Catatan Penulis: Berdasarkan 6 tolok ukur inti seperti SWE-bench Pro, Terminal-Bench 2.0, dan LiveCodeBench, kami melakukan perbandingan mendalam mengenai perbedaan kemampuan pemrograman GPT-5.5 dan Claude Opus 4.7 dalam skenario nyata, serta memberikan saran pemilihan model yang konkret.
Pertarungan kemampuan pemrograman antara GPT-5.5 dan Claude Opus 4.7 menjadi topik paling hangat di dunia pemrograman AI pada April 2026. Artikel ini membandingkan OpenAI GPT-5.5 (kode nama Spud) dan Anthropic Claude Opus 4.7, serta memberikan rekomendasi pemilihan yang jelas dari berbagai dimensi seperti SWE-bench Pro, Terminal-Bench 2.0, pengambilan konteks panjang, efisiensi token, dan harga API.
Ini bukan analisis "keduanya memiliki keunggulan masing-masing" yang bersifat kompromistis. Berdasarkan data benchmark resmi, kami akan memberikan rekomendasi yang tegas untuk skenario yang berbeda. Anthropic merilis Claude Opus 4.7 pada 16 April 2026, diikuti OpenAI yang merilis GPT-5.5 pada 23 April. Hanya berselang 7 hari, kedua model papan atas ini memulai duel kemampuan pemrograman.
Nilai Utama: Setelah membaca artikel ini, Anda akan memahami model mana yang harus dipilih antara GPT-5.5 dan Claude Opus 4.7 untuk 4 skenario tipikal: perbaikan issue GitHub, pemrograman berbasis Agen, refactoring konteks panjang, dan coding interaktif.

Sekilas Perbedaan Utama GPT-5.5 dan Claude Opus 4.7
Penempatan posisi inti dari kedua model ini berbeda, yang membuat keunggulan kemampuan pemrogramannya juga sangat berbeda. Tabel berikut merangkum perbedaan utama dalam dimensi terkait pemrograman:
| Dimensi Perbandingan | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Tanggal Rilis | 2026-04-23 | 2026-04-16 |
| Kode Nama | Spud | – |
| Jendela Konteks | 1M token | 1M token |
| Output Maksimal | 128K token | 128K token |
| Keunggulan Inti | Pemrograman Agen, pengambilan konteks panjang | Perbaikan issue GitHub nyata, penalaran arsitektur |
| TTFT Tipikal | ~3 detik | ~0,5 detik |
| Efisiensi Token | Token output 72% lebih sedikit daripada Opus | Konsumsi token lebih tinggi, namun presisi tinggi |
| Input API | $5/M token | $5/M token |
| Output API | $30/M token | $25/M token |
| Biaya Prompt Besar | >200K tetap harga normal | >200K naik dua kali lipat jadi $10/$37,50 |
Penempatan Posisi Kemampuan Pemrograman GPT-5.5
GPT-5.5 adalah model pemrograman berbasis Agen terkuat dari OpenAI hingga saat ini. Ia bekerja sangat baik dalam alur kerja terminal, pengambilan konteks panjang, dan koordinasi lintas alat, serta sangat cocok untuk proses pemrograman otomatis yang melibatkan langkah-langkah kompleks dan pemanggilan alat. OpenAI secara resmi memposisikannya sebagai pilihan utama untuk "tugas pemrograman jangka panjang", dengan menunjukkan kemampuan menangani beban kerja manusia selama 20 jam pada benchmark internal Expert-SWE.
