Author's Note: A deep dive into the Claude Opus 4.7 benchmarks: 87.6% on SWE-bench Verified, 64.3% on SWE-bench Pro, and 94.2% on GPQA Diamond. It sweeps the floor with GPT-5.4 and Gemini 3.1 Pro. API invocation guide included.
Anthropic officially released Claude Opus 4.7 on April 16, 2026, taking the lead in 7 out of 10 core benchmarks. In this article, we’ll take a deep dive into the core data from the Claude Opus 4.7 benchmark and explore its practical use cases from a real-world testing perspective.
This is not a recap of official marketing materials. All data comes from independent third-party evaluation agencies, covering both the strengths and the shortcomings of Opus 4.7, such as its performance in web search scenarios.
Core Value: Through real-world benchmark data and hands-on experience, I’ll help you decide whether it's worth switching to Claude Opus 4.7 and how to get started at a low cost.
💡 APIYI has already launched support for the official Claude Opus 4.7 model. Recharge $100 and get at least 10% extra, effectively giving you a 20% discount. It supports OpenAI-compatible interfaces for one-click replacement.

Key Highlights of the Claude Opus 4.7 Benchmark
| Benchmark Project | Opus 4.7 Score | vs. Opus 4.6 | vs. GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% (+6.8) | Gemini 3.1 Pro: 80.6% ✅ Leading |
| SWE-bench Pro | 64.3% | 53.4% (+10.9) | GPT-5.4: 57.7% / Gemini: 54.2% ✅ Leading |
| SWE-bench Multilingual | 80.5% | 77.8% (+2.7) | ✅ Leading in multilingual programming |
| GPQA Diamond | 94.2% | – | ✅ The gold standard for scientific reasoning |
| Terminal-Bench 2.0 | 69.4% | – | ✅ Leading in terminal operations |
| OSWorld-Verified (Computer Use) | 78.0% | 72.7% (+5.3) | GPT-5.4: 75.0% ✅ Leading |
| MCP-Atlas (Tool Use) | Leads GPT-5.4 by +9.2 pts | – | ✅ Best for Agent scenarios |
| Vision Multimodal | 98.5% | – | ✅ Top-tier visual understanding |
| BrowseComp (Web Search) | 79.3% | – | GPT-5.4: 89.3% ❌ Lagging |
Core Takeaways from Claude Opus 4.7 Benchmark Testing
Anthropic released Claude Opus 4.7 on April 16, 2026, positioning it as the most powerful Large Language Model generally available (per VentureBeat). In direct 10-point comparisons with GPT-5.4 and Gemini 3.1 Pro, Opus 4.7 took the lead in 7 categories, with the most significant margin in SWE-bench Pro.
The most notable figure is the 64.3% in SWE-bench Pro—currently the industry's highest score for real-world software engineering tasks. This is 6.6 percentage points higher than GPT-5.4's 57.7% and a massive 10.9-point leap over Opus 4.6's 53.4%. In the MCP-Atlas tool invocation benchmark, Opus 4.7 leads GPT-5.4 by a full 9.2 points, meaning it’s better suited for Agentic AI scenarios like automated workflows, coding agents, and multi-step reasoning tasks.
