El anuncio oficial de xAI acaba de publicarse: 8 modelos antiguos de Grok serán retirados el 15 de mayo de 2026 a las 12:00 PT. Las solicitudes se redirigirán automáticamente a grok-4.3, pero la facturación se realizará según los precios del nuevo modelo. En este artículo, analizamos rápidamente el impacto real de este cambio para desarrolladores de IA y usuarios empresariales.
Valor clave: Entiende en 3 minutos la lista de modelos de Grok retirados, las reglas de redirección, los cambios de costos y cómo actualizar tu código de invocación tras la estrategia de baja sincronizada de APIYI.

Resumen de información clave sobre el retiro de modelos Grok
xAI ha proporcionado una línea de tiempo completa y el alcance del impacto en su documentación de migración. Este retiro no es una limpieza de modelos poco utilizados, sino que abarca los modelos principales de razonamiento, no razonamiento, código y generación de imágenes de los últimos seis meses. Para los equipos que dependen a largo plazo de estos slugs en entornos de producción, el 15 de mayo es la fecha límite inamovible para completar la migración del código.
| Información | Detalles |
|---|---|
| Fecha de retiro | 15-05-2026 12:00 PT |
| Emisor | xAI oficial (docs.x.ai) |
| Cantidad de modelos retirados | 8 |
| Destino de redirección | grok-4.3 / grok-imagine-image-quality |
| Precio del nuevo modelo | $1.25 / 1M entrada, $2.50 / 1M salida |
| Ventana de contexto | 1,000,000 tokens |
| Fuente | docs.x.ai/developers/migration/may-15-retirement |
Lista detallada de modelos Grok retirados
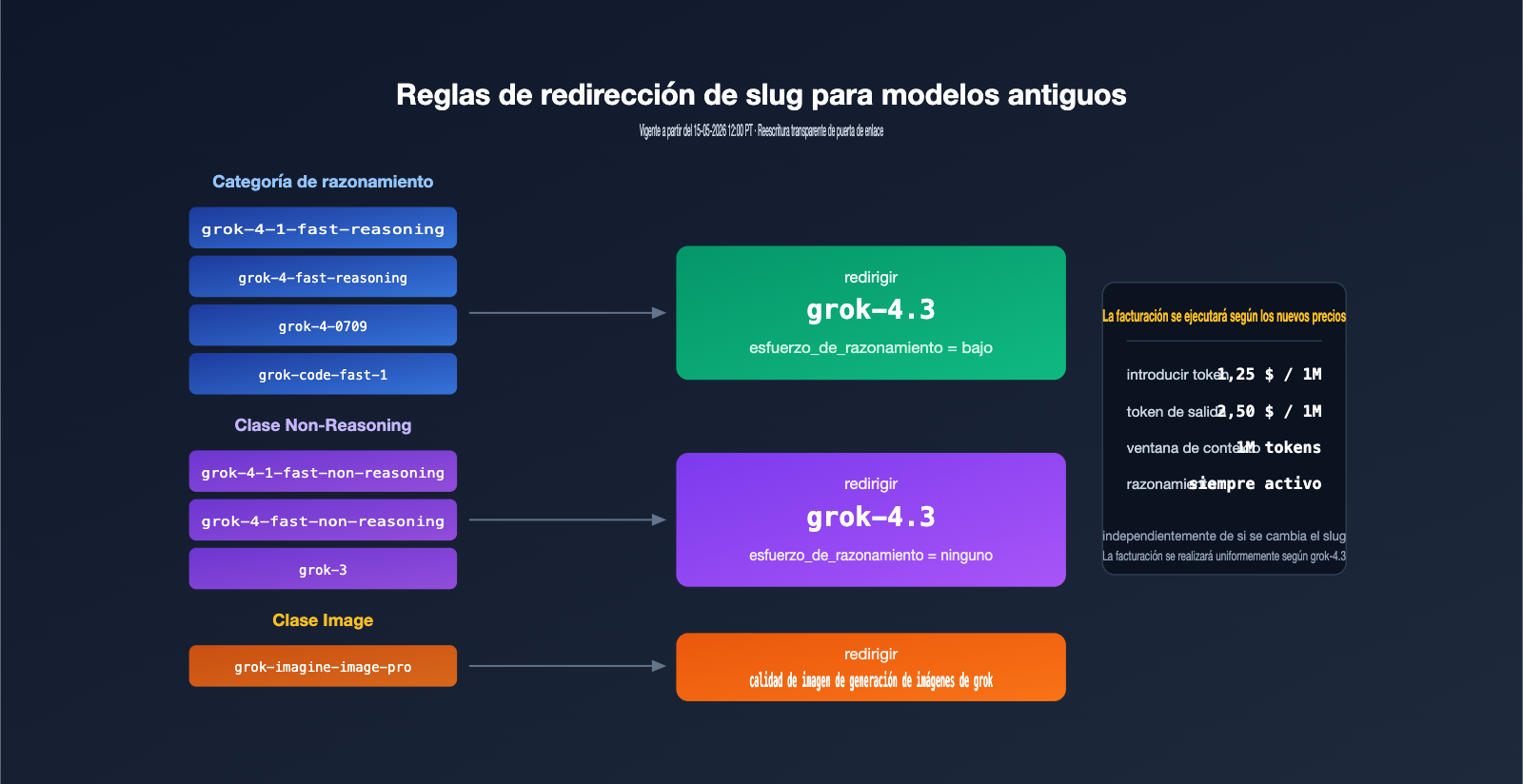
Los 8 modelos que se darán de baja cubren 4 tipos de cargas de trabajo típicas: la serie fast-reasoning (incluyendo grok-4-1-fast-reasoning, grok-4-fast-reasoning) para inferencia de alto rendimiento; la serie fast-non-reasoning (incluyendo grok-4-1-fast-non-reasoning, grok-4-fast-non-reasoning) para conversaciones de baja latencia; grok-4-0709 y grok-3 como modelos insignia generales anteriores; y grok-code-fast-1 junto con grok-imagine-image-pro para generación de código e imágenes, respectivamente.