Penempatan Posisi Kemampuan Pemrograman Claude Opus 4.7
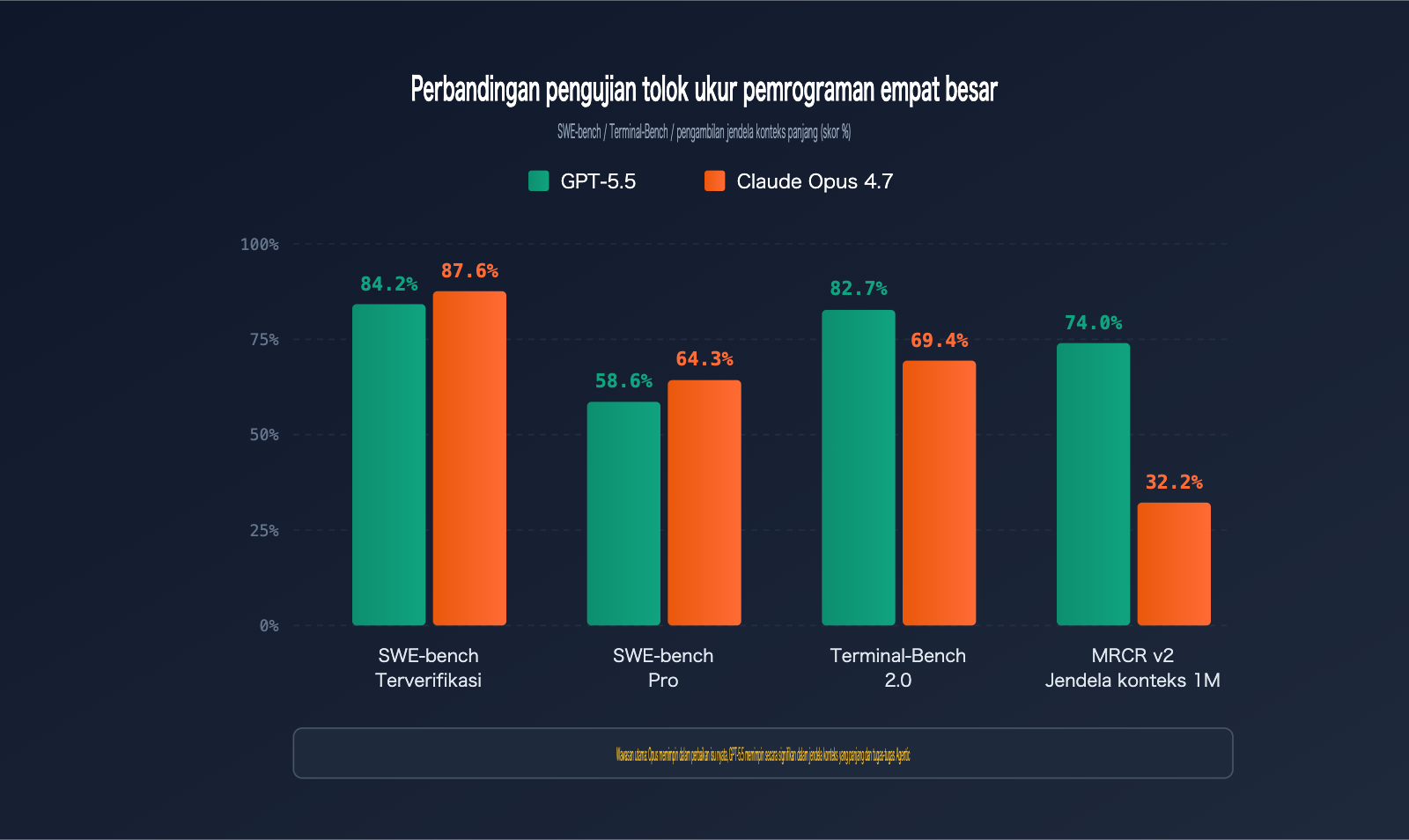
Claude Opus 4.7 merebut kembali tahta dalam tugas rekayasa perangkat lunak nyata. Model ini mencapai 87,6% pada SWE-bench Verified dan 64,3% pada SWE-bench Pro, mengungguli semua pesaing yang ada secara signifikan. Pengujian praktis Anthropic pada Rakuten-SWE-Bench menunjukkan bahwa jumlah tugas produksi yang diselesaikan oleh Opus 4.7 adalah 3 kali lipat dari Opus 4.6, sehingga sangat cocok untuk pekerjaan seperti memperbaiki issue GitHub dan melakukan refactoring basis kode besar yang memerlukan penalaran arsitektur.
