Em 2026, um projeto de código aberto criado por um desenvolvedor independente austríaco durante os fins de semana conquistou 247 mil estrelas no GitHub em dois meses, tornando-se uma plataforma de agentes de IA que empresas do Vale do Silício e da China disputam para implantar.
Este projeto se chama OpenClaw.
Ao mesmo tempo, uma questão surgiu: em cenários reais de Agente como o OpenClaw, qual modelo de IA tem o melhor desempenho?
É exatamente isso que o PinchBench busca resolver. É o benchmark de avaliação oficial do OpenClaw, desenvolvido pela equipe kilo.ai usando Rust, que substitui testes sintéticos por tarefas reais, oferecendo aos desenvolvedores uma base confiável para a escolha de modelos.
Este artigo parte da história de ascensão do OpenClaw, analisa profundamente o sistema de avaliação do PinchBench, ajudando você a entender o verdadeiro significado dos benchmarks de IA e como escolher o modelo ideal para o seu fluxo de trabalho de Agente com base nos dados de avaliação.
I. O que é OpenClaw: Um Fenômeno Open Source que Mudou de Nome 3 Vezes em Um Mês
O Nascimento do OpenClaw e a Polêmica do Nome
A história do OpenClaw começa em novembro de 2025.
O desenvolvedor austríaco Peter Steinberger dedicou seu tempo livre para construir uma plataforma de agente de IA, inicialmente chamada Clawdbot. A ideia central do projeto era simples: fazer com que a IA não fosse apenas uma ferramenta de bate-papo, mas que pudesse realmente assumir seus fluxos de trabalho digitais – ler e-mails, escrever código, gerenciar calendários, pesquisar informações.
Mas o conceito de AI Agent não é novo. Por que o OpenClaw explodiu da noite para o dia?
A chave foi a combinação de timing e suporte open source. No final de janeiro de 2026, com a disseminação viral do projeto Moltbook, o desejo de "fazer a IA realmente funcionar" atingiu o pico em todo o círculo tecnológico, e o Clawdbot aproveitou a onda para se tornar o centro das atenções.
No entanto, logo em seguida, recebeu uma notificação de objeção de marca registrada da Anthropic – "Clawd" no Clawdbot foi considerado um risco de confusão com o nome de um produto interno da Anthropic. O projeto foi forçado a mudar urgentemente seu nome para Moltbot em 27 de janeiro de 2026, em homenagem ao popular projeto Moltbook da mesma época.
Três dias depois, Steinberger confessou no GitHub: o novo nome "nunca soou bem" ("never quite rolled off the tongue"), e o projeto foi renomeado novamente para OpenClaw, nome que mantém até hoje.
Essa polêmica de nomes, por sua vez, tornou-se a melhor "marketing gratuito" para o projeto, tornando o OpenClaw amplamente conhecido na comunidade de desenvolvedores.
Até 2 de março de 2026, o OpenClaw acumulou no GitHub:
- ⭐ 247 mil estrelas (quase metade das estrelas do framework React no mesmo período)
- 🍴 47,7 mil forks
- 🌍 Implantação em larga escala em empresas no Vale do Silício, Europa e China
Arquitetura Técnica Central do OpenClaw
A filosofia de design do OpenClaw é: execução local, independente de modelo, integração com aplicativos de mensagens.
Essas três características determinam suas diferenças fundamentais em relação a outros frameworks de AI Agent.
Execução local significa que seus dados não passam por nenhum servidor de terceiros. Ao contrário da maioria dos assistentes de IA no formato SaaS, o OpenClaw é implantado no próprio dispositivo do usuário, e as invocações da API do modelo também podem apontar para endpoints privados.
Independência de modelo significa que o OpenClaw em si não está vinculado a nenhum Modelo de Linguagem Grande (LLM). É uma "casca cerebral" que suporta a conexão com Claude, GPT, DeepSeek e outros modelos mainstream, permitindo que os desenvolvedores alternem livremente com base no tipo de tarefa e no orçamento de custo.
A integração com aplicativos de mensagens é o design mais característico do OpenClaw – usuários comuns não precisam abrir nenhum aplicativo dedicado, podem invocar as capacidades do AI Agent diretamente enviando mensagens no Signal, Telegram, Discord ou WhatsApp. Isso reduz significativamente a barreira de uso, permitindo que usuários não técnicos também se beneficiem.
| Dimensão de Design | Escolha do OpenClaw | Alternativas Mainstream | Descrição da Diferença |
|---|---|---|---|
| Local de Implantação | Execução Local | SaaS em Nuvem | Maior privacidade de dados, mas requer manutenção própria |
| Vinculação de Modelo | Completamente Independente | Vinculado a Modelo Específico | Alternância flexível, mas requer configuração própria |
| Interface do Usuário | Aplicativos de Mensagens | Web/App Dedicado | Baixa barreira de entrada, funcionalidade limitada pelo aplicativo de mensagens |
| Escopo de Permissões | Acesso Amplo | Restrição Sandbox | Funcionalidade poderosa, mas maior risco de segurança |
| Licença Open Source | Completamente Open Source | Proprietário/Parcialmente Open Source | Impulsionado pela comunidade, mas suporte limitado |
🎯 Sugestão de Uso: A implantação do OpenClaw requer a configuração de um backend LLM de alta qualidade.
