Anmerkung des Autors: Basierend auf sechs Kern-Benchmarks wie SWE-bench Pro, Terminal-Bench 2.0 und LiveCodeBench vergleichen wir tiefgreifend die Leistungsunterschiede zwischen GPT-5.5 und Claude Opus 4.7 in realen Programmierszenarien und geben klare Empfehlungen für die Modellwahl.
Der Wettstreit zwischen GPT-5.5 und Claude Opus 4.7 ist das meistdiskutierte Thema im Bereich der KI-Programmierung im April 2026. Dieser Artikel vergleicht das OpenAI GPT-5.5 (Codename: Spud) und das Anthropic Claude Opus 4.7. Anhand von Metriken wie SWE-bench Pro, Terminal-Bench 2.0, Retrieval bei langem Kontext, Token-Effizienz und API-Preisen geben wir konkrete Empfehlungen.
Dies ist keine „es gibt Vor- und Nachteile auf beiden Seiten“-Analyse. Wir basieren unsere Empfehlungen direkt auf den offiziell veröffentlichten Benchmark-Daten für spezifische Anwendungsszenarien. Anthropic veröffentlichte Claude Opus 4.7 am 16. April 2026, OpenAI folgte am 23. April mit GPT-5.5 – das Duell der beiden Top-Modelle, die nur sieben Tage auseinander liegen, hat begonnen.
Kernnutzen: Nach diesem Artikel wissen Sie genau, ob Sie für GitHub-Issue-Fixes, agentische Programmierung, Refactoring bei langem Kontext oder interaktives Coding GPT-5.5 oder Claude Opus 4.7 wählen sollten.

Kurzüberblick: Die Kernunterschiede zwischen GPT-5.5 und Claude Opus 4.7
Die beiden Modelle haben unterschiedliche Schwerpunkte, was zu verschiedenen Stärken bei der Programmierung führt. Die folgende Tabelle fasst die kritischen Unterschiede in programmierrelevanten Dimensionen zusammen:
| Vergleichsdimension | GPT-5.5 | Claude Opus 4.7 |
|---|---|---|
| Veröffentlichungsdatum | 23.04.2026 | 16.04.2026 |
| Codename | Spud | – |
| Kontextfenster | 1 Mio. Token | 1 Mio. Token |
| Maximale Ausgabe | 128K Token | 128K Token |
| Kernstärke | Agentische Programmierung, langes Kontext-Retrieval | Echte GitHub-Issue-Fixes, Architektur-Reasoning |
| Typische TTFT | ~3 Sek. | ~0,5 Sek. |
| Token-Effizienz | 72% weniger Output-Token als Opus | Höherer Token-Verbrauch, aber präziser |
| API-Eingabe | $5/M Token | $5/M Token |
| API-Ausgabe | $30/M Token | $25/M Token |
| Aufschlag große Eingabe | >200K bleibt beim Standardpreis | >200K verdoppelt auf $10/$37,50 |
Positionierung der Programmierfähigkeiten von GPT-5.5
GPT-5.5 ist das bisher stärkste agentische Programmiermodell von OpenAI. Es überzeugt durch seine Leistung bei Terminal-Workflows, Retrieval aus langen Kontexten und der Koordination zwischen verschiedenen Tools – besonders geeignet für automatisierte Programmierprozesse, die viele Schritte und Tool-Aufrufe erfordern. OpenAI positioniert es als die erste Wahl für "langwierige Programmieraufgaben" und demonstriert mit internen Expert-SWE-Benchmarks die Fähigkeit, Aufgaben zu bewältigen, für die ein Mensch etwa 20 Stunden benötigen würde.
Positionierung der Programmierfähigkeiten von Claude Opus 4.7
Claude Opus 4.7 hat den Thron bei echten Software-Engineering-Aufgaben zurückerobert. Mit 87,6 % bei SWE-bench Verified und 64,3 % bei SWE-bench Pro übertrifft es alle bestehenden Wettbewerber deutlich. Die Praxistests von Anthropic auf dem Rakuten-SWE-Bench zeigen, dass Opus 4.7 drei Mal so viele produktive Aufgaben löst wie Opus 4.6. Es eignet sich besonders für die Reparatur von GitHub-Issues und das Refactoring großer Codebasen, die tiefes architektonisches Verständnis erfordern.