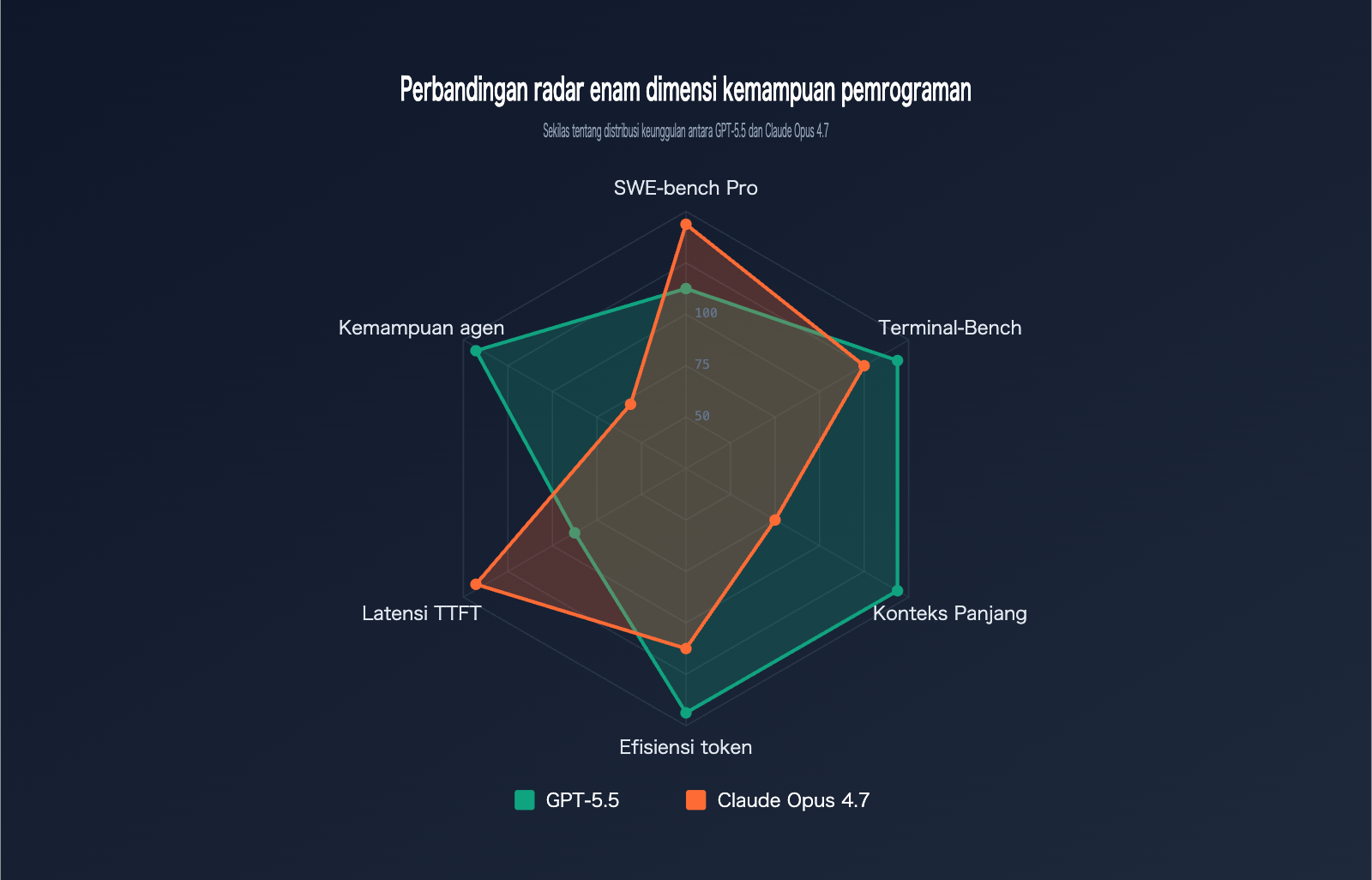
Perbandingan Benchmark GPT-5.5 vs Claude Opus 4.7
Benchmark adalah tolok ukur paling objektif untuk menilai kemampuan pemrograman. Kami telah merangkum data resmi dari kedua model pada 6 benchmark pemrograman utama:
| Benchmark | Konten Pengujian | GPT-5.5 | Claude Opus 4.7 | Pemenang |
|---|---|---|---|---|
| SWE-bench Verified | Perbaikan issue GitHub terverifikasi | 84,2% | 87,6% | Opus 4.7 |
| SWE-bench Pro | Perbaikan issue kompleks multi-file | 58,6% | 64,3% | Opus 4.7 |
| Terminal-Bench 2.0 | Alur kerja perintah terminal | 82,7% | 69,4% | GPT-5.5 |
| Expert-SWE | Pemrograman jangka panjang (median 20 jam) | 73,1% | – | GPT-5.5 |
| OSWorld-Verified | Tugas Agent desktop | 78,7% | 78,0% | GPT-5.5 (tipis) |
| MRCR v2 (512K-1M) | Pengambilan 8-needle konteks panjang | 74,0% | 32,2% | GPT-5.5 |
Analisis Praktis SWE-bench Pro
SWE-bench Pro adalah standar emas untuk mengevaluasi kemampuan model dalam memperbaiki issue GitHub nyata. Claude Opus 4.7 memimpin dengan 64,3% dibandingkan GPT-5.5 yang mencapai 58,6%. Ini berarti untuk setiap 100 tugas perbaikan bug repositori nyata, Opus 4.7 dapat menyelesaikan sekitar 6 lebih banyak.
