執筆者注:SWE-bench Pro、Terminal-Bench 2.0、LiveCodeBench など 6 つの主要なベンチマークに基づき、実際のプログラミングシーンにおける GPT-5.5 と Claude Opus 4.7 の能力差を深く比較し、明確な選定指針を提示します。
GPT-5.5 と Claude Opus 4.7 のプログラミング能力をめぐる争いは、2026 年 4 月の AI プログラミング分野で最も注目されている話題です。本稿では OpenAI GPT-5.5(コードネーム:Spud) と Anthropic Claude Opus 4.7 を比較し、SWE-bench Pro、Terminal-Bench 2.0、長文コンテキスト検索、トークン効率、API 価格など、多角的な視点から明確な選定アドバイスを提供します。
「それぞれ一長一短がある」といった妥協的な分析ではありません。 公式発表されたベンチマークデータに基づき、特定のシナリオにおいてどちらを選択すべきか、直球で推奨を提示します。Anthropic が 2026 年 4 月 16 日に Claude Opus 4.7 をリリースし、続いて OpenAI が 4 月 23 日に GPT-5.5 を発表。わずか 7 日間で登場したこのトップレベルのモデル同士による、プログラミング能力の対決が幕を開けました。
核心的価値:この記事を読めば、GitHub Issue の修正、Agentic プログラミング、長文コンテキストのリファクタリング、インタラクティブなコーディングという 4 つの典型的なシナリオにおいて、GPT-5.5 と Claude Opus 4.7 のどちらを選ぶべきかが明確になります。

GPT-5.5 と Claude Opus 4.7 の主な違い
両モデルはターゲットとする領域が異なるため、プログラミング能力の強みも大きく異なります。以下の表は、プログラミング関連の主要項目における違いをまとめたものです。
| 比較項目 | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| リリース日 | 2026-04-23 | 2026-04-16 |
| コードネーム | Spud | – |
| コンテキストウィンドウ | 1M tokens | 1M tokens |
| 最大出力 | 128K tokens | 128K tokens |
| 強み | Agentic プログラミング、長文コンテキスト検索 | GitHub issue 修正、アーキテクチャ推論 |
| 典型的な TTFT | ~3秒 | ~0.5秒 |
| トークン効率 | 出力トークンが Opus より 72% 少ない | トークン消費量は多いが精度が高い |
| API 入力 | $5/M tokens | $5/M tokens |
| API 出力 | $30/M tokens | $25/M tokens |
| 大規模プロンプト割増 | 200K 超でも同価格 | 200K 超で倍額の $10/$37.50 |
GPT-5.5 のプログラミング能力
