Le 7 avril 2026, Z.ai (anciennement Zhipu AI) a officiellement publié les poids complets du GLM-5.1 sous licence MIT sur le dépôt Hugging Face zai-org/GLM-5. Cette annonce a immédiatement fait sensation dans la communauté IA anglophone, non pas parce qu'il s'agit d'un "énième grand modèle de langage open source", mais parce qu'il a atteint la première place mondiale sur le benchmark d'ingénierie logicielle SWE-Bench Pro avec un score de 58,4, dépassant directement les 57,7 points de GPT-5.4, les 57,3 points de Claude Opus 4.6 et les 54,2 points de Gemini 3.1 Pro. C'est la première fois qu'un modèle open source surpasse tous les modèles propriétaires de pointe sur un benchmark de "correction de code réel" largement cité par l'industrie.
Ce qui intéresse encore plus les développeurs en Chine continentale, c'est la rapidité de mise en ligne de l'API GLM-5.1 : APIYI (apiyi.com) l'a déjà intégrée dès le premier jour. Vous n'avez plus besoin de télécharger vous-même les poids de 754 milliards de paramètres depuis Hugging Face, ni de demander un compte officiel Z.ai. Il suffit de modifier le base_url d'un SDK OpenAI existant pour effectuer l'invocation du modèle. Cet article présente le GLM-5.1 sous 7 angles (architecture, benchmarks, matériel d'entraînement, tarification, méthodes d'accès) et fournit un exemple de code minimal pour appeler GLM-5.1 via APIYI.

Aperçu des informations clés sur GLM-5.1 (Édition avril 2026)
Avant d'entrer dans les détails, résumons tous les faits essentiels concernant le GLM-5.1 dans ce tableau.
| Dimension | Informations connues sur GLM-5.1 |
|---|---|
| Éditeur | Z.ai (anciennement Zhipu AI, cotée à la Bourse de Hong Kong en janvier 2026, valorisation d'environ 31,3 milliards USD) |
| Date de sortie | 7 avril 2026 |
| Licence | MIT (autorise l'usage commercial, la modification et les dérivés propriétaires) |
| Adresse du dépôt | huggingface.co/zai-org/GLM-5 |
| Architecture | MoE (Mixture of Experts), 754B paramètres totaux / 40B paramètres actifs |
| Fenêtre de contexte | 200 000 jetons |
| Sortie maximale | 128 000 jetons |
| Données d'entraînement | 28,5T jetons (augmentation par rapport aux 23T de GLM-5) |
| Matériel d'entraînement | Entièrement sur Huawei Ascend 910B + framework MindSpore (sans Nvidia / AMD) |
| Framework de déploiement | vLLM / SGLang / KTransformers |
| Capacité phare | Agent de codage longue portée (travail continu sur une tâche pendant environ 8 heures) |
| Tarification (API directe) | 1,00 $ / million de jetons en entrée, 3,20 $ / million de jetons en sortie |
| Forfait codage | Plan GLM Coding à partir d'environ 3 $/mois |
| Accès APIYI | ✅ Disponible, accessible via https://api.apiyi.com/v1 |
| Outils compatibles | Claude Code / OpenClaw / Cline / Tout éditeur compatible OpenAI |
🎯 Conseil pour une prise en main rapide : GLM-5.1 est déjà intégré à APIYI (apiyi.com). Il vous suffit de remplacer le
base_urlde votre SDK OpenAI existant parhttps://api.apiyi.com/v1et lemodelpar le nom du modèle GLM-5.1 correspondant pour remplacer immédiatement votre modèle principal dans vos flux de travail Agent / Cursor / Cline, sans avoir à réécrire le moindre code métier.
Pourquoi GLM-5.1 marque un "tournant" pour l'open source
Pour comprendre pourquoi GLM-5.1 est qualifié de "tournant" par la communauté IA anglophone, il faut mettre en perspective quelques faits marquants.
