作者注: Claude Opus 4.7 基準測試深度解讀: SWE-bench Verified 87.6%、SWE-bench Pro 64.3%、GPQA Diamond 94.2%,橫掃 GPT-5.4 和 Gemini 3.1 Pro,附 API 調用實戰。
Anthropic 於 2026 年 4 月 16 日正式發佈 Claude Opus 4.7,在 10 項核心基準中拿下 7 項領先。本文將從實際測評角度,深度解讀 Claude Opus 4.7 benchmark 的核心數據和適用場景。
這不是官方宣傳的複述,所有數據都來自第三方獨立評測機構,包含優點也包含 Opus 4.7 在 web 搜索等場景的短板。
核心價值: 通過真實 benchmark 數據和使用體驗,幫你判斷 Claude Opus 4.7 是否值得切換、以及如何低成本上手。
💡 API 易已同步上線 Claude Opus 4.7 官方模型,充值 100 美金送 10% 起,綜合相當於 8 折享用,支持 OpenAI 兼容接口一鍵替換。

Claude Opus 4.7 Benchmark 核心要點
| 基準項目 | Opus 4.7 成績 | 對比 Opus 4.6 | 對比 GPT-5.4 / Gemini 3.1 Pro |
|---|---|---|---|
| SWE-bench Verified | 87.6% | 80.8% (+6.8) | Gemini 3.1 Pro: 80.6% ✅領先 |
| SWE-bench Pro | 64.3% | 53.4% (+10.9) | GPT-5.4: 57.7% / Gemini: 54.2% ✅領先 |
| SWE-bench Multilingual | 80.5% | 77.8% (+2.7) | ✅ 多語言編程領先 |
| GPQA Diamond | 94.2% | – | ✅ 科學推理標杆 |
| Terminal-Bench 2.0 | 69.4% | – | ✅ 終端操作領先 |
| OSWorld-Verified (Computer Use) | 78.0% | 72.7% (+5.3) | GPT-5.4: 75.0% ✅領先 |
| MCP-Atlas (工具調用) | 領先 GPT-5.4 +9.2 分 | – | ✅ Agent 場景最優 |
| Vision 多模態 | 98.5% | – | ✅ 視覺理解頂級 |
| BrowseComp (Web 搜索) | 79.3% | – | GPT-5.4: 89.3% ❌ 落後 |
Claude Opus 4.7 基準測試核心亮點
Anthropic 2026 年 4 月 16 日發佈 Claude Opus 4.7,定位爲目前通用可用的最強大 LLM (VentureBeat 評價)。在與 GPT-5.4、Gemini 3.1 Pro 的 10 項直接對比中,Opus 4.7 拿下 7 項領先,其中 SWE-bench Pro 的領先幅度最大。
最值得關注的是 SWE-bench Pro 64.3% 這個數字——這是目前業界在真實軟件工程任務上的最高成績,比 GPT-5.4 的 57.7% 高出 6.6 個百分點,比 Opus 4.6 的 53.4% 躍升 10.9 個百分點。在 MCP-Atlas 工具調用基準上,Opus 4.7 領先 GPT-5.4 高達 9.2 分,這意味着它更適合 Agentic AI 場景,比如自動化工作流、代碼生成 Agent、多步推理任務。

Claude Opus 4.7 與前代及競品模型對比
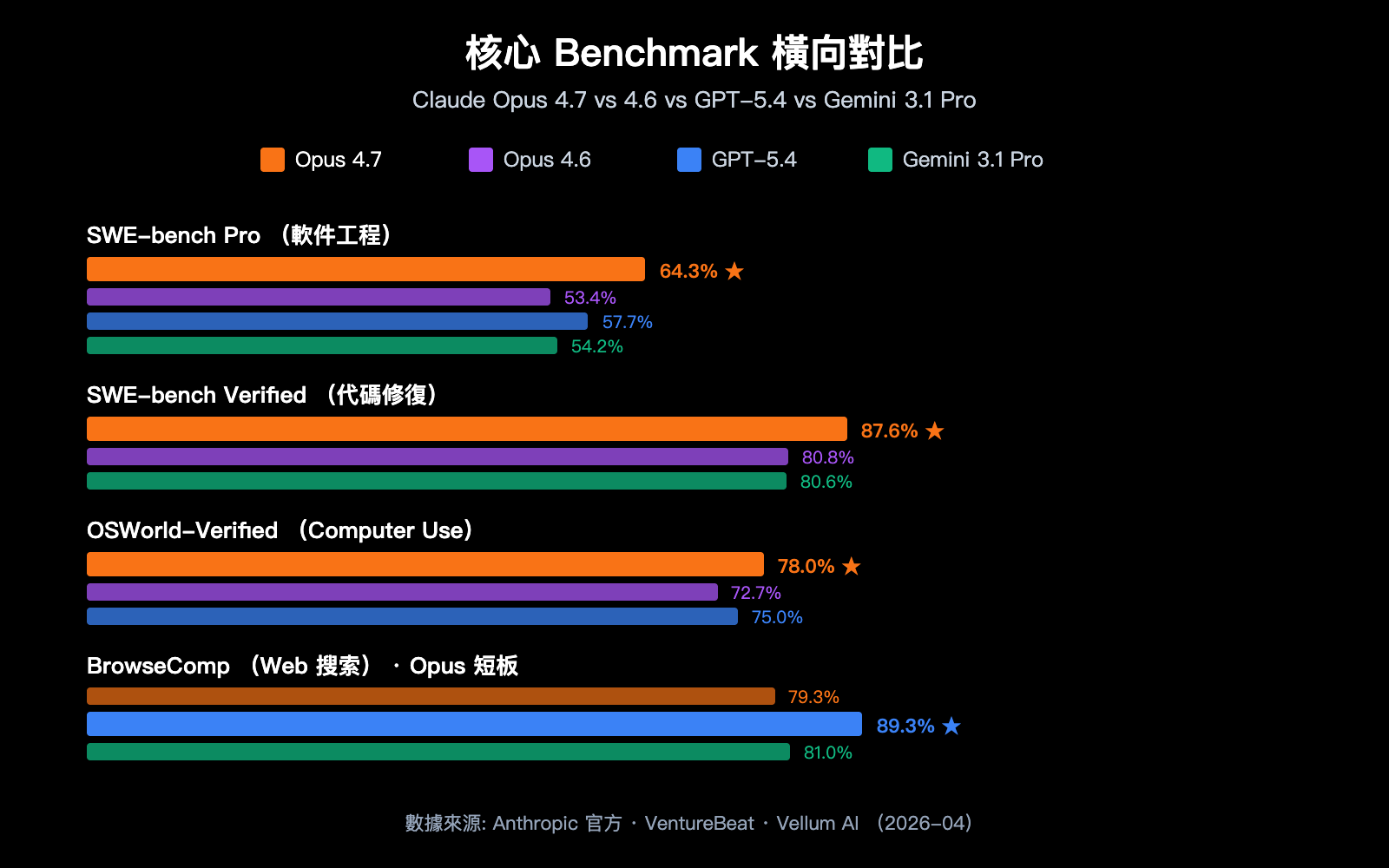
