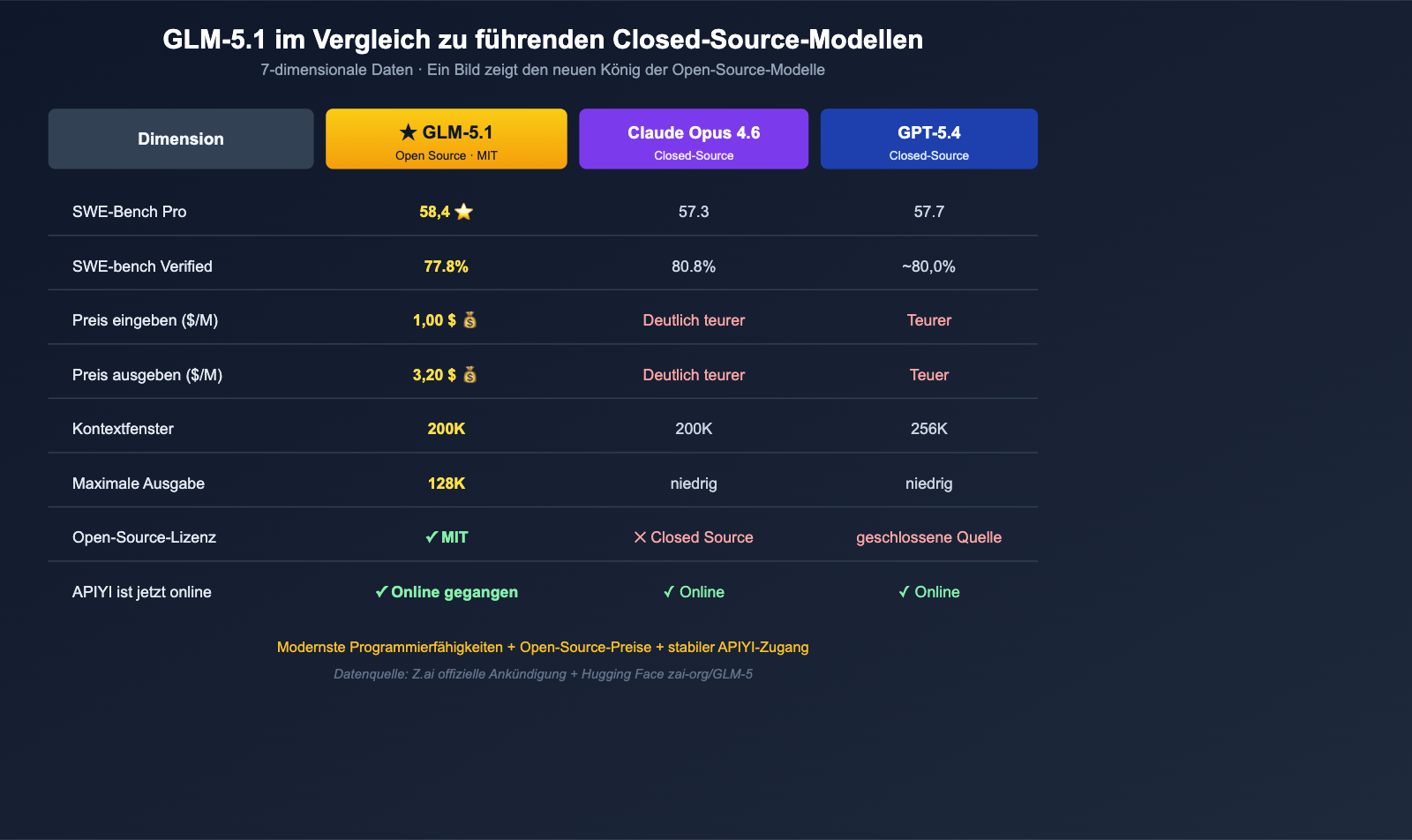
Am 7. April 2026 veröffentlichte Z.ai (ehemals Zhipu AI) offiziell die vollständigen Gewichte von GLM-5.1 unter der MIT-Lizenz im Hugging Face-Repository zai-org/GLM-5. Diese Veröffentlichung sorgte in der englischsprachigen KI-Welt sofort für Aufsehen – nicht etwa, weil es "nur ein weiteres Open-Source-Großes Sprachmodell" ist, sondern weil es im Software-Engineering-Benchmark SWE-Bench Pro mit 58,4 Punkten direkt die weltweite Spitzenposition einnahm. Damit übertraf es GPT-5.4 (57,7 Punkte), Claude Opus 4.6 (57,3 Punkte) und Gemini 3.1 Pro (54,2 Punkte). Es ist das erste Mal, dass ein Open-Source-Modell in einem von der Industrie breit anerkannten Benchmark für "echte Code-Korrekturen" alle führenden proprietären Modelle hinter sich lässt.
