En 2026, un desarrollador independiente austriaco creó un proyecto de código abierto en su tiempo libre de fin de semana que, en dos meses, obtuvo 247.000 estrellas en GitHub, convirtiéndose en una plataforma de agentes de IA que empresas de Silicon Valley y China se apresuraron a implementar.
Este proyecto se llama OpenClaw.
Al mismo tiempo, surgió una pregunta: En escenarios reales de agentes como OpenClaw, ¿qué modelo de IA ofrece el mejor rendimiento?
Esto es precisamente lo que PinchBench busca resolver. Es la evaluación comparativa oficial de OpenClaw, desarrollada por el equipo de kilo.ai usando Rust, que reemplaza las pruebas sintéticas con tareas reales para ofrecer a los desarrolladores una base fiable para la selección de modelos.
Este artículo parte de la historia del ascenso de OpenClaw, analiza en profundidad el sistema de evaluación de PinchBench para ayudarte a comprender el verdadero significado de un benchmark de IA y cómo seleccionar el modelo adecuado para tu flujo de trabajo de agente basándote en los datos de evaluación.
I. ¿Qué es OpenClaw? Un fenómeno de código abierto que cambió de nombre 3 veces en un mes
El nacimiento de OpenClaw y la controversia del nombre
La historia de OpenClaw comienza en noviembre de 2025.
El desarrollador austriaco Peter Steinberger dedicó su tiempo libre a construir una plataforma de agentes de IA, inicialmente llamada Clawdbot. La idea central de este proyecto era simple: hacer que la IA no fuera solo una herramienta de chat, sino que realmente pudiera hacerse cargo de tu flujo de trabajo digital: leer correos, escribir código, gestionar calendarios, buscar información.
Pero el concepto de Agente de IA no es nuevo, ¿por qué OpenClaw explotó de la noche a la mañana?
La clave fue la doble bendición del momento oportuno y el código abierto. A finales de enero de 2026, con la difusión viral del proyecto Moltbook, el deseo de "que la IA realmente haga cosas" alcanzó su punto máximo en todo el círculo tecnológico, y Clawdbot aprovechó la ola para convertirse en el centro de atención.
Sin embargo, pronto recibió una notificación de objeción de marca registrada de Anthropic: se consideró que "Clawd" en Clawdbot presentaba un riesgo de confusión con un nombre de producto interno de Anthropic. El proyecto se vio obligado a cambiar urgentemente su nombre a Moltbot el 27 de enero de 2026, en homenaje al proyecto Moltbook, que también se había vuelto viral en ese momento.
Pero tres días después, Steinberger confesó en GitHub que el nuevo nombre "nunca sonó del todo bien" ("never quite rolled off the tongue"), y el proyecto fue renombrado nuevamente como OpenClaw, nombre que conserva hasta hoy.
Esta controversia sobre el nombre, en cambio, se convirtió en la mejor "marketing gratuito" para el proyecto, haciendo que OpenClaw fuera ampliamente conocido en la comunidad de desarrolladores.
Hasta el 2 de marzo de 2026, OpenClaw había acumulado en GitHub:
- ⭐ 247 mil estrellas (casi la mitad de las estrellas del framework React en el mismo período)
- 🍴 47.7 mil forks
- 🌍 Despliegue a gran escala en empresas de Silicon Valley, Europa y China.
Arquitectura tecnológica central de OpenClaw
La filosofía de diseño de OpenClaw es: ejecución local, agnóstico al modelo, integración con aplicaciones de mensajería.
Estas tres características determinan su diferencia fundamental con otros frameworks de Agentes de IA.
Ejecución local significa que tus datos no pasan por ningún servidor de terceros. A diferencia de la mayoría de los asistentes de IA en formato SaaS, OpenClaw se despliega en el propio dispositivo del usuario, y la invocación del modelo de API también puede apuntar a puntos finales privados.
Agnóstico al modelo significa que OpenClaw en sí mismo no está vinculado a ningún Modelo de Lenguaje Grande. Es una "carcasa cerebral" que admite la conexión a cualquier modelo principal como Claude, GPT, DeepSeek, etc. Los desarrolladores pueden cambiar libremente según el tipo de tarea y el presupuesto de costos.
La integración con aplicaciones de mensajería es el diseño más distintivo de OpenClaw: los usuarios comunes no necesitan abrir ninguna aplicación dedicada, pueden invocar las capacidades del Agente de IA directamente enviando mensajes en Signal, Telegram, Discord o WhatsApp. Esto reduce en gran medida la barrera de uso, permitiendo que usuarios no técnicos también se beneficien.
| Dimensión de diseño | Elección de OpenClaw | Alternativas principales | Explicación de la diferencia |
|---|---|---|---|
| Ubicación de despliegue | Ejecución local | SaaS en la nube | Mayor privacidad de datos, pero requiere mantenimiento propio |
| Vinculación de modelo | Completamente agnóstico | Vinculado a un modelo específico | Cambio flexible, pero requiere configuración propia |
| Interfaz de usuario | Aplicaciones de mensajería | Web/App dedicada | Baja barrera de entrada, funcionalidad limitada por la aplicación de mensajería |
| Alcance de permisos | Acceso amplio | Restricciones de sandbox | Funcionalidad potente, pero mayor riesgo de seguridad |
| Licencia de código abierto | Completamente de código abierto | Código cerrado/parcialmente abierto | Impulsado por la comunidad, pero soporte limitado |
🎯 Sugerencia de uso: Para desplegar OpenClaw, necesitas configurar un backend de Modelo de Lenguaje Grande de alta calidad.
Recomendamos conectar Claude Sonnet 4.6 o GPT-5.4 a través de APIYI (apiyi.com).
Ambos modelos han demostrado un rendimiento excelente en PinchBench, y APIYI admite el cambio de interfaz unificada,
lo que facilita la comparación rápida de los efectos de diferentes modelos sin modificar la configuración central de OpenClaw.
Límites de capacidad de OpenClaw
El rango de capacidades que admite OpenClaw es bastante amplio, pero precisamente por eso ha generado controversia en materia de seguridad:
Fuentes de datos accesibles:
- Cuentas de correo electrónico (leer, clasificar, redactar respuestas)
- Sistemas de calendario (ver, crear, modificar eventos)
- Sistemas de archivos (navegar, leer, crear, mover archivos)
- Repositorios de código (leer código, ejecutar pruebas, enviar cambios)
- Plataformas de mensajería (agregación y respuesta de mensajes multiplataforma)
- Información web (buscar, resumir, extracción estructurada)
Escenarios de uso típicos:
El usuario envía en Telegram: "Ayúdame a organizar los correos de hoy,
marca los que necesitan respuesta hoy y redacta las respuestas."
