The xAI Grok 4.20 Beta series has officially launched on the APIYI platform. We’ve added 4 new models in one go, covering everything from rapid-fire Q&A to deep, multi-agent research. Priced at $2 per million input tokens and $6 per million output tokens, it’s currently one of the most cost-effective choices among mainstream flagship models.
These four models aren't just incremental version bumps; they represent fundamental architectural differences. Some are built for lightning-fast responses, others are optimized for deep reasoning, and one even allows four AI agents to collaborate simultaneously—slashing the hallucination rate by 65%.
Core Value: By the end of this article, you’ll understand the positioning and best use cases for each of the 4 Grok 4.20 Beta models, learn how to perform model invocations, and be equipped to make the best model selection for your needs.

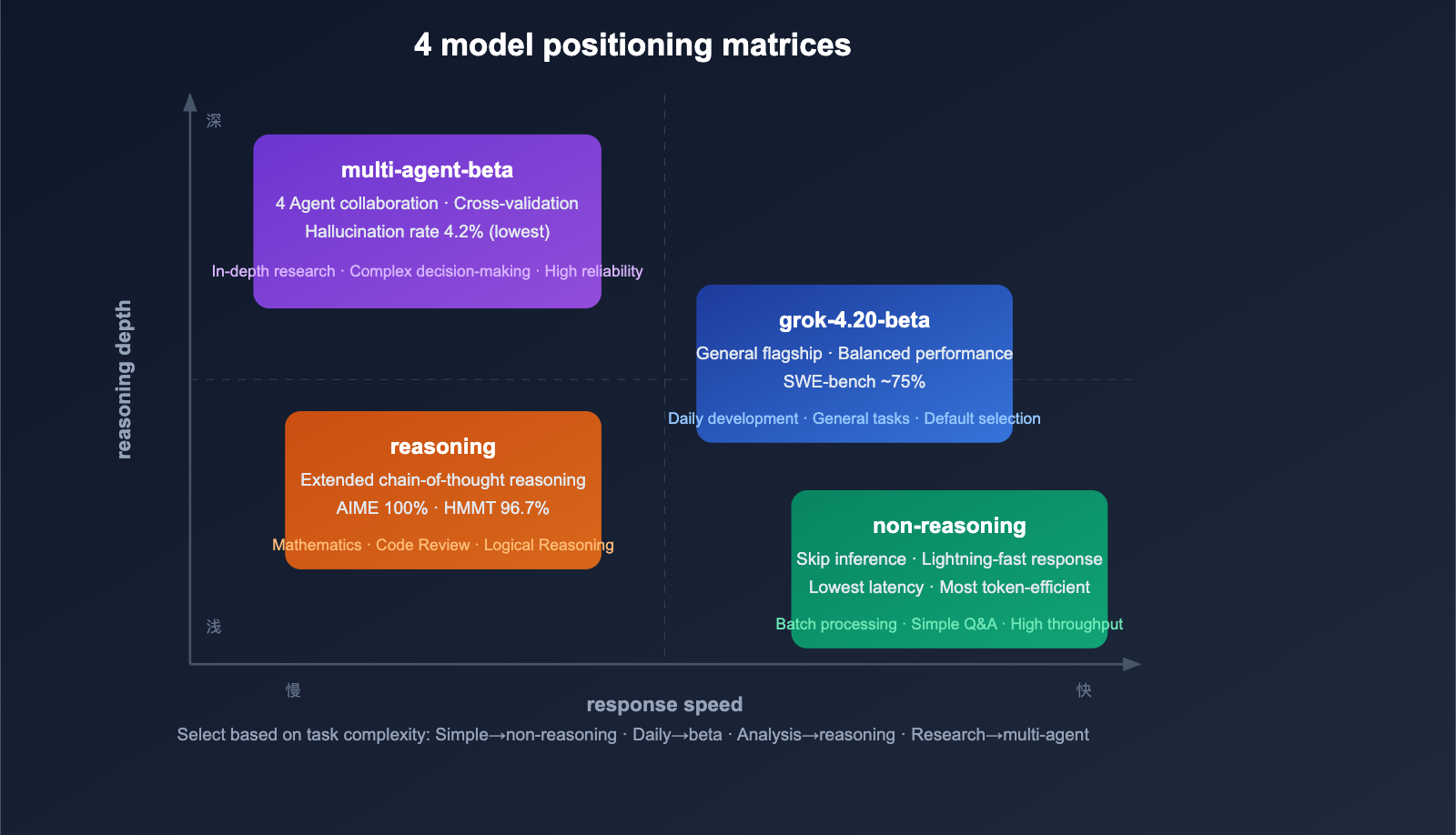
A Quick Look at the 4 Models: Core Differences
Model Matrix
| Model ID | Positioning | Core Feature | Best Use Case |
|---|---|---|---|
grok-4.20-beta |
General Flagship | Balanced performance and speed | Daily development, general tasks |
grok-4.20-multi-agent-beta-0309 |
Multi-agent Collaboration | 4 Agents working in parallel | Deep research, complex analysis |
grok-4.20-beta-0309-non-reasoning |
Rapid Response | Skips reasoning chain, low latency | High-throughput batching, simple Q&A |
grok-4.20-beta-0309-reasoning |
Deep Reasoning | Extended chain-of-thought | Math, code analysis, logic proofs |
Unified Pricing
| Billing Item | Price |
|---|---|
| Input token | $2.00 / million tokens |
| Output token | $6.00 / million tokens |
| Context window | 2 million tokens (2M) |
| Batch discount | 50% |
Price Comparison with Competitors:
| Model | Input Price | Output Price | Cost-Effectiveness |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 Best |
| Gemini 3.1 Pro | $2.00 | $12.00 | Good |
| GPT-5.4 | $2.50 | $15.00 | Average |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Average |
| Claude Opus 4.6 | $15.00 | $75.00 | High |
The output price of Grok 4.20 is only 40% of Claude Sonnet 4.6 and just 8% of Claude Opus 4.6. For output-intensive tasks like code generation or long-form writing, the cost advantage is massive.