| 維度 | Claude Opus 4.7 | Claude Opus 4.6 | GPT-5.4 | Gemini 3.1 Pro |
|---|---|---|---|---|
| 發佈日期 | 2026-04-16 | 2026-01 | 2026-03 | 2026-02 |
| 上下文窗口 | 1M tokens (標準價) | 200K | 400K | 1M |
| SWE-bench Pro | 64.3% | 53.4% | 57.7% | 54.2% |
| Agent/工具調用 | 最強 | 良好 | 強 | 良好 |
| Web 搜索 (BrowseComp) | 79.3% | 72% | 89.3% | 81% |
| Vision 多模態 | 98.5% | 95% | 97% | 96.5% |
| 官方 API 價格 | $5 / $25 (輸入/輸出,每百萬 token) | $5 / $25 | $4.5 / $22 | $4 / $20 |
| API易 綜合折扣 | 充值 100 美金送 10% 起 ≈ 8 折 | 同優惠 | 同優惠 | 同優惠 |
對比解讀 (Claude Opus 4.7 vs 其他模型)
Claude Opus 4.7 vs GPT-5.4: GPT-5.4 在 BrowseComp 的 Web 搜索場景保持領先 (89.3% vs 79.3%)。但其在 SWE-bench Pro (57.7%) 和工具調用 (MCP-Atlas) 上明顯落後於 Opus 4.7。相比之下,Claude Opus 4.7 在編程 Agent、代碼生成、多步任務執行上更有優勢,更適合開發者工作流。
Claude Opus 4.7 vs Gemini 3.1 Pro: Gemini 3.1 Pro 在長文本理解和多模態視頻場景上仍保持領先。但在 SWE-bench Verified (80.6% vs 87.6%) 和 SWE-bench Pro (54.2% vs 64.3%) 上差距明顯。相比之下,Claude Opus 4.7 在軟件工程任務上幾乎是斷層領先,更適合生產級編程場景。
Claude Opus 4.7 vs Opus 4.6: Opus 4.6 在成本敏感場景下仍是穩定選擇。但 4.7 的編程能力、Agentic 推理、Computer Use 都有大幅躍升,且 API 價格保持不變。對於需要處理複雜長鏈路任務的團隊,4.7 幾乎是必升級選擇。
對比說明: 上述數據來源於 Anthropic 官方發佈、VentureBeat、Vellum AI、Decrypt 等第三方評測機構,可通過 API易 apiyi.com 平臺進行實測驗證。
Claude Opus 4.7 快速上手
極簡示例
以下是通過 API 易調用 Claude Opus 4.7 的最簡方式,使用 OpenAI 兼容接口:
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "用 Python 寫一個二叉樹中序遍歷的函數"}]
)
print(response.choices[0].message.content)
查看完整實現代碼 (含 xhigh Effort Mode 調用)
import openai
from typing import Optional
def call_claude_opus_47(
prompt: str,
effort_level: str = "high",
system_prompt: Optional[str] = None,
max_tokens: int = 4096
) -> str:
"""
調用 Claude Opus 4.7,支持 xhigh effort mode
