ملاحظة المؤلف: استنادًا إلى 6 معايير اختبار أساسية مثل SWE-bench Pro وTerminal-Bench 2.0 وLiveCodeBench، نقدم مقارنة متعمقة للفوارق في القدرات البرمجية الواقعية بين GPT-5.5 وClaude Opus 4.7، مع توصيات اختيار محددة.
تعد معركة القدرات البرمجية بين GPT-5.5 وClaude Opus 4.7 الموضوع الأكثر إثارة للاهتمام في مجال برمجة الذكاء الاصطناعي في أبريل 2026. تقارن هذه المقالة بين OpenAI GPT-5.5 (الاسم الرمزي Spud) وAnthropic Claude Opus 4.7، وتقدم توصيات اختيار واضحة من عدة أبعاد: SWE-bench Pro، وTerminal-Bench 2.0، واسترجاع السياق الطويل، وكفاءة الـ Token، وتسعير الـ API.
هذه ليست "تحليلاً توفيقياً" يظهر أن كلاً منهما له مزاياه، بل سنعتمد على بيانات الاختبار القياسية (Benchmark) المعلنة رسمياً لنقدم توصيات مباشرة ومحددة لكل سيناريو. أطلقت Anthropic نموذج Claude Opus 4.7 في 16 أبريل 2026، وتبعتها OpenAI بإطلاق GPT-5.5 في 23 أبريل، حيث ظهر عملاقان في غضون 7 أيام فقط، مما أشعل فتيل المواجهة في القدرات البرمجية.
القيمة الأساسية: بعد قراءة هذه المقالة، ستعرف بوضوح متى تختار GPT-5.5 ومتى تختار Claude Opus 4.7 في 4 سيناريوهات نموذجية: إصلاح مشكلات GitHub، والبرمجة بالوكلاء (Agentic)، وإعادة هيكلة السياق الطويل، والبرمجة التفاعلية.

نظرة سريعة على الفروقات الجوهرية بين GPT-5.5 و Claude Opus 4.7
يختلف التوجه الأساسي لكل نموذج، مما يجعل نقاط قوتهما البرمجية مختلفة تماماً. يوضح الجدول التالي الاختلافات الرئيسية بينهما في الأبعاد المتعلقة بالبرمجة:
| بُعد المقارنة | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| تاريخ الإصدار | 2026-04-23 | 2026-04-16 |
| الاسم الرمزي | Spud | – |
| نافذة السياق | 1M tokens | 1M tokens |
| الحد الأقصى للإخراج | 128K tokens | 128K tokens |
| نقاط القوة الأساسية | برمجة الوكلاء (Agentic)، استرجاع السياق الطويل | إصلاح مشاكل GitHub الفعلية، الاستدلال المعماري |
| زمن الاستجابة (TTFT) | ~3 ثوانٍ | ~0.5 ثانية |
| كفاءة التوكن | مخرجات توكن أقل بـ 72% من Opus | استهلاك أعلى للتوكن، لكن بدقة عالية |
| مدخلات API | $5/M tokens | $5/M tokens |
| مخرجات API | $30/M tokens | $25/M tokens |
| زيادة سعر الموجه الطويل | >200K يبقى السعر ثابتاً | >200K يتضاعف إلى $10/$37.50 |
تموضع القدرات البرمجية لـ GPT-5.5
يعد GPT-5.5 أقوى نموذج برمجة يعتمد على الوكلاء (Agentic) من OpenAI حتى الآن. فهو يتفوق في سير عمل الطرفية (Terminal)، استرجاع السياق الطويل، والتنسيق عبر الأدوات، مما يجعله مثالياً لسير عمل الأتمتة البرمجية متعددة الخطوات التي تتطلب استدعاء الأدوات. تضعه OpenAI كخيار أول "للمهام البرمجية طويلة المدى"، وقد أظهر قدرة على معالجة مهام تعادل 20 ساعة من العمل البشري في اختبارات Expert-SWE.
تموضع القدرات البرمجية لـ Claude Opus 4.7
استعاد Claude Opus 4.7 الصدارة في مهام هندسة البرمجيات الواقعية، حيث حقق 87.6% في اختبار SWE-bench Verified و64.3% في SWE-bench Pro، متفوقاً بشكل ملحوظ على جميع المنافسين. تظهر اختبارات Anthropic العملية على Rakuten-SWE-Bench أن Opus 4.7 حل مهام إنتاجية أكثر بـ 3 مرات من سابقه (Opus 4.6)، وهو مناسب بشكل خاص لإصلاح مشاكل GitHub وإعادة هيكلة مستودعات الأكواد الكبيرة التي تتطلب استدلالاً معمارياً.
