En 2026, un projet open source créé par un développeur indépendant autrichien pendant ses week-ends a recueilli 247 000 étoiles sur GitHub en deux mois, devenant ainsi une plateforme d'agents IA que les entreprises de la Silicon Valley et de Chine s'arrachent.
Ce projet s'appelle OpenClaw.
Parallèlement, une question a émergé : dans des scénarios d'agents réels comme OpenClaw, quel modèle d'IA offre les meilleures performances ?
C'est précisément le problème que PinchBench vise à résoudre. Il s'agit du critère d'évaluation officiel d'OpenClaw, développé en Rust par l'équipe kilo.ai. Il utilise des tâches réelles au lieu de tests synthétiques, offrant ainsi aux développeurs une base fiable pour choisir leur modèle.
Cet article retrace l'histoire d'OpenClaw et analyse en profondeur le système d'évaluation PinchBench. Il vous aidera à comprendre la véritable signification des benchmarks d'IA et à choisir le modèle adapté à votre flux de travail d'agent en fonction des données d'évaluation.
I. Qu'est-ce qu'OpenClaw : un phénomène open source qui a changé de nom 3 fois en un mois
La naissance d'OpenClaw et la controverse autour de son nom
L'histoire d'OpenClaw commence en novembre 2025.
Peter Steinberger, un développeur autrichien, a construit sur son temps libre une plateforme d'agents IA, initialement nommée Clawdbot. Le concept central de ce projet était simple : faire en sorte que l'IA ne soit pas seulement un outil de chat, mais qu'elle puisse réellement prendre en charge vos flux de travail numériques – lire des e-mails, écrire du code, gérer des calendriers, rechercher des informations.
Mais le concept d'agent IA n'est pas nouveau. Pourquoi OpenClaw a-t-il explosé du jour au lendemain ?
La clé réside dans la combinaison du bon moment et du soutien de l'open source. Fin janvier 2026, avec la propagation virale du projet Moltbook, le désir de "faire réellement travailler l'IA" a atteint son paroxysme dans le monde de la technologie, et Clawdbot a naturellement pris le devant de la scène.
Cependant, Anthropic a rapidement émis une objection de marque – le nom "Clawd" dans Clawdbot était jugé susceptible de créer une confusion avec un nom de produit interne d'Anthropic. Le projet a été contraint de changer de nom en urgence pour Moltbot le 27 janvier 2026, en hommage au projet Moltbook qui était devenu viral à la même période.
Trois jours plus tard, Steinberger a avoué sur GitHub que le nouveau nom "ne sonnait pas bien" ("never quite rolled off the tongue"), et le projet a été renommé une fois de plus OpenClaw, nom qu'il a conservé depuis.
Cette controverse autour du nom est finalement devenue la meilleure "publicité gratuite" pour le projet, rendant OpenClaw largement connu au sein de la communauté des développeurs.
Au 2 mars 2026, OpenClaw avait accumulé sur GitHub :
- ⭐ 247 000 Stars (soit près de la moitié des stars du framework React à la même période)
- 🍴 47 700 Forks
- 🌍 Un déploiement à grande échelle dans des entreprises de la Silicon Valley, d'Europe et de Chine.
L'architecture technique clé d'OpenClaw
La philosophie de conception d'OpenClaw est la suivante : exécution locale, indépendance du modèle, intégration aux applications de messagerie.
Ces trois caractéristiques déterminent ses différences fondamentales avec les autres frameworks d'agents IA.
L'exécution locale signifie que vos données ne transitent par aucun serveur tiers. Contrairement à la plupart des assistants IA sous forme de SaaS, OpenClaw est déployé sur l'appareil de l'utilisateur, et les invocations d'API de modèle peuvent également pointer vers des points de terminaison privés.
L'indépendance du modèle signifie qu'OpenClaw lui-même n'est lié à aucun Grand modèle de langage (LLM). C'est une "coque cérébrale" qui prend en charge l'intégration de n'importe quel modèle grand public comme Claude, GPT, DeepSeek, etc. Les développeurs peuvent basculer librement entre les modèles en fonction du type de tâche et du budget.
L'intégration aux applications de messagerie est la conception la plus distinctive d'OpenClaw – les utilisateurs ordinaires n'ont pas besoin d'ouvrir une application dédiée ; ils peuvent directement envoyer des messages via Signal, Telegram, Discord ou WhatsApp pour invoquer les capacités de l'agent IA. Cela réduit considérablement la barrière à l'entrée, permettant aux utilisateurs non techniques d'en bénéficier également.
| Dimension de conception | Choix d'OpenClaw | Alternatives courantes | Explication des différences |
|---|---|---|---|
| Lieu de déploiement | Exécution locale | SaaS cloud | Meilleure confidentialité des données, mais nécessite une maintenance autonome |
| Liaison du modèle | Totalement indépendant | Lié à un modèle spécifique | Commutation flexible, mais nécessite une configuration autonome |
| Interface utilisateur | Application de messagerie | Web/Application dédiée | Faible barrière à l'entrée, fonctionnalités limitées par l'application de messagerie |
| Portée des permissions | Accès étendu | Restrictions de sandbox | Fonctionnalités puissantes, mais risques de sécurité plus élevés |
| Licence open source | Entièrement open source | Propriétaire/Partiellement open source | Communauté pilotée, mais support limité |
🎯 Conseil d'utilisation : Le déploiement d'OpenClaw nécessite la configuration d'un backend LLM de haute qualité.
