作者注:基於 SWE-bench Pro、Terminal-Bench 2.0、LiveCodeBench 等 6 項核心基準測試,深度對比 GPT-5.5 與 Claude Opus 4.7 在真實編程場景下的能力差異,給出明確選型建議。
GPT-5.5 與 Claude Opus 4.7 的編程能力之爭,是 2026 年 4 月 AI 編程領域最受關注的話題。本文對比 OpenAI GPT-5.5(代號 Spud) 和 Anthropic Claude Opus 4.7,從 SWE-bench Pro、Terminal-Bench 2.0、長上下文檢索、Token 效率、API 定價等多個維度給出明確選型建議。
這不是一份"看起來各有千秋"的折中分析,我們會基於官方公佈的 Benchmark 數據,直接給出在不同場景下的明確推薦。Anthropic 在 2026 年 4 月 16 日發佈 Claude Opus 4.7,OpenAI 緊接着在 4 月 23 日發佈 GPT-5.5,兩個頂級模型相隔僅 7 天登場,編程能力對決就此拉開。
核心價值:看完本文,你將明確在 GitHub issue 修復、Agentic 編程、長上下文重構、交互式編碼這 4 類典型場景下,應該選擇 GPT-5.5 還是 Claude Opus 4.7。

GPT-5.5 與 Claude Opus 4.7 核心差異速覽
兩個模型的核心定位不同,導致編程能力的強項也截然不同。下表彙總了它們在編程相關維度的關鍵差異:
| 對比維度 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| 發佈日期 | 2026-04-23 | 2026-04-16 |
| 代號 | Spud | – |
| 上下文窗口 | 1M tokens | 1M tokens |
| 最大輸出 | 128K tokens | 128K tokens |
| 核心強項 | Agentic 編程、長上下文檢索 | 真實 GitHub issue 修復、架構推理 |
| 典型 TTFT | ~3 秒 | ~0.5 秒 |
| Token 效率 | 輸出 Token 比 Opus 少 72% | Token 消耗較高,但精度高 |
| API 輸入 | $5/M tokens | $5/M tokens |
| API 輸出 | $30/M tokens | $25/M tokens |