GPT-5.5 は、OpenAI が現在提供する最も強力な Agentic プログラミングモデルです。ターミナルワークフローや長文コンテキストの検索、ツール間の連携に優れており、特に多段階でツール呼び出しを必要とする自動化されたプログラミングタスクに適しています。OpenAI 公式は、本モデルを「長距離プログラミングタスク」の第一選択肢として位置づけており、Expert-SWE 内部ベンチマークでは 20 時間分に相当する人間レベルの作業を処理できることが示されています。
Claude Opus 4.7 のプログラミング能力
Claude Opus 4.7 は、実際のソフトウェアエンジニアリングのタスクにおいて再び王座を奪還しました。SWE-bench Verified で 87.6%、SWE-bench Pro で 64.3% というスコアを叩き出し、既存の全競合製品を圧倒しています。Anthropic による Rakuten-SWE-Bench の実測テストでは、Opus 4.7 が解決した本番環境のタスク数は Opus 4.6 の 3 倍に達しており、特に GitHub issue の修正や、高度なアーキテクチャ推論を必要とする大規模コードベースのリファクタリングに最適です。
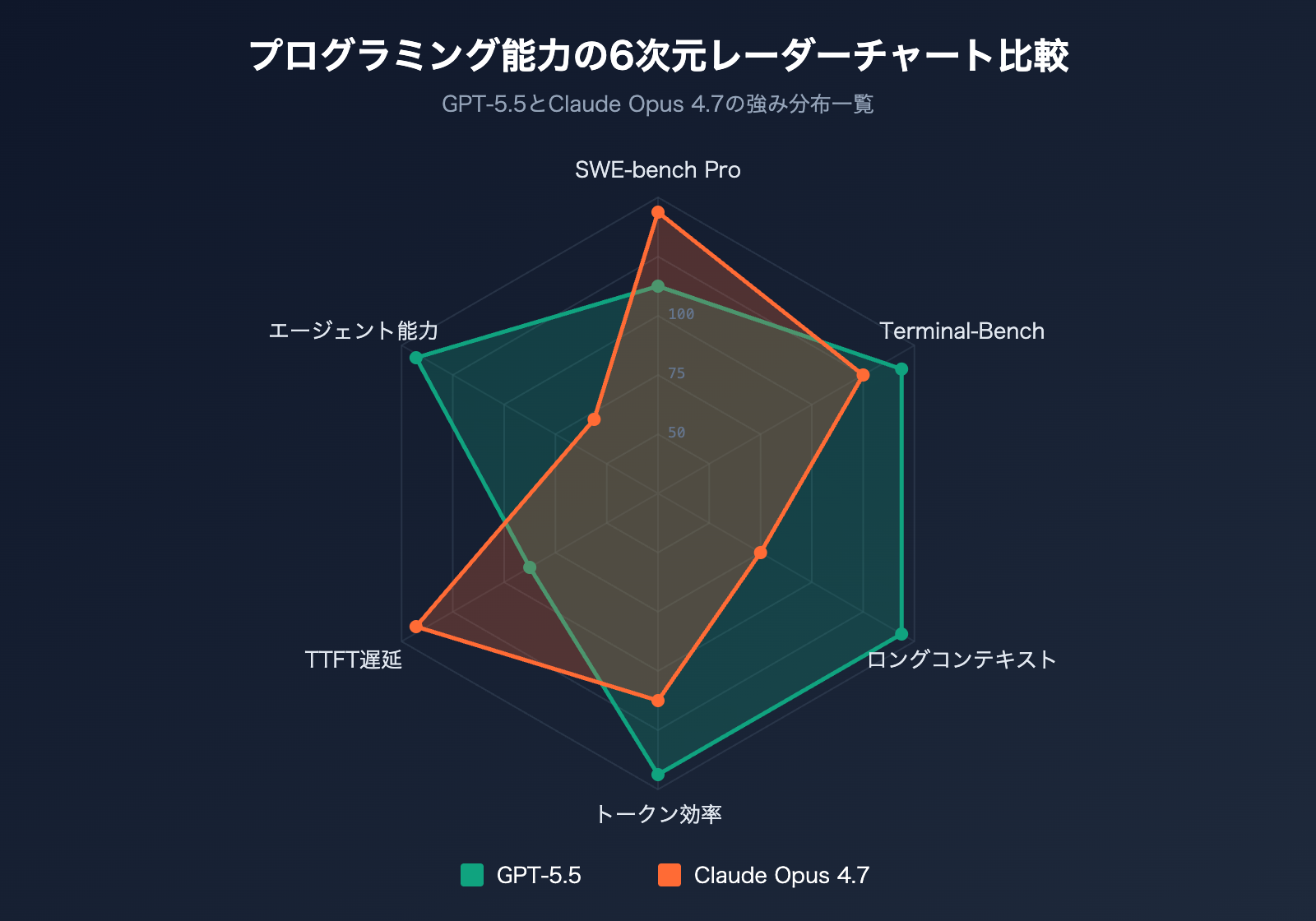
GPT-5.5 と Claude Opus 4.7 のベンチマーク実測比較
ベンチマークは、プログラミング能力を判断するための最も客観的な物差しです。ここでは、両モデルの 6 つの主要なプログラミング・ベンチマークにおける公式データをまとめました。
| ベンチマーク | テスト内容 | GPT-5.5 | Claude Opus 4.7 | 勝者 |
|---|---|---|---|---|
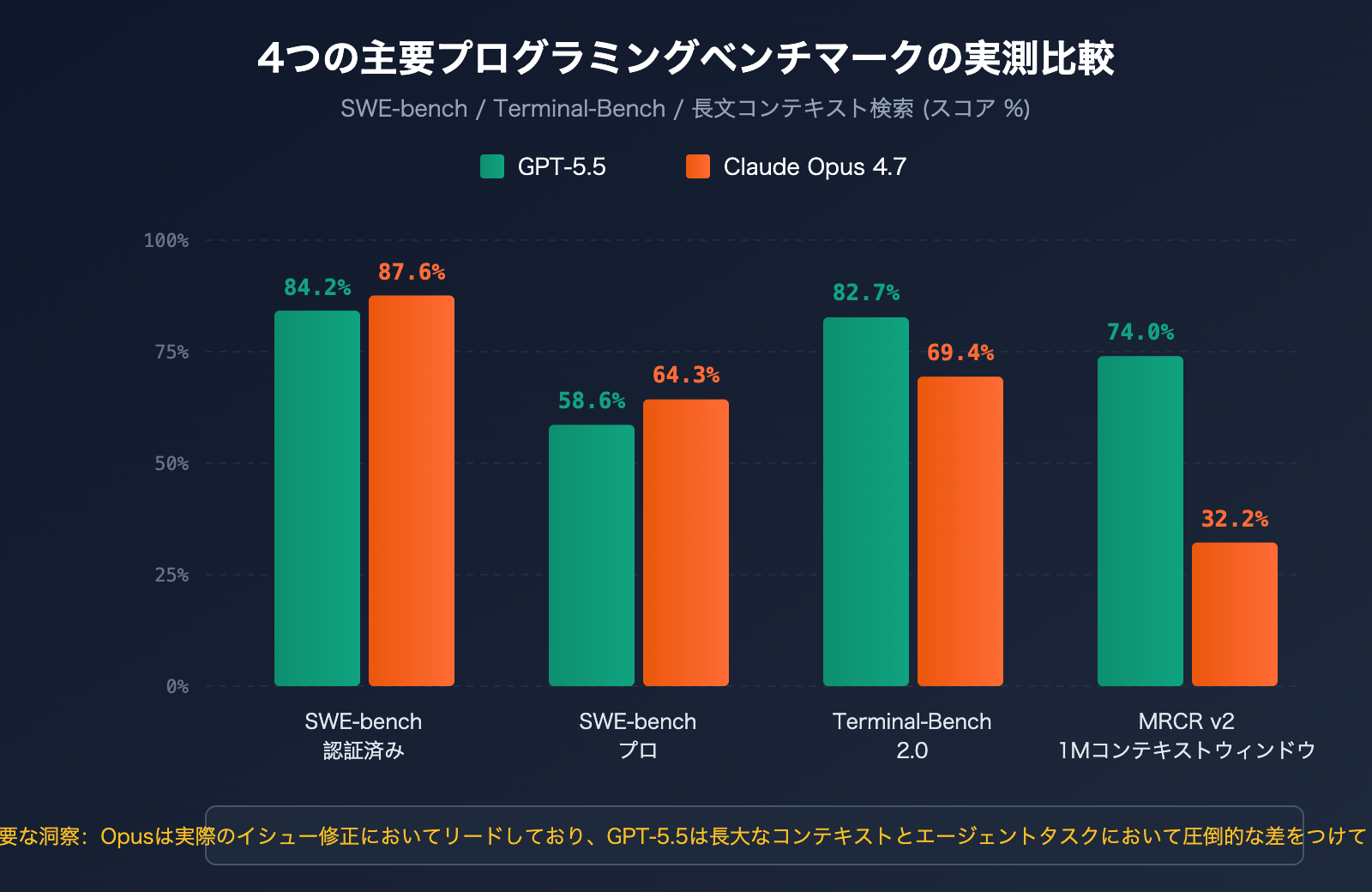
| SWE-bench Verified | 検証済み GitHub issue 修正 | 84.2% | 87.6% | Opus 4.7 |
| SWE-bench Pro | マルチファイル複雑 issue 修正 | 58.6% | 64.3% | Opus 4.7 |
| Terminal-Bench 2.0 | ターミナルコマンドワークフロー | 82.7% | 69.4% | GPT-5.5 |
| Expert-SWE | 長期プログラミング(中央値 20 時間) | 73.1% | – | GPT-5.5 |
| OSWorld-Verified | デスクトップ Agent タスク | 78.7% | 78.0% | GPT-5.5(僅差) |
| MRCR v2 (512K-1M) | 長文脈 8-needle 検索 | 74.0% | 32.2% | GPT-5.5 |
SWE-bench Pro 実戦分析
SWE-bench Pro は、モデルが実際の GitHub issue を解決する能力を評価するためのゴールドスタンダードです。Claude Opus 4.7 は 64.3% を記録し、GPT-5.5 の 58.6% を上回りました。これは、100 件の実際のコードベースのバグ修正タスクにおいて、Opus 4.7 が約 6 件多く解決できることを意味します。