Yang lebih penting, Opus 4.7 mengalami peningkatan sebesar 10,9 poin persentase dibandingkan pendahulunya, Opus 4.6 (53,4%), sebuah lonjakan besar yang jarang terjadi dalam satu iterasi versi. Bagi tim yang alur kerjanya berfokus pada perbaikan issue GitHub, Claude Opus 4.7 adalah pilihan terbaik saat ini.
Saran Pengujian: Ingin memverifikasi perbedaan kinerja kedua model pada basis kode Anda sendiri? Anda dapat melakukan pengujian paralel melalui platform APIYI (apiyi.com). Platform ini mendukung pemanggilan antarmuka terpadu untuk GPT-5.5 dan Claude Opus 4.7 agar lebih mudah untuk dibandingkan secara cepat.
Analisis Praktis Terminal-Bench 2.0
Terminal-Bench 2.0 menguji kemampuan model dalam menyelesaikan tugas kompleks di lingkungan terminal, mencakup tiga dimensi: perencanaan, iterasi, dan koordinasi alat. GPT-5.5 memimpin jauh dengan 82,7% dibandingkan Opus 4.7 yang berada di 69,4%, selisihnya mencapai 13 poin persentase.
Kesenjangan ini berasal dari optimasi GPT-5.5 pada alur kerja Agentik: ia dapat memilih alat dengan lebih akurat, menangani tugas multi-langkah dengan lebih stabil, dan memulihkan diri dari kesalahan dengan lebih andal. Jika alur kerja Anda melibatkan banyak perintah shell, operasi file, atau integrasi CI/CD, GPT-5.5 adalah pilihan yang lebih kokoh.
Kesenjangan Kemampuan Pengambilan Konteks Panjang
Dalam pengujian MRCR v2 untuk pengambilan 8-needle pada rentang 512K-1M token, GPT-5.5 memimpin jauh dengan 74,0% dibandingkan Opus 4.7 yang hanya 32,2%—sebuah jurang perbedaan sebesar 41,8 poin persentase.
Ini berarti jika Anda perlu agar model memahami seluruh repositori kode (500K+ token), akurasi GPT-5.5 dalam mengingat konteks mendalam secara signifikan lebih tinggi. Untuk skenario seperti "refactoring berdasarkan monorepo lengkap", GPT-5.5 bukan sekadar lebih baik, melainkan perbedaan antara bisa dikerjakan atau tidak.
Rekomendasi Praktis Penggunaan GPT-5.5 dan Claude Opus 4.7 untuk Pemrograman
Data benchmark hanya akan bermakna jika diterapkan pada skenario spesifik. Tabel berikut memberikan rekomendasi yang jelas untuk 5 skenario pemrograman tipikal:
| Skenario Pemrograman | Model Rekomendasi | Alasan Utama | Keuntungan yang Diharapkan |
|---|---|---|---|
| Perbaikan GitHub Issue | Claude Opus 4.7 | Unggul 5,7 poin persentase di SWE-bench Pro | Peningkatan tingkat keberhasilan perbaikan 10% |
| Refactoring Codebase Besar | Claude Opus 4.7 | Kemampuan penalaran arsitektur antar file lebih baik | Mengurangi risiko kerusakan arsitektur |
| Otomatisasi Alur Agentic | GPT-5.5 | Unggul 13,3 poin persentase di Terminal-Bench | Stabilitas lebih tinggi pada tugas multi-langkah |
| Pemahaman Konteks Panjang (>500K) | GPT-5.5 | Unggul 41,8 poin persentase di MRCR v2 | Pengambilan konteks mendalam yang andal |
| Interaktif Pair Programming | Claude Opus 4.7 | TTFT hanya 0,5 detik, respons lebih cepat | Irama pengkodean lebih lancar |
| Pembuatan Kode Skala Besar | GPT-5.5 | Efisiensi token 72% lebih tinggi, biaya lebih murah | Efisiensi biaya keseluruhan yang lebih optimal |
Skenario 1: Memperbaiki GitHub Issue Real → Pilih Claude Opus 4.7
Jika kebutuhan utama Anda adalah "menerima deskripsi issue dan membiarkan AI memberikan PR yang bisa digabungkan (mergeable)", Claude Opus 4.7 adalah pilihan terbaik yang tidak terbantahkan. Skor 87,6% pada SWE-bench Verified berarti sekitar sembilan dari sepuluh tugas perbaikan bug yang terdefinisi dengan baik dapat diselesaikan secara langsung.