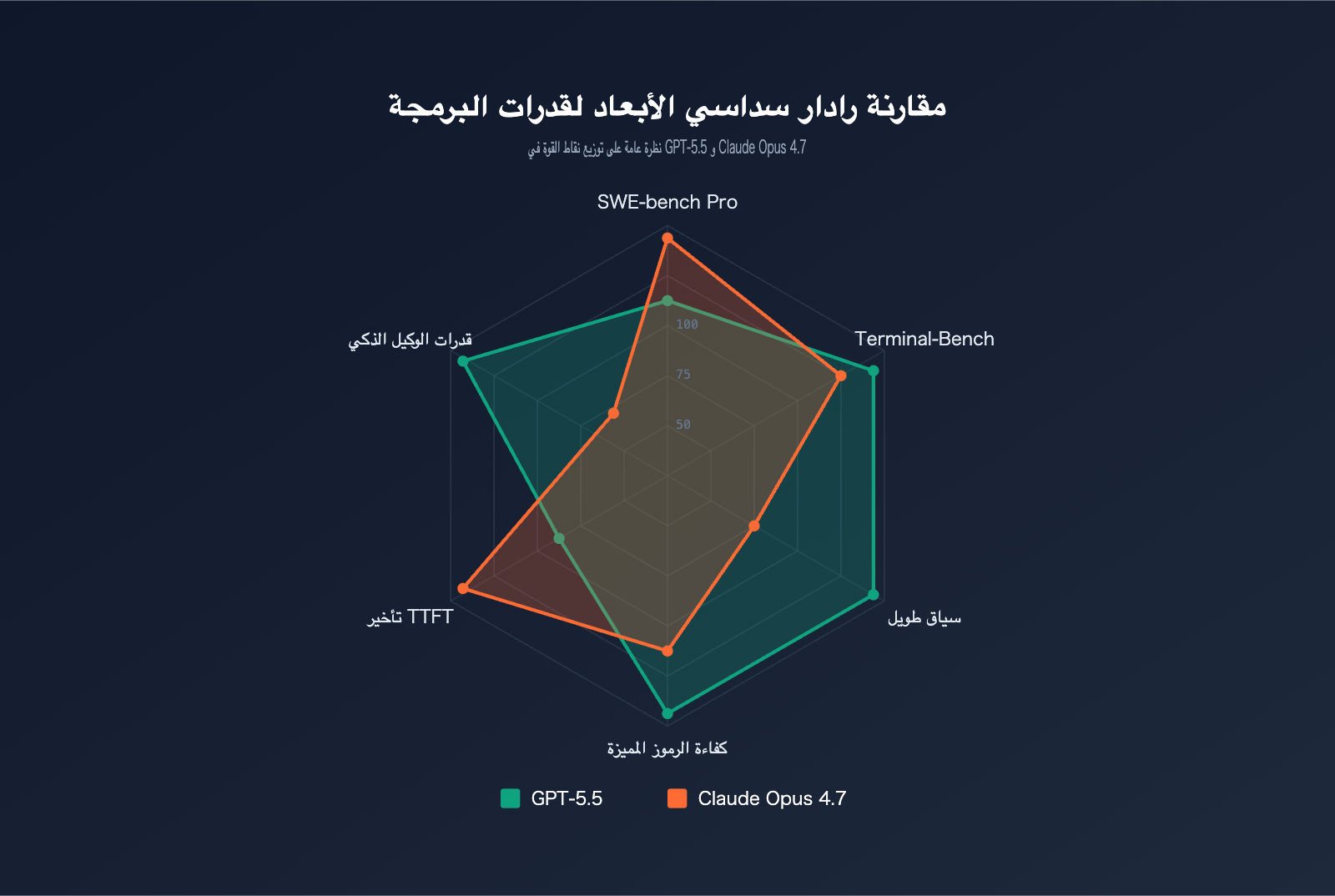
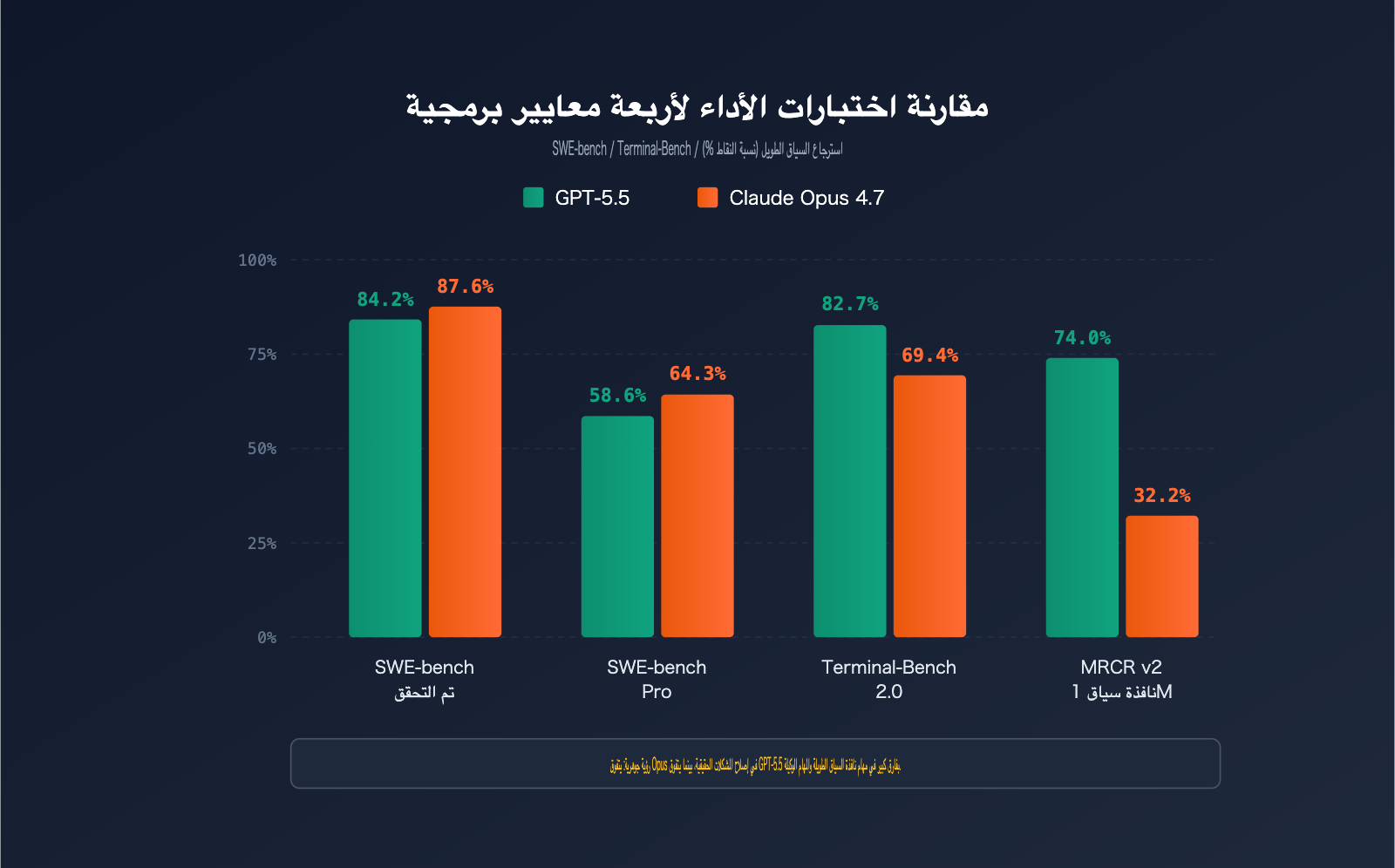
مقارنة النتائج العملية (Benchmark) بين GPT-5.5 و Claude Opus 4.7
تعتبر اختبارات الأداء (Benchmark) المقياس الأكثر موضوعية للحكم على القدرات البرمجية. قمنا بجمع البيانات الرسمية لكلا النموذجين عبر 6 اختبارات رئيسية:
| اختبار الأداء | محتوى الاختبار | GPT-5.5 | Claude Opus 4.7 | الفائز |
|---|---|---|---|---|
| SWE-bench Verified | إصلاح مشاكل GitHub الموثقة | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | إصلاح المشاكل المعقدة في ملفات متعددة | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | سير عمل أوامر الطرفية | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | البرمجة طويلة المدى (20 ساعة) | 73.1% | – | GPT-5.5 |
| OSWorld-Verified | مهام وكيل سطح المكتب | 78.7% | 78.0% | GPT-5.5 (بفارق بسيط) |
