Author's Note: Based on 6 core benchmarks, including SWE-bench Pro, Terminal-Bench 2.0, and LiveCodeBench, this article provides a deep comparison of the programming capabilities of GPT-5.5 and Claude Opus 4.7 in real-world scenarios, along with clear selection recommendations.
The battle for programming dominance between GPT-5.5 and Claude Opus 4.7 is the most discussed topic in the AI development space as of April 2026. This article compares OpenAI GPT-5.5 (codename: Spud) and Anthropic Claude Opus 4.7, offering definitive selection advice based on dimensions such as SWE-bench Pro performance, Terminal-Bench 2.0 scores, long-context retrieval, token efficiency, and API pricing.
This is not a "balanced" analysis where both models seem equally good. We will use official benchmark data to provide specific recommendations tailored to different use cases. Anthropic released Claude Opus 4.7 on April 16, 2026, and OpenAI followed just seven days later on April 23 with GPT-5.5. The showdown between these two top-tier models has officially begun.
Core Value: After reading this, you’ll know exactly whether to choose GPT-5.5 or Claude Opus 4.7 for four typical scenarios: GitHub issue resolution, Agentic programming, long-context refactoring, and interactive coding.

A Quick Look at Core Differences Between GPT-5.5 and Claude Opus 4.7
The core positioning of these two models differs, leading to distinct strengths in programming. The table below summarizes their key differences in coding-related dimensions:
| Dimension | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Release Date | 2026-04-23 | 2026-04-16 |
| Codename | Spud | – |
| Context Window | 1M tokens | 1M tokens |
| Max Output | 128K tokens | 128K tokens |
| Core Strengths | Agentic programming, long-context retrieval | Real GitHub issue resolution, architectural reasoning |
| Typical TTFT | ~3 seconds | ~0.5 seconds |
| Token Efficiency | 72% fewer output tokens than Opus | Higher consumption, but high precision |
| API Input | $5/M tokens | $5/M tokens |
| API Output | $30/M tokens | $25/M tokens |
| Large Prompt Surcharge | No extra charge >200K | Doubled to $10/$37.50 >200K |
GPT-5.5 Programming Positioning
GPT-5.5 is currently OpenAI's most capable Agentic programming model. It excels in terminal workflows, long-context retrieval, and cross-tool coordination, making it particularly suitable for multi-step automated programming processes that require frequent tool calls. OpenAI positions it as the first choice for "long-range programming tasks," having demonstrated the ability to handle tasks equivalent to 20 hours of human work in internal Expert-SWE benchmarks.
Claude Opus 4.7 Programming Positioning
Claude Opus 4.7 has reclaimed the throne in real-world software engineering tasks. It reaches 87.6% on SWE-bench Verified and 64.3% on SWE-bench Pro, significantly leading all existing competitors. Anthropic's internal tests on the Rakuten-SWE-Bench show that Opus 4.7 solves three times as many production tasks as Opus 4.6, making it especially effective for fixing GitHub issues and refactoring large codebases that require deep architectural reasoning.
