2026 年,一个奥地利独立开发者用周末时间做出的开源项目,在两个月内收获了 24.7 万 GitHub Stars,成为硅谷和中国企业争相部署的 AI 智能体平台。
这个项目叫 OpenClaw。
与此同时,一个问题也随之浮现:在 OpenClaw 这样的真实 Agent 场景下,到底哪个 AI 模型表现最好?
这正是 PinchBench 要解决的问题。它是 OpenClaw 的官方评测基准,由 kilo.ai 团队用 Rust 开发,用真实任务替代合成测试,给开发者一个可信赖的模型选择依据。
本文从 OpenClaw 的崛起故事出发,深度解析 PinchBench 评测体系,帮你读懂 AI Benchmark 的真实意义,以及如何根据评测数据选择适合自己 Agent 工作流的模型。
一、OpenClaw 是什么:一个月内改了 3 次名字的开源现象
OpenClaw 的诞生与命名风波
OpenClaw 的故事要从 2025 年 11 月讲起。
奥地利开发者 Peter Steinberger 利用业余时间构建了一个 AI 智能体平台,起初命名为 Clawdbot。这个项目的核心理念很简单:让 AI 不只是聊天工具,而是能真正接管你的数字工作流——读邮件、写代码、管日历、搜信息。
但 AI Agent 这个概念并不新鲜,为什么 OpenClaw 能一夜引爆?
关键在于时机与开源的双重加持。2026 年 1 月下旬,随着 Moltbook 项目的病毒式传播,整个技术圈对"让 AI 真正做事"的渴望到达顶点,Clawdbot 顺势而上成为焦点。
但随即收到 Anthropic 的商标异议通知——Clawdbot 中的"Clawd"被认为与 Anthropic 内部产品名称存在混淆风险。项目被迫于 2026 年 1 月 27 日 紧急改名为 Moltbot,致敬了同期爆红的 Moltbook 项目。
然而三天后,Steinberger 在 GitHub 上坦言:新名字"读起来就是不顺口"("never quite rolled off the tongue"),项目再次更名为 OpenClaw,并延续至今。
这段命名风波,反而成为项目最好的"免费营销",让 OpenClaw 在开发者社区中广为人知。
截至 2026 年 3 月 2 日,OpenClaw 在 GitHub 已积累:
- ⭐ 24.7 万 Stars(相当于 React 框架同期 stars 的近一半)
- 🍴 4.77 万 Forks
- 🌍 在硅谷、欧洲、中国企业中均有大规模部署
OpenClaw 的核心技术架构
OpenClaw 的设计哲学是:本地运行、模型无关、消息应用接入。
这三个特点决定了它与其他 AI Agent 框架的根本差异。
本地运行意味着你的数据不经过任何第三方服务器。与大多数 SaaS 形态的 AI 助理不同,OpenClaw 部署在用户自己的设备上,模型 API 调用也可以指向私有端点。
模型无关意味着 OpenClaw 本身不绑定任何 LLM。它是一个"大脑外壳",支持接入 Claude、GPT、DeepSeek 等任意主流模型,开发者可以根据任务类型和成本预算自由切换。
消息应用接入是 OpenClaw 最有特色的设计——普通用户不需要打开任何专用 App,直接在 Signal、Telegram、Discord 或 WhatsApp 中发消息,就能调用 AI Agent 能力。这大幅降低了使用门槛,让非技术用户也能受益。
| 设计维度 | OpenClaw 选择 | 主流替代方案 | 差异说明 |
|---|---|---|---|
| 部署位置 | 本地运行 | 云端 SaaS | 数据隐私更强,但需自行维护 |
| 模型绑定 | 完全无关 | 绑定特定模型 | 灵活切换,但需自行配置 |
| 用户界面 | 消息应用 | 专用 Web/App | 上手门槛低,功能受消息应用限制 |
| 权限范围 | 广泛访问 | 沙箱限制 | 功能强大,但安全风险更高 |
| 开源协议 | 完全开源 | 闭源/部分开源 | 社区驱动,但支持保障有限 |
🎯 使用建议: 部署 OpenClaw 需要为其配置一个高质量的 LLM 后端。
我们建议通过 API易 apiyi.com 接入 Claude Sonnet 4.6 或 GPT-5.4,
这两款模型在 PinchBench 中均表现优异,且 API易 支持统一接口切换,
方便你在不修改 OpenClaw 核心配置的情况下快速对比不同模型效果。
OpenClaw 的能力边界
OpenClaw 支持的能力范围相当广泛,但也正因为此引发了安全争议:
可访问的数据源:
- 邮件账户(读取、分类、起草回复)
- 日历系统(查看、创建、修改日程)
- 文件系统(浏览、读取、创建、移动文件)
- 代码仓库(读取代码、运行测试、提交变更)
- 消息平台(跨平台消息聚合和响应)
- 网络信息(搜索、摘要、结构化提取)
典型使用场景:
用户在 Telegram 中发送:"帮我整理今天的邮件,
把需要今天回复的标记出来,并起草回复内容"
OpenClaw Agent 执行流程:
1. 调用邮件工具,读取今日未读邮件
2. 用 LLM 判断每封邮件的紧急程度
3. 筛选出需要今日回复的邮件列表
4. 为每封邮件生成回复草稿
5. 在 Telegram 中返回整理结果和草稿预览
这种"真正把事情做完"的能力,是 OpenClaw 与简单聊天机器人的本质区别。
Steinberger 加入 OpenAI 与项目未来
2026 年 2 月 14 日,一条消息震动了整个开源社区:Steinberger 在 GitHub 上宣布将加入 OpenAI,项目移交独立开源基金会管理。
这对 OpenClaw 的影响是双重的:一方面,项目得到了更专业的运营和法律保障;另一方面,外界开始猜测 OpenAI 收购这位创始人的背后动机——是为了技术吸收,还是为了防止潜在竞争对手?