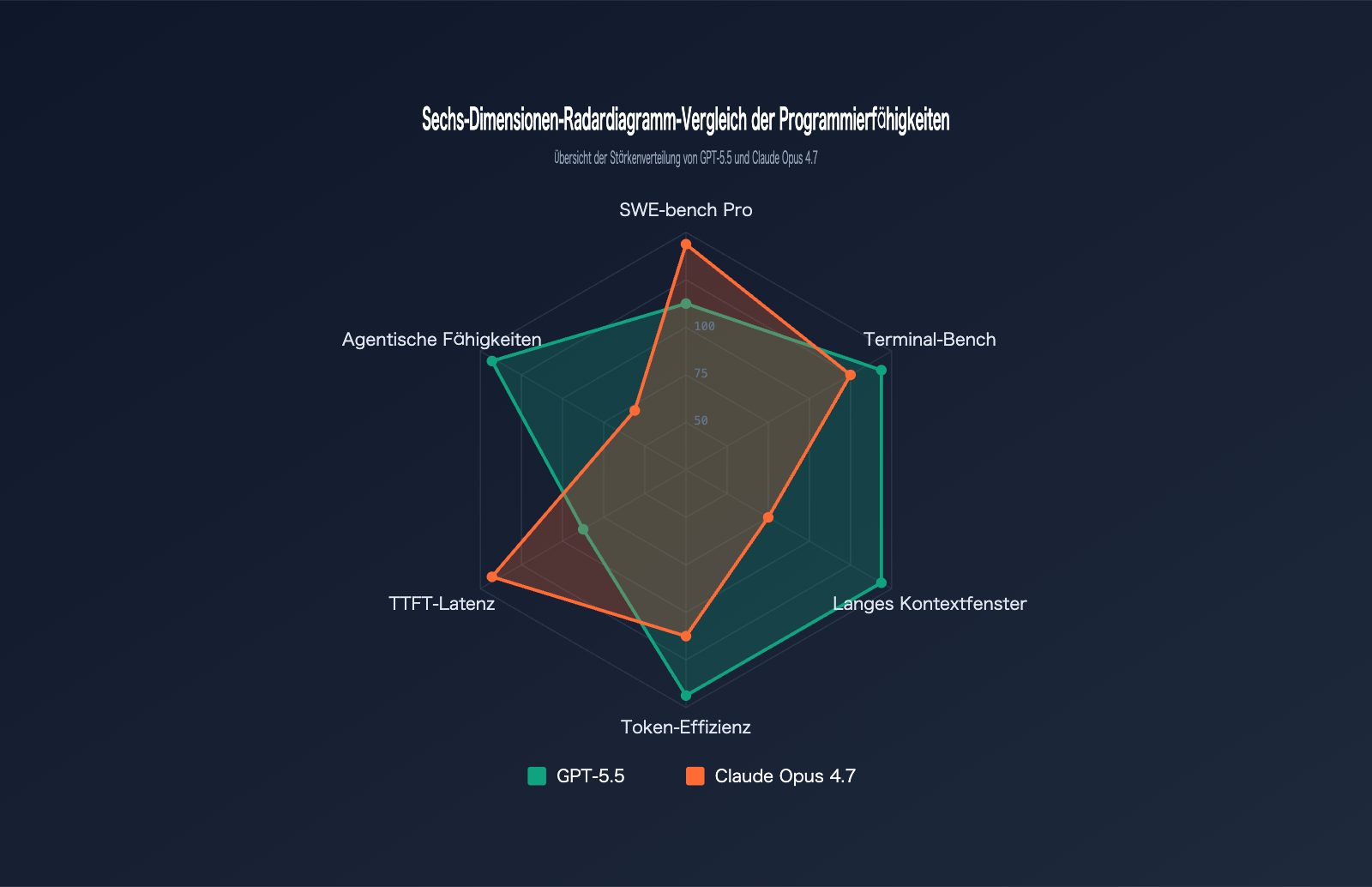
GPT-5.5 vs. Claude Opus 4.7: Benchmark-Vergleich
Benchmarks sind der objektivste Maßstab, um die Programmierfähigkeiten von Modellen zu bewerten. Wir haben die offiziellen Daten beider Modelle in sechs gängigen Programmier-Benchmarks zusammengefasst:
| Benchmark | Testinhalt | GPT-5.5 | Claude Opus 4.7 | Gewinner |
|---|---|---|---|---|
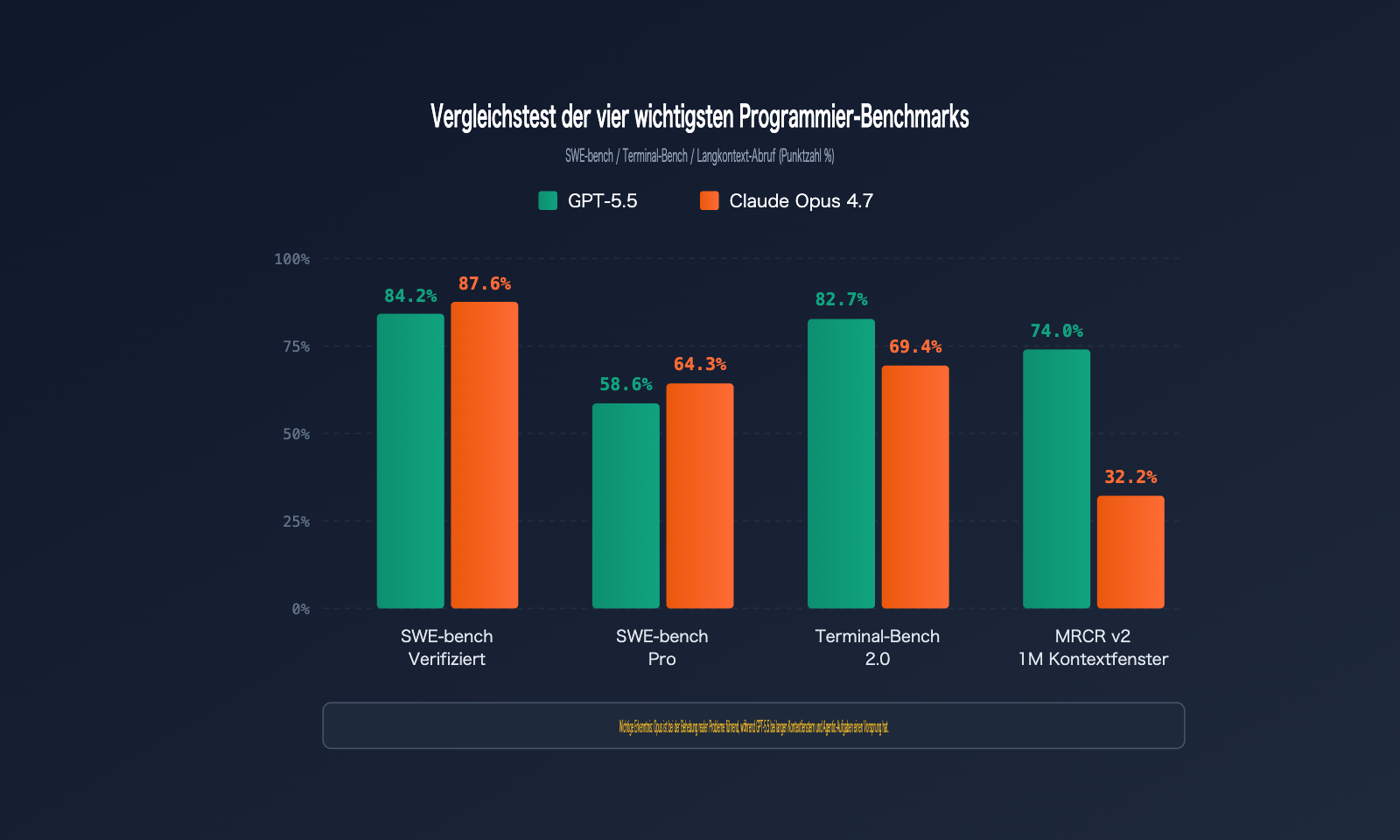
| SWE-bench Verified | Verifizierte GitHub-Issue-Korrekturen | 84,2 % | 87,6 % | Opus 4.7 |
| SWE-bench Pro | Komplexe Korrekturen über mehrere Dateien | 58,6 % | 64,3 % | Opus 4.7 |
| Terminal-Bench 2.0 | Terminal-Befehls-Workflows | 82,7 % | 69,4 % | GPT-5.5 |
| Expert-SWE | Langzeit-Programmierung (Median 20 Std.) | 73,1 % | – | GPT-5.5 |
| OSWorld-Verified | Desktop-Agent-Aufgaben | 78,7 % | 78,0 % | GPT-5.5 (knapp) |
| MRCR v2 (512K-1M) | Langkontext 8-Needle-Abruf | 74,0 % | 32,2 % | GPT-5.5 |
Analyse: SWE-bench Pro in der Praxis
SWE-bench Pro ist der Goldstandard für die Bewertung der Fähigkeit eines Modells, echte GitHub-Issues zu beheben. Claude Opus 4.7 führt mit 64,3 % gegenüber den 58,6 % von GPT-5.5, was bedeutet, dass Opus 4.7 bei 100 Fehlerbehebungsaufgaben in realen Code-Repositories etwa 6 Fehler mehr löst.
Entscheidend ist, dass Opus 4.7 im Vergleich zur Vorgängerversion Opus 4.6 (53,4 %) um volle 10,9 Prozentpunkte zugelegt hat – ein seltener, massiver Sprung innerhalb einer einzigen Versionsiteration. Für Teams, deren Hauptworkflow auf der Korrektur von GitHub-Issues basiert, ist Claude Opus 4.7 aktuell die erste Wahl.