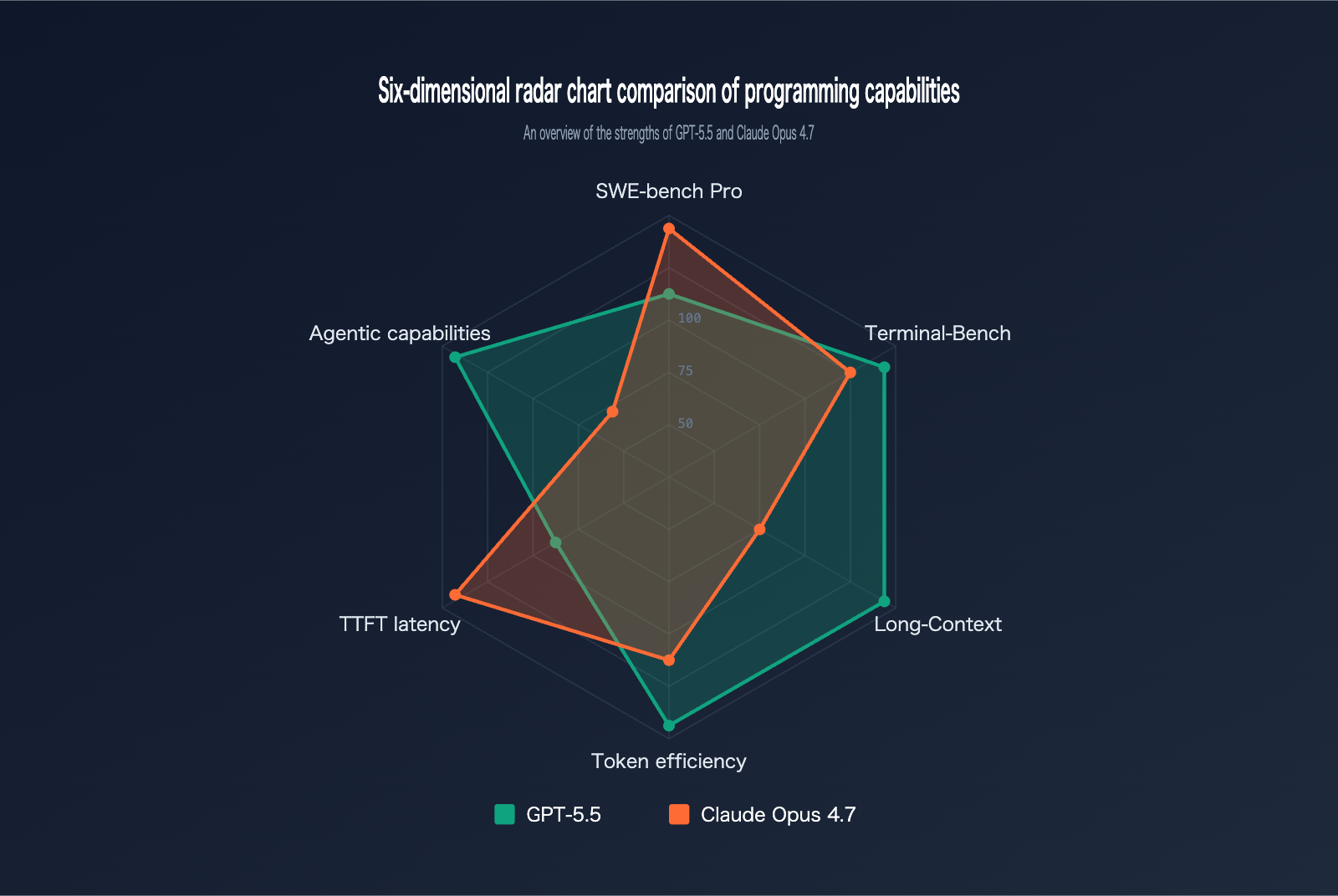
GPT-5.5 vs. Claude Opus 4.7 Benchmark Comparison
Benchmarks are the most objective yardstick for gauging programming capability. We’ve aggregated official data for both models across six mainstream programming benchmarks:
| Benchmark | Scope | GPT-5.5 | Claude Opus 4.7 | Winner |
|---|---|---|---|---|
| SWE-bench Verified | Verified GitHub issue fixes | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | Complex multi-file issue fixes | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | Terminal command workflows | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | Long-range programming (median 20 hrs) | 73.1% | – | GPT-5.5 |
| OSWorld-Verified | Desktop Agent tasks | 78.7% | 78.0% | GPT-5.5 (narrow) |
| MRCR v2 (512K-1M) | Long context 8-needle retrieval | 74.0% | 32.2% | GPT-5.5 |
SWE-bench Pro Hands-on Analysis
SWE-bench Pro is the gold standard for evaluating a model's ability to fix real-world GitHub issues. Claude Opus 4.7 leads GPT-5.5 with 64.3% versus 58.6%, which means for every 100 real-world codebase bug fixes, Opus 4.7 resolves approximately 6 more than its competitor.