Für Entwickler in Festlandchina ist besonders erfreulich, dass die GLM-5.1 API extrem schnell verfügbar gemacht wurde – APIYI (apiyi.com) hat die Anbindung bereits abgeschlossen. Sie müssen weder die 754B-Parameter-Gewichte von Hugging Face herunterladen noch ein offizielles Z.ai-Konto beantragen. Ändern Sie einfach die base_url Ihres bestehenden OpenAI-SDKs, und schon können Sie das Modell nutzen. Dieser Artikel beleuchtet GLM-5.1 aus sieben Dimensionen: Architektur, Benchmarks, Trainingshardware, Preisgestaltung und Anbindungsmöglichkeiten. Zudem finden Sie ein minimales Code-Beispiel für den Modellaufruf über APIYI.

GLM-5.1 Kerninformationen im Überblick (Stand April 2026)
Bevor wir ins Detail gehen, haben wir hier die wichtigsten Fakten zu GLM-5.1 kompakt zusammengefasst.
| Dimension | Bekannte Informationen zu GLM-5.1 |
|---|---|
| Hersteller | Z.ai (ehemals Zhipu AI, Börsengang in Hongkong im Jan. 2026, Bewertung ca. 31,3 Mrd. USD) |
| Veröffentlichungsdatum | 7. April 2026 |
| Lizenz | MIT (erlaubt kommerzielle Nutzung + Modifikationen + proprietäre Derivate) |
| Repository-Adresse | huggingface.co/zai-org/GLM-5 |
| Modellarchitektur | MoE (Mixture of Experts), 754B Gesamtparameter / 40B aktive Parameter |
| Kontextfenster | 200.000 Token |
| Maximale Ausgabe | 128.000 Token |
| Trainingsdaten | 28,5T Token (Steigerung von 23T bei GLM-5) |
| Trainingshardware | Vollständig Huawei Ascend 910B + MindSpore-Framework (kein Nvidia / AMD) |
| Deployment-Framework | vLLM / SGLang / KTransformers |
| Flaggschiff-Fähigkeit | Langstrecken-Agent-Codierung (kann bis zu 8 Stunden an einer Aufgabe arbeiten) |
| Preis (direkte API) | 1,00 USD / Mio. Token Input, 3,20 USD / Mio. Token Output |
| Coding-Paket | GLM Coding Plan ab ca. 3 USD/Monat |
| APIYI-Anbindung | ✅ Verfügbar, Aufruf über https://api.apiyi.com/v1 möglich |
| Kompatible Tools | Claude Code / OpenClaw / Cline / beliebige OpenAI-kompatible Editoren |
🎯 Empfehlung für den schnellen Einstieg: GLM-5.1 ist bereits über APIYI (apiyi.com) angebunden. Sie müssen lediglich die
base_urlIhres bestehenden OpenAI-SDKs aufhttps://api.apiyi.com/v1und denmodel-Namen auf das entsprechende GLM-5.1-Modell ändern. So können Sie das Modell sofort in Ihren Agenten-, Cursor- oder Cline-Workflows als Hauptmodell einsetzen, ohne den bestehenden Code anpassen zu müssen.
Warum GLM-5.1 ein "Open-Source-Wendepunkt" ist
Um zu verstehen, warum GLM-5.1 in der englischsprachigen KI-Community als "Open-Source-Wendepunkt" bezeichnet wird, muss man einige entscheidende Fakten betrachten.
Erstens: Open-Source-Modell an der Spitze von SWE-Bench Pro
SWE-Bench Pro gilt derzeit als einer der schwierigsten Benchmarks für reale Code-Reparaturen. Die Aufgaben stammen aus industriellen Code-Repositories. Das Modell muss den Kontext verstehen, Bugs lokalisieren und Korrekturen schreiben, die Tests bestehen – das ist eine völlig andere Größenordnung als das "Lösen von LeetCode-Aufgaben". Vor der Veröffentlichung von GLM-5.1 wurde diese Bestenliste fast ausschließlich von der GPT-5.x- und Claude-Opus-Serie dominiert; Open-Source-Modelle kamen nie wirklich in die Nähe der Top 3.
