In 2026, an independent Austrian developer created an open-source project in their spare time over a weekend. In just two months, it garnered 247,000 GitHub Stars, becoming an AI agent platform eagerly adopted by companies in Silicon Valley and China.
This project is called OpenClaw.
Meanwhile, a question emerged: In real-world agent scenarios like OpenClaw, which AI model performs best?
This is precisely the problem PinchBench aims to solve. It's OpenClaw's official evaluation benchmark, developed by the kilo.ai team using Rust. It replaces synthetic tests with real-world tasks, providing developers with a trustworthy basis for model selection.
This article starts with the rise of OpenClaw, then dives deep into the PinchBench evaluation system to help you understand the true meaning of AI benchmarks and how to choose the right model for your agent workflow based on the evaluation data.
I. What is OpenClaw: An Open-Source Phenomenon That Changed Its Name 3 Times in a Month
The Birth of OpenClaw and Its Naming Saga
The story of OpenClaw begins in November 2025.
Austrian developer Peter Steinberger built an AI agent platform in his spare time, initially naming it Clawdbot. The core idea behind this project was simple: to make AI more than just a chatbot, enabling it to truly take over your digital workflow—reading emails, writing code, managing calendars, and searching for information.
But the concept of an AI Agent isn't new, so why did OpenClaw explode overnight?
The key was the dual boost of timing and open-source. In late January 2026, with the viral spread of the Moltbook project, the entire tech community's desire for "AI that actually gets things done" reached its peak, and Clawdbot rode this wave to become a focal point.
However, it soon received a trademark objection notice from Anthropic—the "Clawd" in Clawdbot was deemed to pose a risk of confusion with an internal Anthropic product name. The project was forced to urgently rename itself Moltbot on January 27, 2026, paying homage to the Moltbook project that was also gaining popularity at the time.
Just three days later, Steinberger admitted on GitHub that the new name "never quite rolled off the tongue." The project was renamed again to OpenClaw, a name it has kept ever since.
This naming saga, ironically, became the project's best "free marketing," making OpenClaw widely known within the developer community.
As of March 2, 2026, OpenClaw has accumulated on GitHub:
- ⭐ 247,000 Stars (nearly half the stars of the React framework during the same period)
- 🍴 47,700 Forks
- 🌍 Widespread deployment in companies across Silicon Valley, Europe, and China
OpenClaw's Core Technical Architecture
OpenClaw's design philosophy is: local execution, model-agnostic, and message app integration.
These three characteristics define its fundamental differences from other AI Agent frameworks.
Local execution means your data doesn't pass through any third-party servers. Unlike most SaaS-based AI assistants, OpenClaw is deployed on the user's own device, and Large Language Model API invocations can also point to private endpoints.
Model-agnostic means OpenClaw itself isn't tied to any specific Large Language Model. It acts as a "brain shell," supporting integration with any mainstream model like Claude, GPT, or DeepSeek. Developers can freely switch based on task type and cost budget.
Message app integration is OpenClaw's most distinctive design—regular users don't need to open any dedicated app; they can directly invoke AI Agent capabilities by sending messages in Signal, Telegram, Discord, or WhatsApp. This significantly lowers the barrier to entry, allowing non-technical users to benefit.
| Design Dimension | OpenClaw's Choice | Mainstream Alternatives | Difference Explanation |
|---|---|---|---|
| Deployment Location | Local Execution | Cloud SaaS | Stronger data privacy, but requires self-maintenance |
| Model Binding | Completely Agnostic | Bound to Specific Model | Flexible switching, but requires self-configuration |
| User Interface | Message Apps | Dedicated Web/App | Low barrier to entry, functionality limited by message app |
| Permission Scope | Broad Access | Sandbox Restrictions | Powerful features, but higher security risks |
| Open-Source License | Fully Open-Source | Closed-Source/Partially Open-Source | Community-driven, but limited support guarantees |
🎯 Usage Tip: Deploying OpenClaw requires configuring a high-quality Large Language Model backend.
We recommend integrating Claude Sonnet 4.6 or GPT-5.4 via APIYI (apiiyi.com).
Both models perform excellently in PinchBench, and APIYI supports unified interface switching,
making it easy for you to quickly compare different model effects without modifying OpenClaw's core configuration.