Testempfehlung: Möchten Sie die Leistungsunterschiede beider Modelle in Ihrer eigenen Codebasis überprüfen? Sie können die Plattform APIYI (apiyi.com) für parallele Tests nutzen. Sie bietet eine einheitliche Schnittstelle für GPT-5.5 und Claude Opus 4.7 und ermöglicht einen direkten Vergleich.
Analyse: Terminal-Bench 2.0 in der Praxis
Terminal-Bench 2.0 testet die Fähigkeit eines Modells, komplexe Aufgaben in einer Terminalumgebung zu meistern, einschließlich Planung, Iteration und Werkzeugkoordination. GPT-5.5 liegt hier mit 82,7 % deutlich vor Opus 4.7 (69,4 %) – ein Abstand von 13 Prozentpunkten.
Dieser Unterschied resultiert aus der Optimierung von GPT-5.5 für agentische Workflows: Es kann Werkzeuge präziser auswählen, mehrstufige Aufgaben stabiler bewältigen und zuverlässiger nach Fehlern wiederherstellen. Wenn Ihr Workflow viele Shell-Befehle, Dateimanipulationen oder CI/CD-Integrationen umfasst, ist GPT-5.5 die sicherere Wahl.
Unterschiede bei der Langkontext-Abfrage
Im MRCR-v2-Test für 8-Needle-Abrufe im Bereich von 512K bis 1M Tokens liegt GPT-5.5 mit 74,0 % weit vor den 32,2 % von Opus 4.7 – ein Vorsprung von 41,8 Prozentpunkten.
Das bedeutet: Wenn Sie das Modell dazu bringen müssen, eine vollständige Codebasis (über 500K Tokens) zu verstehen, ist die Genauigkeit bei der Erinnerung an tieferliegende Kontexte bei GPT-5.5 signifikant höher. Bei Szenarien wie "Refactoring auf Basis eines vollständigen Monorepo" ist der Unterschied zwischen GPT-5.5 und Opus nicht nur eine Frage der Nuancen, sondern entscheidet darüber, ob das Modell einsetzbar ist oder nicht.
Praxis-Empfehlungen für Programmierszenarien: GPT-5.5 vs. Claude Opus 4.7
Benchmark-Daten sind nur dann sinnvoll, wenn sie auf konkrete Szenarien angewendet werden. Die folgende Tabelle bietet klare Empfehlungen für fünf typische Programmierszenarien:
| Programmierszenario | Empfohlenes Modell | Kernargument | Erwarteter Nutzen |
|---|---|---|---|
| GitHub Issue-Behebung | Claude Opus 4.7 | SWE-bench Pro Vorsprung von 5,7 Prozentpunkten | 10 % höhere Erfolgsquote |
| Refactoring großer Codebases | Claude Opus 4.7 | Stärkere Architektur-Inferenz über Dateien hinweg | Geringeres Risiko von Architekturfehlern |
| Agentische Workflows | GPT-5.5 | Terminal-Bench Vorsprung von 13,3 Prozentpunkten | Höhere Stabilität bei Mehrschritt-Aufgaben |
| Langes Kontextfenster (>500K) | GPT-5.5 | MRCR v2 Vorsprung von 41,8 Prozentpunkten | Zuverlässige Abfrage tiefer Kontexte |
| Interaktives Pair Programming | Claude Opus 4.7 | TTFT nur 0,5 Sek., schnellere Reaktion | Flüssigerer Programmierrhythmus |
| Massengenerierung von Code | GPT-5.5 | 72 % höhere Token-Effizienz, geringere Kosten | Bessere Gesamtkosteneffizienz |
Szenario 1: Behebung echter GitHub Issues → Wahl: Claude Opus 4.7
Wenn Ihr Hauptbedarf darin besteht, eine Issue-Beschreibung entgegenzunehmen und die KI dazu zu bringen, einen mergbaren PR zu erstellen, ist Claude Opus 4.7 zweifellos die beste Wahl. Die Bewertung von 87,6 % bei SWE-bench Verified bedeutet, dass etwa neun von zehn klar definierten Bugfixing-Aufgaben direkt geliefert werden können.
Es ist jedoch zu beachten, dass 87,6 % nicht bedeuten, dass 87,6 % Ihrer technischen Arbeit automatisiert werden können – dies basiert auf einem idealen Test mit "perfekten Aufgabenspezifikationen". Im tatsächlichen Arbeitsalltag beeinflusst die Qualität der Issue-Beschreibung die Erfolgsquote maßgeblich.
Szenario 2: Programmcode mit langem Kontext verstehen → Wahl: GPT-5.5
Wenn Sie das Modell dazu bringen müssen, ein gesamtes Monorepo (in der Regel 500K-1M Token) zu lesen, bevor es eine Entscheidung trifft, ist GPT-5.5 derzeit die einzig zuverlässige Wahl. Die 8-Needle-Suchgenauigkeit von Opus 4.7 im 1M-Kontextbereich liegt bei nur 32,2 %, was bedeutet, dass das Modell wahrscheinlich kritische Definitionen tief in der Codebasis "übersieht".