Première étape : un modèle open source au sommet du SWE-Bench Pro
Le SWE-Bench Pro est actuellement reconnu comme l'un des benchmarks de réparation de code réel les plus exigeants de l'industrie. Les tâches proviennent intégralement de dépôts de code industriels ; le modèle doit comprendre le contexte, localiser le bug et rédiger une correction qui passe les tests — on est loin du simple exercice de type "LeetCode". Avant la sortie de GLM-5.1, ce classement était quasi exclusivement dominé par les séries GPT-5.x et Claude Opus, les modèles open source n'ayant jamais réellement approché le top 3.
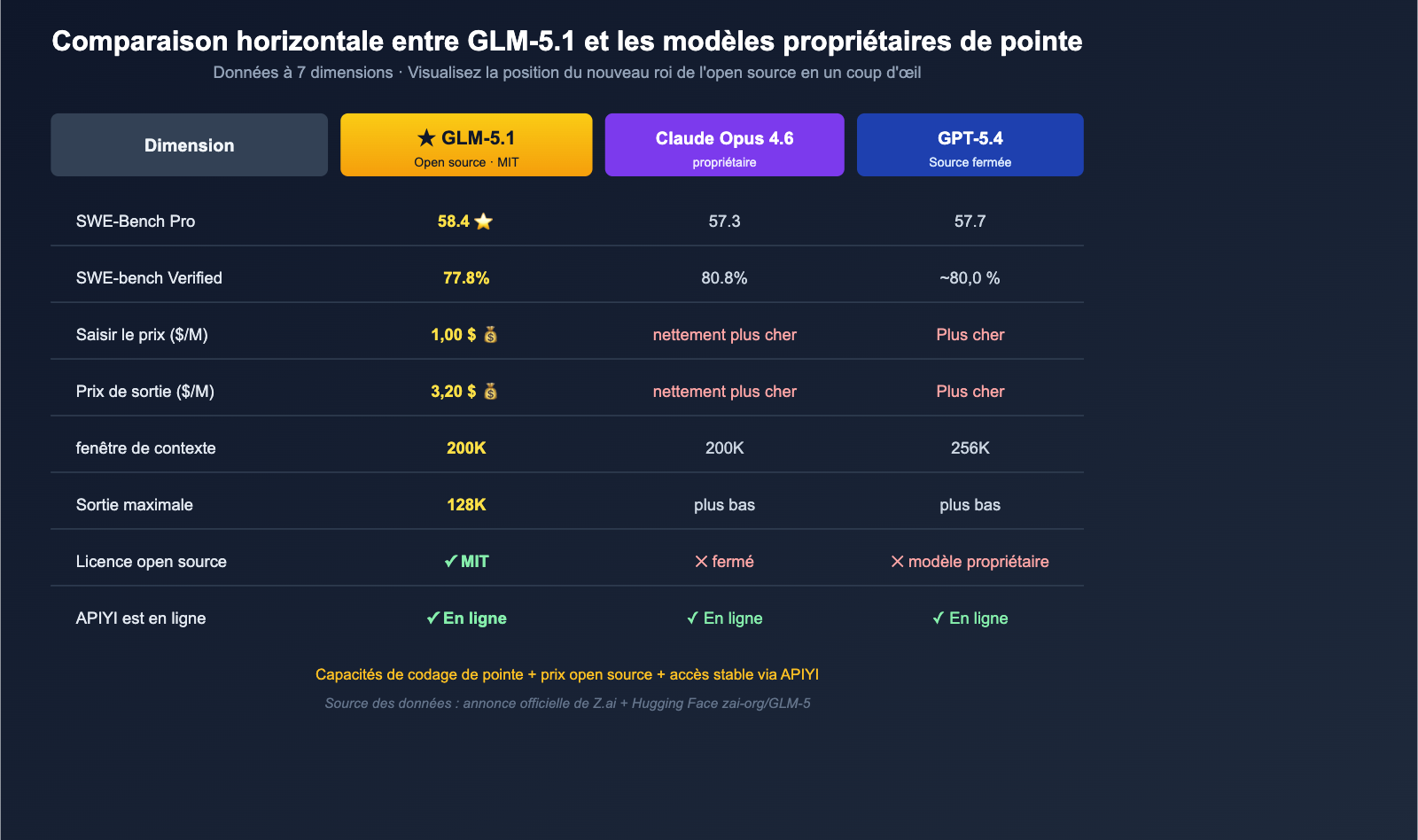
Pourtant, cette fois, GLM-5.1 s'empare de la première place avec un score de 58,4 :
| Modèle | Score SWE-Bench Pro | Open source |
|---|---|---|
| GLM-5.1 | 58,4 ⭐ | ✅ MIT |
| GPT-5.4 | 57,7 | ❌ |
| Claude Opus 4.6 | 57,3 | ❌ |
| Gemini 3.1 Pro | 54,2 | ❌ |
Il ne s'agit pas d'une performance marginale, mais d'une suppression totale de l'écart entre "open source" et "propriétaire" sur le benchmark industriel le plus difficile. Même en tenant compte de la clause de non-responsabilité selon laquelle "le benchmark est auto-déclaré par Z.ai et une évaluation indépendante est en attente", l'importance industrielle de cet événement est indéniable : pour la première fois, la communauté open source dispose d'un modèle gratuit capable de rivaliser avec les modèles propriétaires de pointe sur la "réparation de code réel".