| 大 Prompt 加價 | >200K 仍保持原價 | >200K 翻倍至 $10/$37.50 |
GPT-5.5 編程能力定位
GPT-5.5 是 OpenAI 截至目前最強的 Agentic 編程模型。它在終端工作流、長上下文檢索、跨工具協調上表現出色,特別適合多步驟、需要工具調用的自動化編程流程。OpenAI 官方將其定位爲"長程編程任務"的首選,在 Expert-SWE 內部基準上展現出處理 20 小時人類工作量任務的能力。
Claude Opus 4.7 編程能力定位
Claude Opus 4.7 在真實軟件工程任務上重新奪回王座。它在 SWE-bench Verified 上達到 87.6%,在 SWE-bench Pro 上達到 64.3%,顯著領先所有現有競品。Anthropic 在 Rakuten-SWE-Bench 上的實測顯示,Opus 4.7 解決的生產任務量是 Opus 4.6 的 3 倍,特別適合修復 GitHub issue、重構大型代碼庫這類需要架構推理的工作。
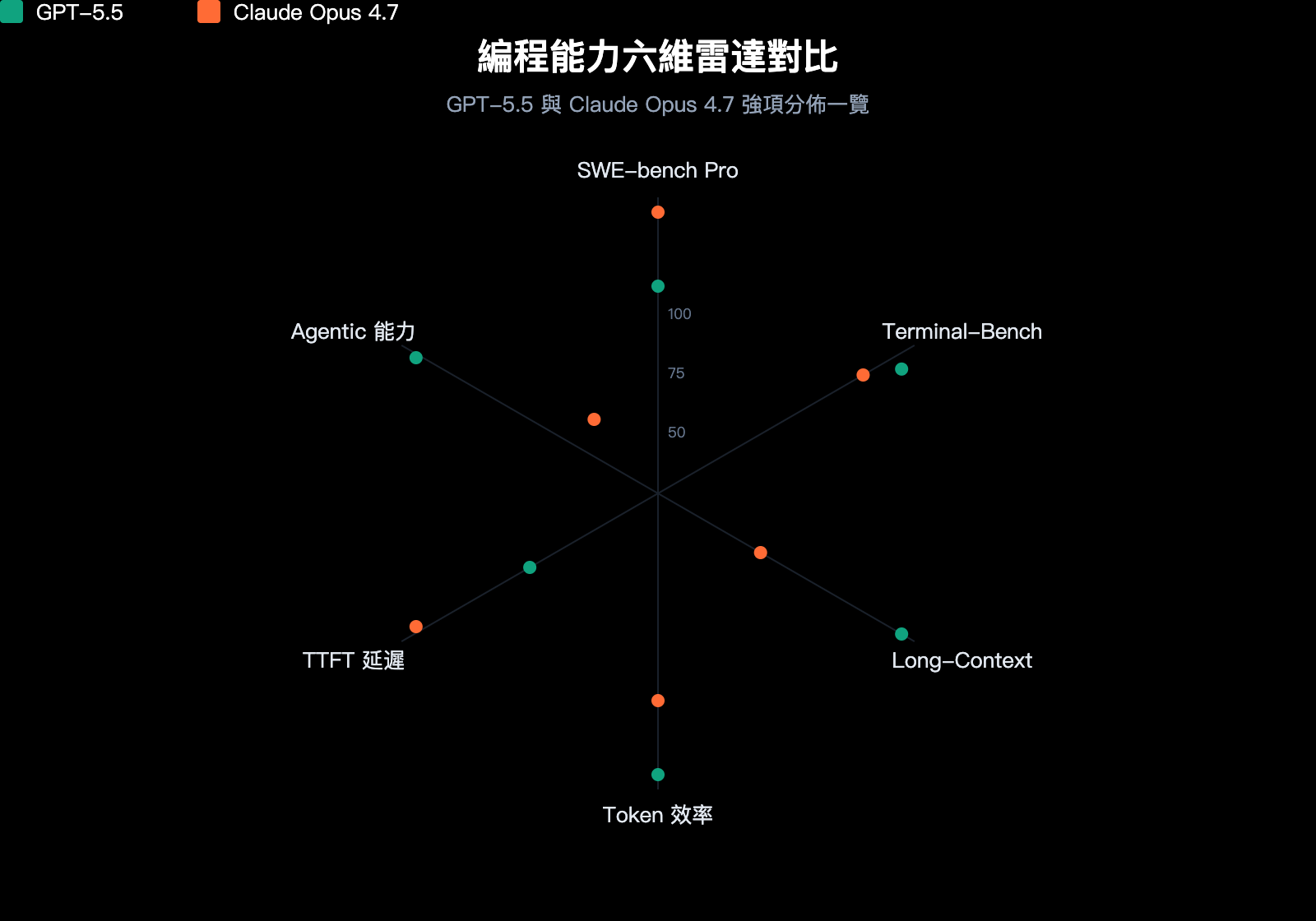
GPT-5.5 與 Claude Opus 4.7 Benchmark 實測對比
Benchmark 是判斷編程能力最客觀的標尺。我們彙總了兩個模型在 6 項主流編程基準上的官方數據:
| 基準測試 | 測試內容 | GPT-5.5 | Claude Opus 4.7 | 勝出方 |
|---|---|---|---|---|
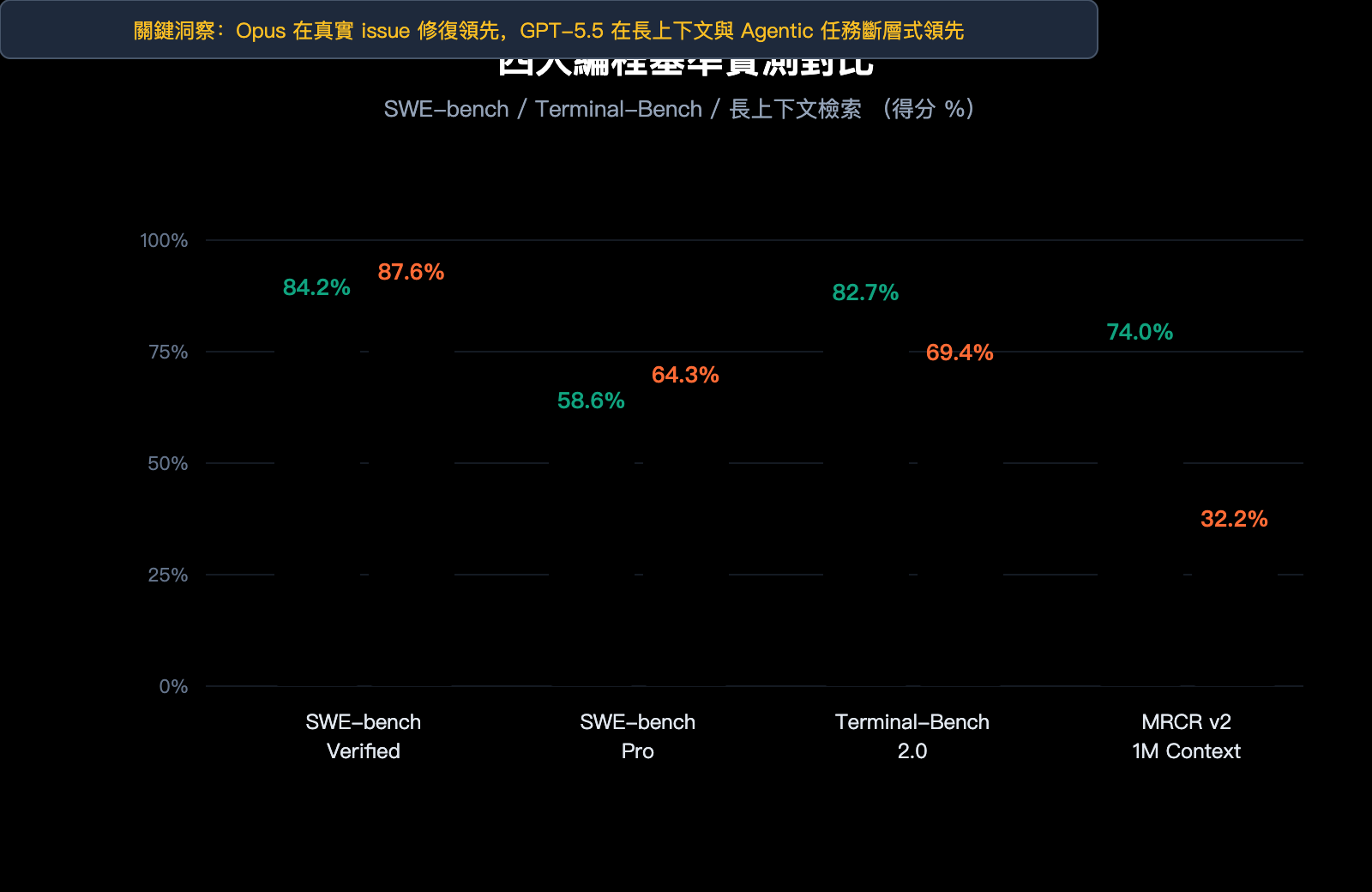
| SWE-bench Verified | 已驗證的 GitHub issue 修復 | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | 多文件複雜 issue 修復 | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | 終端命令工作流 | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | 長程編程(中位數 20 小時) | 73.1% | – | GPT-5.5 |
| OSWorld-Verified | 桌面 Agent 任務 | 78.7% | 78.0% | GPT-5.5(微弱) |
| MRCR v2 (512K-1M) | 長上下文 8-needle 檢索 | 74.0% | 32.2% | GPT-5.5 |
