Pada tahun 2026, sebuah proyek open-source yang dibuat oleh seorang pengembang independen dari Austria di akhir pekan, berhasil mengumpulkan 247 ribu GitHub Stars dalam dua bulan, menjadikannya platform agen AI yang diperebutkan oleh perusahaan di Silicon Valley dan Tiongkok.
Proyek ini bernama OpenClaw.
Namun, seiring dengan itu, muncul pertanyaan: Dalam skenario agen nyata seperti OpenClaw, model AI mana yang memiliki performa terbaik?
Inilah masalah yang ingin dipecahkan oleh PinchBench. Ini adalah benchmark evaluasi resmi OpenClaw, dikembangkan oleh tim kilo.ai menggunakan Rust, yang menggantikan pengujian sintetis dengan tugas nyata, memberikan dasar yang dapat diandalkan bagi pengembang untuk memilih model.
Artikel ini akan dimulai dengan kisah bangkitnya OpenClaw, menganalisis secara mendalam sistem evaluasi PinchBench, membantu Anda memahami arti sebenarnya dari benchmark AI, dan bagaimana memilih model yang sesuai untuk alur kerja agen Anda berdasarkan data evaluasi.
1. Apa Itu OpenClaw: Fenomena Sumber Terbuka yang Berubah Nama 3 Kali dalam Sebulan
Kelahiran OpenClaw dan Kontroversi Penamaan
Kisah OpenClaw dimulai pada November 2025.
Pengembang asal Austria, Peter Steinberger, menggunakan waktu luangnya untuk membangun platform agen AI yang awalnya diberi nama Clawdbot. Konsep inti proyek ini sederhana: menjadikan AI tidak hanya sebagai alat obrolan, tetapi benar-benar dapat mengambil alih alur kerja digital Anda—membaca email, menulis kode, mengelola kalender, dan mencari informasi.
Namun, konsep agen AI bukanlah hal baru. Mengapa OpenClaw bisa meledak dalam semalam?
Kuncinya terletak pada kombinasi waktu yang tepat dan dukungan sumber terbuka. Pada akhir Januari 2026, dengan viralnya proyek Moltbook, seluruh komunitas teknologi mencapai puncak keinginan untuk "membuat AI benar-benar bekerja", dan Clawdbot pun menjadi sorotan.
Namun, tak lama kemudian, Anthropic mengirimkan pemberitahuan keberatan merek dagang—nama "Clawd" dalam Clawdbot dianggap berisiko menimbulkan kebingungan dengan nama produk internal Anthropic. Proyek tersebut terpaksa segera berganti nama menjadi Moltbot pada 27 Januari 2026, sebagai penghormatan kepada proyek Moltbook yang sedang populer saat itu.
Namun, tiga hari kemudian, Steinberger mengakui di GitHub bahwa nama baru tersebut "tidak enak diucapkan" ("never quite rolled off the tongue"), sehingga proyek tersebut kembali berganti nama menjadi OpenClaw dan bertahan hingga saat ini.
Kontroversi penamaan ini justru menjadi "pemasaran gratis" terbaik bagi proyek tersebut, membuat OpenClaw dikenal luas di komunitas pengembang.
Hingga 2 Maret 2026, OpenClaw telah mengumpulkan di GitHub:
- ⭐ 247 ribu Bintang (setara dengan hampir setengah dari bintang kerangka kerja React pada periode yang sama)
- 🍴 47,7 ribu Forks
- 🌍 Telah diterapkan secara besar-besaran di perusahaan-perusahaan di Silicon Valley, Eropa, dan Tiongkok
Arsitektur Teknologi Inti OpenClaw
Filosofi desain OpenClaw adalah: berjalan secara lokal, agnostik model, dan terintegrasi dengan aplikasi pesan.
Ketiga karakteristik ini menentukan perbedaan mendasar antara OpenClaw dengan kerangka kerja agen AI lainnya.
Berjalan secara lokal berarti data Anda tidak melewati server pihak ketiga mana pun. Berbeda dengan sebagian besar asisten AI berbentuk SaaS, OpenClaw diterapkan di perangkat pengguna sendiri, dan pemanggilan model API juga dapat diarahkan ke titik akhir pribadi.
Agnostik model berarti OpenClaw sendiri tidak terikat pada Model Bahasa Besar (LLM) tertentu. Ini adalah "cangkang otak" yang mendukung integrasi dengan model-model utama seperti Claude, GPT, DeepSeek, dan lainnya. Pengembang dapat beralih dengan bebas sesuai jenis tugas dan anggaran biaya.
Terintegrasi dengan aplikasi pesan adalah desain paling khas dari OpenClaw—pengguna biasa tidak perlu membuka aplikasi khusus apa pun. Cukup mengirim pesan langsung di Signal, Telegram, Discord, atau WhatsApp, mereka sudah bisa memanggil kemampuan agen AI. Ini secara signifikan mengurangi hambatan penggunaan, sehingga pengguna non-teknis pun dapat merasakan manfaatnya.
| Dimensi Desain | Pilihan OpenClaw | Alternatif Utama | Penjelasan Perbedaan |
|---|---|---|---|
| Lokasi Penerapan | Berjalan Lokal | SaaS Berbasis Cloud | Privasi data lebih kuat, tetapi perlu pemeliharaan sendiri |
| Keterikatan Model | Sepenuhnya Agnostik | Terikat pada Model Tertentu | Fleksibel beralih, tetapi perlu konfigurasi sendiri |
| Antarmuka Pengguna | Aplikasi Pesan | Web/Aplikasi Khusus | Hambatan awal rendah, fungsionalitas terbatas oleh aplikasi pesan |
| Lingkup Izin | Akses Luas | Batasan Sandbox | Fungsionalitas kuat, tetapi risiko keamanan lebih tinggi |
| Lisensi Sumber Terbuka | Sepenuhnya Sumber Terbuka | Sumber Tertutup/Sebagian Sumber Terbuka | Didorong oleh komunitas, tetapi dukungan terbatas |
🎯 Saran Penggunaan: Menerapkan OpenClaw memerlukan konfigurasi backend LLM berkualitas tinggi.
Kami menyarankan untuk mengintegrasikan Claude Sonnet 4.6 atau GPT-5.4 melalui APIYI apiyi.com.
Kedua model ini menunjukkan kinerja yang sangat baik di PinchBench, dan APIYI mendukung peralihan antarmuka terpadu,
memudahkan Anda membandingkan efek model yang berbeda tanpa mengubah konfigurasi inti OpenClaw.
Batasan Kemampuan OpenClaw
Rentang kemampuan yang didukung OpenClaw cukup luas, tetapi justru karena inilah muncul kontroversi keamanan:
Sumber data yang dapat diakses:
- Akun email (membaca, mengklasifikasikan, membuat draf balasan)
- Sistem kalender (melihat, membuat, mengubah jadwal)
- Sistem file (menjelajahi, membaca, membuat, memindahkan file)
- Repositori kode (membaca kode, menjalankan pengujian, mengirim perubahan)
- Platform pesan (agregasi dan respons pesan lintas platform)
- Informasi web (mencari, meringkas, mengekstraksi terstruktur)
Skenario penggunaan umum:
Pengguna mengirim di Telegram: "Tolong atur email saya hari ini,
tandai yang perlu dibalas hari ini, dan buat draf balasannya."