Dieser Unterschied ist architektonisch bedingt – wenn Ihr Workflow auf einer vollständigen Sicht auf die Codebasis basiert (z. B. globale Umbenennungen, Prüfung der API-Kompatibilität), ist der Prozess mit Opus 4.7 unter Umständen gar nicht durchführbar.
Szenario 3: Agentische Programmier-Workflows → Wahl: GPT-5.5
Agentische Programmierung bezeichnet Workflows, bei denen die KI Aufgaben eigenständig plant, Tools aufruft und iterativ Korrekturen vornimmt. GPT-5.5 erzielt bei Terminal-Bench 2.0 einen Wert von 82,7 % und liegt damit weit vor Opus 4.7. Besonders stabil zeigt es sich bei folgenden Aufgaben:
- Schreiben und Ausführen von automatisierten Bereitstellungsskripten
- Debugging mehrerer Dienste und Protokollanalyse
- Fehlersuche in CI/CD-Pipelines
- Aufbau und Überwachung von Datenpipelines
Integrationshinweis: Beim Aufbau von agentischen Workflows empfiehlt es sich, GPT-5.5 über eine Aggregator-Plattform wie APIYI (apiyi.com) anzubinden. Dies erleichtert die einheitliche Verwaltung von API-Schlüsseln, die Überwachung der Kosten und den bedarfsgerechten Wechsel auf Ersatzmodelle.
Szenario 4: Interaktives Pair Programming → Wahl: Claude Opus 4.7
Das interaktive Programmiererlebnis ist extrem latenzempfindlich. Die TTFT (Latenz bis zum ersten Token) von Opus 4.7 liegt bei etwa 0,5 Sekunden, während GPT-5.5 ca. 3 Sekunden benötigt. Dieser sechsfache Unterschied ist bei häufigen Interaktionen deutlich spürbar.
Wenn Sie IDE-Integrationen wie Cursor, Claude Code oder Continue für häufige kleine Code-Vervollständigungen nutzen, sorgt die niedrige Latenz von Opus 4.7 für einen spürbar flüssigeren Programmierrhythmus.

Beispielaufrufe für GPT-5.5 und Claude Opus 4.7 API
Hier sind minimalistische Beispiele für den Modellaufruf, damit Sie diese schnell testen können. Beide sind mit dem OpenAI-SDK-Format kompatibel, was den Migrationsaufwand minimal hält.
Minimalistischer Aufruf für GPT-5.5
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.5",
messages=[{"role": "user", "content": "Implementiere Quicksort in Python"}]
)
print(response.choices[0].message.content)
Minimalistischer Aufruf für Claude Opus 4.7
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Implementiere Quicksort in Python"}]
)
print(response.choices[0].message.content)
Testcode für den parallelen Vergleich beider Modelle anzeigen
import openai
import time
from typing import Dict
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
def benchmark_model(model: str, prompt: str) -> Dict:
"""Testet Antwortzeit und Ausgabelänge eines einzelnen Modells"""
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2000
)
elapsed = time.time() - start
return {
"model": model,
"elapsed_seconds": round(elapsed, 2),
"output_tokens": response.usage.completion_tokens,
"content_preview": response.choices[0].message.content[:200]
}
# Vergleichstest für Programmierfähigkeiten
test_prompt = """
Bitte implementiere eine LRU-Cache-Klasse in Python. Anforderungen:
1. Unterstütze get(key) und put(key, value) Methoden
2. Automatische Verdrängung des am wenigsten verwendeten Elements bei voller Kapazität
3. Zeitkomplexität für alle Operationen: O(1)
4. Inklusive vollständiger Unit-Tests
"""
# Paralleler Test beider Modelle
gpt_result = benchmark_model("gpt-5.5", test_prompt)
claude_result = benchmark_model("claude-opus-4-7", test_prompt)
print(f"GPT-5.5: {gpt_result['elapsed_seconds']}s, {gpt_result['output_tokens']} Tokens")
print(f"Claude Opus 4.7: {claude_result['elapsed_seconds']}s, {claude_result['output_tokens']} Tokens")
Testempfehlung: Nutzen Sie APIYI (apiyi.com), um kostenloses Testguthaben zu erhalten. Sie können GPT-5.5 und Claude Opus 4.7 parallel unter demselben Account testen – mit einer einheitlichen base_url und einem API-Schlüssel, ohne separate Konten bei OpenAI oder Anthropic beantragen zu müssen.