Flujo de ejecución del Agente OpenClaw:
1. Llama a la herramienta de correo, lee los correos no leídos de hoy.
2. Usa el Modelo de Lenguaje Grande para determinar la urgencia de cada correo.
3. Filtra la lista de correos que necesitan respuesta hoy.
4. Genera un borrador de respuesta para cada correo.
5. Devuelve el resultado organizado y la vista previa del borrador en Telegram.
Esta capacidad de "realmente terminar las cosas" es la diferencia esencial entre OpenClaw y un simple chatbot.
Steinberger se une a OpenAI y el futuro del proyecto
El 14 de febrero de 2026, una noticia sacudió a toda la comunidad de código abierto: Steinberger anunció en GitHub que se uniría a OpenAI, y el proyecto sería transferido a una fundación de código abierto independiente.
Esto tuvo un doble impacto en OpenClaw: por un lado, el proyecto obtuvo una operación y protección legal más profesionales; por otro lado, el mundo exterior comenzó a especular sobre el motivo detrás de la adquisición de este fundador por parte de OpenAI, ¿fue para absorber tecnología o para prevenir un posible competidor?
Actualmente, la Fundación OpenClaw ha sido establecida, y el proyecto sigue siendo completamente de código abierto, pero la priorización de la hoja de ruta de desarrollo es notablemente diferente: las funciones de seguridad de nivel empresarial y el sistema de control de permisos se han convertido en el foco de la próxima versión.
Controversia de seguridad: Riesgos de una capacidad potente
La amplia necesidad de permisos del sistema por parte de OpenClaw generó preocupación entre los investigadores de ciberseguridad desde el principio.
En marzo de 2026, las autoridades chinas anunciaron restricciones para que las empresas estatales y las agencias gubernamentales ejecutaran OpenClaw en computadoras de oficina, principalmente debido a preocupaciones como:
- Los datos podrían filtrarse a proveedores de servicios extranjeros a través de la invocación del modelo de API.
- Los permisos amplios, si no se configuran correctamente, podrían convertirse en un punto de entrada para ataques.
- La información sensible interna de la empresa podría ser transmitida entre sistemas por el Agente.
Este incidente recuerda a todos los desarrolladores empresariales: al introducir herramientas de Agente potentes, los principios de mínimos privilegios y los registros de auditoría son bases de seguridad ineludibles.
II. El verdadero papel de los Benchmarks en la industria de la IA: del examen a la práctica
Por qué la industria de la IA no puede prescindir de los Benchmarks
Si alguna vez has intentado comparar las capacidades de dos modelos de IA, es probable que te hayas encontrado con un dilema: los fabricantes dicen que su modelo es el "más potente", pero ¿qué significa "potente"? ¿En qué tareas? ¿En comparación con qué línea base?
Un Benchmark (referencia de evaluación) es un sistema de prueba estandarizado creado para resolver este problema.
En la industria de la IA, un buen Benchmark debe cumplir tres condiciones:
- Repetibilidad: Cualquiera que use el mismo conjunto de pruebas debe obtener los mismos resultados.
- Representatividad: El contenido de la prueba debe reflejar las necesidades de capacidad de los escenarios de uso reales.
- Imparcialidad: El conjunto de pruebas no debe estar contaminado por los datos de entrenamiento del desarrollador del modelo.
En 2026, más de 15 Benchmarks principales están en uso activo en toda la industria, pero se estima que solo unos 4 pueden predecir el rendimiento en un entorno de producción.
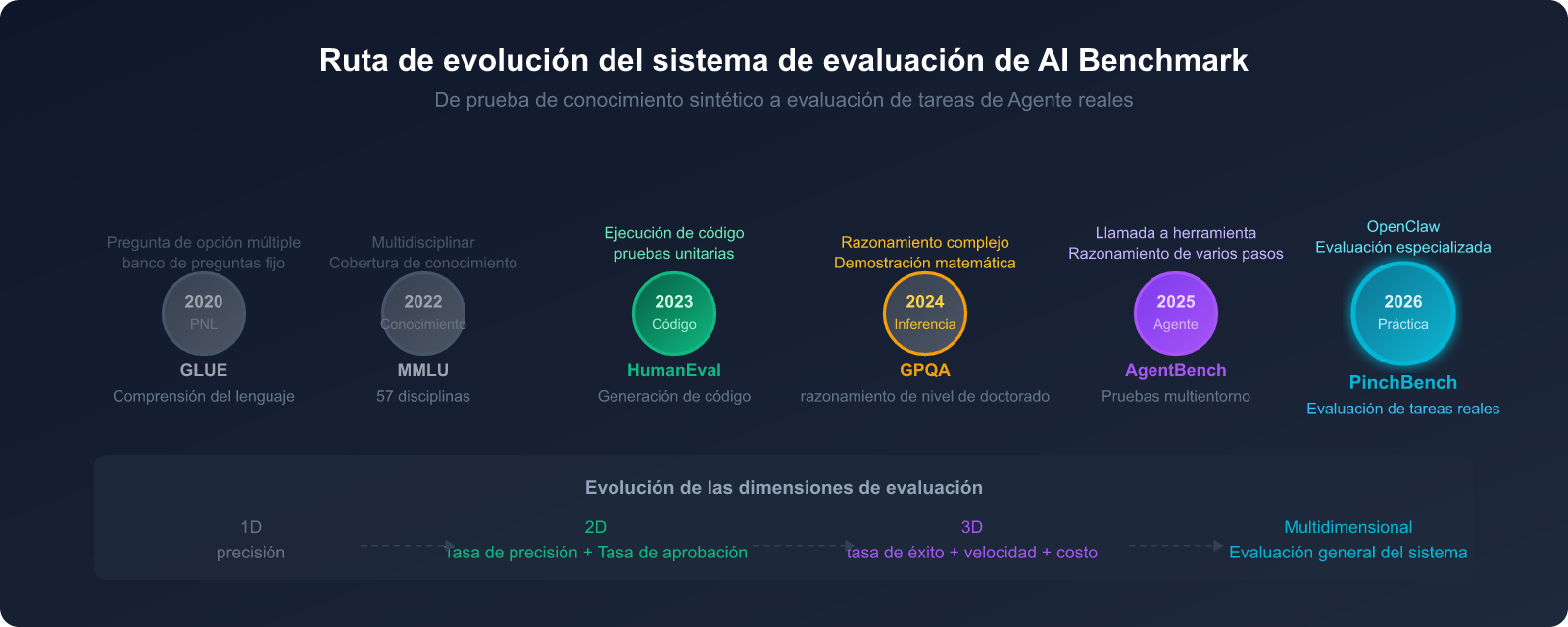
Limitaciones de los Benchmarks tradicionales
Para entender el valor de PinchBench, primero hay que comprender por qué los Benchmarks tradicionales "no son suficientes".