目前,OpenClaw 基金会已经建立,项目仍然保持完全开源,但开发路线图的优先级调整明显:企业级安全功能和权限控制体系成为下一个版本的重点。
安全争议:强大能力带来的风险
OpenClaw 对系统权限的广泛需求,从一开始就引发了网络安全研究者的关注。
2026 年 3 月,中国当局宣布限制国有企业和政府机构在办公电脑上运行 OpenClaw,主要担忧包括:
- 数据可能通过 LLM API 调用泄露给境外服务商
- 广泛权限在配置不当时可能成为攻击入口
- 企业内部敏感信息可能被 Agent 跨系统传递
这一事件提醒所有企业开发者:在引入强大 Agent 工具的同时,权限最小化原则和审计日志是不可跳过的安全基础。
二、Benchmark 在 AI 行业的真实作用:从考试到实战
为什么 AI 行业离不开 Benchmark
如果你曾经想比较两款 AI 模型的能力,你很可能遭遇过一个困境:厂商都说自己的模型"最强",但"强"是什么意思?在什么任务上?和什么基线相比?
Benchmark(评测基准) 正是为了解决这个问题而生的标准化测试体系。
在 AI 行业,一个好的 Benchmark 需要满足三个条件:
- 可重复性:任何人用同样的测试集都能得到相同结果
- 代表性:测试内容能反映真实使用场景的能力需求
- 公正性:测试集不被模型开发商的训练数据污染
2026 年,全行业共有超过 15 个主流 Benchmark 在活跃使用,但真正能预测生产环境表现的,业内估计只有约 4 个。
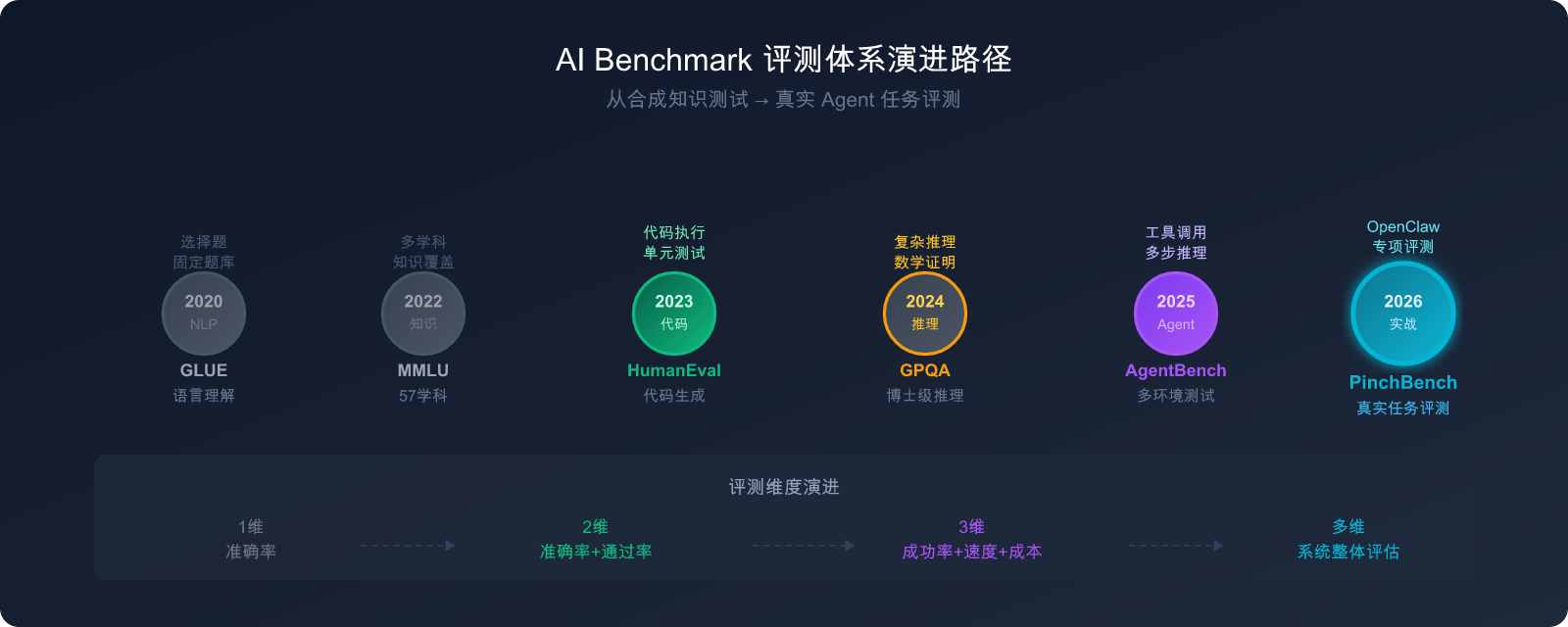
传统 Benchmark 的局限性
理解 PinchBench 的价值,需要先理解传统 Benchmark 为什么"不够用"。
MMLU(大规模多任务语言理解)
MMLU 是目前引用最广泛的通用知识评测,覆盖 57 个学科,共约 14,000 道选择题。问题涵盖医学、法律、历史、数学、编程等领域。
问题在于:这是选择题,模型只需要从 4 个选项中选一个。在实际 Agent 场景中,模型需要自主生成答案,甚至调用工具来获取信息——这与"从 4 个选项选一个"完全不同。
HumanEval(代码生成测试)
HumanEval 是衡量代码生成能力的标志性 Benchmark,包含 164 个 Python 编程问题。但它的题目相对固定,模型训练时可能接触过类似题型,导致"刷题效应"——高分不代表真实编程能力。
合成测试的通病:
| 问题类型 | 具体表现 | 对评测结果的影响 |
|---|---|---|
| 数据污染 | 训练集包含测试题目 | 高分不代表真实泛化能力 |
| 刷题效应 | 模型针对特定 Benchmark 优化 | 排名虚高,实际能力未提升 |
| 场景脱节 | 选择题与真实使用相差甚远 | 排名预测力差 |
| 静态数据集 | 题目固定,无法更新 | 新能力无法被评估 |
| 单维度评测 | 只看准确率 | 忽略速度、成本、可靠性 |
AI Agent 评测的 5 个核心维度
当 AI 系统从"回答问题"进化为"完成任务",评测体系也必须同步升级。
对于 OpenClaw 这类 AI 智能体平台,评测需要覆盖以下 5 个关键维度:
维度 1:任务完成率(Task Completion Rate)
从接收任务到最终完成的整体成功比例。这是最直观的指标,但也最复杂——"完成"的定义本身就是评测设计的核心挑战。
测试方法:给 Agent 一个包含 3-5 个步骤的复合任务,统计完全成功、部分成功、失败的比例。