| MRCR v2 (512K-1M) | استرجاع السياق الطويل 8-needle | 74.0% | 32.2% | GPT-5.5 |
تحليل أداء SWE-bench Pro
يعد SWE-bench Pro المعيار الذهبي لتقييم قدرة النموذج على إصلاح مشاكل GitHub الحقيقية. يتفوق Claude Opus 4.7 بـ 64.3% مقابل 58.6% لـ GPT-5.5، مما يعني أنه في كل 100 مهمة لإصلاح الأخطاء، يمكن لـ Opus 4.7 حل حوالي 6 مهام إضافية. والأهم من ذلك، أن Opus 4.7 حقق قفزة كبيرة بنسبة 10.9 نقطة مئوية مقارنة بالجيل السابق (53.4%)، مما يجعله الخيار الأمثل للفرق التي تركز على إصلاح الأخطاء البرمجية.
اقتراح للاختبار: هل ترغب في التحقق من الفرق في الأداء بين النموذجين على مستودع الأكواد الخاص بك؟ يمكنك إجراء اختبار متوازٍ عبر منصة APIYI (apiyi.com)، حيث تدعم المنصة الاستدعاء الموحد لواجهات برمجة التطبيقات لكل من GPT-5.5 و Claude Opus 4.7، مما يسهل عملية المقارنة السريعة.