Doch dieses Mal hat GLM-5.1 mit 58,4 Punkten die Spitze erreicht:
| Modell | SWE-Bench Pro Punktzahl | Open Source |
|---|---|---|
| GLM-5.1 | 58,4 ⭐ | ✅ MIT-Lizenz |
| GPT-5.4 | 57,7 | ❌ |
| Claude Opus 4.6 | 57,3 | ❌ |
| Gemini 3.1 Pro | 54,2 | ❌ |
Dies ist kein knapper Vorsprung, sondern eine vollständige Schließung der Lücke zwischen "Open Source" und "Closed Source" bei einem der anspruchsvollsten industriellen Benchmarks. Selbst unter Berücksichtigung des Haftungsausschlusses, dass "die Benchmarks von Z.ai selbst gemeldet wurden und eine unabhängige Überprüfung noch aussteht", ist die industrielle Bedeutung dieses Ereignisses nicht zu ignorieren: Die Open-Source-Community verfügt erstmals über ein kostenloses Modell, das bei "echten Code-Reparaturen" mit führenden Closed-Source-Modellen konkurrieren kann.
Zweitens: Eine wirklich kommerziell nutzbare MIT-Lizenz
Ein weiterer entscheidender Fakt bei GLM-5.1 ist die Lizenz – MIT, nicht die übliche Apache 2.0-Lizenz und erst recht keine restriktiven Lizenzen für "nur Forschung / keine kommerzielle Nutzung". Die Bedeutung der MIT-Lizenz ist sehr direkt: Jeder kann das Modell herunterladen, modifizieren, feinabstimmen, bereitstellen, kommerziell nutzen, proprietäre Ableitungen erstellen und verkaufen – es gibt keinerlei Einschränkungen, außer dem Erhalt des Urheberrechtshinweises.
Für Unternehmenskunden bedeutet dies, dass GLM-5.1 bedenkenlos eingesetzt werden kann für:
- Interne Coding-Agenten für die Eigenentwicklung;
- Code-Generierungs- / Review-Module in kommerziellen SaaS-Lösungen;
- IDE-Plugins für die private Bereitstellung;
- Alle Compliance-Szenarien, in denen "die Modellgewichte nicht von der API eines bestimmten Anbieters abhängen dürfen".
Zum Zeitpunkt im April 2026 ist GLM-5.1 fast die einzige Wahl, die gleichzeitig "führende Leistung + MIT-Open-Source + Spitzenplatzierung bei industriellen Benchmarks" bietet.

GLM-5.1 Architektur und Training: 754B MoE + Huawei Full-Stack
Der zweite Punkt, der GLM-5.1 auszeichnet, ist sein Trainings-Stack.
MoE-Architektur: 754B Gesamtparameter / 40B aktiv
GLM-5.1 verwendet eine Mixture-of-Experts (MoE)-Architektur mit insgesamt 754B Parametern, wobei bei jeder Inferenz nur etwa 40B aktiviert werden. Dieses Design aus "großem Modell + dünner Aktivierung" wurde bereits von Open-Source-Modellen wie DeepSeek, Qwen und Mixtral mehrfach validiert. Die wesentlichen Vorteile sind:
- Hohe Modellkapazität beim Training, wodurch mehr Wissen aufgenommen werden kann (28,5T Token Pre-Training-Daten);
- Nur ein kleiner Teil der Experten wird bei der Inferenz aktiviert, was VRAM-Verbrauch und Latenz in die Nähe eines 40B-Dense-Modells bringt;
- Dialog- und Code-Aufgaben können unterschiedliche Expertenpfade nutzen, was die Kohärenz bei langfristigen Aufgaben verbessert.
| Dimension | GLM-5 (Vorgänger) | GLM-5.1 (Aktuell) |
|---|---|---|
| Gesamtparameter | 355B | 754B |
| Aktivierte Parameter | 32B | 40B |
| Pre-Training-Daten | 23T Token | 28,5T Token |
| Kontextfenster | Begrenzt | 200K |
| Maximale Ausgabe | Begrenzt | 128K |
| Coding-Spezialisierung | Vorhanden | ✅ Deutlich verbessert |
| Agent-Langzeitaufgaben | Vorhanden | ✅ ca. 8 Stunden pro Aufgabe |
Wichtiges technisches Highlight: 8-stündiger Langzeit-Agent
Z.ai betont in der Ankündigung wiederholt die "8-Stunden-Einzelaufgaben"-Fähigkeit von GLM-5.1. Das bedeutet: Sie können GLM-5.1 eine echte technische Aufgabe übertragen (z. B. einen Bug über mehrere Dateien hinweg beheben, eine alte Bibliothek migrieren, eine Testgruppe ergänzen), und es kann ohne menschliches Eingreifen kontinuierlich planen → ausführen → testen → reparieren → nachoptimieren, bis ein produktionsreifes Ergebnis vorliegt, wobei der gesamte Prozess bis zu 8 Stunden dauert. Diese Leistungskurve eines "Ausdauer-Agenten" wurde in der Industrie bisher nur bei der Claude-Opus-Serie stabil reproduziert – GLM-5.1 ist das erste Modell in der Open-Source-Welt, das diese Fähigkeit auf das gleiche Niveau hebt.