| Slug del modelo | Categoría | Uso típico | Destino de redirección |
|---|---|---|---|
| grok-4-1-fast-reasoning | razonamiento | Inferencia de alto rendimiento | grok-4.3 (esfuerzo bajo) |
| grok-4-1-fast-non-reasoning | sin razonamiento | Conversación de baja latencia | grok-4.3 (sin esfuerzo) |
| grok-4-fast-reasoning | razonamiento | Inferencia rápida | grok-4.3 (esfuerzo bajo) |
| grok-4-fast-non-reasoning | sin razonamiento | Preguntas y respuestas en tiempo real | grok-4.3 (sin esfuerzo) |
| grok-4-0709 | razonamiento | Insignia general | grok-4.3 (esfuerzo bajo) |
| grok-code-fast-1 | codificación | Codificación inteligente | grok-4.3 (esfuerzo bajo) |
| grok-3 | sin razonamiento | Entorno de producción a largo plazo | grok-4.3 (sin esfuerzo) |
| grok-imagine-image-pro | imagen | Imágenes de alta calidad | grok-imagine-image-quality |
Según la documentación oficial, todos los modelos de razonamiento ofrecerán servicio con grok-4.3 configurado en low reasoning effort, mientras que todos los modelos sin razonamiento cambiarán a none effort para asegurar que la latencia sea lo más cercana posible a la del modelo original. Las solicitudes de generación de imágenes se redirigirán unificadamente a grok-imagine-image-quality para su procesamiento.
Análisis de las reglas de redirección tras la retirada del modelo Grok
Después de las 12:00 PT del 15 de mayo, los slugs antiguos no devolverán un error 404 de inmediato; en su lugar, la puerta de enlace los redirigirá de forma transparente a grok-4.3. Esta "transición suave" es excelente para la compatibilidad, pero también es una trampa de costes oculta: muchos equipos pueden pensar que "si la solicitud tiene éxito, todo está bien", solo para descubrir al final del mes que el precio unitario ha subido silenciosamente.