MMLU (Massive Multitask Language Understanding)
MMLU es la evaluación de conocimiento general más citada actualmente, cubriendo 57 disciplinas con aproximadamente 14,000 preguntas de opción múltiple. Las preguntas abarcan campos como medicina, derecho, historia, matemáticas y programación.
El problema es que son preguntas de opción múltiple, donde el modelo solo necesita elegir una de las 4 opciones. En un escenario real de Agente, el modelo necesita generar respuestas de forma autónoma, e incluso invocar herramientas para obtener información, lo cual es completamente diferente a "elegir una de 4 opciones".
HumanEval (Prueba de generación de código)
HumanEval es un Benchmark emblemático para medir la capacidad de generación de código, que contiene 164 problemas de programación en Python. Sin embargo, sus problemas son relativamente fijos, y los modelos pueden haber encontrado tipos de problemas similares durante el entrenamiento, lo que lleva a un "efecto de memorización": una puntuación alta no siempre representa una capacidad de programación real.
Problemas comunes de las pruebas sintéticas:
| Tipo de problema | Manifestación específica | Impacto en los resultados de la evaluación |
|---|---|---|
| Contaminación de datos | El conjunto de entrenamiento incluye preguntas de prueba | Una puntuación alta no representa una verdadera capacidad de generalización |
| Efecto de memorización | El modelo está optimizado para un Benchmark específico | Clasificación inflada, la capacidad real no mejora |
| Desconexión del escenario | Las preguntas de opción múltiple difieren mucho del uso real | Baja capacidad de predicción de la clasificación |
| Conjunto de datos estático | Las preguntas son fijas, no se pueden actualizar | Las nuevas capacidades no pueden ser evaluadas |
| Evaluación unidimensional | Solo se considera la precisión | Ignora la velocidad, el costo y la fiabilidad |
5 dimensiones clave para la evaluación de Agentes de IA
Cuando los sistemas de IA evolucionan de "responder preguntas" a "completar tareas", el sistema de evaluación también debe actualizarse.
Para plataformas de agentes de IA como OpenClaw, la evaluación debe cubrir las siguientes 5 dimensiones clave:
Dimensión 1: Tasa de finalización de tareas (Task Completion Rate)
La proporción general de éxito desde la recepción de la tarea hasta su finalización. Este es el indicador más intuitivo, pero también el más complejo: la definición misma de "finalización" es el desafío central del diseño de la evaluación.
Método de prueba: Asignar al Agente una tarea compuesta de 3 a 5 pasos y registrar la proporción de éxito total, éxito parcial y fracaso.
Dimensión 2: Precisión de invocación de herramientas (Tool Call Accuracy)
El Agente necesita seleccionar la herramienta correcta entre docenas de herramientas disponibles y llamarla con los parámetros adecuados. Una invocación de herramienta incorrecta no solo es un fallo, sino que también puede tener efectos secundarios (como eliminar archivos por error o enviar correos electrónicos incorrectos).
Método de prueba: Diseñar tareas que requieran una secuencia específica de herramientas y registrar la tasa de error en la selección de herramientas y en los parámetros.
Dimensión 3: Coherencia del razonamiento en múltiples pasos (Multi-step Reasoning Coherence)
Completar una tarea a menudo requiere de 5 a 10 pasos. El Agente necesita mantener una comprensión clara del objetivo durante todo el proceso, sin "perder el rumbo" a mitad de camino.
Método de prueba: Diseñar tareas de flujo largo que requieran más de 10 pasos y observar si hay desviación del objetivo o ruptura lógica en el medio.
Dimensión 4: Retención de contexto entre turnos (Cross-turn Context Retention)
En una conversación de múltiples turnos, el Agente necesita recordar la información intercambiada previamente. Información como "la última vez dijiste que la reunión sería el miércoles" es crucial en el flujo de trabajo de OpenClaw.
Método de prueba: Diseñar escenarios de tareas que requieran citar información de más de 5 turnos anteriores y registrar la tasa de pérdida de la ventana de contexto.
Dimensión 5: Frecuencia de alucinaciones (Hallucination Rate)
Que el Agente invente archivos inexistentes, contactos inexistentes o fechas incorrectas, son problemas menores en un chat, pero en un escenario de Agente pueden causar pérdidas reales (como enviar correos electrónicos con contenido incorrecto).
Método de prueba: Diseñar tareas que requieran citar datos reales (nombres de archivo, direcciones de correo electrónico, fechas) y registrar la frecuencia de aparición de alucinaciones.
🎯 Sugerencia para desarrolladores: Al elegir un modelo de Agente, la tasa de finalización de tareas y la precisión de invocación de herramientas son los dos indicadores más importantes.
Se recomienda utilizar la plataforma APIYI (apiyi.com) para conectar rápidamente varios modelos y verificar su rendimiento en tus tareas reales utilizando las 5 dimensiones anteriores,
en lugar de depender únicamente de los números de las clasificaciones. APIYI admite la facturación por uso, lo que es adecuado para realizar pruebas A/B a pequeña escala antes de la selección final.
Tres. Análisis en profundidad de PinchBench: El estándar oficial de evaluación de OpenClaw
El contexto del nacimiento de PinchBench
PinchBench, desarrollado por el equipo de kilo.ai utilizando Rust, es un benchmark de evaluación diseñado específicamente para escenarios OpenClaw y publicado como código abierto en GitHub (repositorio pinchbench/skill).
El problema central que resuelve: la débil capacidad de las clasificaciones de modelos generales para predecir el rendimiento real de los Agentes.
La investigación ha demostrado que un modelo clasificado en el 5% superior en MMLU podría tener un rendimiento muy inferior en tareas combinadas de clasificación de correo electrónico y programación de reuniones de OpenClaw, en comparación con un modelo de clasificación media en MMLU pero optimizado específicamente para la invocación de herramientas.
La aparición de PinchBench ha proporcionado a los desarrolladores, por primera vez, una base de evaluación fiable y específica para los flujos de trabajo de los Agentes.