Alur Eksekusi Agen OpenClaw:
1. Memanggil alat email, membaca email yang belum dibaca hari ini
2. Menggunakan LLM untuk menilai urgensi setiap email
3. Menyaring daftar email yang perlu dibalas hari ini
4. Membuat draf balasan untuk setiap email
5. Mengembalikan hasil pengaturan dan pratinjau draf di Telegram
Kemampuan "benar-benar menyelesaikan pekerjaan" semacam ini adalah perbedaan mendasar antara OpenClaw dan chatbot sederhana.
Steinberger Bergabung dengan OpenAI dan Masa Depan Proyek
Pada 14 Februari 2026, sebuah berita mengguncang seluruh komunitas sumber terbuka: Steinberger mengumumkan di GitHub bahwa ia akan bergabung dengan OpenAI, dan proyek tersebut akan diserahkan kepada yayasan sumber terbuka independen.
Dampak ini terhadap OpenClaw bersifat ganda: di satu sisi, proyek mendapatkan operasi dan perlindungan hukum yang lebih profesional; di sisi lain, publik mulai berspekulasi tentang motif di balik OpenAI mengakuisisi pendiri ini—apakah untuk menyerap teknologi, atau untuk mencegah potensi pesaing?
Saat ini, Yayasan OpenClaw telah didirikan, dan proyek tetap sepenuhnya sumber terbuka. Namun, penyesuaian prioritas peta jalan pengembangan terlihat jelas: fitur keamanan tingkat perusahaan dan sistem kontrol izin menjadi fokus utama versi berikutnya.
Kontroversi Keamanan: Risiko dari Kemampuan yang Kuat
Kebutuhan OpenClaw akan izin sistem yang luas telah menarik perhatian peneliti keamanan siber sejak awal.
Pada Maret 2026, otoritas Tiongkok mengumumkan pembatasan bagi perusahaan milik negara dan lembaga pemerintah untuk menjalankan OpenClaw di komputer kantor. Kekhawatiran utama meliputi:
- Data mungkin bocor ke penyedia layanan asing melalui pemanggilan API LLM
- Izin yang luas dapat menjadi titik masuk serangan jika tidak dikonfigurasi dengan benar
- Informasi sensitif internal perusahaan dapat ditransfer antar sistem oleh agen
Insiden ini mengingatkan semua pengembang perusahaan: saat memperkenalkan alat agen yang kuat, prinsip izin minimal dan log audit adalah dasar keamanan yang tidak boleh dilewatkan.
2. Peran Nyata Benchmark di Industri AI: Dari Ujian hingga Praktik Nyata
Mengapa Industri AI Tidak Bisa Lepas dari Benchmark
Jika Anda pernah ingin membandingkan kemampuan dua model AI, kemungkinan besar Anda pernah menghadapi dilema: semua vendor mengatakan model mereka "terkuat", tetapi apa artinya "kuat"? Dalam tugas apa? Dibandingkan dengan apa?
Benchmark (tolok ukur evaluasi) adalah sistem pengujian standar yang lahir untuk menyelesaikan masalah ini.
Di industri AI, benchmark yang baik harus memenuhi tiga syarat:
- Reproduksibilitas: Siapa pun yang menggunakan set pengujian yang sama akan mendapatkan hasil yang sama.
- Representativitas: Konten pengujian dapat mencerminkan kebutuhan kemampuan skenario penggunaan nyata.
- Keadilan: Set pengujian tidak terkontaminasi oleh data pelatihan pengembang model.
Pada tahun 2026, ada lebih dari 15 benchmark utama yang aktif digunakan di seluruh industri, tetapi yang benar-benar dapat memprediksi kinerja di lingkungan produksi, diperkirakan hanya sekitar 4.
Keterbatasan Benchmark Tradisional
Untuk memahami nilai PinchBench, kita perlu memahami mengapa benchmark tradisional "tidak cukup".
MMLU (Pemahaman Bahasa Multitugas Skala Besar)
MMLU adalah evaluasi pengetahuan umum yang paling banyak dikutip saat ini, mencakup 57 disiplin ilmu, dengan total sekitar 14.000 soal pilihan ganda. Pertanyaan-pertanyaan tersebut mencakup bidang kedokteran, hukum, sejarah, matematika, pemrograman, dan lainnya.
Masalahnya adalah: ini adalah soal pilihan ganda, model hanya perlu memilih satu dari 4 opsi. Dalam skenario agen yang sebenarnya, model perlu menghasilkan jawaban secara mandiri, bahkan memanggil alat untuk mendapatkan informasi—ini sama sekali berbeda dengan "memilih satu dari 4 opsi".
HumanEval (Pengujian Pembuatan Kode)
HumanEval adalah benchmark ikonik untuk mengukur kemampuan pembuatan kode, berisi 164 masalah pemrograman Python. Namun, soal-soalnya relatif tetap, dan model mungkin pernah terpapar jenis soal serupa saat pelatihan, menyebabkan "efek latihan soal"—skor tinggi tidak selalu mencerminkan kemampuan pemrograman yang sebenarnya.
Kelemahan Umum Pengujian Sintetis:
| Jenis Masalah | Manifestasi Spesifik | Dampak pada Hasil Evaluasi |
|---|---|---|
| Kontaminasi Data | Set pelatihan mengandung soal tes | Skor tinggi tidak mencerminkan kemampuan generalisasi yang sebenarnya |
| Efek Latihan Soal | Model dioptimalkan untuk benchmark tertentu | Peringkat yang terlalu tinggi, kemampuan sebenarnya tidak meningkat |
| Ketidaksesuaian Skenario | Soal pilihan ganda sangat berbeda dengan penggunaan nyata | Daya prediksi peringkat yang buruk |
| Dataset Statis | Soal tetap, tidak dapat diperbarui | Kemampuan baru tidak dapat dievaluasi |
| Evaluasi Satu Dimensi | Hanya melihat akurasi | Mengabaikan kecepatan, biaya, keandalan |
5 Dimensi Inti Evaluasi Agen AI
Ketika sistem AI berevolusi dari "menjawab pertanyaan" menjadi "menyelesaikan tugas", sistem evaluasi juga harus ditingkatkan secara bersamaan.
Untuk platform agen AI seperti OpenClaw, evaluasi perlu mencakup 5 dimensi kunci berikut:
Dimensi 1: Tingkat Penyelesaian Tugas (Task Completion Rate)
Proporsi keberhasilan keseluruhan dari penerimaan tugas hingga penyelesaian akhir. Ini adalah indikator yang paling intuitif, tetapi juga yang paling kompleks—definisi "penyelesaian" itu sendiri adalah tantangan inti dalam desain evaluasi.
Metode Pengujian: Berikan agen tugas gabungan yang terdiri dari 3-5 langkah, dan hitung proporsi keberhasilan penuh, keberhasilan sebagian, dan kegagalan.
Dimensi 2: Akurasi Pemanggilan Alat (Tool Call Accuracy)
Agen perlu memilih alat yang benar dari puluhan alat yang tersedia, dan memanggilnya dengan parameter yang tepat. Pemanggilan alat yang salah tidak hanya berarti kegagalan, tetapi juga dapat menimbulkan efek samping (misalnya, salah menghapus file, mengirim email yang salah).