Trainings-Hardware: Kompletter Huawei-Stack, keine US-Chips
Der dritte Fakt, der besonders hervorgehoben werden muss, ist die Trainings-Hardware von GLM-5.1 – vollständig unter Verwendung von Huawei Ascend 910B-Chips + MindSpore-Framework, ohne Verwendung von Nvidia- oder AMD-GPUs. Dies hat in der englischsprachigen KI-Community für große Diskussionen gesorgt, da es direkt beweist: In einer Umgebung mit Einschränkungen bei Hopper / Blackwell-Chips sind Teams in Festlandchina in der Lage, das Pre-Training eines Modells in der Größenordnung von 754B MoE auf heimischer Hardware durchzuführen. Dies ist nicht nur ein technischer Sieg für das Modell selbst, sondern eine industrielle Demonstration der KI-Trainingsinfrastruktur in Festlandchina.
Vollständiges Benchmark-Datenblatt für GLM-5.1
Um keine wichtigen Datenpunkte zu übersehen, haben wir die von Z.ai veröffentlichten Benchmark-Ergebnisse für GLM-5.1 in der folgenden Tabelle zusammengefasst.
| Benchmark | GLM-5.1 Ergebnis | Bedeutung |
|---|---|---|
| SWE-Bench Pro | 58.4 ⭐ | Echte Code-Korrektur, #1 weltweit (Open Source) |
| SWE-bench Verified | 77,8 % | Allgemeine Code-Korrektur, erreicht ~94,6 % von Claude Opus 4.6 (80,8 %) |
| CyberGym | 68,7 | Sicherheit/CTF-Schlussfolgerung (1507 Aufgaben) |
| MCP-Atlas | 71,8 | Benchmark für MCP-Toolaufrufe |
| T3-Bench | 70,6 | Werkzeugnutzung und Agent-Aufgaben |
| Humanity's Last Exam | 31,0 / 52,3 | Extrem schwierige Schlussfolgerung (ohne/mit Werkzeugen) |
| AIME 2026 | 95,3 | Niveau der US-Mathematikolympiade |
| GPQA-Diamond | 86,2 | Wissenschaftliche Schlussfolgerung auf Expertenniveau |
Hier eine kurze Zusammenfassung der wichtigsten Punkte:
- Code-Ebene: Bei SWE-Bench Pro steht das Modell an der Spitze, bei SWE-bench Verified erreicht es 94,6 % der Leistung von Claude Opus 4.6 – das bedeutet, dass GLM-5.1 bei den meisten alltäglichen technischen Aufgaben auf demselben Niveau wie das derzeit stärkste Claude Opus agiert.
- Mathematische Schlussfolgerung: Mit 95,3 bei AIME 2026 und 86,2 bei GPQA-Diamond gehört es zur absoluten Spitzenklasse.
- Agenten und Werkzeugnutzung: Die Ergebnisse bei MCP-Atlas (71,8) und T3-Bench (70,6) bestätigen die Leistungsfähigkeit bei komplexen, langfristigen Aufgaben.
- Transparenz: Diese Daten stammen derzeit vollständig aus Eigenangaben von Z.ai. Bis zum Redaktionsschluss gab es noch keine unabhängige Überprüfung durch Dritte. Betrachten Sie die Werte daher als Referenz, nicht als absolute Fakten.
🎯 Empfehlung zur Benchmark-Validierung: Der pragmatischste Ansatz bei selbst gemeldeten Benchmarks ist ein Test mit eigenen, realen Aufgaben. GLM-5.1 ist bereits bei APIYI (apiyi.com) verfügbar. Sie können Ihre 5–10 wichtigsten Coding-Prompts direkt mit GLM-5.1, Claude Opus 4.6 und GPT-5.4 vergleichen, um die Ergebnisse von SWE-Bench Pro anhand Ihrer eigenen Geschäftsdaten zu validieren.
Preisstruktur von GLM-5.1: Warum es ein "Preis-Leistungs-Geheimtipp" ist
Ein weiteres Merkmal von GLM-5.1, das man nicht ignorieren kann, ist der Preis. Wir haben ihn direkt mit anderen führenden Modellen verglichen.