SWE-bench Pro 實戰分析
SWE-bench Pro 是評估模型修復真實 GitHub issue 能力的金標準。Claude Opus 4.7 以 64.3% 領先 GPT-5.5 的 58.6%,這意味着在每 100 個真實代碼庫 bug 修復任務中,Opus 4.7 能多解決約 6 個。
更關鍵的是,Opus 4.7 相比上一代 Opus 4.6(53.4%)提升了整整 10.9 個百分點,這是單次版本迭代中罕見的大幅躍遷。對於以 GitHub issue 修復爲主要工作流的團隊,Claude Opus 4.7 是當前的最優選。
測試建議:想驗證兩個模型在你自己代碼庫上的表現差異?可以通過 API易 apiyi.com 平臺並行測試,平臺支持 GPT-5.5 和 Claude Opus 4.7 的統一接口調用,便於快速對比。
Terminal-Bench 2.0 實戰分析
Terminal-Bench 2.0 測試模型在終端環境下完成複雜任務的能力,包括規劃、迭代、工具協調三大維度。GPT-5.5 以 82.7% 大幅領先 Opus 4.7 的 69.4%,差距高達 13 個百分點。
這一差距源於 GPT-5.5 在 Agentic 工作流上的優化:它能夠更精準地選擇工具、更穩定地處理多步驟任務、更可靠地從錯誤中恢復。如果你的工作流涉及大量 shell 命令、文件操作、CI/CD 集成,GPT-5.5 是更穩妥的選擇。
長上下文檢索能力差距
MRCR v2 在 512K-1M tokens 範圍的 8-needle 檢索測試中,GPT-5.5 以 74.0% 大幅領先 Opus 4.7 的 32.2%——這是一個 41.8 個百分點的鴻溝。
這意味着如果你需要讓模型理解整個代碼倉庫(500K+ tokens),GPT-5.5 對深層上下文的回憶精度顯著更高。對於"基於完整 monorepo 重構"這類場景,GPT-5.5 不只是更好,而是能用與不能用的差距。
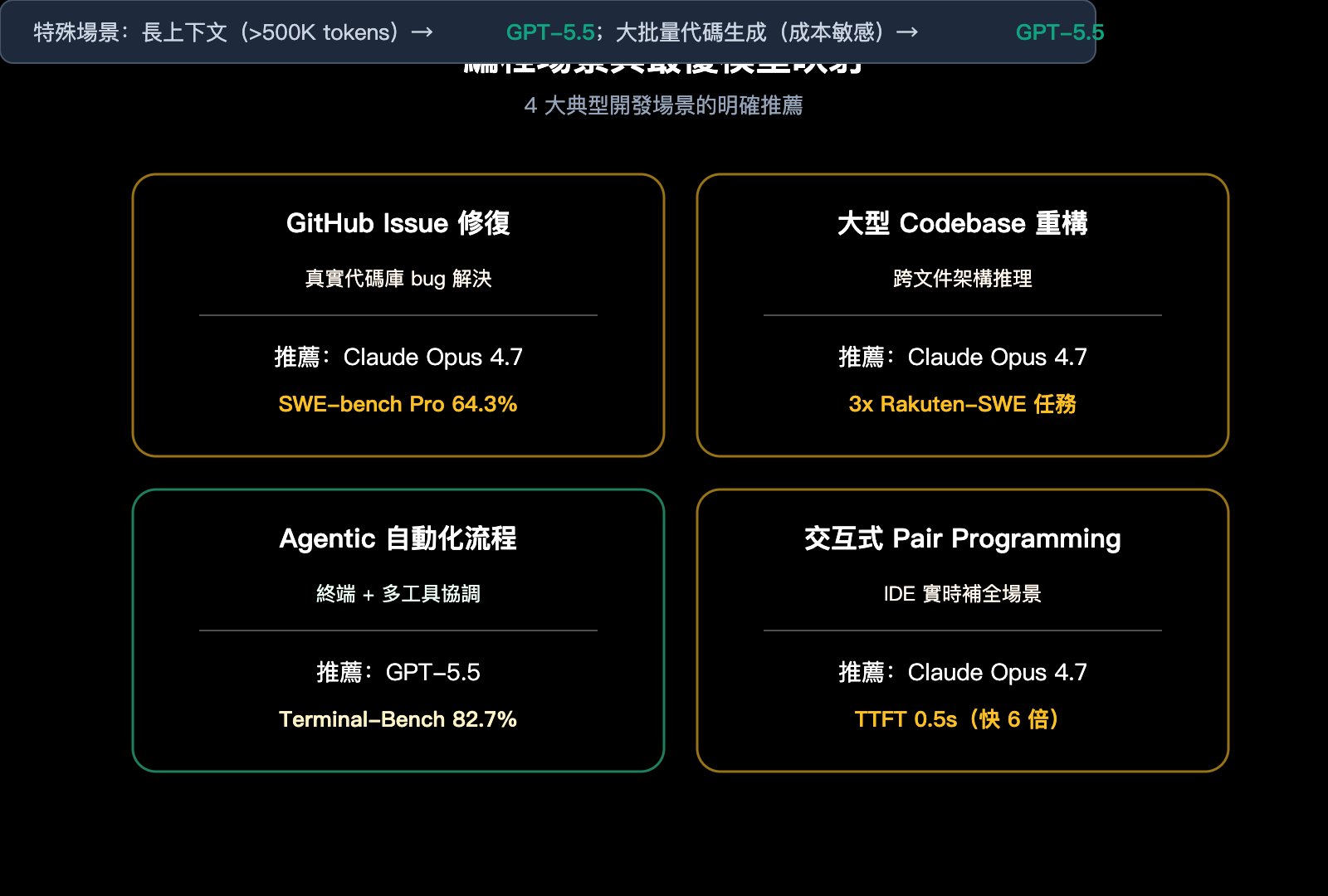
GPT-5.5 與 Claude Opus 4.7 編程場景實戰推薦
Benchmark 數據需要落到具體場景纔有意義。下表給出 5 類典型編程場景的明確推薦:
| 編程場景 | 推薦模型 | 核心理由 | 預期收益 |
|---|---|---|---|
| GitHub Issue 修復 | Claude Opus 4.7 | SWE-bench Pro 領先 5.7 個百分點 | 修復成功率提升 10% |