Metode Pengujian: Rancang tugas yang memerlukan urutan alat tertentu, dan hitung tingkat kesalahan pemilihan alat dan kesalahan parameter.
Dimensi 3: Koherensi Penalaran Multilangkah (Multi-step Reasoning Coherence)
Menyelesaikan suatu tugas seringkali membutuhkan 5-10 langkah. Agen perlu menjaga pemahaman yang jelas tentang tujuan sepanjang proses, tidak boleh "tersesat di tengah jalan".
Metode Pengujian: Rancang tugas alur kerja panjang yang membutuhkan 10+ langkah, dan amati apakah terjadi penyimpangan tujuan atau diskontinuitas logis di tengah jalan.
Dimensi 4: Retensi Konteks Lintas Giliran (Cross-turn Context Retention)
Dalam percakapan multi-giliran, agen perlu mengingat informasi yang telah dipertukarkan sebelumnya. Informasi seperti "Anda bilang terakhir kali akan rapat pada hari Rabu" sangat penting dalam alur kerja OpenClaw.
Metode Pengujian: Rancang skenario tugas yang memerlukan referensi informasi dari 5+ giliran sebelumnya, dan hitung tingkat kehilangan konteks.
Dimensi 5: Frekuensi Halusinasi (Hallucination Rate)
Agen mengarang file yang tidak ada, kontak yang tidak ada, tanggal yang salah. Halusinasi ini mungkin hanya masalah kecil dalam obrolan, tetapi dalam skenario agen dapat menyebabkan kerugian nyata (misalnya, mengirim email dengan konten yang salah).
Metode Pengujian: Rancang tugas yang memerlukan referensi data nyata (nama file, alamat email, tanggal), dan hitung frekuensi munculnya halusinasi.
🎯 Saran Pengembang: Saat memilih model agen, tingkat penyelesaian tugas dan akurasi pemanggilan alat adalah dua indikator terpenting.
Disarankan untuk menggunakan platform APIYI apiyi.com untuk mengintegrasikan beberapa model dengan cepat, memverifikasi efeknya pada tugas nyata Anda menggunakan 5 dimensi di atas,
daripada hanya mengandalkan angka peringkat. APIYI mendukung pembayaran sesuai penggunaan, cocok untuk melakukan pengujian A/B skala kecil sebelum membuat pilihan akhir.
Tiga. Analisis Mendalam PinchBench: Standar Penilaian Resmi OpenClaw
Latar Belakang Lahirnya PinchBench
PinchBench dikembangkan oleh tim kilo.ai menggunakan Rust, merupakan benchmark penilaian yang dirancang khusus untuk skenario OpenClaw, dan dirilis sebagai open source di GitHub (repositori pinchbench/skill).
Masalah inti yang dipecahkan: Peringkat model umum memiliki kemampuan prediksi yang lemah terhadap kinerja Agent yang sebenarnya.
Penelitian menunjukkan bahwa model yang menempati peringkat 5% teratas dalam skor MMLU, dalam tugas gabungan klasifikasi email + penjadwalan rapat di OpenClaw, mungkin berkinerja jauh lebih buruk daripada model yang peringkat MMLU-nya sedang tetapi dioptimalkan khusus untuk pemanggilan alat.
Kemunculan PinchBench memberikan pengembang, untuk pertama kalinya, dasar penilaian yang tepercaya yang khusus ditujukan untuk alur kerja Agent.
23 Kategori Tugas PinchBench
PinchBench menggunakan tugas nyata, bukan soal buatan, mencakup 23 kategori tugas, di mana setiap kategori sesuai dengan skenario penggunaan nyata pengguna OpenClaw:
Kategori Tugas Inti (6 Kategori Utama):
| Kategori Tugas Utama | Konten Uji Spesifik | Alat yang Terlibat | Tingkat Kesulitan Penilaian |
|---|---|---|---|
| Manajemen Jadwal | Penjadwalan rapat, penyelesaian konflik, penanganan zona waktu, pengingat berkala | API Kalender, alat zona waktu | ★★★☆☆ |
| Penulisan Kode | Implementasi fitur, perbaikan Bug, refactoring kode, pengujian unit | Eksekusi kode, sistem file | ★★★★☆ |
| Penanganan Email | Klasifikasi, prioritas, draf balasan otomatis, penanganan lampiran | API Klien Email | ★★★☆☆ |
| Penelitian Informasi | Pencarian web, agregasi informasi, pembuatan ringkasan, verifikasi sumber | Mesin pencari, peramban | ★★★★☆ |
| Manajemen File | Organisasi, konversi format, operasi massal, kontrol versi | Sistem file, alat konversi | ★★☆☆☆ |
| Kolaborasi Multialat | Transfer data lintas platform, orkestrasi rantai alat, pemicu bersyarat | Kombinasi berbagai alat | ★★★★★ |
Metodologi Penilaian PinchBench
PinchBench mengadopsi mekanisme penilaian ganda, yang mempertimbangkan objektivitas dan evaluasi kualitas:
Verifikasi Otomatis (Automated Checks)
Digunakan untuk standar objektif yang dapat diverifikasi:
- Apakah kode melewati semua test case
- Apakah file dipindahkan dengan benar ke lokasi yang ditentukan
- Apakah acara kalender dibuat pada waktu yang tepat
- Apakah pemanggilan API mengembalikan format yang diharapkan
Juri Model Bahasa Besar (LLM Judge)
Digunakan untuk evaluasi kualitatif yang memerlukan penilaian subjektif:
- Nada dan tingkat profesionalisme balasan email
- Akurasi dan kelengkapan informasi laporan penelitian
- Akurasi pemahaman tugas (apakah benar-benar memahami maksud pengguna)
- Rasionalitas strategi penanganan kasus-kasus ekstrem
Kombinasi ini mempertimbangkan efisiensi (pemeriksaan otomatis dapat dijalankan dalam skala besar) dan kualitas (juri Model Bahasa Besar menangkap detail yang sulit diukur oleh manusia).
Matriks Indikator Penilaian Tiga Dimensi:
┌─────────────────────────────────────────────────┐
│ Sistem Penilaian Tiga Dimensi PinchBench│
├─────────────────────────────────────────────────┤
│ Tingkat Keberhasilan (Success Rate) │
│ → Mengukur kualitas penyelesaian tugas secara komprehensif│
│ → Dimensi peringkat utama │
│ → Menggabungkan verifikasi otomatis + Juri Model Bahasa Besar│
├─────────────────────────────────────────────────┤
│ Kecepatan (Speed) │
│ → Waktu rata-rata untuk menyelesaikan tugas (detik/menit)│
│ → Sangat penting untuk skenario respons *real-time*│
│ → Termasuk latensi API dan waktu inferensi │
├─────────────────────────────────────────────────┤
│ Biaya (Cost) │
│ → Biaya Token (USD) yang dikeluarkan untuk menyelesaikan tugas│
│ → Indikator kunci untuk skenario penggunaan frekuensi tinggi│
│ → Membantu menghitung ROI dan keputusan pemilihan model│
└─────────────────────────────────────────────────┘
Per 13 Maret 2026, data peringkat publik PinchBench:
- 📊 49 model telah menyelesaikan penilaian, mencakup semua model komersial dan open source utama
- 🔄 327 catatan eksekusi, terus diperbarui
- 🌐 Peringkat publik: pinchbench.com (pembaruan real-time)
- 📁 Repositori open source: github.com/pinchbench/skill (definisi tugas publik)
🎯 Saran Penggunaan PinchBench: Saat melihat peringkat, disarankan untuk beralih antara tiga tampilan: tingkat keberhasilan, kecepatan, dan biaya,
untuk menyaring model yang paling sesuai berdasarkan kebutuhan aktual Anda (respons real-time vs kualitas vs biaya).