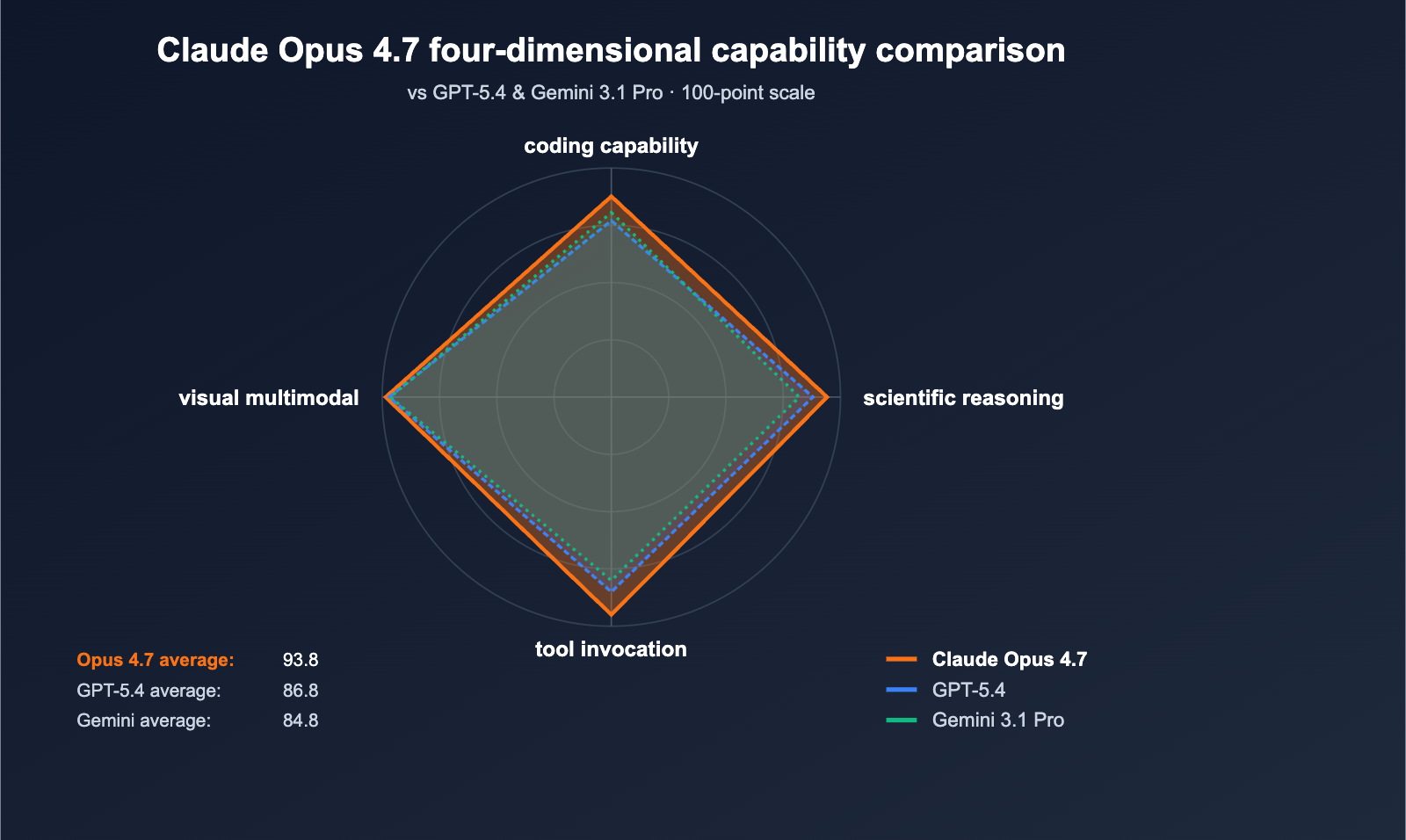
description: A comprehensive comparison of the Claude Opus 4.7 model against its predecessors and competitors, covering performance, features, and cost-efficiency.