| 大型 Codebase 重構 | Claude Opus 4.7 | 跨文件架構推理能力更強 | 減少架構破壞風險 |
| Agentic 自動化流程 | GPT-5.5 | Terminal-Bench 領先 13.3 個百分點 | 多步任務穩定性更高 |
| 長上下文(>500K)理解 | GPT-5.5 | MRCR v2 領先 41.8 個百分點 | 深層上下文檢索可靠 |
| 交互式 Pair Programming | Claude Opus 4.7 | TTFT 僅 0.5 秒,響應更快 | 編碼節奏更流暢 |
| 大批量代碼生成 | GPT-5.5 | Token 效率高 72%,成本更低 | 綜合成本更優 |
場景一:修復真實 GitHub Issue → 選 Claude Opus 4.7
如果你的核心需求是"接到一個 issue 描述,讓 AI 給出可合併的 PR",Claude Opus 4.7 是無可爭議的最優選。它在 SWE-bench Verified 上 87.6% 的得分意味着大約九成的良好定義 bug 修復任務能直接交付。
需要注意的是,87.6% 不等於你 87.6% 的工程工作能被自動化——這是基於"完美任務規範"的理想測試。在實際工作流中,issue 描述質量會顯著影響成功率。
場景二:長上下文代碼理解 → 選 GPT-5.5
當你需要讓模型讀完整個 monorepo(通常 500K-1M tokens)再做決策時,GPT-5.5 是當前唯一可靠的選擇。Opus 4.7 在 1M 上下文區間的 8-needle 檢索精度只有 32.2%,意味着模型很可能"看不見"代碼庫深處的關鍵定義。
這個差距是架構級別的——如果你的工作流依賴完整代碼庫視圖(例如全局重命名、API 兼容性檢查),用 Opus 4.7 可能根本跑不通流程。
場景三:Agentic 編程工作流 → 選 GPT-5.5
Agentic 編程是指 AI 自主規劃、調用工具、迭代修正的工作流。GPT-5.5 在 Terminal-Bench 2.0 的 82.7% 得分遠超 Opus 4.7,特別在以下任務中表現穩定:
- 自動化部署腳本編寫與執行
- 多服務調試與日誌分析
- CI/CD 流水線問題排查
- 數據管道構建與監控
集成建議:構建 Agentic 編程流程時,建議通過 API易 apiyi.com 這類聚合平臺調用 GPT-5.5,便於統一管理 API Key、監控調用成本、按需切換備用模型。
