2026年4月7日,Z.ai(原智谱AI)正式将 GLM-5.1 的完整权重以 MIT协议 发布至 Hugging Face 仓库 zai-org/GLM-5。此次发布在英文 AI 圈引发了巨大轰动——这不仅仅是因为它“又是一个开源大规模语言模型”,更因为其在 SWE-Bench Pro 软件工程基准测试中以 58.4 分 登顶全球榜首,正面超越了 GPT-5.4 的 57.7 分、Claude Opus 4.6 的 57.3 分以及 Gemini 3.1 Pro 的 54.2 分。这是开源模型首次在工业界广泛认可的“真实代码修复”基准测试中,将闭源前沿模型全部甩在身后。
对于中国大陆的开发者来说,更令人兴奋的是 GLM-5.1 API 的上线节奏极快——APIYI (apiyi.com) 已经在第一时间完成接入。你不再需要亲自去 Hugging Face 下载 754B 参数的权重,也不需要申请 Z.ai 官方账号,只需通过现有的 OpenAI SDK 修改 base_url 即可直接调用。本文将从架构、基准、训练硬件、定价、接入方式等 7 个维度,全面介绍 GLM-5.1,并提供在 APIYI 上调用 GLM-5.1 的最小代码示例。

GLM-5.1 核心信息一览(2026 年 4 月版)
在深入拆解之前,我们先用一张表将“GLM-5.1”的所有关键事实总结如下:
| 维度 | GLM-5.1 已知信息 |
|---|---|
| 发布厂商 | Z.ai(原智谱AI,2026 年 1 月港股上市,估值约 313 亿美元) |
| 开源时间 | 2026 年 4 月 7 日 |
| 开源协议 | MIT(允许商用 + 二次修改 + 闭源衍生) |
| 仓库地址 | huggingface.co/zai-org/GLM-5 |
| 模型架构 | MoE(混合专家),754B 总参数 / 40B 激活参数 |
| 上下文窗口 | 200,000 tokens |
| 最大输出 | 128,000 tokens |
| 训练数据 | 28.5T tokens(在 GLM-5 基础上从 23T 提升) |
| 训练硬件 | 全部使用 Huawei Ascend 910B + MindSpore 框架(无 Nvidia / AMD) |
| 部署框架 | vLLM / SGLang / KTransformers |
| 旗舰能力 | 长程 Agent 编码(单任务可持续工作约 8 小时) |
| 定价(API 直采) | 输入 $1.00 / 百万 token,输出 $3.20 / 百万 token |
| 编码套餐 | GLM Coding Plan 起价约 $3/月 |
| APIYI 接入 | ✅ 已上线,通过 https://api.apiyi.com/v1 即可调用 |
| 兼容工具 | Claude Code / OpenClaw / Cline / 任意 OpenAI 兼容编辑器 |
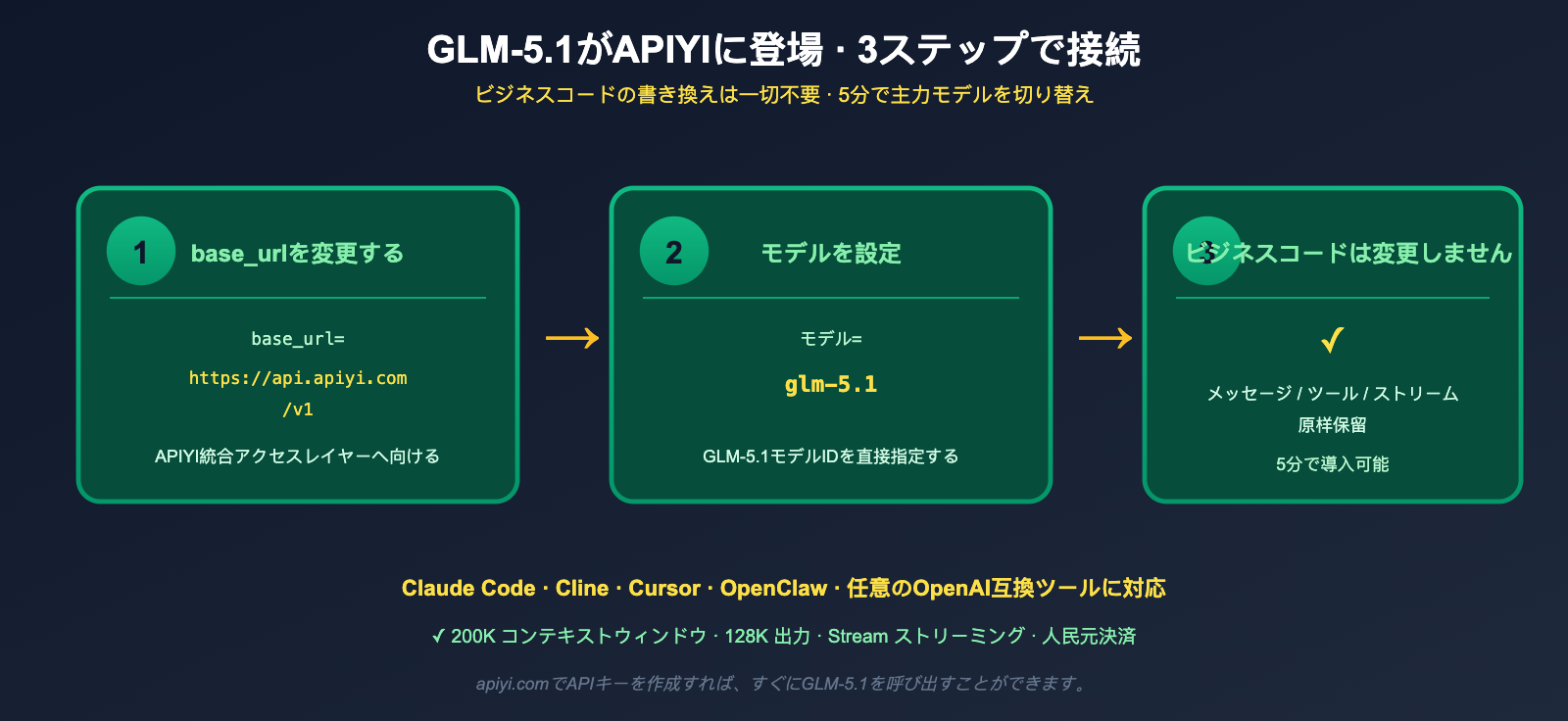
🎯 快速上手建议:GLM-5.1 已经在 APIYI (apiyi.com) 完成接入,你只需要将现有 OpenAI SDK 的
base_url改为https://api.apiyi.com/v1,并将model设置为对应的 GLM-5.1 模型名称,即可立刻在你的 Agent / Cursor / Cline 工作流中替换主力模型,无需重写任何业务代码。
GLM-5.1 が「オープンソースの転換点」と呼ばれる理由
GLM-5.1 がなぜ英語圏のAIコミュニティで「オープンソースの転換点(开源拐点)」と呼ばれているのか。その理由を理解するには、いくつかの重要な事実を照らし合わせて見る必要があります。
第1の理由:SWE-Bench Pro でオープンソースモデルが首位に