Nous vous suggérons d'intégrer Claude Sonnet 4.6 ou GPT-5.4 via APIYI apiyi.com.
Ces deux modèles ont montré d'excellentes performances dans PinchBench, et APIYI prend en charge la commutation d'interface unifiée,
ce qui vous permet de comparer rapidement les effets de différents modèles sans modifier la configuration principale d'OpenClaw.
Le champ d'action d'OpenClaw
Le champ d'action d'OpenClaw est assez vaste, mais c'est précisément ce qui a suscité des controverses en matière de sécurité :
Sources de données accessibles :
- Comptes de messagerie (lecture, classification, rédaction de réponses)
- Systèmes de calendrier (affichage, création, modification d'événements)
- Systèmes de fichiers (navigation, lecture, création, déplacement de fichiers)
- Dépôts de code (lecture de code, exécution de tests, soumission de modifications)
- Plateformes de messagerie (agrégation et réponse aux messages multiplateformes)
- Informations web (recherche, résumé, extraction structurée)
Scénarios d'utilisation typiques :
L'utilisateur envoie sur Telegram : "Trie mes e-mails d'aujourd'hui,
marque ceux qui nécessitent une réponse aujourd'hui et rédige les réponses."
Processus d'exécution de l'agent OpenClaw :
1. Appelle l'outil de messagerie, lit les e-mails non lus d'aujourd'hui
2. Utilise le LLM pour déterminer l'urgence de chaque e-mail
3. Filtre la liste des e-mails nécessitant une réponse aujourd'hui
4. Génère un brouillon de réponse pour chaque e-mail
5. Retourne les résultats triés et l'aperçu des brouillons dans Telegram
Cette capacité à "vraiment accomplir des tâches" est la différence fondamentale entre OpenClaw et un simple chatbot.
Steinberger rejoint OpenAI et l'avenir du projet
Le 14 février 2026, une nouvelle a secoué toute la communauté open source : Steinberger a annoncé sur GitHub qu'il rejoindrait OpenAI, et que le projet serait transféré à une fondation open source indépendante.
L'impact sur OpenClaw est double : d'une part, le projet bénéficie d'une gestion et d'une protection juridique plus professionnelles ; d'autre part, des spéculations ont commencé à circuler sur les motivations d'OpenAI derrière le recrutement de ce fondateur – s'agissait-il d'une absorption technologique, ou d'une prévention contre un concurrent potentiel ?
Actuellement, la Fondation OpenClaw a été établie, et le projet reste entièrement open source, mais les priorités de la feuille de route de développement ont clairement été ajustées : les fonctionnalités de sécurité de niveau entreprise et le système de contrôle des permissions sont devenus les points focaux de la prochaine version.
Controverse sur la sécurité : les risques liés à des capacités puissantes
La large demande de permissions système d'OpenClaw a, dès le début, attiré l'attention des chercheurs en cybersécurité.
En mars 2026, les autorités chinoises ont annoncé des restrictions sur l'exécution d'OpenClaw sur les ordinateurs de bureau des entreprises d'État et des agences gouvernementales, principalement en raison des préoccupations suivantes :
- Les données pourraient être divulguées à des fournisseurs de services étrangers via les invocations d'API LLM.
- Des permissions étendues pourraient devenir des points d'entrée pour des attaques si elles sont mal configurées.
- Des informations sensibles internes à l'entreprise pourraient être transmises entre systèmes par l'Agent.
Cet événement rappelle à tous les développeurs d'entreprise : lors de l'introduction d'outils d'Agent puissants, le principe du moindre privilège et les journaux d'audit sont des bases de sécurité incontournables.
II. Le rôle réel des Benchmarks dans l'industrie de l'IA : de l'examen à la pratique
Pourquoi l'industrie de l'IA ne peut pas se passer des Benchmarks
Si vous avez déjà voulu comparer les capacités de deux modèles d'IA, vous avez probablement rencontré un dilemme : les fabricants affirment tous que leur modèle est le "plus puissant", mais que signifie "puissant" ? Pour quelle tâche ? Par rapport à quelle base de référence ?
Un Benchmark (critère d'évaluation) est un système de test standardisé conçu pour résoudre ce problème.
Dans l'industrie de l'IA, un bon Benchmark doit satisfaire trois conditions :
- Répétabilité : N'importe qui utilisant le même ensemble de tests doit obtenir les mêmes résultats.
- Représentativité : Le contenu du test doit refléter les besoins en capacités des scénarios d'utilisation réels.
- Impartialité : L'ensemble de tests ne doit pas être contaminé par les données d'entraînement des développeurs de modèles.
En 2026, plus de 15 Benchmarks majeurs étaient activement utilisés dans l'industrie, mais seuls environ 4 d'entre eux étaient estimés capables de prédire la performance en environnement de production.

Les limites des Benchmarks traditionnels
Pour comprendre la valeur de PinchBench, il faut d'abord comprendre pourquoi les Benchmarks traditionnels sont "insuffisants".
MMLU (Massive Multitask Language Understanding)
MMLU est l'évaluation de connaissances générales la plus citée actuellement, couvrant 57 disciplines et environ 14 000 questions à choix multiples. Les questions couvrent des domaines tels que la médecine, le droit, l'histoire, les mathématiques et la programmation.
Le problème est le suivant : ce sont des questions à choix multiples, le modèle n'a qu'à choisir une option parmi 4. Dans un scénario d'Agent réel, le modèle doit générer des réponses de manière autonome, voire appeler des outils pour obtenir des informations – ce qui est complètement différent de "choisir une option parmi 4".