🎯 Pricing Note: The Grok 4.20 Beta series available on APIYI (apiyi.com) is priced exactly the same as the xAI official site ($2 input / $6 output), with additional discounts available through platform recharge events. A single API key allows you to access over 200 models, including Grok, Claude, and GPT.
In-Depth Analysis of 4 Models
Model 1: grok-4.20-beta (General Flagship)
This is the default entry point for the Grok 4.20 series, striking a great balance between performance, speed, and cost.
Key Features:
- Inherits the full capabilities of the Grok 4 family
- 2 million token context window—the largest among Western frontier models
- Supports image input (JPG/PNG)
- Continuously improved weekly based on real-world feedback
Benchmark Performance:
- SWE-bench: ~75% (close to GPT-5's 74.9%)
- GPQA (Graduate level): 88.4%
- Arena Elo: ~1,505-1,535
Use Cases: Daily coding assistance, content creation, data analysis, and general conversation.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified endpoint
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "Implement an LRU cache in Python"}
]
)
print(response.choices[0].message.content)
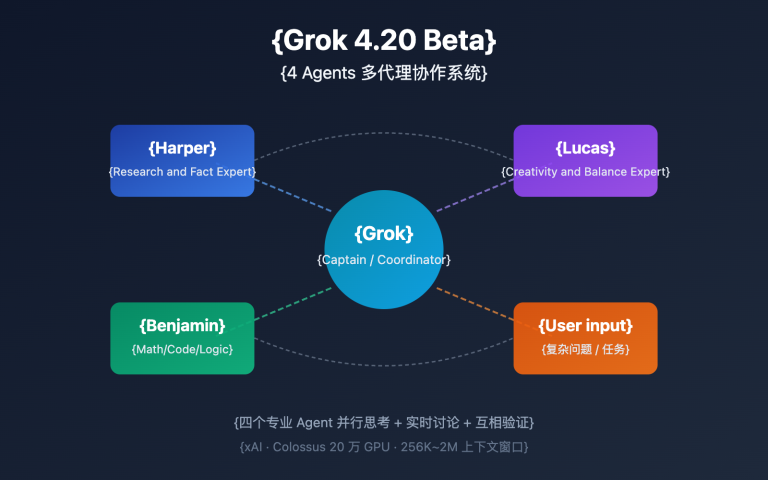
Model 2: grok-4.20-multi-agent-beta-0309 (Multi-Agent)
This is the most innovative variant of Grok 4.20—it uses 4 AI agents collaborating simultaneously to process your request.
The 4 Agents and Their Roles:
| Agent | Role | Expertise |
|---|---|---|
| Grok (Captain) | Coordinator | Task decomposition, workflow management, output aggregation |
| Harper | Researcher | Real-time data retrieval, fact-checking (integrated with X/Twitter data) |
| Benjamin | Analyst | Logical reasoning, mathematical calculation, code analysis |
| Lucas | Challenger | Creative synthesis, built-in opposition—questions the conclusions of other agents |
Workflow:
User Query
↓
Grok decomposes the task → assigns it to 4 agents
↓
Harper gathers data | Benjamin analyzes logic | Lucas challenges findings
↓
Internal debate + cross-validation among agents
↓
Grok aggregates consensus → returns final answer
Key Highlight—65% Reduction in Hallucinations:
| Metric | Single Model Baseline | Multi-Agent Mode | Improvement |
|---|---|---|---|
| Hallucination Rate | ~12% | ~4.2% | 65% reduction |
| "Say I don't know" rate | — | 78% | Industry-leading |
Lucas's "built-in opposition" is a key design choice: its job is to find holes in the conclusions of other agents. This adversarial collaboration makes the final output much more reliable.