Las 23 categorías de tareas de PinchBench
PinchBench utiliza tareas reales en lugar de problemas sintéticos, cubriendo 23 categorías de tareas, cada una de las cuales corresponde a un escenario de uso real para los usuarios de OpenClaw:
Categorías de tareas principales (6 grandes categorías):
| Categoría principal de tarea | Contenido específico de la prueba | Herramientas involucradas | Dificultad de evaluación |
|---|---|---|---|
| Gestión de agenda | Programación de reuniones, resolución de conflictos, manejo de zonas horarias, recordatorios periódicos | API de calendario, herramientas de zona horaria | ★★★☆☆ |
| Escritura de código | Implementación de funciones, corrección de errores, refactorización de código, pruebas unitarias | Ejecución de código, sistema de archivos | ★★★★☆ |
| Procesamiento de correo electrónico | Clasificación, priorización, borradores de respuesta automática, manejo de archivos adjuntos | API de cliente de correo electrónico | ★★★☆☆ |
| Investigación de información | Búsqueda web, agregación de información, generación de resúmenes, verificación de fuentes | Motor de búsqueda, navegador | ★★★★☆ |
| Gestión de archivos | Organización, conversión de formato, operaciones por lotes, control de versiones | Sistema de archivos, herramientas de conversión | ★★☆☆☆ |
| Colaboración multitarea | Flujo de datos multiplataforma, orquestación de cadenas de herramientas, activación condicional | Combinación de múltiples herramientas | ★★★★★ |
Metodología de evaluación de PinchBench
PinchBench adopta un mecanismo de evaluación dual, que considera tanto la objetividad como la evaluación de la calidad:
Verificación automática (Automated Checks)
Utilizado para criterios objetivos verificables:
- Si el código pasa todos los casos de prueba
- Si los archivos se mueven correctamente a la ubicación especificada
- Si los eventos del calendario se crean en el momento correcto
- Si la invocación de la API devuelve el formato esperado
Juez LLM (LLM Judge)
Utilizado para evaluaciones cualitativas que requieren juicio subjetivo:
- El tono y la profesionalidad de las respuestas por correo electrónico
- La precisión y exhaustividad de la información en los informes de investigación
- La precisión de la comprensión de la tarea (si realmente se entendió la intención del usuario)
- La razonabilidad de la estrategia de manejo de casos extremos
Esta combinación equilibra la eficiencia (las comprobaciones automatizadas pueden ejecutarse a gran escala) y la calidad (el juez LLM captura detalles que son difíciles de cuantificar para los humanos).
Matriz de métricas de evaluación tridimensionales:
┌─────────────────────────────────────────────────┐
│ Sistema de Evaluación Tridimensional de PinchBench │
├─────────────────────────────────────────────────┤
│ Tasa de Éxito (Success Rate) │
│ → Mide de forma integral la calidad de finalización de la tarea │
│ → Dimensión principal de la clasificación │
│ → Combina verificación automática + Juez LLM │
├─────────────────────────────────────────────────┤
│ Velocidad (Speed) │
│ → Tiempo promedio para completar la tarea (segundos/minutos) │
│ → Crucial para escenarios de respuesta en tiempo real │
│ → Incluye latencia de API y tiempo de inferencia │
├─────────────────────────────────────────────────┤
│ Costo (Cost) │
│ → Costo de tokens consumidos para completar la tarea (USD) │
│ → Indicador clave para escenarios de uso de alta frecuencia │
│ → Ayuda a calcular el ROI y las decisiones de selección de modelos │
└─────────────────────────────────────────────────┘
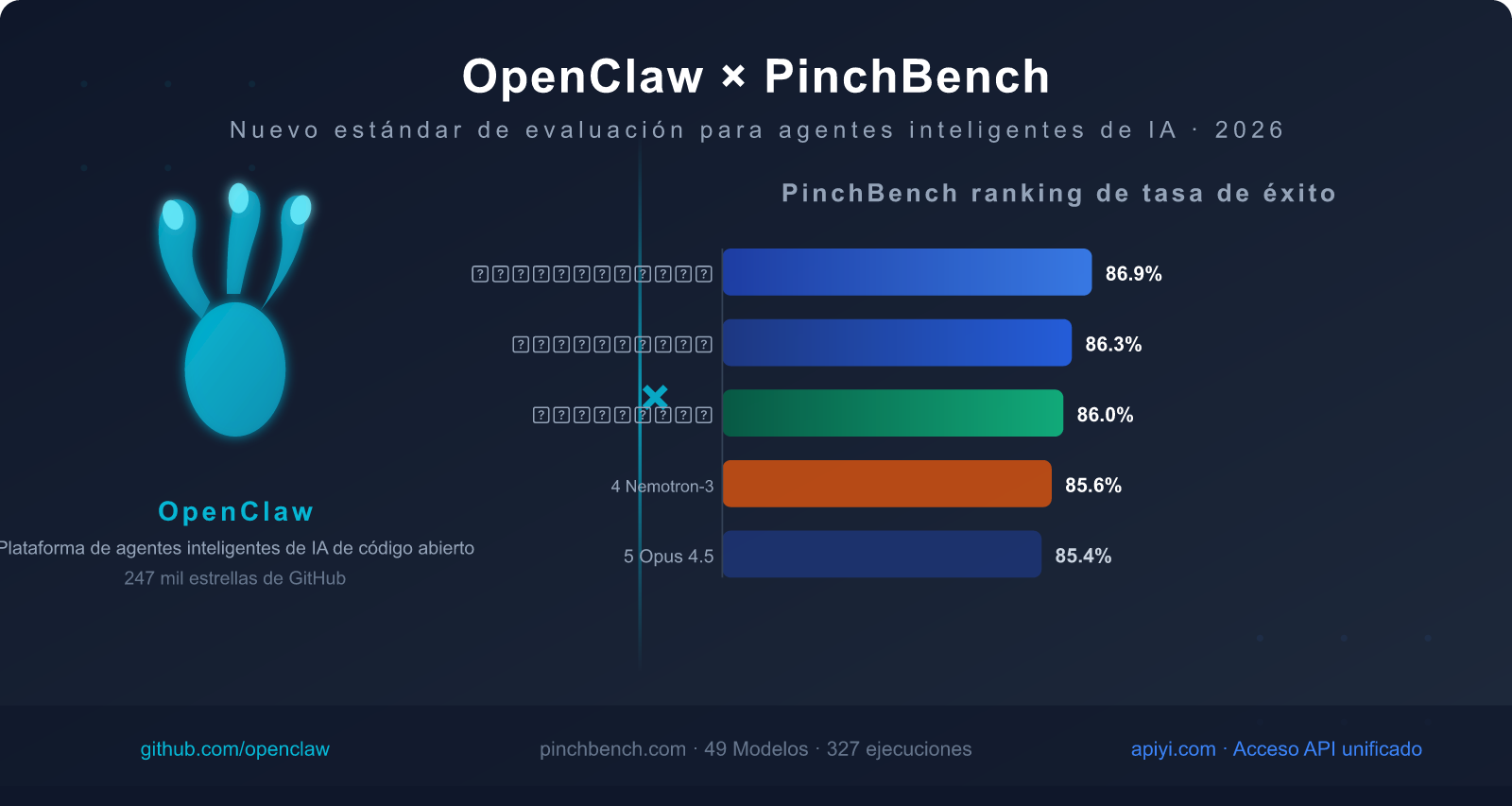
A fecha de 13 de marzo de 2026, los datos de la clasificación pública de PinchBench son:
- 📊 49 modelos han completado la evaluación, cubriendo todos los modelos comerciales y de código abierto principales.