Vergleich der Token-Preise
| Modell | Input ($/M) | Output ($/M) | Open Source |
|---|---|---|---|
| GLM-5.1 | $1.00 | $3.20 | ✅ MIT |
| Claude Opus 4.6 | Deutlich teurer | Deutlich teurer | ❌ |
| GPT-5.4 | Teurer | Teurer | ❌ |
| Gemini 3.1 Pro | Mittel | Mittel | ❌ |
Die Werte von $1,00 / $3,20 liegen im Bereich der "führenden Coding-Modelle" am unteren Ende der Preisskala. Im Vergleich zu einem geschlossenen Modell wie Claude Opus 4.6 kostet GLM-5.1 nur einen Bruchteil, obwohl Z.ai die "94,6 % der Coding-Leistung von Claude Opus 4.6" als zentrales Verkaufsargument anführt.
GLM Coding Plan und Paket-Optionen
Neben der nutzungsbasierten Abrechnung bietet Z.ai den GLM Coding Plan an – ein festes Paket für "intensive Coding-Szenarien" wie Cursor, Cline oder Claude Code. Der Einstiegspreis liegt bei ca. 3 $/Monat für 120 Prompts, was weit unter vergleichbaren Paketen für geschlossene Modelle liegt. In Workflows, in denen häufig, aber kostengünstig auf Modelle zugegriffen wird, ermöglicht dies "Opus-ähnliche Coding-Leistung bei nahezu kostenlosen Betriebskosten".
🎯 Empfehlung zur Modellauswahl: Für Teams, die "Claude Opus-Leistung ohne die hohen Opus-Kosten" suchen, empfehlen wir den Zugriff auf GLM-5.1 über APIYI (apiyi.com). Sie profitieren von einer einheitlichen Schnittstelle und können in Ihrem Code jederzeit zwischen GPT-5.4 und Claude Opus 4.6 wechseln, um per A/B-Test zu ermitteln, welches Modell das beste Preis-Leistungs-Verhältnis für Ihre Anforderungen bietet.
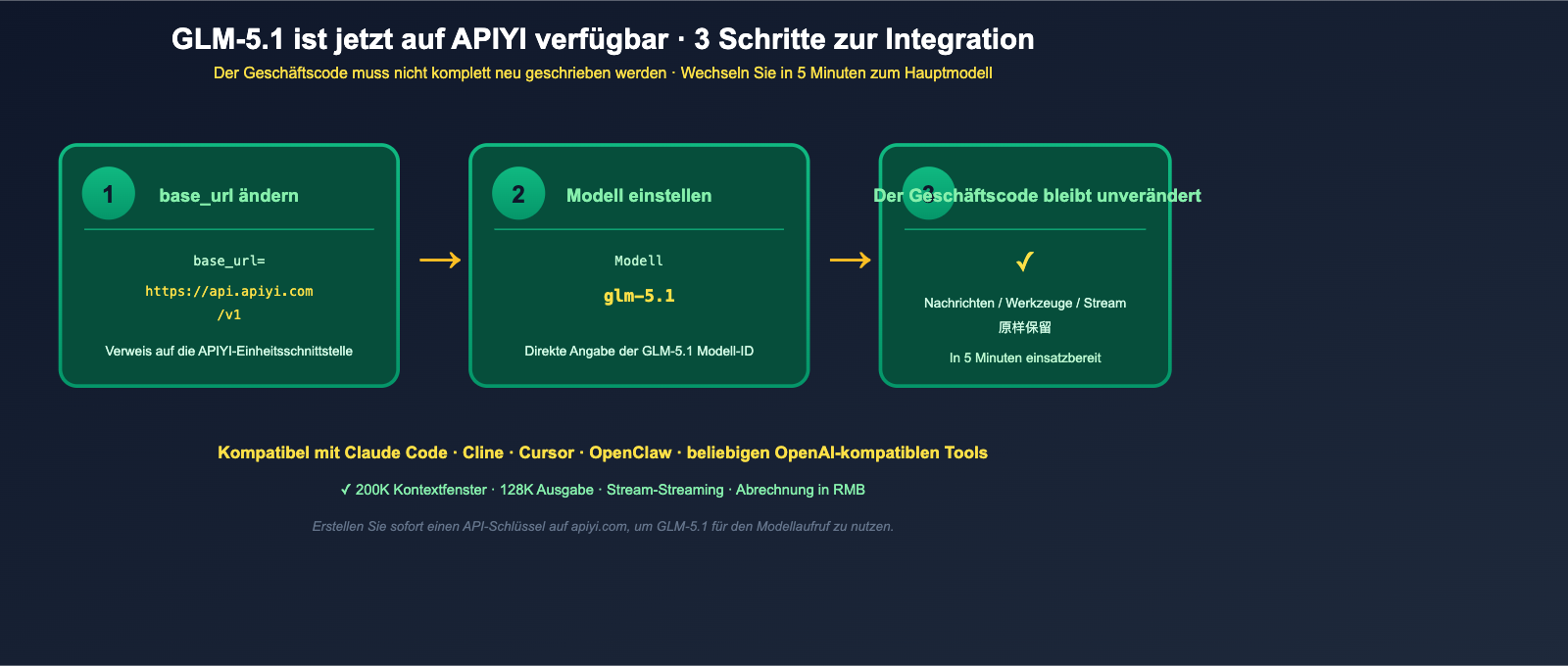
GLM-5.1 ist jetzt auf APIYI verfügbar: Minimales Aufrufbeispiel
Das Wichtigste für chinesische Entwickler vorab: GLM-5.1 ist jetzt auf APIYI (apiyi.com) verfügbar. Sie können es direkt über das vorhandene OpenAI-kompatible SDK aufrufen – Sie müssen die 754B-Parameter-Gewichte nicht mehr selbst auf Hugging Face bereitstellen.
Minimales Python-Beispiel
Hier ist ein minimales Python-Beispiel, das zeigt, wie Sie GLM-5.1 mit dem offiziellen OpenAI-SDK aufrufen:
from openai import OpenAI
# Ändern Sie base_url zu APIYI und api_key zu Ihrem APIYI-Schlüssel
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="DEIN_APIYI_SCHLUESSEL"