Args:
prompt: 用戶輸入
effort_level: 推理努力等級,可選 "low" / "medium" / "high" / "xhigh"
system_prompt: 系統提示詞
max_tokens: 最大輸出 token 數
Returns:
模型響應內容
"""
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
try:
response = client.chat.completions.create(
model="claude-opus-4-7",
messages=messages,
max_tokens=max_tokens,
extra_body={
"reasoning_effort": effort_level
}
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# 複雜編程任務推薦使用 xhigh 模式
result = call_claude_opus_47(
prompt="設計並實現一個 LRU 緩存,支持 O(1) 的 get 和 put 操作",
effort_level="xhigh",
system_prompt="你是資深 Python 工程師,寫出可讀性和性能兼顧的代碼"
)
print(result)
建議: 通過 API 易 apiyi.com 獲取免費測試額度,快速驗證 Claude Opus 4.7 在你場景下的效果。平臺支持 Opus 4.7、GPT-5.4、Gemini 3.1 Pro 的統一 OpenAI 兼容接口,方便橫向對比。充值活動 100 美金送 10% 起,綜合相當於 8 折使用官方模型。
Claude Opus 4.7 實測表現與典型場景
適合 Claude Opus 4.7 的 4 類核心場景
- 🧑💻 大型代碼重構: SWE-bench Verified 87.6% 證明其能理解跨文件上下文,適合 10 萬行級代碼庫的架構調整、依賴升級、批量重構
- 🤖 Agent 自動化工作流: MCP-Atlas 工具調用領先 GPT-5.4 9.2 分,適合構建瀏覽器自動化、RPA、多步推理 Agent
- 🔬 科研輔助與推理: GPQA Diamond 94.2% 意味着研究生級別的學科推理能力,適合論文輔助、數據分析、假設驗證
- 🖥️ Computer Use 桌面自動化: OSWorld-Verified 78.0% 領先行業,適合需要模擬鼠標鍵盤的自動化測試、UI 操作
不適合 Claude Opus 4.7 的場景
- 實時 Web 搜索: BrowseComp 79.3%,明顯落後於 GPT-5.4 的 89.3%,此類場景建議切換 GPT-5.4
- 大規模低成本調用: 輸出價格 $25/M tokens,日常對話類應用建議使用 Claude Haiku 或 GPT-5.4-mini
- 超短延遲要求: Opus 系列響應延遲高於 Sonnet/Haiku,實時交互場景慎選
Claude Opus 4.7 價格與成本估算
官方定價 vs API 易綜合成本
| 項目 | 官方價格 (Anthropic) | API 易價格 (含充值贈送) |
|---|---|---|
| 輸入 token | $5 / 百萬 tokens | 同官方單價 |
| 輸出 token | $25 / 百萬 tokens | 同官方單價 |
| 充值贈送 | 無 | 100 美金送 10% 起 |
| 綜合等效折扣 | 無 | 約 8 折 (充值梯度越高贈送越多) |
| 支付方式 | 僅限美元信用卡 | 支持人民幣、美元、多種方式 |