Sugerimos conectar-se ao Claude Sonnet 4.6 ou GPT-5.4 através da APIYI apiyi.com.
Ambos os modelos demonstraram excelente desempenho no PinchBench, e a APIYI suporta alternância de interface unificada,
facilitando a comparação rápida dos efeitos de diferentes modelos sem modificar a configuração central do OpenClaw.
Limites de Capacidade do OpenClaw
O OpenClaw suporta uma ampla gama de capacidades, mas é precisamente por isso que gerou controvérsia de segurança:
Fontes de dados acessíveis:
- Contas de e-mail (ler, classificar, rascunhar respostas)
- Sistemas de calendário (visualizar, criar, modificar agendamentos)
- Sistemas de arquivos (navegar, ler, criar, mover arquivos)
- Repositórios de código (ler código, executar testes, enviar alterações)
- Plataformas de mensagens (agregação e resposta de mensagens multiplataforma)
- Informações da web (pesquisar, resumir, extrair de forma estruturada)
Cenários de uso típicos:
Usuário envia no Telegram: "Por favor, organize meus e-mails de hoje,
marque os que precisam de resposta hoje e rascunhe o conteúdo da resposta."
Fluxo de execução do OpenClaw Agent:
1. Invoca a ferramenta de e-mail para ler os e-mails não lidos de hoje.
2. Usa o LLM para determinar a urgência de cada e-mail.
3. Filtra a lista de e-mails que precisam de resposta hoje.
4. Gera um rascunho de resposta para cada e-mail.
5. Retorna os resultados organizados e a prévia dos rascunhos no Telegram.
Essa capacidade de "realmente fazer as coisas" é a diferença essencial entre o OpenClaw e um simples chatbot.
Steinberger Junta-se à OpenAI e o Futuro do Projeto
Em 14 de fevereiro de 2026, uma notícia abalou toda a comunidade open source: Steinberger anunciou no GitHub que se juntaria à OpenAI, e o projeto seria transferido para uma fundação open source independente.
O impacto no OpenClaw é duplo: por um lado, o projeto obteve uma operação e proteção legal mais profissionais; por outro lado, o mundo exterior começou a especular sobre o motivo por trás da aquisição deste fundador pela OpenAI – seria para absorção de tecnologia ou para prevenir um potencial concorrente?
Atualmente, a Fundação OpenClaw foi estabelecida, e o projeto permanece totalmente open source, mas o roteiro de desenvolvimento mostra uma clara prioridade: recursos de segurança de nível empresarial e sistemas de controle de permissões tornaram-se o foco da próxima versão.
Controvérsia de Segurança: Riscos Trazidos por Capacidades Poderosas
A ampla necessidade de permissões do OpenClaw levantou preocupações entre pesquisadores de segurança cibernética desde o início.
Em março de 2026, as autoridades chinesas anunciaram restrições à execução do OpenClaw em computadores de empresas estatais e agências governamentais, principalmente devido a preocupações como:
- Dados podem ser vazados para provedores de serviços estrangeiros através de invocações da API do LLM.
- Permissões amplas podem se tornar um ponto de entrada para ataques se configuradas incorretamente.
- Informações sensíveis internas da empresa podem ser transmitidas entre sistemas pelo Agent.
Este incidente serve como um lembrete para todos os desenvolvedores corporativos: ao introduzir ferramentas de Agent poderosas, os princípios de privilégio mínimo e logs de auditoria são fundamentos de segurança inegociáveis.
II. O Verdadeiro Papel do Benchmark na Indústria de IA: Do Exame à Prática
Por Que a Indústria de IA Não Pode Viver Sem Benchmarks
Se você já tentou comparar as capacidades de dois modelos de IA, provavelmente encontrou um dilema: os fabricantes dizem que seus modelos são os "mais fortes", mas o que significa "forte"? Em que tarefa? Em comparação com qual linha de base?
Um Benchmark (referencial de avaliação) é um sistema de teste padronizado criado para resolver esse problema.
Na indústria de IA, um bom Benchmark precisa atender a três condições:
- Reprodutibilidade: Qualquer pessoa usando o mesmo conjunto de testes deve obter os mesmos resultados.
- Representatividade: O conteúdo do teste deve refletir as necessidades de capacidade em cenários de uso reais.
- Imparcialidade: O conjunto de testes não deve ser contaminado pelos dados de treinamento do desenvolvedor do modelo.
Em 2026, havia mais de 15 Benchmarks mainstream em uso ativo em toda a indústria, mas estima-se que apenas cerca de 4 deles podem realmente prever o desempenho em ambientes de produção.

Limitações dos Benchmarks Tradicionais
Para entender o valor do PinchBench, é preciso primeiro entender por que os Benchmarks tradicionais são "insuficientes".
MMLU (Massive Multitask Language Understanding)
MMLU é atualmente a avaliação de conhecimento geral mais citada, cobrindo 57 disciplinas e cerca de 14.000 questões de múltipla escolha. As questões abrangem áreas como medicina, direito, história, matemática e programação.
O problema é: são questões de múltipla escolha, e o modelo só precisa escolher uma das 4 opções. Em cenários reais de Agent, o modelo precisa gerar respostas de forma autônoma e até mesmo invocar ferramentas para obter informações – o que é completamente diferente de "escolher uma das 4 opções".