Perlu dicatat bahwa 87,6% tidak berarti 87,6% dari pekerjaan teknik Anda dapat diotomatisasi—ini adalah pengujian ideal berdasarkan "spesifikasi tugas yang sempurna". Dalam alur kerja nyata, kualitas deskripsi issue akan sangat memengaruhi tingkat keberhasilan.
Skenario 2: Pemahaman Kode Konteks Panjang → Pilih GPT-5.5
Saat Anda perlu membiarkan model membaca keseluruhan monorepo (biasanya 500K-1M token) sebelum mengambil keputusan, GPT-5.5 adalah satu-satunya pilihan yang andal saat ini. Akurasi pencarian 8-needle Opus 4.7 pada rentang konteks 1M hanya 32,2%, yang berarti model kemungkinan besar akan "melewatkan" definisi penting di kedalaman codebase.
Kesenjangan ini berada pada tingkat arsitektur—jika alur kerja Anda bergantung pada tampilan codebase yang lengkap (misalnya penggantian nama global, pemeriksaan kompatibilitas API), menggunakan Opus 4.7 mungkin membuat alur kerja Anda tidak berjalan sama sekali.
Skenario 3: Alur Kerja Pemrograman Agentic → Pilih GPT-5.5
Pemrograman Agentic merujuk pada alur kerja di mana AI secara mandiri merencanakan, memanggil alat, dan melakukan perbaikan iteratif. Skor 82,7% GPT-5.5 pada Terminal-Bench 2.0 jauh melampaui Opus 4.7, terutama stabil pada tugas-tugas berikut:
- Penulisan dan eksekusi skrip deployment otomatis
- Debugging multi-layanan dan analisis log
- Pemecahan masalah alur CI/CD
- Pembangunan dan pemantauan data pipeline
Saran Integrasi: Saat membangun alur kerja pemrograman Agentic, disarankan untuk memanggil GPT-5.5 melalui platform agregasi seperti APIYI (apiyi.com). Ini memudahkan pengelolaan kunci API yang terpadu, pemantauan biaya pemanggilan, dan peralihan ke model cadangan sesuai kebutuhan.
Skenario 4: Pair Programming Interaktif → Pilih Claude Opus 4.7
Pengalaman pengkodean interaktif sangat sensitif terhadap latensi. TTFT (Time To First Token / latensi token pertama) Opus 4.7 adalah sekitar 0,5 detik, sementara GPT-5.5 sekitar 3 detik. Kesenjangan 6 kali lipat ini sangat terasa dalam skenario interaksi yang sering.
Jika Anda menggunakan alat integrasi IDE seperti Cursor, Claude Code, atau Continue untuk melengkapi cuplikan kode kecil secara sering, latensi rendah dari Opus 4.7 akan memberikan ritme pengkodean yang jauh lebih lancar.

Berikut adalah panduan praktis untuk melakukan pemanggilan API GPT-5.5 dan Claude Opus 4.7.
Contoh Pemanggilan API GPT-5.5 dan Claude Opus 4.7
Berikut adalah contoh pemanggilan super ringkas untuk kedua model tersebut agar Anda dapat melakukan verifikasi dengan cepat. Keduanya kompatibel dengan format SDK OpenAI, sehingga biaya migrasinya sangat rendah.
Pemanggilan Ringkas GPT-5.5
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Implementasikan quick sort menggunakan Python"}]
)
print(response.choices[0].message.content)
Pemanggilan Ringkas Claude Opus 4.7
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Implementasikan quick sort menggunakan Python"}]
)
print(response.choices[0].message.content)
Lihat kode pengujian perbandingan paralel dua model
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Menguji waktu respons dan panjang output dari satu model"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Uji perbandingan kemampuan pemrograman
test_prompt = """
Harap implementasikan kelas LRU cache menggunakan Python, dengan ketentuan:
1. Mendukung metode get(key) dan put(key, value)
2. Secara otomatis membuang item yang paling jarang digunakan saat kapasitas penuh
3. Kompleksitas waktu untuk semua operasi adalah O(1)
4. Sertakan unit test yang lengkap
"""
# Uji paralel untuk kedua model
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']} detik, {gpt_result['output_tokens']} token")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']} detik, {claude_result['output_tokens']} token")
Saran Pengujian: Dapatkan kuota pengujian gratis melalui APIYI apiyi.com. Anda dapat melakukan pengujian paralel untuk GPT-5.5 dan Claude Opus 4.7 dalam satu akun, menggunakan base_url dan kunci API yang sama tanpa perlu mengajukan akun OpenAI dan Anthropic secara terpisah.
