Nota del autor: Basado en 6 puntos de referencia clave, incluidos SWE-bench Pro, Terminal-Bench 2.0 y LiveCodeBench, realizamos un análisis comparativo profundo entre GPT-5.5 y Claude Opus 4.7 en escenarios de programación reales, ofreciendo recomendaciones claras para su elección.
La batalla por la supremacía en programación entre GPT-5.5 y Claude Opus 4.7 es el tema más candente en el ámbito de la IA de abril de 2026. Este artículo compara el OpenAI GPT-5.5 (nombre en clave Spud) y el Anthropic Claude Opus 4.7, ofreciendo recomendaciones precisas sobre qué modelo elegir basándonos en dimensiones como SWE-bench Pro, Terminal-Bench 2.0, recuperación de contexto largo, eficiencia de tokens y precios de la API.
Este no es un análisis equilibrado que intenta quedar bien con todos, sino una recomendación directa para diferentes escenarios basada en los datos oficiales de referencia. Anthropic lanzó Claude Opus 4.7 el 16 de abril de 2026 y OpenAI hizo lo propio con GPT-5.5 el 23 de abril. Dos modelos de primer nivel lanzados con solo 7 días de diferencia; el duelo por la superioridad en programación ha comenzado.
Valor principal: Tras leer este artículo, sabrás exactamente si debes elegir GPT-5.5 o Claude Opus 4.7 para 4 escenarios típicos: corrección de issues de GitHub, programación con agentes, refactorización de contextos largos y codificación interactiva.

Vista rápida de las diferencias principales entre GPT-5.5 y Claude Opus 4.7
Cada modelo tiene un posicionamiento distinto, lo que hace que sus fortalezas en programación sean totalmente diferentes. La siguiente tabla resume las diferencias clave:
| Dimensión de comparación | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Fecha de lanzamiento | 2026-04-23 | 2026-04-16 |
| Nombre en clave | Spud | – |
| Ventana de contexto | 1M tokens | 1M tokens |
| Salida máxima | 128K tokens | 128K tokens |
| Fortalezas clave | Programación con agentes, recuperación de contexto largo | Corrección de issues reales de GitHub, inferencia arquitectónica |
| TTFT típico | ~3 segundos | ~0.5 segundos |
| Eficiencia de tokens | 72% menos tokens de salida que Opus | Consumo de tokens mayor, pero alta precisión |
| Entrada API | $5/M tokens | $5/M tokens |
| Salida API | $30/M tokens | $25/M tokens |
| Recargo por prompt largo | Mantiene precio base >200K | Se duplica a $10/$37.50 >200K |
Posicionamiento de la capacidad de programación de GPT-5.5
GPT-5.5 es el modelo de programación con agentes más potente de OpenAI hasta la fecha. Destaca en flujos de trabajo de terminal, recuperación de contexto largo y coordinación entre herramientas, siendo especialmente adecuado para procesos de programación automatizados que requieren múltiples pasos e invocación de herramientas. OpenAI lo posiciona oficialmente como la primera opción para "tareas de programación de larga duración", demostrando en los benchmarks internos de Expert-SWE capacidad para gestionar cargas de trabajo equivalentes a 20 horas de trabajo humano.
Posicionamiento de la capacidad de programación de Claude Opus 4.7
Claude Opus 4.7 recupera el trono en tareas reales de ingeniería de software. Ha alcanzado un 87.6% en SWE-bench Verified y un 64.3% en SWE-bench Pro, superando significativamente a todos los competidores actuales. Las pruebas de Anthropic en el benchmark Rakuten-SWE-Bench muestran que Opus 4.7 resuelve tres veces más tareas de producción que su predecesor, el Opus 4.6, lo que lo hace ideal para corregir issues de GitHub o refactorizar bases de código masivas que requieren una profunda inferencia arquitectónica.
