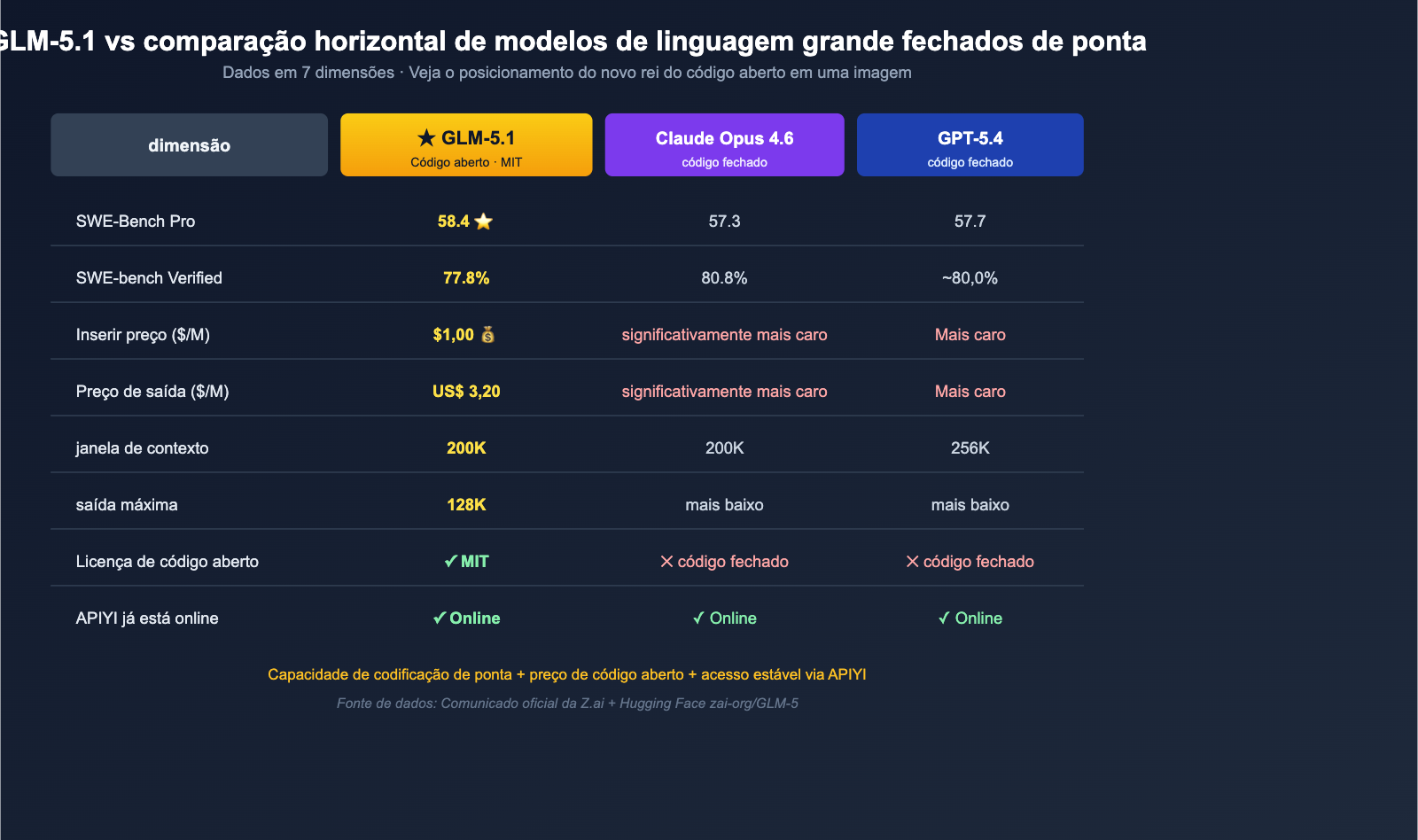
Em 7 de abril de 2026, a Z.ai (antiga Zhipu AI) disponibilizou oficialmente os pesos completos do GLM-5.1 sob a licença MIT no repositório zai-org/GLM-5 do Hugging Face. Este lançamento causou um impacto imediato na comunidade global de IA — não por ser "apenas mais um Modelo de Linguagem Grande open-source", mas porque ele alcançou o topo do ranking mundial no benchmark de engenharia de software SWE-Bench Pro com 58,4 pontos, superando diretamente os 57,7 pontos do GPT-5.4, os 57,3 pontos do Claude Opus 4.6 e os 54,2 pontos do Gemini 3.1 Pro. Esta é a primeira vez que um modelo de código aberto supera todos os modelos proprietários de ponta em um benchmark de "correção de código real" amplamente citado pela indústria.