| 賬單貨幣 | USD | RMB / USD 可選 |
成本提示: Opus 4.7 的新 tokenizer 在處理文本時會比 4.6 多消耗約 1x-1.35x tokens (根據內容類型波動)。雖然官方單價未漲,但實際賬單成本可能上升約 20-30%。通過 API 易 apiyi.com 的充值贈送優惠,可以抵消這部分隱性成本,實際使用成本持平甚至低於 4.6 時代。
常見問題 FAQ
Q1: 什麼是 Claude Opus 4.7?
Claude Opus 4.7 是 Anthropic 於 2026 年 4 月 16 日發佈的旗艦大模型,在編碼 (SWE-bench Verified 87.6%)、Agent 工具調用、科學推理 (GPQA Diamond 94.2%) 等多項基準上領先 GPT-5.4 和 Gemini 3.1 Pro。相比 Opus 4.6,它新增了 "xhigh effort" 深度推理模式,且官方價格未漲。
Q2: Claude Opus 4.7 和 GPT-5.4 哪個更好?
取決於場景。在編程 (SWE-bench Pro 64.3% vs 57.7%)、工具調用 (MCP-Atlas +9.2 分)、Computer Use (78.0% vs 75.0%) 上,Opus 4.7 明顯領先;但在 Web 搜索 (BrowseComp 79.3% vs 89.3%) 上 GPT-5.4 保持優勢。開發類工作流優選 Opus 4.7,聯網搜索類優選 GPT-5.4。
Q3: Claude Opus 4.7 什麼時候發佈?國內什麼時候能用?
官方發佈日期爲 2026 年 4 月 16 日,已上線 Claude API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry。國內開發者可通過 API 易 apiyi.com 等聚合平臺同步使用官方模型,無需申請海外賬號。
Q4: Claude Opus 4.7 最適合哪些實際項目?
主要適合以下場景:
- 大型代碼重構: 跨文件上下文理解、依賴遷移、架構調整
- Agent 自動化: MCP 工具鏈、瀏覽器自動化、RPA 流程
- 科研與數據分析: 研究生級別推理、假設驗證、論文輔助
- Computer Use 桌面自動化: UI 自動化測試、GUI 操作腳本
Q5: 如何通過 API 快速調用 Claude Opus 4.7?
推薦通過支持 OpenAI 兼容協議的聚合平臺調用,3 步即可上手:
- 訪問 API 易 apiyi.com 註冊賬號,獲取 API Key
- 充值 100 美金獲 10% 起贈送 (綜合約 8 折),或先用免費額度測試
- 將 OpenAI SDK 的
base_url改爲https://vip.apiyi.com/v1,model 填寫claude-opus-4-7
API 易支持 Claude Opus 4.7、GPT-5.4、Gemini 3.1 Pro 等主流模型統一接入,便於橫向對比切換。
Q6: Claude Opus 4.7 有哪些已知限制?
主要限制包括:
- Token 消耗增加: 新 tokenizer 比 4.6 多用 1x-1.35x tokens,實際賬單可能上升 20-30%
- Web 搜索短板: BrowseComp 79.3%,落後 GPT-5.4,實時聯網場景慎選
- 響應延遲: Opus 系列延遲高於 Sonnet/Haiku,實時對話類應用建議搭配輕量模型
- 官方單價較高: $5/$25 每百萬 token,大規模調用推薦通過 API 易享受充值贈送優惠對沖成本
Q7: Claude Opus 4.7 的上下文窗口是多少?