さらに重要なのは、Opus 4.7 が前世代の Opus 4.6(53.4%)から 10.9 パーセントポイントも向上した点です。これは単一のバージョンアップとしては異例の大きな飛躍です。GitHub issue の修正を主なワークフローとするチームにとって、現在 Claude Opus 4.7 は最良の選択肢と言えます。
テスト推奨事項:両モデルが自社のコードベースでどのようなパフォーマンスを発揮するかを確認したい場合は、APIYI (apiyi.com) プラットフォームでの並列テストをお試しください。このプラットフォームは GPT-5.5 と Claude Opus 4.7 の共通インターフェース呼び出しに対応しており、迅速な比較に最適です。
Terminal-Bench 2.0 実戦分析
Terminal-Bench 2.0 は、ターミナル環境で複雑なタスクを完了する能力(計画、反復、ツール調整の 3 つの側面)をテストします。GPT-5.5 は 82.7% を記録し、Opus 4.7 の 69.4% を 13 パーセントポイントも引き離しました。
この差は、GPT-5.5 が Agentic ワークフロー向けに最適化されていることに起因します。GPT-5.5 はツールの選択においてより正確であり、マルチステップタスクの処理がより安定しており、エラーからの復旧も信頼性が高いです。大量のシェルコマンド、ファイル操作、CI/CD 統合を含むワークフローであれば、GPT-5.5 がより堅実な選択となります。
長文脈検索能力の差
MRCR v2 における 512K-1M トークンの範囲での 8-needle 検索テストでは、GPT-5.5 が 74.0% を記録し、Opus 4.7 の 32.2% を大きく引き離しました。その差は実に 41.8 パーセントポイントに及びます。
これは、コードリポジトリ全体(500K+ トークン)をモデルに理解させる必要がある場合、GPT-5.5 の深層コンテキストに対する想起精度が圧倒的に高いことを示しています。「モノレポ全体のリファクタリング」といったシナリオでは、GPT-5.5 は単に「優れている」というだけでなく、実行の可否を分ける決定的な違いとなります。
GPT-5.5 と Claude Opus 4.7 プログラミング実践ガイド
ベンチマークのデータは、具体的なシナリオに落とし込んで初めて意味を持ちます。以下の表では、5つの典型的なプログラミングシナリオにおける推奨モデルをまとめました。
| プログラミングシナリオ | 推奨モデル | 核心的な理由 | 期待されるメリット |
|---|---|---|---|
| GitHub Issue 修正 | Claude Opus 4.7 | SWE-bench Pro で 5.7 ポイントリード | 修正成功率 10% 向上 |
| 大規模コードベースのリファクタリング | Claude Opus 4.7 | ファイル横断的な推論能力が強力 | アーキテクチャ破壊リスクの低減 |
| Agentic 自動化ワークフロー | GPT-5.5 | Terminal-Bench で 13.3 ポイントリード | 多段階タスクの安定性が高い |
| 長コンテキスト(>500K)理解 | GPT-5.5 | MRCR v2 で 41.8 ポイントリード | 深層コンテキスト検索が確実 |