場景四:交互式 Pair Programming → 選 Claude Opus 4.7
交互式編碼體驗對延遲極度敏感。Opus 4.7 的 TTFT(首 token 延遲)約 0.5 秒,而 GPT-5.5 約 3 秒,6 倍的差距在頻繁交互場景下感知非常明顯。
如果你使用 Cursor、Claude Code、Continue 等 IDE 集成工具進行頻繁的小段代碼補全,Opus 4.7 的低延遲會帶來更流暢的編碼節奏。
GPT-5.5 與 Claude Opus 4.7 API 調用示例
下面給出兩個模型的極簡調用示例,方便你快速驗證。兩者都兼容 OpenAI SDK 格式,遷移成本極低。
GPT-5.5 極簡調用
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "用 Python 實現快速排序"}]
)
print(response.choices[0].message.content)
Claude Opus 4.7 極簡調用
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "用 Python 實現快速排序"}]
)
print(response.choices[0].message.content)
查看雙模型並行對比測試代碼
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""測試單個模型的響應時間和輸出長度"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# 編程能力對比測試
test_prompt = """
請用 Python 實現一個 LRU 緩存類,要求:
1. 支持 get(key) 和 put(key, value) 方法
2. 容量滿時自動淘汰最久未使用的項
3. 所有操作時間複雜度 O(1)
4. 包含完整的單元測試
"""
# 並行測試兩個模型
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
測試建議:通過 API易 apiyi.com 獲取免費測試額度,可在同一賬號下並行測試 GPT-5.5 和 Claude Opus 4.7,使用統一的 base_url 和 API Key,無需分別申請 OpenAI 和 Anthropic 賬號。