Claude Opus 4.7 vs. Previous Generations and Competitors
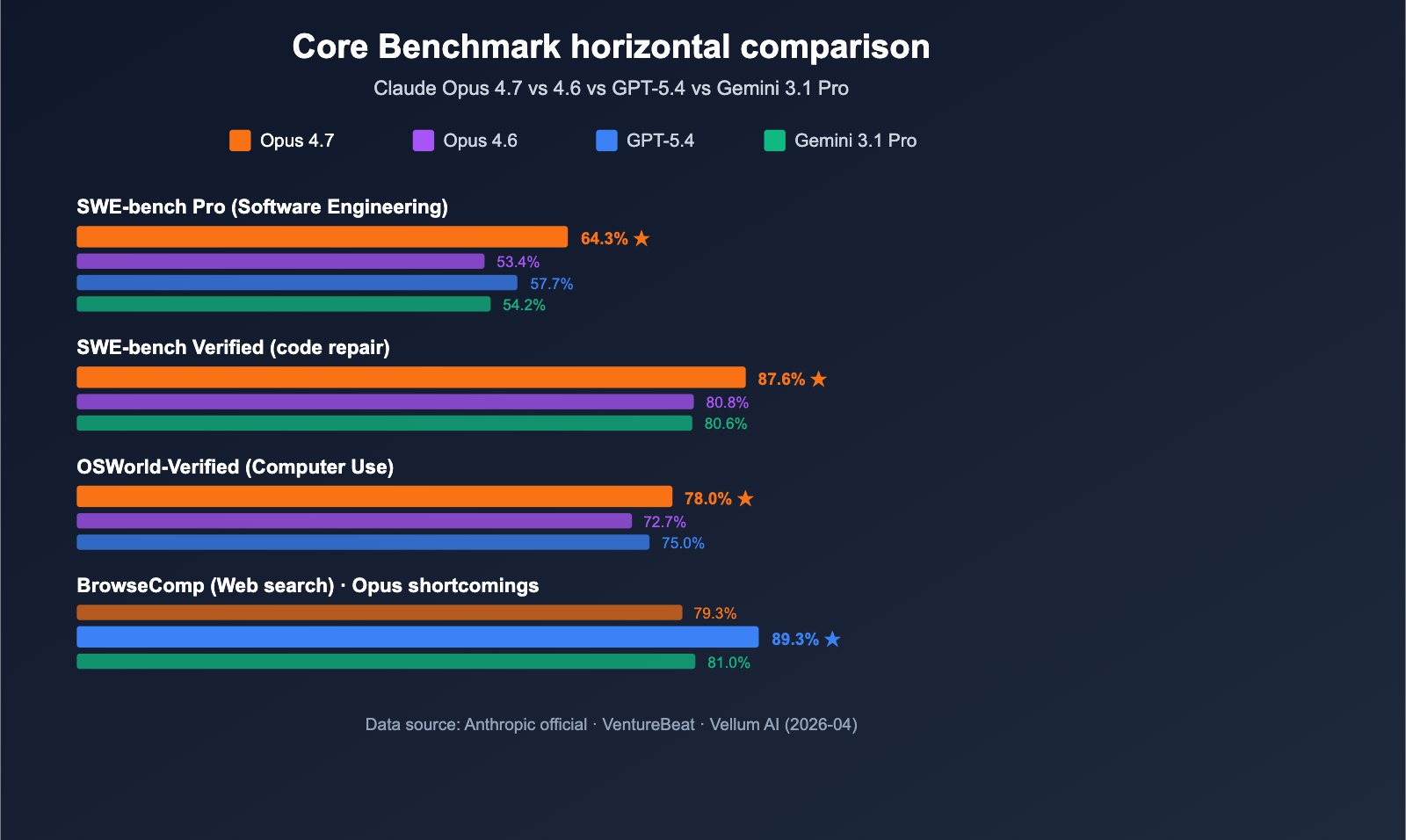
| Dimension | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Release Date | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| Context Window | 1M tokens (Standard) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Agent/Tool Invocation | Top-tier | Good | Strong | Good |
| Web Search (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Vision Multimodal | 98.5% | 95% | 97% | 96.5% |
| Official API Price | $5 / $25 (Input/Output per 1M tokens) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| APIYI Comprehensive Discount | Top up $100 for 10% bonus (approx. 20% off) | Same discount | Same discount | Same discount |
Comparison Breakdown (Claude Opus 4.7 vs. Others)
Claude Opus 4.7 vs. GPT-5.4: GPT-5.4 holds the lead in web searching via BrowseComp (89.3% vs 79.3%). However, it falls significantly behind Opus 4.7 in SWE-bench Pro (57.7%) and tool invocation (MCP-Atlas). In contrast, Claude Opus 4.7 shines in programming agents, code generation, and multi-step task execution, making it a better fit for developer workflows.
