L'annonce officielle de xAI vient de tomber : 8 anciens modèles Grok seront officiellement retirés le 15 mai 2026 à 12h00 PT. Les requêtes seront automatiquement redirigées vers grok-4.3, mais la facturation sera appliquée selon les tarifs des nouveaux modèles. Cet article analyse l'impact réel de ce changement pour les développeurs IA et les entreprises.
Valeur ajoutée : Comprenez en 3 minutes la liste des modèles Grok retirés, les règles de redirection, l'évolution des coûts et comment mettre à jour votre code d'invocation via le service proxy API d'APIYI.

Aperçu des informations clés sur le retrait des modèles Grok
Dans sa documentation de migration, xAI a clairement établi le calendrier et la portée de ces changements. Ce retrait ne concerne pas seulement quelques modèles peu utilisés, mais couvre l'ensemble des modèles de raisonnement, de non-raisonnement, de code et de génération d'images utilisés au cours des six derniers mois. Pour les équipes qui dépendent de ces identifiants (slugs) en production, le 15 mai est la date limite impérative pour effectuer la transition.
| Élément | Détails |
|---|---|
| Date de retrait | 15/05/2026 à 12h00 PT |
| Émetteur | xAI (docs.x.ai) |
| Nombre de modèles retirés | 8 |
| Cible de redirection | grok-4.3 / grok-imagine-image-quality |
| Prix du nouveau modèle | 1,25 $ / 1M d'entrées, 2,50 $ / 1M de sorties |
| Fenêtre de contexte | 1 000 000 de jetons |
| Source | docs.x.ai/developers/migration/may-15-retirement |
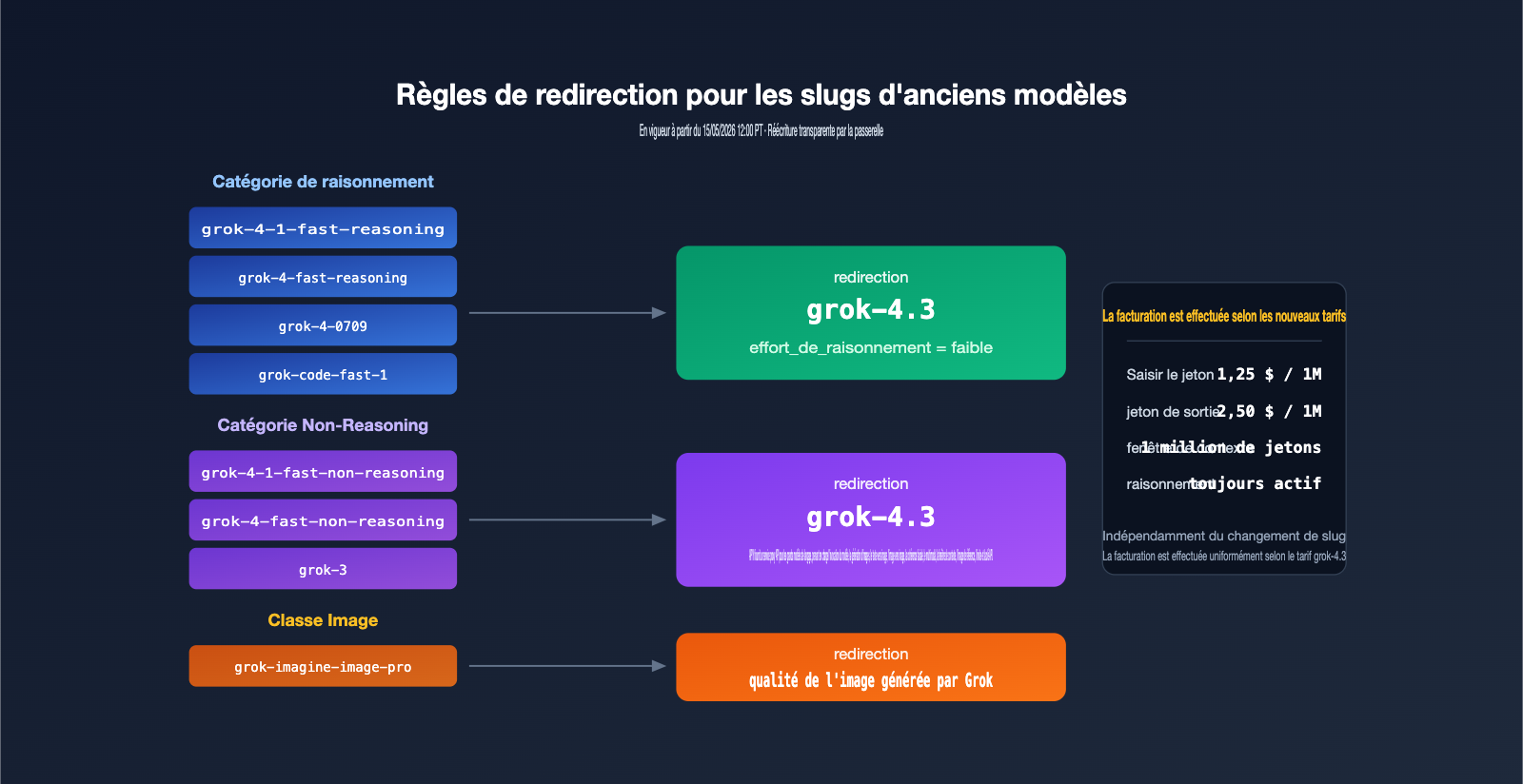
Liste détaillée des modèles Grok retirés
Les 8 modèles supprimés couvrent 4 types de charges de travail : la série fast-reasoning (incluant grok-4-1-fast-reasoning, grok-4-fast-reasoning) pour le raisonnement à haut débit ; la série fast-non-reasoning (incluant grok-4-1-fast-non-reasoning, grok-4-fast-non-reasoning) pour les conversations à faible latence ; grok-4-0709 et grok-3 en tant qu'anciens modèles phares ; enfin grok-code-fast-1 et grok-imagine-image-pro pour le code et l'image.
| Slug du modèle | Catégorie | Usage typique | Cible de redirection |
|---|---|---|---|
| grok-4-1-fast-reasoning | raisonnement | Raisonnement haut débit | grok-4.3 (low effort) |
| grok-4-1-fast-non-reasoning | non-raisonnement | Conversation basse latence | grok-4.3 (none effort) |
| grok-4-fast-reasoning | raisonnement | Raisonnement rapide | grok-4.3 (low effort) |
| grok-4-fast-non-reasoning | non-raisonnement | Réponses en temps réel | grok-4.3 (none effort) |
| grok-4-0709 | raisonnement | Modèle phare généraliste | grok-4.3 (low effort) |