HumanEval (Test de génération de code)
HumanEval est un Benchmark emblématique pour mesurer la capacité de génération de code, contenant 164 problèmes de programmation Python. Cependant, ses questions sont relativement fixes, et les modèles peuvent avoir rencontré des types de problèmes similaires lors de l'entraînement, ce qui conduit à un "effet de bachotage" – un score élevé ne signifie pas une réelle capacité de programmation.
Les problèmes courants des tests synthétiques :
| Type de problème | Manifestation spécifique | Impact sur les résultats de l'évaluation |
|---|---|---|
| Contamination des données | L'ensemble d'entraînement contient des questions de test | Un score élevé ne représente pas une réelle capacité de généralisation |
| Effet de bachotage | Le modèle est optimisé pour un Benchmark spécifique | Classement artificiellement élevé, capacité réelle non améliorée |
| Décalage avec le scénario | Les questions à choix multiples sont très différentes de l'utilisation réelle | Faible pouvoir prédictif du classement |
| Jeu de données statique | Questions fixes, impossibles à mettre à jour | Les nouvelles capacités ne peuvent pas être évaluées |
| Évaluation unidimensionnelle | Ne considère que la précision | Ignore la vitesse, le coût, la fiabilité |
Les 5 dimensions clés de l'évaluation des agents IA
Lorsque les systèmes d'IA évoluent de la "réponse aux questions" à l'"accomplissement de tâches", le système d'évaluation doit également être mis à niveau.
Pour une plateforme d'agents IA comme OpenClaw, l'évaluation doit couvrir les 5 dimensions clés suivantes :
Dimension 1 : Taux d'achèvement des tâches (Task Completion Rate)
Le pourcentage global de succès de la réception de la tâche à son achèvement final. C'est l'indicateur le plus intuitif, mais aussi le plus complexe – la définition même de "l'achèvement" est le défi central de la conception de l'évaluation.
Méthode de test : Donner à l'Agent une tâche complexe en 3 à 5 étapes, et calculer le pourcentage de succès complet, de succès partiel et d'échec.
Dimension 2 : Précision de l'invocation d'outils (Tool Call Accuracy)
L'Agent doit choisir le bon outil parmi des dizaines d'outils disponibles et l'invoquer avec les bons paramètres. Une invocation d'outil incorrecte n'est pas seulement un échec, elle peut également avoir des effets secondaires (par exemple, suppression accidentelle de fichiers, envoi d'e-mails erronés).
Méthode de test : Concevoir des tâches nécessitant une séquence d'outils spécifique, et calculer le taux d'erreur de sélection d'outil et le taux d'erreur de paramètre.
Dimension 3 : Cohérence du raisonnement multi-étapes (Multi-step Reasoning Coherence)
L'accomplissement d'une tâche nécessite souvent 5 à 10 étapes, et l'Agent doit maintenir une compréhension claire de l'objectif tout au long du processus, sans "se perdre en chemin".
Méthode de test : Concevoir des tâches à long processus nécessitant plus de 10 étapes, et observer si des dérives d'objectifs ou des ruptures logiques se produisent en cours de route.
Dimension 4 : Rétention du contexte sur plusieurs tours (Cross-turn Context Retention)
Dans une conversation multi-tours, l'Agent doit se souvenir des informations échangées précédemment. Des informations comme "vous avez dit la dernière fois que la réunion était mercredi" sont cruciales dans le flux de travail d'OpenClaw.
Méthode de test : Concevoir des scénarios de tâches nécessitant de faire référence à des informations datant de plus de 5 tours, et calculer le taux de perte de contexte.
Dimension 5 : Fréquence des hallucinations (Hallucination Rate)
L'Agent invente des fichiers inexistants, des contacts inexistants, des dates erronées ; ces hallucinations ne sont que des problèmes mineurs dans le chat, mais dans un scénario d'Agent, elles peuvent causer des pertes réelles (par exemple, l'envoi d'e-mails avec un contenu incorrect).
Méthode de test : Concevoir des tâches nécessitant de faire référence à des données réelles (noms de fichiers, adresses e-mail, dates), et calculer la fréquence d'apparition des hallucinations.
🎯 Conseil aux développeurs : Lors du choix d'un modèle d'Agent, le taux d'achèvement des tâches et la précision de l'invocation d'outils sont les deux indicateurs les plus importants.
Il est recommandé d'utiliser la plateforme APIYI apiyi.com pour intégrer rapidement plusieurs modèles, et de vérifier leur efficacité sur vos propres tâches réelles en utilisant les 5 dimensions ci-dessus,
plutôt que de vous fier uniquement aux chiffres des classements. APIYI prend en charge la facturation à l'usage, ce qui est idéal pour effectuer des tests A/B à petite échelle avant de faire un choix final.
III. PinchBench : Une analyse approfondie du standard d'évaluation officiel d'OpenClaw
Contexte de la création de PinchBench
PinchBench, développé en Rust par l'équipe kilo.ai, est un benchmark d'évaluation conçu spécifiquement pour les scénarios OpenClaw et publié en open source sur GitHub (dépôt pinchbench/skill).
Le problème central qu'il résout : les classements de modèles généraux ont une faible capacité à prédire les performances réelles des Agents.
Des recherches ont montré qu'un modèle classé dans les 5 % supérieurs sur MMLU peut avoir des performances bien inférieures à celles d'un modèle de classement MMLU moyen, mais optimisé pour l'invocation d'outils, dans les tâches combinées de classification d'e-mails et de planification de réunions d'OpenClaw.