Claude Opus 4.7 vs. Gemini 3.1 Pro: Gemini 3.1 Pro remains ahead in long-context understanding and multimodal video scenarios. However, the performance gap is clear in SWE-bench Verified (80.6% vs 87.6%) and SWE-bench Pro (54.2% vs 64.3%). Claude Opus 4.7 provides a significant lead in software engineering tasks, making it better suited for production-level coding.
Claude Opus 4.7 vs. Opus 4.6: Opus 4.6 is still a solid choice for cost-sensitive tasks. But 4.7 brings massive leaps in programming capability, agentic reasoning, and computer use, all while keeping the API price unchanged. For teams dealing with complex, multi-stage workflows, upgrading to 4.7 is basically a no-brainer.
Note on Data: The data above is sourced from official Anthropic releases, VentureBeat, Vellum AI, Decrypt, and other third-party evaluation agencies. You can run your own tests on the APIYI (apiyi.com) platform.
Quick Start with Claude Opus 4.7
Minimalist Example
Here's the simplest way to call Claude Opus 4.7 via APIYI using an OpenAI-compatible interface:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Write a Python function for inorder traversal of a binary tree."}]
)
print(response.choices[0].message.content)
View full implementation (including xhigh Effort Mode)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
Call Claude Opus 4.7 with support for xhigh effort mode.
Args:
prompt: User input
effort_level: Reasoning effort level, options are "low" / "medium" / "high" / "xhigh"
system_prompt: System prompt
max_tokens: Maximum output tokens
Returns:
Model response content
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# xhigh mode is recommended for complex programming tasks
result = call_claude_opus_47(
prompt="Design and implement an LRU cache that supports O(1) get and put operations.",
effort_level="xhigh",
system_prompt="You are a senior Python engineer; write code that balances readability with performance."
)
print(result)
Tip: Head over to apiyi.com to grab free testing credits and quickly verify how Claude Opus 4.7 performs for your specific use cases. The platform provides a unified, OpenAI-compatible interface for Opus 4.7, GPT-5.4, and Gemini 3.1 Pro, making cross-model comparisons a breeze. Recharge now to get 10% or more in bonus credits, effectively giving you a 20% discount on official model pricing.
Performance and Use Cases for Claude Opus 4.7
4 Core Scenarios Where Claude Opus 4.7 Excels
- 🧑💻 Large-scale Code Refactoring: With a SWE-bench Verified score of 87.6%, it effectively understands cross-file context—perfect for architecture adjustments, dependency upgrades, and batch refactoring in 100k-line codebases.
- 🤖 Agentic Workflows: Outperforming GPT-5.4 by 9.2 points in MCP-Atlas tool calls, it’s ideal for building browser automation, RPA, and multi-step reasoning agents.
- 🔬 Research & Reasoning: A GPQA Diamond score of 94.2% demonstrates graduate-level reasoning capabilities, perfect for research assistance, data analysis, and hypothesis verification.
- 🖥️ Computer Use Desktop Automation: Leading the industry with a 78.0% score in OSWorld-Verified, it’s the go-to for automated testing and UI operations that require mouse and keyboard simulation.
When NOT to use Claude Opus 4.7
- Real-time Web Search: With a BrowseComp score of 79.3%, it significantly trails GPT-5.4's 89.3%. We recommend switching to GPT-5.4 for these tasks.
- High-volume/Low-cost Calls: At $25/M tokens for output, you're better off using Claude Haiku or GPT-5.4-mini for daily conversational apps.
- Ultra-low Latency Requirements: The Opus series has higher response latency than Sonnet or Haiku; be careful using it for real-time interactive applications.