SWE-Bench Pro は、現在業界で最も難易度が高いとされる実戦的なコード修正ベンチマークの一つです。タスクはすべて実際の産業用コードリポジトリから抽出されており、モデルにはコンテキストの理解、バグの特定、そしてテストを通過する修正コードの記述が求められます。これは「LeetCodeを解く」のとは全く次元が異なる難易度です。今回の GLM-5.1 リリース前まで、このランキングは GPT-5.x シリーズと Claude Opus シリーズが交互に独占しており、オープンソースモデルがトップ3に肉薄することさえありませんでした。
しかし今回、GLM-5.1 は 58.4 ポイントを獲得し、直接首位に立ちました:
| モデル | SWE-Bench Pro スコア | オープンソースか |
|---|---|---|
| GLM-5.1 | 58.4 ⭐ | ✅ MITライセンス |
| GPT-5.4 | 57.7 | ❌ |
| Claude Opus 4.6 | 57.3 | ❌ |
| Gemini 3.1 Pro | 54.2 | ❌ |
これはわずかな差での勝利ではなく、「オープンソース vs クローズドソース」の差を、最も難易度の高い産業用ベンチマークにおいて完全に埋めたことを意味します。「ベンチマークは Z.ai の自己申告であり、独立した評価はまだ追いついていない」という免責事項を考慮しても、この出来事が持つ産業的意義は無視できません。オープンソースコミュニティは初めて、「実際のコード修正」において最先端のクローズドソースモデルと対等に競える無料のモデルを手に入れたのです。
第2の理由:真に商用利用可能な MIT ライセンス
GLM-5.1 のもう一つの重要な事実は、そのライセンスが MITライセンス であるという点です。よくある Apache 2.0 ではなく、ましてや「研究専用 / 商用不可」といった制限付きライセンスでもありません。MITライセンスの意味は非常に明確です。誰でもダウンロード、修正、微調整、デプロイ、商用利用、クローズドソース派生、販売が可能であり、制限は一切なく、著作権表示を保持するだけでよいのです。
企業ユーザーにとって、これは GLM-5.1 を以下の用途に何の懸念もなく利用できることを意味します:
- 自社製品向けの内部 Coding Agent(コーディングエージェント)開発
- 商用 SaaS 内のコード生成 / レビューモジュール
- オンプレミス環境にデプロイする IDE プラグイン
- 「モデルの重みが特定のベンダーの API に依存してはならない」というコンプライアンスが必要なあらゆるシナリオ
2026年4月という現時点で、「最先端の性能 + MITライセンス + 産業用ベンチマークでの首位」をすべて満たすモデルとして、GLM-5.1 はほぼ唯一の選択肢と言えます。

GLM-5.1 のアーキテクチャとトレーニング: 754B MoE + Huawei フルスタック
GLM-5.1 を際立たせているもう一つの事実は、そのトレーニングスタックです。
MoE アーキテクチャ: 総パラメータ数 754B / アクティブパラメータ数 40B
GLM-5.1 は混合エキスパート(MoE)アーキテクチャを採用しており、総パラメータ数は 754B ですが、推論ごとにアクティブになるのは約 40B です。この「大規模モデル + 疎なアクティブ化(Sparse Activation)」という設計は、DeepSeek、Qwen、Mixtral などのオープンソース大規模言語モデルによって繰り返し検証されてきました。主な利点は以下の通りです:
- トレーニング時のモデル容量が大きい: より多くの知識(28.5T トークンの事前学習データ)を吸収できる。
- 推論時に一部のエキスパートのみがアクティブになる: VRAM 使用量と遅延が 40B の密な(Dense)モデルに近い。