GPT-5.5 與 Claude Opus 4.7 綜合成本分析
API 定價是選型必須考慮的硬指標。表面上看 Opus 4.7 輸出 Token 便宜 17%,但綜合分析後真相會反轉:
| 成本維度 | GPT-5.5 | Claude Opus 4.7 | 實際影響 |
|---|---|---|---|
| 輸入定價 | $5/M tokens | $5/M tokens | 持平 |
| 輸出定價 | $30/M tokens | $25/M tokens | Opus 便宜 17% |
| >200K Prompt | 保持原價 | 翻倍至 $10/$37.50 | 長上下文 GPT 優勢大 |
| 同任務輸出 Token | 100% 基線 | 比 GPT 多 72% | GPT 綜合便宜 |
| TTFT 延遲 | ~3 秒 | ~0.5 秒 | Opus 體驗好 |
| 大批量任務實際成本 | 1.0x 基準 | 1.4-1.5x 基準 | GPT 更省錢 |
成本對比的關鍵發現
Token 效率改變了價格比較的本質。在同等編程任務下,GPT-5.5 平均消耗的輸出 Token 比 Opus 4.7 少 72%。即使 Opus 單價便宜 17%,乘以 1.72 倍的 Token 用量後,GPT-5.5 的實際任務成本反而更低。
長上下文場景差距進一步拉大。當 Prompt 超過 200K tokens 時,Opus 4.7 的輸入和輸出價格雙雙翻倍至 $10 和 $37.50,而 GPT-5.5 保持原價。對於需要長上下文理解的工作流(如完整 monorepo 分析),GPT-5.5 的成本優勢可能達到 2-3 倍。
對比解讀
Claude Opus 4.7 成本特點:單 Token 價格在主流前沿模型中具有競爭力。但在大批量生成場景下,其較高的 Token 消耗會拉高總成本;在長上下文場景下,>200K 翻倍機制會顯著增加預算壓力。
GPT-5.5 成本特點:單 Token 價格略高,但出色的 Token 效率和長上下文不加價機制讓它在大規模、長上下文場景下綜合成本反而更低。OpenAI 顯然在設計定價時考慮了 Agentic 工作流的成本結構。
成本測算建議:實際項目成本受 Prompt 長度、輸出長度、調用頻率多重因素影響。建議通過 API易 apiyi.com 平臺接入兩個模型,平臺提供細粒度的調用賬單,便於做出基於真實數據的選型決策。
常見問題 FAQ
Q1: GPT-5.5 和 Claude Opus 4.7 哪個編程能力更強?