HumanEval (Teste de Geração de Código)
HumanEval é um Benchmark icônico para medir a capacidade de geração de código, contendo 164 problemas de programação em Python. No entanto, suas questões são relativamente fixas, e os modelos podem ter tido contato com tipos de problemas semelhantes durante o treinamento, levando a um "efeito de memorização" – pontuações altas não significam capacidade real de programação.
Problemas comuns de testes sintéticos:
| Tipo de Problema | Manifestação Específica | Impacto nos Resultados da Avaliação |
|---|---|---|
| Contaminação de Dados | Conjunto de treinamento contém questões de teste | Pontuação alta não representa capacidade real de generalização |
| Efeito de Memorização | Modelo otimizado para um Benchmark específico | Classificação inflacionada, capacidade real não melhorada |
| Desconexão do Cenário | Questões de múltipla escolha muito diferentes do uso real | Baixa capacidade de previsão da classificação |
| Conjunto de Dados Estático | Questões fixas, impossibilidade de atualização | Novas capacidades não podem ser avaliadas |
| Avaliação Unidimensional | Foca apenas na precisão | Ignora velocidade, custo, confiabilidade |
5 Dimensões Essenciais para a Avaliação de AI Agent
Quando os sistemas de IA evoluem de "responder perguntas" para "completar tarefas", o sistema de avaliação também deve ser atualizado.
Para plataformas de agente de IA como o OpenClaw, a avaliação precisa cobrir as seguintes 5 dimensões principais:
Dimensão 1: Taxa de Conclusão da Tarefa (Task Completion Rate)
A proporção geral de sucesso desde o recebimento da tarefa até a conclusão final. Este é o indicador mais intuitivo, mas também o mais complexo – a própria definição de "conclusão" é o desafio central do design da avaliação.
Método de teste: Dê ao Agent uma tarefa composta de 3-5 etapas, e estatísticas da proporção de sucesso total, sucesso parcial e falha.
Dimensão 2: Precisão da Invocação de Ferramentas (Tool Call Accuracy)
O Agent precisa escolher a ferramenta correta entre dezenas de ferramentas disponíveis e invocá-la com os parâmetros corretos. Uma invocação de ferramenta incorreta não é apenas uma falha, mas também pode causar efeitos colaterais (como exclusão acidental de arquivos, envio de e-mails errados).
Método de teste: Projete tarefas que exijam uma sequência específica de ferramentas, e estatísticas da taxa de erro na seleção de ferramentas e nos parâmetros.
Dimensão 3: Coerência do Raciocínio Multietapas (Multi-step Reasoning Coherence)
Completar uma tarefa geralmente requer 5-10 etapas, e o Agent precisa manter uma compreensão clara do objetivo durante todo o processo, não podendo "se perder no caminho".
Método de teste: Projete tarefas de fluxo longo que exijam mais de 10 etapas, e observe se ocorre desvio de objetivo ou quebra de lógica no meio.
Dimensão 4: Retenção de Contexto Entre Turnos (Cross-turn Context Retention)
Em diálogos de várias rodadas, o Agent precisa lembrar as informações trocadas anteriormente. Informações como "você disse na última vez que teríamos uma reunião na quarta-feira" são cruciais no fluxo de trabalho do OpenClaw.
Método de teste: Projete cenários de tarefas que exijam a citação de informações de 5 ou mais rodadas anteriores, e estatísticas da taxa de perda de contexto.
Dimensão 5: Frequência de Alucinações (Hallucination Rate)
O Agent inventa arquivos inexistentes, contatos inexistentes, datas erradas. Essas alucinações são pequenos problemas em um bate-papo, mas em um cenário de Agent podem causar perdas reais (como o envio de e-mails com conteúdo incorreto).
Método de teste: Projete tarefas que exijam a citação de dados reais (nomes de arquivos, endereços de e-mail, datas), e estatísticas da frequência de ocorrência de alucinações.
🎯 Sugestão para Desenvolvedores: Ao escolher um modelo de Agent, a taxa de conclusão da tarefa e a precisão da invocação de ferramentas são os dois indicadores mais importantes.
Recomenda-se usar a plataforma APIYI apiyi.com para conectar-se rapidamente a vários modelos, e verificar o efeito em suas próprias tarefas reais usando as 5 dimensões acima,
em vez de depender apenas dos números do ranking. A APIYI suporta faturamento por uso, sendo adequada para testes A/B em pequena escala antes da seleção final.
Três. Análise Aprofundada do PinchBench: O Padrão Oficial de Avaliação do OpenClaw
Contexto do Surgimento do PinchBench
O PinchBench, desenvolvido pela equipe kilo.ai usando Rust, é um benchmark de avaliação feito sob medida para cenários OpenClaw, lançado como código aberto no GitHub (repositório pinchbench/skill).
O problema central que ele resolve: A capacidade dos rankings de modelos gerais de prever o desempenho real de Agentes é muito fraca.
Pesquisas mostram que um modelo classificado entre os 5% melhores no MMLU pode ter um desempenho muito inferior em tarefas combinadas de classificação de e-mails + agendamento de reuniões no OpenClaw, em comparação com um modelo com classificação média no MMLU, mas otimizado especificamente para invocação de ferramentas.