Cambios en el comportamiento de razonamiento tras la retirada del modelo Grok
La mayor diferencia entre grok-4.3 y la serie anterior fast-reasoning radica en el diseño de "razonamiento siempre activo". grok-4.3 convierte el razonamiento (chain-of-thought) de un interruptor opcional a un comportamiento estándar del modelo. Los desarrolladores pueden elegir entre tres niveles de intensidad de razonamiento: low, medium y high, sin opción de desactivarlo por completo. Los modelos anteriores fast-non-reasoning omitían directamente el proceso de razonamiento; aunque el nivel none tras la redirección permite que grok-4.3 simule la experiencia de "respuesta directa" original, en la cadena real se seguirán consumiendo algunos tokens de razonamiento interno.
Es importante destacar que xAI no ha proporcionado un "parámetro de modo de compatibilidad" en el SDK. Esto significa que, aunque el código que tiene definido model="grok-4-fast-reasoning" siga funcionando, no podrá controlar con precisión la intensidad del razonamiento. Si tu aplicación es sensible a la latencia y la consistencia, debes pasar explícitamente el campo reasoning_effort; de lo contrario, obtendrás el nivel predeterminado y no podrás replicar la curva de comportamiento del modelo antiguo.
Para aplicaciones en tiempo real que buscan una velocidad de respuesta extrema, recomendamos utilizar APIYI (apiyi.com) para medir la diferencia de latencia entre los dos niveles de esfuerzo y decidir si es necesario ajustar el diseño de la indicación (prompt) en el lado del negocio. Al cambiar a una interfaz unificada, puedes comparar rápidamente el rendimiento y la latencia del primer token (time to first token) con diferentes niveles de esfuerzo de razonamiento sin modificar parámetros adicionales.