维度 2:工具调用准确性(Tool Call Accuracy)
Agent 需要从数十个可用工具中选择正确的一个,并以正确参数调用。错误的工具调用不只是失败,还可能产生副作用(如误删文件、发出错误邮件)。
测试方法:设计需要特定工具序列的任务,统计工具选择错误率和参数错误率。
维度 3:多步推理连贯性(Multi-step Reasoning Coherence)
完成一个任务往往需要 5-10 个步骤,Agent 需要在整个过程中保持对目标的清醒认识,不能"走着走着忘了去哪儿"。
测试方法:设计需要 10+ 步骤的长流程任务,观察中途是否出现目标漂移或逻辑断裂。
维度 4:上下文跨轮保留(Cross-turn Context Retention)
在多轮对话中,Agent 需要记住之前交换的信息。"你上次说要在周三开会"这样的信息,在 OpenClaw 的工作流中至关重要。
测试方法:设计需要引用 5+ 轮前信息的任务场景,统计上下文丢失率。
维度 5:幻觉频率(Hallucination Rate)
Agent 虚构不存在的文件、不存在的联系人、错误的日期,这些幻觉在聊天中只是小问题,但在 Agent 场景中可能造成真实损失(如发送错误内容的邮件)。
测试方法:设计需要引用真实数据(文件名、邮件地址、日期)的任务,统计幻觉出现频率。
🎯 开发者建议: 选择 Agent 模型时,任务完成率和工具调用准确性是最重要的两个指标。
推荐使用 API易 apiyi.com 平台快速接入多款模型,通过以上 5 个维度在自己的实际任务上验证效果,
而非单纯依赖排行榜数字。API易 支持按量计费,适合做小规模 A/B 测试再做最终选型。
三、PinchBench 深度解析:OpenClaw 的官方评测标准
PinchBench 诞生的背景
PinchBench 由 kilo.ai 团队使用 Rust 开发,是专为 OpenClaw 场景量身打造的评测基准,开源发布在 GitHub(pinchbench/skill 仓库)。
它解决的核心问题:通用模型排行榜对真实 Agent 性能的预测能力很弱。
研究发现,一个在 MMLU 上得分排名前 5% 的模型,在 OpenClaw 的邮件分类+会议调度组合任务中,可能表现远不如一个 MMLU 排名中等但专门针对工具调用优化的模型。
PinchBench 的出现,让开发者第一次有了一个专门针对 Agent 工作流的可信评测依据。
PinchBench 的 23 个任务类别
PinchBench 使用真实任务而非合成题目,覆盖 23 个任务类别,每个类别都对应 OpenClaw 用户的真实使用场景:
核心任务类别(6大类):
| 任务大类 | 具体测试内容 | 涉及工具 | 评测难度 |
|---|---|---|---|
| 日程管理 | 会议调度、冲突解决、时区处理、周期性提醒 | 日历 API、时区工具 | ★★★☆☆ |
| 代码编写 | 功能实现、Bug 修复、代码重构、单元测试 | 代码执行、文件系统 | ★★★★☆ |
| 邮件处理 | 分类、优先级排序、自动回复草稿、附件处理 | 邮件客户端 API | ★★★☆☆ |
| 信息研究 | 网络搜索、信息聚合、摘要生成、来源核实 | 搜索引擎、浏览器 | ★★★★☆ |
| 文件管理 | 组织整理、格式转换、批量操作、版本控制 | 文件系统、转换工具 | ★★☆☆☆ |
| 多工具协作 | 跨平台数据流转、工具链编排、条件触发 | 多种工具组合 | ★★★★★ |
PinchBench 的评测方法论