| grok-code-fast-1 | codage | Codage intelligent | grok-4.3 (low effort) |
| grok-3 | non-raisonnement | Production long terme | grok-4.3 (none effort) |
| grok-imagine-image-pro | image | Image haute qualité | grok-imagine-image-quality |
Selon la documentation officielle, tous les modèles de type "reasoning" seront servis par grok-4.3 avec un niveau d'effort "low", tandis que les modèles "non-reasoning" passeront en mode "none effort" pour garantir une latence aussi proche que possible des modèles originaux. Les requêtes de génération d'images seront, quant à elles, systématiquement redirigées vers grok-imagine-image-quality.
Analyse des règles de redirection pour le retrait du modèle Grok
Après le 15 mai à 12h00 PT, les anciens slugs ne renverront pas immédiatement une erreur 404. Au lieu de cela, la passerelle les redirigera de manière transparente vers grok-4.3. Cette « transition en douceur » est très pratique pour la compatibilité, mais elle constitue également un piège financier potentiel : de nombreuses équipes pensent que « si la requête aboutit, tout va bien », pour finalement découvrir à la fin du mois que le prix unitaire a discrètement augmenté.
Changements dans le comportement de raisonnement suite au retrait du modèle Grok
La différence majeure entre grok-4.3 et l'ancienne série fast-reasoning réside dans la conception « always-on reasoning ». grok-4.3 fait du raisonnement (chaîne de pensée) un comportement par défaut du modèle, plutôt qu'une option activable. Les développeurs peuvent choisir entre trois niveaux d'intensité de raisonnement (low, medium, high), mais il n'existe pas d'option pour désactiver complètement le raisonnement. Les anciens modèles fast-non-reasoning ignoraient directement le processus de raisonnement ; après la redirection, le niveau « none effort » permettra à grok-4.3 de simuler l'expérience de « réponse directe » originale, bien que la chaîne de traitement consomme toujours une petite quantité de jetons de raisonnement internes.
Il est important de noter que xAI n'a pas fourni de « paramètre de mode de compatibilité » au niveau du SDK. Cela signifie que même si le code utilisant model="grok-4-fast-reasoning" continue de fonctionner, il ne pourra pas contrôler précisément l'intensité du raisonnement. Si votre application est sensible à la latence et à la cohérence, vous devez explicitement transmettre le champ reasoning_effort, sinon vous obtiendrez le niveau par défaut, ce qui ne reproduira pas la courbe de comportement de l'ancien modèle.