More importantly, Opus 4.7 shows a massive 10.9 percentage point improvement over its predecessor, Opus 4.6 (53.4%)—a rare and significant jump for a single version iteration. For teams whose primary workflow revolves around fixing GitHub issues, Claude Opus 4.7 is currently the top choice.
Testing Tip: Want to verify how these two models perform on your own codebase? You can run parallel tests via the APIYI platform (apiyi.com), which supports unified model invocation for both GPT-5.5 and Claude Opus 4.7, making side-by-side comparisons quick and easy.
Terminal-Bench 2.0 Hands-on Analysis
Terminal-Bench 2.0 tests a model's ability to complete complex tasks in a terminal environment, covering planning, iteration, and tool coordination. GPT-5.5 leads significantly with 82.7% compared to Opus 4.7’s 69.4%—a notable 13 percentage point gap.
This difference stems from optimizations in GPT-5.5’s Agentic workflows: it excels at precise tool selection, handles multi-step tasks more consistently, and recovers from errors more reliably. If your workflow involves heavy use of shell commands, file operations, or CI/CD integration, GPT-5.5 is the more robust option.
Long Context Retrieval Gaps
In the MRCR v2 512K-1M token range 8-needle retrieval test, GPT-5.5 leads with 74.0% over Opus 4.7's 32.2%—a chasm of 41.8 percentage points.