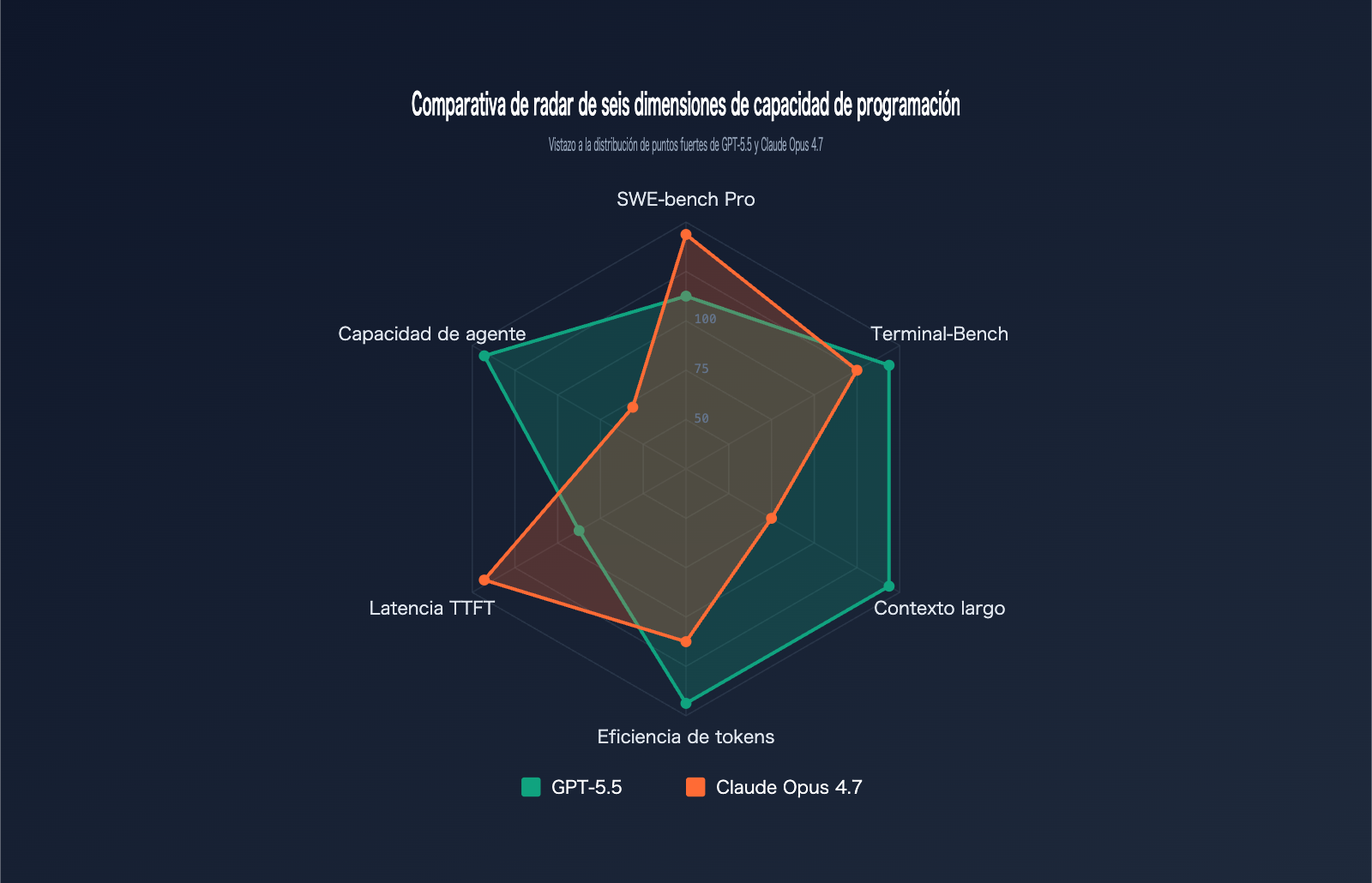
Comparativa de rendimiento: GPT-5.5 vs. Claude Opus 4.7
Los benchmarks son la vara de medir más objetiva para evaluar la capacidad de programación. Hemos recopilado los datos oficiales de ambos modelos en 6 pruebas de programación de referencia:
| Benchmark | Contenido de la prueba | GPT-5.5 | Claude Opus 4.7 | Ganador |
|---|---|---|---|---|
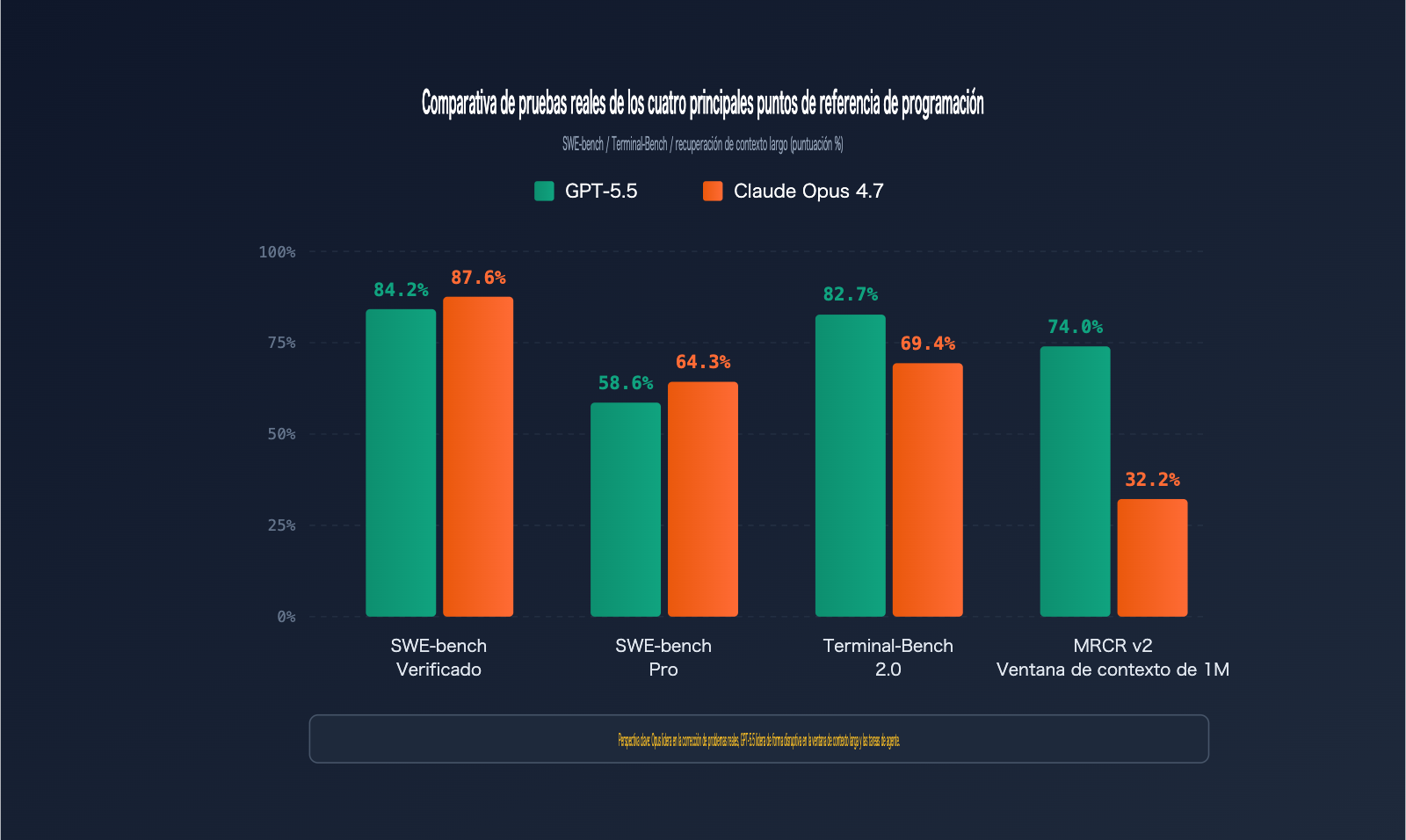
| SWE-bench Verified | Resolución de issues de GitHub verificada | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | Resolución de issues complejos en múltiples archivos | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | Flujos de trabajo de comandos en terminal | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | Programación de largo alcance (mediana de 20 horas) | 73.1% | – | GPT-5.5 |
| OSWorld-Verified | Tareas de agente de escritorio | 78.7% | 78.0% | GPT-5.5 (ligera ventaja) |
| MRCR v2 (512K-1M) | Recuperación de contexto largo (8-needle) | 74.0% | 32.2% | GPT-5.5 |
Análisis práctico de SWE-bench Pro
SWE-bench Pro es el estándar de oro para evaluar la capacidad de un modelo para corregir issues reales de GitHub. Claude Opus 4.7 lidera con un 64.3% frente al 58.6% de GPT-5.5, lo que significa que, por cada 100 tareas de reparación de errores en repositorios reales, Opus 4.7 puede resolver aproximadamente 6 más.