- 対話とコードタスクで異なるエキスパート経路を走らせる: 長期的なタスクの整合性が向上する。
| 次元 | GLM-5 (前世代) | GLM-5.1 (今回) |
|---|---|---|
| 総パラメータ数 | 355B | 754B |
| アクティブパラメータ数 | 32B | 40B |
| 事前学習データ | 23T トークン | 28.5T トークン |
| コンテキストウィンドウ | 制限あり | 200K |
| 最大出力 | 制限あり | 128K |
| コーディング特化 | あり | ✅ 著しく強化 |
| エージェント長距離タスク | あり | ✅ 単一タスク約8時間 |
エンジニアリングのハイライト: 8時間の長距離エージェント
Z.ai は発表の中で、GLM-5.1 の「8時間の単一タスク」能力を繰り返し強調しています。これは、**「実際のエンジニアリングタスク(例:ファイル間をまたぐバグの修正、古いライブラリの移行、テストセットの追加)を GLM-5.1 に任せると、人間が介入することなく、計画 → 実行 → テスト → 修正 → 二次最適化 を継続し、本番環境で使える結果を出すまで最大8時間稼働し続ける」**ことを意味します。このような「持久力型エージェント」の能力曲線は、これまで Claude Opus シリーズでのみ産業界で安定的に再現されてきました。GLM-5.1 は、オープンソースの世界で初めてこのレベルに到達したモデルです。
トレーニングハードウェア: Huawei フルスタック、米国製チップは不使用
特筆すべき3つ目の事実は、GLM-5.1 のトレーニングハードウェアです。すべて Huawei Ascend 910B チップ + MindSpore フレームワークを使用して完了しており、Nvidia や AMD の GPU は一切使用していません。 この事実は英語圏の AI コミュニティで大きな議論を呼びました。なぜなら、**「Hopper / Blackwell が制限される環境下でも、中国のチームが国産ハードウェア上で 754B MoE クラスのモデルを事前学習できる」**ことを直接証明したからです。これは単なるモデルの技術的勝利にとどまらず、中国の AI トレーニングインフラにおける産業レベルのデモンストレーションと言えます。
GLM-5.1 完全ベンチマーク成績表
重要なデータポイントを漏らさないよう、Z.ai が公開した GLM-5.1 のベンチマーク成績を以下の表にまとめました。
| ベンチマーク | GLM-5.1 スコア | 意味 |
|---|---|---|
| SWE-Bench Pro | 58.4 ⭐ | 実際のコード修正、世界1位(オープンソース) |
| SWE-bench Verified | 77.8% | 汎用コード修正、Claude Opus 4.6 (80.8%) の約94.6%に相当 |
| CyberGym | 68.7 | セキュリティ/CTF 推論(1507タスク単体実行) |
| MCP-Atlas | 71.8 | MCP ツール呼び出しベンチマーク |
| T3-Bench | 70.6 | ツール使用とエージェントタスク |
| Humanity's Last Exam | 31.0 / 52.3 | 超難関推論(ツールなし / ツールあり) |
| AIME 2026 | 95.3 | 米国数学オリンピックレベル |
| GPQA-Diamond | 86.2 | 専門家レベルの科学的推論 |
要点を簡単に解説します:
- コード生成: SWE-Bench Pro でトップに立ち、SWE-bench Verified では Claude Opus 4.6 の 94.6% に達しました。これは、ほとんどの日常的なエンジニアリングタスクにおいて、GLM-5.1 のコーディング能力が現在最強の Claude Opus と同等レベルにあることを意味します。