Claude Opus 4.7 Pricing and Cost Estimation
Official Pricing vs. APIYI Combined Costs
| Item | Official Price (Anthropic) | APIYI Price (Incl. Top-up Bonuses) |
|---|---|---|
| Input tokens | $5 / million tokens | Same as official unit price |
| Output tokens | $25 / million tokens | Same as official unit price |
| Top-up Bonus | None | 10% bonus starting at $100 |
| Effective Discount | None | Approx. 20% off (higher tiers get more) |
| Payment Methods | USD Credit Card only | Supports CNY, USD, and more |
| Billing Currency | USD | RMB / USD options available |
Cost Note: The new tokenizer in Opus 4.7 consumes about 1x-1.35x more tokens when processing text compared to version 4.6 (fluctuating based on content type). While the official unit price hasn't increased, your actual bill could rise by about 20-30%. By taking advantage of the deposit bonuses at APIYI (apiyi.com), you can offset these hidden costs, keeping your actual usage expenses on par with—or even lower than—the 4.6 era.
Frequently Asked Questions (FAQ)
Q1: What is Claude Opus 4.7?
Claude Opus 4.7 is the flagship Large Language Model released by Anthropic on April 16, 2026. It leads in multiple benchmarks, including coding (SWE-bench Verified 87.6%), Agent tool invocation, and scientific reasoning (GPQA Diamond 94.2%), outperforming GPT-5.4 and Gemini 3.1 Pro. Compared to Opus 4.6, it introduces the new "xhigh effort" deep reasoning mode, all while maintaining the same official pricing.
Q2: Which is better, Claude Opus 4.7 or GPT-5.4?
It depends on your use case. Opus 4.7 clearly leads in programming (SWE-bench Pro 64.3% vs 57.7%), tool invocation (MCP-Atlas +9.2 points), and Computer Use (78.0% vs 75.0%). However, GPT-5.4 holds the advantage in web searching (BrowseComp 79.3% vs 89.3%). Choose Opus 4.7 for development workflows, and GPT-5.4 for web-connected research tasks.
Q3: When was Claude Opus 4.7 released, and when will it be available locally?
The official release date was April 16, 2026. It is already available via Claude API, Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Developers can access the official model synchronously via aggregation platforms like APIYI (apiyi.com) without needing to apply for an overseas account.
Q4: What real-world projects is Claude Opus 4.7 best suited for?
It's primarily suited for these scenarios:
- Large-scale code refactoring: Understanding cross-file context, dependency migration, and architectural adjustments.
- Agent automation: MCP toolchains, browser automation, and RPA processes.
- Research and data analysis: Graduate-level reasoning, hypothesis verification, and research paper assistance.
- Computer Use desktop automation: UI automated testing and GUI operation scripts.
Q5: How can I quickly use Claude Opus 4.7 via API?
We recommend using an aggregation platform that supports the OpenAI-compatible protocol. You can get started in 3 easy steps:
- Visit APIYI (apiyi.com) to register and obtain your API key.
- Top up $100 to get at least a 10% bonus (effectively ~20% off), or test it first with the free credit.
- Update your OpenAI SDK's
base_urltohttps://vip.apiyi.com/v1and set the model toclaude-opus-4-7.
APIYI supports unified access to major models like Claude Opus 4.7, GPT-5.4, and Gemini 3.1 Pro, making it easy to compare and switch between them.
Q6: Are there any known limitations to Claude Opus 4.7?
Key limitations include:
- Increased token consumption: The new tokenizer uses 1x-1.35x more tokens than 4.6, potentially increasing your bill by 20-30%.
- Web search gap: With a BrowseComp score of 79.3%, it trails behind GPT-5.4 for real-time web-connected tasks.
- Latency: Opus series latency is higher than Sonnet/Haiku; consider using lighter models for real-time conversational apps.
- Higher official unit price: At $5/$25 per million tokens, we recommend using the deposit bonuses at APIYI to hedge costs for high-volume calls.