PinchBench 采用双重评测机制,兼顾客观性和质量评估:
自动验证(Automated Checks)
用于可验证的客观标准:
- 代码是否通过所有测试用例
- 文件是否被正确移动到指定位置
- 日历事件是否在正确的时间创建
- API 调用是否返回预期格式
LLM 裁判(LLM Judge)
用于需要主观判断的定性评估:
- 邮件回复的语气和专业程度
- 研究报告的信息准确性和完整性
- 任务理解的准确性(是否真正理解了用户意图)
- 边缘情况的处理策略合理性
这种组合方式兼顾了效率(自动化检查可大规模运行)和质量(LLM 裁判捕捉人类难以量化的细节)。
三维评测指标矩阵:
┌─────────────────────────────────────────────────┐
│ PinchBench 三维评测体系 │
├─────────────────────────────────────────────────┤
│ 成功率 (Success Rate) │
│ → 综合衡量任务完成质量 │
│ → 主要排名维度 │
│ → 结合自动验证 + LLM 裁判 │
├─────────────────────────────────────────────────┤
│ 速度 (Speed) │
│ → 完成任务的平均时间(秒/分钟) │
│ → 对实时响应场景至关重要 │
│ → 包含 API 延迟和推理时间 │
├─────────────────────────────────────────────────┤
│ 成本 (Cost) │
│ → 完成任务消耗的 Token 费用(USD) │
│ → 高频使用场景的关键指标 │
│ → 帮助计算 ROI 和选型决策 │
└─────────────────────────────────────────────────┘
截至 2026 年 3 月 13 日,PinchBench 公开排行榜数据:
- 📊 49 个模型完成评测,覆盖所有主流商业和开源模型
- 🔄 327 次运行记录,持续更新
- 🌐 公开排行榜:pinchbench.com(实时更新)
- 📁 开源仓库:github.com/pinchbench/skill(任务定义公开)
🎯 PinchBench 使用建议: 在查看排行榜时,建议切换查看成功率、速度和成本三个视图,
根据自己的实际需求(实时性 vs 质量 vs 成本)来筛选最适合的模型。
通过 API易 apiyi.com 统一接入后,可以方便地在同一业务场景下对比不同模型的实际成本。
四、PinchBench 排行榜深度解读与模型选型指南
当前 Top 5 成功率排名(2026年3月13日数据)
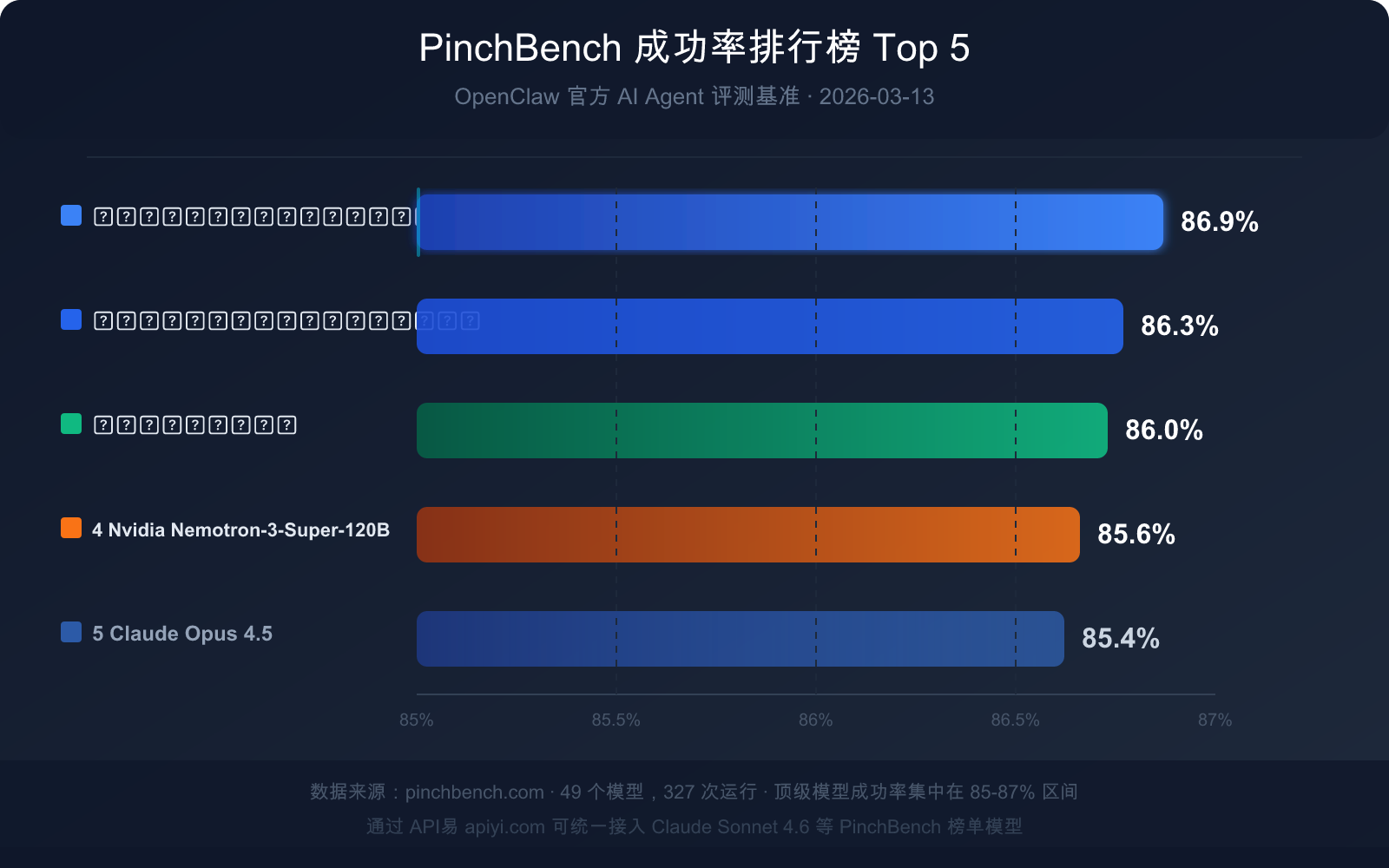
| 排名 | 模型名称 | 成功率 | 模型类型 | 核心优势 |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | 商业闭源 | 成功率最高,速度与质量均衡 |
| 🥈 2 | Claude Opus 4.6 | 86.3% | 商业闭源 | 复杂推理能力最强 |
| 🥉 3 | GPT-5.4 | 86.0% | 商业闭源 | 工具调用稳定性好 |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | 开源可部署 | 开源模型中表现最佳 |
| 5 | Claude Opus 4.5 | 85.4% | 商业闭源 | 上一代旗舰,仍具竞争力 |