Deuxième étape : une licence MIT réellement commerciale
Un autre fait crucial concernant GLM-5.1 est sa licence : MIT. Il ne s'agit pas de la classique Apache 2.0, et encore moins de licences restrictives de type "usage recherche uniquement / non commercial". La licence MIT est très claire : n'importe qui peut télécharger, modifier, affiner, déployer, commercialiser, créer des dérivés fermés ou vendre le modèle sans aucune restriction, à condition de conserver l'avis de droit d'auteur.
Pour les entreprises, cela signifie que GLM-5.1 peut être utilisé sans aucune crainte pour :
- Des agents de codage internes pour des produits propriétaires ;
- Des modules de génération ou de revue de code au sein d'un SaaS commercial ;
- Des extensions d'IDE déployées en privé ;
- Tout scénario de conformité où "les poids du modèle ne doivent pas dépendre de l'API d'un fournisseur tiers".
En avril 2026, GLM-5.1 est pratiquement le seul choix capable de combiner "performance de pointe + licence open source MIT + sommet des benchmarks industriels".

Architecture et entraînement de GLM-5.1 : 754B MoE + pile technologique Huawei
Le deuxième fait qui distingue GLM-5.1 est sa pile d'entraînement.
Architecture MoE : 754B de paramètres totaux / 40B activés
GLM-5.1 utilise une architecture de mélange d'experts (MoE) avec un total de 754B de paramètres, dont environ 40B sont activés à chaque inférence. Cette conception de "grand modèle + activation creuse" a été éprouvée par des modèles comme DeepSeek, Qwen ou Mixtral. Ses avantages principaux sont :
- Une grande capacité lors de l'entraînement, permettant d'absorber plus de connaissances (28,5T tokens de données de pré-entraînement) ;
- Une activation limitée à une petite partie des experts lors de l'inférence, avec une consommation de mémoire vidéo et une latence proches d'un modèle dense de 40B ;
- Des chemins d'experts distincts pour le dialogue et le code, offrant une meilleure cohérence sur les tâches longues.
| Dimension | GLM-5 (génération précédente) | GLM-5.1 (actuel) |
|---|---|---|
| Paramètres totaux | 355B | 754B |
| Paramètres activés | 32B | 40B |
| Données de pré-entraînement | 23T tokens | 28,5T tokens |
| Fenêtre de contexte | Limitée | 200K |
| Sortie maximale | Limitée | 128K |
| Spécialisation Coding | Oui | ✅ Amélioration significative |
| Tâches longues Agent | Oui | ✅ ~8 heures par tâche |
Point fort technique : Agent longue durée de 8 heures
Dans son annonce, Z.ai insiste sur la capacité de GLM-5.1 à gérer des "tâches uniques de 8 heures". Cela signifie que vous pouvez confier une tâche d'ingénierie réelle (comme corriger un bug multi-fichiers, migrer une ancienne bibliothèque ou compléter une suite de tests) à GLM-5.1, et il peut enchaîner planification → exécution → test → correction → optimisation secondaire sans intervention humaine, jusqu'à obtenir un résultat prêt pour la production, le tout sur une durée allant jusqu'à 8 heures. Cette courbe de capacité d'"Agent endurant" n'avait été reproduite de manière stable dans l'industrie que par la série Claude Opus — GLM-5.1 est le premier modèle du monde open source à atteindre ce niveau de performance.