Use Cases: In-depth research reports, complex decision analysis, and tasks requiring high-trust output.
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "Analyze the competitive landscape and trends for AI programming tools in 2026"}
]
)
Model 3: grok-4.20-beta-0309-non-reasoning (Non-Reasoning)
This variant is optimized for speed and throughput. It skips the internal Chain-of-Thought and generates answers directly.
Key Features:
- Low latency, high throughput
- Does not generate internal reasoning tokens, saving on output costs
- Ideal for simple, straightforward tasks
Use Cases:
- High-frequency API calls (batch data processing)
- Chatbots / Customer service systems
- Content classification, tag extraction
- Simple code completion
- Translation, summarization
Not Recommended For: Complex mathematical derivations, multi-step logical analysis, or architectural design requiring deep thought.
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "Convert the following JSON to CSV format: ..."}
]
)
Model 4: grok-4.20-beta-0309-reasoning (Reasoning)
This is the deep reasoning variant, the counterpart to the non-reasoning version. It enables an extended Chain-of-Thought, performing deep internal reasoning before providing an answer.
Key Features:
- Extended reasoning tokens for deep problem analysis
- Exceptional performance in math and logic tasks (AIME 2025: 100%, HMMT25: 96.7%)
- Artificial Analysis Intelligence Index: 48
Use Cases:
- Mathematical proofs and derivations
- Code review and bug analysis
- Architectural design trade-offs
- Complex logical argumentation
- Academic paper analysis
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "Analyze potential race conditions and deadlock risks in this concurrent code"}
]
)
💡 Selection Guide: For most daily tasks,
grok-4.20-betais sufficient. Use the multi-agent version for high-trust output, the non-reasoning version for batch processing, and the reasoning version for complex analysis. You can access all 4 models with a single API key via APIYI (apiyi.com) and switch between them as needed.
Model Selection Decision Tree
Choosing by Task Type
| Task Type | Recommended Model | Reason |
|---|---|---|
| Daily Coding Assistance | grok-4.20-beta |
Balances performance and cost |
| Batch Data Processing | non-reasoning |
Fastest speed, lowest latency |
| Code Review/Bug Analysis | reasoning |
Requires deep reasoning |
| Research Report Writing | multi-agent |
4-agent cross-validation |
| Real-time Data Analysis | multi-agent |
Harper integrates real-time X data |
| Math/Logical Deduction | reasoning |
100% perfect score on AIME |
| Chatbot | non-reasoning |
Low latency, fast response |
| Translation/Summarization | non-reasoning |
Simple tasks don't require reasoning |
| Architecture Design | reasoning or multi-agent |
Requires trade-off analysis |
Choosing by Cost Sensitivity
Extreme Savings → non-reasoning (No reasoning tokens, minimal output)
↓
Daily Value → grok-4.20-beta (General-purpose balance)
↓
Quality First → reasoning (Deep reasoning, more output tokens)
↓
Highest Reliability → multi-agent (4 agents, most detailed output)
🚀 Quick Start: We recommend starting with
grok-4.20-beta. Register via APIYI (apiyi.com) to get your API key. Pricing is identical to the official xAI site ($2 input / $6 output), with discounts applied through recharge promotions.