L'émergence de PinchBench a fourni aux développeurs, pour la première fois, une base d'évaluation fiable spécifiquement adaptée aux workflows d'Agent.
Les 23 catégories de tâches de PinchBench
PinchBench utilise des tâches réelles plutôt que des problèmes synthétiques, couvrant 23 catégories de tâches, chacune correspondant à un scénario d'utilisation réel pour les utilisateurs d'OpenClaw :
Catégories de tâches principales (6 grandes catégories) :
| Catégorie de tâche | Contenu de test spécifique | Outils impliqués | Difficulté d'évaluation |
|---|---|---|---|
| Gestion d'agenda | Planification de réunions, résolution de conflits, gestion des fuseaux horaires, rappels périodiques | API de calendrier, outils de fuseau horaire | ★★★☆☆ |
| Écriture de code | Implémentation de fonctionnalités, correction de bugs, refactoring de code, tests unitaires | Exécution de code, système de fichiers | ★★★★☆ |
| Traitement d'e-mails | Classification, priorisation, rédaction de réponses automatiques, gestion des pièces jointes | API de client de messagerie | ★★★☆☆ |
| Recherche d'informations | Recherche web, agrégation d'informations, génération de résumés, vérification des sources | Moteur de recherche, navigateur | ★★★★☆ |
| Gestion de fichiers | Organisation, conversion de format, opérations en masse, contrôle de version | Système de fichiers, outils de conversion | ★★☆☆☆ |
| Collaboration multi-outils | Flux de données multiplateformes, orchestration de chaînes d'outils, déclencheurs conditionnels | Combinaison de plusieurs outils | ★★★★★ |
Méthodologie d'évaluation de PinchBench
PinchBench utilise un mécanisme d'évaluation double, conciliant objectivité et évaluation de la qualité :
Vérifications automatisées (Automated Checks)
Utilisées pour les critères objectifs vérifiables :
- Le code passe-t-il tous les cas de test ?
- Le fichier a-t-il été correctement déplacé vers l'emplacement spécifié ?
- L'événement de calendrier a-t-il été créé au bon moment ?
- L'invocation de l'API renvoie-t-elle le format attendu ?
Juge LLM (LLM Judge)
Utilisé pour l'évaluation qualitative nécessitant un jugement subjectif :
- Le ton et le professionnalisme de la réponse par e-mail
- L'exactitude et l'exhaustivité des informations dans le rapport de recherche
- La précision de la compréhension de la tâche (si l'intention de l'utilisateur a été réellement comprise)
- La pertinence de la stratégie de gestion des cas limites
Cette combinaison concilie efficacité (les vérifications automatisées peuvent être exécutées à grande échelle) et qualité (le juge LLM capture des détails difficiles à quantifier par l'homme).
Matrice d'indicateurs d'évaluation tridimensionnelle :
┌─────────────────────────────────────────────────┐
│ Système d'évaluation tridimensionnel PinchBench │
├─────────────────────────────────────────────────┤
│ Taux de réussite (Success Rate) │
│ → Mesure globale de la qualité d'achèvement des tâches │
│ → Dimension principale du classement │
│ → Combine vérifications automatisées + juge LLM │
├─────────────────────────────────────────────────┤
│ Vitesse (Speed) │
│ → Temps moyen pour accomplir une tâche (secondes/minutes) │
│ → Crucial pour les scénarios de réponse en temps réel │
│ → Inclut la latence de l'API et le temps d'inférence │
├─────────────────────────────────────────────────┤
│ Coût (Cost) │
│ → Coût en tokens (USD) pour accomplir une tâche │
│ → Indicateur clé pour les scénarios d'utilisation fréquente │
│ → Aide au calcul du ROI et à la décision de sélection de modèle │
└─────────────────────────────────────────────────┘
Au 13 mars 2026, les données du classement public de PinchBench sont les suivantes :
- 📊 49 modèles ont été évalués, couvrant tous les modèles commerciaux et open source majeurs
- 🔄 327 enregistrements d'exécution, mis à jour en continu
- 🌐 Classement public : pinchbench.com (mis à jour en temps réel)
- 📁 Dépôt open source : github.com/pinchbench/skill (définitions des tâches publiques)
🎯 Conseil d'utilisation de PinchBench : Lorsque vous consultez le classement, il est recommandé de basculer entre les trois vues (taux de réussite, vitesse et coût) pour filtrer le modèle le plus adapté à vos besoins réels (réactivité vs qualité vs coût). En vous connectant via l'accès unifié d'APIYI (apiyi.com), vous pouvez facilement comparer les coûts réels de différents modèles dans le même scénario métier.