- 数学的推論: AIME 2026 で 95.3、GPQA-Diamond で 86.2 を記録し、「最先端レベル」に位置しています。
- エージェントとツール使用: MCP-Atlas 71.8、T3-Bench 70.6 と、長距離タスクの能力がベンチマークで証明されました。
- 誠実な評価: このデータは現在すべて Z.ai の自己申告によるものです。執筆時点では完全に独立した第三者機関による再現テストは行われていないため、参考値として捉え、「絶対的な数値」とは見なさないようにしてください。
🎯 ベンチマーク検証の提案: 自己申告のベンチマークに対して最も現実的な態度は、自身の業務における実際のタスクで一度試してみることです。GLM-5.1 はすでに APIYI (apiyi.com) で利用可能です。チームで最も頻繁に行う 5〜10 個の実際のコーディングプロンプトを GLM-5.1、Claude Opus 4.6、GPT-5.4 でそれぞれ実行し、自身の業務データで SWE-Bench Pro の結論を逆検証してみてください。
GLM-5.1 の料金体系:なぜ「コストパフォーマンスのダークホース」なのか
GLM-5.1 のもう一つの見逃せない特徴は価格です。主要な最先端モデルと比較してみましょう。
トークン単価の比較
| モデル | 入力 ($/M) | 出力 ($/M) | オープンソース |
|---|---|---|---|
| GLM-5.1 | $1.00 | $3.20 | ✅ MIT |
| Claude Opus 4.6 | かなり高価 | かなり高価 | ❌ |
| GPT-5.4 | 高価 | 高価 | ❌ |
| Gemini 3.1 Pro | 中程度 | 中程度 | ❌ |
$1.00 / $3.20 という数字は、「最先端コーディングモデル」の価格帯において最安値レベルです。Claude Opus 4.6 といったクローズドモデルと比較すると、GLM-5.1 の実質単価はその数分の一に過ぎません。それでありながら、Z.ai は「Claude Opus 4.6 の 94.6% のコーディング性能」を主要なセールスポイントとして掲げています。
GLM Coding Plan とプランの活用法
トークン課金以外にも、Z.ai は GLM Coding Plan を提供しています。これは Cursor、Cline、Claude Code といった「ヘビーなコーディング環境」向けの固定料金プランで、月額約 3 ドルから利用でき、120 回のプロンプトが含まれています。これは同種のクローズドなコーディングプランよりもはるかに安価です。こうしたプランは通常、Max / Pro / Lite といった複数の階層と組み合わされており、「日常的なエンジニアのワークフロー」のような「呼び出し頻度は高いが、1回あたりのコストは抑えたい」というシーンにおいて、「Opus レベルのコーディング能力をほぼ無料に近いコストで」実現できます。
🎯 モデル選定のアドバイス: 「Claude Opus レベルのコーディング能力は欲しいが、Opus の価格に圧迫されたくない」というチームには、APIYI (apiyi.com) を通じて GLM-5.1 を呼び出すことをお勧めします。統一されたインターフェースと日本円での決済が利用できるだけでなく、同じ業務コード内でいつでも GPT-5.4 や Claude Opus 4.6 に切り替えて A/B テストを行い、実際の請求データからどのモデルが最もコストパフォーマンスが高いかを判断できます。

GLM-5.1 が APIYI に登場:最小呼び出しサンプル
最後に、中国のデベロッパーの皆様が最も関心を寄せている点についてお伝えします。GLM-5.1 が APIYI (apiyi.com) に登場しました。既存の OpenAI 互換 SDK を通じて直接呼び出しが可能であり、Hugging Face から 754B パラメータの重みを自分でデプロイする必要は一切ありません。