OpenClaw's Capability Boundaries
OpenClaw supports a wide range of capabilities, but this has also sparked security concerns:
Accessible Data Sources:
- Email accounts (read, classify, draft replies)
- Calendar systems (view, create, modify events)
- File systems (browse, read, create, move files)
- Code repositories (read code, run tests, commit changes)
- Messaging platforms (cross-platform message aggregation and response)
- Web information (search, summarize, structured extraction)
Typical Use Case:
User sends in Telegram: "Help me organize today's emails,
mark those that need a reply today, and draft the replies."
OpenClaw Agent execution flow:
1. Call email tool, read today's unread emails
2. Use Large Language Model to determine urgency of each email
3. Filter out emails requiring a reply today
4. Generate a reply draft for each email
5. Return organized results and draft previews in Telegram
This ability to "truly get things done" is the fundamental difference between OpenClaw and simple chatbots.
Steinberger Joins OpenAI and the Project's Future
On February 14, 2026, a piece of news shook the entire open-source community: Steinberger announced on GitHub that he would be joining OpenAI, and the project would be handed over to an independent open-source foundation.
This had a dual impact on OpenClaw: on one hand, the project gained more professional operation and legal protection; on the other hand, outsiders began to speculate about OpenAI's motives for acquiring the founder—was it for technology absorption, or to prevent a potential competitor?
Currently, the OpenClaw Foundation has been established, and the project remains fully open-source, but there's a clear shift in the development roadmap's priorities: enterprise-grade security features and a permission control system are the focus for the next version.
Security Concerns: Risks from Powerful Capabilities
OpenClaw's extensive demand for system permissions raised concerns among cybersecurity researchers from the outset.
In March 2026, Chinese authorities announced restrictions on state-owned enterprises and government agencies running OpenClaw on office computers, primarily due to concerns including:
- Data potentially leaking to overseas service providers through Large Language Model API invocations
- Broad permissions potentially becoming attack vectors if misconfigured
- Internal corporate sensitive information possibly being transmitted across systems by the Agent
This incident reminds all enterprise developers: when introducing powerful Agent tools, the principle of least privilege and audit logs are non-negotiable security fundamentals.
II. The True Role of Benchmarks in the AI Industry: From Exams to Real-World Application
Why the AI Industry Can't Do Without Benchmarks
If you've ever tried to compare the capabilities of two AI models, you've likely encountered a dilemma: vendors all claim their model is the "strongest," but what does "strong" mean? For what tasks? Compared to what baseline?
A Benchmark is a standardized testing system designed to solve this very problem.
In the AI industry, a good Benchmark needs to meet three conditions:
- Reproducibility: Anyone using the same test set should get the same results.
- Representativeness: The test content should reflect the capability requirements of real-world use cases.
- Fairness: The test set should not be contaminated by the model developer's training data.
In 2026, there were over 15 mainstream Benchmarks actively in use across the industry, but experts estimate only about 4 of them can truly predict performance in a production environment.

Limitations of Traditional Benchmarks
To understand the value of PinchBench, we first need to understand why traditional Benchmarks aren't "enough."
MMLU (Massive Multitask Language Understanding)
MMLU is currently the most widely cited general knowledge evaluation, covering 57 subjects with approximately 14,000 multiple-choice questions. Questions span fields like medicine, law, history, mathematics, and programming.
The problem is: these are multiple-choice questions, where the model only needs to select one out of four options. In actual Agent scenarios, the model needs to autonomously generate answers, and even invoke tools to retrieve information—this is completely different from "choosing one out of four options."
HumanEval (Code Generation Test)
HumanEval is a landmark Benchmark for measuring code generation capabilities, containing 164 Python programming problems. However, its problems are relatively fixed, and models might have encountered similar types during training, leading to a "cramming effect"—a high score doesn't necessarily reflect true programming ability.
Common Pitfalls of Synthetic Tests:
| Problem Type | Specific Manifestation | Impact on Evaluation Results |
|---|---|---|
| Data Contamination | Training set includes test questions | High scores don't reflect true generalization ability |
| Cramming Effect | Model optimized for specific Benchmark | Inflated rankings, no actual capability improvement |
| Scenario Disconnect | Multiple-choice questions differ greatly from real-world use | Poor predictive power for rankings |
| Static Dataset | Fixed questions, cannot be updated | New capabilities cannot be assessed |
| Single-Dimension Evaluation | Only focuses on accuracy | Ignores speed, cost, reliability |
5 Core Dimensions for AI Agent Evaluation
As AI systems evolve from "answering questions" to "completing tasks," the evaluation system must also upgrade.