Claude Opus 4.7 支持 100 萬 (1M) tokens 上下文窗口,且爲標準定價,無長上下文加價。這意味着可以在一次請求中處理整個中型代碼倉庫、長篇技術文檔或完整會議記錄,相當於約 75 萬漢字或 200 個 PDF 頁面。
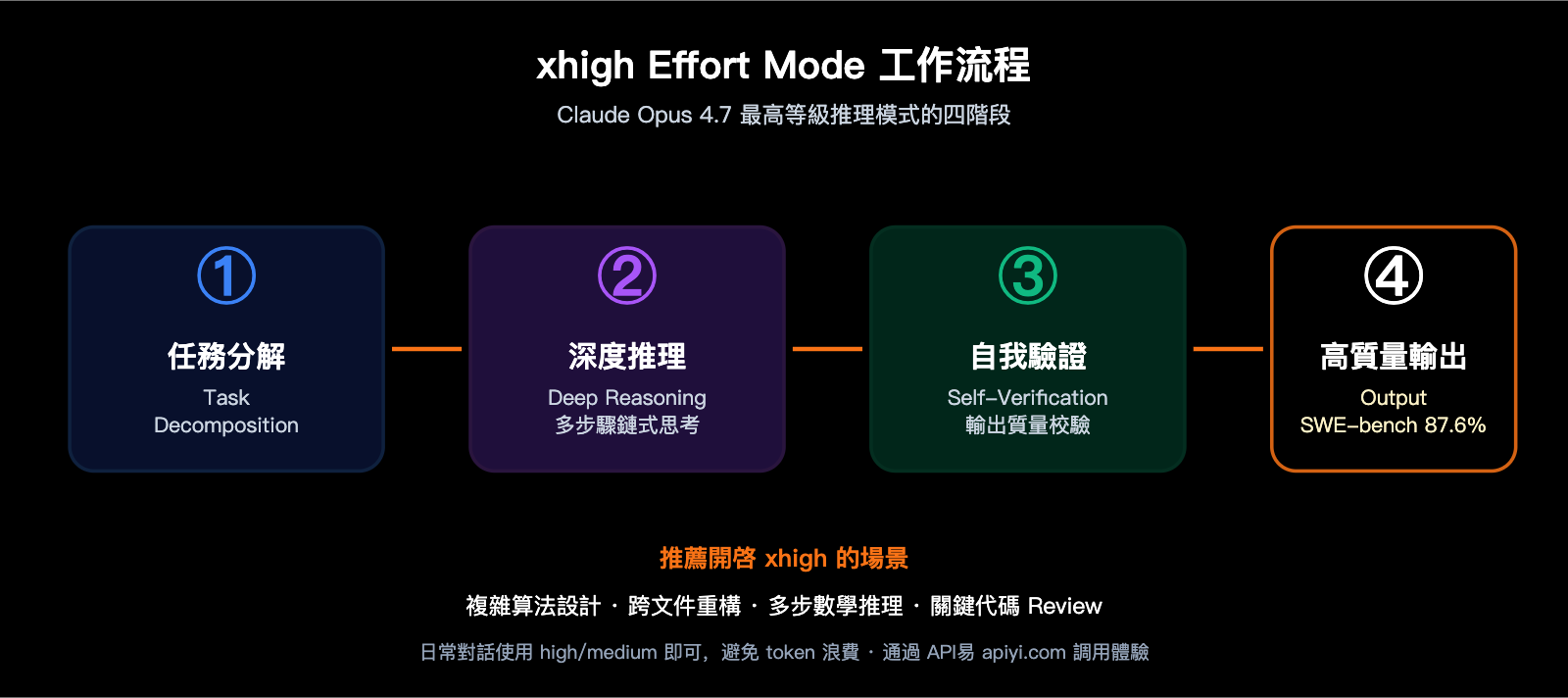
Q8: xhigh Effort Mode 是什麼?什麼時候用?