Más importante aún, Opus 4.7 ha mejorado 10.9 puntos porcentuales respecto a la generación anterior, Opus 4.6 (53.4%), un salto masivo poco común en una sola iteración de versión. Para equipos cuyo flujo de trabajo principal se basa en la resolución de issues de GitHub, Claude Opus 4.7 es la opción preferida actualmente.
Sugerencia de prueba: ¿Quieres verificar la diferencia de rendimiento entre ambos modelos en tu propio código? Puedes realizar pruebas paralelas a través de la plataforma APIYI (apiyi.com), la cual permite una invocación de modelo unificada para GPT-5.5 y Claude Opus 4.7, facilitando una comparación rápida.
Análisis práctico de Terminal-Bench 2.0
Terminal-Bench 2.0 evalúa la capacidad de un modelo para completar tareas complejas en un entorno de terminal, abarcando planificación, iteración y coordinación de herramientas. GPT-5.5 lidera con un 82.7%, superando por mucho el 69.4% de Opus 4.7, una brecha de 13 puntos porcentuales.
Esta diferencia se debe a las optimizaciones de GPT-5.5 en flujos de trabajo agentes: es más preciso al seleccionar herramientas, más estable al manejar tareas de múltiples pasos y más confiable para recuperarse de errores. Si tu trabajo involucra una gran cantidad de comandos shell, operaciones de archivo e integración CI/CD, GPT-5.5 es la elección más robusta.
Brecha en la capacidad de recuperación de contexto largo
En la prueba de recuperación 8-needle de MRCR v2 dentro del rango de 512K-1M tokens, GPT-5.5 aventaja a Opus 4.7 con un 74.0% frente a un 32.2%, una brecha significativa de 41.8 puntos.
Esto significa que, si necesitas que el modelo comprenda todo un repositorio de código (más de 500K tokens), la precisión de recuperación de contexto profundo de GPT-5.5 es notablemente superior. En escenarios como "refactorización basada en un monorepo completo", la diferencia de GPT-5.5 no es solo "ser mejor", sino la diferencia entre poder realizar o no la tarea.
Análisis práctico de GPT-5.5 y Claude Opus 4.7 en escenarios de programación
Los datos de evaluación (benchmarks) solo cobran sentido cuando se aplican a escenarios concretos. La siguiente tabla presenta recomendaciones claras para 5 tipos de escenarios de programación típicos:
| Escenario de programación | Modelo recomendado | Motivo principal | Beneficio esperado |
|---|---|---|---|
| Corrección de GitHub Issues | Claude Opus 4.7 | Lidera en SWE-bench Pro por 5.7 puntos | Mejora del 10% en éxito de reparación |
| Refactorización de base de código grande | Claude Opus 4.7 | Mayor capacidad de razonamiento de arquitectura | Menor riesgo de ruptura estructural |
| Flujos de trabajo con agentes | GPT-5.5 | Lidera en Terminal-Bench por 13.3 puntos | Mayor estabilidad en tareas de varios pasos |
| Comprensión de contexto largo (>500K) | GPT-5.5 | Lidera en MRCR v2 por 41.8 puntos | Recuperación confiable de contexto profundo |
| Pair Programming interactivo | Claude Opus 4.7 | TTFT de solo 0.5s, respuesta más rápida | Ritmo de codificación más fluido |
| Generación masiva de código | GPT-5.5 | 72% más eficiente en tokens, menor costo | Optimización de costos generales |
Escenario 1: Reparar un GitHub Issue real → Elegir Claude Opus 4.7
Si tu necesidad principal es "recibir la descripción de un issue y que la IA genere un PR combinable", Claude Opus 4.7 es la opción ganadora sin lugar a dudas. Su puntuación del 87.6% en SWE-bench Verified significa que cerca del 90% de las tareas de corrección de errores bien definidas pueden entregarse directamente.