IV. Interprétation approfondie du classement PinchBench et guide de sélection de modèles
Classement actuel des 5 meilleurs taux de réussite (données du 13 mars 2026)
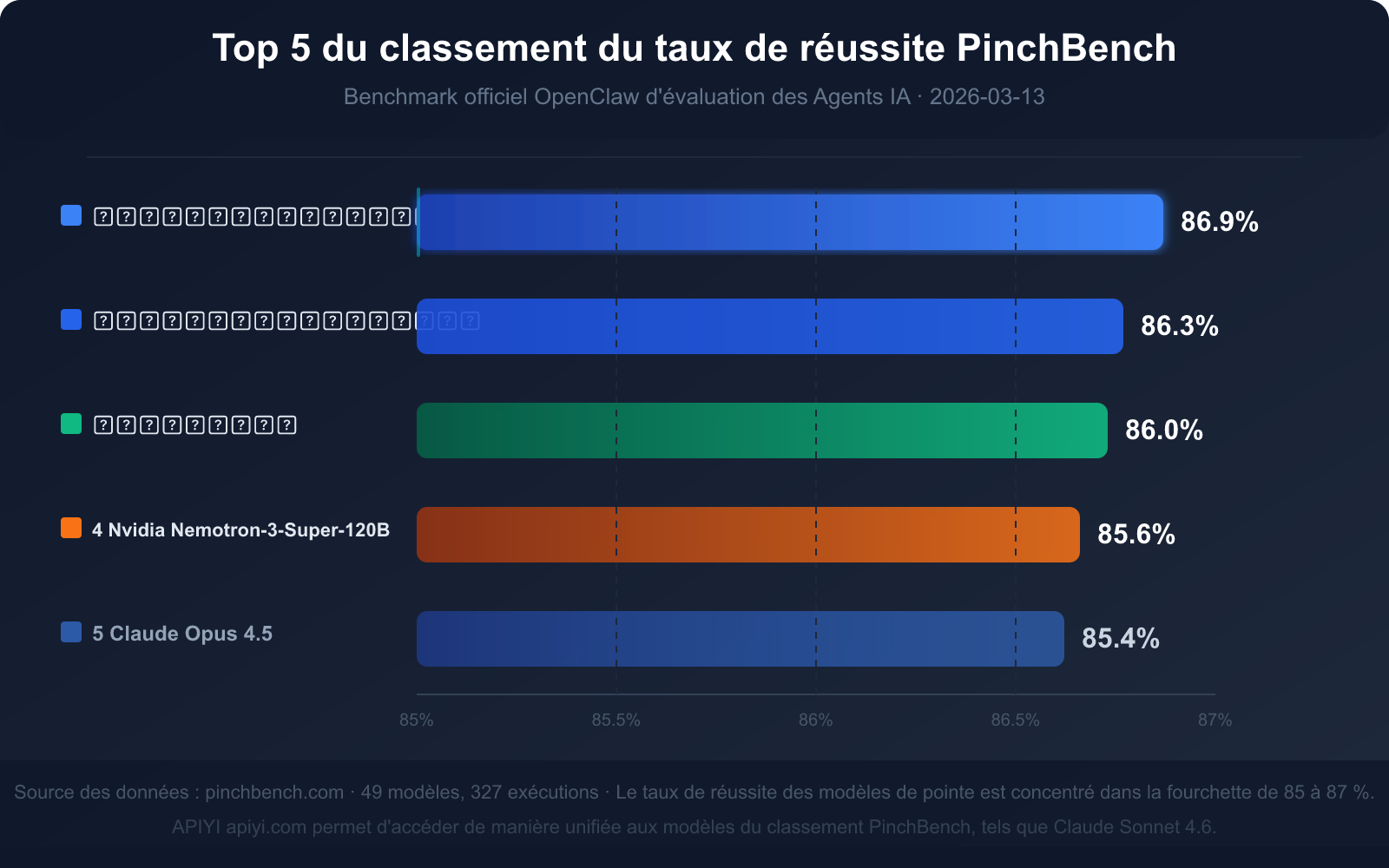
| Classement | Nom du modèle | Taux de réussite | Type de modèle | Avantages clés |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Commercial propriétaire | Taux de réussite le plus élevé, équilibre vitesse/qualité |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Commercial propriétaire | Capacité de raisonnement complexe la plus forte |
| 🥉 3 | GPT-5.4 | 86.0% | Commercial propriétaire | Bonne stabilité d'invocation d'outils |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Open source déployable | Meilleure performance parmi les modèles open source |
| 5 | Claude Opus 4.5 | 85.4% | Commercial propriétaire | Ancien fleuron, toujours compétitif |
Aperçu des données clés : Que signifie un taux de réussite de 85 % ?
Le taux de réussite des modèles de pointe sur PinchBench se situe dans la fourchette de 85 % à 87 %, et non près du score maximal. Ce chiffre en lui-même transmet trois signaux importants :
Signal 1 : Les tâches d'Agent IA restent un problème de haute difficulté à ce jour
Même le Claude Sonnet 4.6 (86,9 %), classé premier, échoue encore dans environ 13 tâches sur 100. Ce n'est pas un manque de capacité du modèle, mais plutôt la complexité inhérente aux tâches du monde réel – des instructions ambiguës, des informations incomplètes, des cas limites d'invocation d'outils, tout cela peut entraîner des échecs.
Signal 2 : La conception tolérante aux pannes est indispensable dans le développement d'Agents
Lorsqu'un taux d'échec de 13 % est considéré comme un "niveau d'excellence", un processus d'Agent entièrement automatisé sans point de révision humaine est à haut risque en environnement de production. La meilleure pratique est de : conserver des étapes de confirmation manuelle pour les opérations à haut risque (comme l'envoi d'e-mails, la soumission de code).
Signal 3 : L'écart entre les modèles est minime, la conception de la tâche est plus importante
L'écart entre le classement 1 et le classement 5 n'est que de 1,5 point de pourcentage (86,9 % contre 85,4 %). Cela signifie que l'impact du choix du modèle est bien moindre que celui de la manière de concevoir l'invite de tâche, de définir l'interface de l'outil et de gérer les situations d'erreur.