Analisis Biaya Komprehensif GPT-5.5 vs Claude Opus 4.7
Harga API adalah metrik penting yang harus dipertimbangkan saat memilih model. Sekilas, harga output Token Opus 4.7 terlihat 17% lebih murah, namun setelah analisis mendalam, faktanya justru sebaliknya:
| Dimensi Biaya | GPT-5.5 | Claude Opus 4.7 | Dampak Aktual |
|---|---|---|---|
| Harga Input | $5/juta token | $5/juta token | Setara |
| Harga Output | $30/juta token | $25/juta token | Opus lebih murah 17% |
| >200K Prompt | Harga tetap | Naik 2x ke $10/$37.50 | GPT unggul di konteks panjang |
| Output Token Tugas | 100% (baseline) | 72% lebih banyak dari GPT | GPT secara total lebih murah |
| Latensi TTFT | ~3 detik | ~0,5 detik | Opus terasa lebih cepat |
| Biaya Tugas Masif | 1.0x (baseline) | 1.4-1.5x (baseline) | GPT lebih hemat |
Temuan Utama Perbandingan Biaya
Efisiensi Token mengubah esensi perbandingan harga. Untuk tugas pemrograman yang sama, GPT-5.5 rata-rata mengonsumsi Token output 72% lebih sedikit daripada Opus 4.7. Meskipun harga per Token Opus 17% lebih murah, jika dikalikan dengan penggunaan Token yang 1,72 kali lipat lebih besar, biaya tugas aktual GPT-5.5 justru lebih rendah.
Kesenjangan semakin melebar pada skenario konteks panjang. Saat Prompt melebihi 200K token, harga input dan output Opus 4.7 naik dua kali lipat menjadi $10 dan $37.50, sementara GPT-5.5 tetap dengan harga asli. Untuk alur kerja yang membutuhkan pemahaman konteks panjang (seperti analisis monorepo lengkap), keunggulan biaya GPT-5.5 bisa mencapai 2-3 kali lipat.
Interpretasi Perbandingan
Karakteristik Biaya Claude Opus 4.7: Harga per Token sangat kompetitif di antara model mutakhir utama. Namun, dalam skenario pembuatan konten skala besar, konsumsi Token yang lebih tinggi akan meningkatkan total biaya; dalam skenario konteks panjang, mekanisme kenaikan harga dua kali lipat setelah 200K akan menambah beban anggaran secara signifikan.
Karakteristik Biaya GPT-5.5: Harga per Token sedikit lebih tinggi, namun efisiensi Token yang luar biasa dan kebijakan harga tetap pada konteks panjang membuatnya jauh lebih murah untuk penggunaan skala besar dan konteks panjang. OpenAI jelas mempertimbangkan struktur biaya alur kerja Agentic saat menetapkan harga.
Saran Perhitungan Biaya: Biaya proyek aktual dipengaruhi oleh berbagai faktor seperti panjang Prompt, panjang output, dan frekuensi pemanggilan. Disarankan untuk mengakses kedua model melalui platform APIYI apiyi.com yang menyediakan tagihan pemanggilan terperinci, sehingga memudahkan Anda dalam pengambilan keputusan berdasarkan data nyata.
FAQ Pertanyaan Umum
Q1: Antara GPT-5.5 dan Claude Opus 4.7, mana yang memiliki kemampuan pemrograman lebih baik?
Tidak ada jawaban "lebih baik" yang mutlak, semuanya bergantung pada tugas spesifik Anda. Claude Opus 4.7 memimpin di SWE-bench Pro (64,3% vs 58,6%) dan Verified (87,6%), menjadikannya pilihan lebih tepat untuk memperbaiki issue GitHub nyata serta melakukan refactoring basis kode skala besar. Sementara itu, GPT-5.5 unggul di Terminal-Bench 2.0 (82,7% vs 69,4%) dan pengambilan data dalam jendela konteks panjang (74,0% vs 32,2%), sehingga lebih cocok untuk alur kerja pemrograman berbasis Agent dan pemahaman kode di seluruh monorepo.
Q2: Apa perbedaan harga API antara GPT-5.5 dan Claude Opus 4.7?
Kedua model memiliki harga input token yang sama yaitu $5/M. Untuk output token, Opus 4.7 ($25/M) lebih murah 17% dibandingkan GPT-5.5 ($30/M). Namun, harga Opus 4.7 akan naik dua kali lipat jika prompt melebihi 200K, sedangkan GPT-5.5 tetap konsisten dengan harga awal. Mengingat konsumsi output token GPT-5.5 yang 72% lebih sedikit dibanding Opus, maka untuk tugas dalam skala besar, GPT-5.5 menawarkan biaya keseluruhan yang lebih hemat.