- 🔄 327 registros de ejecución, en constante actualización.
- 🌐 Clasificación pública: pinchbench.com (actualización en tiempo real)
- 📁 Repositorio de código abierto: github.com/pinchbench/skill (definiciones de tareas públicas)
🎯 Consejo de uso de PinchBench: Al consultar la clasificación, se recomienda cambiar entre las tres vistas de tasa de éxito, velocidad y costo para filtrar el modelo más adecuado según tus necesidades reales (tiempo real vs. calidad vs. costo). Después de la integración unificada a través de APIYI apiyi.com, puedes comparar fácilmente los costos reales de diferentes modelos en el mismo escenario de negocio.
Cuatro. Análisis en profundidad de la clasificación de PinchBench y guía de selección de modelos
Clasificación actual del Top 5 por tasa de éxito (datos del 13 de marzo de 2026)
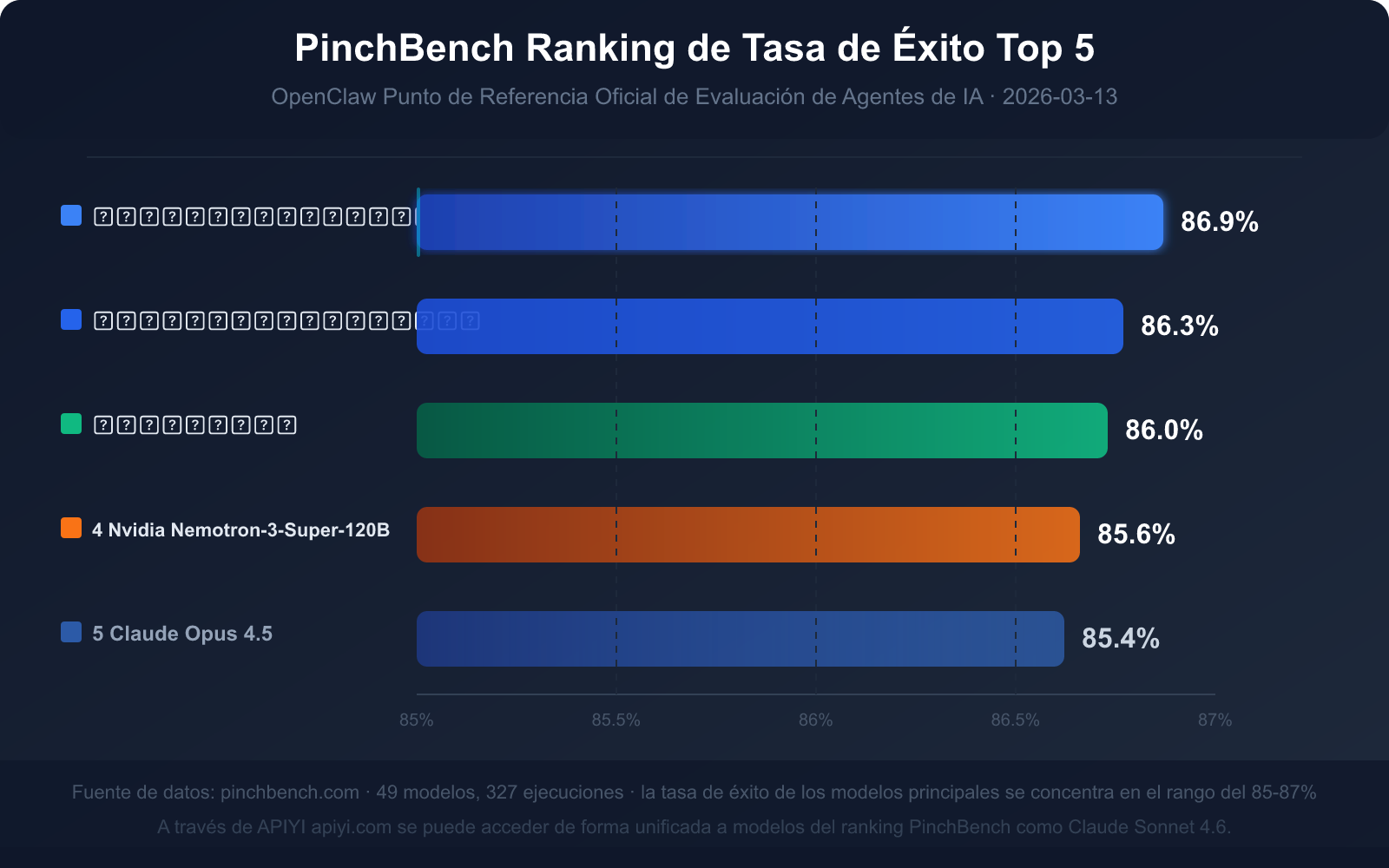
| Clasificación | Nombre del modelo | Tasa de éxito | Tipo de modelo | Ventaja principal |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Comercial de código cerrado | La tasa de éxito más alta, equilibrio entre velocidad y calidad |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Comercial de código cerrado | La capacidad de razonamiento complejo más fuerte |
| 🥉 3 | GPT-5.4 | 86.0% | Comercial de código cerrado | Buena estabilidad en la invocación de herramientas |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Código abierto desplegable | Mejor rendimiento entre los modelos de código abierto |
| 5 | Claude Opus 4.5 | 85.4% | Comercial de código cerrado | Buque insignia de la generación anterior, aún competitivo |
Perspectivas clave de los datos: ¿Qué significa una tasa de éxito del 85%?
La tasa de éxito de los modelos principales en PinchBench se concentra en el rango del 85%-87%, en lugar de acercarse a la puntuación máxima. Este número por sí mismo transmite tres señales importantes:
Señal 1: Las tareas de Agente de IA siguen siendo un problema de alta dificultad
Incluso el Claude Sonnet 4.6, clasificado en primer lugar (86.9%), fallará en aproximadamente 13 de cada 100 tareas. Esto no se debe a una falta de capacidad del modelo, sino a la complejidad inherente de las tareas del mundo real: instrucciones ambiguas, información incompleta, casos extremos en la invocación de herramientas, todo ello puede llevar al fracaso.
Señal 2: El diseño tolerante a fallos es indispensable en el desarrollo de Agentes
Cuando una tasa de fallo del 13% es un "nivel superior", un proceso de Agente totalmente automático sin nodos de revisión humana es de alto riesgo en entornos de producción. La mejor práctica es: mantener pasos de confirmación manual para operaciones de alto riesgo (como enviar correos electrónicos o enviar código).