Pour les applications en temps réel visant une réactivité maximale, nous vous suggérons d'utiliser APIYI (apiyi.com) pour tester les différences de latence entre les deux niveaux d'effort avant de décider d'ajuster la conception de vos invites (prompt). En basculant vers une interface unifiée, vous pouvez comparer rapidement le débit et la latence du premier jeton (TTFT) pour différents niveaux de reasoning_effort sans avoir à modifier de paramètres supplémentaires.
Changements dans le modèle d'image suite au retrait du modèle Grok
grok-imagine-image-pro a été le modèle de génération d'images phare de xAI au cours des six derniers mois, axé sur une haute résolution. Avec le passage à grok-imagine-image-quality, le nouveau modèle offre des optimisations supplémentaires en termes de détails visuels et de respect des invites, mais les caractéristiques de coût par image et de latence ont également évolué.
🎯 Conseil de migration : Nous recommandons aux projets utilisant actuellement
grok-imagine-image-prod'effectuer immédiatement un test de régression sur leurs invites habituelles dans un environnement de bac à sable (sandbox). Comparez les différences visuelles, la vitesse de génération et les coûts par image entre les anciens et les nouveaux modèles afin d'éviter une bascule forcée côté production.
Analyse de l'impact des coûts liés au retrait des modèles Grok
L'évolution des coûts est un aspect crucial, souvent sous-estimé, dans l'annonce du retrait de ces modèles. Le prix unifié de grok-4.3 est de 1,25 $/1M de tokens en entrée et 2,50 $/1M de tokens en sortie. Pour les équipes utilisant déjà grok-4-0709 ou grok-3, l'impact est quasi nul. En revanche, pour les projets dépendant des modèles à bas coût (slugs) comme fast-reasoning, fast-non-reasoning et grok-code-fast-1, la hausse des prix sera significative.
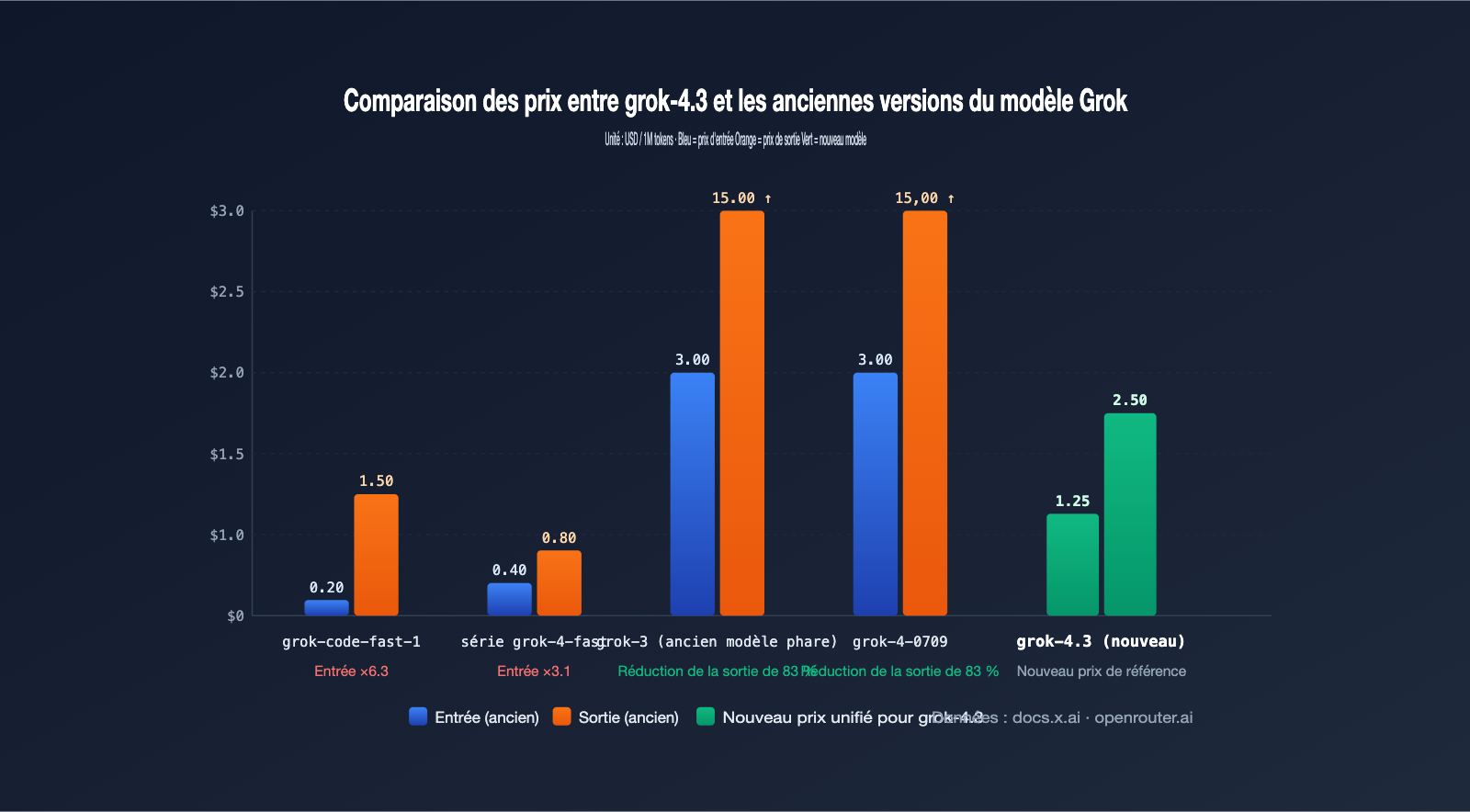
5 changements de coûts clés suite au retrait des modèles Grok
Le tableau ci-dessous résume les 5 points de variation de coûts auxquels les développeurs seront confrontés après le 15 mai. Nous vous recommandons de vérifier ces points avant toute migration.
| Point de variation | Performance ancien modèle | Performance grok-4.3 | Niveau de risque |
|---|---|---|---|
| Prix unitaire entrée | Série fast < 0,5 $/1M | 1,25 $/1M unifié | Élevé |
| Prix unitaire sortie | grok-code-fast-1 à 1,50 $/1M | 2,50 $/1M unifié | Élevé |
| Facturation tokens raisonnement | Non facturé sur certains modèles | Facturé au prix de sortie | Moyen |