)
resp = client.chat.completions.create(
model="glm-5.1", # Geben Sie direkt die Modell-ID von GLM-5.1 an
messages=[
{"role": "system", "content": "Du bist ein erfahrener Softwareentwickler."},
{"role": "user", "content": "Schreibe einen LRU-Cache in Python mit Ablaufzeit und Kapazitätslimit."}
],
max_tokens=4096
)
print(resp.choices[0].message.content)
Ihr Code bleibt dabei unverändert – die Logik, mit der Sie zuvor GPT-4, Claude oder DeepSeek aufgerufen haben, funktioniert genauso für GLM-5.1.
Integration in Cursor / Cline / Claude Code
Z.ai hat offiziell bestätigt, dass GLM-5.1 mit allen OpenAI-Standard-Coding-Tools kompatibel ist, einschließlich Claude Code, OpenClaw und Cline. Sie müssen in diesen Tools lediglich den OpenAI-kompatiblen Endpunkt auf https://api.apiyi.com/v1 umstellen und das Modell GLM-5.1 auswählen. So können Sie Ihr primäres Coding-Modell von Opus oder GPT-5 auf GLM-5.1 umstellen, ohne Ihren Workflow anzupassen. Für IDEs wie Cursor, die ebenfalls OpenAI Custom Endpoints unterstützen, ist der Prozess identisch.
Beispiel für Streaming und langes Kontextfenster
GLM-5.1 behält auf APIYI das volle 200K-Kontextfenster und die 128K-Ausgabekapazität bei. Für langwierige Agenten-Aufgaben können Sie den Stream-Modus aktivieren, um eine geringere Latenz für das erste Token zu erzielen:
stream = client.chat.completions.create(
model="glm-5.1",
messages=[
{"role": "user", "content": "Überprüfe dieses 5000 Zeilen umfassende Python-Repository vollständig und liste potenzielle Bugs sowie Refactoring-Vorschläge auf."}
],
stream=True,
max_tokens=128000
)
for chunk in stream:
delta = chunk.choices[0].delta
if delta.content:
print(delta.content, end="", flush=True)
🎯 Empfehlung zur Einbindung: GLM-5.1 unterstützt auf APIYI (apiyi.com) bereits die OpenAI-kompatible Schnittstelle, Stream-Ausgabe und das volle 200K-Kontextfenster. Wir empfehlen Ihnen, die Tools Ihres Teams (Cursor / Cline / Claude Code) noch heute auf APIYI umzustellen und GLM-5.1 eine Woche lang als primäres Coding-Modell zu testen, um zu sehen, ob es das von Ihnen aktuell genutzte Opus oder GPT-5 ersetzen kann.
Für wen ist GLM-5.1 geeignet – und für wen nicht?