Analyse complète des indicateurs tridimensionnels
Il ne suffit pas de regarder uniquement le taux de réussite. Voici un cadre d'évaluation complet basé sur trois dimensions :
| Scénario d'utilisation | Indicateurs prioritaires | Indicateurs secondaires | Orientation modèle recommandée |
|---|---|---|---|
| Tâches légères et fréquentes (classification d'e-mails, rappels) | Vitesse + Coût | Taux de réussite | Modèles légers comme Claude Haiku 4.5 |
| Tâches d'ingénierie complexes (refactoring de code, recherche) | Taux de réussite | Vitesse | Claude Sonnet 4.6 / GPT-5.4 |
| Scénarios de réponse en temps réel (assistant instantané) | Vitesse | Taux de réussite | Modèles Top du classement Vitesse |
| Applications sensibles aux coûts | Coût | Taux de réussite | Modèles open source auto-déployés / API à faible coût |
| Sécurité et conformité d'entreprise | Taux de réussite + Contrôlabilité | Coût | Modèles open source déployés en privé |
🎯 Conseil de sélection global : Selon les données de PinchBench, Claude Sonnet 4.6 est le choix global avec le taux de réussite le plus élevé pour les scénarios OpenClaw actuels. Pour les scénarios fréquents et sensibles aux coûts, il est recommandé d'utiliser d'abord Claude Sonnet 4.6 pour établir une ligne de base du taux de réussite des tâches, puis de tester si des modèles plus légers peuvent réduire considérablement les coûts tout en restant dans une fourchette de taux de réussite acceptable. Tous ces tests peuvent être effectués via l'interface API unifiée d'APIYI (apiyi.com), sans avoir besoin d'enregistrer plusieurs comptes de fournisseurs de services.
Analyse de la compétitivité des modèles open source
Nvidia Nemotron-3-Super-120B se classe 4ème avec un taux de réussite de 85,6 %, soit seulement 1,3 point de pourcentage de moins que le premier – ce qui est un résultat très impressionnant pour un modèle open source.
Avantages des modèles open source :
- Souveraineté des données : Le modèle et les données sont dans un environnement contrôlé, répondant aux exigences de conformité
- Structure des coûts : Investissement initial en GPU, sans frais d'invocation d'API ultérieurs (pour les scénarios à volume élevé)
- Marge de personnalisation : Possibilité de Fine-tuning pour des tâches spécifiques
Limites des modèles open source :
- Coût de déploiement : Un modèle de 120 milliards de paramètres nécessite 4 à 8 GPU A100/H100
- Charge de maintenance : Les mises à jour de modèles et la gestion des versions nécessitent une équipe d'opérations dédiée
- Coût des tests initiaux : Avant de confirmer qu'un modèle open source convient à votre scénario, la validation de prototype via une API commerciale est souvent plus économique
V. Guide pratique : Comment configurer le modèle optimal dans OpenClaw
Intégration rapide de Claude Sonnet 4.6 pour OpenClaw
Voici un exemple de configuration complète pour intégrer le modèle classé numéro un par PinchBench via APIYI :
Étape 1 : Obtenir une clé API
Rendez-vous sur le site officiel d'APIYI, apiyi.com, inscrivez-vous et accédez à la console pour obtenir votre clé API. APIYI propose des interfaces compatibles OpenAI et prend également en charge le SDK natif d'Anthropic.
Étape 2 : Configurer le backend du modèle d'OpenClaw
# Exemple de fichier de configuration OpenClaw (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Nombre maximal d'étapes d'exécution
tool_timeout: 30 # Délai d'attente pour un seul appel d'outil (secondes)
retry_on_error: true # Réessayer automatiquement en cas d'échec de l'appel d'outil
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # Les opérations à haut risque nécessitent une confirmation manuelle
Étape 3 : Vérifier la configuration
# Tester la connexion avec le SDK Anthropic
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Envoyer une requête de test
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "Veuillez énumérer 3 types de tâches que vous pouvez exécuter dans OpenClaw"
}]
)
print(response.content[0].text)
Étape 4 : Configuration du test A/B multi-modèles
# Comparer différents modèles sur la même tâche (recommandé avant le déploiement officiel)
models_to_test = [
"claude-sonnet-4-6", # Classé numéro un par PinchBench
"gpt-5.4-turbo", # Classé numéro trois par PinchBench (compatible format OpenAI)
"claude-opus-4-5", # Ancien modèle phare, pour comparaison des coûts
]
# APIYI prend en charge l'invocation unifiée de tous les modèles ci-dessus
# base_url reste inchangé, il suffit de modifier le paramètre model
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: Taux de succès={result.success_rate}, Durée={result.avg_time}s, Coût=${result.cost_per_task}")
🎯 Démarrage rapide : Visitez APIYI apiyi.com pour vous inscrire et obtenir un crédit de test.
APIYI prend en charge l'accès API unifié aux modèles du classement PinchBench tels que Claude Sonnet 4.6 et GPT-5.4.
Plus besoin de demander des autorisations d'accès auprès de plusieurs fournisseurs, ce qui réduit considérablement les obstacles initiaux aux tests de modèles.