Ten en cuenta que un 87.6% no equivale a que el 87.6% de tu trabajo de ingeniería se automatice; esta es una prueba ideal basada en una "especificación perfecta". En un flujo de trabajo real, la calidad de la descripción del issue afectará significativamente la tasa de éxito.
Escenario 2: Comprensión de código con contexto largo → Elegir GPT-5.5
Cuando necesitas que el modelo lea todo un monorepo (generalmente entre 500K y 1M de tokens) antes de tomar decisiones, GPT-5.5 es la única opción confiable actualmente. La precisión de recuperación "8-needle" de Opus 4.7 en el rango de 1M de contexto es de solo el 32.2%, lo que significa que es probable que el modelo "no vea" definiciones críticas en las profundidades del repositorio.
Esta brecha es a nivel arquitectónico: si tu flujo de trabajo depende de una visión completa del código (por ejemplo, cambios de nombre globales o comprobaciones de compatibilidad de API), es posible que con Opus 4.7 el flujo ni siquiera funcione.
Escenario 3: Flujos de trabajo de programación con agentes → Elegir GPT-5.5
La programación con agentes se refiere a flujos donde la IA planifica, utiliza herramientas e itera correcciones de forma autónoma. La puntuación del 82.7% de GPT-5.5 en Terminal-Bench 2.0 supera ampliamente a Opus 4.7, mostrando especial estabilidad en:
- Escritura y ejecución de scripts de despliegue automatizados.
- Depuración de servicios múltiples y análisis de registros.
- Solución de problemas en tuberías (pipelines) de CI/CD.
- Construcción y monitoreo de tuberías de datos.
Sugerencia de integración: Al construir flujos de trabajo de programación con agentes, recomendamos usar plataformas de agregación como APIYI (apiyi.com) para invocar GPT-5.5; esto facilita la gestión unificada de claves API, el monitoreo de costos y el cambio de modelos alternativos según sea necesario.
Escenario 4: Pair Programming interactivo → Elegir Claude Opus 4.7
La experiencia de codificación interactiva es extremadamente sensible a la latencia. El TTFT (latencia del primer token) de Opus 4.7 es de unos 0.5 segundos, mientras que el de GPT-5.5 es de unos 3 segundos. Esta diferencia de 6 veces es muy perceptible en escenarios de interacción frecuente.
Si utilizas herramientas de integración en IDEs como Cursor, Claude Code o Continue para completar fragmentos de código frecuentes, la baja latencia de Opus 4.7 te permitirá mantener un ritmo de trabajo mucho más fluido.

Ejemplos de invocación de API para GPT-5.5 y Claude Opus 4.7
A continuación, presento ejemplos mínimos de invocación para ambos modelos, para que puedas verificarlos rápidamente. Ambos son compatibles con el formato del SDK de OpenAI, por lo que el coste de migración es mínimo.
Invocación mínima para GPT-5.5
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Implementa una ordenación rápida (quicksort) en Python"}]
)
print(response.choices[0].message.content)
Invocación mínima para Claude Opus 4.7
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Implementa una ordenación rápida (quicksort) en Python"}]
)
print(response.choices[0].message.content)
Ver código de prueba comparativa en paralelo para ambos modelos
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Prueba el tiempo de respuesta y la longitud de salida de un único modelo"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Prueba comparativa de capacidad de programación
test_prompt = """
Por favor, implementa una clase de caché LRU en Python. Requisitos:
1. Soporta métodos get(key) y put(key, value)
2. Elimina automáticamente el elemento usado menos recientemente cuando esté llena
3. Complejidad temporal de O(1) para todas las operaciones
4. Incluye pruebas unitarias completas
"""
# Prueba en paralelo de ambos modelos
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
Sugerencia de prueba: Obtén saldo de prueba gratuito a través de APIYI (apiyi.com). Puedes probar GPT-5.5 y Claude Opus 4.7 en paralelo bajo la misma cuenta usando una base_url y clave API unificadas, sin necesidad de solicitar cuentas de OpenAI y Anthropic por separado.