| 対話型ペアプログラミング | Claude Opus 4.7 | TTFT 0.5 秒で圧倒的に高速 | コーディングリズムが円滑に |
| 大量のコード生成 | GPT-5.5 | トークン効率 72% 向上、コスト低減 | 総コストの最適化 |
シナリオ1:GitHub Issue の修正 → Claude Opus 4.7 を選択
「Issue の内容を受け取り、マージ可能な PR を生成する」ことが最優先であれば、Claude Opus 4.7 が間違いなく最適な選択です。SWE-bench Verified において 87.6% というスコアを記録しており、定義が明確なバグ修正タスクの約 9 割を直接完了させることができます。
注意点として、87.6% という数値は「開発業務が 87.6% 自動化できる」という意味ではありません。これは「完璧に定義されたタスク」に対する理想的なテスト結果です。実際のワークフローでは、Issue の記述品質が成功率に大きな影響を与えることを覚えておきましょう。
シナリオ2:長コンテキストのコード理解 → GPT-5.5 を選択
モノレポ全体(通常 500K〜1M トークン)を読み込ませて意思決定を行う必要がある場合、現時点で GPT-5.5 が唯一信頼できる選択肢です。Opus 4.7 は 1M コンテキスト領域における 8-needle 検索精度が 32.2% に留まっており、コードベースの深層にある重要な定義を見落とす可能性があります。
この差はアーキテクチャレベルのものです。プロジェクト全体を俯瞰した作業(グローバルなリネームや API 互換性チェックなど)が必要な場合、Opus 4.7 ではワークフローが完結しない恐れがあります。
シナリオ3:Agentic プログラミングワークフロー → GPT-5.5 を選択
Agentic プログラミングとは、AI が自律的に計画を立て、ツールを呼び出し、修正を繰り返すワークフローのことです。GPT-5.5 は Terminal-Bench 2.0 で 82.7% というスコアを叩き出し、Opus 4.7 を圧倒しています。特に以下のタスクで安定した性能を発揮します。
- 自動化デプロイスクリプトの作成と実行
- 複数サービスのデバッグとログ分析
- CI/CD パイプラインの問題調査
- データパイプラインの構築と監視
統合のヒント:Agentic プログラミングのワークフローを構築する際は、APIYI(apiyi.com)のような集約プラットフォーム経由で GPT-5.5 を呼び出すことをお勧めします。APIキーの一元管理、呼び出しコストの監視、必要に応じた予備モデルへの切り替えが容易になります。
シナリオ4:対話型ペアプログラミング → Claude Opus 4.7 を選択
対話型のコーディング体験において、遅延は致命的です。Opus 4.7 の TTFT(最初のトークンが出るまでの遅延)は約 0.5 秒ですが、GPT-5.5 は約 3 秒かかります。この 6 倍もの差は、頻繁なインタラクションにおいて非常に大きく感じられます。
Cursor、Claude Code、Continue などの IDE 統合ツールを使用して小刻みなコード補完を行う場合、Opus 4.7 の低遅延がよりスムーズなコーディングリズムを実現してくれます。