Setelah terintegrasi secara terpadu melalui APIYI apiyi.com, Anda dapat dengan mudah membandingkan biaya aktual berbagai model dalam skenario bisnis yang sama.
Empat. Analisis Mendalam Peringkat PinchBench dan Panduan Pemilihan Model
Peringkat Tingkat Keberhasilan Top 5 Saat Ini (Data 13 Maret 2026)
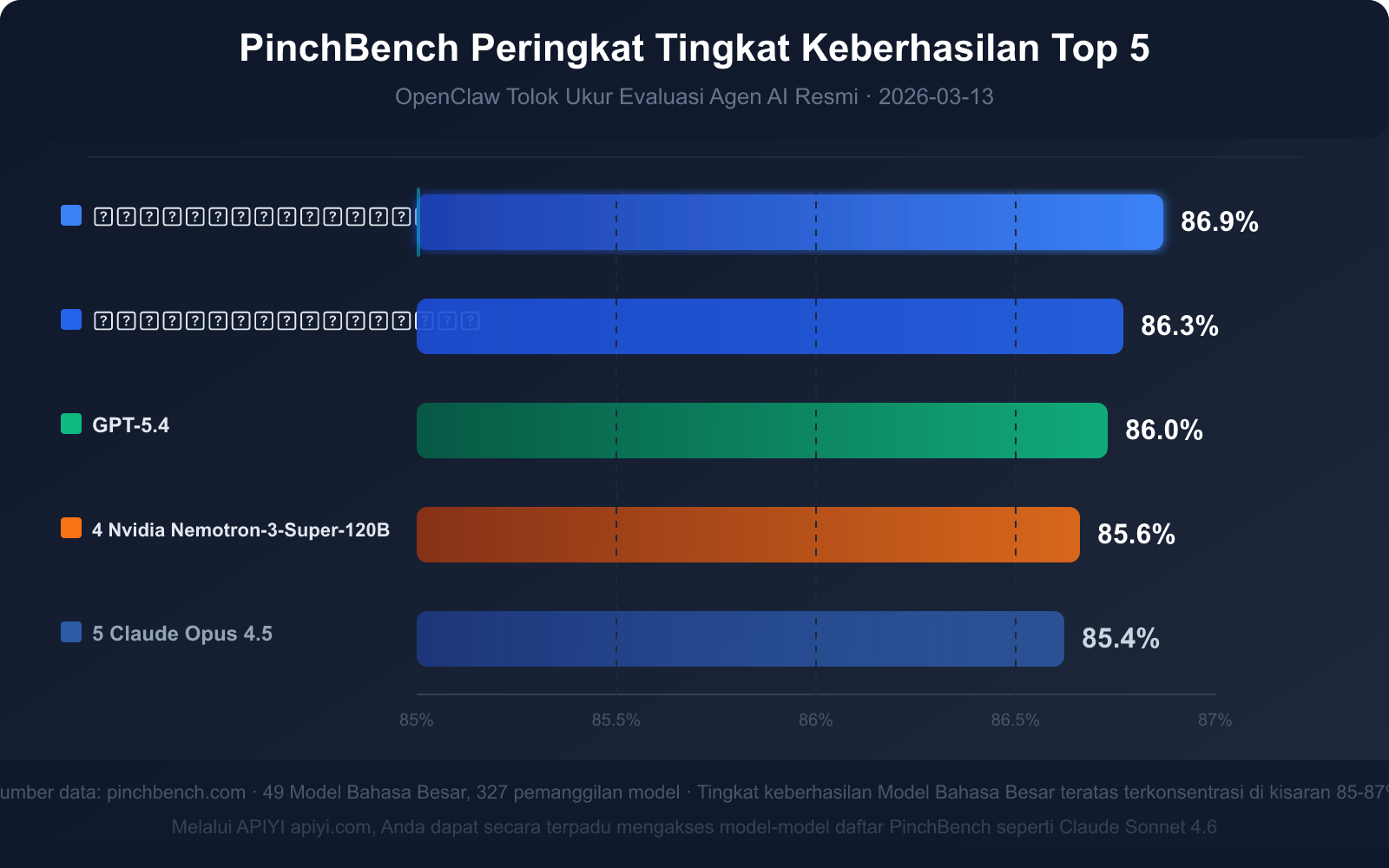
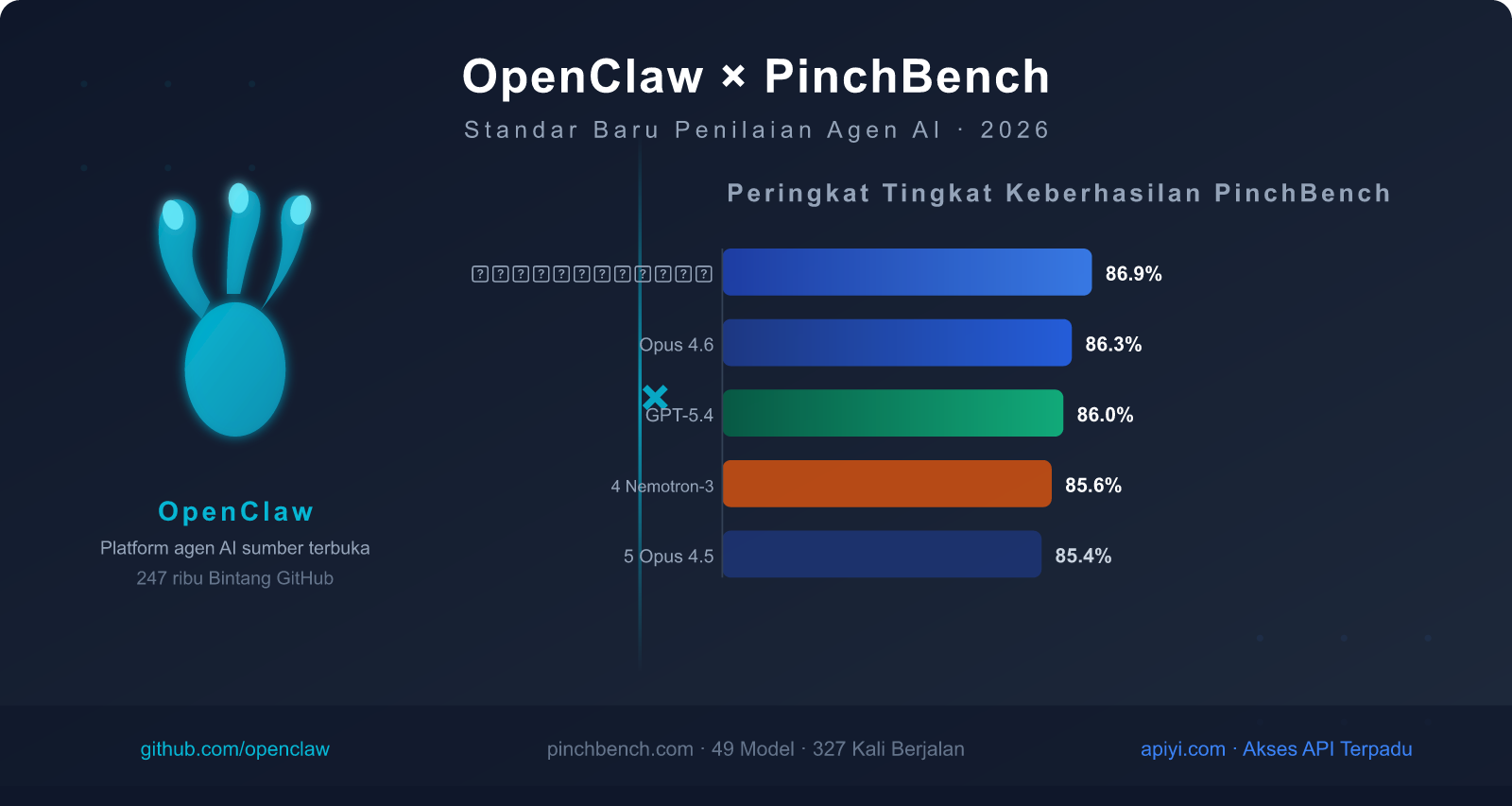
| Peringkat | Nama Model | Tingkat Keberhasilan | Tipe Model | Keunggulan Utama |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Komersial Closed Source | Tingkat keberhasilan tertinggi, keseimbangan kecepatan dan kualitas |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Komersial Closed Source | Kemampuan penalaran kompleks terkuat |
| 🥉 3 | GPT-5.4 | 86.0% | Komersial Closed Source | Stabilitas pemanggilan alat yang baik |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Open Source yang dapat di-deploy | Kinerja terbaik di antara model open source |
| 5 | Claude Opus 4.5 | 85.4% | Komersial Closed Source | Flagship generasi sebelumnya, masih kompetitif |
Wawasan Data Kunci: Apa Arti Tingkat Keberhasilan 85%?