Cambios en el modelo de imagen tras la retirada del modelo Grok
grok-imagine-image-pro ha sido el modelo de generación de imágenes principal de xAI durante el último medio año, destacando por su alta resolución. Con el cambio a grok-imagine-image-quality, el nuevo modelo ofrece mejoras adicionales en los detalles de la imagen y en el seguimiento de la indicación (prompt), pero las características de coste por imagen y latencia también han cambiado.
🎯 Recomendación de migración: Sugerimos a los proyectos que utilizan
grok-imagine-image-proque realicen inmediatamente una prueba de regresión en un entorno de pruebas (sandbox) con sus indicaciones habituales. Comparen las diferencias visuales, la velocidad de generación y el coste por imagen entre el modelo nuevo y el antiguo para evitar cambios forzados en el entorno de producción.
Análisis del impacto en los costos tras la retirada de los modelos Grok
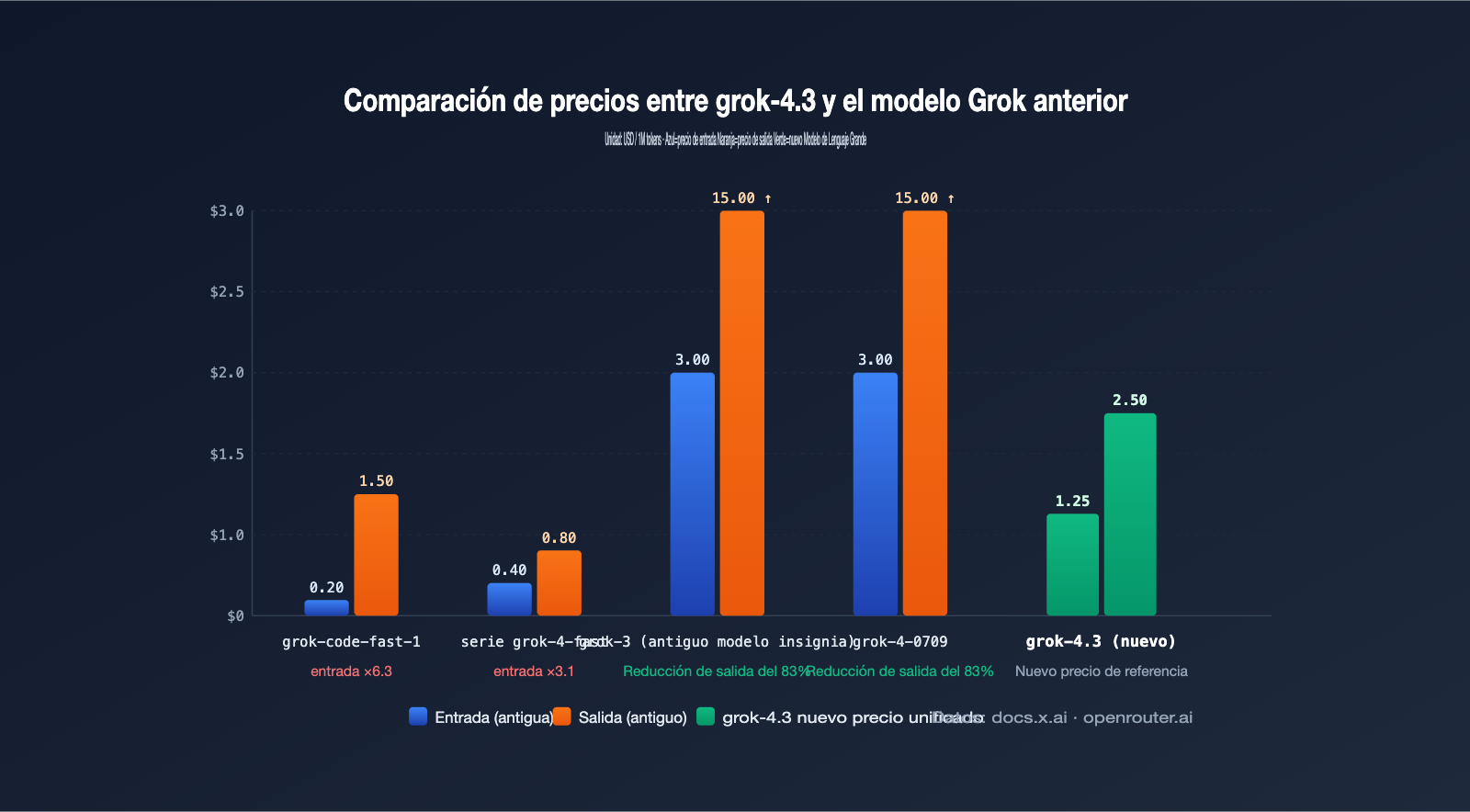
El cambio en los costos es el punto más subestimado en el anuncio de retirada de modelos. El precio unificado de grok-4.3 es de $1.25 por cada 1M de tokens de entrada y $2.50 por cada 1M de tokens de salida. Para los equipos que ya utilizaban grok-4-0709 o grok-3, esto es prácticamente imperceptible, pero para aquellos proyectos que dependían de los slugs de bajo costo como fast-reasoning, fast-non-reasoning y grok-code-fast-1, el precio unitario experimentará un aumento significativo.
5 cambios clave en los costos tras la retirada de los modelos Grok
La siguiente tabla resume los 5 puntos de cambio en los costos que más afectarán a los desarrolladores después del 15 de mayo. Se recomienda realizar una revisión antes de proceder con la migración.