Zielgruppe
| Zielgruppe | Grund für die Eignung |
|---|---|
| Power-User von Coding-Agenten | Spitzenreiter im SWE-Bench Pro, exzellent bei 8-Stunden-Aufgaben |
| Teams mit begrenztem Budget | Preis von $1.00/$3.20 liegt weit unter Opus / GPT-5 |
| Unternehmen mit Bedarf an MIT-lizenzierter Bereitstellung | Keine Einschränkungen, kommerziell nutzbar, Open-Source-Derivate möglich |
| Cursor / Cline / Claude Code Nutzer | Native Kompatibilität mit OpenAI-Schnittstellen, Austausch per Klick |
| Forscher im Bereich heimischer KI-Stacks | Vollständig auf Huawei Ascend 910B + MindSpore trainiert |
| Szenarien mit Fokus auf Mathematik / Wissenschaft | AIME 2026 95.3 / GPQA-Diamond 86.2 |
Weniger geeignet für
| Zielgruppe | Grund |
|---|---|
| Nutzer, die Wert auf "unabhängige Benchmarks" legen | Aktuelle Daten stammen von Z.ai selbst, Reproduktion erforderlich |
| Aufgaben mit Schwerpunkt auf Multimodalität (Bild/Video) | GLM-5.1 ist auf Text und Code spezialisiert, Multimodalität ist keine Stärke |
| Nutzer, die vollständig vom Anthropic / OpenAI-Ökosystem abhängen | Einige erweiterte Funktionen sind weiterhin an die Original-Schnittstellen gebunden |
GLM-5.1 Häufig gestellte Fragen (FAQ)
Q1: Ist GLM-5.1 wirklich Open Source? Kann es kommerziell genutzt werden?
Ja. GLM-5.1 wurde am 7. April 2026 von Z.ai auf Hugging Face (zai-org/GLM-5) unter der MIT-Lizenz vollständig als Open Source veröffentlicht. Dies erlaubt die kommerzielle Nutzung, die Erstellung proprietärer Derivate sowie ein erneutes Finetuning, sofern der Urheberrechtshinweis beibehalten wird. Dies ist eine der freizügigsten Open-Source-Lizenzen überhaupt. Das bedeutet, Sie können GLM-5.1 direkt in Ihre kommerziellen Produkte, SaaS-Lösungen oder privaten Bereitstellungen integrieren, ohne Lizenzgebühren zahlen zu müssen.
Q2: Ist GLM-5.1 wirklich besser als GPT-5.4 und Claude Opus 4.6?
Beim SWE-Bench Pro Benchmark übertreffen die von Z.ai veröffentlichten Ergebnisse (58,4) tatsächlich die von GPT-5.4 (57,7) und Claude Opus 4.6 (57,3). Aber Vorsicht: Diese Daten stammen derzeit von Z.ai selbst und wurden noch nicht vollständig von unabhängigen Drittanbietern verifiziert. Wir empfehlen, diese Zahlen nicht als "absolute Wahrheit" zu betrachten, sondern das Modell mit den tatsächlichen Aufgaben Ihres Unternehmens zu testen – dies können Sie jetzt direkt über GLM-5.1 auf APIYI (apiyi.com) tun, ohne eine eigene Infrastruktur aufbauen zu müssen.
Q3: Ist die API für GLM-5.1 bereits auf APIYI verfügbar? Wie nutze ich sie?
Ja, sie ist verfügbar. Sie müssen lediglich die base_url des offiziellen OpenAI-SDKs auf https://api.apiyi.com/v1 ändern, den api_key durch Ihren APIYI-Schlüssel ersetzen und das model auf die entsprechende Modell-ID von GLM-5.1 setzen. Der Modellaufruf funktioniert sofort, ohne dass Sie Ihren Geschäftscode umschreiben müssen. Das "minimale Aufrufbeispiel" im Artikel zeigt die Python-Version; die SDKs für Node, Go und Rust funktionieren analog.
Q4: Ist GLM-5.1 besser als andere Open-Source-Modelle wie DeepSeek, Qwen oder Kimi?
Das größte Alleinstellungsmerkmal von GLM-5.1 ist das "Long-Range Agent Coding + Spitzenplatz bei SWE-Bench Pro" – ein Bereich, den DeepSeek, Qwen und Kimi bisher nicht in dieser Form dominiert haben. Wenn Ihr Fokus auf "alltäglichen Dialogen + RAG" liegt, sind DeepSeek und Qwen nach wie vor sehr wettbewerbsfähig. Wenn Ihr Schwerpunkt jedoch auf Coding Agents / IDE-Integration / Code-Reparatur liegt, ist GLM-5.1 derzeit die erste Wahl in der Open-Source-Welt. Auf APIYI können Sie diese Modelle in einem direkten Vergleichstest gegenüberstellen und sich innerhalb von 15 Minuten ein eigenes Urteil bilden.