This means if you need the model to "understand" an entire codebase (500K+ tokens), GPT-5.5 provides significantly higher precision in recalling deep context. For scenarios like "refactoring based on a complete monorepo," the difference isn't just about performance—it's often the difference between success and failure.
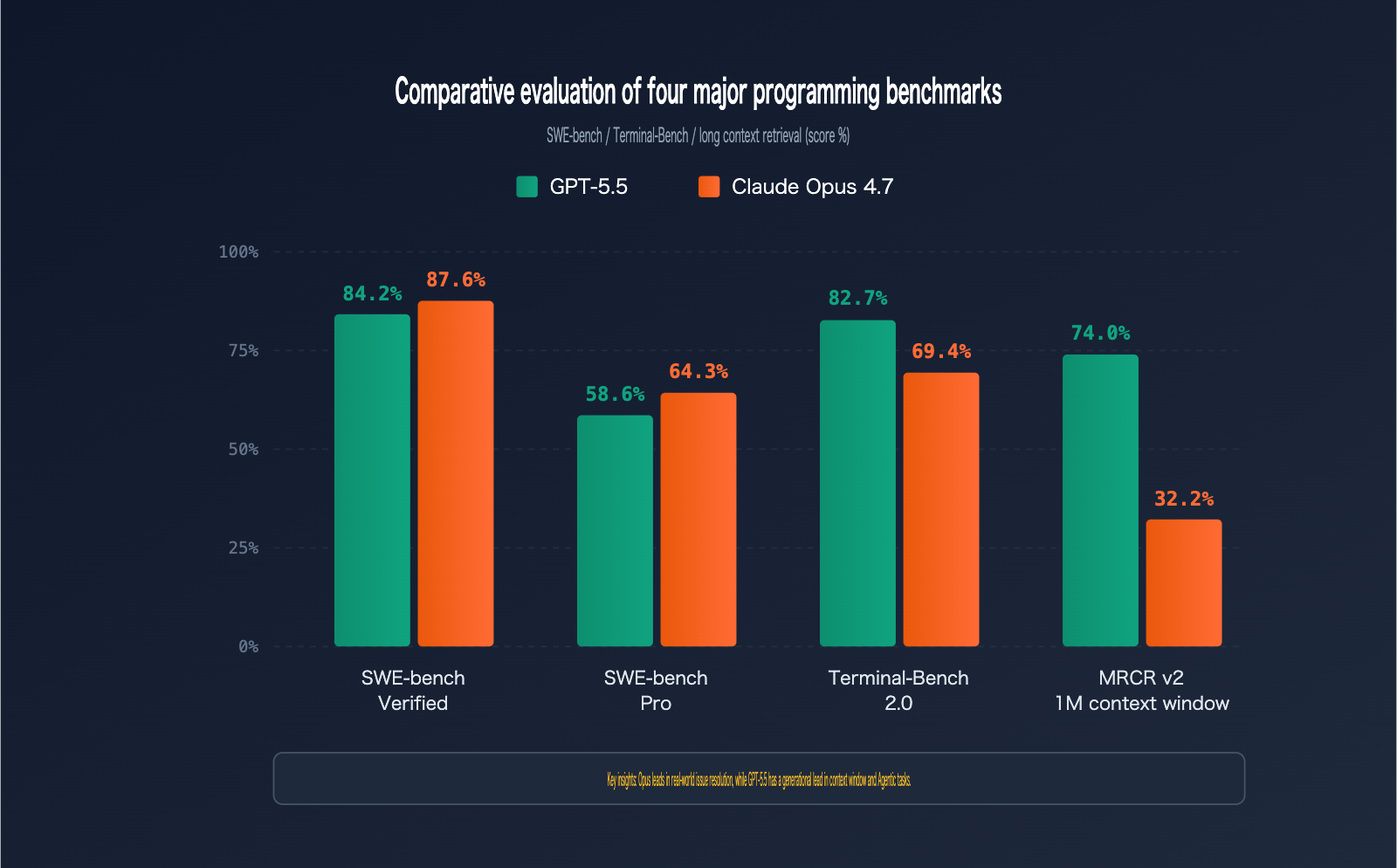
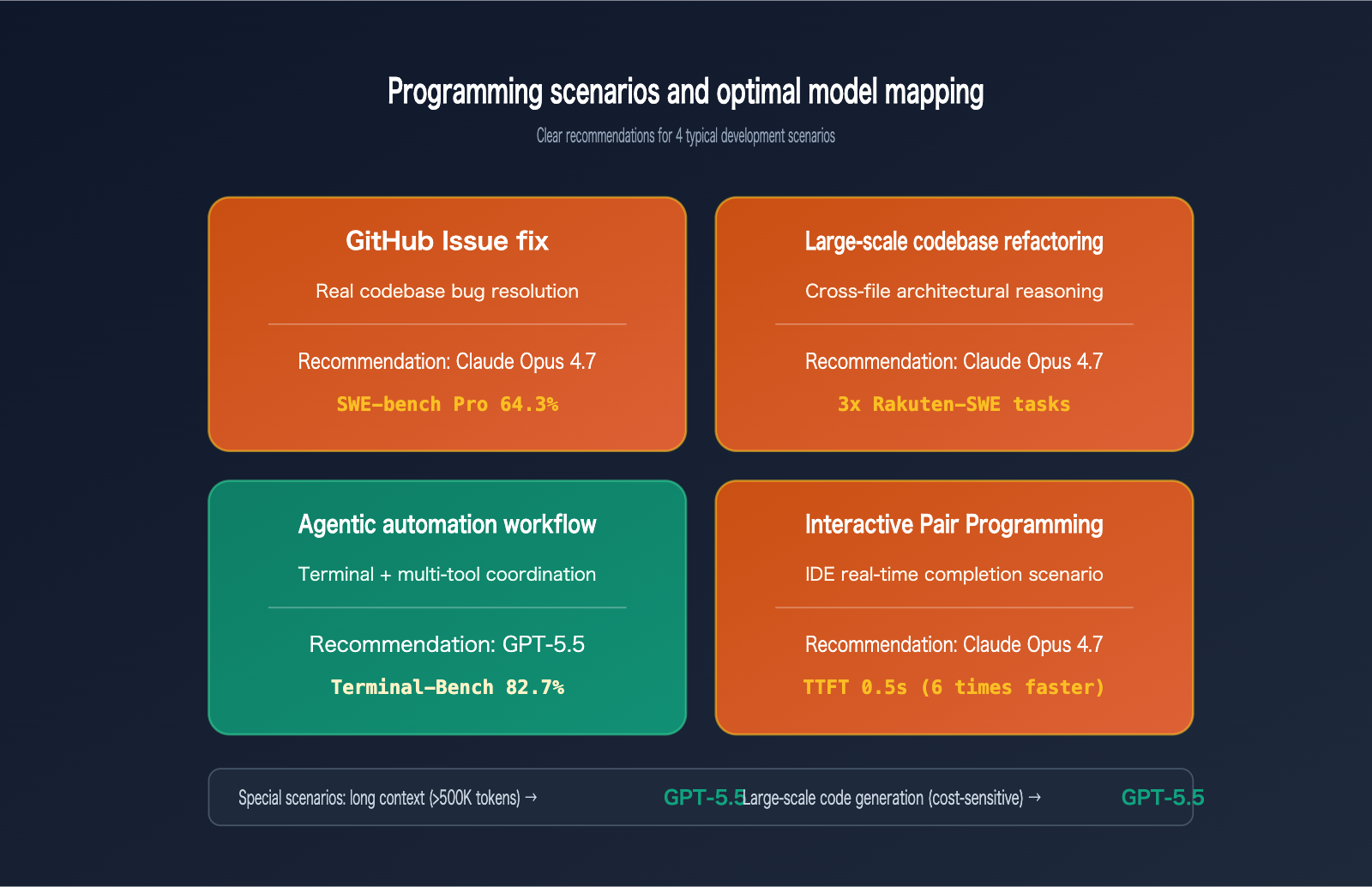
Practical Recommendations for GPT-5.5 vs. Claude Opus 4.7 in Programming Scenarios
Benchmark data only becomes meaningful when applied to specific real-world scenarios. The table below provides clear recommendations across five typical programming scenarios:
| Programming Scenario | Recommended Model | Core Reasoning | Expected Benefit |
|---|---|---|---|
| GitHub Issue Resolution | Claude Opus 4.7 | 5.7% lead on SWE-bench Pro | 10% increase in fix success rate |
| Large Codebase Refactoring | Claude Opus 4.7 | Superior cross-file architectural reasoning | Reduced risk of architectural breakage |
| Agentic Automation Workflows | GPT-5.5 | 13.3% lead on Terminal-Bench | Higher stability in multi-step tasks |
| Long Context (>500K) Understanding | GPT-5.5 | 41.8% lead on MRCR v2 | Reliable deep-context retrieval |
| Interactive Pair Programming | Claude Opus 4.7 | 0.5s TTFT, faster response | Smoother coding rhythm |
| High-Volume Code Generation | GPT-5.5 | 72% higher token efficiency | Better overall cost-effectiveness |
Scenario 1: Resolving Real GitHub Issues → Choose Claude Opus 4.7
If your primary goal is to "take an issue description and have the AI provide a mergeable PR," Claude Opus 4.7 is the undisputed winner. Its 87.6% score on SWE-bench Verified means that approximately nine out of ten well-defined bug-fix tasks can be delivered directly.
Keep in mind that 87.6% doesn't mean 87.6% of your engineering work can be fully automated—this is an ideal test based on "perfect task specifications." In real-world workflows, the quality of your issue descriptions will significantly impact the success rate.
Scenario 2: Long Context Code Understanding → Choose GPT-5.5
When you need a model to read an entire monorepo (typically 500K-1M tokens) before making a decision, GPT-5.5 is currently the only reliable choice. Opus 4.7 has an 8-needle retrieval accuracy of only 32.2% within the 1M context range, meaning the model is likely to "miss" critical definitions buried deep in the codebase.
This gap is architectural—if your workflow relies on a complete view of the codebase (e.g., global renaming, API compatibility checks), using Opus 4.7 might cause the process to fail entirely.