Análisis de coste integral: GPT-5.5 vs. Claude Opus 4.7
El precio de la API es un factor crítico al seleccionar un modelo. A primera vista, los tokens de salida de Opus 4.7 parecen ser un 17% más baratos, pero tras un análisis exhaustivo, la realidad es distinta:
| Dimensión de coste | GPT-5.5 | Claude Opus 4.7 | Impacto real |
|---|---|---|---|
| Precio de entrada | $5/M tokens | $5/M tokens | Igualado |
| Precio de salida | $30/M tokens | $25/M tokens | Opus es 17% más barato |
| Prompt >200K | Mantiene precio | Doble: $10/$37.50 | GPT superior en contexto largo |
| Tokens por tarea | 100% base | 72% más que GPT | GPT es más barato en conjunto |
| Latencia TTFT | ~3 segundos | ~0.5 segundos | Opus ofrece mejor experiencia |
| Coste en volumen | 1.0x base | 1.4-1.5x base | GPT ahorra más dinero |
Hallazgos clave sobre la comparativa de costes
La eficiencia de los tokens altera la esencia de la comparación de precios. En las mismas tareas de programación, GPT-5.5 consume de media un 72% menos de tokens de salida que Opus 4.7. Incluso si Opus tiene un precio unitario un 17% menor, al multiplicarlo por el uso de tokens (1.72x), el coste real de la tarea con GPT-5.5 termina siendo menor.
La brecha se amplía en escenarios de ventana de contexto extensa. Cuando el prompt supera los 200K tokens, los precios de entrada y salida de Opus 4.7 se duplican a $10 y $37.50, mientras que GPT-5.5 mantiene su precio original. Para flujos de trabajo que requieren comprensión de contexto largo (como el análisis de un repositorio completo), la ventaja de costes de GPT-5.5 puede ser de 2 a 3 veces superior.
Interpretación de la comparativa
Características de coste de Claude Opus 4.7: Su precio por token es competitivo entre los modelos de vanguardia. Sin embargo, en escenarios de generación a gran escala, su mayor consumo de tokens eleva el coste total; además, la duplicación de precio al superar los 200K tokens aumenta la presión presupuestaria.
Características de coste de GPT-5.5: Su precio por token es ligeramente más alto, pero su excelente eficiencia y la ausencia de recargos por contexto largo hacen que el coste total sea menor en escenarios de escala masiva y contextos extensos. Claramente, OpenAI ha tenido en cuenta la estructura de costes de los flujos de trabajo de agentes al diseñar sus precios.
Recomendación para el cálculo de costes: El coste real del proyecto depende de múltiples factores como la longitud del prompt, la longitud de la salida y la frecuencia de las invocaciones. Te sugiero acceder a ambos modelos a través de la plataforma APIYI (apiyi.com), la cual ofrece facturas detalladas por invocación, facilitando así la toma de decisiones basada en datos reales.
Preguntas frecuentes (FAQ)
Q1: ¿Qué modelo tiene mejores capacidades de programación: GPT-5.5 o Claude Opus 4.7?
No existe un "mejor" absoluto; todo depende de la tarea. Claude Opus 4.7 destaca en SWE-bench Pro (64,3% frente a 58,6%) y Verified (87,6%), lo que lo hace ideal para corregir incidencias reales de GitHub y realizar refactorizaciones en bases de código grandes. Por su parte, GPT-5.5 lidera en Terminal-Bench 2.0 (82,7% frente a 69,4%) y en recuperación de contexto largo (74,0% frente a 32,2%), siendo más adecuado para flujos de trabajo de programación mediante agentes y para la comprensión de código a través de repositorios completos (monorepos).
Q2: ¿Cuál es la diferencia de precios de la API entre GPT-5.5 y Claude Opus 4.7?
Ambos cuestan $5/M por tokens de entrada. En cuanto a los tokens de salida, Opus 4.7 ($25/M) es un 17% más barato que GPT-5.5 ($30/M). Sin embargo, el precio de Opus 4.7 se duplica cuando el prompt supera los 200K tokens, mientras que GPT-5.5 mantiene su precio original. Si consideramos además que GPT-5.5 consume un 72% menos de tokens de salida que Opus, el coste operativo total de GPT-5.5 resulta inferior en tareas masivas.