关键数据洞察:85% 成功率意味着什么?
顶级模型在 PinchBench 上的成功率集中在 85%-87% 区间,而非接近满分。这个数字本身传递出三个重要信号:
信号 1:AI Agent 任务至今仍是高难度问题
即使是排名第一的 Claude Sonnet 4.6(86.9%),在 100 个任务中仍有约 13 个会失败。这不是模型能力不足,而是真实世界任务的固有复杂性——模糊的指令、不完整的信息、工具调用的边缘情况,都会导致失败。
信号 2:容错设计在 Agent 开发中不可或缺
当 13% 的失败率是"顶级水平"时,没有人工审核节点的全自动 Agent 流程在生产环境中是高风险的。最佳实践是:高风险操作(如发送邮件、提交代码)保留人工确认步骤。
信号 3:模型之间差距极小,任务设计更重要
排名 1 和排名 5 之间的差距仅为 1.5 个百分点(86.9% vs 85.4%)。这意味着:选择哪个模型的影响,远小于如何设计任务提示词、如何定义工具接口、如何处理错误情况。
三维指标综合分析
仅看成功率是不够的。以下是三个维度的综合考量框架:
| 使用场景 | 优先指标 | 次要指标 | 推荐模型方向 |
|---|---|---|---|
| 高频轻量任务(邮件分类、提醒) | 速度 + 成本 | 成功率 | Claude Haiku 4.5 等轻量模型 |
| 复杂工程任务(代码重构、研究) | 成功率 | 速度 | Claude Sonnet 4.6 / GPT-5.4 |
| 实时响应场景(即时助理) | 速度 | 成功率 | 速度榜 Top 模型 |
| 成本敏感型应用 | 成本 | 成功率 | 开源自部署 / API 低价模型 |
| 企业安全合规 | 成功率 + 可控性 | 成本 | 私有化部署开源模型 |
🎯 综合选型建议: 根据 PinchBench 数据,Claude Sonnet 4.6 是当前 OpenClaw 场景下成功率最高的综合选择。
对于成本敏感的高频场景,建议先用 Claude Sonnet 4.6 确定任务成功率基线,
再测试更轻量模型能否在允许的成功率范围内显著降低成本。
所有这些测试都可以通过 API易 apiyi.com 的统一 API 接口完成,无需分别注册多个服务商账号。
开源模型的竞争力分析
Nvidia Nemotron-3-Super-120B 以 85.6% 的成功率排名第 4,仅比第一名低 1.3 个百分点——这对于开源模型来说是一个非常亮眼的成绩。
开源模型的优势:
- 数据主权:模型和数据均在自控环境,满足合规要求
- 成本结构:一次性 GPU 投入,无后续 API 调用费用(高量场景)
- 定制空间:可以针对特定任务进行 Fine-tuning
开源模型的局限:
- 部署成本:120B 参数模型需要 4-8 张 A100/H100 GPU
- 维护负担:模型更新、版本管理需要专职运维
- 初期测试成本:在确认开源模型适合自己场景之前,通过商业 API 做原型验证往往更经济
五、实战指南:如何在 OpenClaw 中配置最优模型
快速接入 Claude Sonnet 4.6 驱动 OpenClaw
以下是通过 API易 接入 PinchBench 排名第一模型的完整配置示例:
步骤 1:获取 API 密钥
访问 API易官网 apiyi.com 注册账号,进入控制台获取 API Key。API易 提供 OpenAI 兼容接口,同时支持 Anthropic 原生 SDK。