Señal 3: La diferencia entre modelos es mínima, el diseño de la tarea es más importante
La diferencia entre el puesto 1 y el puesto 5 es de solo 1.5 puntos porcentuales (86.9% vs 85.4%). Esto significa que el impacto de elegir un modelo u otro es mucho menor que cómo diseñar la indicación de la tarea, cómo definir la interfaz de la herramienta o cómo manejar las situaciones de error.
Análisis integral de las métricas tridimensionales
Mirar solo la tasa de éxito no es suficiente. A continuación, se presenta un marco de consideración integral de las tres dimensiones:
| Escenario de uso | Métrica prioritaria | Métrica secundaria | Dirección del modelo recomendado |
|---|---|---|---|
| Tareas ligeras de alta frecuencia (clasificación de correo, recordatorios) | Velocidad + Costo | Tasa de éxito | Modelos ligeros como Claude Haiku 4.5 |
| Tareas de ingeniería complejas (refactorización de código, investigación) | Tasa de éxito | Velocidad | Claude Sonnet 4.6 / GPT-5.4 |
| Escenarios de respuesta en tiempo real (asistente instantáneo) | Velocidad | Tasa de éxito | Modelos Top en la clasificación de velocidad |
| Aplicaciones sensibles al costo | Costo | Tasa de éxito | Modelos de código abierto auto-desplegados / Modelos de API de bajo costo |
| Seguridad y cumplimiento empresarial | Tasa de éxito + Controlabilidad | Costo | Modelos de código abierto desplegados de forma privada |
🎯 Recomendación de selección integral: Según los datos de PinchBench, Claude Sonnet 4.6 es la opción integral con la tasa de éxito más alta para los escenarios actuales de OpenClaw. Para escenarios de alta frecuencia sensibles al costo, se recomienda usar primero Claude Sonnet 4.6 para establecer una línea base de tasa de éxito de la tarea, y luego probar si un modelo más ligero puede reducir significativamente el costo dentro de un rango de tasa de éxito aceptable. Todas estas pruebas se pueden realizar a través de la interfaz API unificada de APIYI apiyi.com, sin necesidad de registrarse en múltiples proveedores de servicios por separado.
Análisis de la competitividad de los modelos de código abierto
Nvidia Nemotron-3-Super-120B ocupa el puesto 4 con una tasa de éxito del 85.6%, solo 1.3 puntos porcentuales por debajo del primer lugar, lo cual es un resultado muy destacado para un modelo de código abierto.
Ventajas de los modelos de código abierto:
- Soberanía de datos: Tanto el modelo como los datos están en un entorno controlado, cumpliendo con los requisitos de cumplimiento.
- Estructura de costos: Inversión única en GPU, sin costos posteriores de invocación de API (para escenarios de alto volumen).
- Espacio de personalización: Se puede realizar Fine-tuning para tareas específicas.
Limitaciones de los modelos de código abierto:
- Costo de despliegue: Un modelo de 120B parámetros requiere de 4 a 8 GPU A100/H100.
- Carga de mantenimiento: Las actualizaciones del modelo y la gestión de versiones requieren personal de operaciones y mantenimiento dedicado.
- Costo de prueba inicial: Antes de confirmar que un modelo de código abierto es adecuado para tu escenario, la validación de prototipos a través de una API comercial suele ser más económica.
V. Guía práctica: Cómo configurar el modelo óptimo en OpenClaw
Integración rápida de Claude Sonnet 4.6 para potenciar OpenClaw
A continuación, se muestra un ejemplo de configuración completa para integrar el modelo número uno en el ranking de PinchBench a través de APIYI:
Paso 1: Obtener la clave API
Visita el sitio web oficial de APIYI, apiyi.com, regístrate y accede a la consola para obtener tu clave API. APIYI ofrece una interfaz compatible con OpenAI y también soporta el SDK nativo de Anthropic.
Paso 2: Configurar el backend del modelo de OpenClaw
# Ejemplo de archivo de configuración de OpenClaw (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Número máximo de pasos de ejecución
tool_timeout: 30 # Tiempo de espera para una única invocación de herramienta (segundos)
retry_on_error: true # Reintentar automáticamente si la invocación de la herramienta falla
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # Las operaciones de alto riesgo requieren confirmación manual
Paso 3: Verificar el efecto de la configuración
# Usar el SDK de Anthropic para probar la conexión
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Enviar solicitud de prueba
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "Por favor, enumera 3 tipos de tareas que puedes ejecutar en OpenClaw"
}]
)
print(response.content[0].text)
Paso 4: Configuración de pruebas A/B con múltiples modelos
# Comparar diferentes modelos en la misma tarea (recomendado antes del despliegue oficial)
models_to_test = [
"claude-sonnet-4-6", # PinchBench clasificado como el número uno
"gpt-5.4-turbo", # PinchBench clasificado como el número tres (compatible con formato OpenAI)
"claude-opus-4-5", # Flagship de la generación anterior, para comparación de costos
]
# APIYI soporta la invocación de interfaz unificada para todos los modelos anteriores
# base_url permanece igual, solo se necesita modificar el parámetro del modelo
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: Tasa de éxito={result.success_rate}, Tiempo={result.avg_time}s, Costo=${result.cost_per_task}")
🎯 Inicio rápido: Visita APIYI apiyi.com para registrarte y obtener un crédito de prueba.
Soporta la integración unificada de API para modelos como Claude Sonnet 4.6 y GPT-5.4, que están en la lista de PinchBench.
No es necesario solicitar acceso a múltiples proveedores por separado, lo que reduce significativamente la barrera inicial para las pruebas de modelos.
Autoevalúa tu Agente con las 5 dimensiones de PinchBench
Antes de desplegar en un entorno de producción, se recomienda evaluar la configuración de tu Agente con la siguiente lista de autoevaluación:
Lista de verificación de autoevaluación del Agente inspirada en PinchBench
□ Dimensión 1 - Tasa de finalización de tareas
Asigna al Agente 10 tareas compuestas con más de 3 pasos
Registra el número de éxitos completos / parciales / fallos
Objetivo: Tasa de éxito completo ≥ 80%
□ Dimensión 2 - Precisión de la invocación de herramientas
Revisa los registros de invocación de herramientas y cuenta los siguientes tipos de errores:
- Error de selección de herramienta (se eligió la herramienta incorrecta)
- Error de formato de parámetro (tipo o formato de parámetro incorrecto)
- Error de valor de parámetro (el tipo de parámetro es correcto pero el valor no es razonable)
Objetivo: Tasa de error de herramienta ≤ 5%
□ Dimensión 3 - Coherencia del razonamiento multi-paso
Diseña una tarea de flujo largo que requiera más de 15 pasos
Observa si hay desviación del objetivo a mitad de camino (olvido del objetivo inicial)
Objetivo: Sin desviación del objetivo en tareas de flujo largo
□ Dimensión 4 - Retención de contexto
Proporciona información clave en la ronda 1, y haz que se cite en la ronda 8
Verifica si el Agente puede citarla correctamente
Objetivo: Tasa de precisión de citación entre rondas ≥ 90%
□ Dimensión 5 - Detección de alucinaciones
Diseña tareas que requieran citar datos reales (nombre de archivo/contacto/fecha)
Verifica si el Agente inventa datos inexistentes
Objetivo: Tasa de ocurrencia de alucinaciones ≤ 2%
VI. El futuro de AI Benchmark: De la evaluación puntual a la evaluación del ecosistema
Tendencias de evolución del sistema Benchmark actual
En 2026, el campo de AI Benchmark está experimentando una profunda transformación. El núcleo de este cambio es la expansión del objeto de evaluación de modelos únicos a sistemas de Agente completos.