Q5: Welche Hardware wird für die lokale Bereitstellung von GLM-5.1 benötigt?
GLM-5.1 basiert auf einer MoE-Architektur mit 754 Mrd. Gesamtparametern (40 Mrd. aktiv). Eine lokale Bereitstellung erfordert professionelle Multi-GPU-Cluster, was für normale Teams kaum realistisch ist. Z.ai empfiehlt offiziell den Einsatz von vLLM, SGLang oder KTransformers für eine groß angelegte Inferenz-Bereitstellung. Wenn Sie GLM-5.1 lediglich nutzen und nicht erforschen möchten, ist der effizienteste Weg der direkte Aufruf über APIYI (apiyi.com) – ohne GPU-Kosten, ohne Wartungsaufwand und mit nutzungsbasierter Abrechnung.
Q6: Wurde GLM-5.1 wirklich ohne Nvidia-GPUs trainiert?
Ja. Z.ai hat offengelegt, dass GLM-5.1 vollständig auf Huawei Ascend 910B-Chips mit dem MindSpore-Framework trainiert wurde, ohne den Einsatz von Nvidia- oder AMD-GPUs. Dies ist der erste Fall im Bereich der Open-Source-Großen Sprachmodelle im Jahr 2026, bei dem das Training eines 754B MoE-Modells vollständig auf heimischer Hardware realisiert wurde, was eine erhebliche industrielle Bedeutung hat.
Zusammenfassung: GLM-5.1 ist der Wendepunkt für Open-Source-KI im Jahr 2026
Nachdem wir Architektur, Benchmarks, Preise, Trainings-Stacks und API-Zugriffswege analysiert haben, ist die Position von GLM-5.1 zum Stand April 2026 eindeutig: Es ist nicht einfach nur ein weiteres gewöhnliches Open-Source-Modell-Update, sondern ein Meilenstein, der beweist, dass Open Source tatsächlich mit den führenden geschlossenen Modellen konkurrieren kann. Der weltweite erste Platz bei SWE-Bench Pro mit 58,4 Punkten, die vollständige Öffnung unter der MIT-Lizenz, der extrem niedrige Preis von 1,00 $/3,20 $, ein Kontextfenster von 200.000 Token bei 128.000 Token Output, die 8-stündige Agenten-Fähigkeit sowie der vollständige Trainings-Stack auf Huawei Ascend 910B – jeder dieser Fakten wäre einen eigenen Bericht wert, doch zusammen markieren sie den "Wendepunkt für Open Source".
Die noch bessere Nachricht für Entwickler in Festlandchina: Die GLM-5.1 API ist jetzt über APIYI verfügbar. Sie müssen keine 754B-Gewichte selbst bereitstellen, benötigen keine ausländische Kreditkarte und müssen auf keine Genehmigungen warten. Ändern Sie einfach die base_url auf https://api.apiyi.com/v1 und das Modell auf GLM-5.1. Sie können noch heute Ihr primäres Coding-Modell in Cursor, Cline oder Claude Code durch diesen neuen Open-Source-König ersetzen. Falls Sie sich immer noch über die Rechnungen von Opus oder GPT-5 ärgern, ist dies ein Zeitfenster, das einen Nachmittag zum Testen definitiv wert ist.
🎯 Abschließende Empfehlung: Wenn Sie die "führende Coding-Leistung + Open-Source-Preise + stabile APIYI-Anbindung" von GLM-5.1 sofort erleben möchten, empfehlen wir Ihnen, noch heute auf apiyi.com einen API-Schlüssel zu erstellen. Ändern Sie die
base_urlIhres bestehenden OpenAI-SDKs aufhttps://api.apiyi.com/v1und das Modell aufGLM-5.1und testen Sie es eine Woche lang mit den alltäglichen Coding-Aufgaben Ihres Teams. Unabhängig davon, ob Sie dauerhaft wechseln, wird Ihnen dieser einwöchige Praxistest ein fundiertes Verständnis über den tatsächlichen Stand der Open-Source-KI im Jahr 2026 vermitteln.
Autor: APIYI Team | Wir konzentrieren uns auf die Implementierung großer Sprachmodelle und das Open-Source-Ökosystem. Weitere Informationen zu GLM-5.1 / Claude / GPT-5 sowie Praxisbeispiele und Vergleiche finden Sie bei APIYI unter apiyi.com.