Python 最小サンプル
以下は、公式の OpenAI SDK を使用して GLM-5.1 を呼び出すための最小限の Python サンプルコードです。
from openai import OpenAI
# base_url を APIYI に変更し、api_key をあなたの APIYI Key に置き換えてください
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="YOUR_APIYI_KEY"
)
resp = client.chat.completions.create(
model="glm-5.1", # GLM-5.1 モデル ID を直接指定
messages=[
{"role": "system", "content": "あなたは熟練したソフトウェアエンジニアです。"},
{"role": "user", "content": "有効期限と容量上限を備えた LRU キャッシュを Python で書いてください。"}
],
max_tokens=4096
)
print(resp.choices[0].message.content)
ビジネスロジックに変更は必要ありません。これまで GPT-4 / Claude / DeepSeek を呼び出すために使用していたロジックを、そのまま GLM-5.1 に適用できます。
Cursor / Cline / Claude Code への接続
Z.ai 公式は、GLM-5.1 が Claude Code、OpenClaw、Cline を含むすべての OpenAI 標準準拠のコーディングツールと互換性があることを明言しています。これらのツールで OpenAI 互換エンドポイントを https://api.apiyi.com/v1 に設定し、GLM-5.1 モデルを選択するだけで、ワークフローを一切変更することなく、主力コーディングモデルを Opus / GPT-5 から GLM-5.1 に切り替えることができます。Cursor のような OpenAI Custom Endpoint をサポートする IDE でも、手順は全く同じです。
ストリーミング呼び出しと長いコンテキストのサンプル
GLM-5.1 は APIYI 上で 200K のコンテキストウィンドウと 128K の出力能力を完全に保持しています。長時間の Agent タスクでは、stream モードを有効にすることで、最初のトークンまでの遅延を短縮できます。
stream = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "この 5000 行の Python リポジトリを完全にレビューし、潜在的なバグとリファクタリングの提案をリストアップしてください。"}
],
stream=True,
max_tokens=128000
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
print(delta.content, end="", flush=True)
🎯 接続の推奨: GLM-5.1 は APIYI (apiyi.com) にて、OpenAI 互換インターフェース、ストリーミング出力、および 200K のフルコンテキストをサポートしています。チームの Cursor / Cline / Claude Code のツール設定を今日から APIYI に向け、GLM-5.1 を新しい主力コーディングモデルとして1週間試用し、実際のエンジニアリングタスクで現在使用している Opus / GPT-5 に取って代われるか検証することをお勧めします。