For AI agent platforms like OpenClaw, evaluations need to cover the following 5 key dimensions:
Dimension 1: Task Completion Rate
The overall success rate from receiving a task to its final completion. This is the most intuitive metric, but also the most complex—the definition of "completion" itself is a core challenge in evaluation design.
Test Method: Give the Agent a complex task involving 3-5 steps, and record the proportion of fully successful, partially successful, and failed attempts.
Dimension 2: Tool Call Accuracy
The Agent needs to select the correct tool from dozens of available options and invoke it with the right parameters. Incorrect tool invocations aren't just failures; they can also have side effects (e.g., accidentally deleting files, sending incorrect emails).
Test Method: Design tasks that require a specific sequence of tools, and record the error rate for tool selection and parameter usage.
Dimension 3: Multi-step Reasoning Coherence
Completing a task often requires 5-10 steps, and the Agent needs to maintain a clear understanding of the goal throughout the process, not "wander off track."
Test Method: Design long-flow tasks requiring 10+ steps, and observe whether goal drift or logical breaks occur midway.
Dimension 4: Cross-turn Context Retention
In multi-turn conversations, the Agent needs to remember previously exchanged information. Information like "you mentioned last time we'd have a meeting on Wednesday" is crucial in OpenClaw's workflow.
Test Method: Design task scenarios that require referencing information from 5+ turns prior, and record the context loss rate.
Dimension 5: Hallucination Rate
Agents fabricating non-existent files, non-existent contacts, or incorrect dates are minor issues in chat, but in Agent scenarios, they can cause real losses (e.g., sending emails with incorrect content).
Test Method: Design tasks that require referencing real data (filenames, email addresses, dates), and record the frequency of hallucinations.
🎯 Developer Recommendation: When choosing an Agent model, task completion rate and tool call accuracy are the two most important metrics.
We recommend using the APIYI (apiiyi.com) platform to quickly integrate multiple models and validate their effectiveness on your actual tasks across these 5 dimensions,
rather than solely relying on leaderboard numbers. APIYI supports pay-as-you-go billing, which is ideal for small-scale A/B testing before final selection.
3. PinchBench Deep Dive: OpenClaw's Official Evaluation Standard
The Genesis of PinchBench
PinchBench was developed by the kilo.ai team using Rust, specifically tailored as an evaluation benchmark for OpenClaw scenarios, and open-sourced on GitHub (pinchbench/skill repository).
The core problem it addresses: General model leaderboards have weak predictive power for real-world Agent performance.
Research has shown that a model ranking in the top 5% on MMLU might perform significantly worse in OpenClaw's email classification + meeting scheduling combined tasks than a model with a mediocre MMLU ranking but specifically optimized for tool invocation.
PinchBench's emergence provides developers with a credible evaluation basis specifically for Agent workflows for the first time.
PinchBench's 23 Task Categories
PinchBench uses real-world tasks instead of synthetic problems, covering 23 task categories, each corresponding to a genuine use case for OpenClaw users:
Core Task Categories (6 major types):
| Task Category | Specific Test Content | Involved Tools | Evaluation Difficulty |
|---|---|---|---|
| Schedule Management | Meeting scheduling, conflict resolution, timezone handling, recurring reminders | Calendar API, timezone tools | ★★★☆☆ |
| Code Writing | Feature implementation, bug fixing, code refactoring, unit testing | Code execution, file system | ★★★★☆ |
| Email Processing | Classification, prioritization, auto-reply drafting, attachment handling | Email client API | ★★★☆☆ |
| Information Research | Web search, information aggregation, summary generation, source verification | Search engine, browser | ★★★★☆ |
| File Management | Organization, format conversion, batch operations, version control | File system, conversion tools | ★★☆☆☆ |
| Multi-tool Collaboration | Cross-platform data transfer, toolchain orchestration, conditional triggers | Multiple tool combinations | ★★★★★ |
PinchBench's Evaluation Methodology
PinchBench employs a dual evaluation mechanism, balancing objectivity with quality assessment:
Automated Checks
Used for verifiable objective criteria:
- Whether the code passes all test cases
- Whether files are correctly moved to the specified location
- Whether calendar events are created at the correct time
- Whether API calls return the expected format
LLM Judge
Used for qualitative assessment requiring subjective judgment:
- The tone and professionalism of email replies
- The accuracy and completeness of information in research reports
- The accuracy of task understanding (whether the user's intent was truly grasped)
- The reasonableness of handling strategies for edge cases
This combined approach balances efficiency (automated checks can run at scale) and quality (LLM judges capture details that are hard for humans to quantify).