O surgimento do PinchBench deu aos desenvolvedores, pela primeira vez, uma base de avaliação confiável e específica para fluxos de trabalho de Agentes.
As 23 Categorias de Tarefas do PinchBench
O PinchBench utiliza tarefas reais, e não problemas sintéticos, cobrindo 23 categorias de tarefas, cada uma correspondendo a um cenário de uso real para usuários do OpenClaw:
Categorias de tarefas principais (6 grandes categorias):
| Categoria Principal da Tarefa | Conteúdo Específico do Teste | Ferramentas Envolvidas | Dificuldade da Avaliação |
|---|---|---|---|
| Gerenciamento de Agenda | Agendamento de reuniões, resolução de conflitos, tratamento de fuso horário, lembretes periódicos | API de Calendário, Ferramentas de Fuso Horário | ★★★☆☆ |
| Escrita de Código | Implementação de funcionalidades, correção de bugs, refatoração de código, testes unitários | Execução de Código, Sistema de Arquivos | ★★★★☆ |
| Processamento de E-mail | Classificação, priorização, rascunho de resposta automática, tratamento de anexos | API de Cliente de E-mail | ★★★☆☆ |
| Pesquisa de Informações | Busca na web, agregação de informações, geração de resumos, verificação de fontes | Mecanismos de Busca, Navegador | ★★★★☆ |
| Gerenciamento de Arquivos | Organização, conversão de formato, operações em lote, controle de versão | Sistema de Arquivos, Ferramentas de Conversão | ★★☆☆☆ |
| Colaboração Multi-ferramentas | Fluxo de dados entre plataformas, orquestração de cadeias de ferramentas, gatilhos condicionais | Combinação de várias ferramentas | ★★★★★ |
Metodologia de Avaliação do PinchBench
O PinchBench adota um mecanismo de avaliação duplo, que equilibra objetividade e avaliação de qualidade:
Verificação Automatizada (Automated Checks)
Usado para critérios objetivos e verificáveis:
- Se o código passa em todos os casos de teste
- Se os arquivos são movidos corretamente para o local especificado
- Se os eventos do calendário são criados no horário correto
- Se as invocações da API retornam o formato esperado
Juiz LLM (LLM Judge)
Usado para avaliações qualitativas que exigem julgamento subjetivo:
- Tom e profissionalismo das respostas de e-mail
- Precisão e integridade das informações em relatórios de pesquisa
- Precisão da compreensão da tarefa (se a intenção do usuário foi realmente compreendida)
- Racionalidade das estratégias de tratamento de casos extremos
Essa combinação equilibra eficiência (verificações automatizadas podem ser executadas em larga escala) e qualidade (o juiz LLM captura detalhes que são difíceis de quantificar por humanos).
Matriz de métricas de avaliação tridimensional:
┌─────────────────────────────────────────────────┐
│ Sistema de Avaliação Tridimensional do PinchBench │
├─────────────────────────────────────────────────┤
│ Taxa de Sucesso (Success Rate) │
│ → Medida abrangente da qualidade de conclusão da tarefa │
│ → Principal dimensão de classificação │
│ → Combina verificação automatizada + Juiz LLM │
├─────────────────────────────────────────────────┤
│ Velocidade (Speed) │
│ → Tempo médio para concluir a tarefa (segundos/minutos) │
│ → Crucial para cenários de resposta em tempo real │
│ → Inclui latência da API e tempo de inferência │
├─────────────────────────────────────────────────┤
│ Custo (Cost) │
│ → Custo de tokens consumidos para concluir a tarefa (USD) │
│ → Indicador chave para cenários de uso de alta frequência │
│ → Ajuda no cálculo do ROI e na decisão de seleção de modelos │
└─────────────────────────────────────────────────┘
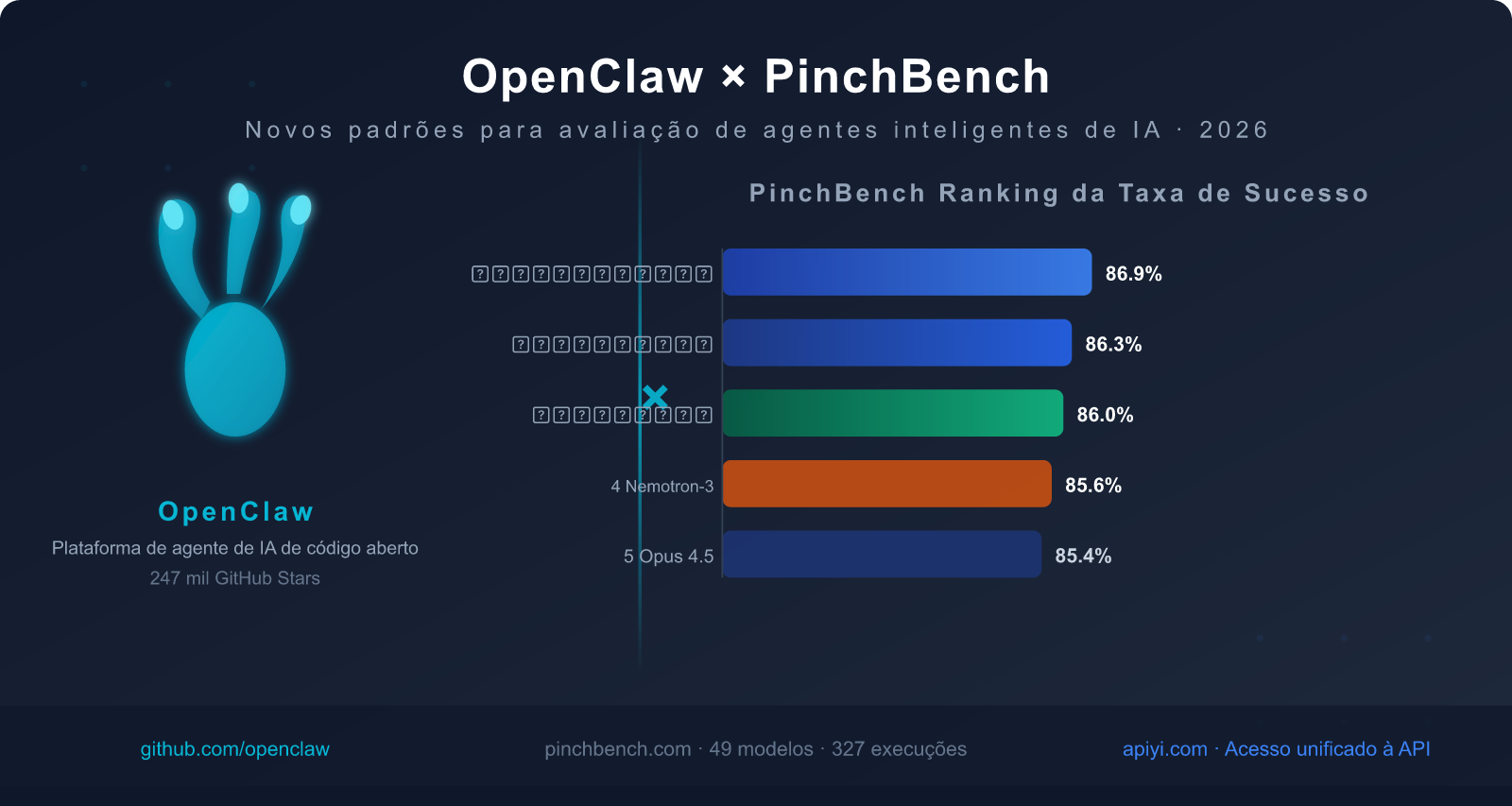
Até 13 de março de 2026, os dados do ranking público do PinchBench são:
- 📊 49 modelos avaliados, cobrindo todos os principais modelos comerciais e de código aberto
- 🔄 327 registros de execução, em constante atualização
- 🌐 Ranking público: pinchbench.com (atualização em tempo real)
- 📁 Repositório de código aberto: github.com/pinchbench/skill (definições de tarefas públicas)
🎯 Sugestão de uso do PinchBench: Ao consultar o ranking, é recomendável alternar entre as três visualizações: taxa de sucesso, velocidade e custo,
para filtrar o modelo mais adequado de acordo com suas necessidades reais (tempo real vs. qualidade vs. custo).
Após a integração unificada via APIYI apiyi.com, é fácil comparar os custos reais de diferentes modelos no mesmo cenário de negócios.
Quatro. Análise Aprofundada do Ranking PinchBench e Guia de Seleção de Modelos
Ranking Atual dos Top 5 em Taxa de Sucesso (dados de 13 de março de 2026)
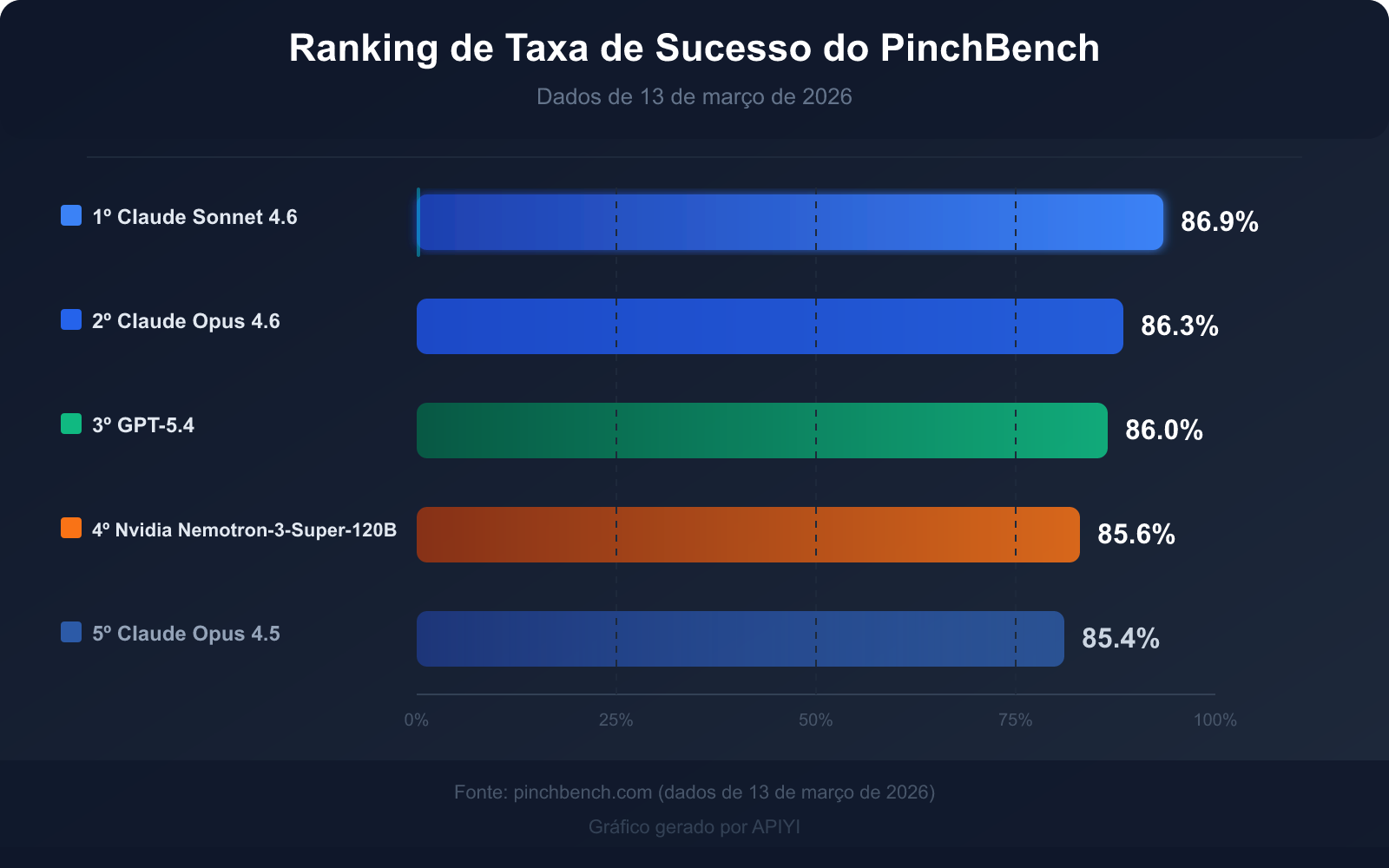
| Ranking | Nome do Modelo | Taxa de Sucesso | Tipo de Modelo | Principal Vantagem |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | Comercial proprietário | Maior taxa de sucesso, equilíbrio entre velocidade e qualidade |
| 🥈 2 | Claude Opus 4.6 | 86.3% | Comercial proprietário | Capacidade de raciocínio complexo mais forte |
| 🥉 3 | GPT-5.4 | 86.0% | Comercial proprietário | Boa estabilidade na invocação de ferramentas |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | Código aberto e implantável | Melhor desempenho entre os modelos de código aberto |
| 5 | Claude Opus 4.5 | 85.4% | Comercial proprietário | Flagship da geração anterior, ainda competitivo |