Tingkat keberhasilan model-model teratas di PinchBench terkonsentrasi di kisaran 85%-87%, bukan mendekati skor sempurna. Angka ini sendiri menyampaikan tiga sinyal penting:
Sinyal 1: Tugas AI Agent Masih Merupakan Masalah yang Sangat Menantang Hingga Saat Ini
Bahkan Claude Sonnet 4.6 (86.9%) yang menempati peringkat pertama, masih akan gagal dalam sekitar 13 dari 100 tugas. Ini bukan karena kurangnya kemampuan model, melainkan kompleksitas inheren dari tugas dunia nyata—instruksi yang ambigu, informasi yang tidak lengkap, dan kasus-kasus ekstrem dalam pemanggilan alat, semuanya dapat menyebabkan kegagalan.
Sinyal 2: Desain Toleransi Kesalahan Sangat Penting dalam Pengembangan Agent
Ketika tingkat kegagalan 13% dianggap sebagai "tingkat teratas", alur Agent otomatis penuh tanpa titik tinjauan manusia berisiko tinggi di lingkungan produksi. Praktik terbaik adalah: operasi berisiko tinggi (seperti mengirim email, mengirimkan kode) harus mempertahankan langkah konfirmasi manual.
Sinyal 3: Perbedaan Antar Model Sangat Kecil, Desain Tugas Lebih Penting
Perbedaan antara peringkat 1 dan peringkat 5 hanya 1.5 poin persentase (86.9% vs 85.4%). Ini berarti: dampak pemilihan model mana, jauh lebih kecil daripada bagaimana merancang petunjuk tugas, bagaimana mendefinisikan antarmuka alat, dan bagaimana menangani situasi kesalahan.
Analisis Komprehensif Indikator Tiga Dimensi
Hanya melihat tingkat keberhasilan tidaklah cukup. Berikut adalah kerangka pertimbangan komprehensif dari tiga dimensi:
| Skenario Penggunaan | Indikator Prioritas | Indikator Sekunder | Arah Model yang Direkomendasikan |
|---|---|---|---|
| Tugas Ringan Frekuensi Tinggi (klasifikasi email, pengingat) | Kecepatan + Biaya | Tingkat Keberhasilan | Model ringan seperti Claude Haiku 4.5 |
| Tugas Rekayasa Kompleks (refactoring kode, penelitian) | Tingkat Keberhasilan | Kecepatan | Claude Sonnet 4.6 / GPT-5.4 |
| Skenario Respons Real-time (asisten instan) | Kecepatan | Tingkat Keberhasilan | Model Top Peringkat Kecepatan |
| Aplikasi Sensitif Biaya | Biaya | Tingkat Keberhasilan | Open Source yang di-deploy sendiri / Model API berbiaya rendah |
| Keamanan dan Kepatuhan Perusahaan | Tingkat Keberhasilan + Kontrol | Biaya | Model Open Source yang di-deploy secara privat |
🎯 Saran Pemilihan Model Komprehensif: Berdasarkan data PinchBench, Claude Sonnet 4.6 adalah pilihan komprehensif dengan tingkat keberhasilan tertinggi untuk skenario OpenClaw saat ini.
Untuk skenario frekuensi tinggi yang sensitif biaya, disarankan untuk terlebih dahulu menggunakan Claude Sonnet 4.6 untuk menentukan baseline tingkat keberhasilan tugas,
kemudian menguji apakah model yang lebih ringan dapat secara signifikan mengurangi biaya dalam rentang tingkat keberhasilan yang diizinkan.
Semua pengujian ini dapat diselesaikan melalui antarmuka API terpadu APIYI apiyi.com, tanpa perlu mendaftar akun penyedia layanan yang berbeda.
Analisis Daya Saing Model Open Source
Nvidia Nemotron-3-Super-120B menempati peringkat ke-4 dengan tingkat keberhasilan 85.6%, hanya 1.3 poin persentase lebih rendah dari peringkat pertama—ini adalah pencapaian yang sangat menonjol untuk model open source.
Keunggulan Model Open Source:
- Kedaulatan Data: Model dan data berada dalam lingkungan yang terkontrol sendiri, memenuhi persyaratan kepatuhan
- Struktur Biaya: Investasi GPU satu kali, tanpa biaya pemanggilan API lanjutan (untuk skenario volume tinggi)
- Ruang Kustomisasi: Dapat di-fine-tune untuk tugas-tugas tertentu
Keterbatasan Model Open Source:
- Biaya Deployment: Model dengan 120B parameter memerlukan 4-8 GPU A100/H100
- Beban Pemeliharaan: Pembaruan model, manajemen versi memerlukan operasi dan pemeliharaan khusus
- Biaya Pengujian Awal: Sebelum memastikan model open source sesuai untuk skenario Anda, validasi prototipe melalui API komersial seringkali lebih ekonomis
V. Panduan Praktis: Cara Mengonfigurasi Model Terbaik di OpenClaw
Integrasi Cepat Claude Sonnet 4.6 untuk Menggerakkan OpenClaw
Berikut adalah contoh konfigurasi lengkap untuk mengintegrasikan model peringkat pertama PinchBench melalui APIYI:
Langkah 1: Dapatkan kunci API
Kunjungi situs web resmi APIYI apiyi.com untuk mendaftar akun, lalu masuk ke konsol untuk mendapatkan Kunci API. APIYI menyediakan antarmuka yang kompatibel dengan OpenAI, sekaligus mendukung SDK asli Anthropic.