Q3: Kapan GPT-5.5 dan Claude Opus 4.7 dirilis?
Claude Opus 4.7 dirilis oleh Anthropic pada 16 April 2026 dan sudah tersedia secara penuh di Claude API, Amazon Bedrock, Google Cloud Vertex AI, dan Microsoft Foundry. GPT-5.5 (nama kode internal: Spud) dirilis oleh OpenAI pada 23 April 2026. Kedua model pemrograman tingkat atas ini diluncurkan hanya dengan selisih waktu 7 hari, menunjukkan persaingan yang sangat ketat.
Q4: Skenario pemrograman apa yang sebaiknya menggunakan Claude Opus 4.7?
Gunakan Opus 4.7 untuk skenario berikut:
- Memperbaiki issue GitHub: Unggul 5,7 poin persentase di SWE-bench Pro.
- Refactoring basis kode besar: Kemampuan penalaran arsitektur lintas file yang lebih kuat.
- Pair Programming interaktif: TTFT hanya 0,5 detik, respons 6 kali lebih cepat.
- Tinjauan kualitas kode: Skor kualitas kode lebih tinggi berdasarkan pengujian Rakuten-SWE-Bench.
Q5: Bagaimana cara melakukan pemanggilan model GPT-5.5 dan Claude Opus 4.7 melalui API dengan cepat?
Kami menyarankan untuk menggunakan platform agregasi API yang mendukung kedua model tersebut untuk pengujian:
- Kunjungi APIYI di apiyi.com untuk mendaftarkan akun.
- Dapatkan kunci API terpadu dan kuota uji coba gratis.
- Gunakan contoh kode dalam artikel ini (ganti
base_urlmenjadihttps://vip.apiyi.com/v1), lalu tentukanmodelkegpt-5.5atauclaude-opus-4-7untuk melakukan pemanggilan.
APIYI mendukung akses antarmuka terpadu untuk model-model populer seperti OpenAI, Anthropic, Google, dan lainnya, sehingga Anda bisa membandingkan performa GPT-5.5 dan Claude Opus 4.7 secara langsung tanpa perlu mendaftar ke banyak akun berbeda.
Q6: Apa saja keterbatasan yang diketahui dari GPT-5.5 dan Claude Opus 4.7?
Keterbatasan GPT-5.5:
- Latensi TTFT sekitar 3 detik, sehingga terasa lebih lambat dalam skenario interaktif.
- Performa dalam memperbaiki issue nyata di SWE-bench tidak sebaik Opus 4.7.
Keterbatasan Claude Opus 4.7:
- Kemampuan pengambilan data dalam jendela konteks panjang masih lemah (32,2% pada rentang 1M).
- Harga naik dua kali lipat saat prompt >200K, sehingga beban biaya konteks panjang cukup tinggi.
- Konsumsi output token lebih boros, biaya total untuk tugas berskala besar cenderung lebih mahal.
- Performa pada tugas berbasis Agent seperti Terminal-Bench tidak sebaik GPT-5.5.
Q7: Apakah perlu menggunakan GPT-5.5 dan Claude Opus 4.7 secara bersamaan?
Untuk tim pengembangan profesional, kami sangat menyarankan penggunaan keduanya secara bersamaan. Strategi pembagian tugas yang ideal adalah: gunakan Opus 4.7 untuk perbaikan issue GitHub, tinjauan kode, dan pengambilan keputusan arsitektur kunci; gunakan GPT-5.5 untuk analisis jendela konteks panjang, alur otomatisasi Agent, dan pembuatan kode dalam jumlah besar. Pola penggunaan campuran ini memungkinkan Anda memanfaatkan keunggulan masing-masing model sekaligus menyeimbangkan biaya dan pengalaman pengguna.
Poin Utama GPT-5.5 dan Claude Opus 4.7
- Perbaikan Issue Nyata pilih Opus: Claude Opus 4.7 unggul di SWE-bench Pro/Verified, menjadi pilihan utama untuk memperbaiki issue GitHub yang nyata.
- Pemrograman berbasis Agent pilih GPT: GPT-5.5 unggul 13 poin persentase di Terminal-Bench 2.0, dengan pemanggilan alat multi-langkah yang lebih stabil.
- Jendela konteks panjang pilih GPT: Dalam tes MRCR v2, GPT-5.5 (74%) jauh melampaui Opus (32,2%), menjadikannya satu-satunya pilihan andal untuk konteks 1M.
- Sensitivitas latensi pilih Opus: TTFT Opus hanya 0,5 detik, 6 kali lebih cepat dari GPT, memberikan pengalaman koding interaktif yang lebih lancar.