Principais Insights dos Dados: O Que Significa Uma Taxa de Sucesso de 85%?
A taxa de sucesso dos modelos de ponta no PinchBench concentra-se na faixa de 85%-87%, e não perto da pontuação máxima. Este número, por si só, transmite três sinais importantes:
Sinal 1: As tarefas de Agente de IA ainda são um problema de alta dificuldade
Mesmo o Claude Sonnet 4.6 (86.9%), que ocupa o primeiro lugar, ainda falha em cerca de 13 de cada 100 tarefas. Isso não se deve à falta de capacidade do modelo, mas sim à complexidade inerente às tarefas do mundo real — instruções ambíguas, informações incompletas e casos extremos na invocação de ferramentas podem levar a falhas.
Sinal 2: O design tolerante a falhas é indispensável no desenvolvimento de Agentes
Quando uma taxa de falha de 13% é considerada "nível superior", um fluxo de Agente totalmente automatizado sem pontos de revisão humana é de alto risco em ambientes de produção. A melhor prática é: manter etapas de confirmação manual para operações de alto risco (como enviar e-mails, submeter código).
Sinal 3: A diferença entre os modelos é mínima, o design da tarefa é mais importante
A diferença entre o 1º e o 5º lugar é de apenas 1.5 pontos percentuais (86.9% vs 85.4%). Isso significa que o impacto de qual modelo escolher é muito menor do que como projetar o comando da tarefa, como definir as interfaces das ferramentas e como lidar com situações de erro.
Análise Abrangente das Métricas Tridimensionais
Olhar apenas para a taxa de sucesso não é suficiente. Abaixo está uma estrutura de consideração abrangente para as três dimensões:
| Cenário de Uso | Indicadores Prioritários | Indicadores Secundários | Direção do Modelo Recomendado |
|---|---|---|---|
| Tarefas leves de alta frequência (classificação de e-mails, lembretes) | Velocidade + Custo | Taxa de Sucesso | Modelos leves como Claude Haiku 4.5 |
| Tarefas de engenharia complexas (refatoração de código, pesquisa) | Taxa de Sucesso | Velocidade | Claude Sonnet 4.6 / GPT-5.4 |
| Cenários de resposta em tempo real (assistente instantâneo) | Velocidade | Taxa de Sucesso | Modelos Top do ranking de velocidade |
| Aplicações sensíveis ao custo | Custo | Taxa de Sucesso | Código aberto auto-implantável / Modelos de API de baixo custo |
| Conformidade de segurança empresarial | Taxa de Sucesso + Controlabilidade | Custo | Modelos de código aberto com implantação privada |
🎯 Sugestão de seleção abrangente: De acordo com os dados do PinchBench, o Claude Sonnet 4.6 é a escolha mais abrangente com a maior taxa de sucesso para cenários OpenClaw atualmente.