Langkah 2: Konfigurasi backend model OpenClaw
# Contoh file konfigurasi OpenClaw (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Jumlah langkah eksekusi maksimum
tool_timeout: 30 # Batas waktu pemanggilan alat tunggal (detik)
retry_on_error: true # Otomatis coba lagi jika pemanggilan alat gagal
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # Operasi berisiko tinggi memerlukan konfirmasi manual
Langkah 3: Verifikasi efek konfigurasi
# Uji koneksi menggunakan Anthropic SDK
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Kirim permintaan pengujian
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "Sebutkan 3 jenis tugas yang bisa kamu lakukan di OpenClaw"
}]
)
print(response.content[0].text)
Langkah 4: Konfigurasi pengujian A/B multi-model
# Bandingkan model yang berbeda pada tugas yang sama (disarankan sebelum deployment resmi)
models_to_test = [
"claude-sonnet-4-6", # Peringkat pertama di PinchBench
"gpt-5.4-turbo", # Peringkat ketiga di PinchBench (kompatibel dengan format OpenAI)
"claude-opus-4-5", # Flagship generasi sebelumnya, perbandingan referensi biaya
]
# APIYI mendukung pemanggilan antarmuka terpadu untuk semua model di atas
# base_url tetap, cukup ubah parameter model
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: Tingkat keberhasilan={result.success_rate}, Waktu={result.avg_time}s, Biaya=${result.cost_per_task}")
🎯 Mulai Cepat: Kunjungi APIYI apiyi.com dan daftar untuk mendapatkan kuota pengujian. Mendukung akses API terpadu untuk model-model teratas PinchBench seperti Claude Sonnet 4.6, GPT-5.4, dan lainnya. Tidak perlu mengajukan izin akses dari berbagai penyedia layanan secara terpisah, sehingga sangat mengurangi hambatan awal untuk pengujian model.
Uji Mandiri Agent Anda dengan 5 Dimensi PinchBench
Sebelum deployment ke lingkungan produksi, disarankan untuk mengevaluasi konfigurasi Agent Anda menggunakan daftar uji mandiri berikut:
Daftar Uji Mandiri Agent yang Terinspirasi PinchBench
□ Dimensi 1 - Tingkat Penyelesaian Tugas
Berikan Agent 10 tugas kompleks yang terdiri dari 3 langkah atau lebih
Catat jumlah yang berhasil sepenuhnya / berhasil sebagian / gagal
Target: Tingkat keberhasilan penuh ≥ 80%
□ Dimensi 2 - Akurasi Pemanggilan Alat
Periksa log pemanggilan alat, dan hitung jenis kesalahan berikut:
- Kesalahan pemilihan alat (memilih alat yang salah)
- Kesalahan format parameter (tipe atau format parameter tidak sesuai)
- Kesalahan nilai parameter (tipe parameter benar tetapi nilai tidak masuk akal)
Target: Tingkat kesalahan alat ≤ 5%
□ Dimensi 3 - Koherensi Penalaran Multi-Langkah
Rancang tugas alur panjang yang membutuhkan lebih dari 15 langkah
Amati apakah terjadi penyimpangan tujuan di tengah jalan (melupakan tujuan awal)
Target: Tugas alur panjang tanpa penyimpangan tujuan
□ Dimensi 4 - Retensi Konteks
Berikan informasi kunci pada putaran ke-1, lalu referensikan informasi tersebut pada putaran ke-8
Periksa apakah Agent dapat mereferensikan dengan benar
Target: Tingkat akurasi referensi lintas putaran ≥ 90%
□ Dimensi 5 - Deteksi Halusinasi
Rancang tugas yang memerlukan referensi data nyata (nama file/kontak/tanggal)
Periksa apakah Agent mengarang data yang tidak ada
Target: Tingkat kejadian halusinasi ≤ 2%
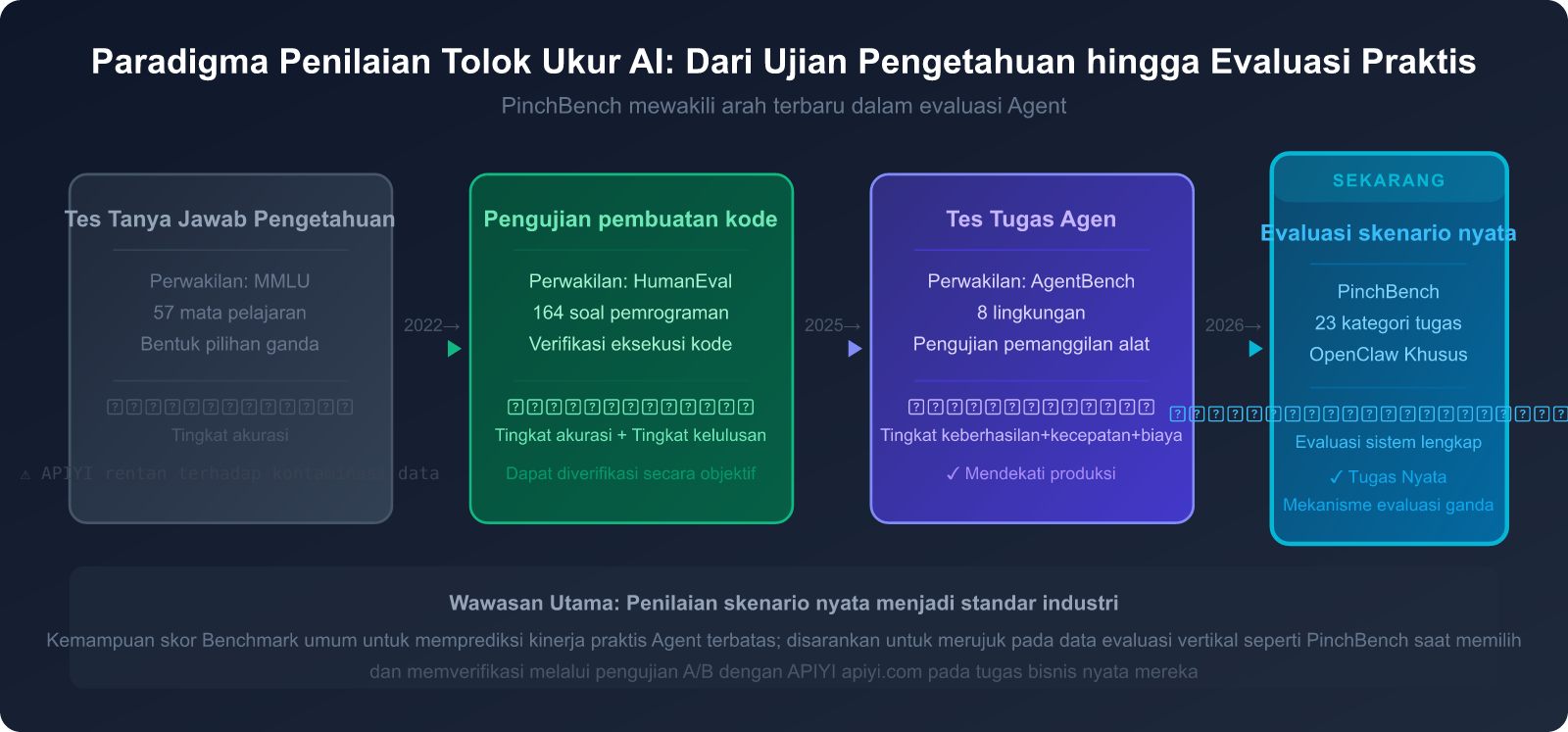
VI. Masa Depan AI Benchmark: Dari Evaluasi Titik Tunggal ke Penilaian Ekosistem
Tren Evolusi Sistem Benchmark Saat Ini
Pada tahun 2026, bidang AI Benchmark sedang mengalami transformasi mendalam. Inti dari transformasi ini adalah perluasan objek evaluasi dari model tunggal menjadi sistem Agent yang lengkap.