Q7: What is the context window for Claude Opus 4.7?
Claude Opus 4.7 supports a 1 million (1M) token context window at standard pricing, with no extra charges for long contexts. This means you can process an entire mid-sized codebase, long technical documentation, or complete meeting transcripts in a single request—equivalent to about 750,000 Chinese characters or 200 PDF pages.
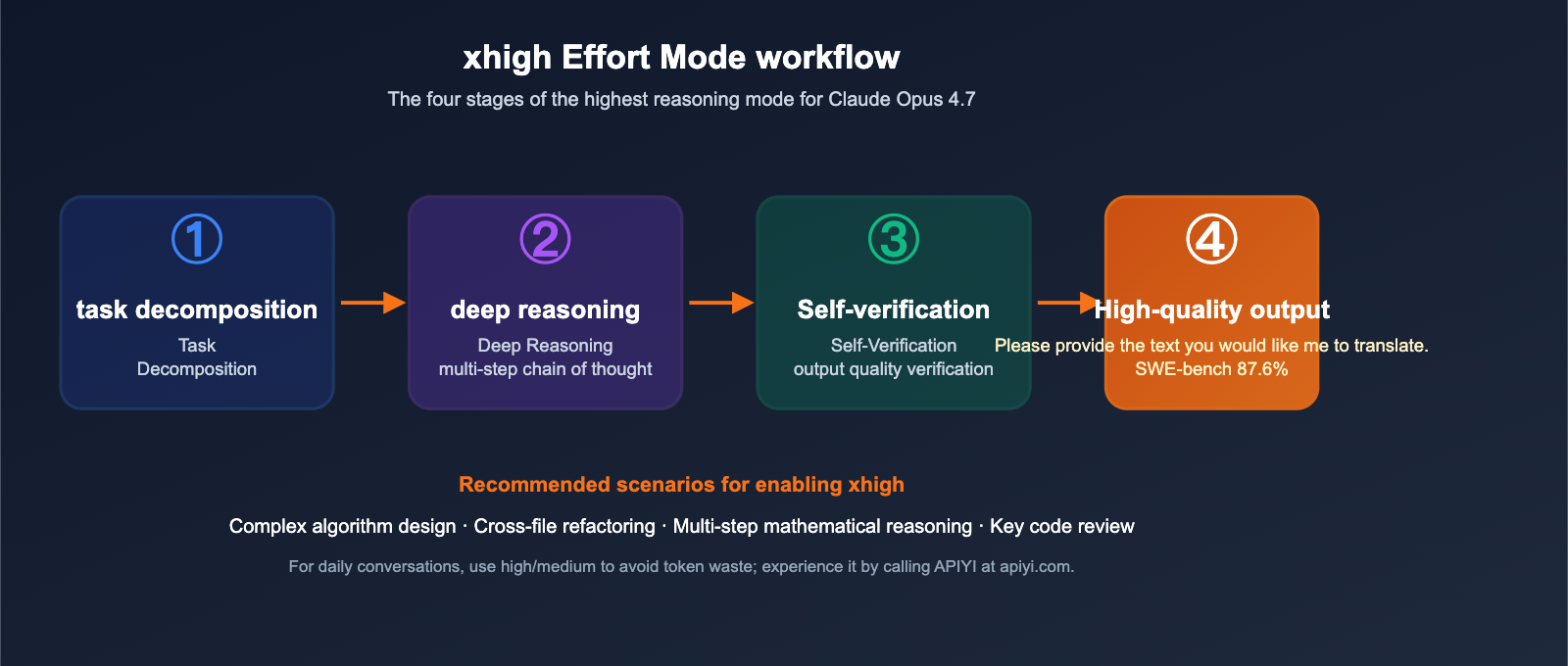
Q8: What is “xhigh effort” mode, and when should I use it?
"xhigh effort" is a new top-tier reasoning mode in Opus 4.7, where the model dedicates more tokens and time to multi-step thinking and self-verification. We recommend enabling it for:
- Complex algorithm design (e.g., LRU caches, distributed consistency).