GLM-5.1 は誰に向いているか、向いていないか
向いている方
| 対象者 | 推奨理由 |
|---|---|
| コーディング Agent のヘビーユーザー | SWE-Bench Pro でトップクラス、8時間の長距離タスク能力 |
| 最先端モデルを使いたいが予算が限られているチーム | $1.00/$3.20 という単価は Opus / GPT-5 より大幅に安価 |
| MIT ライセンスでの商用デプロイが必要な企業 | 制限なし、商用利用可能、クローズドソース派生も可 |
| Cursor / Cline / Claude Code ユーザー | OpenAI インターフェースとネイティブ互換、ワンクリックで置換可能 |
| 国産 AI 学習スタックに興味がある研究者 | Huawei Ascend 910B + MindSpore によるフル学習 |
| 数学 / 科学的推論を多用するシナリオ | AIME 2026 95.3 / GPQA-Diamond 86.2 の高いスコア |
あまり向いていない方
| 対象者 | 理由 |
|---|---|
| 「独立した第三者ベンチマーク」を重視する方 | 現在のデータはすべて Z.ai の自己申告であり、検証が必要 |
| タスクがマルチモーダル(画像/動画)中心の方 | GLM-5.1 はテキストとコードに特化しており、マルチモーダルは強みではない |
| Anthropic / OpenAI のツールエコシステムに完全に依存している方 | 一部の高度な機能は依然として元のインターフェースに依存する可能性がある |
GLM-5.1 に関するよくある質問(FAQ)
Q1: GLM-5.1 は本当にオープンソースですか?商用利用は可能ですか?
はい。GLM-5.1 は 2026 年 4 月 7 日、Z.ai により Hugging Face(zai-org/GLM-5)にて MIT ライセンス で完全にオープンソース化されました。商用利用、クローズドソースでの派生、二次的な微調整がすべて許可されており、必要なのは著作権表示のみです。これは現在最も寛容なオープンソースライセンスの一つであり、GLM-5.1 をそのまま自社の商用製品、SaaS、プライベート環境にデプロイしても、ライセンス料を支払う必要がないことを意味します。
Q2: GLM-5.1 は本当に GPT-5.4 や Claude Opus 4.6 より強力ですか?
SWE-Bench Pro というベンチマークにおいて、Z.ai が発表したスコア(58.4)は、確かに GPT-5.4(57.7)や Claude Opus 4.6(57.3)を上回っています。ただし注意点として、このデータは現時点では Z.ai の自己申告であり、独立した第三者機関による完全な再現はまだ行われていません。これらの数値を「絶対的な真理」と捉えるのではなく、自身の業務における実際のタスクで一度試してみることをお勧めします。これは APIYI (apiyi.com) 上の GLM-5.1 を使えば、自分でデプロイすることなく今すぐ実行可能です。
Q3: GLM-5.1 の API は APIYI に実装されていますか?どう呼び出せばいいですか?
すでに実装済みです。OpenAI 公式 SDK の base_url を https://api.apiyi.com/v1 に変更し、api_key をあなたの APIYI キーに置き換え、model を GLM-5.1 対応のモデル ID に設定するだけで、すぐに呼び出し可能です。業務コードを書き直す必要は一切ありません。記事内の「最小呼び出し例」には Python 版を掲載していますが、Node / Go / Rust SDK でも同様に利用可能です。
Q4: GLM-5.1 は DeepSeek、Qwen、Kimi といった他の国産オープンソースモデルより強力ですか?