| Punto de cambio de costo | Rendimiento del modelo antiguo | Rendimiento de grok-4.3 | Nivel de riesgo |
|---|---|---|---|
| Precio unitario de entrada | Serie fast generalmente < $0.5/1M | $1.25/1M unificado | Alto |
| Precio unitario de salida | grok-code-fast-1 solo $1.50/1M | $2.50/1M unificado | Alto |
| Facturación de tokens de razonamiento | Algunos modelos no los contabilizan | Tokens de razonamiento facturados como salida | Medio |
| Ventana de contexto | 256K~512K | 1M facturación total | Medio |
| Caché y llamadas a herramientas | Estrategia de precios dispersa | 0.20/1M prompt cache + llamadas a herramientas por uso | Bajo |
Es importante señalar que grok-4.3 tiene el razonamiento activado por defecto (always-on). Incluso si se selecciona un esfuerzo bajo (low effort), cada solicitud consumirá más tokens de razonamiento que la versión antigua fast-non-reasoning. Esta parte se factura según el precio de salida, lo que representa el "aumento invisible" más fácil de pasar por alto en la factura mensual. En nuestras pruebas internas, observamos que al cambiar un mismo conjunto de prompts de preguntas y respuestas cortas a grok-4.3 (esfuerzo bajo), el número promedio de tokens de salida aumentó entre un 20% y un 35% en comparación con fast-non-reasoning. Esto significa que, aunque el precio unitario se mantenga, la factura mensual subirá de forma natural.
Tomemos como ejemplo un agente de atención al cliente típico: con 1 millón de llamadas diarias, 800 tokens de entrada y 400 de salida por solicitud, el costo mensual usando grok-4-fast-non-reasoning rondaba los 4,000 dólares. Al cambiar la misma carga a grok-4.3, el costo mensual calculado según los precios oficiales ascendería a unos 13,500 dólares, y al sumar el incremento de los tokens de razonamiento, la factura real se acercaría a los 17,000 dólares. Esta diferencia de magnitud es suficiente para que los equipos de operaciones y finanzas realicen una revisión formal del presupuesto en mayo.
Otro tipo de costo que suele subestimarse es la carga de trabajo necesaria para adaptar los prompts. El comportamiento de razonamiento de grok-4.3 tiende a "deducir paso a paso antes de dar la respuesta", por lo que las plantillas de prompts optimizadas para grok-3 pueden resultar en "respuestas redundantes y sin conclusiones en el primer párrafo". Para recuperar el estilo de respuesta de "respuesta directa + conclusión breve" del modelo anterior, es necesario restringir explícitamente la estructura de salida mediante el system prompt o ajustar el esfuerzo de razonamiento a none. Ambas opciones requieren horas de trabajo adicionales para pruebas de regresión e iteración de la biblioteca de prompts.
💰 Control de costos: Recomendamos que, durante la fase de migración, utilicen el panel de registros de solicitudes de APIYI (apiyi.com) para verificar el consumo de tokens agregados por slug de modelo. Esto les permitirá decidir, según el escenario real, si es necesario cambiar a un esfuerzo medio (medium effort) para mejorar la calidad o establecer el esfuerzo en none para controlar los costos.
Análisis del impacto del retiro de los modelos Grok
Impacto en los desarrolladores
El retiro masivo afecta de forma más directa a los usuarios de grok-code-fast-1, ya que este modelo ofrecía una excelente relación calidad-precio, logrando una puntuación del 80,0 % en LiveCodeBench por un costo de $0,20/$1,50. Al migrar a grok-4.3, el precio unitario se duplica, lo que obliga a los equipos a reevaluar sus presupuestos para tareas de alta frecuencia como la autocompletación de código, revisiones de PR y orquestación de agentes. La combinación de "autocompletación en línea + recuperación de contexto largo" que funcionaba anteriormente podría requerir ahora una segmentación en varios pasos para controlar el consumo de tokens.
Para quienes utilizan marcos de trabajo de agentes, las cadenas que dependían de la serie fast para la toma de decisiones de herramientas también se verán afectadas. Aunque grok-4.3 tiene capacidades de invocación de herramientas más potentes, su latencia inicial es ligeramente mayor, por lo que los ingenieros deberán reajustar los parámetros de tiempo de espera (timeout), reintentos y concurrencia. Recomendamos realizar pruebas de regresión en el entorno de pruebas de APIYI (apiyi.com) para confirmar que la tasa de éxito y la distribución de latencia sean aceptables antes de realizar el cambio total.