- Refactoring tasks spanning multiple files.
- Mathematical reasoning requiring multi-step logical chains.
- Critical code reviews and vulnerability audits.
For daily conversations or simple CRUD coding, high or medium settings are sufficient and help avoid unnecessary token costs.
Claude Opus 4.7 Key Takeaways
- 🏆 Leader across 7 major benchmarks: 64.3% on SWE-bench Pro, 87.6% on Verified, 94.2% on GPQA, and leads GPT-5.4 by 9.2 points on MCP-Atlas.
- 💡 xhigh Effort Mode: Introduces a new top-tier reasoning mode, perfect for complex algorithms and cross-file refactoring.
- 🚀 Built for Agent scenarios: Leads the pack in tool calling and Computer Use, making it the top choice for Agentic AI.
- ⚠️ Web search limitations: Trails GPT-5.4 by 10 points in BrowseComp; consider comparing models if your work relies heavily on live web searching.
- 💰 Get 20% off with APIYI: Official pricing remains steady, but through apiyi.com, you get at least a 10% bonus on $100+ top-ups, effectively bringing costs down by about 20%.
Summary
The benchmark data for Claude Opus 4.7 points to one clear conclusion: it’s currently the most powerful general-purpose model for programming and Agent scenarios. Here’s the breakdown:
- Unrivaled in programming: With 64.3% on SWE-bench Pro, it far outperforms GPT-5.4 and Gemini 3.1 Pro, making it the go-to for production-grade coding tasks.
- King of Agent tool calling: It holds a 9.2-point lead in MCP-Atlas and a 3-point lead in Computer Use, making it the top pick for automation workflows.
- Keep an eye on real-world costs: The new tokenizer results in a 20-30% implicit cost increase, so it's smart to use aggregators to offset the price with top-up bonuses.
If your focus is on AI programming, Agent development, or complex reasoning tasks, Claude Opus 4.7 is worth switching to immediately. We recommend giving it a spin via APIYI (apiyi.com)—it features instant access to the latest official models, one-click replacement for OpenAI-compatible interfaces, and at least a 10% bonus on $100 top-ups, effectively giving you a 20% discount while skipping the headache of overseas accounts and direct USD payments.
Related Articles
If you're interested in the Claude Opus 4.7 benchmark, we recommend checking out these resources:
- 📘 Complete Guide to Claude Opus 4.7 Model Invocation – Learn the full usage of High Effort Mode, prompt caching, and tool calling.
- 📊 GPT-5.4 vs. Claude Opus 4.7 vs. Gemini 3.1 Pro: An In-depth Comparison – Master the decision-making process for selecting the top three flagship models across various niche scenarios.
- 🚀 MCP Protocol and Claude Opus 4.7 Agent in Action – Explore how to build production-grade agent workflows using Opus 4.7.
📚 References
-
Official Anthropic Announcement: Claude Opus 4.7 product introduction and benchmark data
- Link:
anthropic.com/news/claude-opus-4-7 - Note: Primary source of data, including all official benchmark results.
- Link:
-
VentureBeat Independent Review: Analysis of how Opus 4.7 reclaimed the top spot among general-purpose Large Language Models
- Link:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - Note: A third-party perspective providing a comprehensive comparison of Opus 4.7 against its competitors.
- Link:
-
Vellum AI Benchmarks Breakdown: A deep dive into the benchmark methodology and credibility
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Note: Ideal for technical readers who want to understand the benchmark methodology in detail.
- Link:
-
Official Claude API Documentation: Explanations of the context window, pricing, and tokenizer
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Note: The authoritative reference for integration and model invocation, including migration guides.
- Link:
Author: APIYI Technical Team
Technical Discussion: Feel free to share your experience with Claude Opus 4.7 in the comments. For more resources on API invocation, visit the APIYI documentation center at docs.apiyi.com.