O que é ainda mais relevante para os desenvolvedores é que o ritmo de lançamento da API do GLM-5.1 foi extremamente ágil — o APIYI (apiyi.com) já concluiu a integração imediatamente. Você não precisa mais baixar os pesos de 754B de parâmetros do Hugging Face nem solicitar uma conta oficial da Z.ai; basta usar o SDK da OpenAI que você já possui, alterar a base_url e começar a realizar a invocação do modelo. Este artigo apresenta uma visão completa do GLM-5.1 em 7 dimensões: arquitetura, benchmarks, hardware de treinamento, precificação e métodos de acesso, além de fornecer um exemplo de código mínimo para utilizar o GLM-5.1 via APIYI.

Visão geral das informações essenciais do GLM-5.1 (Edição de abril de 2026)
Antes de detalhar, vamos resumir todos os fatos cruciais sobre o GLM-5.1 em uma única tabela.
| Dimensão | Informações conhecidas do GLM-5.1 |
|---|---|
| Fabricante | Z.ai (antiga Zhipu AI, listada na bolsa de Hong Kong em jan/2026, avaliação de ~US$ 31,3 bi) |
| Data de lançamento | 7 de abril de 2026 |
| Licença | MIT (permite uso comercial + modificação + derivação fechada) |
| Repositório | huggingface.co/zai-org/GLM-5 |
| Arquitetura | MoE (Mistura de Especialistas), 754B parâmetros totais / 40B ativos |
| Janela de contexto | 200.000 tokens |
| Saída máxima | 128.000 tokens |
| Dados de treinamento | 28,5T tokens (aumento em relação aos 23T do GLM-5) |
| Hardware de treino | Totalmente em Huawei Ascend 910B + framework MindSpore (sem Nvidia / AMD) |
| Framework de deploy | vLLM / SGLang / KTransformers |
| Capacidade principal | Codificação de agente de longo prazo (trabalho contínuo de ~8h por tarefa) |
| Precificação (API direta) | US$ 1,00 / milhão de tokens de entrada, US$ 3,20 / milhão de tokens de saída |
| Pacote de codificação | Plano GLM Coding a partir de ~US$ 3/mês |
| Acesso via APIYI | ✅ Disponível, via https://api.apiyi.com/v1 |
| Ferramentas compatíveis | Claude Code / OpenClaw / Cline / Qualquer editor compatível com OpenAI |
🎯 Dica para começar rápido: O GLM-5.1 já está integrado ao APIYI (apiyi.com). Você só precisa alterar a
base_urldo seu SDK da OpenAI parahttps://api.apiyi.com/v1e definir omodelcom o nome correspondente do GLM-5.1. Assim, você pode substituir o modelo principal no seu fluxo de trabalho de Agente / Cursor / Cline imediatamente, sem precisar reescrever qualquer código de negócio.
Por que o GLM-5.1 é um "ponto de virada" para o código aberto
Para entender por que o GLM-5.1 é chamado pela comunidade internacional de IA de "ponto de virada" do código aberto, precisamos analisar alguns fatos fundamentais.
Primeiro: o modelo de código aberto que lidera o SWE-Bench Pro
O SWE-Bench Pro é atualmente reconhecido como um dos benchmarks de reparo de código real mais difíceis da indústria. As tarefas vêm inteiramente de repositórios de código de nível industrial, e o modelo precisa entender o contexto, localizar bugs e escrever correções que passem nos testes — algo em um nível completamente diferente de "resolver um LeetCode". Antes do lançamento do GLM-5.1, este ranking era dominado alternadamente pelas séries GPT-5.x e Claude Opus, e nenhum modelo de código aberto havia chegado perto do top 3.