Auto-évaluez votre Agent avec les 5 dimensions de PinchBench
Avant de déployer en production, il est recommandé d'évaluer la configuration de votre Agent à l'aide de la liste de contrôle d'auto-évaluation suivante :
Liste de contrôle d'auto-évaluation de l'Agent inspirée par PinchBench
□ Dimension 1 - Taux d'achèvement des tâches
Donnez à l'Agent 10 tâches complexes de plus de 3 étapes
Enregistrez le nombre de succès complets / partiels / échecs
Objectif : Taux de succès complet ≥ 80%
□ Dimension 2 - Précision de l'invocation d'outils
Vérifiez les journaux d'invocation d'outils et comptez les types d'erreurs suivants :
- Erreur de sélection d'outil (mauvais outil choisi)
- Erreur de format de paramètre (type ou format de paramètre incorrect)
- Erreur de valeur de paramètre (type de paramètre correct mais valeur déraisonnable)
Objectif : Taux d'erreur d'outil ≤ 5%
□ Dimension 3 - Cohérence du raisonnement multi-étapes
Concevez une tâche à long processus nécessitant plus de 15 étapes
Observez si un décalage d'objectif se produit en cours de route (oubli de l'objectif initial)
Objectif : Pas de décalage d'objectif pour les tâches à long processus
□ Dimension 4 - Rétention du contexte
Fournissez des informations clés au tour 1, puis référencez ces informations au tour 8
Vérifiez si l'Agent peut référencer correctement
Objectif : Taux de précision des références inter-tours ≥ 90%
□ Dimension 5 - Détection des hallucinations
Concevez des tâches nécessitant de référencer des données réelles (nom de fichier/contact/date)
Vérifiez si l'Agent fabrique des données inexistantes
Objectif : Taux d'hallucination ≤ 2%
VI. L'avenir des benchmarks IA : De l'évaluation ponctuelle à l'évaluation de l'écosystème
Tendances d'évolution du système de benchmark actuel
En 2026, le domaine des benchmarks IA connaît une profonde transformation. Au cœur de ce changement, l'objet de l'évaluation s'étend du modèle unique au système d'Agent complet.
La mentalité des benchmarks traditionnels est la suivante : donner des problèmes au modèle et voir s'il répond correctement. Cependant, avec la popularisation de plateformes d'Agent comme OpenClaw, la question vraiment importante est devenue : lorsque le modèle agit comme le "cerveau" d'un système, peut-il permettre à ce système d'accomplir son travail ?
La réponse à cette question ne dépend pas seulement des connaissances du modèle, mais aussi de :
- Sa capacité à comprendre les descriptions d'outils
- Ses stratégies de décision face à des informations incertaines
- Sa capacité à identifier et à corriger les erreurs
- Sa capacité à suivre l'intention de l'utilisateur sur le long terme
La valeur de PinchBench réside précisément dans sa capacité à quantifier et à afficher publiquement ces dimensions.

La bonne façon d'utiliser les données des benchmarks IA
Les données de benchmark sont précieuses, mais elles peuvent aussi être facilement mal utilisées. Voici quelques erreurs courantes et les bonnes pratiques :
Erreur 1 : Considérer le modèle le mieux classé comme "forcément le meilleur"
Bonne pratique : Le classement est basé sur un ensemble de tâches spécifiques de PinchBench, et vos propres tâches peuvent avoir une distribution de poids différente. Testez d'abord sur vos propres tâches avant de faire un choix.
Erreur 2 : Ne regarder que le taux de succès, en ignorant la vitesse et le coût
Bonne pratique : Les trois dimensions (succès, vitesse, coût) sont indissociables. Dans un scénario de traitement par lots, une différence de vitesse de 50 % signifie une économie de coût de 50 % ; dans un scénario de réponse en temps réel, une différence de vitesse de 2 secondes signifie une dégradation significative de l'expérience utilisateur.
Erreur 3 : Penser qu'une différence de 1 % dans le taux de succès est insignifiante
Bonne pratique : Une différence
Questions fréquentes
Q : Quelle est la différence fondamentale entre OpenClaw et AutoGPT, AutoGen ?
La différence essentielle d'OpenClaw réside dans sa méthode d'accès et sa barrière à l'entrée : il fournit une interface d'agent via des applications de messagerie (Signal, WhatsApp, etc.), ce qui signifie que les utilisateurs ordinaires n'ont pas besoin d'installer une application dédiée ou de comprendre les détails techniques. Du point de vue de l'architecture technique, OpenClaw est plus proche d'un "secrétaire IA personnel", tandis que des frameworks comme AutoGen sont plus adaptés aux développeurs pour construire des systèmes multi-agents complexes. OpenClaw met l'accent sur une "expérience grand public prête à l'emploi", tandis qu'AutoGen met l'accent sur un "cadre de développement flexible de niveau entreprise".
🎯 Quel que soit le framework d'agent que vous choisissez, vous pouvez accéder de manière unifiée aux modèles backend via APIYI apiyi.com, évitant ainsi de configurer une clé API séparément pour chaque framework.
Q : À quelle fréquence le classement des taux de réussite de PinchBench est-il mis à jour ?
Le classement PinchBench est mis à jour en temps réel – chaque fois qu'un nouveau modèle termine son évaluation, les données sont immédiatement reflétées sur pinchbench.com. Comme les principaux fabricants continuent de publier de nouvelles versions, le classement changera fréquemment. Nous vous recommandons de consulter les dernières données avant de faire votre sélection finale. Les données de cet article sont basées sur un instantané du 13 mars 2026 (49 modèles, 327 enregistrements d'exécution).
Q : Comment choisir le modèle le plus adapté pour OpenClaw ?
Nous recommandons une méthode de sélection en trois étapes :
- Vérifier le taux de réussite PinchBench : Filtrer les 5 meilleurs taux d'achèvement des tâches.