تحليل أداء Terminal-Bench 2.0
يختبر هذا المعيار قدرة النموذج على إكمال المهام المعقدة في بيئة الطرفية (Terminal). يتفوق GPT-5.5 بفارق كبير بنسبة 82.7% مقابل 69.4% لـ Opus 4.7. يعود هذا الفارق إلى التحسينات في سير عمل الوكلاء (Agentic) لدى GPT-5.5، مما يجعله أكثر دقة في اختيار الأدوات والتعافي من الأخطاء، وهو الخيار الأنسب إذا كان عملك يتضمن الكثير من أوامر shell والتعامل مع الملفات.
فجوة القدرة على استرجاع السياق الطويل
في اختبار MRCR v2 (استرجاع 8-needle ضمن نطاق 512K-1M توكن)، يتفوق GPT-5.5 بنسبة 74.0% مقابل 32.2% لـ Opus 4.7، وهي فجوة شاسعة. هذا يعني أنه إذا كنت بحاجة إلى أن يفهم النموذج كامل مستودع الأكواد (500K+ tokens)، فإن دقة GPT-5.5 في استرجاع المعلومات من العمق تتفوق بشكل ملحوظ. بالنسبة لمهام مثل "إعادة الهيكلة بناءً على مستودع أكواد كامل"، فإن GPT-5.5 ليس مجرد خيار أفضل، بل هو الخيار الأكثر فاعلية.
توصيات عملية لاستخدام GPT-5.5 و Claude Opus 4.7 في سيناريوهات البرمجة
لا تكتسب بيانات المقارنة (Benchmark) أهميتها إلا عند تطبيقها على سيناريوهات واقعية. يوضح الجدول التالي توصيات محددة لـ 5 سيناريوهات برمجية نموذجية:
| سيناريو البرمجة | النموذج الموصى به | السبب الجوهري | العائد المتوقع |
|---|---|---|---|
| إصلاح مشكلات GitHub | Claude Opus 4.7 | تفوق في SWE-bench Pro بنسبة 5.7% | زيادة 10% في نجاح الإصلاحات |
| إعادة هيكلة كود ضخم | Claude Opus 4.7 | قدرة أقوى على الاستدلال بين الملفات | تقليل مخاطر انهيار البنية |
| سير عمل الأتمتة (Agentic) | GPT-5.5 | تفوق في Terminal-Bench بنسبة 13.3% | استقرار أعلى في المهام المتعددة |
| فهم السياق الطويل (>500K) | GPT-5.5 | تفوق في MRCR v2 بنسبة 41.8% | استرجاع سياقي موثوق وعميق |
| البرمجة الزوجية التفاعلية | Claude Opus 4.7 | زمن استجابة (TTFT) يبلغ 0.5 ثانية فقط | إيقاع برمجي أكثر سلاسة |
| توليد كميات كبيرة من الكود | GPT-5.5 | كفاءة Tokens أعلى بنسبة 72% | تكلفة إجمالية أفضل |
السيناريو الأول: إصلاح مشكلات GitHub الواقعية → اختر Claude Opus 4.7
إذا كان مطلبك الأساسي هو "تلقي وصف لمشكلة (Issue) والحصول على طلب سحب (PR) جاهز للدمج"، فإن Claude Opus 4.7 هو الخيار الأمثل بلا منازع. تشير نتيجته البالغة 87.6% في اختبار SWE-bench Verified إلى أن حوالي تسعة أعشار مهام إصلاح الأخطاء محددة المعالم يمكن تسليمها مباشرة.
تجدر الإشارة إلى أن نسبة 87.6% لا تعني أن 87.6% من عملك الهندسي سيتم أتمتته بالكامل؛ فهذا الاختبار قائم على "مواصفات مهام مثالية". في سير العمل الحقيقي، تؤثر جودة وصف المشكلة بشكل كبير على معدل النجاح.
السيناريو الثاني: فهم الكود ذي السياق الطويل → اختر GPT-5.5
عندما تحتاج إلى جعل النموذج يقرأ مستودع الكود بالكامل (عادةً ما يتراوح بين 500 ألف إلى مليون رمز) قبل اتخاذ قرار، فإن GPT-5.5 هو الخيار الموثوق الوحيد حالياً. دقة استرجاع Opus 4.7 في نطاق مليون رمز (8-needle) تبلغ 32.2% فقط، مما يعني أن النموذج قد "يغفل" عن تعريفات رئيسية في أعماق قاعدة الكود.
هذا الفرق يكمن في مستوى البنية ذاته؛ فإذا كان سير عملك يعتمد على رؤية كاملة لقاعدة الكود (مثل إعادة التسمية الشاملة أو فحص توافقية API)، فقد لا ينجح Opus 4.7 في إكمال العملية.