Cara berpikir Benchmark tradisional adalah: memberikan pertanyaan kepada model dan melihat apakah jawabannya benar. Namun, setelah platform Agent seperti OpenClaw menjadi populer, pertanyaan yang benar-benar penting menjadi: Ketika model bertindak sebagai "otak" suatu sistem, bisakah ia membuat sistem tersebut menyelesaikan pekerjaannya?
Jawaban atas pertanyaan ini tidak hanya bergantung pada cadangan pengetahuan model, tetapi juga pada:
- Kemampuan model untuk memahami deskripsi alat
- Strategi pengambilan keputusan model di bawah informasi yang tidak pasti
- Kemampuan model untuk mengidentifikasi dan memulihkan dari kesalahan
- Kemampuan model untuk melacak niat pengguna dalam jangka panjang
Nilai PinchBench terletak pada kemampuannya untuk mengukur dan menampilkan dimensi-dimensi ini secara publik.
Cara Tepat Menggunakan Data AI Benchmark
Data Benchmark memang berharga, tetapi juga sangat mudah disalahgunakan. Berikut adalah beberapa kesalahpahaman umum dan praktik yang benar:
Kesalahpahaman 1: Menganggap model dengan peringkat tertinggi "pasti yang terbaik"
Praktik yang benar: Peringkat didasarkan pada set tugas spesifik PinchBench, dan tugas Anda mungkin memiliki distribusi bobot yang berbeda. Uji dulu pada tugas Anda sendiri, baru kemudian pilih model.
Kesalahpahaman 2: Hanya melihat tingkat keberhasilan, mengabaikan kecepatan dan biaya
Praktik yang benar: Tiga dimensi metrik ini tidak bisa dipisahkan. Dalam skenario pemrosesan batch, perbedaan kecepatan 50% berarti penghematan biaya 50%; dalam skenario respons real-time, perbedaan kecepatan 2 detik berarti penurunan signifikan dalam pengalaman pengguna.
Kesalahpahaman 3: Menganggap perbedaan tingkat keberhasilan 1% tidak penting
Praktik yang benar: Perbedaan tingkat keberhasilan 1% mungkin terlihat sepele dalam pengujian skala kecil, tetapi dalam skenario produksi frekuensi tinggi, ini bisa berarti ratusan kegagalan setiap hari. Anda perlu mengevaluasi dampak sebenarnya dengan mempertimbangkan skala tugas Anda.
Kesalahpahaman 4: Menggunakan data Benchmark statis untuk perencanaan jangka panjang
Praktik yang benar: Model AI beriterasi dengan sangat cepat, dengan rata-rata pembaruan penting setiap kuartal dari vendor utama pada tahun 2026. Disarankan untuk memasukkan evaluasi kinerja model ke dalam tinjauan teknis rutin, bukan "sekali pilih untuk selamanya".
Praktik Terbaik Evaluasi Agent Tingkat Perusahaan
Untuk tim teknis yang menerapkan OpenClaw atau platform Agent serupa di perusahaan, berikut adalah serangkaian praktik terbaik evaluasi yang dapat diterapkan:
Langkah Pertama: Buat Set Tugas Baseline
Pilih 20-50 tugas tipikal dari bisnis Anda yang sebenarnya, mencakup operasi frekuensi tinggi harian dan skenario kompleks yang sesekali terjadi. Set tugas ini harus didefinisikan bersama oleh pihak bisnis dan teknis untuk menghindari bias evaluasi yang disebabkan oleh perspektif teknis murni.
Langkah Kedua: Pelacakan Metrik Tiga Dimensi Berkelanjutan
Saran Sistem Metrik Evaluasi Agent Internal Perusahaan
Metrik Inti (Statistik Mingguan):
- Tingkat penyelesaian tugas: Target ≥ 85% (setara dengan standar model top PinchBench)
- Tingkat kesalahan pemanggilan alat: Target ≤ 5%
- Waktu rata-rata tugas: Didefinisikan berdasarkan SLA bisnis
Metrik Pendukung (Statistik Bulanan):
- Biaya Token/tugas: Mengontrol biaya operasional
- Tingkat intervensi manual: Persentase tugas yang memerlukan intervensi manual
- Distribusi jenis kesalahan: Menganalisis arah perbaikan
Metrik Peringatan (Pemantauan Real-time):
- Tingkat kegagalan operasi berisiko tinggi: Kegagalan seperti mengirim email/menghapus file segera memicu peringatan
- Insiden halusinasi: Situasi pemalsuan informasi perlu segera dicatat dan dianalisis
Langkah Ketiga: Evaluasi Ulang Model Secara Berkala
Disarankan untuk mengevaluasi ulang model yang sedang digunakan dan model kandidat yang baru dirilis setiap kuartal menggunakan set tugas internal. Gabungkan dengan data publik terbaru dari PinchBench untuk menentukan apakah perlu meningkatkan atau mengganti model.
Langkah Keempat: Akumulasi Pengetahuan Domain
Benchmark umum tidak dapat mencakup skenario khusus setiap perusahaan. Dengan akumulasi penggunaan, secara bertahap bangun set tugas dan standar penilaian yang sesuai dengan bisnis Anda, ini akan menjadi alat penyaringan penting untuk memilih penyedia AI.
🎯 Saran Pemilihan untuk Perusahaan: Pada tahap awal pengenalan platform Agent, disarankan untuk mengintegrasikan beberapa model kandidat melalui APIYI apiyi.com dengan pembayaran sesuai penggunaan. Lakukan pengujian aktual selama 3-4 minggu dengan set tugas internal Anda sebelum memutuskan apakah akan beralih ke paket bulanan. APIYI mendukung antarmuka terpadu untuk model-model utama seperti Claude, GPT, Gemini, sehingga pada tahap pengujian tidak perlu mendaftar akun penyedia layanan yang berbeda, yang secara signifikan mengurangi biaya pengelolaan evaluasi.
Pertanyaan yang Sering Diajukan
T: Apa perbedaan utama antara OpenClaw dengan AutoGPT dan AutoGen?