Umfassende Kostenanalyse: GPT-5.5 vs. Claude Opus 4.7
Die Preisgestaltung der API ist ein entscheidender Faktor bei der Modellauswahl. Auf den ersten Blick wirkt Opus 4.7 bei den Ausgabe-Tokens um 17 % günstiger, doch eine umfassende Analyse offenbart ein anderes Bild:
| Kostenfaktor | GPT-5.5 | Claude Opus 4.7 | Tatsächliche Auswirkung |
|---|---|---|---|
| Eingabepreis | $5/M Tokens | $5/M Tokens | Gleichstand |
| Ausgabepreis | $30/M Tokens | $25/M Tokens | Opus 17 % günstiger |
| >200K Prompt | Bleibt gleich | Verdopplung auf $10/$37.50 | Großer Vorteil GPT bei langem Kontext |
| Ausgabe-Tokens pro Aufgabe | 100 % Basiswert | 72 % mehr als GPT | GPT insgesamt günstiger |
| TTFT-Latenz | ~3 Sekunden | ~0,5 Sekunden | Opus bietet bessere UX |
| Kosten für Großaufträge | 1,0x Basis | 1,4-1,5x Basis | GPT spart mehr Geld |
Wichtige Erkenntnisse zum Kostenvergleich
Token-Effizienz verändert die Preisbasis. Bei identischen Programmieraufgaben verbraucht GPT-5.5 im Durchschnitt 72 % weniger Ausgabe-Tokens als Opus 4.7. Auch wenn der Einzelpreis von Opus um 17 % niedriger liegt, führen die 1,72-fache Token-Menge zu real niedrigeren Kosten bei GPT-5.5.
Der Abstand vergrößert sich bei Szenarien mit langem Kontext. Sobald die Eingabeaufforderung 200K Tokens überschreitet, verdoppeln sich die Preise bei Opus 4.7 auf $10 bzw. $37,50, während GPT-5.5 preisstabil bleibt. Bei Workflows mit tiefem Kontextverständnis (wie der Analyse ganzer Repositories) kann GPT-5.5 einen Kostenvorteil von Faktor 2 bis 3 erreichen.
Fazit der Analyse
Kostenprofil von Claude Opus 4.7: Der Preis pro Token ist unter den führenden Modellen wettbewerbsfähig. Bei der Massengenerierung treibt der höhere Token-Verbrauch jedoch die Gesamtkosten nach oben; zudem sorgt der Verdopplungsmechanismus bei >200K Tokens für Budgetdruck.
Kostenprofil von GPT-5.5: Der Token-Einzelpreis ist etwas höher, aber die exzellente Token-Effizienz und das ausbleibende Preis-Upgrade bei langem Kontext machen es bei großskaligen, kontextintensiven Szenarien unterm Strich günstiger. OpenAI hat die Preisstruktur offensichtlich auf Agent-basierte Workflows optimiert.
Empfehlung zur Kostenkalkulation: Die tatsächlichen Projektkosten hängen von Faktoren wie Länge der Eingabeaufforderung, Ausgabelänge und Aufrufhäufigkeit ab. Wir empfehlen die Anbindung über die APIYI-Plattform (apiyi.com), da diese detaillierte Abrechnungsdaten pro Modell bereitstellt, um datenbasierte Entscheidungen zu treffen.
Häufig gestellte Fragen (FAQ)
Q1: Welches Modell ist besser in der Programmierung: GPT-5.5 oder Claude Opus 4.7?
Es gibt kein absolutes "Besser", es hängt vom jeweiligen Aufgabenbereich ab. Claude Opus 4.7 führt bei SWE-bench Pro (64,3 % gegenüber 58,6 %) und Verified (87,6 %) und eignet sich daher besser für die Behebung echter GitHub-Issues und komplexe Refactorings großer Codebasen. GPT-5.5 hingegen überzeugt bei Terminal-Bench 2.0 (82,7 % gegenüber 69,4 %) sowie bei der Suche in langen Kontextfenstern (74,0 % gegenüber 32,2 %) und ist somit die erste Wahl für agentische Programmier-Workflows und das Verständnis ganzer Monorepos.
Q2: Wo liegen die Unterschiede in der API-Preisgestaltung zwischen GPT-5.5 und Claude Opus 4.7?
Beide Modelle kosten 5 $ pro Million Eingabe-Token. Bei den Ausgabe-Token ist Opus 4.7 (25 $/M) etwa 17 % günstiger als GPT-5.5 (30 $/M). Allerdings verdoppelt sich der Preis bei Opus 4.7, sobald der Prompt 200.000 Token überschreitet, während GPT-5.5 seinen Preis beibehält. Wenn man zusätzlich berücksichtigt, dass GPT-5.5 bei gleicher Aufgabenstellung 72 % weniger Ausgabe-Token verbraucht, ist GPT-5.5 bei umfangreichen Aufgaben oft die kosteneffizientere Wahl.