السيناريو الثالث: سير عمل البرمجة الذكي (Agentic) → اختر GPT-5.5
تشير البرمجة الذكية (Agentic) إلى سير العمل حيث يقوم الذكاء الاصطناعي بالتخطيط المستقل، واستدعاء الأدوات، والتصحيح التكراري. يتفوق GPT-5.5 بنتيجة 82.7% في اختبار Terminal-Bench 2.0، متجاوزاً Opus 4.7 بوضوح، خاصة في المهام المستقرة التالية:
- كتابة وتنفيذ نصوص الأتمتة والنشر.
- تصحيح أخطاء الخدمات المتعددة وتحليل سجلات الأحداث (Logs).
- استكشاف مشاكل خطوط أنابيب CI/CD وإصلاحها.
- بناء ومراقبة خطوط معالجة البيانات.
نصيحة التكامل: عند بناء سير عمل برمجي ذكي، يُنصح باستدعاء GPT-5.5 عبر منصات التجميع مثل APIYI (apiyi.com)، مما يسهل إدارة مفتاح API بشكل موحد، ومراقبة تكاليف الاستدعاء، والتبديل إلى نماذج بديلة عند الحاجة.
السيناريو الرابع: البرمجة الزوجية التفاعلية → اختر Claude Opus 4.7
تجربة البرمجة التفاعلية حساسة للغاية للتأخير. زمن الاستجابة (TTFT) الخاص بـ Opus 4.7 يبلغ حوالي 0.5 ثانية، بينما يبلغ حوالي 3 ثوانٍ في GPT-5.5. هذا الفرق، الذي يصل إلى 6 أضعاف، محسوس جداً في سيناريوهات التفاعل المتكرر.
إذا كنت تستخدم أدوات دمج IDE مثل Cursor أو Claude Code أو Continue لإكمال مقاطع كود قصيرة ومتكررة، فإن التأخير المنخفض في Opus 4.7 سيمنحك إيقاعاً برمجياً أكثر سلاسة.

أمثلة على استدعاء نماذج GPT-5.5 و Claude Opus 4.7 عبر API
نقدم لك أدناه أمثلة مبسطة لاستدعاء كلا النموذجين، مما يسهل عليك التحقق منها بسرعة. يتوافق كلا النموذجين مع تنسيق OpenAI SDK، مما يجعل عملية الانتقال سهلة للغاية.
استدعاء مبسط لنموذج GPT-5.5
import openai
# تهيئة العميل باستخدام مفتاح API الخاص بك
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# تنفيذ استدعاء النموذج
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "قم بتنفيذ خوارزمية الفرز السريع (Quick Sort) باستخدام لغة Python"}]
)
print(response.choices[0].message.content)
استدعاء مبسط لنموذج Claude Opus 4.7
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "قم بتنفيذ خوارزمية الفرز السريع (Quick Sort) باستخدام لغة Python"}]
)
print(response.choices[0].message.content)
عرض كود الاختبار للمقارنة المتوازية بين النموذجين
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""اختبار زمن الاستجابة وطول المخرجات للنموذج الواحد"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# اختبار المقارنة في القدرات البرمجية
test_prompt = """
يرجى تنفيذ فئة (Class) لذاكرة التخزين المؤقت LRU باستخدام Python، مع مراعاة:
1. دعم طريقتي get(key) و put(key, value)
2. التخلص تلقائياً من العنصر الأقدم استخداماً عند امتلاء السعة
3. أن يكون التعقيد الزمني لجميع العمليات O(1)
4. تضمين اختبارات الوحدة الكاملة (Unit Tests)
"""
# اختبار النموذجين بشكل متوازٍ
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']} ثانية، {gpt_result['output_tokens']} توكن")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']} ثانية، {claude_result['output_tokens']} توكن")
نصيحة للاختبار: يمكنك الحصول على رصيد تجريبي مجاني من خلال خدمة APIYI عبر apiyi.com، وإجراء اختبارات متوازية بين GPT-5.5 و Claude Opus 4.7 باستخدام نفس الحساب، مع استخدام رابط base_url ومفتاح API موحد، مما يغنيك عن تقديم طلبات منفصلة لكل من OpenAI و Anthropic.