GLM-5.1 の最大の違いは 「長距離 Agent コーディング + SWE-Bench Pro での首位獲得」 にあります。これはこれまで DeepSeek、Qwen、Kimi が正面から攻略できていなかった分野です。もしあなたの業務が「日常会話 + RAG」であれば、DeepSeek や Qwen は依然として非常に競争力があります。しかし、もし業務が コーディング Agent / IDE 統合 / コード修正 であれば、GLM-5.1 は現在のオープンソース界における第一の選択肢です。APIYI 上では、これらを同じ比較テスト環境に入れて、15 分で自分なりの判断を下すことができます。
Q5: GLM-5.1 をローカル環境にデプロイするにはどのようなハードウェアが必要ですか?
GLM-5.1 は総パラメータ数 754B / アクティブ 40B の MoE アーキテクチャを採用しており、ローカルデプロイにはプロフェッショナル向けのマルチ GPU クラスタが必要なため、一般的なチームにはほぼ現実的ではありません。Z.ai 公式は、大規模な推論サービスとしてデプロイする場合、vLLM / SGLang / KTransformers の使用を推奨しています。もし GLM-5.1 を研究目的ではなく利用したいのであれば、最も効率的な方法は APIYI (apiyi.com) を通じて直接呼び出すことです。GPU も運用も不要で、従量課金で利用できます。
Q6: GLM-5.1 の学習には本当に Nvidia GPU が使われなかったのですか?
はい。Z.ai は GLM-5.1 が完全に Huawei Ascend 910B チップと MindSpore フレームワーク上で学習され、Nvidia / AMD の GPU を一切使用していないことを公表しています。これは 2026 年のオープンソース大規模言語モデル分野において、公開レベルで「完全国産ハードウェア + 754B MoE モデル」の学習を完了させた初の事例であり、産業的に大きな象徴的意味を持っています。
まとめ:GLM-5.1 は 2026 年のオープンソース AI における転換点
アーキテクチャ、ベンチマーク、価格、学習スタック、そして API 接続経路をすべてつなぎ合わせると、2026 年 4 月という時点における GLM-5.1 の立ち位置は非常に明確です。これは単なるオープンソースモデルのアップグレードではなく、「オープンソースがクローズドソースの最先端を本当に打ち負かせる」ことを示す象徴的な出来事です。SWE-Bench Pro で世界 1 位の 58.4 を記録し、MIT ライセンスで完全に開放され、$1.00/$3.20 という極めて低い価格、200K のコンテキストウィンドウ + 128K の出力、8 時間の長距離 Agent 能力、そして Huawei Ascend 910B による学習スタック。これらの事実はどれ一つとってもニュースになるレベルであり、それが重なることで「オープンソースの転換点」となりました。
日本の開発者にとってさらに良いニュースは、GLM-5.1 API が APIYI に実装されたことです。754B のウェイトを自分でデプロイする必要も、海外のクレジットカードも、承認を待つ必要もありません。base_url を https://api.apiyi.com/v1 に、model を GLM-5.1 に変更するだけで、今日から Cursor / Cline / Claude Code の主力コーディングモデルをこの新しいオープンソースの王者に置き換えることができます。もし Opus や GPT-5 の請求額に頭を悩ませているなら、今こそテストしてみる絶好のチャンスです。
🎯 最終アドバイス: GLM-5.1 の「最先端のコーディング能力 + オープンソースの価格 + APIYI の安定した接続」をいち早く体験したい方は、今日 apiyi.com で API キーを作成し、既存の OpenAI SDK の
base_urlをhttps://api.apiyi.com/v1に、modelを GLM-5.1 に変更して、チームの日常的なコードタスクで 1 週間試してみることをお勧めします。最終的に主力モデルを切り替えるかどうかに関わらず、この 1 週間の実測は、2026 年のオープンソース AI の実力を肌で感じる貴重な経験になるはずです。
著者: APIYI Team | AI 大規模言語モデルの活用とオープンソースエコシステムに注目。GLM-5.1 / Claude / GPT-5 の実戦的な呼び出しや比較については、APIYI (apiyi.com) をご覧ください。