Matériel d'entraînement : pile Huawei complète, sans puces américaines
Le troisième fait marquant est le matériel utilisé pour l'entraînement de GLM-5.1 : entièrement réalisé avec des puces Huawei Ascend 910B et le framework MindSpore, sans aucune utilisation de GPU Nvidia ou AMD. Cela a suscité un vif débat dans la communauté IA anglophone, car cela prouve directement que : dans un environnement restreint par les limitations sur les puces Hopper / Blackwell, des équipes chinoises sont capables d'entraîner des modèles de l'ordre de 754B MoE sur du matériel national. Ce n'est pas seulement une victoire technique pour le modèle, c'est une démonstration industrielle de l'infrastructure d'entraînement IA en Chine.
Fiche technique complète : GLM-5.1
Pour ne manquer aucun point de données important, nous avons compilé la fiche technique de GLM-5.1 publiée par Z.ai dans le tableau ci-dessous.
| Référence | Score GLM-5.1 | Signification |
|---|---|---|
| SWE-Bench Pro | 58.4 ⭐ | Correction de code réelle, n°1 mondial (open source) |
| SWE-bench Verified | 77.8% | Correction de code généraliste, ~94,6 % de Claude Opus 4.6 (80,8 %) |
| CyberGym | 68.7 | Sécurité/Raisonnement CTF (sur 1507 tâches) |
| MCP-Atlas | 71.8 | Référence d'invocation d'outils MCP |
| T3-Bench | 70.6 | Utilisation d'outils et tâches d'agent |
| Humanity's Last Exam | 31.0 / 52.3 | Raisonnement complexe (sans outil / avec outil) |
| AIME 2026 | 95.3 | Niveau compétition olympique de mathématiques |
| GPQA-Diamond | 86.2 | Raisonnement scientifique niveau expert |
Voici les points clés à retenir :
- Niveau code : Il arrive en tête sur SWE-Bench Pro et atteint 94,6 % des performances de Claude Opus 4.6 sur SWE-bench Verified. Cela signifie que pour la grande majorité des tâches d'ingénierie quotidiennes, les capacités de codage de GLM-5.1 sont au même niveau que le modèle le plus puissant du moment, Claude Opus.
- Raisonnement mathématique : Avec 95,3 à l'AIME 2026 et 86,2 au GPQA-Diamond, il se situe à un niveau "de pointe".
- Agents et outils : Les scores de 71,8 sur MCP-Atlas et 70,6 sur T3-Bench confirment ses capacités sur les tâches complexes et longues.
- Évaluation honnête : Ces données proviennent actuellement entièrement des rapports de Z.ai. À l'heure où nous écrivons ces lignes, aucune évaluation indépendante par un tiers n'a encore été réalisée. Ces chiffres sont donc à prendre comme une référence, et non comme une "vérité absolue".
🎯 Conseil de validation : Face à des benchmarks auto-déclarés, l'approche la plus pragmatique consiste à tester le modèle sur vos propres tâches métier. GLM-5.1 est désormais disponible sur APIYI (apiyi.com). Vous pouvez directement soumettre 5 à 10 de vos invites de codage habituelles à GLM-5.1, Claude Opus 4.6 et GPT-5.4 pour vérifier par vous-même les conclusions de SWE-Bench Pro avec vos propres données.
Structure tarifaire de GLM-5.1 : Pourquoi c'est le "outsider au meilleur rapport qualité-prix"
L'autre caractéristique incontournable de GLM-5.1 est son prix. Comparons-le directement aux modèles de pointe actuels.