Q3: ¿Cuándo se lanzaron GPT-5.5 y Claude Opus 4.7?
Claude Opus 4.7 fue lanzado por Anthropic el 16 de abril de 2026 y ya está disponible en la API de Claude, Amazon Bedrock, Google Cloud Vertex AI y Microsoft Foundry. GPT-5.5 (nombre en clave interno: Spud) fue lanzado por OpenAI el 23 de abril de 2026. Ambos modelos de élite fueron lanzados con apenas 7 días de diferencia, marcando una competencia intensa.
Q4: ¿En qué escenarios de programación se recomienda elegir Claude Opus 4.7?
Se recomienda optar por Opus 4.7 en los siguientes casos:
- Corrección de incidencias en GitHub: supera a otros modelos en 5,7 puntos porcentuales en SWE-bench Pro.
- Refactorización de bases de código grandes: mayor capacidad de razonamiento arquitectónico entre archivos.
- Programación en pareja interactiva: TTFT (tiempo hasta el primer token) de solo 0,5 segundos, 6 veces más rápido.
- Revisión de calidad de código: mayor puntuación en pruebas reales de calidad de código según Rakuten-SWE-Bench.
Q5: ¿Cómo realizar llamadas a la API de GPT-5.5 y Claude Opus 4.7 rápidamente?
Recomendamos utilizar una plataforma de agregación de API que admita ambos modelos para realizar pruebas:
- Visita APIYI en apiyi.com y crea una cuenta.
- Obtén tu clave API unificada y saldo de prueba gratuito.
- Utiliza el código de ejemplo de este artículo (reemplazando
base_urlporhttps://vip.apiyi.com/v1) y especifica el modelo comogpt-5.5oclaude-opus-4-7según sea necesario.
APIYI admite la integración unificada de interfaces para modelos principales como OpenAI, Anthropic y Google, lo que te permite comparar el rendimiento real de GPT-5.5 y Claude Opus 4.7 sin necesidad de registrar múltiples cuentas por separado.
Q6: ¿Cuáles son las limitaciones conocidas de GPT-5.5 y Claude Opus 4.7?
Limitaciones de GPT-5.5:
- Latencia de TTFT de unos 3 segundos, lo que ralentiza la experiencia en escenarios interactivos.
- Rendimiento inferior al de Opus 4.7 en la corrección de incidencias reales de SWE-bench.
Limitaciones de Claude Opus 4.7:
- Capacidad débil de recuperación en contextos largos (32,2% en rangos de 1M).
- El precio se duplica con prompts >200K, generando presión de costes en contextos extensos.
- Consumo elevado de tokens de salida, lo que aumenta el coste global en tareas masivas.
- Rendimiento inferior a GPT-5.5 en tareas de agentes como Terminal-Bench.
Q7: ¿Vale la pena utilizar GPT-5.5 y Claude Opus 4.7 al mismo tiempo?
Para equipos de desarrollo profesionales, se recomienda encarecidamente utilizar ambos. Una estrategia de división de tareas eficaz sería: usar Opus 4.7 para la corrección de incidencias en GitHub, revisiones de código y decisiones de arquitectura clave; y emplear GPT-5.5 para el análisis de contextos largos, procesos de automatización mediante agentes y generación masiva de código. Este modelo híbrido permite aprovechar las fortalezas de cada uno, logrando un equilibrio entre costes y experiencia de usuario.
Puntos clave de GPT-5.5 y Claude Opus 4.7
- Para corrección de incidencias reales, elige Opus: Claude Opus 4.7 lidera tanto en SWE-bench Pro como en Verified, siendo la opción preferida para resolver incidencias de GitHub.
- Para programación mediante agentes, elige GPT: GPT-5.5 aventaja en 13 puntos porcentuales en Terminal-Bench 2.0, ofreciendo llamadas a herramientas multietapa más estables.
- Para contextos largos, elige GPT: En las pruebas MRCR v2, GPT-5.5 (74%) supera ampliamente a Opus (32,2%), siendo la única opción fiable para contextos de 1M.