Three-Dimensional Evaluation Metric Matrix:
┌─────────────────────────────────────────────────┐
│ PinchBench Three-Dimensional Evaluation System│
├─────────────────────────────────────────────────┤
│ Success Rate │
│ → Comprehensively measures task completion quality│
│ → Primary ranking dimension │
│ → Combines automated checks + LLM Judge │
├─────────────────────────────────────────────────┤
│ Speed │
│ → Average time to complete tasks (seconds/minutes)│
│ → Crucial for real-time response scenarios │
│ → Includes API latency and inference time │
├─────────────────────────────────────────────────┤
│ Cost │
│ → Token cost (USD) consumed to complete tasks │
│ → Key metric for high-frequency use cases │
│ → Helps calculate ROI and model selection decisions│
└─────────────────────────────────────────────────┘
As of March 13, 2026, PinchBench's public leaderboard data shows:
- 📊 49 models evaluated, covering all mainstream commercial and open-source models
- 🔄 327 run records, continuously updated
- 🌐 Public leaderboard: pinchbench.com (real-time updates)
- 📁 Open-source repository: github.com/pinchbench/skill (task definitions are public)
🎯 PinchBench Usage Tip: When viewing the leaderboard, we recommend switching between the success rate, speed, and cost views,
to filter for the most suitable model based on your actual needs (real-time vs. quality vs. cost).
After integrating through APIYI apiyi.com, you can easily compare the actual costs of different models within the same business scenario.
4. PinchBench Leaderboard Deep Dive and Model Selection Guide
Current Top 5 Success Rate Ranking (Data as of March 13, 2026)
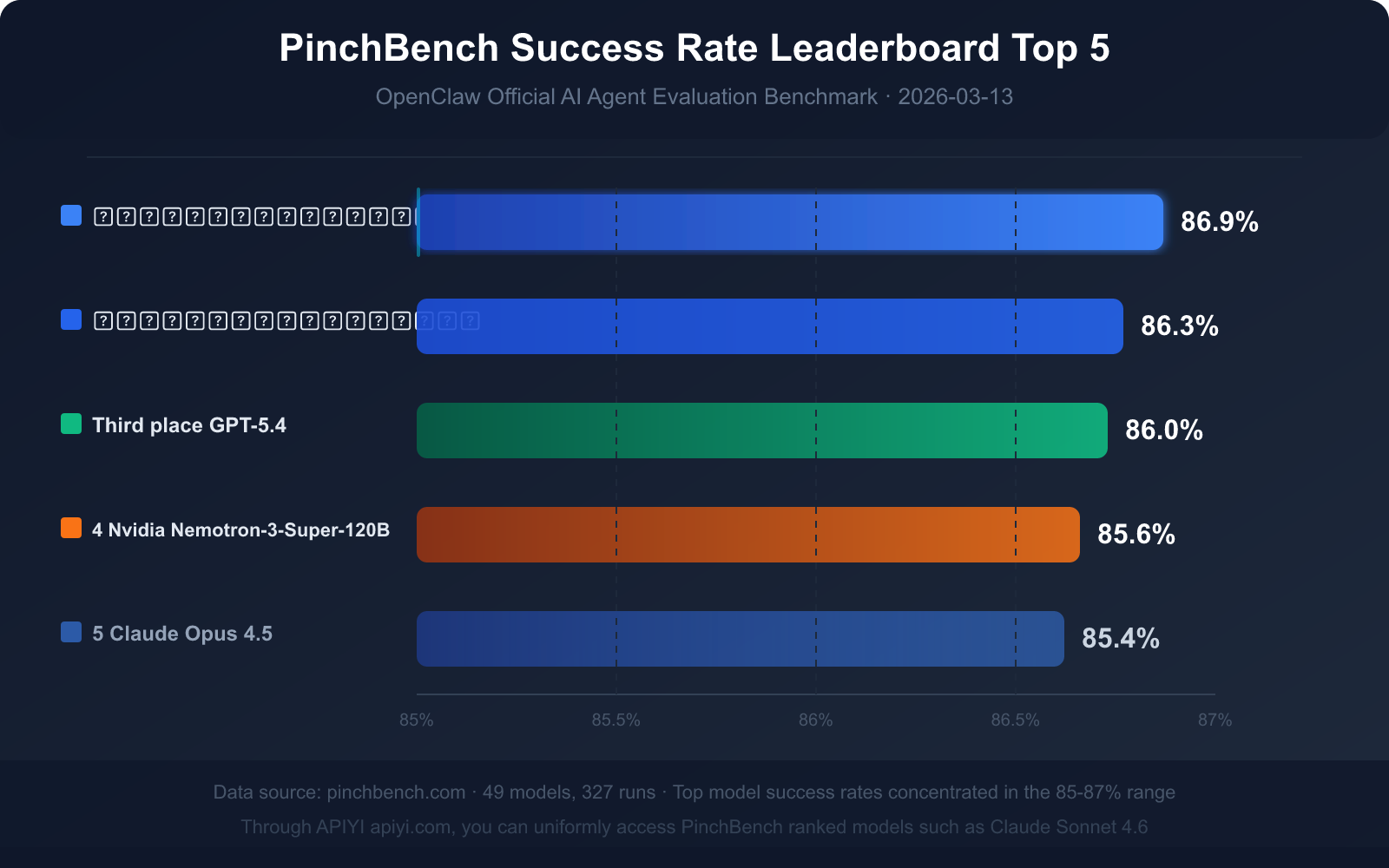
| Rank | Model Name | Success Rate | Model Type | Key Advantage |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Commercial Closed-source | Highest success rate, balanced speed and quality |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Commercial Closed-source | Strongest complex reasoning ability |
| 🥉 3 | GPT-5.4 | 86.0% | Commercial Closed-source | Good tool invocation stability |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Open-source Deployable | Best performing among open-source models |
| 5 | Claude Opus 4.5 | 85.4% | Commercial Closed-source | Previous generation flagship, still competitive |
Key Data Insight: What Does an 85% Success Rate Mean?
Top models on PinchBench achieve success rates primarily in the 85%-87% range, rather than near-perfect scores. This figure itself conveys three important signals:
Signal 1: AI Agent Tasks Remain Highly Challenging
Even the top-ranked Claude Sonnet 4.6 (86.9%) still fails about 13 out of 100 tasks. This isn't necessarily a lack of model capability, but rather the inherent complexity of real-world tasks—ambiguous instructions, incomplete information, and edge cases in tool invocation can all lead to failures.
Signal 2: Fault-Tolerant Design is Indispensable in Agent Development
When a 13% failure rate is considered "top-tier," fully automated Agent processes without human review nodes are high-risk in production environments. The best practice is to: retain human confirmation steps for high-risk operations (e.g., sending emails, submitting code).
Signal 3: Minimal Gap Between Models, Task Design is More Crucial
The gap between rank 1 and rank 5 is only 1.5 percentage points (86.9% vs 85.4%). This implies that the impact of choosing one model over another is far less significant than how you design the task prompt, define tool interfaces, or handle error conditions.
Three-Dimensional Metric Comprehensive Analysis
Looking solely at success rate isn't enough. Here's a comprehensive consideration framework across the three dimensions:
| Use Case | Primary Metric | Secondary Metric | Recommended Model Direction |
|---|---|---|---|
| High-frequency lightweight tasks (email classification, reminders) | Speed + Cost | Success Rate | Lightweight models like Claude Haiku 4.5 |
| Complex engineering tasks (code refactoring, research) | Success Rate | Speed | Claude Sonnet 4.6 / GPT-5.4 |
| Real-time response scenarios (instant assistant) | Speed | Success Rate | Top models on the speed leaderboard |
| Cost-sensitive applications | Cost | Success Rate | Open-source self-deployed / Low-cost API models |
| Enterprise security and compliance | Success Rate + Controllability | Cost | Privately deployed open-source models |
🎯 Comprehensive Model Selection Advice: Based on PinchBench data, Claude Sonnet 4.6 is currently the best overall choice for OpenClaw scenarios, offering the highest success rate.
For cost-sensitive, high-frequency scenarios, we recommend first establishing a task success rate baseline with Claude Sonnet 4.6,
then testing if lighter models can significantly reduce costs within an acceptable success rate range.
All these tests can be performed through APIYI apiyi.com's unified API interface, eliminating the need to register multiple service provider accounts separately.