沒有絕對的"更強",要看具體任務。Claude Opus 4.7 在 SWE-bench Pro(64.3% vs 58.6%)和 Verified(87.6%)上領先,更適合修復真實 GitHub issue 和大型代碼庫重構。GPT-5.5 在 Terminal-Bench 2.0(82.7% vs 69.4%)和長上下文檢索(74.0% vs 32.2%)上領先,更適合 Agentic 編程流程和跨整個 monorepo 的代碼理解。
Q2: GPT-5.5 和 Claude Opus 4.7 的 API 定價區別在哪裏?
兩者輸入 Token 都是 $5/M。輸出 Token 上 Opus 4.7($25/M)比 GPT-5.5($30/M)便宜 17%。但 Opus 4.7 在 Prompt 超過 200K 時價格翻倍,而 GPT-5.5 保持原價。再考慮到 GPT-5.5 輸出 Token 比 Opus 少 72%,大批量任務下 GPT-5.5 綜合成本更低。
Q3: GPT-5.5 和 Claude Opus 4.7 何時發佈?
Claude Opus 4.7 由 Anthropic 在 2026 年 4 月 16 日發佈,已在 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry 全面上線。GPT-5.5(內部代號 Spud)由 OpenAI 在 2026 年 4 月 23 日發佈,兩個頂級編程模型相隔僅 7 天登場,競爭激烈。
Q4: 哪些編程場景應該選擇 Claude Opus 4.7?
以下場景優先選擇 Opus 4.7:
- 修復 GitHub issue:SWE-bench Pro 領先 5.7 個百分點
- 大型代碼庫重構:跨文件架構推理能力更強
- 交互式 Pair Programming:TTFT 僅 0.5 秒,響應快 6 倍
- 代碼質量審查:Rakuten-SWE-Bench 實測代碼質量得分更高
Q5: 如何快速通過 API 調用 GPT-5.5 和 Claude Opus 4.7?
推薦使用支持雙模型的 API 聚合平臺進行測試:
- 訪問 API易 apiyi.com 註冊賬號
- 獲取統一 API Key 和免費測試額度
- 使用本文示例代碼(base_url 替換爲
https://vip.apiyi.com/v1),分別指定 model 爲gpt-5.5或claude-opus-4-7即可調用
API易支持 OpenAI、Anthropic、Google 等主流模型的統一接口接入,無需分別申請多個賬號即可快速對比 GPT-5.5 和 Claude Opus 4.7 的實際表現。
Q6: GPT-5.5 和 Claude Opus 4.7 各有哪些已知限制?
GPT-5.5 限制:
- TTFT 延遲約 3 秒,交互式場景體驗較慢
- SWE-bench 修復真實 issue 上不及 Opus 4.7
Claude Opus 4.7 限制:
- 長上下文檢索能力薄弱(1M 範圍 32.2%)
- Prompt >200K 時價格翻倍,長上下文成本壓力大
- 輸出 Token 消耗較高,大批量任務綜合成本偏高
- Terminal-Bench 等 Agentic 任務表現不及 GPT-5.5
Q7: 是否有必要同時使用 GPT-5.5 和 Claude Opus 4.7?