تحليل التكلفة الشامل لنموذجي GPT-5.5 و Claude Opus 4.7
تُعد تسعيرة الـ API مؤشراً جوهرياً لا بد من مراعاته عند الاختيار. للوهلة الأولى، يبدو أن Opus 4.7 أرخص بنسبة 17% في استهلاك التوكن للمخرجات، لكن التحليل الشامل يقلب الموازين:
| بعد التكلفة | GPT-5.5 | Claude Opus 4.7 | التأثير الفعلي |
|---|---|---|---|
| سعر المدخلات | 5$ لكل مليون توكن | 5$ لكل مليون توكن | متساويان |
| سعر المخرجات | 30$ لكل مليون توكن | 25$ لكل مليون توكن | Opus أرخص بـ 17% |
| >200K موجه | نفس السعر | يتضاعف إلى 10$/37.50$ | GPT أفضل للسياق الطويل |
| التوكن للمهمة ذاتها | خط أساس 100% | أكثر بـ 72% من GPT | GPT أرخص إجمالاً |
| زمن الاستجابة الأول (TTFT) | ~3 ثوانٍ | ~0.5 ثانية | Opus أفضل تجربةً |
| تكلفة المهام الضخمة | خط أساس 1.0x | 1.4-1.5x من الأساس | GPT أكثر توفيراً |
النتائج الرئيسية لمقارنة التكاليف
كفاءة التوكن تغير جوهر مقارنة الأسعار. في مهام البرمجة المتطابقة، يستهلك GPT-5.5 توكن مخرجات أقل بنسبة 72% مقارنة بـ Opus 4.7. وحتى مع كون سعر Opus الفردي أرخص بـ 17%، فإن التكلفة الفعلية للمهمة تصبح أقل لصالح GPT-5.5 بعد ضربها في حجم استهلاك التوكن الأكبر لدى Opus.
تتسع الفجوة في سيناريوهات نافذة السياق الطويلة. عندما يتجاوز الموجه (Prompt) حاجز الـ 200 ألف توكن، يتضاعف سعر المدخلات والمخرجات لنموذج Opus 4.7 ليصبح 10$ و 37.50$ على التوالي، بينما يحافظ GPT-5.5 على سعره الأصلي. بالنسبة لسير العمل الذي يتطلب فهم سياق طويل (مثل تحليل مستودع برمجيات كامل)، قد تصل ميزة التكلفة في GPT-5.5 إلى 2-3 أضعاف.
تفسير المقارنة
خصائص تكلفة Claude Opus 4.7: يتمتع بسعر تنافسي لكل توكن بين النماذج الرائدة، ولكن في سيناريوهات التوليد واسعة النطاق، يؤدي ارتفاع استهلاك التوكن إلى رفع التكلفة الإجمالية، كما تضغط آلية مضاعفة السعر عند تجاوز 200 ألف توكن على الميزانية.
خصائص تكلفة GPT-5.5: رغم أن سعره لكل توكن أعلى قليلاً، إلا أن كفاءته المتميزة في استهلاك التوكن وسياسة عدم زيادة السعر في السياق الطويل تجعله أكثر توفيراً في التكاليف الإجمالية للمشاريع واسعة النطاق. من الواضح أن OpenAI راعت هيكل تكاليف سير عمل الوكلاء (Agentic workflows) عند وضع التسعيرة.
نصيحة لحساب التكلفة: تتأثر تكلفة المشروع الفعلي بعدة عوامل منها طول الموجه، طول المخرجات، وتكرار الاستدعاء. نوصي بالوصول إلى كلا النموذجين عبر منصة APIYI على apiyi.com، حيث توفر المنصة فواتير استدعاء تفصيلية، مما يسهل عليك اتخاذ قرار الاختيار بناءً على بيانات فعلية.
الأسئلة الشائعة FAQ
س1: أيهما يمتلك قدرة برمجية أقوى، GPT-5.5 أم Claude Opus 4.7؟
لا توجد إجابة مطلقة بـ "أقوى"، فالأمر يعتمد على المهمة المحددة. يتفوق Claude Opus 4.7 في اختبارات SWE-bench Pro (64.3% مقابل 58.6%) وVerified (87.6%)، مما يجعله أكثر ملاءمة لإصلاح مشكلات GitHub الحقيقية وإعادة هيكلة قواعد الأكواد الضخمة. بينما يتفوق GPT-5.5 في Terminal-Bench 2.0 (82.7% مقابل 69.4%) واسترجاع السياق الطويل (74.0% مقابل 32.2%)، مما يجعله الأنسب لعمليات البرمجة الوكيلة (Agentic) وفهم الأكواد عبر مستودعات برمجية كاملة (monorepo).
س2: ما هي الفروقات في تسعير API بين GPT-5.5 و Claude Opus 4.7؟
كلا النموذجين يكلفان 5 دولارات لكل مليون رمز (Token) للمدخلات. بالنسبة للمخرجات، يعد Opus 4.7 أرخص بنسبة 17% (25 دولاراً/مليون رمز) مقارنة بـ GPT-5.5 (30 دولاراً/مليون رمز). ومع ذلك، يتضاعف سعر Opus 4.7 عند تجاوز الموجه 200 ألف رمز، بينما يحافظ GPT-5.5 على سعره الأصلي. وبالنظر إلى أن استهلاك GPT-5.5 لرموز المخرجات أقل بنسبة 72%، فإن تكلفته الإجمالية تكون أقل في المهام ذات الحجم الكبير.