- Sensitivitas biaya pilih GPT: Output token GPT-5.5 72% lebih sedikit dari Opus, menghasilkan biaya tugas gabungan yang lebih hemat.
- Pengujian paralel cepat: Gunakan APIYI apiyi.com dengan satu akun untuk memanggil kedua model secara terpadu demi perbandingan skenario nyata yang mudah.
Ringkasan
Kesimpulan utama dari perbandingan kemampuan pemrograman antara GPT-5.5 dan Claude Opus 4.7:
- Tidak ada juara mutlak: Kedua model memiliki keunggulan yang jelas di bidangnya masing-masing, jadi mengejar "model terbaik" secara membabi buta adalah strategi yang keliru.
- Pemilihan berbasis tugas: Tentukan skenario pemrograman utama Anda terlebih dahulu (perbaikan issue / Agentic / jendela konteks panjang / interaktif), baru kemudian putuskan model andalan Anda.
- Disarankan menggunakan dua model sekaligus: Tim pengembang profesional harus mengakses kedua model secara bersamaan dan merutekan tugas ke pilihan yang paling optimal berdasarkan skenario, guna memaksimalkan hasil.
Jika Anda hanya bisa memilih satu: untuk perbaikan GitHub issue dan code review sehari-hari, pilihlah Claude Opus 4.7; untuk otomatisasi Agentic dan analisis jendela konteks panjang, pilihlah GPT-5.5.
Direkomendasikan untuk melakukan verifikasi pemilihan dengan cepat melalui APIYI (apiyi.com). Platform ini menyediakan antarmuka terpadu untuk GPT-5.5 dan Claude Opus 4.7, kuota uji coba gratis, dan tagihan yang terperinci, menjadikannya jalur paling praktis untuk membuat keputusan pemilihan model yang berbasis data.
Bacaan Lanjutan
Jika Anda tertarik dengan perbandingan pemrograman antara GPT-5.5 dan Claude Opus 4.7, kami merekomendasikan untuk membaca artikel berikut:
- 📘 Ulasan Lengkap Claude Opus 4.7: Kekuatan Rekayasa di Balik 87,6% SWE-bench – Analisis mendalam mengenai sumber kemampuan Opus 4.7.
- 📊 Panduan Pengujian GPT-5.5 Spud: 8 Tips Penggunaan untuk Sang Raja Baru Pemrograman Agentic – Kuasai penggunaan tingkat lanjut GPT-5.5.
- 🚀 Panduan Pemilihan Model Pemrograman AI 2026: Perbandingan Panorama dari GPT ke Claude – Jelajahi metodologi pemilihan model yang lebih makro.
📚 Referensi
-
Pengantar Resmi GPT-5.5 dari OpenAI: Tolok ukur inti dan penjelasan kemampuan
- Tautan:
openai.com/index/introducing-gpt-5-5 - Penjelasan: Dokumen rilis resmi GPT-5.5, mencakup tolok ukur utama seperti SWE-bench, Terminal-Bench, dan lainnya.
- Tautan:
-
Catatan Rilis Resmi Claude Opus 4.7 dari Anthropic: Penempatan model dan data performa
- Tautan:
anthropic.com/news/claude-opus-4-7 - Penjelasan: Dokumen rilis resmi Opus 4.7, berisi data mendalam tentang SWE-bench Verified/Pro.
- Tautan:
-
Papan Peringkat Publik SWE-Bench Pro: Verifikasi pihak ketiga independen
- Tautan:
labs.scale.com/leaderboard/swe_bench_pro_public - Penjelasan: Papan peringkat publik SWE-Bench Pro yang dikelola oleh Scale AI untuk memverifikasi peringkat nyata dari kedua model.
- Tautan:
-
Papan Peringkat LLM Vellum 2026: Perbandingan model AI komprehensif
- Tautan:
vellum.ai/llm-leaderboard - Penjelasan: Platform perbandingan komprehensif yang mencakup dimensi pemrograman, penalaran, jendela konteks panjang, dan lainnya.
- Tautan:
-
Perbandingan Model Artificial Analysis: Analisis performa dan biaya
- Tautan:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Penjelasan: Menyediakan data perbandingan mendetail mengenai TTFT (Time To First Token), throughput, dan biaya keseluruhan.
- Tautan:
Penulis: Tim Teknis APIYI
Diskusi Teknis: Mari berdiskusi di kolom komentar, informasi lebih lanjut dapat diakses di pusat dokumentasi APIYI melalui docs.apiyi.com