Comparaison du prix par jeton (token)
| Modèle | Entrée ($/M) | Sortie ($/M) | Open source |
|---|---|---|---|
| GLM-5.1 | 1,00 $ | 3,20 $ | ✅ MIT |
| Claude Opus 4.6 | Nettement plus cher | Nettement plus cher | ❌ |
| GPT-5.4 | Plus cher | Plus cher | ❌ |
| Gemini 3.1 Pro | Moyen | Moyen | ❌ |
Le duo 1,00 $ / 3,20 $ se situe au niveau du "prix plancher" dans la catégorie des modèles de codage de pointe. Par rapport à un modèle propriétaire comme Claude Opus 4.6, le coût unitaire réel de GLM-5.1 ne représente qu'une fraction, alors que Z.ai met en avant ses "94,6 % de performance de codage par rapport à Claude Opus 4.6" comme argument de vente principal.
Plan de codage GLM et offres groupées
Au-delà de la facturation à l'usage, Z.ai a lancé le GLM Coding Plan, une offre forfaitaire destinée aux scénarios de "codage intensif" comme Cursor, Cline ou Claude Code. À partir de 3 $/mois pour 120 invites, ce tarif est bien inférieur aux abonnements de codage propriétaires équivalents. Ces forfaits, souvent déclinés en versions Max / Pro / Lite, permettent, dans un flux de travail quotidien de développeur (appels fréquents mais peu coûteux), d'obtenir des capacités de codage de niveau Opus pour un coût quasi dérisoire.
🎯 Conseil de sélection : Pour les équipes qui souhaitent "bénéficier de la puissance de codage de Claude Opus sans subir le prix d'Opus", nous recommandons d'utiliser GLM-5.1 via APIYI (apiyi.com). Vous profiterez d'une interface unifiée et, surtout, de la possibilité de basculer instantanément entre GPT-5.4 et Claude Opus 4.6 pour effectuer des tests A/B sur votre propre code, afin de déterminer quel modèle offre le meilleur retour sur investissement selon vos factures réelles.
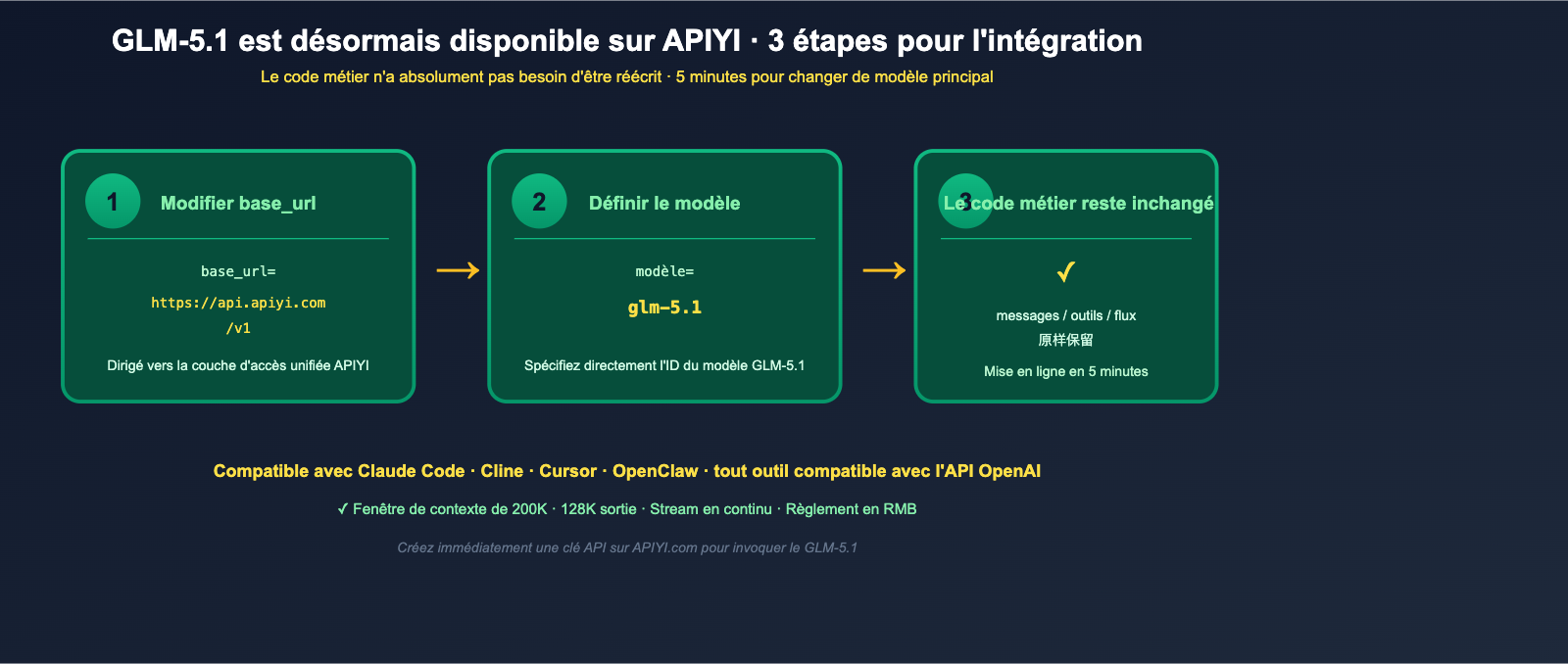
GLM-5.1 est désormais disponible sur APIYI : exemple d'invocation minimale
Enfin, voici la partie qui intéresse le plus les développeurs : GLM-5.1 est désormais disponible sur APIYI (apiyi.com). Vous pouvez l'appeler directement via le SDK OpenAI existant, sans avoir besoin de déployer vous-même les poids de 754B de paramètres sur Hugging Face.
Exemple minimal en Python
Voici un exemple minimal d'invocation en Python, montrant comment appeler GLM-5.1 avec le SDK officiel d'OpenAI :
from openai import OpenAI