Desta vez, o GLM-5.1 assumiu a liderança com 58,4 pontos:
| Modelo | Pontuação SWE-Bench Pro | Código Aberto |
|---|---|---|
| GLM-5.1 | 58,4 ⭐ | ✅ MIT |
| GPT-5.4 | 57,7 | ❌ |
| Claude Opus 4.6 | 57,3 | ❌ |
| Gemini 3.1 Pro | 54,2 | ❌ |
Não foi uma vitória por pouco; foi a eliminação definitiva da lacuna entre "código aberto vs. código fechado" no benchmark industrial mais difícil. Mesmo considerando o aviso de que "o benchmark foi reportado pela Z.ai e avaliações independentes ainda estão por vir", o significado industrial disso é inegável: pela primeira vez, a comunidade de código aberto possui um modelo gratuito capaz de competir de igual para igual com os modelos fechados de ponta em "reparo de código real".
Segundo: uma licença MIT verdadeiramente comercializável
Outro fato crucial sobre o GLM-5.1 é sua licença de código aberto — MIT, e não a comum Apache 2.0, muito menos licenças restritivas do tipo "apenas para pesquisa / não comercial". O significado da licença MIT é direto: qualquer pessoa pode baixar, modificar, ajustar (fine-tuning), implantar, comercializar, criar derivados fechados e vender, sem restrições, bastando apenas manter o aviso de direitos autorais.
Para usuários corporativos, isso significa que o GLM-5.1 pode ser usado sem preocupações em:
- Agentes de codificação internos para produtos próprios;
- Módulos de geração/revisão de código em SaaS comerciais;
- Plugins de IDE com implantação privada;
- Qualquer cenário de conformidade onde o "peso do modelo não pode depender da API de um fornecedor específico".
Em abril de 2026, o GLM-5.1 é praticamente a única escolha que atende simultaneamente aos requisitos de "desempenho de ponta + código aberto MIT + liderança em benchmark industrial".

Arquitetura e treinamento do GLM-5.1: 754B MoE + Full Stack Huawei
O segundo fato que torna o GLM-5.1 único é sua pilha de treinamento.
Arquitetura MoE: 754B de parâmetros totais / 40B ativos
O GLM-5.1 utiliza uma arquitetura de Mistura de Especialistas (MoE), com 754B de parâmetros totais, ativando apenas cerca de 40B por inferência. Esse design de "Modelo de Linguagem Grande + ativação esparsa" já foi validado repetidamente por modelos de código aberto como DeepSeek, Qwen e Mixtral. Os principais benefícios são:
- Grande capacidade do modelo durante o treinamento, permitindo absorver mais conhecimento (28,5T de tokens de dados de pré-treinamento);
- Ativação de apenas uma pequena parte dos especialistas durante a inferência, com uso de VRAM e latência próximos a um modelo denso de 40B;
- Tarefas de diálogo e código podem seguir caminhos de especialistas diferentes, resultando em melhor coerência em tarefas de longo prazo.
| Dimensão | GLM-5 (geração anterior) | GLM-5.1 (atual) |
|---|---|---|
| Parâmetros totais | 355B | 754B |
| Parâmetros ativos | 32B | 40B |
| Dados de pré-treinamento | 23T tokens | 28,5T tokens |
| Janela de contexto | Limitada | 200K |
| Saída máxima | Limitada | 128K |
| Especialização em código | Sim | ✅ Significativamente aprimorada |
| Tarefas de agente de longo prazo | Sim | ✅ Cerca de 8 horas por tarefa |
Destaque de engenharia: Agente de longo prazo de 8 horas
A Z.ai enfatiza repetidamente a capacidade de "tarefa única de 8 horas" do GLM-5.1. Isso significa que: você pode entregar uma tarefa de engenharia real (como corrigir um bug entre arquivos, migrar uma biblioteca antiga ou completar um conjunto de testes) ao GLM-5.1, e ele continuará planejando → executando → testando → corrigindo → otimizando sem intervenção humana, até entregar um resultado pronto para produção, em um processo que dura até 8 horas. Essa curva de capacidade de "agente de resistência" só havia sido reproduzida de forma estável na indústria pela série Claude Opus — o GLM-5.1 é o primeiro modelo do mundo open source a atingir esse nível de desempenho.