La mentalidad tradicional de Benchmark es: dar problemas al modelo y ver si los resuelve correctamente. Pero con la popularización de plataformas de Agente como OpenClaw, la pregunta realmente importante se convierte en: Cuando el modelo actúa como el "cerebro" de un sistema, ¿puede hacer que este sistema complete el trabajo?
La respuesta a esta pregunta no solo depende del conocimiento del modelo, sino también de:
- La capacidad del modelo para comprender las descripciones de las herramientas.
- Las estrategias de decisión del modelo ante información incierta.
- La capacidad del modelo para identificar y recuperarse de errores.
- La capacidad del modelo para rastrear la intención del usuario a largo plazo.
El valor de PinchBench radica precisamente en que cuantifica y muestra públicamente estas dimensiones.

La forma correcta de usar los datos de AI Benchmark
Los datos de Benchmark son valiosos, pero también pueden ser mal utilizados. Aquí hay algunos errores comunes y las prácticas correctas:
Error 1: Considerar el modelo mejor clasificado como "siempre el mejor"
Práctica correcta: La clasificación se basa en el conjunto de tareas específicas de PinchBench; tus tareas pueden tener una distribución de pesos diferente. Primero, prueba en tus propias tareas y luego selecciona el modelo.
Error 2: Solo mirar la tasa de éxito, ignorando la velocidad y el costo
Práctica correcta: Las métricas tridimensionales son indispensables. En escenarios de procesamiento por lotes, una diferencia del 50% en la velocidad significa un ahorro del 50% en costos; en escenarios de respuesta en tiempo real, una diferencia de 2 segundos en la velocidad significa una disminución significativa en la experiencia del usuario.
Error 3: Pensar que una diferencia del 1% en la tasa de éxito es insignificante
Práctica correcta: Una diferencia del 1% en la tasa de éxito puede parecer trivial en pruebas a pequeña escala, pero en escenarios de producción de alta frecuencia, podría generar cientos de fallos al día. Es necesario evaluar el impacto real en función del volumen de tus tareas.
Error 4: Usar datos estáticos de Benchmark para la planificación a largo plazo
Práctica correcta: Los modelos de IA evolucionan a una velocidad asombrosa, con los principales fabricantes lanzando actualizaciones importantes en promedio cada trimestre en 2026. Se recomienda incluir la evaluación del rendimiento del modelo en las revisiones técnicas regulares, en lugar de "elegir un modelo para siempre".
Mejores prácticas para la evaluación de Agentes a nivel empresarial
Para los equipos técnicos que implementan OpenClaw o plataformas de Agente similares en empresas, a continuación se presenta un conjunto de mejores prácticas de evaluación aplicables:
Paso 1: Establecer un conjunto de tareas de referencia
Selecciona de 20 a 50 tareas típicas de tu negocio real, que cubran operaciones diarias de alta frecuencia y escenarios complejos ocasionales. Este conjunto de tareas debe ser definido conjuntamente por las partes interesadas del negocio y el equipo técnico, para evitar sesgos de evaluación causados por una perspectiva puramente técnica.
Paso 2: Seguimiento continuo de métricas tridimensionales
Sugerencia de sistema de métricas de evaluación de Agentes a nivel empresarial
Métricas clave (estadísticas semanales):
- Tasa de finalización de tareas: Objetivo ≥ 85% (comparable con el nivel de los modelos top de PinchBench)
- Tasa de error de invocación de herramientas: Objetivo ≤ 5%
- Tiempo promedio por tarea: Definido según el SLA del negocio
Métricas auxiliares (estadísticas mensuales):
- Costo de tokens/tarea: Controlar los costos operativos
- Tasa de intervención humana: Porcentaje de tareas que requieren intervención manual
- Distribución de tipos de error: Analizar direcciones de mejora
Métricas de alerta (monitoreo en tiempo real):
- Tasa de fallo de operaciones de alto riesgo: Fallos como enviar correos/eliminar archivos deben generar una alerta inmediata
- Eventos de alucinación: La invención de información debe registrarse y analizarse de inmediato
Paso 3: Reevaluación periódica del modelo
Se recomienda reevaluar trimestralmente el modelo actualmente desplegado, así como los nuevos modelos candidatos, utilizando el conjunto de tareas internas. Combina esto con los últimos datos públicos de PinchBench para determinar si es necesario actualizar o cambiar el modelo.
Paso 4: Acumular conocimiento del dominio
Los Benchmarks generales no pueden cubrir los escenarios específicos de cada empresa. A medida que se acumula el uso, establece gradualmente un conjunto de tareas y criterios de puntuación adecuados para tu propio negocio; esto se convertirá en una herramienta de filtrado importante para seleccionar proveedores de IA.
🎯 Recomendación para la selección empresarial: Al inicio de la implementación de una plataforma de Agente, se sugiere acceder a varios modelos candidatos a través de APIYI apiyi.com con un plan de pago por uso.
Realiza pruebas prácticas durante 3-4 semanas con tu conjunto de tareas internas antes de decidir si migrar a un plan mensual.
APIYI soporta una interfaz unificada para modelos populares como Claude, GPT y Gemini,
lo que elimina la necesidad de registrarse en múltiples cuentas de proveedores durante la fase de prueba y reduce significativamente los costos de gestión de la evaluación.
Preguntas Frecuentes
P: ¿Cuál es la diferencia fundamental entre OpenClaw y AutoGPT, AutoGen?
La diferencia fundamental de OpenClaw radica en su método de acceso y la barrera de entrada: ofrece una interfaz de Agente a través de aplicaciones de mensajería (Signal, WhatsApp, etc.), lo que permite a los usuarios comunes utilizarlo sin necesidad de instalar una aplicación dedicada o entender detalles técnicos. Desde una perspectiva de arquitectura técnica, OpenClaw se asemeja más a un "secretario personal de IA", mientras que frameworks como AutoGen son más adecuados para desarrolladores que buscan construir sistemas multi-Agente complejos. OpenClaw enfatiza una "experiencia de consumo lista para usar", mientras que AutoGen se centra en un "framework de desarrollo empresarial flexible".