對於專業開發團隊,強烈建議兩者並用。典型分工策略:用 Opus 4.7 處理 GitHub issue 修復、代碼 review、關鍵架構決策;用 GPT-5.5 處理長上下文分析、Agentic 自動化流程、大批量代碼生成。這種混用模式既能享受各自的能力優勢,又能在成本和體驗間取得平衡。
GPT-5.5 與 Claude Opus 4.7 核心要點 Key Takeaways
- 真實 Issue 修復看 Opus:Claude Opus 4.7 在 SWE-bench Pro/Verified 雙雙領先,是修復真實 GitHub issue 的首選
- Agentic 編程看 GPT:GPT-5.5 在 Terminal-Bench 2.0 上領先 13 個百分點,多步工具調用更穩定
- 長上下文看 GPT:MRCR v2 測試中 GPT-5.5(74%)遠超 Opus(32.2%),1M 上下文唯一可靠選擇
- 延遲敏感看 Opus:Opus TTFT 僅 0.5 秒,比 GPT 快 6 倍,交互式編碼體驗更流暢
- 成本敏感看 GPT:GPT-5.5 輸出 Token 比 Opus 少 72%,綜合任務成本更低
- 快速並行測試:通過 API易 apiyi.com 一個賬號即可統一調用兩個模型,便於真實場景對比
總結
GPT-5.5 與 Claude Opus 4.7 編程能力對比的核心結論:
- 沒有全能冠軍:兩個模型各有清晰的強項領域,盲目追求"最好的模型"是錯誤思路
- 任務驅動選型:先明確你的核心編程場景(issue 修復 / Agentic / 長上下文 / 交互式),再決定主力模型
- 建議雙模型並行:專業開發團隊應同時接入兩個模型,按場景路由到最優選擇,最大化產出
如果你只能選一個:日常以 GitHub issue 修復和代碼 review 爲主,選 Claude Opus 4.7;以 Agentic 自動化和長上下文分析爲主,選 GPT-5.5。
推薦通過 API易 apiyi.com 快速驗證選型,平臺提供 GPT-5.5 和 Claude Opus 4.7 的統一接口、免費測試額度和細粒度賬單,是做出數據驅動選型決策的最便捷路徑。
延伸閱讀 Related Articles
如果你對 GPT-5.5 與 Claude Opus 4.7 編程對比感興趣,推薦繼續閱讀:
- 📘 Claude Opus 4.7 完整評測:SWE-bench 87.6% 背後的工程實力 – 深度解析 Opus 4.7 的能力來源
- 📊 GPT-5.5 Spud 實測指南:Agentic 編程新王者的 8 個使用技巧 – 掌握 GPT-5.5 的進階用法
- 🚀 AI 編程模型選型指南 2026:從 GPT 到 Claude 的全景對比 – 探索更宏觀的模型選型方法論
📚 參考資料
-
OpenAI 官方 GPT-5.5 介紹:核心 Benchmark 和能力說明
- 鏈接:
openai.com/index/introducing-gpt-5-5 - 說明: GPT-5.5 官方發佈文檔,包含 SWE-bench、Terminal-Bench 等核心基準
- 鏈接:
-
Anthropic 官方 Claude Opus 4.7 發佈說明:模型定位和性能數據
- 鏈接:
anthropic.com/news/claude-opus-4-7 - 說明: Opus 4.7 官方發佈文檔,含 SWE-bench Verified/Pro 詳細數據
- 鏈接:
-
SWE-Bench Pro 公開排行榜:第三方獨立驗證
- 鏈接:
labs.scale.com/leaderboard/swe_bench_pro_public - 說明: Scale AI 維護的 SWE-Bench Pro 公開排行榜,可驗證兩個模型的真實排名
- 鏈接:
-
Vellum LLM Leaderboard 2026:綜合性 AI 模型對比
- 鏈接:
vellum.ai/llm-leaderboard - 說明: 涵蓋編程、推理、長上下文等多維度的綜合對比平臺
- 鏈接:
-
Artificial Analysis 模型對比:性能與成本分析
- 鏈接:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - 說明: 提供 TTFT、Throughput、綜合成本的細粒度對比數據
- 鏈接:
作者:APIYI 技術團隊
技術交流:歡迎在評論區討論,更多資料可訪問 API易 docs.apiyi.com 文檔中心