"xhigh effort" 是 Opus 4.7 新增的最高等級推理模式,模型會花費更多 token 和時間做多步思考與自我驗證。推薦在以下場景開啓:
- 複雜算法設計 (如 LRU 緩存、分佈式一致性)
- 跨多文件的重構任務
- 需要多步邏輯鏈的數學推理
- 關鍵代碼 Review 和漏洞審查
日常對話、簡單 CRUD 編寫等場景使用 high 或 medium 即可,避免不必要的 token 開銷。
Claude Opus 4.7 核心要點 Key Takeaways
- 🏆 7 大榜單領先: SWE-bench Pro 64.3%、Verified 87.6%、GPQA 94.2%、MCP-Atlas 領先 GPT-5.4 9.2 分
- 💡 xhigh Effort Mode: 新增最高等級推理模式,適合複雜算法與跨文件重構
- 🚀 適合 Agent 場景: 工具調用和 Computer Use 全面領先,Agentic AI 首選模型
- ⚠️ Web 搜索短板: BrowseComp 落後 GPT-5.4 10 分,聯網搜索場景建議對比選型
- 💰 API 易 8 折上手: 官方單價未漲,通過 apiyi.com 充值 100 美金送 10% 起,綜合約 8 折
總結
Claude Opus 4.7 benchmark 數據清晰指向一個結論——它是當前編程和 Agent 場景下的最強通用模型。關鍵要點:
- 編程斷層領先: SWE-bench Pro 64.3% 遠超 GPT-5.4 和 Gemini 3.1 Pro,生產級代碼任務首選
- Agent 工具調用王者: MCP-Atlas 領先 9.2 分,Computer Use 領先 3 分,自動化場景優選
- 實際成本需關注: 新 tokenizer 帶來 20-30% 的隱性成本上漲,需配合聚合平臺充值優惠對沖
如果你的工作重心在 AI 編程、Agent 開發、複雜推理任務上,Claude Opus 4.7 值得立刻切換。推薦通過 API 易 apiyi.com 快速體驗——官方模型同步上線、OpenAI 兼容接口一鍵替換、充值 100 美金送 10% 起相當於 8 折享用,免去海外賬號和美元支付的麻煩。
延伸閱讀 Related Articles
如果你對 Claude Opus 4.7 benchmark 感興趣,推薦繼續閱讀:
- 📘 Claude Opus 4.7 API 調用完整指南 – 瞭解 xhigh Effort Mode、Prompt Caching、工具調用的完整用法
- 📊 GPT-5.4 vs Claude Opus 4.7 vs Gemini 3.1 Pro 深度對比 – 掌握三大旗艦模型在各細分場景的選型決策
- 🚀 MCP 協議與 Claude Opus 4.7 Agent 實戰 – 探索如何用 Opus 4.7 構建生產級 Agent 工作流
📚 參考資料
-
Anthropic 官方發佈公告: Claude Opus 4.7 產品介紹和 benchmark 數據
- 鏈接:
anthropic.com/news/claude-opus-4-7 - 說明: 一手數據來源,包含全部官方基準測試成績
- 鏈接:
-
VentureBeat 獨立評測: Opus 4.7 在通用 LLM 中重回第一的分析
- 鏈接:
venturebeat.com/technology/anthropic-releases-claude-opus-4-7-narrowly-retaking-lead-for-most-powerful-generally-available-llm - 說明: 第三方獨立視角,對 Opus 4.7 vs 競品的綜合對比
- 鏈接:
-
Vellum AI Benchmarks 解讀: 逐項拆解 benchmark 方法論與可信度
- 鏈接:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - 說明: 適合想深入理解基準測試方法的技術讀者
- 鏈接:
-
Claude 官方 API 文檔: 上下文窗口、pricing、tokenizer 說明
- 鏈接:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - 說明: 集成與調用的權威參考,含遷移指南
- 鏈接:
作者: APIYI 技術團隊
技術交流: 歡迎在評論區討論 Claude Opus 4.7 的使用體驗,更多 API 調用資料可訪問 API 易 docs.apiyi.com 文檔中心