- Para baja latencia, elige Opus: El TTFT de Opus es de solo 0,5 segundos, 6 veces más rápido que GPT, ofreciendo una experiencia de codificación más fluida.
- Para optimización de costes, elige GPT: GPT-5.5 consume un 72% menos de tokens de salida que Opus, resultando más económico para tareas generales.
- Pruebas paralelas rápidas: Con una cuenta de APIYI (apiyi.com), puedes invocar ambos modelos de forma unificada, facilitando una comparación en escenarios reales.
Resumen
Conclusiones clave de la comparativa de capacidades de programación entre GPT-5.5 y Claude Opus 4.7:
- No hay un campeón absoluto: Ambos modelos tienen áreas de fortaleza muy claras; buscar ciegamente "el mejor modelo" es un enfoque equivocado.
- Selección basada en tareas: Primero define tu escenario de programación principal (corrección de issues, flujos Agentic, contexto largo o interactivo) y luego decide qué modelo será tu principal herramienta.
- Se recomienda el uso paralelo de ambos: Los equipos de desarrollo profesionales deberían integrar ambos modelos y enrutar las tareas al modelo óptimo según el escenario para maximizar la productividad.
Si solo puedes elegir uno: para el trabajo diario centrado en la resolución de issues de GitHub y revisiones de código, elige Claude Opus 4.7; si tu enfoque principal es la automatización Agentic y el análisis de contexto largo, elige GPT-5.5.
Te recomendamos utilizar APIYI (apiyi.com) para validar rápidamente tu elección. La plataforma ofrece una interfaz unificada para GPT-5.5 y Claude Opus 4.7, cuotas de prueba gratuitas y una facturación detallada, siendo la vía más sencilla para tomar decisiones de selección basadas en datos.
Lecturas recomendadas
Si te interesa la comparativa de programación entre GPT-5.5 y Claude Opus 4.7, te recomendamos seguir leyendo:
- 📘 Análisis completo de Claude Opus 4.7: La destreza de ingeniería detrás del 87.6% en SWE-bench – Un análisis profundo de las capacidades de Opus 4.7.
- 📊 Guía de pruebas de GPT-5.5 Spud: 8 trucos para el nuevo rey de la programación Agentic – Domina el uso avanzado de GPT-5.5.
- 🚀 Guía de selección de modelos de programación con IA 2026: Comparativa panorámica de GPT a Claude – Explora metodologías más generales para la selección de modelos.
📚 Referencias
-
Introducción oficial de GPT-5.5 de OpenAI: Benchmark central y explicación de capacidades
- Enlace:
openai.com/index/introducing-gpt-5-5 - Descripción: Documento oficial de lanzamiento de GPT-5.5, que incluye benchmarks principales como SWE-bench y Terminal-Bench.
- Enlace:
-
Notas de lanzamiento de Claude Opus 4.7 de Anthropic: Posicionamiento del modelo y datos de rendimiento
- Enlace:
anthropic.com/news/claude-opus-4-7 - Descripción: Documento oficial de lanzamiento de Opus 4.7, con datos detallados de SWE-bench Verified/Pro.
- Enlace:
-
Clasificación pública de SWE-Bench Pro: Verificación independiente de terceros
- Enlace:
labs.scale.com/leaderboard/swe_bench_pro_public - Descripción: La clasificación pública de SWE-Bench Pro mantenida por Scale AI, donde se puede verificar el ranking real de ambos modelos.
- Enlace:
-
Vellum LLM Leaderboard 2026: Comparativa integral de modelos de IA
- Enlace:
vellum.ai/llm-leaderboard - Descripción: Plataforma de comparación exhaustiva que abarca múltiples dimensiones como programación, razonamiento y ventanas de contexto largas.
- Enlace:
-
Comparativa de modelos de Artificial Analysis: Análisis de rendimiento y costes
- Enlace:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Descripción: Ofrece datos comparativos detallados sobre TTFT, rendimiento (throughput) y coste total.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Te invitamos a participar en la sección de comentarios. Para más información, puedes visitar el centro de documentación de APIYI en docs.apiyi.com.