GPT-5.5 と Claude Opus 4.7 のAPI呼び出し例
以下に、両モデルの極めてシンプルな呼び出し例を紹介します。どちらもOpenAI SDK形式と互換性があるため、移行の手間がほとんどかかりません。
GPT-5.5 の極めてシンプルな呼び出し
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# GPT-5.5 を使ったモデル呼び出し
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Pythonでクイックソートを実装して"}]
)
print(response.choices[0].message.content)
Claude Opus 4.7 の極めてシンプルな呼び出し
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Claude Opus 4.7 を使ったモデル呼び出し
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Pythonでクイックソートを実装して"}]
)
print(response.choices[0].message.content)
2モデルの並列比較テストコードを表示
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""個別のモデルの応答時間と出力長をテストします"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# プログラミング能力の比較テスト
test_prompt = """
PythonでLRUキャッシュクラスを実装してください。要件:
1. get(key) および put(key, value) メソッドをサポートすること
2. 容量がいっぱいになったら、最も長い間使われていない項目を自動的に削除すること
3. すべての操作の時間計算量を O(1) にすること
4. 完全なユニットテストを含めること
"""
# 2つのモデルで並列テスト
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} tokens")
テストのヒント: APIYI (apiyi.com) から無料テスト枠を取得すれば、同じアカウントで GPT-5.5 と Claude Opus 4.7 を並列テスト可能です。共通のベースURLとAPIキーを使用できるため、OpenAIやAnthropicで個別に申請する必要はありません。
GPT-5.5 と Claude Opus 4.7 の総合コスト分析
APIの価格設定は、モデル選定において無視できない重要な指標です。一見すると Opus 4.7 の出力トークン単価は17%安いですが、総合的に分析すると真実は逆転します。
| コスト項目 | GPT-5.5 | Claude Opus 4.7 | 実質的な影響 |
|---|---|---|---|
| 入力価格 | $5/M トークン | $5/M トークン | 同等 |