| Fenêtre de contexte | 256K~512K | 1M facturé intégralement | Moyen |
| Cache et appels d'outils | Stratégies disparates | 0,20 $/1M prompt cache + facturation à l'appel | Faible |
Il est important de noter que grok-4.3 active le raisonnement en permanence (always-on reasoning). Même en choisissant un effort faible (low effort), chaque requête consomme plus de tokens de raisonnement que l'ancien modèle fast-non-reasoning. Cette partie est facturée au prix de sortie, ce qui constitue une "hausse invisible" souvent oubliée dans les factures mensuelles. Lors de nos tests internes, nous avons observé qu'avec un même prompt de questions-réponses courtes, le passage à grok-4.3 (effort faible) augmente le nombre moyen de tokens de sortie de 20 % à 35 %. Cela signifie que même si le prix unitaire semble stable, la facture mensuelle augmentera mécaniquement.
Prenons l'exemple d'un agent de service client : avec 1 million d'appels par jour (800 tokens entrée + 400 tokens sortie), le coût mensuel avec grok-4-fast-non-reasoning était d'environ 4 000 $. Avec la même charge sur grok-4.3, le coût monte à environ 13 500 $ selon les prix officiels, et atteint près de 17 000 $ en incluant l'augmentation des tokens de raisonnement. Un tel écart mérite une révision budgétaire formelle par les équipes opérationnelles et financières en mai.
Une autre catégorie de coûts souvent sous-estimée est le travail de refonte des invites (prompts). Le raisonnement de grok-4.3 privilégie une "déduction étape par étape avant de donner la réponse". Les modèles d'invites optimisés pour grok-3 risquent de produire des réponses trop longues ou sans conclusion immédiate. Pour retrouver le style "réponse directe + conclusion courte", il faut soit contraindre explicitement la structure de sortie via le system prompt, soit régler l'effort de raisonnement sur none. Ces deux options impliquent un temps de travail supplémentaire pour les tests de régression et l'itération de la bibliothèque d'invites.
💰 Contrôle des coûts : Nous vous suggérons, lors de la phase de migration, d'utiliser le tableau de bord des journaux de requêtes d'APIYI (apiyi.com) pour agréger la consommation de tokens par modèle. Cela vous permettra de déterminer, selon vos besoins réels, s'il est préférable de passer à un effort moyen (medium effort) pour améliorer la qualité, ou de verrouiller l'effort sur none pour maîtriser les coûts.