步骤 2:配置 OpenClaw 的模型后端
# OpenClaw 配置文件示例(config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # 最大执行步骤数
tool_timeout: 30 # 单次工具调用超时(秒)
retry_on_error: true # 工具调用失败时自动重试
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # 高风险操作需人工确认
步骤 3:验证配置效果
# 使用 Anthropic SDK 测试连接
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# 发送测试请求
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "请列举你能在 OpenClaw 中执行的 3 种任务类型"
}]
)
print(response.content[0].text)
步骤 4:多模型 A/B 测试配置
# 在同一任务上对比不同模型(推荐在正式部署前执行)
models_to_test = [
"claude-sonnet-4-6", # PinchBench 排名第一
"gpt-5.4-turbo", # PinchBench 排名第三(兼容 OpenAI 格式)
"claude-opus-4-5", # 上一代旗舰,成本参考对比
]
# API易 支持所有上述模型的统一接口调用
# base_url 不变,只需修改 model 参数
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: 成功率={result.success_rate}, 耗时={result.avg_time}s, 成本=${result.cost_per_task}")
🎯 快速上手: 访问 API易 apiyi.com 注册即可获得测试额度,
支持 Claude Sonnet 4.6、GPT-5.4 等 PinchBench 榜单模型的统一 API 接入,
无需分别申请多个服务商的访问权限,大幅降低模型测试的前期门槛。
用 PinchBench 的 5 个维度自测你的 Agent
在部署到生产环境前,建议用以下自测清单评估你的 Agent 配置:
PinchBench 启发的 Agent 自测清单
□ 维度1-任务完成率
给 Agent 10 个包含 3 步以上的复合任务
记录完全成功 / 部分成功 / 失败的数量
目标:完全成功率 ≥ 80%
□ 维度2-工具调用准确性
检查工具调用日志,统计以下错误类型:
- 工具选择错误(选了错误的工具)
- 参数格式错误(参数类型或格式不对)
- 参数值错误(参数类型对但值不合理)
目标:工具错误率 ≤ 5%
□ 维度3-多步推理连贯性
设计一个需要 15 步以上的长流程任务
观察中途是否出现目标漂移(忘记了最初目标)
目标:长流程任务无目标漂移
□ 维度4-上下文保留
在第 1 轮提供关键信息,在第 8 轮引用该信息
检查 Agent 是否能正确引用
目标:跨轮引用准确率 ≥ 90%
□ 维度5-幻觉检测
设计需要引用真实数据(文件名/联系人/日期)的任务
检查 Agent 是否捏造不存在的数据
目标:幻觉发生率 ≤ 2%
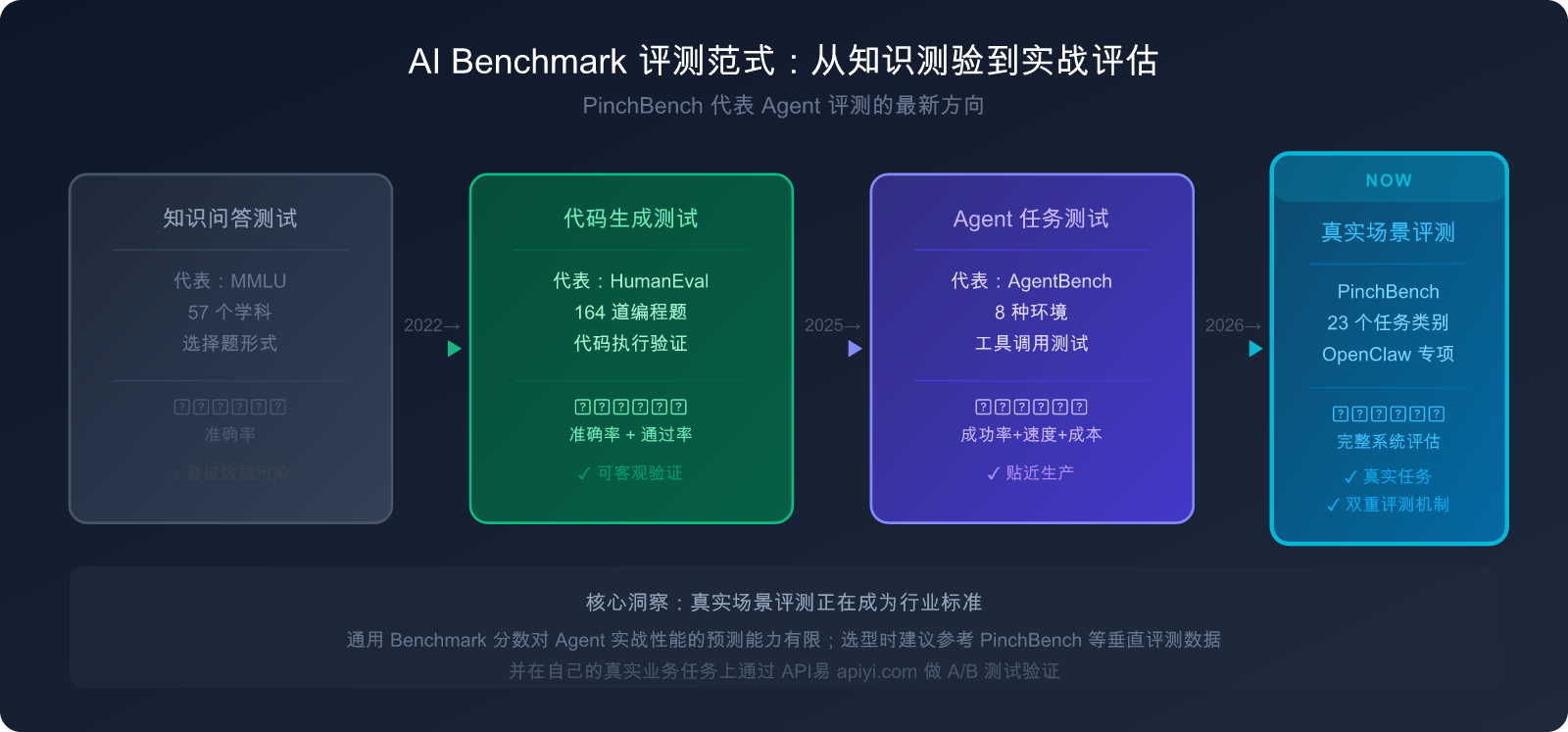
六、AI Benchmark 的未来:从单点评测到生态系统评估
当前 Benchmark 体系的演进趋势