Perbedaan inti OpenClaw terletak pada cara akses dan hambatan penggunaannya: OpenClaw menyediakan antarmuka Agent melalui aplikasi pesan (seperti Signal, WhatsApp), sehingga pengguna biasa tidak perlu menginstal aplikasi khusus atau memahami detail teknis. Dari perspektif arsitektur teknis, OpenClaw lebih mirip "sekretaris AI pribadi", sementara kerangka kerja seperti AutoGen lebih cocok untuk pengembang yang ingin membangun sistem multi-Agent yang kompleks. OpenClaw menekankan "pengalaman konsumen yang siap pakai", sedangkan AutoGen menekankan "kerangka kerja pengembangan tingkat perusahaan yang fleksibel".
🎯 Apa pun kerangka kerja Agent yang Anda pilih, Anda bisa mengintegrasikan model backend secara terpadu melalui APIYI apiyi.com, menghindari konfigurasi kunci API terpisah untuk setiap kerangka kerja.
T: Seberapa sering peringkat tingkat keberhasilan PinchBench diperbarui?
Peringkat PinchBench diperbarui secara real-time—setiap kali ada model baru yang selesai dievaluasi, data akan langsung tercermin di pinchbench.com. Karena produsen besar terus merilis versi baru, peringkat akan sering berubah. Disarankan untuk memeriksa data terbaru sebelum membuat pilihan resmi. Data dalam artikel ini didasarkan pada snapshot tanggal 13 Maret 2026 (49 model, 327 catatan eksekusi).
T: Bagaimana cara memilih model yang paling sesuai untuk OpenClaw?
Kami merekomendasikan metode pemilihan tiga langkah:
- Lihat tingkat keberhasilan PinchBench: Saring 5 teratas berdasarkan tingkat penyelesaian tugas.
- Lihat dimensi kecepatan dan biaya: Saring lagi berdasarkan jenis tugas Anda (real-time vs. batch processing, frekuensi tinggi vs. frekuensi rendah).
- Uji A/B secara aktual: Bandingkan 2-3 model kandidat pada tugas bisnis Anda yang sebenarnya.
Melalui APIYI apiyi.com, Anda dapat dengan cepat beralih antar model yang berbeda menggunakan
base_urlyang sama, lalu membuat keputusan akhir setelah menyelesaikan uji A/B.
T: Bisakah model open source sepenuhnya menggantikan model komersial untuk menggerakkan OpenClaw?
Berdasarkan data PinchBench, Nvidia Nemotron-3-Super-120B (85.6%) memiliki perbedaan sekitar 1.3 poin persentase dengan model komersial teratas (86.9%). Untuk tugas Agent umum, perbedaan ini dapat diterima. Namun, perlu diperhatikan: penerapan mandiri model dengan 120B parameter membutuhkan 4-8 GPU kelas atas, dengan investasi perangkat keras awal dan biaya operasional yang tidak sedikit. Disarankan untuk memvalidasi kelayakan desain Agent menggunakan API komersial terlebih dahulu, baru kemudian mengevaluasi apakah layak untuk bermigrasi ke model open source yang diterapkan secara mandiri.
T: Bagaimana cara menghindari risiko keamanan OpenClaw?
Prinsip intinya adalah privilese minimal: hanya berikan OpenClaw cakupan izin minimum yang diperlukan untuk menyelesaikan tugas. Saran spesifik:
- Izin baca-saja untuk email (bukan izin baca, tulis, hapus penuh)
- Izin baca-saja + membuat PR untuk repositori kode (bukan langsung push ke cabang utama)
- Sistem file terbatas pada direktori kerja tertentu (bukan seluruh sistem file)
- Operasi berisiko tinggi (mengirim email, menghapus file) harus menyertakan langkah konfirmasi manual
Saat penerapan di perusahaan, log audit operasi yang lengkap juga perlu dikonfigurasi untuk memastikan setiap operasi Agent memiliki catatan yang dapat dilacak.
T: Apa perbedaan antara PinchBench dan benchmark Agent lainnya?
Fitur terbesar PinchBench adalah spesifisitas skenario: ia dirancang khusus untuk skenario penggunaan OpenClaw, bukan untuk evaluasi Agent umum. Ini berarti nilai referensinya lebih tinggi bagi pengguna OpenClaw, tetapi tidak cocok untuk langsung digunakan mengevaluasi pilihan model untuk kerangka kerja Agent lainnya. Benchmark Agent terkenal lainnya termasuk AgentBench (mencakup berbagai lingkungan), SWE-Bench (berfokus pada tugas kode), dan lain-lain, masing-masing memiliki fokusnya sendiri.
Ringkasan: OpenClaw + PinchBench Menetapkan Standar Baru untuk Era Agent
OpenClaw, yang dimulai sebagai proyek akhir pekan oleh seorang pengembang Austria, telah berkembang menjadi platform intelligent agent AI paling populer di dunia dalam dua bulan. Ini mencerminkan keinginan kuat seluruh industri agar "AI benar-benar melakukan sesuatu".
Sementara itu, kemunculan PinchBench mengisi kekosongan penting dalam bidang evaluasi Agent: kita akhirnya memiliki alat ukur yang khusus untuk mengukur kemampuan Agent.
Sekilas Kesimpulan Utama:
- Claude Sonnet 4.6 adalah pilihan optimal secara keseluruhan untuk skenario OpenClaw saat ini (tingkat keberhasilan 86.9%, peringkat pertama di PinchBench)
- Tingkat keberhasilan model teratas berkisar antara 85-87%, tugas Agent masih menantang, dan desain toleransi kesalahan sangat diperlukan.
- Kecepatan dan biaya sama pentingnya, model dengan tingkat keberhasilan tinggi belum tentu cocok untuk semua skenario, diperlukan evaluasi komprehensif tiga dimensi.
- PinchBench mewakili arah masa depan evaluasi AI: tugas skenario nyata menggantikan pengujian sintetis.
- Perbedaan dalam pemilihan model sekitar 1-2%, desain tugas dan prompt engineering seringkali memiliki dampak yang lebih besar.
Bagi pengembang dan perusahaan yang ingin mendalami ekosistem OpenClaw, sekarang adalah waktu yang tepat:
Komunitas open source aktif, alat evaluasi lengkap, dan biaya akses API untuk model-model utama juga terus menurun. Anda tidak perlu menunggu "solusi sempurna" muncul; Anda bisa mulai memvalidasi kelayakan alur kerja Agent dengan tugas berskala kecil sekarang.
🎯 Bertindak Sekarang: Jika Anda sedang membangun alur kerja AI berbasis OpenClaw, direkomendasikan untuk mengintegrasikannya secara terpadu melalui APIYI apiyi.com.
Platform ini mendukung model-model utama seperti Claude Sonnet 4.6 (peringkat pertama di PinchBench) dan GPT-5.4 (peringkat ketiga).
Dengan satu set antarmuka API yang sama, Anda tidak perlu mendaftar ke beberapa penyedia layanan secara terpisah, mendukung pembayaran sesuai penggunaan, dan cocok untuk memulai dengan pengujian skala kecil sebelum memperluas secara bertahap.
Kunjungi situs web resmi APIYI di apiyi.com untuk mendaftar dan mulai mencoba.
Data dalam artikel ini dikumpulkan berdasarkan informasi publik per Maret 2026. Untuk data real-time peringkat PinchBench, silakan kunjungi pinchbench.com untuk melihat versi terbaru.
Penulis: Tim APIYI | Untuk informasi lebih lanjut tentang integrasi API model AI, silakan kunjungi APIYI di apiyi.com.