Scenario 3: Agentic Programming Workflows → Choose GPT-5.5
Agentic programming refers to workflows where the AI autonomously plans, calls tools, and iterates through corrections. GPT-5.5's score of 82.7% on Terminal-Bench 2.0 far exceeds Opus 4.7, showing particular stability in:
- Writing and executing automated deployment scripts
- Multi-service debugging and log analysis
- Troubleshooting CI/CD pipelines
- Building and monitoring data pipelines
Integration Tip: When building Agentic programming workflows, it's recommended to use an aggregation platform like APIYI (apiyi.com) to invoke GPT-5.5. This makes it easier to manage API keys, monitor invocation costs, and switch to backup models on demand.
Scenario 4: Interactive Pair Programming → Choose Claude Opus 4.7
Interactive coding experiences are extremely sensitive to latency. Opus 4.7 has a TTFT (Time to First Token) of about 0.5 seconds, while GPT-5.5 is around 3 seconds. That 6x gap is very noticeable during frequent interactions.
If you use IDE tools like Cursor, Claude Code, or Continue for frequent small snippets of code completion, the low latency of Opus 4.7 will result in a much smoother coding flow.
GPT-5.5 and Claude Opus 4.7 API Invocation Examples
Below are minimalist invocation examples for both models to help you verify them quickly. Both are compatible with the OpenAI SDK format, making migration a breeze.
GPT-5.5 Minimalist Invocation
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Implement quicksort in Python"}]
)
print(response.choices[0].message.content)
Claude Opus 4.7 Minimalist Invocation
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Implement quicksort in Python"}]
)
print(response.choices[0].message.content)
View Parallel Benchmark Test Code for Both Models
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Test a model's response time and output length"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Programming capability benchmark test
test_prompt = """
Please implement an LRU cache class in Python that:
1. Supports get(key) and put(key, value) methods.
2. Automatically evicts the least recently used item when at capacity.
3. Has O(1) time complexity for all operations.
4. Includes complete unit tests.
"""
# Test both models in parallel
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
Testing Tip: Use APIYI (apiyi.com) to get free test credits. You can benchmark GPT-5.5 and Claude Opus 4.7 in parallel under a single account using a unified
base_urland API key, saving you the hassle of applying for separate OpenAI and Anthropic accounts.
Comprehensive Cost Analysis: GPT-5.5 vs. Claude Opus 4.7
API pricing is a hard metric you can't ignore when choosing a model. On the surface, Opus 4.7 output tokens are 17% cheaper, but the reality shifts when you dig deeper into the data:
| Cost Dimension | GPT-5.5 | Claude Opus 4.7 | Actual Impact |
|---|---|---|---|
| Input Pricing | $5/M tokens | $5/M tokens | Parity |
| Output Pricing | $30/M tokens | $25/M tokens | Opus is 17% cheaper |
| >200K Prompt | Same price | Doubled to $10/$37.50 | GPT has a big lead in long context |
| Output Tokens per Task | 100% baseline | 72% more than GPT | GPT is cheaper overall |
| TTFT Latency | ~3s | ~0.5s | Opus has better feel |
| Cost for Bulk Tasks | 1.0x baseline | 1.4-1.5x baseline | GPT is more cost-effective |
Key Findings in Cost Comparison
Token efficiency changes the nature of the price comparison. For identical programming tasks, GPT-5.5 consumes 72% fewer output tokens on average than Opus 4.7. Even though Opus has a 17% lower unit price, once you factor in that 1.72x multiplier in token usage, GPT-5.5 actually ends up being the cheaper option per task.
The gap widens in long-context scenarios. When the prompt exceeds 200K tokens, the input and output prices for Opus 4.7 double to $10 and $37.50, respectively, whereas GPT-5.5 pricing remains unchanged. For workflows requiring extensive context (like analyzing an entire monorepo), GPT-5.5 can be 2-3 times more cost-effective.
Comparison Takeaways
Claude Opus 4.7 cost profile: Its per-token price is very competitive among top-tier models. However, in high-volume generation scenarios, its higher token consumption drives up the total cost; additionally, the doubling of costs for >200K contexts adds significant budget pressure.