Hardware de treinamento: Stack completa Huawei, sem chips americanos
O terceiro fato que merece destaque é o hardware de treinamento do GLM-5.1 — todo realizado usando chips Huawei Ascend 910B + framework MindSpore, sem utilizar qualquer GPU Nvidia ou AMD. Isso gerou uma discussão considerável na comunidade internacional de IA, pois prova diretamente que: em um ambiente com restrições de Hopper / Blackwell, equipes da China continental já conseguem realizar o pré-treinamento de modelos da magnitude de 754B MoE em hardware nacional. Isso não é apenas uma vitória técnica do modelo, mas uma demonstração de nível industrial da infraestrutura de treinamento de IA na China continental.
Relatório Completo de Benchmarks do GLM-5.1
Para não deixar passar nenhum ponto de dados importante, organizamos o relatório de benchmarks do GLM-5.1 divulgado pela Z.ai na tabela abaixo.
| Benchmark | Pontuação GLM-5.1 | Significado |
|---|---|---|
| SWE-Bench Pro | 58.4 ⭐ | Correção de código real, #1 global (open source) |
| SWE-bench Verified | 77.8% | Correção de código geral, próximo aos ~94.6% do Claude Opus 4.6 (80.8%) |
| CyberGym | 68.7 | Raciocínio de segurança/CTF (execução única de 1507 tarefas) |
| MCP-Atlas | 71.8 | Benchmark de invocação de ferramentas MCP |
| T3-Bench | 70.6 | Uso de ferramentas e tarefas de agente |
| Humanity's Last Exam | 31.0 / 52.3 | Raciocínio de alta complexidade (sem ferramentas / com ferramentas) |
| AIME 2026 | 95.3 | Nível de olimpíada de matemática dos EUA |
| GPQA-Diamond | 86.2 | Raciocínio científico de nível especialista |
Uma breve interpretação dos pontos principais:
- Nível de código: O SWE-Bench Pro já atingiu o topo, e o SWE-bench Verified alcançou 94.6% da performance do Claude Opus 4.6 — o que significa que, para a grande maioria das tarefas de engenharia diárias, a capacidade de codificação do GLM-5.1 já está no mesmo patamar do Claude Opus, o modelo mais forte da atualidade;
- Raciocínio matemático: Com 95.3 no AIME 2026 e 86.2 no GPQA-Diamond, ele pertence ao "nível de fronteira";
- Agentes e uso de ferramentas: Com 71.8 no MCP-Atlas e 70.6 no T3-Bench, a capacidade para tarefas de longa duração foi confirmada pelos benchmarks;
- Avaliação honesta: Estes dados vêm totalmente de relatórios da própria Z.ai. Até o momento da publicação, não houve uma verificação independente por laboratórios terceiros, portanto, use-os como referência, mas não como "valores absolutos".
🎯 Sugestão de validação de benchmark: Ao lidar com benchmarks autorrelatados, a atitude mais pragmática é testar com as tarefas reais do seu negócio. O GLM-5.1 já está disponível no APIYI apiyi.com; você pode usar os 5 a 10 comandos (prompts) de codificação mais comuns da sua equipe e rodá-los no GLM-5.1, Claude Opus 4.6 e GPT-5.4, usando seus próprios dados de negócio para validar inversamente as conclusões do SWE-Bench Pro.
Estrutura de preços do GLM-5.1: Por que é considerado um "cavalo de batalha com excelente custo-benefício"
Outra característica do GLM-5.1 que não pode ser ignorada é o preço. Colocamos ele diretamente na mesma tabela de comparação com os principais modelos de fronteira.