| 出力価格 | $30/M トークン | $25/M トークン | Opus が17%安い |
| >200K プロンプト | 通常価格 | $10/$37.50 に倍増 | 長文脈はGPTが有利 |
| 同タスク出力トークン数 | 100% (基準) | GPTより72%多い | GPTがトータルで安価 |
| TTFT 応答速度 | ~3 秒 | ~0.5 秒 | Opus が快適 |
| 大量タスクの実質コスト | 1.0x (基準) | 1.4-1.5x (基準) | GPTの方が経済的 |
コスト比較における重要な発見
トークンの効率性が価格比較の本質を変えています。 同じプログラミングタスクにおいて、GPT-5.5 の平均出力トークン消費量は Opus 4.7 よりも 72% 少なくなっています。たとえ Opus の単価が 17% 安くても、1.72 倍のトークン量がかかれば、実際のタスクコストは GPT-5.5 の方が低くなります。
長いコンテキスト(長文脈)での差はさらに広がります。 プロンプトが 200K トークンを超えると、Opus 4.7 の入出力価格は倍の $10 および $37.50 になりますが、GPT-5.5 は価格据え置きです。大規模リポジトリ分析など、長いコンテキスト理解が必要なワークフローでは、GPT-5.5 のコストメリットは 2〜3 倍に達する可能性があります。
解説
Claude Opus 4.7 のコスト特徴: トークン単価は主要な最先端モデルの中で競争力があります。しかし、大量生成を行うシナリオではトークン消費量が多く、総コストが引き上がります。また、長文脈シナリオでは 200K 超過時の倍増システムが予算上の圧力となります。
GPT-5.5 のコスト特徴: 単一トークンの価格はやや高めですが、優れたトークン効率と長文脈でも価格が変わらない仕組みにより、大規模・長文脈シナリオでは総合コストが低くなります。OpenAI は、エージェントベースのワークフローのコスト構造を考慮して価格設計を行っていることが伺えます。
コスト算出のアドバイス: 実際のプロジェクトコストは、プロンプトの長さ、出力長、呼び出し頻度など多くの要因に左右されます。APIYI (apiyi.com) プラットフォーム経由で両モデルにアクセスし、提供される詳細な課金明細を確認することで、データに基づいた最適な選定が可能です。
よくある質問 FAQ
Q1: GPT-5.5 と Claude Opus 4.7 は、どちらの方がプログラミング能力が高いですか?
絶対的な「どちらが上」ということはなく、タスクの内容によります。Claude Opus 4.7 は「SWE-bench Pro」(64.3% 対 58.6%)および「Verified」(87.6%)でリードしており、実際の GitHub issue の修正や大規模なコードベースのリファクタリングに適しています。一方、GPT-5.5 は「Terminal-Bench 2.0」(82.7% 対 69.4%)や長大なコンテキスト検索(74.0% 対 32.2%)で優れており、エージェント型のプログラミングフローやモノレポ全体のコード理解に向いています。
Q2: GPT-5.5 と Claude Opus 4.7 の API 料金に違いはありますか?