Grok 4.20 vs. Mainstream Models: A Side-by-Side Comparison
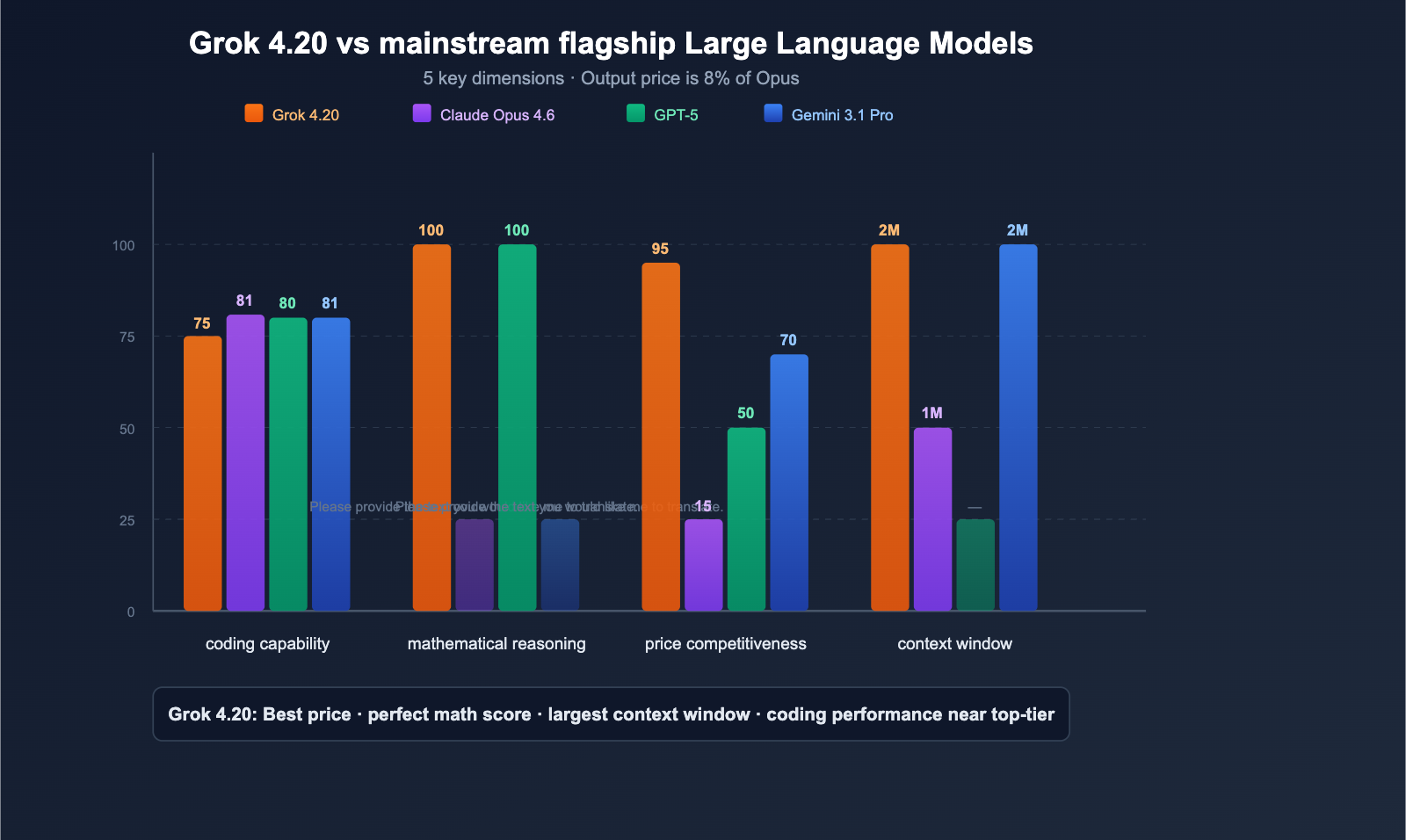
Full Dimension Comparison
| Dimension | Grok 4.20 Beta | Claude Opus 4.6 | GPT-5 Series | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| Math (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| Context Window | 2M | 1M | Varies by model | 2M |
| Input Price | $2 | $15 | $2.50 | $2 |
| Output Price | $6 | $75 | $15 | $12 |
| Multi-agent | ✅ 4 Agents | ❌ | ❌ | ❌ |
| Real-time Data | ✅ X/Twitter | ❌ | ✅ Search | ✅ Search |
| Hallucination Control | 4.2% (Lowest) | Lower | Lower | Medium |
| Image Input | ✅ JPG/PNG | ✅ Multi-format | ✅ Multi-format | ✅ Multi-format |
Best Use Cases for Each Model
- Grok 4.20: High cost-performance, general-purpose, deep research (multi-agent), real-time data analysis
- Claude Opus 4.6: Software engineering (highest SWE-bench), ultra-long output (128K), enterprise-grade security
- GPT-5: Perfect math scores, desktop automation, largest user ecosystem
- Gemini 3.1 Pro: Google ecosystem integration, 2M context window, moderate cost
💰 Cost-Performance Analysis: The output price of Grok 4.20 ($6/MTok) is only 8% of Claude Opus 4.6 ($75/MTok). For output-intensive tasks (long code generation, research reports), using Grok 4.20 can reduce costs by over 90%. Through APIYI (apiyi.com), you can access the full range of Grok, Claude, and GPT models, switching flexibly based on your task requirements.