Comparação de preço por Token
| Modelo | Entrada ($/M) | Saída ($/M) | Open Source |
|---|---|---|---|
| GLM-5.1 | $1.00 | $3.20 | ✅ MIT |
| Claude Opus 4.6 | Significativamente mais caro | Significativamente mais caro | ❌ |
| GPT-5.4 | Mais caro | Mais caro | ❌ |
| Gemini 3.1 Pro | Médio | Médio | ❌ |
Estes valores de $1.00 / $3.20 estão na "faixa de preço base" para modelos de codificação de fronteira: comparado a modelos de código fechado como o Claude Opus 4.6, o preço unitário real do GLM-5.1 é apenas uma fração, enquanto a própria Z.ai promove os "94.6% da performance de codificação do Claude Opus 4.6" como um de seus principais diferenciais.
GLM Coding Plan e planos de assinatura
Além da cobrança por token, a Z.ai lançou o GLM Coding Plan — um plano fixo voltado para cenários de "codificação intensiva" como Cursor, Cline e Claude Code, com preço inicial de cerca de $3/mês, incluindo 120 comandos, muito abaixo dos planos de codificação de modelos fechados similares. Esses planos geralmente são vinculados a várias categorias (Max / Pro / Lite), permitindo que, em fluxos de trabalho de "programação diária" (onde há chamadas frequentes, mas com custo unitário baixo), você obtenha "capacidade de codificação nível Opus + custo quase gratuito".
🎯 Sugestão de seleção de modelo: Para equipes que desejam "usar capacidade de codificação nível Claude Opus, mas não querem ser esmagadas pelo preço do Opus", recomendamos usar o GLM-5.1 diretamente via APIYI apiyi.com: você não só desfruta de uma interface unificada e faturamento em moeda local, como também pode alternar entre GPT-5.4 / Claude Opus 4.6 no mesmo código de negócio para testes A/B, usando os dados reais de fatura para deduzir qual modelo oferece o melhor custo-benefício.
GLM-5.1 já disponível na APIYI: exemplo mínimo de invocação
Por fim, a parte que mais interessa aos desenvolvedores: o GLM-5.1 já está disponível na APIYI (apiyi.com). Você pode invocá-lo diretamente usando o SDK compatível com OpenAI existente, sem a necessidade de implantar os pesos de 754B de parâmetros por conta própria no Hugging Face.
Exemplo mínimo em Python
Abaixo, apresento um exemplo mínimo de invocação em Python, mostrando como utilizar o SDK oficial da OpenAI para chamar o GLM-5.1:
from openai import OpenAI
# Altere a base_url para a APIYI e substitua api_key pela sua chave API da APIYI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_APIYI_KEY"
)
resp = client.chat.completions.create(
model="glm-5.1", # Especifique diretamente o ID do modelo GLM-5.1
messages=[
{"role": "system", "content": "Você é um engenheiro de software especialista."},
{"role": "user", "content": "Escreva um cache LRU em Python com tempo de expiração e limite de capacidade."}
],
max_tokens=4096
)
print(resp.choices[0].message.content)
O código de negócio permanece exatamente o mesmo — a lógica que você usava para chamar GPT-4, Claude ou DeepSeek é a mesma que você usará para o GLM-5.1.
Integração com Cursor / Cline / Claude Code
A Z.ai confirmou oficialmente que o GLM-5.1 é compatível com todas as ferramentas de codificação que seguem o padrão OpenAI, incluindo Claude Code, OpenClaw e Cline. Nessas ferramentas, basta apontar o endpoint compatível com OpenAI para https://api.apiyi.com/v1 e selecionar o modelo GLM-5.1. Assim, você pode trocar seu modelo principal de codificação de Opus/GPT-5 para GLM-5.1 sem alterar nenhum fluxo de trabalho. Para IDEs como o Cursor, que também suportam um endpoint personalizado da OpenAI, o processo é idêntico.