Para cenários de alta frequência e sensíveis ao custo, é recomendável usar primeiro o Claude Sonnet 4.6 para estabelecer a linha de base da taxa de sucesso da tarefa,
e depois testar se modelos mais leves podem reduzir significativamente o custo dentro da taxa de sucesso aceitável.
Todos esses testes podem ser realizados através da interface unificada da APIYI apiyi.com, sem a necessidade de registrar contas separadas em vários provedores de serviço.
Análise da Competitividade dos Modelos de Código Aberto
O Nvidia Nemotron-3-Super-120B, com uma taxa de sucesso de 85.6%, ocupa o 4º lugar, apenas 1.3 pontos percentuais abaixo do primeiro colocado — um resultado muito impressionante para um modelo de código aberto.
Vantagens dos modelos de código aberto:
- Soberania dos dados: O modelo e os dados estão em um ambiente controlado, atendendo aos requisitos de conformidade
- Estrutura de custos: Investimento único em GPU, sem custos subsequentes de invocação da API (para cenários de alto volume)
- Espaço para personalização: Pode ser ajustado (Fine-tuning) para tarefas específicas
Limitações dos modelos de código aberto:
- Custo de implantação: Um modelo de 120B parâmetros requer 4-8 GPUs A100/H100
- Carga de manutenção: Atualizações de modelo e gerenciamento de versão exigem operações e manutenção dedicadas
- Custo de teste inicial: Antes de confirmar que um modelo de código aberto é adequado para seu cenário, a validação de protótipos via API comercial é frequentemente mais econômica
V. Guia Prático: Como Configurar o Modelo Ideal no OpenClaw
Integração Rápida do Claude Sonnet 4.6 para Operar o OpenClaw
Abaixo está um exemplo completo de configuração para integrar o modelo número um no ranking PinchBench via APIYI:
Passo 1: Obter a chave API
Acesse o site oficial da APIYI, apiyi.com, registre uma conta e vá para o console para obter sua chave API. A APIYI oferece interfaces compatíveis com OpenAI e também suporta o SDK nativo da Anthropic.
Passo 2: Configurar o backend do modelo do OpenClaw
# Exemplo de arquivo de configuração do OpenClaw (config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # Número máximo de passos de execução
tool_timeout: 30 # Tempo limite para uma única invocação de ferramenta (segundos)
retry_on_error: true # Tentar novamente automaticamente em caso de falha na invocação da ferramenta
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # Operações de alto risco exigem confirmação manual
Passo 3: Verificar o efeito da configuração
# Usar o SDK da Anthropic para testar a conexão
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Enviar uma requisição de teste
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "Por favor, liste 3 tipos de tarefas que você pode executar no OpenClaw"
}]
)
print(response.content[0].text)
Passo 4: Configuração de teste A/B com múltiplos modelos
# Comparar diferentes modelos na mesma tarefa (recomendado antes da implantação oficial)
models_to_test = [
"claude-sonnet-4-6", # PinchBench classificado em primeiro lugar
"gpt-5.4-turbo", # PinchBench classificado em terceiro lugar (compatível com formato OpenAI)
"claude-opus-4-5", # Carro-chefe da geração anterior, para comparação de custos
]
# API
## Perguntas Frequentes
**P: Qual é a principal diferença entre OpenClaw e AutoGPT, AutoGen?**
A principal diferença do OpenClaw reside na **forma de acesso e na barreira de entrada**: ele oferece uma interface de Agente através de aplicativos de mensagens (Signal, WhatsApp, etc.), eliminando a necessidade de usuários comuns instalarem um aplicativo dedicado ou entenderem detalhes técnicos. Do ponto de vista da arquitetura técnica, o OpenClaw é mais parecido com um "secretário pessoal de IA", enquanto frameworks como AutoGen são mais adequados para desenvolvedores construírem sistemas multi-Agente complexos. O OpenClaw enfatiza uma "experiência de consumo pronta para uso", enquanto o AutoGen foca em um "framework de desenvolvimento flexível para empresas".
> 🎯 Independentemente do framework de Agente escolhido, você pode integrar modelos de backend de forma unificada através da APIYI apiyi.com, evitando a necessidade de configurar uma chave API separadamente para cada framework.
**P: Com que frequência o ranking de taxa de sucesso do PinchBench é atualizado?**
O ranking do PinchBench é atualizado em tempo real — sempre que um novo modelo conclui uma avaliação, os dados são imediatamente refletidos em pinchbench.com. Com o lançamento contínuo de novas versões pelos principais fabricantes, o ranking pode mudar frequentemente. Recomenda-se verificar os dados mais recentes antes de fazer uma seleção formal. Os dados deste artigo são baseados em um snapshot de 13 de março de 2026 (49 modelos, 327 registros de execução).
**P: Como escolher o modelo mais adequado para o OpenClaw?**
Recomendamos um método de seleção em três etapas:
1. **Verifique a taxa de sucesso do PinchBench**: Filtre os 5 melhores em taxa de conclusão de tarefas.