Open-Source Model Competitiveness Analysis
Nvidia Nemotron-3-Super-120B ranks 4th with a success rate of 85.6%, only 1.3 percentage points lower than the top spot—this is a very impressive achievement for an open-source model.
Advantages of Open-Source Models:
- Data Sovereignty: Both models and data are within your controlled environment, meeting compliance requirements.
- Cost Structure: One-time GPU investment, no subsequent API invocation fees (for high-volume scenarios).
- Customization Scope: Can be fine-tuned for specific tasks.
Limitations of Open-Source Models:
- Deployment Cost: A 120B parameter model requires 4-8 A100/H100 GPUs.
- Maintenance Burden: Model updates and version management require dedicated operations personnel.
- Initial Testing Cost: Before confirming an open-source model is suitable for your scenario, prototyping with commercial APIs is often more economical.
V. Practical Guide: How to Configure the Optimal Model in OpenClaw
Quickly Integrate Claude Sonnet 4.6 to Drive OpenClaw
Here's a complete configuration example for integrating the top-ranked PinchBench model via APIYI:
Step 1: Get Your API Key
Visit the APIYI official website, apiyi.com, register an account, and go to the console to get your API key. APIYI provides OpenAI-compatible interfaces and also supports Anthropic's native SDK.
Step 2: Configure OpenClaw's Model Backend
# OpenClaw configuration example (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Maximum number of execution steps
tool_timeout: 30 # Timeout for a single tool invocation (seconds)
retry_on_error: true # Automatically retry on tool invocation failure
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # High-risk operations require human confirmation
Step 3: Verify Configuration
# Test connection using Anthropic SDK
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Send a test request
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "Please list 3 types of tasks you can perform in OpenClaw"
}]
)
print(response.content[0].text)
Step 4: Multi-model A/B Testing Configuration
# Compare different models on the same task (recommended before official deployment)
models_to_test = [
"claude-sonnet-4-6", # Ranked #1 on PinchBench
"gpt-5.4-turbo", # Ranked #3 on PinchBench (OpenAI-compatible format)
"claude-opus-4-5", # Previous generation flagship, for cost comparison
]
# APIYI supports unified API invocation for all the above models
# base_url remains unchanged, only the model parameter needs to be modified
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: Success Rate={result.success_rate}, Time Taken={result.avg_time}s, Cost=${result.cost_per_task}")
🎯 Quick Start: Visit APIYI at apiyi.com to register and get test credits.
It supports unified API access for PinchBench-listed models like Claude Sonnet 4.6 and GPT-5.4,
eliminating the need to apply for access from multiple service providers and significantly lowering the initial barrier for model testing.
Self-test Your Agent with PinchBench's 5 Dimensions
Before deploying to a production environment, we recommend evaluating your Agent configuration using the following self-test checklist:
PinchBench-Inspired Agent Self-Test Checklist
□ Dimension 1 - Task Completion Rate
Give the Agent 10 complex tasks with 3+ steps
Record the number of fully successful / partially successful / failed tasks
Goal: Full success rate ≥ 80%
□ Dimension 2 - Tool Invocation Accuracy
Check tool invocation logs and count the following error types:
- Incorrect tool selection (chose the wrong tool)
- Parameter format error (incorrect parameter type or format)
- Parameter value error (correct type but unreasonable value)
Goal: Tool error rate ≤ 5%
□ Dimension 3 - Multi-step Reasoning Coherence
Design a long-flow task requiring 15+ steps
Observe if goal drift occurs midway (forgot the initial goal)
Goal: No goal drift in long-flow tasks
□ Dimension 4 - Context Retention
Provide key information in round 1, reference it in round 8
Check if the Agent can correctly reference it
Goal: Cross-round reference accuracy ≥ 90%
□ Dimension 5 - Hallucination Detection
Design tasks requiring reference to real data (filenames/contacts/dates)
Check if the Agent fabricates non-existent data
Goal: Hallucination rate ≤ 2%
VI. The Future of AI Benchmarks: From Single-Point Evaluation to Ecosystem Assessment
Evolution Trends in Current Benchmark Systems
In 2026, the AI benchmark landscape is undergoing a profound transformation. At the core of this shift is the expansion of evaluation targets from single models to complete Agent systems.
Traditional benchmarks operate on the principle of giving a model a problem and seeing if it answers correctly. However, with the widespread adoption of Agent platforms like OpenClaw, the truly important question becomes: Can the model, acting as the "brain" of a system, enable that system to get work done?