Exemplo de invocação via streaming e janela de contexto longa
O GLM-5.1 na APIYI mantém integralmente a capacidade de 200K de janela de contexto e 128K de saída. Para tarefas de agentes de longa duração, você pode ativar o modo stream para obter uma latência menor no primeiro token:
stream = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "Faça uma revisão completa deste repositório Python de 5000 linhas, listando possíveis bugs e sugestões de refatoração."}
],
stream=True,
max_tokens=128000
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
print(delta.content, end="", flush=True)
🎯 Sugestão de integração: O GLM-5.1 na APIYI (apiyi.com) já oferece suporte à interface compatível com OpenAI, saída via streaming e a janela de contexto completa de 200K. Recomendamos que você aponte hoje mesmo o endpoint das ferramentas Cursor, Cline ou Claude Code da sua equipe para a APIYI e teste o GLM-5.1 como seu novo modelo principal de codificação por uma semana, validando com tarefas reais se ele consegue substituir o Opus ou GPT-5 que você utiliza atualmente.
Para quem o GLM-5.1 é indicado (e para quem não é)
Público-alvo
| Público | Motivo |
|---|---|
| Usuários intensivos de Coding Agent | Liderança no SWE-Bench Pro, capacidade para tarefas de longa duração de 8 horas |
| Equipes que buscam modelos de ponta com orçamento limitado | Preço unitário de $1.00/$3.20, muito abaixo do Opus/GPT-5 |
| Empresas que precisam de implantação comercial com licença MIT | Sem restrições, permite uso comercial e derivações de código fechado |
| Usuários de Cursor / Cline / Claude Code | Compatibilidade nativa com a interface OpenAI, substituição com um clique |
| Pesquisadores interessados na stack de treinamento de IA nacional | Treinado inteiramente em Huawei Ascend 910B + MindSpore |
| Cenários de raciocínio matemático/científico | AIME 2026 95.3 / GPQA-Diamond 86.2 |
Não recomendado para
| Público | Motivo |
|---|---|
| Usuários que priorizam "benchmarks de terceiros independentes" | Os dados atuais são reportados pela própria Z.ai; é necessário realizar a própria verificação |
| Tarefas focadas em multimodal (imagem/vídeo) | O GLM-5.1 é focado em texto e código; multimodal não é seu ponto forte |
| Dependência total do ecossistema de ferramentas da Anthropic/OpenAI | Alguns recursos avançados ainda dependem das interfaces originais dos fabricantes |
FAQ sobre o GLM-5.1
Q1: O GLM-5.1 é realmente open source? Pode ser usado comercialmente?
Sim. O GLM-5.1 foi totalmente disponibilizado como código aberto pela Z.ai em 7 de abril de 2026 no Hugging Face (zai-org/GLM-5) sob a licença MIT, o que permite uso comercial, derivações de código fechado e ajuste fino (fine-tuning) secundário, bastando manter o aviso de direitos autorais. Esta é uma das licenças de código aberto mais permissivas que existem, o que significa que você pode integrar o GLM-5.1 diretamente em seus produtos comerciais, SaaS ou implementações privadas sem pagar qualquer taxa de licenciamento.
Q2: O GLM-5.1 é realmente melhor que o GPT-5.4 e o Claude Opus 4.6?
No benchmark SWE-Bench Pro, a pontuação divulgada pela Z.ai (58,4) supera, de fato, o GPT-5.4 (57,7) e o Claude Opus 4.6 (57,3). No entanto, um aviso: esses dados foram reportados pela própria Z.ai e ainda não foram totalmente replicados por laboratórios de avaliação independentes. Recomendamos que você não trate esses números como uma "verdade absoluta", mas sim que os teste com as tarefas reais do seu negócio — algo que agora pode ser feito diretamente com o GLM-5.1 via APIYI (apiyi.com), sem a necessidade de realizar sua própria implementação.
Q3: A API do GLM-5.1 já está disponível na APIYI? Como faço a chamada?
Já está disponível. Basta alterar a base_url do SDK oficial da OpenAI para https://api.apiyi.com/v1, substituir a api_key pela sua chave API da APIYI e definir o model com o ID correspondente ao GLM-5.1. Você poderá realizar a invocação do modelo imediatamente, sem precisar reescrever seu código de negócio. O "exemplo mínimo de chamada" no artigo mostra a versão em Python, mas os SDKs de Node, Go e Rust também são compatíveis.