Impacto en los usuarios empresariales
La prioridad para los usuarios corporativos es el cumplimiento de los SLA y la normativa. La actualización a grok-4.3 cubre todos los escenarios de los 8 modelos anteriores, simplificando la matriz de selección de modelos, lo cual es positivo para la gobernanza empresarial (registro de modelos, auditoría y cumplimiento de seguridad). Sin embargo, desde el punto de vista financiero, es necesario revisar los presupuestos y las reglas de deducción existentes, especialmente si los paquetes de tokens mensuales o los descuentos por compromiso se ven afectados por la unificación de precios. El equipo de operaciones también debe actualizar los umbrales de alerta para evitar aumentos inesperados en la factura de mayo.
Para escenarios de llamadas a múltiples modelos, sugerimos agregar Grok, Claude y GPT en una vista de facturación unificada, realizando la atribución de costos por departamento o línea de negocio para mitigar el impacto de las frecuentes iteraciones de modelos en el control presupuestario. Este retiro masivo recuerda a las empresas que el riesgo de depender de un solo proveedor no solo implica una interrupción del servicio, sino también costos ocultos derivados de cambios internos "bajo el capó" con el mismo identificador (slug).
Impacto en la industria
La decisión de xAI de retirar 8 modelos a la vez indica que la combinación de "razonamiento siempre activo + 1M de ventana de contexto" de grok-4.3 es lo suficientemente versátil como para manejar cargas de trabajo de razonamiento, conversación, código e invocación de herramientas simultáneamente. Esto coincide con la tendencia de Claude y OpenAI de unificar sus "modelos de razonamiento" con los "modelos de instrucción", lo que sugiere que la comercialización de los Modelos de Lenguaje Grande está entrando en una etapa de "un solo modelo insignia para todo". El ecosistema de modelos será más simplificado, pero los límites de capacidad y la elasticidad de precios de cada modelo serán mayores.
Otra tendencia a observar es que el "razonamiento activado por defecto + niveles de esfuerzo" se está convirtiendo en el nuevo estándar de la industria. Este diseño devuelve la elección entre latencia y costo al desarrollador, siempre que el SDK y la plataforma de monitoreo soporten de forma nativa el campo de esfuerzo. Para los servicios proxy de API y plataformas de agregación, la gestión del ciclo de vida de los modelos se convertirá en una capacidad central. APIYI (apiyi.com) ya ha sincronizado la documentación de migración de Grok en su consola y ha enviado notificaciones de baja para los slugs afectados, ayudando a los desarrolladores a no pasar nada por alto.
Instrucciones de baja sincronizada de APIYI
Para mantener la coherencia con la estrategia oficial de xAI y evitar confusiones en la facturación, APIYI (apiyi.com) ha establecido un plan de baja, ofreciendo una transición fluida para los usuarios que aún llaman a slugs antiguos. La consola calculará, por cuenta, la frecuencia de uso y el porcentaje de gasto de cada slug retirado en los últimos 30 días, permitiendo a los responsables de equipo tener una visión global clara de los módulos afectados antes de la migración.
| Fase | Tiempo | Acción de APIYI |
|---|---|---|
| Periodo de alerta | Antes del 15-05-2026 | Banner en consola y notificación por correo a cuentas afectadas |
| Periodo de redirección | Desde el 15-05-2026 12:00 PT | Los slugs antiguos se redirigen a grok-4.3 y se marcan como deprecated en la cabecera |
| Baja total | Según el ritmo de xAI | Se elimina la opción de slugs antiguos en la consola |
Los desarrolladores no necesitan cambiar la base_url, solo deben reemplazar el campo model en los parámetros de la solicitud por grok-4.3. Si su negocio utiliza llamadas de razonamiento y sin razonamiento, recomendamos añadir una configuración de effort en la capa de encapsulación del SDK para facilitar la programación unificada durante las pruebas de carga y experimentos A/B. A continuación, se muestra un ejemplo de llamada completo que puede copiar directamente en su proyecto para verificarlo.