GPT-5.5 cost profile: While the per-token price is slightly higher, its superior token efficiency and "no-penalty" long-context policy make it more cost-effective for large-scale, long-context tasks. OpenAI clearly designed their pricing model with agentic workflows in mind.
Cost Estimation Advice: Actual project costs depend on many factors, including prompt length, output length, and call frequency. We recommend integrating both models via the APIYI (apiyi.com) platform, which provides granular usage billing to help you make decisions based on real, accurate data.
FAQ
Q1: Which is better at programming, GPT-5.5 or Claude Opus 4.7?
There's no single "winner"—it really depends on the task. Claude Opus 4.7 leads on benchmarks like SWE-bench Pro (64.3% vs 58.6%) and Verified (87.6%), making it the go-to for fixing real-world GitHub issues and large-scale codebase refactoring. On the other hand, GPT-5.5 takes the lead in Terminal-Bench 2.0 (82.7% vs 69.4%) and long-context retrieval (74.0% vs 32.2%), which makes it the better choice for Agentic programming workflows and understanding code across an entire monorepo.
Q2: How do the API pricing models for GPT-5.5 and Claude Opus 4.7 compare?
Both models charge $5/M for input tokens. When it comes to output tokens, Opus 4.7 ($25/M) is 17% cheaper than GPT-5.5 ($30/M). However, keep in mind that Opus 4.7 doubles its price once your prompt exceeds 200K tokens, while GPT-5.5 maintains its base rate. Plus, since GPT-5.5 consumes 72% fewer output tokens, it often works out to be the more cost-effective option for high-volume tasks.
Q3: When were GPT-5.5 and Claude Opus 4.7 released?
Claude Opus 4.7 was launched by Anthropic on April 16, 2026, and is widely available via the Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. GPT-5.5 (codenamed Spud) was released by OpenAI just seven days later, on April 23, 2026, marking a fierce competition between these two top-tier coding models.
Q4: When should I choose Claude Opus 4.7 for programming tasks?
You should prioritize Opus 4.7 for these scenarios:
- Fixing GitHub issues: It outperforms in this area with a 5.7 percentage point lead on SWE-bench Pro.
- Large codebase refactoring: It offers superior reasoning capabilities across multiple files.
- Interactive Pair Programming: With a TTFT of just 0.5 seconds, it's 6 times more responsive.
- Code quality reviews: It has achieved higher scores in real-world Rakuten-SWE-Bench tests.
Q5: How can I quickly call GPT-5.5 and Claude Opus 4.7 via API?
We recommend using an API proxy service that supports both models for testing:
- Sign up for an account at APIYI (apiyi.com).
- Obtain your unified API key and free testing credits.
- Use the sample code provided in this article (simply replace the
base_urlwithhttps://vip.apiyi.com/v1) and set the model togpt-5.5orclaude-opus-4-7to get started.
APIYI offers a unified interface for major models like OpenAI, Anthropic, and Google, allowing you to compare the performance of GPT-5.5 and Claude Opus 4.7 without the hassle of managing multiple accounts.
Q6: What are the known limitations of GPT-5.5 and Claude Opus 4.7?
GPT-5.5 Limitations:
- TTFT latency is around 3 seconds, which can feel slow for interactive tasks.
- Slightly behind Opus 4.7 in fixing real-world GitHub issues (SWE-bench).
Claude Opus 4.7 Limitations:
- Struggles with long-context retrieval (32.2% accuracy in the 1M range).
- Price doubles when prompts exceed 200K tokens, leading to high costs for long-context tasks.
- Higher output token consumption makes it more expensive for bulk tasks.
- Performance on Agentic tasks (like Terminal-Bench) falls short of GPT-5.5.
Q7: Does it make sense to use both GPT-5.5 and Claude Opus 4.7?
For professional development teams, using both is highly recommended. A typical strategy is to use Opus 4.7 for fixing GitHub issues, code reviews, and critical architectural decisions, while utilizing GPT-5.5 for long-context analysis, Agentic automation flows, and large-scale code generation. This hybrid approach lets you leverage the unique strengths of each model while balancing costs and user experience.