Analyse de l'impact du retrait des modèles Grok
Impact sur les développeurs
Le retrait collectif affecte directement les développeurs utilisant grok-code-fast-1, car ce modèle offrait un excellent rapport qualité-prix avec un score de 80,0 % sur LiveCodeBench pour un coût de 0,20 $/1,50 $. La migration vers grok-4.3 double le coût unitaire. Les équipes doivent donc réévaluer leur budget pour les tâches fréquentes comme la complétion de code, la revue de PR et l'orchestration d'agents. La combinaison « complétion en ligne + recherche dans un long contexte », qui fonctionnait bien auparavant, pourrait devoir être segmentée en plusieurs étapes pour mieux contrôler la consommation de jetons.
Pour les utilisateurs de frameworks d'agents, les chaînes dépendant de la série « fast » pour la prise de décision sur les outils seront également impactées. Bien que grok-4.3 dispose de capacités d'invocation d'outils plus avancées, sa latence initiale est légèrement plus élevée. Les ingénieurs devront donc réajuster les paramètres de timeout, de nouvelle tentative (retry) et de concurrence. Nous recommandons d'effectuer des tests de régression dans l'environnement de pré-production d'APIYI (apiyi.com) afin de confirmer que le taux de réussite et la distribution de la latence restent dans des limites acceptables avant de basculer l'ensemble du trafic.
Impact sur les entreprises
La priorité des entreprises reste le SLA et la conformité. La mise à jour vers grok-4.3 couvre l'ensemble des cas d'usage des 8 anciens modèles, ce qui simplifie la matrice de sélection et facilite la gouvernance (registre des modèles, audit, conformité). Cependant, le département financier doit revoir les budgets et les règles de déduction, notamment pour les forfaits de jetons mensuels et les remises sur engagement, qui pourraient être invalidés par l'unification de la tarification. Côté exploitation, il est crucial de mettre à jour les seuils d'alerte pour éviter toute hausse inattendue de la facture en mai.
Pour les scénarios impliquant plusieurs modèles, nous conseillons d'agréger les coûts de Grok, Claude et GPT dans une vue unifiée, avec une répartition par département ou ligne de métier, afin d'atténuer l'impact des itérations fréquentes sur le contrôle budgétaire. Ce retrait massif rappelle également aux entreprises que le risque lié à un fournisseur unique ne se limite pas à une interruption de service, mais aussi aux coûts cachés liés au « changement de moteur sous un même identifiant (slug) ».
Impact sur l'industrie
Le choix de xAI de retirer 8 modèles d'un coup signale que la combinaison « raisonnement permanent + contexte de 1M » de grok-4.3 est désormais suffisamment polyvalente pour gérer le raisonnement, la conversation, le code et l'invocation d'outils. Cette tendance, alignée sur la stratégie de Claude et OpenAI visant à unifier les « modèles de raisonnement » et les « modèles d'instruction », montre que la mise sur le marché des grands modèles de langage entre dans une ère de « modèle phare unique ». Les développeurs disposeront d'une matrice plus restreinte, mais avec des capacités et une élasticité tarifaire accrues.
Une autre tendance notable est la généralisation du « raisonnement activé par défaut + niveaux d'effort ». Cette approche redonne aux développeurs le choix entre latence et coût, à condition que les SDK et les plateformes de monitoring supportent nativement le champ effort. Pour les services proxy API et les plateformes d'agrégation, la gestion du cycle de vie des modèles devient une compétence clé. APIYI (apiyi.com) a déjà synchronisé la documentation de migration de Grok dans sa console et envoyé des notifications de fin de vie pour les slugs concernés afin d'aider les développeurs à ne rien oublier.
Instructions de retrait sur APIYI
Afin de rester aligné avec la stratégie officielle de xAI et d'éviter toute confusion tarifaire, APIYI (apiyi.com) a mis en place un plan de retrait avec une transition fluide pour les utilisateurs appelant encore les anciens slugs. La console permet désormais de consulter, par compte, le nombre d'appels et la part des coûts pour chaque slug retiré au cours des 30 derniers jours, offrant ainsi une vision globale avant la migration.