س3: متى تم إطلاق GPT-5.5 و Claude Opus 4.7؟
أطلقت شركة Anthropic نموذج Claude Opus 4.7 في 16 أبريل 2026، وهو متاح حالياً عبر Claude API و Amazon Bedrock و Google Cloud Vertex AI و Microsoft Foundry. أما GPT-5.5 (الاسم الرمزي الداخلي Spud) فقد أطلقته OpenAI في 23 أبريل 2026، حيث ظهرا بفارق 7 أيام فقط، مما يعكس منافسة شرسة بين أقوى نموذجين في البرمجة.
س4: ما هي سيناريوهات البرمجة التي ينبغي فيها اختيار Claude Opus 4.7؟
يُفضل اختيار Opus 4.7 في السيناريوهات التالية:
- إصلاح مشكلات GitHub: يتفوق بنسبة 5.7 نقطة مئوية في SWE-bench Pro.
- إعادة هيكلة قواعد الأكواد الضخمة: قدرة أقوى على الاستنتاج المعماري عبر الملفات.
- البرمجة التفاعلية (Pair Programming): زمن الاستجابة الأول (TTFT) يبلغ 0.5 ثانية فقط، وهو أسرع بـ 6 مرات.
- مراجعة جودة الكود: حقق درجات أعلى في اختبارات جودة الكود ضمن Rakuten-SWE-Bench.
س5: كيف يمكن استدعاء GPT-5.5 و Claude Opus 4.7 بسرعة عبر API؟
نوصي باستخدام منصة تجميع API التي تدعم كلا النموذجين للاختبار:
- قم بزيارة منصة APIYI على apiyi.com لإنشاء حساب.
- احصل على مفتاح API موحد ورصيد اختبار مجاني.
- استخدم كود المثال التالي (قم باستبدال
base_urlبـhttps://vip.apiyi.com/v1)، وحدد النموذج كـgpt-5.5أوclaude-opus-4-7لإجراء الاستدعاء.
تدعم APIYI الواجهات الموحدة للنماذج الرائدة مثل OpenAI و Anthropic و Google، مما يتيح لك المقارنة السريعة بين أداء GPT-5.5 و Claude Opus 4.7 دون الحاجة للتقديم على حسابات متعددة.
س6: ما هي القيود المعروفة لكل من GPT-5.5 و Claude Opus 4.7؟
قيود GPT-5.5:
- تأخير زمن الاستجابة الأول (TTFT) يبلغ حوالي 3 ثوانٍ، مما يجعل التجربة أبطأ في السيناريوهات التفاعلية.
- أداء أقل من Opus 4.7 في إصلاح المشكلات الحقيقية ضمن SWE-bench.
قيود Claude Opus 4.7:
- قدرة ضعيفة على استرجاع السياق الطويل (32.2% في نطاق 1 مليون).
- تضاعف السعر عند تجاوز الموجه 200 ألف رمز، مما يضغط على تكاليف السياق الطويل.
- استهلاك أعلى لرموز المخرجات، مما يجعل التكلفة الإجمالية مرتفعة في المهام الكبيرة.
- أداء أقل من GPT-5.5 في المهام الوكيلة (Agentic) مثل Terminal-Bench.
س7: هل من الضروري استخدام GPT-5.5 و Claude Opus 4.7 معاً؟
بالنسبة لفرق التطوير المحترفة، نوصي بشدة باستخدامهما معاً. استراتيجية العمل المثالية: استخدم Opus 4.7 لإصلاح مشكلات GitHub، مراجعة الكود، والقرارات المعمارية الحاسمة؛ واستخدم GPT-5.5 لتحليل السياق الطويل، عمليات الأتمتة الوكيلة، وتوليد الأكواد بكميات كبيرة. يتيح هذا الدمج الاستفادة من نقاط قوة كل نموذج مع تحقيق توازن بين التكلفة وتجربة المستخدم.
النقاط الجوهرية (Key Takeaways) لـ GPT-5.5 و Claude Opus 4.7
- لإصلاح المشكلات الحقيقية اختر Opus: يتفوق Claude Opus 4.7 في اختباري SWE-bench Pro وVerified، مما يجعله الخيار الأول لإصلاح مشكلات GitHub.
- للبرمجة الوكيلة اختر GPT: يتفوق GPT-5.5 في Terminal-Bench 2.0 بفارق 13 نقطة مئوية، مما يوفر استدعاء أدوات أكثر استقراراً.
- للسياق الطويل اختر GPT: في اختبارات MRCR v2، تفوق GPT-5.5 (74%) بشكل كبير على Opus (32.2%)، مما يجعله الخيار الموثوق الوحيد لسياق 1 مليون رمز.
- للحساسية تجاه التأخير اختر Opus: زمن استجابة Opus (TTFT) هو 0.5 ثانية فقط، أسرع بـ 6 مرات من GPT، مما يوفر تجربة برمجة أكثر سلاسة.