# Remplacez base_url par APIYI et api_key par votre clé APIYI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="VOTRE_CLE_APIYI"
)
resp = client.chat.completions.create(
model="glm-5.1", # Spécifiez directement l'ID du modèle GLM-5.1
messages=[
{"role": "system", "content": "Vous êtes un ingénieur logiciel expert."},
{"role": "user", "content": "Écrivez un cache LRU en Python avec un temps d'expiration et une limite de capacité."}
],
max_tokens=4096
)
print(resp.choices[0].message.content)
Votre code métier reste inchangé : la logique utilisée précédemment pour appeler GPT-4, Claude ou DeepSeek fonctionne exactement de la même manière pour GLM-5.1.
Intégration avec Cursor / Cline / Claude Code
Z.ai a officiellement confirmé que GLM-5.1 est compatible avec tous les outils de développement conformes aux standards OpenAI, y compris Claude Code, OpenClaw et Cline. Dans ces outils, il suffit de pointer l'URL de compatibilité OpenAI vers https://api.apiyi.com/v1 et de sélectionner le modèle GLM-5.1. Vous pourrez ainsi basculer votre modèle de codage principal de Opus / GPT-5 vers GLM-5.1 sans modifier aucun flux de travail. Pour les IDE comme Cursor qui prennent également en charge les points de terminaison personnalisés (Custom Endpoint) OpenAI, la procédure est identique.
Exemple d'invocation en streaming et longue fenêtre de contexte
GLM-5.1 sur APIYI conserve intégralement sa capacité de 200K pour la fenêtre de contexte et 128K pour la sortie. Pour les tâches d'Agent longue durée, vous pouvez activer le mode stream pour obtenir une latence plus faible sur le premier jeton (token) :
stream = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "Examinez en détail ce dépôt Python de 5000 lignes et listez les bugs potentiels ainsi que les suggestions de refactorisation."}
],
stream=True,
max_tokens=128000
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
print(delta.content, end="", flush=True)
🎯 Conseil d'intégration : GLM-5.1 sur APIYI (apiyi.com) prend déjà en charge l'interface compatible OpenAI, la sortie en flux (stream) et la fenêtre de contexte complète de 200K. Nous vous suggérons de configurer dès aujourd'hui vos outils Cursor / Cline / Claude Code pour pointer vers APIYI et d'essayer GLM-5.1 comme nouveau modèle de codage principal pendant une semaine, afin de vérifier sur des tâches d'ingénierie réelles s'il peut remplacer Opus / GPT-5.