Practical API Invocation
Basic Invocation Example
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI unified interface
)
# General task → Basic version
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "You are a senior Python developer."},
{"role": "user", "content": "Implement an asynchronous task queue"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
Automatic Model Selection Based on Tasks
def choose_grok_model(task_type):
"""Automatically select the optimal Grok model based on task type"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# Usage example
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Analyze the performance bottlenecks in this code..."}]
)
View Multi-Model Comparison Test Code
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Implement quicksort in Python and analyze its time complexity"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" Time taken: {elapsed:.1f}s | Tokens: {tokens}")
print(f" Preview: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | Error: {e}")
time.sleep(1)
🎯 Practical Advice: I recommend running a benchmark with
grok-4.20-betafirst, then comparing the output quality for complex tasks against thereasoningversion. You can access all 4 models via APIYI (apiyi.com); pricing is consistent with the official site, with discounts available through top-up promotions.
FAQ
Q1: Is the pricing the same for all 4 models?
Yes, all 4 models share a unified price: $2 per million tokens for input and $6 for output. However, the actual cost varies by model—reasoning models generate more reasoning tokens (counted as output), and the multi-agent version may consume more tokens due to the collaboration of 4 agents. The non-reasoning version is the most cost-effective as it skips the reasoning chain and produces fewer output tokens. Pricing via APIYI (apiyi.com) matches the official xAI site, with discounts applied via platform top-up events.
Q2: What is the difference between the multi-agent version and the reasoning version?
The reasoning version features a single agent performing deep thinking—ideal for analytical tasks with clear answers (math, code review). The multi-agent version involves 4 agents collaborating in a discussion—perfect for open-ended questions requiring multi-perspective analysis (market research, decision analysis). The core advantage of the multi-agent version is cross-verification, which reduces the hallucination rate (from 12% down to 4.2%).
Q3: Can Grok 4.20 replace Claude for code reviews?
In some scenarios, yes. The Grok 4.20 reasoning version achieves ~75% on SWE-bench, lower than Claude Opus 4.6's 81.4%, but at only 8% of the cost. For non-critical daily code reviews, the Grok 4.20 reasoning version is a high-value choice. For security audits and large-scale architectural reviews, Claude Opus 4.6 remains more reliable. You can access both models via APIYI (apiyi.com) and switch between them flexibly based on the task.
Q4: What are the practical uses for a 2-million token context window?
2 million tokens is roughly equivalent to a 1,500-page technical book. Practical applications include: (1) Loading an entire medium-to-large codebase for analysis at once; (2) Processing ultra-long documents (legal contracts, academic paper collections); (3) Maintaining long-term conversation memory. This is currently the largest context window among leading Western models.
Q5: How do I call these models on the APIYI platform?
After registering at APIYI (apiyi.com) and obtaining your API key, simply use the OpenAI-compatible format. Just set the base_url to https://api.apiyi.com/v1 and the model to the corresponding model ID (e.g., grok-4.20-beta). See the code examples above for details. Pricing for all 4 models is consistent with the official site, with discounts provided through top-up promotions.
Summary: Optimal Usage Strategies for 4 Models
The Grok 4.20 Beta series offers precise model selections for various scenarios. The core strategy is to match the model to the task complexity:
| Complexity | Recommended Model | Cost |
|---|---|---|
| 🟢 Simple/High-frequency | non-reasoning |
Lowest |
| 🟡 Daily General-purpose | grok-4.20-beta |
Moderate |
| 🟠 Deep Analysis | reasoning |
Higher |
| 🔴 Highest Reliability | multi-agent |
Highest |
With its $2/$6 pricing, Grok 4.20 stands out as the flagship model with the lowest output cost currently on the market. Combined with a 2-million token context window and a multi-agent system, it's incredibly competitive for research, analysis, and high-throughput scenarios.
We recommend accessing the full Grok 4.20 Beta series via APIYI (apiyi.com). It's a one-stop shop where pricing matches the official site, and you can take advantage of discounts through recharge promotions. With a single API key, you can access over 200 models, including Grok, Claude, and GPT.
References
-
xAI Official Documentation: Grok models and pricing details
- Link:
docs.x.ai/developers/models
- Link:
-
Artificial Analysis: Grok 4.20 Beta benchmark evaluation
- Link:
artificialanalysis.ai/models/grok-4-20
- Link:
-
xAI Multi-Agent Documentation: In-depth look at Multi-Agent capabilities
- Link:
docs.x.ai/developers/model-capabilities/text/multi-agent
- Link:
-
OpenRouter: Grok 4.20 Beta model page
- Link:
openrouter.ai
- Link:
Author: APIYI Team | We launch the latest AI models as soon as they drop. Visit APIYI at apiyi.com to experience the full Grok 4.20 Beta series.