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Explica el razonamiento siempre activo en 200 palabras"}
],
extra_body={"reasoning_effort": "low"}
)
print(response.choices[0].message.content)
Ver versión para Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "grok-4.3",
messages: [{ role: "user", content: "Resume los puntos clave de la migración a grok-4.3" }],
// @ts-expect-error campo extra de xAI
reasoning_effort: "low",
});
console.log(completion.choices[0].message.content);
🚀 Consejo de migración: Antes de migrar, recomendamos utilizar el panel de "Comparación de modelos" de APIYI (apiyi.com) para enviar el mismo grupo de indicaciones a
grok-4.3y al modelo original. Compare la calidad de la respuesta y la latencia inicial antes de decidir el nivel final de reasoning effort.
Preguntas frecuentes
Q1: ¿Se podrán seguir utilizando los slugs antiguos después del 15 de mayo?
Sí, pero el modelo que se ejecutará realmente será grok-4.3 y la facturación se realizará según las nuevas tarifas de grok-4.3 ($1.25/$2.50). Recomendamos actualizar el campo model en su código a grok-4.3 lo antes posible para evitar aumentos inesperados en su factura mensual.
Q2: ¿Sigue siendo adecuado grok-code-fast-1 para la autocompletación de código tras la migración?
grok-4.3 ha mejorado sus resultados en LiveCodeBench y SWE-bench en comparación con grok-code-fast-1, ofreciendo una capacidad de codificación general superior, aunque con una mayor latencia y un precio unitario más elevado. Sugerimos realizar pruebas con muestras de su negocio real para medir la latencia P95 y el consumo promedio de tokens por PR antes de decidir si sigue siendo adecuado para la autocompletación en línea.
Q3: ¿Es necesario solicitar una nueva clave API en la plataforma APIYI?
No, su clave APIYI original es directamente compatible con los nuevos modelos como grok-4.3 y la base_url permanece sin cambios; solo necesita ajustar el nombre del modelo en el cuerpo de la solicitud. Puede consultar la lista completa de modelos y su estado en el panel de control de APIYI en apiyi.com.
Q4: ¿Qué precauciones debo tener al migrar al modelo de generación de imágenes grok-imagine-image-pro?
Las solicitudes serán redirigidas a grok-imagine-image-quality. Tenga en cuenta que el estilo de la imagen, la semilla de muestreo y los parámetros predeterminados son diferentes. Recomendamos ejecutar sus indicaciones (prompts) históricas en un entorno de pruebas para confirmar que los resultados sean estables antes de pasar a producción, evitando así cambios repentinos en las imágenes de su servicio.
Resumen
xAI ha retirado 8 de sus modelos principales, incluyendo fast-reasoning, fast-non-reasoning, grok-code-fast-1, grok-3 y grok-imagine-image-pro. A partir del 15 de mayo a las 12:00 PT, todos se cambiarán a grok-4.3 y grok-imagine-image-quality. Aunque la migración técnica no es compleja, los cambios en el precio unitario y la facturación de los tokens de razonamiento tienen un impacto significativo en los negocios sensibles a los costos. Recomendamos priorizar tres acciones: actualizar el campo model en su código de producción a grok-4.3, pasar explícitamente reasoning_effort para controlar la latencia y los costos, y realizar una estimación de costos de extremo a extremo con muestras de su negocio real.
Nuestra recomendación es aprovechar esta actualización de modelos como una oportunidad de gestión: utilice APIYI en apiyi.com para ejecutar simultáneamente modelos como grok-4.3, Claude y GPT, comparando latencia y costos. Cambie su estrategia de selección de modelos de "seguir el ritmo del proveedor" a "seleccionar según indicadores de negocio". A largo plazo, esto será más estable y le permitirá reducir los costos de cambio a solo unas pocas horas cuando ocurra el próximo anuncio de retiro masivo.
Autor: Equipo de APIYI — APIYI apiyi.com, servicio proxy de API para modelos de lenguaje grandes de nivel empresarial, que permite la integración unificada de modelos líderes como Grok, Claude, GPT y Gemini.