The answer to this question depends not only on the model's knowledge base but also on:
- The model's ability to understand tool descriptions
- The model's decision-making strategy under uncertain information
- The model's ability to identify and recover from errors
- The model's ability to track user intent over the long term
PinchBench's value lies in its ability to quantify and publicly display these dimensions.
Correct Usage of AI Benchmark Data
Benchmark data is valuable, but it's also easy to misuse. Here are some common misconceptions and correct practices:
Misconception 1: Assuming the highest-ranked model is "always the best."
Correct Practice: Rankings are based on PinchBench's specific task set, and your tasks might have different weighting. Test on your own tasks first before making a selection.
Misconception 2: Only looking at success rate, ignoring speed and cost.
Correct Practice: All three metrics are essential. In batch processing scenarios, a 50% difference in speed means a 50% cost saving; in real-time response scenarios, a 2-second difference in speed means a significant drop in user experience.
Misconception 3: Believing a 1% difference in success rate is insignificant.
Correct Practice: A 1% success rate difference might seem negligible in small-scale tests, but in high-frequency production scenarios, it could lead to hundreds of failures daily. You need to evaluate the actual impact based on your task volume.
Misconception 4: Using static benchmark data for long-term planning.
Correct Practice: AI models iterate extremely quickly, with major vendors releasing significant updates roughly every quarter in 2026. It's advisable to incorporate model performance evaluation into regular technical reviews, rather than a "one-time selection for life."
Best Practices for Enterprise-Grade Agent Evaluation
For technical teams deploying OpenClaw or similar Agent platforms in an enterprise setting, here's a set of actionable evaluation best practices:
Step 1: Establish a Baseline Task Set
Select 20-50 typical tasks from your actual business operations, covering both daily high-frequency operations and occasional complex scenarios. This task set should be jointly defined by business and technical stakeholders to avoid evaluation bias caused by a purely technical perspective.
Step 2: Continuous Tracking of Three-Dimensional Metrics
Recommended Enterprise Internal Agent Evaluation Metric System
Core Metrics (Weekly Statistics):
- Task Completion Rate: Goal ≥ 85% (benchmarking against top PinchBench models)
- Tool Invocation Error Rate: Goal ≤ 5%
- Average Task Duration: Defined according to business SLA
Auxiliary Metrics (Monthly Statistics):
- Token Cost/Task: Control operational costs
- Human Intervention Rate: Percentage of tasks requiring human takeover
- Error Type Distribution: Analyze areas for improvement
Alert Metrics (Real-time Monitoring):
- High-Risk Operation Failure Rate: Immediate alert for failures like sending emails/deleting files
- Hallucination Events: Fabricated information needs immediate logging and analysis
Step 3: Regular Model Re-evaluation
We recommend re-evaluating currently deployed models, as well as newly released candidate models, using your internal task set every quarter. Combine this with PinchBench's latest public data to determine if a model upgrade or switch is necessary.
Step 4: Accumulate Domain Knowledge
General benchmarks can't cover every enterprise's unique scenarios. As you gain experience, gradually build a task set and scoring criteria tailored to your business. This will become a crucial screening tool for selecting AI vendors.
🎯 Enterprise Selection Tip: When initially adopting an Agent platform, we recommend using APIYI (apiyi.com) to access multiple candidate models on a pay-as-you-go basis.
Conduct 3-4 weeks of real-world testing with your internal task set before deciding whether to migrate to a monthly subscription plan.
APIYI supports a unified interface for mainstream models like Claude, GPT, and Gemini,
significantly reducing the management cost of evaluation during the testing phase by eliminating the need to register separate accounts with multiple service providers.
Frequently Asked Questions
Q: What are the core differences between OpenClaw and AutoGPT, AutoGen?
OpenClaw's core difference lies in its access method and ease of use: it provides an Agent interface through messaging apps (Signal, WhatsApp, etc.), so regular users don't need to install a dedicated app or understand technical details. From a technical architecture perspective, OpenClaw is closer to a "personal AI assistant," while frameworks like AutoGen are more suitable for developers building complex multi-Agent systems. OpenClaw emphasizes an "out-of-the-box consumer experience," while AutoGen focuses on a "flexible enterprise-grade development framework."
🎯 No matter which Agent framework you choose, you can unify your backend model access through APIYI apiyi.com, avoiding the need to configure separate API keys for each framework.
Q: How often is PinchBench's success rate ranking updated?