- Considérer la vitesse et le coût : Filtrer ensuite en fonction de votre type de tâche (temps réel vs traitement par lots, haute fréquence vs basse fréquence).
- Effectuer des tests A/B réels : Comparer 2-3 modèles candidats sur vos tâches métier réelles.
Via APIYI apiyi.com, vous pouvez basculer rapidement entre différents modèles en utilisant la même
base_url, et prendre la décision finale après avoir terminé les tests A/B.
Q : Les modèles open source peuvent-ils entièrement remplacer les modèles commerciaux pour piloter OpenClaw ?
Selon les données de PinchBench, le Nvidia Nemotron-3-Super-120B (85,6 %) présente un écart d'environ 1,3 point de pourcentage par rapport aux modèles commerciaux de pointe (86,9 %). Pour les tâches d'agent courantes, cet écart est acceptable. Cependant, il convient de noter que le déploiement autonome d'un modèle de 120 milliards de paramètres nécessite 4 à 8 GPU haut de gamme, et l'investissement initial en matériel ainsi que les coûts d'exploitation et de maintenance sont considérables. Nous vous recommandons de valider d'abord la faisabilité de la conception de votre agent avec une API commerciale, puis d'évaluer s'il est judicieux de migrer vers un modèle open source auto-déployé.
Q : Comment atténuer les risques de sécurité d'OpenClaw ?
Le principe fondamental est la minimisation des privilèges : n'accorder à OpenClaw que l'étendue minimale des autorisations nécessaires pour accomplir sa tâche. Recommandations spécifiques :
- Autorisation de lecture seule pour les e-mails (plutôt que des autorisations complètes de lecture, écriture et suppression)
- Autorisation de lecture seule + soumission de PR pour les dépôts de code (plutôt que de pousser directement vers la branche principale)
- Système de fichiers limité à un répertoire de travail spécifique (plutôt qu'à l'ensemble du système de fichiers)
- Les opérations à haut risque (envoi d'e-mails, suppression de fichiers) doivent inclure une étape de confirmation manuelle.
Lors d'un déploiement en entreprise, il est également nécessaire de configurer des journaux d'audit d'opérations complets pour garantir que chaque opération de l'agent est traçable.
Q : Quelle est la différence entre PinchBench et les autres benchmarks d'agents ?
La principale caractéristique de PinchBench est sa spécificité de scénario : il est conçu spécifiquement pour les cas d'utilisation d'OpenClaw, et non pour une évaluation générique des agents. Cela signifie qu'il a une valeur de référence plus élevée pour les utilisateurs d'OpenClaw, mais qu'il ne convient pas pour évaluer directement le choix de modèles pour d'autres frameworks d'agents. D'autres benchmarks d'agents bien connus incluent AgentBench (couvrant divers environnements), SWE-Bench (se concentrant sur les tâches de code), etc., chacun ayant ses propres spécificités.
Résumé : OpenClaw + PinchBench établissent une nouvelle norme pour l'ère des agents
OpenClaw, un projet de week-end d'un développeur autrichien, est devenu en deux mois la plateforme d'agents IA la plus populaire au monde. Cela reflète le désir ardent de l'industrie de voir l'IA "faire réellement des choses".
L'émergence de PinchBench, quant à elle, comble une lacune cruciale dans le domaine de l'évaluation des agents : nous avons enfin un outil dédié pour mesurer les capacités des agents.
Conclusions clés en un coup d'œil :
- Claude Sonnet 4.6 est le meilleur choix global pour les scénarios OpenClaw actuels (86,9 % de taux de réussite, classé premier sur PinchBench).
- Les taux de réussite des modèles de pointe se situent entre 85 et 87 %, les tâches d'agent restent un défi, et une conception tolérante aux pannes est indispensable.
- La vitesse et le coût sont également importants, un modèle à fort taux de réussite n'est pas forcément adapté à tous les scénarios, une évaluation globale en trois dimensions est nécessaire.
- PinchBench représente l'avenir de l'évaluation de l'IA : les tâches en scénario réel remplacent les tests synthétiques.
- La différence dans le choix du modèle est d'environ 1 à 2 %, l'impact de la conception des tâches et de l'ingénierie des invites est souvent plus important.
Pour les développeurs et les entreprises souhaitant approfondir l'écosystème OpenClaw, c'est un moment idéal :
La communauté open source est active, les outils d'évaluation sont matures et les coûts d'accès aux API des modèles grand public continuent de baisser. Vous n'avez pas besoin d'attendre la "solution parfaite", vous pouvez commencer dès maintenant à valider la faisabilité de vos workflows d'agents avec des tâches à petite échelle.
🎯 Agissez dès maintenant : Si vous construisez un workflow IA basé sur OpenClaw, nous vous recommandons de l'intégrer via APIYI apiyi.com.
La plateforme prend en charge les modèles grand public tels que Claude Sonnet 4.6 (1er sur PinchBench) et GPT-5.4 (3ème).
Une seule interface API, pas besoin de s'inscrire auprès de plusieurs fournisseurs, prend en charge la facturation à l'usage, idéale pour commencer par des tests à petite échelle et s'étendre progressivement.
Visitez le site officiel d'APIYI apiyi.com pour vous inscrire et commencer l'expérience.
Les données de cet article sont basées sur des informations publiques compilées en mars 2026. Pour les données en temps réel du classement PinchBench, veuillez visiter pinchbench.com pour la dernière version.
Auteur : Équipe APIYI | Pour plus d'informations sur l'intégration des API de modèles IA, veuillez visiter APIYI apiyi.com.