behind a configurable routing layer.
We recommend making Grok 4.3 your go-to for high-frequency calls and Agent toolchains. By using the unified interface from APIYI (apiyi.com), you can minimize migration costs while retaining the flexibility to mix and match models like Claude 4.7 Opus, GPT-5.4, and Gemini 3.1 Pro. This allows you to dynamically schedule tasks across different models to achieve the optimal balance of cost and quality.
APIYI Technical Team · Focusing on practical content for AI model APIs and developer tools. For more technical articles, please visit apiyi.com