Q4: O GLM-5.1 é melhor que outros modelos open source nacionais como DeepSeek, Qwen e Kimi?
O grande diferencial do GLM-5.1 é a "codificação de agente de longo alcance + liderança no SWE-Bench Pro" — um patamar que DeepSeek, Qwen e Kimi ainda não atingiram de forma direta. Se o seu foco é "conversa diária + RAG", o DeepSeek e o Qwen continuam sendo muito competitivos; mas, se o seu negócio envolve Agente de Programação / Integração com IDE / Correção de código, o GLM-5.1 é a primeira escolha no mundo open source atualmente. Na APIYI, você pode colocar esses modelos em um teste comparativo e formar sua própria opinião em 15 minutos.
Q5: Que hardware é necessário para implementar o GLM-5.1 localmente?
O GLM-5.1 possui uma arquitetura MoE com 754B de parâmetros totais e 40B ativos. A implementação local exige um cluster de GPU profissional com múltiplas placas, o que é quase inviável para equipes comuns. A Z.ai recomenda oficialmente o uso de vLLM, SGLang ou KTransformers para uma implementação de inferência em larga escala. Se o seu objetivo é apenas usar o GLM-5.1 e não pesquisá-lo, a forma mais eficiente é realizar a invocação via APIYI (apiyi.com) — sem precisar de GPU, sem manutenção e pagando apenas pelo uso.
Q6: O treinamento do GLM-5.1 realmente não utilizou GPUs da Nvidia?
Sim. A Z.ai revelou que o GLM-5.1 foi treinado inteiramente em chips Huawei Ascend 910B com o framework MindSpore, sem utilizar qualquer GPU da Nvidia ou AMD. Este é o primeiro caso no campo de modelos de linguagem grandes de código aberto em 2026 a concluir o treinamento de um "modelo de linguagem grande MoE de 754B com hardware totalmente nacional", o que possui um significado industrial considerável.
Conclusão: O GLM-5.1 é um ponto de virada para a IA open source em 2026
Ao conectar a arquitetura, benchmarks, preços, stack de treinamento e o caminho de acesso via API, a posição do GLM-5.1 em abril de 2026 torna-se muito clara: não se trata apenas de mais uma atualização comum de modelo open source, mas de um evento emblemático onde o "código aberto realmente supera o estado da arte de código fechado". A liderança global no SWE-Bench Pro com 58,4 pontos, a abertura total da licença MIT, o preço extremamente baixo de $1,00/$3,20, a janela de contexto de 200K + 128K de saída, a capacidade de agente de longo alcance de 8 horas e a stack de treinamento totalmente em Huawei Ascend 910B — cada um desses fatos, isoladamente, já mereceria uma reportagem; somados, tornam-se um "ponto de virada para o open source".
Para os desenvolvedores, a melhor notícia é que a API do GLM-5.1 já está disponível na APIYI: você não precisa implementar pesos de 754B por conta própria, não precisa de cartão de crédito internacional e não precisa esperar por aprovações. Basta alterar a base_url para https://api.apiyi.com/v1 e o model para GLM-5.1, e hoje mesmo você pode substituir seu principal modelo de codificação no Cursor, Cline ou Claude Code por este novo rei do open source. Se você ainda sofre com as faturas do Opus ou do GPT-5, esta é uma janela de oportunidade que vale a pena testar durante uma tarde.
🎯 Sugestão final: Para experimentar em primeira mão a "capacidade de codificação de ponta + preço open source + acesso estável da APIYI" do GLM-5.1, recomendamos que você crie uma chave API no apiyi.com hoje mesmo, altere a
base_urldo seu SDK da OpenAI parahttps://api.apiyi.com/v1, defina omodelcomo GLM-5.1 e utilize-o em suas tarefas diárias de código por uma semana. Independentemente de decidir mudar seu modelo principal, esse teste prático lhe dará uma percepção em primeira mão do nível real da IA open source em 2026.
Autor: Equipe APIYI | Focados na implementação de modelos de linguagem grandes de IA e no ecossistema open source. Para mais exemplos práticos e comparações entre GLM-5.1, Claude e GPT-5, visite APIYI em apiyi.com.