Q3: Wann wurden GPT-5.5 und Claude Opus 4.7 veröffentlicht?
Claude Opus 4.7 wurde von Anthropic am 16. April 2026 veröffentlicht und ist über die Claude API, Amazon Bedrock, Google Cloud Vertex AI sowie Microsoft Foundry vollständig verfügbar. GPT-5.5 (interne Bezeichnung: Spud) folgte am 23. April 2026 durch OpenAI. Damit trafen diese beiden Spitzenmodelle im Abstand von nur sieben Tagen aufeinander, was den Wettbewerb stark verschärft hat.
Q4: In welchen Programmier-Szenarien sollte man sich für Claude Opus 4.7 entscheiden?
In folgenden Szenarien ist Opus 4.7 die bevorzugte Wahl:
- Behebung von GitHub-Issues: Führend bei SWE-bench Pro mit einem Vorsprung von 5,7 Prozentpunkten.
- Refactoring großer Codebasen: Stärkere Fähigkeit zur dateiübergreifenden Architektur-Analyse.
- Interaktives Pair Programming: TTFT (Time To First Token) von nur 0,5 Sekunden, was eine sechsmal schnellere Reaktion bedeutet.
- Code-Reviews: Höhere Bewertung der Codequalität im Rakuten-SWE-Bench-Test.
Q5: Wie kann ich GPT-5.5 und Claude Opus 4.7 schnell über die API aufrufen?
Für Tests empfiehlt sich eine API-Aggregationsplattform, die beide Modelle unterstützt:
- Besuchen Sie APIYI unter apiyi.com und registrieren Sie ein Konto.
- Erhalten Sie Ihren einheitlichen API-Schlüssel sowie ein Startguthaben für Tests.
- Verwenden Sie den Beispielcode in diesem Artikel (ersetzen Sie die
base_urldurchhttps://vip.apiyi.com/v1) und geben Sie alsmodelentwedergpt-5.5oderclaude-opus-4-7an.
APIYI bietet eine einheitliche Schnittstelle für führende Modelle wie OpenAI, Anthropic und Google, sodass Sie ohne separate Konten die Leistung von GPT-5.5 und Claude Opus 4.7 direkt vergleichen können.
Q6: Welche bekannten Einschränkungen haben GPT-5.5 und Claude Opus 4.7?
Einschränkungen von GPT-5.5:
- TTFT-Latenz von ca. 3 Sekunden, was bei interaktiven Anwendungen weniger flüssig wirkt.
- Bei der Behebung echter Issues im SWE-bench-Test liegt es hinter Opus 4.7.
Einschränkungen von Claude Opus 4.7:
- Schwächen bei der Suche in sehr langen Kontexten (32,2 % bei 1 Mio. Token).
- Preisverdoppelung bei Prompts über 200.000 Token, was die Kosten bei langen Kontexten erhöht.
- Höherer Verbrauch an Ausgabe-Token, was bei Batch-Prozessen die Gesamtkosten treibt.
- Bei agentischen Aufgaben (wie Terminal-Bench) liegt die Leistung unter der von GPT-5.5.
Q7: Ist es sinnvoll, GPT-5.5 und Claude Opus 4.7 gleichzeitig zu nutzen?
Für professionelle Entwicklungsteams ist die kombinierte Nutzung beider Modelle sehr zu empfehlen. Eine bewährte Strategie: Verwenden Sie Opus 4.7 für das Beheben von GitHub-Issues, Code-Reviews und architektonische Grundsatzentscheidungen. Nutzen Sie GPT-5.5 für Analysen großer Kontextmengen, agentische Automatisierungsprozesse und umfangreiche Code-Generierungen. Dieser hybride Ansatz ermöglicht es Ihnen, die jeweiligen Stärken optimal zu kombinieren und ein Gleichgewicht zwischen Kosten und Performance zu finden.
Wichtigste Erkenntnisse zu GPT-5.5 und Claude Opus 4.7
- Echte Issue-Behebung: Claude Opus 4.7 führt bei SWE-bench Pro/Verified und ist die erste Wahl für reale GitHub-Issues.
- Agentisches Programmieren: GPT-5.5 liegt bei Terminal-Bench 2.0 um 13 Prozentpunkte vorn und bietet stabilere mehrstufige Werkzeugaufrufe.
- Großer Kontext: Im MRCR v2-Test übertrifft GPT-5.5 (74 %) Opus (32,2 %) deutlich und ist die einzige zuverlässige Wahl für 1M-Kontextfenster.
- Latenz-Sensitivität: Opus bietet eine TTFT von nur 0,5 s – 6-mal schneller als GPT – und sorgt für ein flüssigeres Coding-Erlebnis.