Key Takeaways
- For fixing real-world issues, choose Opus: Claude Opus 4.7 leads in both SWE-bench Pro and Verified benchmarks, making it the top choice for GitHub issue resolution.
- For Agentic programming, choose GPT: GPT-5.5 holds a 13 percentage point lead on Terminal-Bench 2.0, providing more stable multi-step tool invocation.
- For long context, choose GPT: In MRCR v2 tests, GPT-5.5 (74%) significantly outperforms Opus (32.2%), making it the only reliable choice for 1M context windows.
- For latency-sensitive tasks, choose Opus: Opus has a TTFT of just 0.5s—6 times faster than GPT—offering a much smoother coding experience.
- For cost-efficiency, choose GPT: GPT-5.5 uses 72% fewer output tokens, resulting in lower costs for high-volume tasks.
- Fast parallel testing: You can unify model invocation for both models using a single account at APIYI (apiyi.com) to compare them in real-world scenarios.
Summary
Here are the key takeaways from the comparison between GPT-5.5 and Claude Opus 4.7 in terms of programming capabilities:
- No universal champion: Both models have clear areas of expertise. Blindly searching for "the best model" is the wrong approach.
- Task-driven selection: First, identify your core programming scenario (issue resolution, Agentic workflows, large context windows, or interactive coding), then decide on your primary model.
- Dual-model strategy: Professional development teams should integrate both models, routing tasks to the optimal model based on the scenario to maximize productivity.
If you can only pick one: choose Claude Opus 4.7 for daily GitHub issue resolution and code reviews; choose GPT-5.5 for Agentic automation and long-context analysis.
We recommend using APIYI (apiyi.com) to quickly validate your choice. The platform offers a unified interface for both GPT-5.5 and Claude Opus 4.7, provides free testing credits, and offers granular billing, making it the most convenient path to data-driven decision-making.
Related Articles
If you're interested in the programming comparison between GPT-5.5 and Claude Opus 4.7, we recommend checking out:
- 📘 Claude Opus 4.7 Full Evaluation: The Engineering Prowess Behind 87.6% on SWE-bench – An in-depth look at what makes Opus 4.7 tick.
- 📊 GPT-5.5 Spud Practical Guide: 8 Tips for the New King of Agentic Programming – Master the advanced features of GPT-5.5.
- 🚀 AI Programming Model Selection Guide 2026: A Panoramic Comparison from GPT to Claude – Explore a more holistic methodology for model selection.
📚 References
-
Official OpenAI GPT-5.5 Introduction: Core benchmarks and capability overview
- Link:
openai.com/index/introducing-gpt-5-5 - Description: Official release documentation for GPT-5.5, including key benchmarks like SWE-bench and Terminal-Bench.
- Link:
-
Official Anthropic Claude Opus 4.7 Release Notes: Model positioning and performance data
- Link:
anthropic.com/news/claude-opus-4-7 - Description: Official release documentation for Opus 4.7, featuring detailed data on SWE-bench Verified/Pro.
- Link:
-
SWE-Bench Pro Public Leaderboard: Independent third-party verification
- Link:
labs.scale.com/leaderboard/swe_bench_pro_public - Description: The SWE-Bench Pro leaderboard maintained by Scale AI, where you can verify the real-world rankings of both models.
- Link:
-
Vellum LLM Leaderboard 2026: Comprehensive AI model comparison
- Link:
vellum.ai/llm-leaderboard - Description: A comprehensive platform covering multidimensional comparisons including coding, reasoning, long context windows, and more.
- Link:
-
Artificial Analysis Model Comparison: Performance and cost analysis
- Link:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Description: Provides fine-grained comparison data on TTFT, throughput, and overall costs.
- Link:
Author: APIYI Technical Team
Technical Discussion: We'd love to hear your thoughts in the comments section! For more resources, feel free to visit the APIYI documentation center at docs.apiyi.com.