À qui s'adresse GLM-5.1 (et à qui il ne s'adresse pas)
Public cible
| Profil | Raison |
|---|---|
| Utilisateurs intensifs de Coding Agent | En tête du classement SWE-Bench Pro, capable de gérer des tâches de 8 heures |
| Équipes au budget limité souhaitant utiliser des modèles de pointe | Prix unitaire de $1.00/$3.20, bien inférieur à Opus / GPT-5 |
| Entreprises ayant besoin d'un déploiement commercial sous licence MIT | Aucune restriction, utilisable commercialement, dérivables en modèles fermés |
| Utilisateurs de Cursor / Cline / Claude Code | Compatibilité native avec l'interface OpenAI, remplacement en un clic |
| Chercheurs intéressés par la pile d'entraînement IA nationale | Entraîné entièrement sur Huawei Ascend 910B + MindSpore |
| Scénarios de raisonnement mathématique / scientifique | AIME 2026 95.3 / GPQA-Diamond 86.2 |
Profils moins adaptés
| Profil | Raison |
|---|---|
| Utilisateurs accordant une importance capitale aux "benchmarks tiers indépendants" | Les données actuelles proviennent uniquement de Z.ai, nécessitent une vérification indépendante |
| Tâches principalement multimodales (image/vidéo) | GLM-5.1 se concentre sur le texte et le code, le multimodal n'est pas son point fort |
| Dépendance totale à l'écosystème d'outils Anthropic / OpenAI | Certaines fonctionnalités avancées restent réservées aux interfaces d'origine |
FAQ sur GLM-5.1
Q1 : GLM-5.1 est-il vraiment open source ? Peut-on l'utiliser commercialement ?
Oui. GLM-5.1 a été rendu entièrement open source par Z.ai le 7 avril 2026 sur Hugging Face (zai-org/GLM-5) sous licence MIT. Cela autorise l'usage commercial, les dérivés fermés et le fine-tuning, à condition de conserver la mention de copyright. C'est l'une des licences open source les plus permissives, ce qui signifie que vous pouvez intégrer GLM-5.1 directement dans vos produits commerciaux, SaaS ou déploiements privés sans payer de frais de licence.
Q2 : GLM-5.1 est-il vraiment plus performant que GPT-5.4 et Claude Opus 4.6 ?
Sur le benchmark SWE-Bench Pro, le score publié par Z.ai (58,4) dépasse effectivement ceux de GPT-5.4 (57,7) et Claude Opus 4.6 (57,3). Attention toutefois : ces données sont auto-déclarées par Z.ai et n'ont pas encore été totalement reproduites par des laboratoires tiers indépendants. Nous vous conseillons de ne pas prendre ces chiffres pour une "vérité absolue", mais plutôt de tester le modèle sur vos propres tâches métier — ce qui est désormais possible directement via APIYI (apiyi.com) avec GLM-5.1, sans avoir à gérer le déploiement vous-même.
Q3 : L'API de GLM-5.1 est-elle disponible sur APIYI ? Comment l'utiliser ?
C'est déjà en ligne. Il vous suffit de modifier le base_url du SDK OpenAI officiel par https://api.apiyi.com/v1, de remplacer l'api_key par votre clé API APIYI et de définir le model sur l'identifiant correspondant à GLM-5.1. Vous pouvez l'appeler immédiatement sans réécrire votre code métier. L'article propose un "exemple d'invocation minimal" en Python, mais les SDK Node, Go et Rust sont tout aussi compatibles.
Q4 : GLM-5.1 est-il meilleur que les autres modèles open source comme DeepSeek, Qwen ou Kimi ?