2. **Considere a velocidade e o custo**: Filtre novamente com base no tipo da sua tarefa (tempo real vs. processamento em lote, alta frequência vs. baixa frequência).
3. **Teste A/B real**: Compare 2-3 modelos candidatos em suas tarefas de negócios reais.
> Através da APIYI apiyi.com, você pode alternar rapidamente entre diferentes modelos usando a mesma base_url, tomando a decisão final após concluir os testes A/B.
**P: Modelos de código aberto podem substituir completamente os modelos comerciais para impulsionar o OpenClaw?**
Pelos dados do PinchBench, o Nvidia Nemotron-3-Super-120B (85,6%) tem uma diferença de aproximadamente 1,3 pontos percentuais em relação aos modelos comerciais de ponta (86,9%). Para tarefas de Agente comuns, essa diferença pode ser aceitável. No entanto, é importante notar que a implantação de um modelo de 120B parâmetros requer 4-8 GPUs de alto desempenho, o que implica em um investimento inicial significativo em hardware e custos de manutenção. **Recomenda-se primeiro validar a viabilidade do design do Agente com APIs comerciais e, em seguida, avaliar se vale a pena migrar para modelos de código aberto auto-hospedados.**
**P: Como mitigar os riscos de segurança do OpenClaw?**
O princípio central é a **permissão mínima**: conceda ao OpenClaw apenas o escopo mínimo de permissões necessárias para concluir suas tarefas. Sugestões específicas:
- Permissão de leitura apenas para e-mails (em vez de permissões completas de leitura, escrita e exclusão)
- Permissão de leitura e criação de PRs para repositórios de código (em vez de push direto para a branch principal)
- Sistema de arquivos restrito a um diretório de trabalho específico (em vez de todo o sistema de arquivos)
- Operações de alto risco (enviar e-mails, excluir arquivos) devem incluir uma etapa de confirmação manual.
Ao implantar em empresas, também é necessário configurar logs completos de auditoria de operações para garantir que cada ação do Agente tenha um registro rastreável.
**P: Qual é a diferença entre PinchBench e outros benchmarks de Agente?**
A principal característica do PinchBench é a **especificidade do cenário**: ele foi projetado especificamente para os casos de uso do OpenClaw, e não para avaliações gerais de Agentes. Isso significa que ele tem um valor de referência maior para usuários do OpenClaw, mas não é adequado para avaliar diretamente a escolha de modelos para outros frameworks de Agente. Outros benchmarks de Agente conhecidos incluem AgentBench (que cobre vários ambientes), SWE-Bench (focado em tarefas de código), entre outros, cada um com suas próprias ênfases.
---
## Resumo: OpenClaw + PinchBench estabelecem um novo padrão para a era dos Agentes
O OpenClaw, que começou como um projeto de fim de semana de um desenvolvedor austríaco, cresceu em dois meses para se tornar a plataforma de Agentes de IA mais popular do mundo, refletindo o forte desejo de toda a indústria por "IA que realmente faz as coisas".
O surgimento do PinchBench preenche uma lacuna crucial na área de avaliação de Agentes: **finalmente temos uma régua para medir especificamente a capacidade dos Agentes**.
**Principais conclusões em resumo**:
- **Claude Sonnet 4.6 é a melhor escolha geral para o cenário OpenClaw atualmente** (86,9% de taxa de sucesso, primeiro lugar no PinchBench)
- **A taxa de sucesso dos modelos de ponta concentra-se entre 85-87%**, as tarefas de Agente ainda são desafiadoras, e o design tolerante a falhas é indispensável.
- **Velocidade e custo são igualmente importantes**, modelos com alta taxa de sucesso podem não ser adequados para todos os cenários, exigindo uma avaliação tridimensional abrangente.
- **PinchBench representa a direção futura da avaliação de IA**: tarefas de cenário real estão substituindo testes sintéticos.
- **A diferença na escolha do modelo é de cerca de 1-2%**, o design da tarefa e a engenharia de comandos geralmente têm um impacto maior.
Para desenvolvedores e empresas que desejam se aprofundar no ecossistema OpenClaw, agora é um excelente momento:
A comunidade de código aberto é ativa, as ferramentas de avaliação são completas e os custos de acesso à API dos modelos mainstream estão em constante declínio. Você não precisa esperar pela "solução perfeita"; pode começar agora a validar a viabilidade do fluxo de trabalho do Agente com tarefas em pequena escala.
> 🎯 **Aja agora**: Se você está construindo um fluxo de trabalho de IA baseado no OpenClaw, recomendamos a integração unificada através da APIYI apiyi.com.
> A plataforma suporta modelos mainstream como Claude Sonnet 4.6 (primeiro no PinchBench) e GPT-5.4 (terceiro),
> com o mesmo conjunto de interfaces API, sem a necessidade de registrar-se separadamente em vários provedores, e suporta faturamento por uso, ideal para começar com testes em pequena escala e expandir gradualmente.
> Visite o site oficial da APIYI apiyi.com para se registrar e começar a experimentar.
---
*Os dados deste artigo são baseados em informações públicas compiladas em março de 2026. Para dados em tempo real do ranking PinchBench, visite pinchbench.com para a versão mais recente.*
*Autor: Equipe APIYI | Para mais informações sobre a integração de API de modelos de IA, visite apiyi.com.*