どちらも入力トークンは $5/M です。出力トークンに関しては、Opus 4.7($25/M)の方が GPT-5.5($30/M)よりも 17% 安価です。しかし、Opus 4.7 はプロンプトが 200K を超えると料金が倍増するのに対し、GPT-5.5 は価格が維持されます。さらに、GPT-5.5 の出力トークン消費効率は Opus より 72% 高いため、大量のタスクを実行する場合、GPT-5.5 の方が総合的なコストは抑えられます。
Q3: GPT-5.5 と Claude Opus 4.7 はいつリリースされましたか?
Claude Opus 4.7 は 2026 年 4 月 16 日に Anthropic から発表され、Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry で全面的に利用可能です。GPT-5.5(内部コードネーム:Spud)は 2026 年 4 月 23 日に OpenAI から発表されました。トップクラスのプログラミング用モデルがわずか 7 日差で登場し、激しい競争が繰り広げられています。
Q4: どのようなプログラミング作業で Claude Opus 4.7 を選ぶべきですか?
以下のシーンでは、Opus 4.7 を優先的に選択することをお勧めします。
- GitHub issue の修正:SWE-bench Pro で 5.7 ポイントの差をつけてリード
- 大規模なコードベースのリファクタリング:ファイル間をまたぐアーキテクチャ推論能力がより強力
- 対話型のペアプログラミング:TTFT(初トークンまでの時間)がわずか 0.5 秒と、6 倍高速な応答を実現
- コード品質レビュー:Rakuten-SWE-Bench の実測テストでコード品質スコアがより高得点
Q5: どうすれば API を経由して GPT-5.5 と Claude Opus 4.7 を素早く呼び出せますか?
両方のモデルに対応した API 中継サービスを利用したテストがおすすめです。
- APIYI(apiyi.com)にアクセスしてアカウントを登録
- 統一された APIキー と無料のテスト枠を取得
- 本記事のサンプルコードを使用し(
base_urlをhttps://vip.apiyi.com/v1に置換)、modelにgpt-5.5またはclaude-opus-4-7を指定して呼び出す
APIYI は OpenAI、Anthropic、Google などの主要モデルの統一インターフェースに対応しているため、複数のアカウントを個別に申し込む必要なく、GPT-5.5 と Claude Opus 4.7 の実際のパフォーマンスを素早く比較できます。
Q6: GPT-5.5 と Claude Opus 4.7 にはそれぞれどのような制限がありますか?
GPT-5.5 の制限:
- TTFT 遅延が約 3 秒あり、対話的なシーンでの体験はやや遅め
- 実際の issue 修正を行う SWE-bench においては、Opus 4.7 に及ばない
Claude Opus 4.7 の制限:
- 長大なコンテキスト検索能力がやや弱い(1M 範囲で 32.2%)
- プロンプトが 200K を超えると料金が倍になり、長文脈利用時のコスト負担が大きい
- 出力トークンの消費量が多く、大規模なタスクでは総合コストが高くなる傾向がある
- Terminal-Bench などのエージェント型タスクでのパフォーマンスが GPT-5.5 に及ばない
Q7: GPT-5.5 と Claude Opus 4.7 を両方使う必要はありますか?