La principale différenciation de GLM-5.1 réside dans sa capacité de "codage par agent longue portée + sa première place au SWE-Bench Pro" — un domaine que DeepSeek, Qwen et Kimi n'avaient pas encore conquis frontalement. Si votre activité repose sur le "dialogue quotidien + RAG", DeepSeek et Qwen restent très compétitifs. En revanche, si votre cœur de métier concerne les agents de codage, l'intégration IDE ou la correction de code, GLM-5.1 est actuellement le meilleur choix dans le monde open source. Sur APIYI, vous pouvez comparer ces modèles en 15 minutes pour vous faire votre propre avis.
Q5 : Quel matériel est nécessaire pour déployer GLM-5.1 localement ?
GLM-5.1 possède une architecture MoE avec 754 milliards de paramètres au total et 40 milliards activés. Un déploiement local nécessite un cluster de GPU multi-cartes de niveau professionnel, ce qui est quasiment irréaliste pour une équipe standard. Z.ai recommande officiellement d'utiliser vLLM, SGLang ou KTransformers pour un déploiement de service d'inférence à grande échelle. Si vous souhaitez simplement utiliser GLM-5.1 sans faire de recherche, la méthode la plus efficace est de passer par APIYI (apiyi.com) — pas besoin de GPU, pas de maintenance, et vous payez à l'usage.
Q6 : L'entraînement de GLM-5.1 a-t-il vraiment été réalisé sans GPU Nvidia ?
Oui. Z.ai a révélé que GLM-5.1 a été entièrement entraîné sur des puces Huawei Ascend 910B avec le framework MindSpore, sans utiliser de GPU Nvidia ou AMD. C'est le premier cas dans le domaine des grands modèles de langage open source en 2026 à réussir l'entraînement d'un modèle MoE de 754B sur du matériel entièrement national, ce qui revêt une importance symbolique majeure pour l'industrie.
Conclusion : GLM-5.1 est un tournant pour l'IA open source en 2026
En reliant l'architecture, les benchmarks, les prix, la pile d'entraînement et les méthodes d'accès API, la position de GLM-5.1 en avril 2026 est très claire : il ne s'agit pas d'une simple mise à jour de modèle open source, mais d'un événement marquant prouvant que "l'open source peut réellement surpasser les modèles propriétaires de pointe". La première place mondiale au SWE-Bench Pro (58,4), l'ouverture totale sous licence MIT, les prix extrêmement bas ($1,00/$3,20), la fenêtre de contexte de 200K + 128K en sortie, les capacités d'agent longue portée sur 8 heures et la pile d'entraînement entièrement basée sur Huawei Ascend 910B — chacun de ces faits mériterait un article, mais leur cumul constitue un véritable "point de bascule".
Pour les développeurs, la bonne nouvelle est que l'API GLM-5.1 est déjà disponible sur APIYI : pas besoin de déployer vous-même 754B de poids, pas besoin de carte bancaire internationale, pas d'attente d'approbation. Il suffit de changer le base_url par https://api.apiyi.com/v1 et le model par GLM-5.1 pour remplacer dès aujourd'hui votre modèle de codage principal dans Cursor, Cline ou Claude Code par ce nouveau champion open source. Si vous vous inquiétez encore de vos factures Opus / GPT-5, c'est une fenêtre d'opportunité idéale pour faire des tests.
🎯 Conseil final : Pour découvrir immédiatement les "capacités de codage de pointe + prix open source + accès stable via APIYI" de GLM-5.1, nous vous suggérons de créer une clé API sur apiyi.com dès aujourd'hui, de modifier le
base_urlde votre SDK OpenAI parhttps://api.apiyi.com/v1et lemodelpar GLM-5.1, puis de l'utiliser sur vos tâches de code quotidiennes pendant une semaine. Que vous décidiez ou non de changer de modèle principal, ce test pratique vous donnera une première idée concrète du niveau réel de l'IA open source en 2026.
Auteur : Équipe APIYI | Suivez-nous pour plus d'actualités sur le déploiement des grands modèles de langage et l'écosystème open source. Pour plus d'exemples d'utilisation et de comparaisons de GLM-5.1 / Claude / GPT-5, visitez APIYI sur apiyi.com.