🎯 Independientemente del framework de Agente que elijas, puedes integrar modelos de backend de manera unificada a través de APIYI apiyi.com, evitando la configuración individual de la clave API para cada framework.
P: ¿Con qué frecuencia se actualiza el ranking de tasa de éxito de PinchBench?
La clasificación de PinchBench se actualiza en tiempo real: cada vez que un nuevo modelo completa una evaluación, los datos se reflejan inmediatamente en pinchbench.com. A medida que los principales fabricantes lanzan continuamente nuevas versiones, el ranking cambiará con frecuencia. Se recomienda consultar los datos más recientes antes de tomar una decisión de selección formal. Los datos de este artículo se basan en una instantánea del 13 de marzo de 2026 (49 modelos, 327 registros de ejecución).
P: ¿Cómo elegir el modelo más adecuado para OpenClaw?
Recomendamos un método de selección en tres pasos:
- Ver la tasa de éxito de PinchBench: Filtra los 5 principales en tasa de finalización de tareas.
- Considerar la velocidad y el costo: Filtra nuevamente según tu tipo de tarea (tiempo real vs. procesamiento por lotes, alta frecuencia vs. baja frecuencia).
- Pruebas A/B reales: Compara 2-3 modelos candidatos en tus tareas de negocio reales.
A través de APIYI apiyi.com, puedes cambiar rápidamente entre diferentes modelos usando la misma base_url, y tomar la decisión final después de completar las pruebas A/B.
P: ¿Pueden los modelos de código abierto reemplazar completamente a los modelos comerciales para impulsar OpenClaw?
Según los datos de PinchBench, la diferencia entre Nvidia Nemotron-3-Super-120B (85.6%) y los modelos comerciales de primer nivel (86.9%) es de aproximadamente 1.3 puntos porcentuales. Para tareas de Agente generales, esta diferencia es aceptable. Sin embargo, ten en cuenta que el auto-despliegue de un modelo de 120B parámetros requiere de 4 a 8 GPU de gama alta, lo que implica una inversión inicial considerable en hardware y costos de operación y mantenimiento. Se recomienda primero validar la viabilidad del diseño del Agente con una API comercial, y luego evaluar si vale la pena migrar a un modelo de código abierto auto-desplegado.
P: ¿Cómo se pueden mitigar los riesgos de seguridad de OpenClaw?
El principio fundamental es la minimización de privilegios: otorga a OpenClaw solo el mínimo alcance de permisos necesarios para completar sus tareas. Sugerencias específicas:
- Permisos de solo lectura para correos electrónicos (en lugar de permisos completos de lectura, escritura y eliminación)
- Permisos de solo lectura + creación de PR para repositorios de código (en lugar de push directo a la rama principal)
- Sistema de archivos limitado a un directorio de trabajo específico (en lugar de todo el sistema de archivos)
- Las operaciones de alto riesgo (enviar correos electrónicos, eliminar archivos) deben incluir un paso de confirmación manual.
Al implementar en una empresa, también es necesario configurar registros completos de auditoría de operaciones para asegurar que cada operación del Agente tenga un registro rastreable.
P: ¿Cuál es la diferencia entre PinchBench y otros benchmarks de Agentes?
La característica más importante de PinchBench es su especificidad de escenario: está diseñado específicamente para los casos de uso de OpenClaw, no para una evaluación general de Agentes. Esto significa que tiene un valor de referencia más alto para los usuarios de OpenClaw, pero no es adecuado para evaluar directamente la selección de modelos para otros frameworks de Agentes. Otros benchmarks de Agentes conocidos incluyen AgentBench (que cubre múltiples entornos), SWE-Bench (centrado en tareas de código), etc., cada uno con su propio enfoque.
Resumen: OpenClaw + PinchBench establecen un nuevo estándar para la era de los Agentes
OpenClaw, que comenzó como un proyecto de fin de semana de un desarrollador austriaco, ha crecido en dos meses hasta convertirse en la plataforma de Agentes de IA más popular del mundo. Esto refleja el fuerte deseo de toda la industria de que la "IA realmente haga cosas".
La aparición de PinchBench, por su parte, ha llenado un vacío crucial en el campo de la evaluación de Agentes: finalmente tenemos una herramienta diseñada específicamente para medir la capacidad de los Agentes.
Conclusiones clave rápidas:
- Claude Sonnet 4.6 es la mejor opción general para los escenarios actuales de OpenClaw (86.9% de tasa de éxito, primer puesto en PinchBench)
- La tasa de éxito de los modelos de primer nivel se concentra entre el 85-87%, las tareas de Agente siguen siendo un desafío, y el diseño tolerante a fallos es indispensable.
- La velocidad y el costo son igualmente importantes, un modelo con alta tasa de éxito no siempre es adecuado para todos los escenarios, se requiere una evaluación integral tridimensional.
- PinchBench representa la dirección futura de la evaluación de IA: las tareas de escenarios reales están reemplazando las pruebas sintéticas.
- La diferencia en la elección del modelo es de aproximadamente 1-2%, el diseño de la tarea y la ingeniería de la indicación suelen tener un impacto mayor.
Para los desarrolladores y empresas que desean profundizar en el ecosistema de OpenClaw, este es un momento excelente:
La comunidad de código abierto está activa, las herramientas de evaluación son completas y los costos de acceso a la API de los modelos principales están disminuyendo continuamente. No necesitas esperar a que aparezca la "solución perfecta"; puedes empezar ahora mismo a validar la viabilidad de los flujos de trabajo de Agente con tareas a pequeña escala.
🎯 Actúa ahora: Si estás construyendo un flujo de trabajo de IA basado en OpenClaw, te recomendamos la integración unificada a través de APIYI apiyi.com.
La plataforma es compatible con modelos principales como Claude Sonnet 4.6 (primer puesto en PinchBench) y GPT-5.4 (tercer puesto),
utilizando el mismo conjunto de interfaces API, sin necesidad de registrarse con múltiples proveedores. Admite la facturación por uso, lo que es ideal para comenzar con pruebas a pequeña escala y expandirse gradualmente.
Visita el sitio web oficial de APIYI apiyi.com para registrarte y empezar a experimentar.
Los datos de este artículo se basan en información pública recopilada en marzo de 2026. Para obtener los datos en tiempo real de la clasificación de PinchBench, visita pinchbench.com para ver la versión más reciente.
Autor: Equipo de APIYI | Para más detalles sobre la integración de API de modelos de IA, visita APIYI apiyi.com