The PinchBench leaderboard is updated in real-time—whenever a new model completes evaluation, the data is immediately reflected on pinchbench.com. As major vendors continuously release new versions, rankings will change frequently. We recommend checking the latest data before making your final model selection. The data in this article is based on a snapshot from March 13, 2026 (49 models, 327 run records).
Q: How do I choose the most suitable model for OpenClaw?
We recommend a three-step selection process:
- Check PinchBench success rates: Filter for the Top 5 task completion rates.
- Consider speed and cost: Filter further based on your task type (real-time vs. batch processing, high-frequency vs. low-frequency).
- Perform actual A/B testing: Compare 2-3 candidate models on your real-world business tasks.
With APIYI apiyi.com, you can quickly switch between different models using the same
base_url, allowing you to complete A/B testing before making a final decision.
Q: Can open-source models completely replace commercial models for driving OpenClaw?
Looking at PinchBench data, Nvidia Nemotron-3-Super-120B (85.6%) is about 1.3 percentage points behind top commercial models (86.9%). For general Agent tasks, this gap might be acceptable. However, it's important to note: self-deploying a 120B parameter model requires 4-8 high-end GPUs, meaning initial hardware investment and operational costs aren't low. We recommend first validating your Agent design's feasibility with commercial APIs, then evaluating whether it's worth migrating to a self-deployed open-source model.
Q: How can I mitigate OpenClaw's security risks?
The core principle is least privilege: only grant OpenClaw the minimum permissions required to complete its tasks. Specific recommendations include:
- Read-only email access (instead of full read, write, delete permissions)
- Read-only + PR submission access for code repositories (instead of direct pushes to the main branch)
- File system access limited to specific working directories (instead of the entire file system)
- High-risk operations (sending emails, deleting files) must include a human confirmation step
For enterprise deployments, you'll also need to configure comprehensive operational audit logs to ensure every Agent action has a traceable record.
Q: What's the difference between PinchBench and other Agent Benchmarks?
PinchBench's biggest characteristic is its scenario specificity: it's designed specifically for OpenClaw's use cases, rather than for general Agent evaluation. This means it has higher reference value for OpenClaw users but isn't suitable for directly evaluating model choices for other Agent frameworks. Other well-known Agent Benchmarks include AgentBench (covering various environments), SWE-Bench (focused on coding tasks), and so on, each with its own emphasis.
Summary: OpenClaw + PinchBench Set New Standards for the Agent Era
OpenClaw, which started as a weekend project by an Austrian developer, grew into one of the world's hottest AI Agent platforms within two months. This reflects the industry's strong desire for "AI that actually gets things done."
The emergence of PinchBench, on the other hand, fills a critical gap in Agent evaluation: we finally have a dedicated ruler to measure Agent capabilities.
Key Takeaways at a Glance:
- Claude Sonnet 4.6 is currently the overall best choice for OpenClaw scenarios (86.9% success rate, ranked first on PinchBench).
- Top models' success rates are concentrated between 85-87%, indicating that Agent tasks remain challenging and fault-tolerant design is indispensable.
- Speed and cost are equally important; a high success rate model isn't necessarily suitable for all scenarios, requiring a comprehensive three-dimensional evaluation.
- PinchBench represents the future direction of AI evaluation: real-world scenario tasks are replacing synthetic tests.
- Model selection differences are about 1-2%, while the impact of task design and prompt engineering is often greater.
For developers and enterprises looking to dive into the OpenClaw ecosystem, now is an excellent time:
The open-source community is active, evaluation tools are robust, and the cost of API access for mainstream models continues to decrease. You don't need to wait for a "perfect solution"; you can start validating the feasibility of Agent workflows with small-scale tasks right now.
🎯 Act Now: If you're building an AI workflow based on OpenClaw, we recommend unifying your access through APIYI apiyi.com.
The platform supports mainstream models like Claude Sonnet 4.6 (PinchBench #1) and GPT-5.4 (#3).
With a single API interface, you don't need to register with multiple service providers separately. It supports pay-as-you-go billing, making it suitable for starting with small-scale tests and gradually expanding.
Visit the APIYI official website at apiyi.com to register and start experiencing it.
The data in this article is compiled based on public information from March 2026. For real-time PinchBench leaderboard data, please visit pinchbench.com for the latest version.
Author: APIYI Team | For more details on AI model API access, please visit APIYI apiyi.com