プロのエンジニアチームであれば、両方を併用することを強く推奨します。典型的な分担戦略としては、GitHub issue の修正、コードレビュー、重要なアーキテクチャの意思決定には Opus 4.7 を使用し、長文脈の分析、エージェント型の自動化プロセス、大量のコード生成には GPT-5.5 を使用するのが効率的です。この併用モデルにより、それぞれの強みを活かしつつ、コストと体験のバランスを最適化できます。
GPT-5.5 と Claude Opus 4.7 の要点まとめ
- 実際の Issue 修正は Opus:Claude Opus 4.7 は SWE-bench Pro/Verified の両方でリードしており、実際の GitHub issue 修正には最適です
- エージェント型プログラミングは GPT:GPT-5.5 は Terminal-Bench 2.0 で 13 ポイントのリードを誇り、多段階のツール呼び出しがより安定しています
- 長大なコンテキストは GPT:MRCR v2 テストにおいて GPT-5.5(74%)は Opus(32.2%)を大きく引き離し、1M のコンテキストを扱う唯一の信頼できる選択肢です
- 低遅延を求めるなら Opus:Opus の TTFT はわずか 0.5 秒で、GPT より 6 倍高速。対話型コーディングが非常にスムーズです
- コストを意識するなら GPT:GPT-5.5 は出力トークン効率が Opus より 72% 優れており、総合的なタスクコストを抑えられます
- 素早い並行テスト:APIYI(apiyi.com)のアカウントが一つあれば、両モデルを統一して呼び出せるため、実際のタスクでの比較が容易です
まとめ
GPT-5.5 と Claude Opus 4.7 のプログラミング能力比較における核心的な結論は以下の通りです。
- 「万能な勝者」は存在しない:両モデルにはそれぞれ明確な強みがあり、「最高のモデル」を盲目的に追い求めるのは誤ったアプローチです。
- タスクに基づいたモデル選定:まずは自身の主要なプログラミングシナリオ(Issue修正 / エージェント活用 / 長大なコンテキスト / インタラクティブな作業)を明確にしてから、主力モデルを決定してください。
- 2モデルの並行利用を推奨:プロの開発チームであれば、両モデルを同時に導入し、シナリオに応じて最適なモデルに振り分ける(ルーティングする)ことで、生産性を最大化できます。
もし一つだけ選ぶのであれば、GitHubでのIssue修正やコードレビューがメインなら「Claude Opus 4.7」を、エージェントによる自動化や長大なコンテキスト分析がメインなら「GPT-5.5」をおすすめします。
APIYI (apiyi.com) を通じて迅速にモデル選定を検証することをお勧めします。このプラットフォームは、GPT-5.5 と Claude Opus 4.7 の統一API、無料テスト枠、そして詳細な利用料確認機能を提供しており、データに基づいた最適な選定決定を行うための最も手軽なルートです。
関連記事
GPT-5.5 と Claude Opus 4.7 のプログラミング能力比較に興味がある方は、以下の記事もあわせてご覧ください。
- 📘 Claude Opus 4.7 完全レビュー:SWE-bench 87.6% を支えるエンジニアリング力 – Opus 4.7 の能力の源泉を深く掘り下げます
- 📊 GPT-5.5 Spud 実践ガイド:エージェント型プログラミングの新王者が持つ8つの活用テクニック – GPT-5.5 の高度な使い方を習得しましょう
- 🚀 AIプログラミングモデル選定ガイド 2026:GPT から Claude までの全体像を比較 – よりマクロな視点でのモデル選定手法を探ります
📚 参考文献
-
OpenAI 公式 GPT-5.5 紹介: コアベンチマークおよび機能解説
- リンク:
openai.com/index/introducing-gpt-5-5 - 説明: SWE-bench、Terminal-Bench などの主要なベンチマークを含む、GPT-5.5 の公式リリースドキュメント
- リンク:
-
Anthropic 公式 Claude Opus 4.7 リリースノート: モデルのポジショニングと性能データ
- リンク:
anthropic.com/news/claude-opus-4-7 - 説明: SWE-bench Verified/Pro の詳細データを含む、Opus 4.7 の公式リリースドキュメント
- リンク:
-
SWE-Bench Pro 公開リーダーボード: 第三者による独立検証
- リンク:
labs.scale.com/leaderboard/swe_bench_pro_public - 説明: Scale AI が管理する SWE-Bench Pro 公開リーダーボード。両モデルの実際の順位を検証可能
- リンク:
-
Vellum LLM リーダーボード 2026: AI モデルの総合比較
- リンク:
vellum.ai/llm-leaderboard - 説明: プログラミング、推論、長いコンテキストウィンドウなど、多角的な比較を行うプラットフォーム
- リンク:
-
Artificial Analysis モデル比較: 性能とコストの分析
- リンク:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - 説明: TTFT(最初のトークンまでの時間)、スループット、総合コストに関する詳細な比較データを提供
- リンク:
著者: APIYI 技術チーム
技術交流: コメント欄での議論を歓迎します。その他の資料については、APIYI ドキュメントセンター(docs.apiyi.com)をご覧ください。