- للحساسية تجاه التكلفة اختر GPT: استهلاك GPT-5.5 لرموز المخرجات أقل بـ 72%، مما يجعل تكلفته الإجمالية للمهام أكثر كفاءة.
- اختبار متوازٍ وسريع: يمكنك استدعاء النموذجين عبر حساب واحد في APIYI (apiyi.com)، مما يسهل المقارنة في السيناريوهات الواقعية.
ملخص
النتائج الرئيسية للمقارنة بين قدرات البرمجة في GPT-5.5 و Claude Opus 4.7:
- لا يوجد فائز مطلق: يتمتع كل نموذج بنقاط قوة واضحة في مجالات محددة، لذا فإن السعي الأعمى وراء "أفضل نموذج" ليس التوجه الصحيح.
- الاختيار القائم على المهام: حدد أولاً سيناريو البرمجة الأساسي الخاص بك (إصلاح المشكلات، الوكيل الذكي Agentic، نافذة السياق الطويلة، أو التفاعل)، ثم اختر النموذج الرئيسي بناءً عليه.
- نوصي باستخدام نموذجين معاً: يجب على فرق التطوير المحترفة دمج كلا النموذجين، وتوجيه المهام إلى النموذج الأمثل حسب السيناريو لتحقيق أقصى قدر من الإنتاجية.
إذا كان عليك اختيار نموذج واحد فقط: اختر Claude Opus 4.7 إذا كان عملك اليومي يتركز على إصلاح مشكلات GitHub ومراجعة الأكواد؛ واختر GPT-5.5 إذا كنت تركز على أتمتة الوكلاء الذكية (Agentic) وتحليل السياقات الطويلة.
نوصي بالتحقق السريع من اختيارك عبر منصة APIYI على apiyi.com، حيث توفر المنصة واجهة موحدة لكل من GPT-5.5 و Claude Opus 4.7، مع أرصدة تجريبية مجانية وفواتير دقيقة، مما يجعلها الطريق الأسهل لاتخاذ قرارات قائمة على البيانات.
قراءة إضافية
إذا كنت مهتماً بالمقارنة البرمجية بين GPT-5.5 و Claude Opus 4.7، نوصي بمواصلة القراءة حول:
- 📘 التقييم الكامل لـ Claude Opus 4.7: القوة الهندسية وراء نسبة 87.6% في اختبار SWE-bench – تحليل معمق لمصادر قدرات Opus 4.7.
- 📊 دليل الاختبار الفعلي لـ GPT-5.5 Spud: ثماني نصائح لاستخدام ملك البرمجة الذكية (Agentic) – أتقن الاستخدام المتقدم لنموذج GPT-5.5.
- 🚀 دليل اختيار نماذج البرمجة بالذكاء الاصطناعي 2026: مقارنة شاملة من GPT إلى Claude – استكشف منهجية أكثر شمولية لاختيار النماذج.
📚 المراجع
-
مقدمة OpenAI الرسمية لنموذج GPT-5.5: معايير الأداء (Benchmark) الأساسية وشرح القدرات
- الرابط:
openai.com/index/introducing-gpt-5-5 - الوصف: وثيقة الإصدار الرسمية لـ GPT-5.5، تتضمن معايير أساسية مثل SWE-bench و Terminal-Bench.
- الرابط:
-
بيان إصدار Anthropic الرسمي لنموذج Claude Opus 4.7: تحديد موقع النموذج وبيانات الأداء
- الرابط:
anthropic.com/news/claude-opus-4-7 - الوصف: وثيقة الإصدار الرسمية لـ Opus 4.7، تتضمن بيانات تفصيلية حول SWE-bench Verified/Pro.
- الرابط:
-
قائمة الصدارة العامة لـ SWE-Bench Pro: التحقق المستقل من طرف ثالث
- الرابط:
labs.scale.com/leaderboard/swe_bench_pro_public - الوصف: قائمة صدارة SWE-Bench Pro التي تديرها Scale AI، حيث يمكن التحقق من التصنيف الحقيقي للنموذجين.
- الرابط:
-
قائمة Vellum LLM لعام 2026: مقارنة شاملة لنماذج الذكاء الاصطناعي
- الرابط:
vellum.ai/llm-leaderboard - الوصف: منصة مقارنة شاملة تغطي أبعادًا متعددة مثل البرمجة، الاستدلال، ونوافذ السياق الطويلة.
- الرابط:
-
مقارنة النماذج عبر Artificial Analysis: تحليل الأداء والتكلفة
- الرابط:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - الوصف: توفر بيانات مقارنة دقيقة حول زمن الوصول للرمز الأول (TTFT)، الإنتاجية (Throughput)، والتكلفة الإجمالية.
- الرابط:
المؤلف: فريق APIYI التقني
التواصل التقني: نرحب بمناقشاتكم في قسم التعليقات، ولمزيد من المعلومات يمكنكم زيارة مركز توثيق APIYI على الرابطdocs.apiyi.com.