| Phase | Date | Action APIYI |
|---|---|---|
| Période d'alerte | Avant le 15/05/2026 | Bannière dans la console, notification par e-mail aux comptes concernés |
| Période de redirection | À partir du 15/05/2026 12:00 PT | Redirection automatique des anciens slugs vers grok-4.3, avec marquage deprecated dans les en-têtes |
| Retrait complet | Selon le calendrier xAI | Suppression des options des anciens slugs dans la console |
Les développeurs n'ont pas besoin de changer la base_url, il suffit de remplacer le champ model par grok-4.3 dans les paramètres de la requête. Si votre activité utilise à la fois des appels avec et sans raisonnement, nous recommandons d'ajouter une option effort dans votre couche d'encapsulation SDK pour faciliter la gestion lors des tests de charge et des tests A/B. Voici un exemple complet que vous pouvez copier dans votre projet pour vérification :
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Expliquez le raisonnement permanent (always-on reasoning) en 200 mots"}
],
extra_body={"reasoning_effort": "low"}
)
print(response.choices[0].message.content)
Voir la version Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "grok-4.3",
messages: [{ role: "user", content: "Résumé des points clés de la migration vers grok-4.3" }],
// @ts-expect-error champ supplémentaire xAI
reasoning_effort: "low",
});
console.log(completion.choices[0].message.content);
🚀 Conseils de migration : Avant de migrer, nous vous recommandons d'utiliser le panneau de « Comparaison de modèles » sur APIYI (apiyi.com) pour envoyer la même invite à
grok-4.3et à l'ancien modèle. Comparez la qualité des réponses et la latence initiale avant de définir le niveau d'effort de raisonnement optimal.
Foire aux questions
Q1 : Les anciens slugs seront-ils toujours utilisables après le 15 mai ?
Oui, mais le modèle réellement exécuté sera grok-4.3, et la facturation sera basée sur les nouveaux tarifs de grok-4.3 (1,25 $ / 2,50 $). Nous vous recommandons de mettre à jour le champ model dans votre code vers grok-4.3 dès que possible afin d'éviter toute augmentation inattendue de votre facture mensuelle.
Q2 : grok-code-fast-1 est-il toujours adapté à la complétion de code après la migration ?
grok-4.3 affiche de meilleurs résultats que grok-code-fast-1 sur LiveCodeBench et SWE-bench, offrant une capacité de codage globale supérieure, bien que la latence et le prix unitaire soient plus élevés. Nous vous conseillons de tester la latence P95 et la consommation moyenne de jetons par PR avec vos échantillons métier réels avant de décider s'il reste adapté à la complétion en ligne.
Q3 : Dois-je demander une nouvelle clé API sur la plateforme APIYI ?
Non, votre clé APIYI existante est directement compatible avec les nouveaux modèles comme grok-4.3, et la base_url reste inchangée. Il vous suffit d'ajuster le nom du modèle dans le corps de votre requête. La liste complète des modèles et leur état sont disponibles sur la console APIYI apiyi.com.
Q4 : Quelles sont les précautions à prendre pour la migration du modèle de génération d’images grok-imagine-image-pro ?
Les requêtes seront redirigées vers grok-imagine-image-quality. Le style visuel, la graine d'échantillonnage (seed) et les paramètres par défaut diffèrent. Nous vous recommandons d'exécuter vos invites historiques dans un environnement de bac à sable pour confirmer la stabilité des résultats avant la mise en production, afin d'éviter tout changement soudain dans vos images métier.
Conclusion
xAI retire huit modèles principaux, dont fast-reasoning, fast-non-reasoning, grok-code-fast-1, grok-3 et grok-imagine-image-pro. À partir du 15 mai à 12h00 PT, tout basculera vers grok-4.3 et grok-imagine-image-quality. Bien que la migration technique soit légère, les changements de prix unitaires et de facturation des jetons de raisonnement auront un impact significatif sur les activités sensibles aux coûts. Nous vous conseillons de prioriser trois actions : mettre à jour le champ model dans votre code de production vers grok-4.3, transmettre explicitement reasoning_effort pour contrôler la latence et les coûts, et effectuer une estimation des coûts de bout en bout avec des échantillons métier réels.
Notre conseil est de considérer cette mise à niveau comme une opportunité de gouvernance : utilisez APIYI apiyi.com pour comparer la latence et les coûts entre grok-4.3, Claude, GPT et d'autres modèles. Passer d'une approche où vous suivez le rythme du fournisseur à une sélection basée sur vos indicateurs métier sera plus stable sur le long terme et vous permettra de limiter les coûts de bascule à quelques heures lors de la prochaine annonce de retrait massif.
Auteur : Équipe APIYI — APIYI apiyi.com, service proxy API pour grands modèles de langage, offrant un accès unifié aux modèles leaders tels que Grok, Claude, GPT et Gemini.