2026 年,AI Benchmark 领域正在经历一场深层转变。这场转变的核心,是评测对象从单一模型扩展到完整的 Agent 系统。
传统 Benchmark 的思维方式是:给模型出题,看它答得对不对。但在 OpenClaw 这样的 Agent 平台普及之后,真正重要的问题变成了:当模型作为一个系统的"大脑",它能让这个系统完成工作吗?
这个问题的答案,不仅取决于模型的知识储备,还取决于:
- 模型对工具描述的理解能力
- 模型在不确定信息下的决策策略
- 模型对错误的识别和恢复能力
- 模型对用户意图的长期追踪能力
PinchBench 的价值,正在于它把这些维度量化并公开展示。
AI Benchmark 数据的正确使用姿势
Benchmark 数据有价值,但也很容易被误用。以下是几个常见误区和正确做法:
误区 1:把排名最高的模型当作"一定最好"
正确做法:排名基于 PinchBench 的特定任务集,你的任务可能有不同的权重分布。先在自己的任务上测试,再做选型。
误区 2:只看成功率,忽略速度和成本
正确做法:三维指标缺一不可。在批处理场景下,速度差 50% 意味着成本节省 50%;在实时响应场景下,速度差 2 秒意味着用户体验的显著下降。
误区 3:认为差 1% 的成功率无关紧要
正确做法:1% 的成功率差距在小规模测试中看起来微不足道,但在高频生产场景中可能每天产生数百次失败。需要结合你的任务量级来评估实际影响。
误区 4:用静态 Benchmark 数据做长期规划
正确做法:AI 模型迭代速度极快,2026 年主流厂商平均每季度发布一次重要更新。建议将模型性能评估纳入常规技术审查,而非"一次选型定终身"。
企业级 Agent 评测的最佳实践
对于在企业中部署 OpenClaw 或类似 Agent 平台的技术团队,以下是一套可落地的评测最佳实践:
第一步:建立基线任务集
从你的实际业务中选取 20-50 个典型任务,涵盖日常高频操作和偶发复杂场景。这个任务集应该由业务方和技术方共同定义,避免纯技术视角导致的评测偏差。
第二步:三维指标持续追踪
企业内部 Agent 评测指标体系建议
核心指标(每周统计):
- 任务完成率:目标 ≥ 85%(对标 PinchBench 顶级模型水准)
- 工具调用错误率:目标 ≤ 5%
- 平均任务耗时:根据业务 SLA 定义
辅助指标(每月统计):
- Token 成本/任务:控制运营成本
- 人工干预率:需要人工接管的任务占比
- 错误类型分布:分析改进方向
预警指标(实时监控):
- 高风险操作失败率:发邮件/删文件等失败立即告警
- 幻觉事件:捏造信息的情况需立即记录并分析
第三步:模型定期重评
建议每季度重新用内部任务集评测当前部署的模型,以及新发布的候选模型。结合 PinchBench 的最新公开数据,判断是否需要升级或切换模型。
第四步:积累领域知识
通用 Benchmark 无法覆盖每个企业的特殊场景。随着使用积累,逐步建立适合自己业务的任务集和评分标准,这将成为选择 AI 供应商的重要筛选工具。
🎯 企业选型建议: 在引入 Agent 平台的初期,建议通过 API易 apiyi.com 按量计费接入多款候选模型,
用自己的内部任务集做 3-4 周的实际测试后再决定是否迁移到包月方案。
API易 支持 Claude、GPT、Gemini 等主流模型的统一接口,
测试阶段无需分别注册多个服务商账号,大幅降低评测的管理成本。
常见问题解答
Q: OpenClaw 和 AutoGPT、AutoGen 有什么核心区别?