- Kosteneffizienz: GPT-5.5 verbraucht 72 % weniger Ausgabe-Token als Opus, was die Kosten bei vielen Aufgaben senkt.
- Schnelles paralleles Testen: Über ein Konto bei APIYI (apiyi.com) können beide Modelle einheitlich aufgerufen und direkt verglichen werden.
Fazit
Zentrale Erkenntnisse zum Vergleich der Programmierfähigkeiten von GPT-5.5 und Claude Opus 4.7:
- Kein universeller Champion: Beide Modelle haben klare Stärken in unterschiedlichen Bereichen. Die blinde Suche nach dem „besten Modell“ ist ein Trugschluss.
- Aufgabenorientierte Modellauswahl: Definieren Sie zunächst Ihr primäres Programmier-Szenario (Issue-Behebung / Agentic-Workflows / großes Kontextfenster / interaktive Entwicklung), bevor Sie sich für ein Hauptmodell entscheiden.
- Empfehlung zur parallelen Nutzung: Professionelle Entwicklungsteams sollten beide Modelle integrieren und Anfragen je nach Szenario an das jeweils optimale Modell weiterleiten, um den Output zu maximieren.
Falls Sie sich für ein Modell entscheiden müssen: Wenn Ihr Fokus auf der Behebung von GitHub-Issues und Code-Reviews liegt, wählen Sie Claude Opus 4.7. Bei Agentic-Automatisierung und der Analyse großer Code-Kontexte ist GPT-5.5 die bessere Wahl.
Wir empfehlen, die Modellauswahl schnell über APIYI (apiyi.com) zu validieren. Die Plattform bietet einheitliche Schnittstellen für GPT-5.5 und Claude Opus 4.7, kostenlose Testguthaben sowie eine detaillierte Kostenübersicht – der einfachste Weg, um datengestützte Entscheidungen bei der Modellauswahl zu treffen.
Weiterführende Artikel
Wenn Sie sich für den Programmiervergleich zwischen GPT-5.5 und Claude Opus 4.7 interessieren, empfehlen wir diese weiterführenden Inhalte:
- 📘 Claude Opus 4.7 Komplett-Test: Die technische Stärke hinter 87,6 % bei SWE-bench – Eine tiefgehende Analyse der Fähigkeiten von Opus 4.7.
- 📊 GPT-5.5 Spud Praxistest: 8 Tipps zur Nutzung des neuen Königs der Agentic-Programmierung – Meistern Sie die fortgeschrittene Anwendung von GPT-5.5.
- 🚀 Leitfaden zur Auswahl von KI-Programmiermodellen 2026: Ein Panorama-Vergleich von GPT bis Claude – Entdecken Sie eine ganzheitliche Methodik zur Modellauswahl.
📚 Referenzen
-
Offizielle Einführung von GPT-5.5 durch OpenAI: Zentrale Benchmarks und Leistungsmerkmale
- Link:
openai.com/index/introducing-gpt-5-5 - Beschreibung: Offizielle Veröffentlichungsunterlagen zu GPT-5.5, einschließlich zentraler Benchmarks wie SWE-bench und Terminal-Bench.
- Link:
-
Offizielle Veröffentlichungshinweise zu Claude Opus 4.7 von Anthropic: Modellpositionierung und Leistungsdaten
- Link:
anthropic.com/news/claude-opus-4-7 - Beschreibung: Offizielle Veröffentlichungsunterlagen zu Opus 4.7, inklusive detaillierter Daten zu SWE-bench Verified/Pro.
- Link:
-
SWE-Bench Pro öffentliches Ranking: Unabhängige Verifizierung durch Dritte
- Link:
labs.scale.com/leaderboard/swe_bench_pro_public - Beschreibung: Das von Scale AI verwaltete öffentliche SWE-Bench Pro-Ranking zur Überprüfung der tatsächlichen Platzierungen beider Modelle.
- Link:
-
Vellum LLM Leaderboard 2026: Umfassender Vergleich von KI-Modellen
- Link:
vellum.ai/llm-leaderboard - Beschreibung: Plattform für umfassende Vergleiche in den Bereichen Programmierung, Schlussfolgerung, langes Kontextfenster und weitere Dimensionen.
- Link:
-
Artificial Analysis Modellvergleich: Analyse von Leistung und Kosten
- Link:
artificialanalysis.ai/models/comparisons/gpt-5-5-vs-claude-opus-4-7-non-reasoning - Beschreibung: Bietet detaillierte Vergleichsdaten zu TTFT, Durchsatz und Gesamtkosten.
- Link:
Autor: Technisches Team von APIYI
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren mit. Weitere Informationen finden Sie im Dokumentationszentrum von APIYI unter docs.apiyi.com.