OpenClaw 的核心差异在于接入方式和使用门槛:它通过消息应用(Signal、WhatsApp 等)提供 Agent 界面,普通用户无需安装专用 App 或了解技术细节。从技术架构看,OpenClaw 更接近"个人 AI 秘书",而 AutoGen 等框架更适合开发者构建复杂的多 Agent 系统。OpenClaw 强调"开箱即用的消费级体验",AutoGen 强调"灵活的企业级开发框架"。
🎯 无论选择哪种 Agent 框架,都可以通过 API易 apiyi.com 统一接入后端模型,避免为每个框架单独配置 API 密钥。
Q: PinchBench 的成功率排名多久更新一次?
PinchBench 排行榜是实时更新的——每次有新模型完成评测,数据立即反映在 pinchbench.com 上。随着各大厂商持续发布新版本,排名会频繁变动。建议在正式选型前查看最新数据。本文数据基于 2026 年 3 月 13 日快照(49 个模型,327 次运行记录)。
Q: 如何为 OpenClaw 选择最合适的模型?
推荐三步选型法:
- 看 PinchBench 成功率:筛选任务完成率 Top 5
- 看速度和成本维度:根据你的任务类型(实时 vs 批处理,高频 vs 低频)再筛选
- 实际 A/B 测试:用 2-3 款候选模型在你的真实业务任务上对比
通过 API易 apiyi.com 可以用同一个 base_url 快速切换不同模型,完成 A/B 测试后再做最终决策。
Q: 开源模型能完全替代商业模型驱动 OpenClaw 吗?
从 PinchBench 数据看,Nvidia Nemotron-3-Super-120B(85.6%)与顶级商业模型(86.9%)差距约 1.3 个百分点。对于一般 Agent 任务,这个差距可以接受。但需注意:自部署 120B 参数模型需要 4-8 张高端 GPU,初期硬件投入和运维成本不低。建议先用商业 API 验证 Agent 设计可行性,再评估是否值得迁移到自部署开源模型。
Q: OpenClaw 的安全风险如何规避?
核心原则是权限最小化:只授予 OpenClaw 完成任务所需的最小权限范围。具体建议:
- 邮件只读权限(而非读写删除全权限)
- 代码仓库只读+提 PR 权限(而非直接推送到主分支)
- 文件系统限定在特定工作目录(而非整个文件系统)
- 高风险操作(发送邮件、删除文件)必须加人工确认步骤
企业部署时,还需配置完整的操作审计日志,确保每次 Agent 操作都有可追溯记录。
Q: PinchBench 和其他 Agent Benchmark 有什么区别?
PinchBench 最大的特点是场景专一性:它专门针对 OpenClaw 的使用场景设计,而不是通用 Agent 评测。这意味着它对 OpenClaw 用户的参考价值更高,但不适合直接用来评估其他 Agent 框架的模型选择。其他知名的 Agent Benchmark 包括 AgentBench(覆盖多种环境)、SWE-Bench(专注代码任务)等,各有侧重。
总结:OpenClaw + PinchBench 为 Agent 时代建立了新标准
OpenClaw 从一个奥地利开发者的周末项目,在两个月内成长为全球最热门的 AI 智能体平台,这背后反映的是整个行业对"AI 真正做事"的强烈渴望。
而 PinchBench 的出现,则填补了 Agent 评测领域的关键空白:我们终于有了一把专门测量 Agent 能力的尺子。
核心结论速览:
- Claude Sonnet 4.6 是当前 OpenClaw 场景的综合最优选(86.9% 成功率,PinchBench 排名第一)
- 顶级模型成功率集中在 85-87%,Agent 任务仍具挑战,容错设计不可或缺
- 速度和成本同样重要,高成功率模型未必适合所有场景,需三维综合评估
- PinchBench 代表 AI 评测的未来方向:真实场景任务正在取代合成测试
- 模型选择差异约 1-2%,任务设计和提示词工程的影响往往更大
对于想要深入 OpenClaw 生态的开发者和企业来说,现在是一个绝佳的时机:
开源社区活跃,评测工具完善,主流模型的 API 接入成本也在持续下降。你不需要等到"完美方案"出现,可以从现在开始用小规模任务验证 Agent 工作流的可行性。
🎯 立即行动: 如果你正在构建基于 OpenClaw 的 AI 工作流,推荐通过 API易 apiyi.com 统一接入。
平台支持 Claude Sonnet 4.6(PinchBench 第一)、GPT-5.4(第三)等主流模型,
同一套 API 接口,无需分别注册多个服务商,支持按量计费,适合从小规模测试开始逐步扩展。
访问 API易官网 apiyi.com 注册即可开始体验。
本文数据基于 2026 年 3 月公开资料整理,PinchBench 排行榜实时数据请访问 pinchbench.com 查看最新版本。
作者:APIYI Team | 关于 AI 模型 API 接入,欢迎访问 API易 apiyi.com 了解详情